Extensive testing and comparison showed that ClickHouse outperformed other solutions like Elasticsearch in three key areas: performance, compatibility, and cost-efficiency for large-scale operations.
The fastest open-source analytical database
Open-source. Column-orientated. Built for blazingly fast analytics with SQL.
Applied to data warehousing, real-time analytics, observability and ML/GenAI workloads.

Start using ClickHouse in seconds
Install ClickHouse for macOS, Linux, and FreeBSD
curl https://clickhouse.com/ | shOr install for Windows, Docker or see other install options. Or try without installing in our playground.
Watch this getting started video to learn more about ClickHouse.
Choosing ClickHouse
The leading OSS analytics database
ClickHouse is an open-source, column-oriented SQL database built for speed and scale - running anywhere from a laptop to hundreds of servers at true petabyte scale. With a single binary, it unifies application analytics, warehousing, observability, and GenAI workloads in one blazing-fast engine.
Find out more
Migrating from Apache Druid
Optimize your performance and cut infrastructure costs with ClickHouse.
We needed something to slice and dice real-time data, like rides and driver hours across cities and regions where Lyft runs. Using ClickHouse resulted into a lot of performance benefits for us with huge cost savings for the org.
Find out more
Migrating from Snowflake
Cut costs and improve latency with true high concurrency - no tier gated features or pricing models that penalize interactivity.
It's a lot faster. The data is consistent. We have to do less work. It's just way, way better for us. Anything we're doing in Snowflake now that we can do cheaper or faster in ClickHouse, we want to do that.
Find out more
Migrating from BigQuery
Run highly-concurrency queries without second-long latency, CSP lock-in or run away costs due to per query pricing.
We needed a solution that could scale, but also provide end-user facing analytics capabilities with low latency and high throughput.
Find out more
Migrating from Redshift
Run faster cold queries, tap into broader integrations, and avoid CSP lock-in.
As data size grew, we faced performance and cost challenges with AWS Redshift. Switching to ClickHouse improved our query performance by 20 times and greatly cut costs.
Find out more
Migrating from Apache Pinot
Simplify your open-source stack and enjoy faster queries, richer aggregation functions, and full SQL compliance.
With ClickHouse, our performance is 10 times faster
Frequent releases for everyone
ClickHouse feature development moves as fast as it queries. We ship monthly releases packed with new features, performance improvements, and bug fixes - shared openly in our community release webinars.
Jul 2026
Jun 2026
Apr 2026

From your laptop to quadrillion scale and beyond
Scale the same engine on your laptop to billions, expand to trillions on a server, and then out to hundreds of nodes for quadrillions.

So what makes ClickHouse fast?
Learn what makes ClickHouse so fast from isolated inserts and queries, efficient data pruning, and high compression to a state-of-the-art query engine and, above all, meticulous attention to detail.







Powerful ClickHouse features
Full JOIN support
ClickHouse fully supports all standard join types and adds powerful non-equality capabilities such as ASOF join.
Continuous improvements to join algorithms deliver market leading performance, allowing users to query across normalized datasets without extra preprocessing - keeping analytics flexible and removing the need for forced denormalization.






Full Text Search
ClickHouse delivers fast, scalable token based search through native inverted indexes built directly into the storage engine.
Inverted indices enable analytics on large unstructured or semi-structured data at petabyte scale. Filter text precisely, then aggregate and join in the same SQL query with ClickHouse's signature speed and efficiency.

Built for high concurrency
Cloud-native architecture enables effective data tiering and scaling, resulting in the leading price / performance ratio on the market.
Lightweight data changes
ClickHouse delivers fast, reliable handling of updates and deletes through lightweight mutations that modify only the affected rows rather than rewriting entire datasets.
Patched parts allow efficient, fine-grained changes while preserving performance, making it practical to support evolving data, late arriving events, and workloads that require correction of historical records.

Flexible schema-on-write with JSON
ClickHouse lets you ingest semi-structured data without schema explosion, combining JSON flexibility with the full performance of a columnar database.


What's different about ClickHouse?
Open-source. Column-oriented. Built for blazingly fast analytics with SQL.
01
Query
Sparse primary index in memory
ClickHouse uses a sparse primary index - just a few megabytes per terabyte - scaling effortlessly while pruning data quickly. Query caches, advanced skip indices accelerating performance further. Inserts are equally fast, streamed row by row or in batches, with writes optimized through part sorting and separation of reads and writes, delivering throughput without slowing queries.

A parallelized, vectorized engine filters and aggregates data at speed across a single server or hundreds of nodes thanks to partial states, support for sharding and shared processing across replicas.
02
ClickHouse scales vertically, fully using machine resources and parallelizing reads at a low level.
A decentralized architecture with sharding and replication enables horizontal scaling to hundreds of nodes and quadrillions of rows.

ClickHouse Cloud builds on this foundation with separation of storage and compute: nodes read from a single authoritative copy in object storage, cache data locally, and scale compute dynamically both vertically and horizontally while all reads and writes stay consistent.

03
ClickHouse offers advanced features to manipulate, filter, and transform data efficiently. Materialized views can be refreshable or incremental, with incremental views shifting compute from query time to insert time and dramatically accelerating repeated queries.



Main table
...
...
...
...
PB
Materialized View
...
...
...
GB
Projections let you maintain the same data sorted in different ways, enabling ClickHouse to optimize for multiple access patterns and deliver consistently fast queries.

04
A column-oriented design delivers high compression, while the LSM-inspired engine and background merges keep parts compact and queries fast, no matter how large the dataset.
ClickHouse is built on a unique architecture with a pluggable storage layer: data can live on SSDs, spinning disks, or object storage, and can naturally flow across tiers from hot to cold.

05

ClickHouse ensures reliability through its replication model, which uses Raft-based coordination via Keeper and provides either immediate or eventual consistency depending on requirements. This lightweight design enables replication across availability zones or even regions with high latencies, delivering high durability without heavy overhead.

For long-term protection, backups can be written to object storage, giving teams confidence their data is safe and recoverable.
Snapshots offer a lightweight means to create a point in time of your data.
06
With support for 70+ file formats for ingestion and output, ClickHouse delivers unmatched interoperability.

The ability to read and write open table and lake formats such as Parquet, Iceberg, and Delta, with catalog integrations like AWS Glue and Unity making them seamless to query - bringing the performance of ClickHouse's query engine to your data lake.

ClickHouse is a full database engine with complete SQL support, including joins, and an optimizer that can reorder joins globally and leverage column statistics automatically. It extends standard SQL with 100s of analytical functions, making complex aggregations and filters simpler and more expressive.
All proven by benchmarks that can be reproduced by anyone.
At ClickHouse, we measure performance relentlessly - believing every millisecond matters. We continually push to make queries faster.
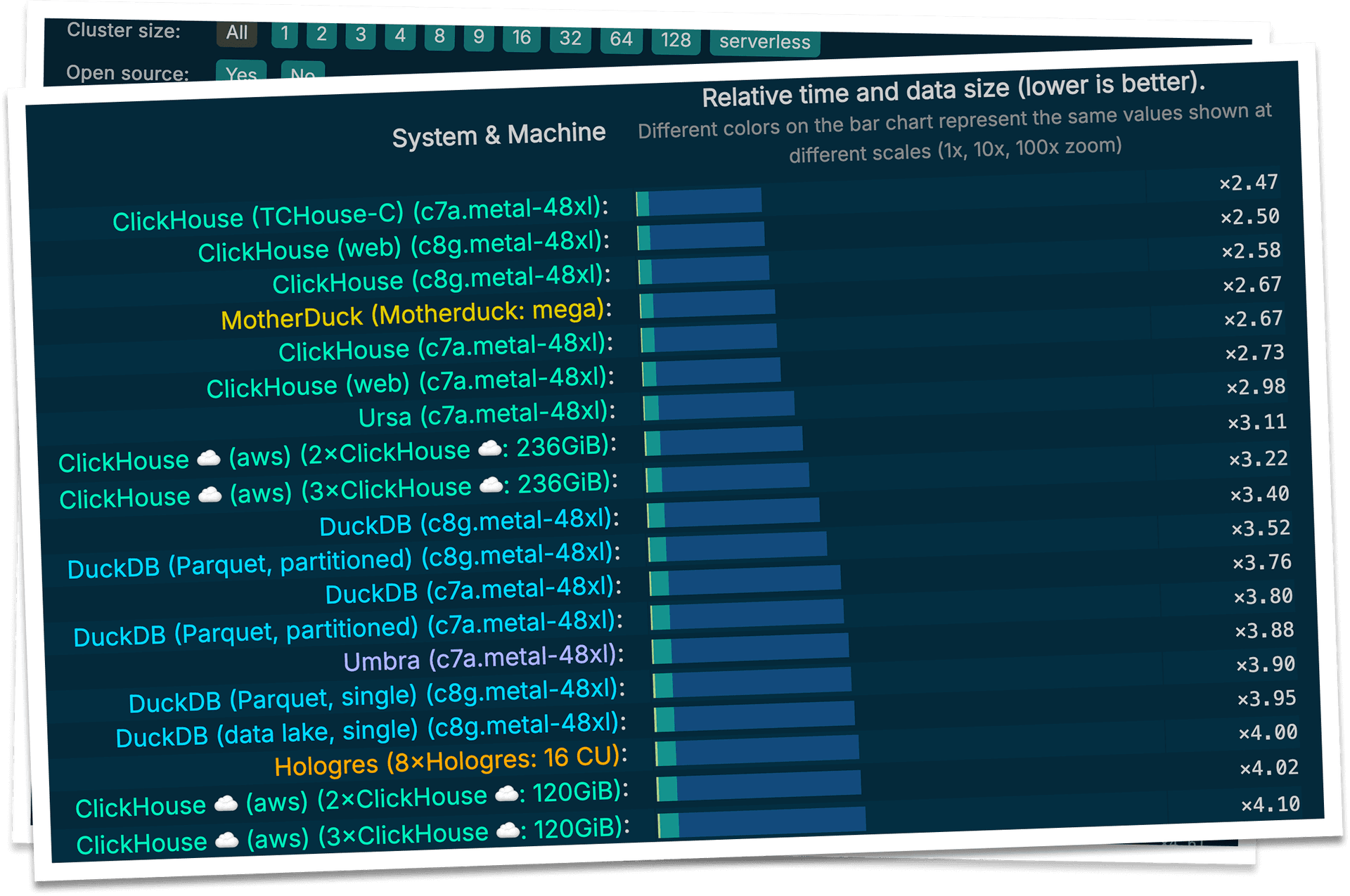
We back up our claims with public, reproducible benchmarks like ClickBench and JSONBench. You can explore our results directly and compare ClickHouse against other technologies before deciding how to power your analytics.
Full control over ClickHouse with clickhousectl
The official CLI to run, query, and build with ClickHouse locally and in the cloud.
Terminal
$
Join the 100k+ developers using ClickHouse today
Backed by 3k+ contributors and thousands of commits per month, ClickHouse thrives on a vibrant open-source community that pushes the project forward at speed.
3k+Contributors
81.2k+PRs
815+Releases
48.9k+Stars
Built for innovation, open by design
Inviting experimentation and contribution
Our academic paper shows how ClickHouse serves not only as a high performance database, but also as a platform for advancing the state of the art and is the best way to learn how its internals work. For deeper insights, explore our in-depth articles and blogs.

Start using ClickHouse in seconds
Install ClickHouse for MacOS, Linux, and FreeBSD.
curl https://clickhouse.com/ | shOr install for Windows, Docker or see other install options. Or try without installing in our playground.
Watch this getting started video to learn more about ClickHouse.