Hello, and welcome to the May 2025 ClickHouse newsletter!
This month, we have a deep dive into how ClickHouse has become "lazier", why the Microsoft Clarity analytics platform chose ClickHouse, an MCP/Real-Time Analytics panel, viewer retention metrics with ClickHouse, and more!
Featured community member: Can Tian #
This month's featured community member is Can Tian, Senior Data Platform Engineer at DeepL.

Can Tian has a background in building scalable, cloud-native data systems using Python, C++, and modern infrastructure tools. With experience across DeepL, FactoryPal, and Springer Nature, he has worked on everything from data engineering to analytics and platform design.
Can has made impactful contributions to dbt-clickhouse, including adding support for incremental “microbatch” strategies, implementing schema change handling for distributed incremental models, and fixing critical issues related to ON CLUSTER statements in replicated databases.
Upcoming events #
It’s only two weeks until Open House, the ClickHouse User Conference in San Francisco on May 29, and the impressive lineup of speakers continues to grow.
Lyft engineers Jeana Choi and Ritesh Varyani will explain how they use ClickHouse for near-real-time and sub-second analytics, enabling swift decision-making.
Global events #
- v25.5 Community Call - May 22
Free training #
- ClickHouse FastTrack Training - Amsterdam - May 12
- ClickHouse Observability Training - Amsterdam - May 13
- ClickHouse Fundamentals Training - Virtual - May 14
- ClickHouse Developer FastTrack Training - Munich - May 14
- ClickHouse Developer Training - Virtual - May 21
- ClickHouse Fundamentals - Virtual - May 20, May 22, June 11
- ClickHouse Developer Training - Virtual - May 21-22
- In-Person ClickHouse Query Optimization Workshop - San Francisco - May 28
- In-Person ClickHouse Developer Training Full Day San Francisco - May 28
- Integrating your Data Lake with ClickHouse - Virtual - June 5
Events in AMER #
- ClickHouse Meetup in Austin - May 13
- Microsoft Build - Seattle - May 19-21
- ClickHouse Meetup in Seattle - May 20
- AWS Summit Washington D.C. - June 10-11
- ClickHouse Meetup in Washington D.C. - June 12
- Confluent’s Financial Services Leaders Summit, New York - June 10
- ClickHouse Meetup in Atlanta - July 8
- ClickHouse Meetup in New York - July 15
- AWS Summit Toronto - September 4
- AWS Summit Los Angeles - September 17
Events in EMEA #
- Munich Happy Hour - May 14
- AWS Summit Dubai - May 21
- AWS Summit Tel Aviv - May 28
- AWS Summit Stockholm - June 4
- AWS Summit Hamburg - June 5
- AWS Summit Madrid - June 11
- Tech BBQ Copenhagen - August 27-28
- AWS Summit Zurich - September 11
- BigData London - September 24-25
- PyData Amsterdam - September 24-25
Events in APAC #
- DevOpsDays Singapore - May 15
- Data Engineering Summit, Bengaluru - May 15-16
- ClickHouse Meetup in Shenzhen - May 17
- AWS Summit Singapore - May 29
- AWS Summit Sydney - June 4-5
- Tokyo Meetup - AI Night! - June 5
- KubeCon + CloudNativeCon Japan - June 16-17
- AWS Summit Japan - June 25-26
25.4 release #

It’s difficult to pick my favorite feature in the 25.4 release, but if I must, I’d go for lazy materialization. This optimization defers reading column data until needed, resulting in much faster queries. More on that in the next section!
MergeTree tables on read-only disks can now refresh their state and load new data parts, which effectively lets us create a ClickHouse-native data lake. Also included in this release is CPU slot scheduling, which lets you cap the number of threads running concurrently for a given workload.
Finally, there’s a nice quality-of-life update in clickhouse-local: tables in the default database persist!
ClickHouse gets lazier (and faster): Introducing lazy materialization #

The lazy materialization functionality has been given the Tom Schreiber treatment, i.e., a super in-depth article breaking down how it works and the use cases it will help with.
Tom starts with ClickHouse’s existing building blocks of I/O efficiency and runs a real-world query through them, layer by layer, until lazy materialization kicks in and dramatically optimizes performance.
Why Microsoft Clarity chose ClickHouse #

Microsoft Clarity is a free analytics tool that helps website and app owners understand user interactions through visual snapshots and user interaction data. It provides heatmaps, session recordings, and insights.
When Microsoft decided to offer Clarity as a free public service, it needed to revamp its infrastructure. The original proof-of-concept using Elasticsearch and Spark couldn't handle the anticipated scale of millions of projects and hundreds of trillions of events. The system was slow, had low ingestion throughput, and would be prohibitively expensive at scale.
They turned to ClickHouse as a solution, and in the blog, they describe why they made that choice, what problems it has helped solve, and the challenges they encountered along the way.
Introducing AgentHouse #

Dmitry Pavlov announced AgentHouse, a chat-based demo environment where you can interact with ClickHouse datasets using the Claude Sonnet Large Language Model.
It uses LibreChat under the covers, which means that you can get not only text answers to your questions, but also interactive charts.
How we handle billion-row ClickHouse inserts with UUID range bucketing #

CloudQuery faced a challenge with ClickHouse when ingesting large batches of data, sometimes exceeding 25 million records per operation. These massive inserts caused out-of-memory errors because ClickHouse materializes the entire dataset in memory before spilling to disk.
To solve this problem, they developed an “Insert-Splitter” algorithm that breaks up large inserts into smaller, manageable chunks based on UUID ranges. This approach required careful implementation due to ClickHouse's UUID sorting behavior.
It worked well, though! Splitting a single 26-million-row insert into four balanced buckets reduced peak memory usage by 75% without sacrificing processing speed.
MySQL CDC connector for ClickPipes is now in Private Preview #

We recently announced the private preview of the MySQL Change Data Capture (CDC) connector in ClickPipes.
This lets customers replicate their MySQL databases to ClickHouse Cloud in just a few clicks and leverage ClickHouse for blazing-fast analytics. It works for continuous replication and one-time migration from MySQL, no matter where it's running.
Bootstrapping with ClickHouse #

William Attache from AB Tasty wanted to speed up some statistical algorithms that use bootstrapping data by implementing them directly in ClickHouse SQL.
The blog walks us through his trial-and-error process with ClickHouse's native functions, explaining why initial random number strategies failed and how he eventually solved the problem using SQL-based workarounds and Python user-defined functions.
Vimeo: behind viewer retention analytics at scale #
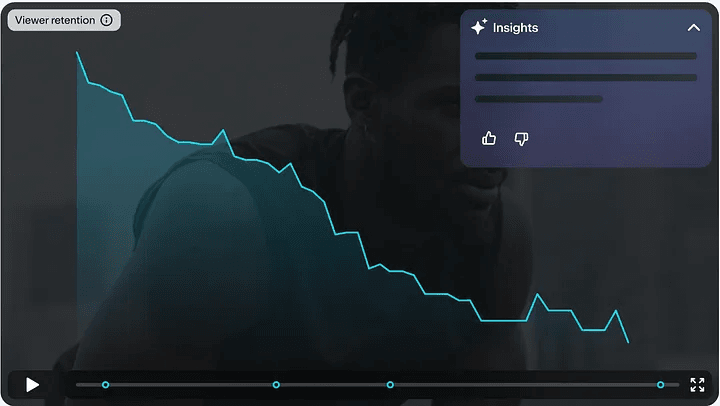
This article fascinated me as a video creator. While view counts provide basic feedback, understanding viewer retention - the percentage of viewers still watching each moment -offers deeper insights into content performance.
Vimeo's blog post reveals how they've built a sophisticated retention analytics system using ClickHouse. Rather than storing absolute view counts, they track viewing patterns by recording changes (+1 when a viewer starts watching a segment, -1 when they stop) and use window functions to calculate cumulative views at each second.
They have also built an AI-powered insights layer, pre-processing retention data through window averaging and run-length encoding to prevent overwhelming the AI's context window. Combined with carefully crafted prompt engineering, they can generate concise, actionable insights about viewer engagement patterns.
Video Corner #
- Gordon Chan, Staff Engineer at Buildkite (a scale-out delivery platform), shared their journey adopting ClickHouse for test analytics.
- Prathamesh Sonpatki, Developer Evangelist at Last9, shared his insights on observability challenges and solutions from building an observability platform that uses ClickHouse under the hood.
- Ryadh Dahimene hosted a panel discussion on Model Context Protocol (MCP) at the intersection of real-time analytics with experts from various companies. The participants included representatives from Anthropic, ClickHouse, RunReveal, Five One, and A16Z.
- I created a video showing how to backfill materialized views on existing tables.
- I also showed how to querying Apache Iceberg tables via the AWS Glue catalog.
- Finally, we have a short video explaining ClickHouse’s JSON data type.



