Ten years ago this month, we released ClickHouse as an open-source project. What started as a prototype I built to solve a real data problem has grown into something I could not have imagined: 2,000 contributors, users on every continent, and a community that continues to push the project further than any single team could.
In this issue, you will find our own engineering updates alongside stories from community members building real systems with ClickHouse. Seeing people share what they have built is one of the best parts of having an open community.
Here's to the next ten years.
— Alexey Milovidov, inventor of ClickHouse
Featured community member: Vasily Chekalkin
This month's featured community member is Vasily Chekalkin, Staff Engineer at Neara in Sydney, Australia.

Vasily contributed a series of improvements to ClickHouse's WebAssembly (WASM) user-defined functions in the 26.5 release.
He added a DETERMINISTIC keyword, which means WASM UDFs can be declared as pure functions, making them eligible for constant folding and widening coercions for arguments. He also made WASM UDFs visible in system.functions with their argument and return types. Together, these changes make WASM UDFs easier to introspect and better integrated with the query optimizer.
To see what's possible when you push WASM UDFs to their limits, check out his side project chgeos - PostGIS-compatible spatial functions for ClickHouse (ST_Intersects, ST_Buffer, ST_Within, and more) delivered as a WASM module powered by GEOS 3.12+.
Beyond WASM UDFs, Vasily is a regular contributor across ClickHouse's Geospatial and Iceberg functionality, from fixing WKT parsing to propagating table UUIDs from the Iceberg REST catalog.
➡️ Connect with Vasily on LinkedIn
Ten years of ClickHouse in open source
Alexey Milovidov kicked off the 10-year anniversary week with the full origin story.
It starts with a 2008 prototype built to keep up with web analytics data that was growing faster than any existing database could handle, runs through the open-source release on June 15, 2016, and reflects on what it means to build truly in the open, with 2,000+ contributors and counting.
26.5 release

ClickHouse 26.5 sees some important performance optimizations, particularly around Top-N queries - those that sort or group a large dataset only to return a handful of rows.
Pushing ORDER BY … LIMIT through a JOIN (20.4× faster with 175× less memory on TPC-H SF100) and supporting GROUP BY … LIMIT without an ORDER BY (11.9× faster and 185× less peak memory) both let ClickHouse stop work early instead of processing rows it will only throw away later.
Open House 2026 announcements

We hosted our annual Open House conference a few weeks ago in San Francisco and detailed all the announcements in this blog post.
Highlights included ClickHouse Postgres, a managed Postgres service that achieved 5x+ more transactions/sec than AWS RDS, and ClickHouse Agents, a new agentic analytics service powered by Claude with a native chat interface and a no-code agent builder.
➡️ Read about the announcements
Introducing native ClickHouse support in Jaeger

Mahad Zaryab walks through the design decisions behind native ClickHouse support in Jaeger v2.18.0, the most-requested storage backend from users running Jaeger at scale.
On a single-node benchmark, it achieved an ingestion rate of 50,000+ spans per second, with 8.6× compression, and sub-50ms search latency across 10 million spans.
Building ClickCannon: a tool for benchmarking ClickHouse

Spencer Torres introduces ClickCannon, an open-source benchmarking tool for ClickHouse that grew out of internal work to build sizing recommendations for ClickStack.
It replays real production data at controlled throughput, simulates concurrent user query patterns, and decouples disk and insert workers, allowing each to be scaled independently, giving teams a flexible framework for testing any ClickHouse insert and query workload.
Building a high-throughput KPI pipeline on ClickHouse: partitioning, idempotent recalculation, and flat column storage
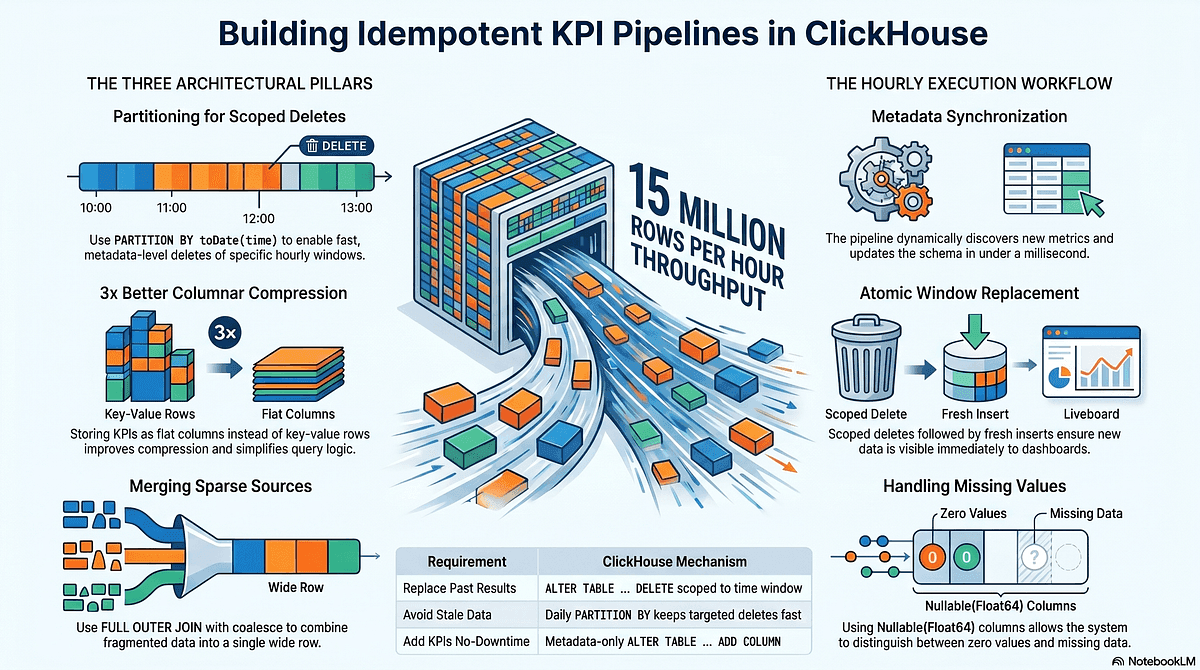
Mobin Shaterian details three ClickHouse-specific design decisions behind a telecom KPI pipeline processing 15 million rows per hour.
The pipeline uses ALTER TABLE … DELETE scoped to a time window for idempotent recalculation, stores hundreds of KPIs as flat columns for compression and query simplicity, and merges sparse KPI sources with CTEs and FULL OUTER JOIN so cells with missing data still land in the right row.
How ClickHouse became fast at joins
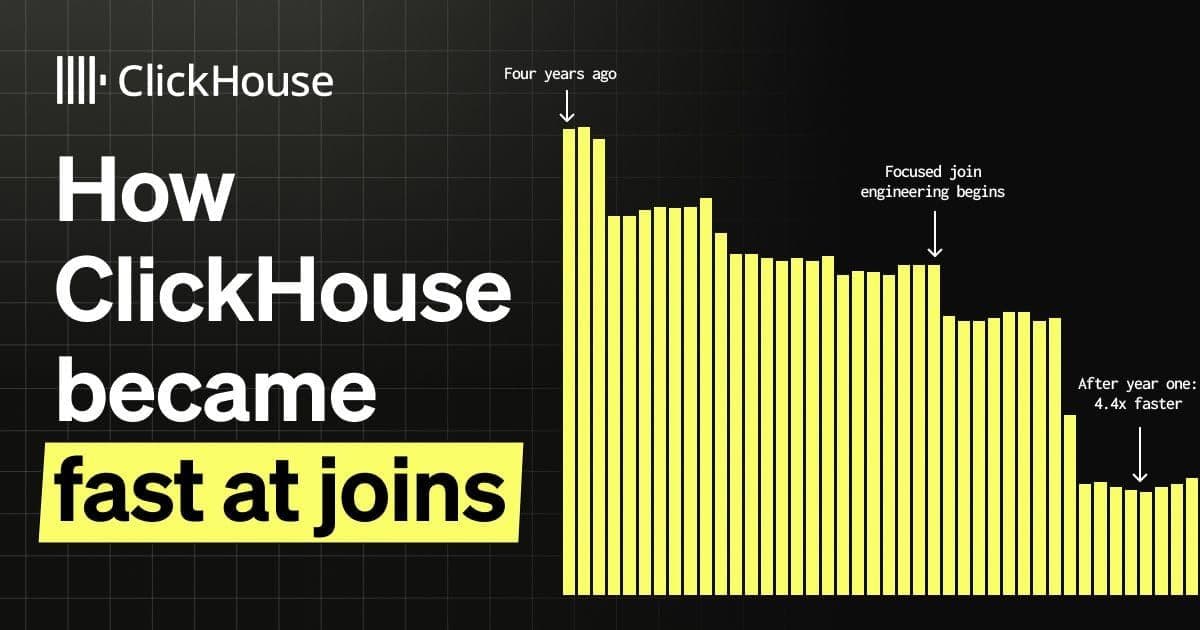
Tom Schreiber charts two years of focused join engineering that made ClickHouse 26× faster on TPC-H SF100 join-heavy workloads.
Year one laid the foundation with parallel hash join as the default, smarter filter pushdown, and local join reordering.
In year two, we added correlated subquery support, lazy column replication, runtime filters, and statistics-based join reordering, the last of which dropped a six-table query from 3,903 seconds to 2.7 seconds.
Quick reads
- Mohamed Hussain S explains how to avoid ClickHouse's "too many parts" trap by batching inserts into larger writes, using async inserts as a buffer, and avoiding overly granular partition keys, such as hourly timestamps.
- Mobin Shaterian explains how a telecom KPI platform was rebuilt to handle 10 billion records per month, replacing JSON string columns with flat columnar storage, buffering inserts through Kafka, and pre-calculating KPIs with Airflow to cut query times from minutes to milliseconds.
- RaviKumar Vatthumalli explains how switching ClickHouse query results from JSON to ArrowStream reduced memory usage in browser tabs for analytics dashboards.
- Caesario Kisty builds a ClickHouse-native RAG ingestion pipeline where ClickHouse handles state tracking, chunking, HNSW vector search, and scheduling via refreshable materialized views.
- Mark Needham wrote a blog post showing how to do random native sampling in ClickHouse
Get started today
Interested in seeing how ClickHouse works on your data? Get started with ClickHouse Cloud in minutes and receive $300 in free credits.
Sign upEvents
Global virtual events
- Nikkei AI Insight - Jun 18, 2026
- Combining Postgres & ClickHouse to Build a Unified Data Stack - Jun 23, 2026
- How to benchmark whether a system is truly real-time and cost-efficient - Jun 24, 2026
- Full Text Search at ClickHouse scale and speed - Jun 30, 2026
- ClickHouse Open Office & Live AMA - Jul 2, 2026 (APJ-timing)
- Observing and Improving AI Agents with Langfuse - Jul 8, 2026
Virtual training
- ClickHouse Fundamentals - Jun 24, 2026
- Integrating ClickHouse with your Data Lake - Jun 30, 2026
- Observability with ClickStack: Level 1 - Jul 8, 2026 (APJ-timing)
- Observability with ClickStack: Level 2 - Jul 9, 2026 (APJ-timing)
- Observability with ClickStack: Level 3 - Jul 10, 2026 (APJ-timing)
- ClickHouse Fundamentals - Jul 15, 2026
Events in AMER
- AWS Summit New York - New York - Jun 17, 2026
- Seattle Iceberg Meetup - Seattle - Jun 25, 2026
- AWS Summit Bogotá - Bogotá - Jul 30, 2026
Events in EMEA
- Google Cloud Summit London - London - Jun 17, 2026
- VivaTech - Paris - Jun 17, 2026
- The Agentic Data Stack - Amsterdam - Jun 18, 2026
- Meetup Partenaires ClickHouse - Paris - Jun 24, 2026
- Agentic AI in the Energy Industry - Panel Session - Amsterdam - Jul 1, 2026
- Data at Scale - Amsterdam - Jul 7, 2026
- WeAreDevelopers - Berlin - Jul 8, 2026
- Open House Roadshow - Amsterdam - Sept 1, 2026
- Open House Roadshow - London - Sept 30, 2026
Events in APAC
- KubeCon + CloudNativeCon India - Mumbai - Jun 18-19, 2026
- ClaudSG x ClickHouse: How AI Queries & Answers From your Data - Singapore - Singapore - June 19, 2026
- PyCon Singapore - Singapore - June 19-20, 2026
- AWS Summit Shanghai - Shanghai - Jun 23, 2026
- Agentic AI Unplugged: Running AI Agents at Scale - Sydney - Jun 24, 2026
- AWS Summit Japan - Tokyo - Jun 25-26, 2026
- Google Cloud Summit Sydney - Sydney - Jun 25, 2026
- ClickHouse KL Meetup - June 2026 - Kuala Lumpur - Jun 26, 2026
- KCD Kuala Lumpur - Kuala Lumpur - Jun 27, 2026
- ClickHouse + Confluent Seoul Meetup - Seoul - Jun 30, 2026
- Lakes to Queries: Building High-Performance Data Platforms - Mumbai - Jul 4, 2026
- Google Cloud Day Taipei - July 9, 2026
- Pipes, Streams, and Queries: Engineering Fast Data at Scale - Bangalore - Jul 11, 2026
- ClickHouse Melbourne Meetup - July 2026 - Melbourne - Jul 16, 2026
- Click-a-Thon India - Bangalore - August 1-2, 2026
- Open House Roadshow - Sydney - Aug 11, 2026
- Open House Roadshow - Melbourne - Aug 13, 2026


