Have you noticed our new look? We took an opportunity to update our website, refresh our brand, and are – presently – designing swag. Keep an eye on the website, or join an event near you, for an opportunity to acquire some new ClickHouse gear!
We’ve reordered this month’s newsletter to get into the query of the month more quickly, but the customary reading list and upcoming events appear at the bottom.
By the way, if you’re reading this on our website, did you know you can receive every monthly newsletter as an email in your inbox? Sign up here.
ClickHouse v23.3
- 22 new features.
- 14 performance optimisations.
- 61 bug fixes.
You can read about all the features in detail in the v23.3 blog post and, if you are interested, don’t forget to sign-up for the live 23.4 release call (Q&A welcome).
Lightweight Deletes are now GA (Jianmei Zhang and Alexander Gololobov)
This approach to removing data now represents the preferred and most efficient way to remove data from ClickHouse. Exposed via the DELETE FROM table syntax, users can specify a condition to remove specific rows.
Traces in Grafana
As part of our recent blog post on building an Observability solution on ClickHouse we focused on traces and realized that their rendering in our official Grafana plugin could be significantly improved. With a small few changes, the latest release now supports the visualization of traces using the Traces Panel and Explore view in Grafana.
Parallel Replicas (Nikita Mikhailov)
With parallel replicas, data can be processed in parallel by multiple replicas of the same shard. This allows query performance to be scaled as distinct subsets of data can be processed in parallel by multiple ClickHouse hosts.
Query of the Month - “Lightweight Deletes”
Lightweight deletes have the potential to impact how users fundamentally approach handling uses in ClickHouse, where the data is not immutable. For this month's query, we explore how Lightweight deletes can be used when incrementally updating materialized tables.
We regularly see users with complex schemas needing to materialize multiple tables into a new table via a JOIN operation to accelerate subsequent queries. In data warehousing use cases, this table would typically represent a model. This "de-normalization" process is typically achieved in ClickHouse by using an INSERT INTO SELECT query link, where the results of the join are inserted into a target table. We visualize this below:
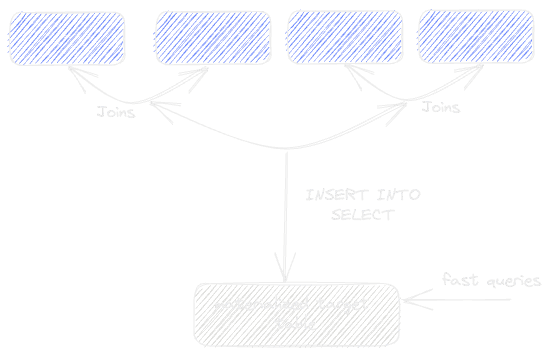
As well as simplifying subsequent queries, this approach has the potential to improve query performance dramatically. While this solves cases where the data is static, more thought is required if the source tables are subject to changes. In cases where the source tables are append-only, the denormalized table can easily be updated with a simple condition that identifies any changes. For example, this could be a timestamp column on the source tables that identifies new rows. With this condition, we can stream new rows into the target table by re-executing the INSERT INTO SELECT.
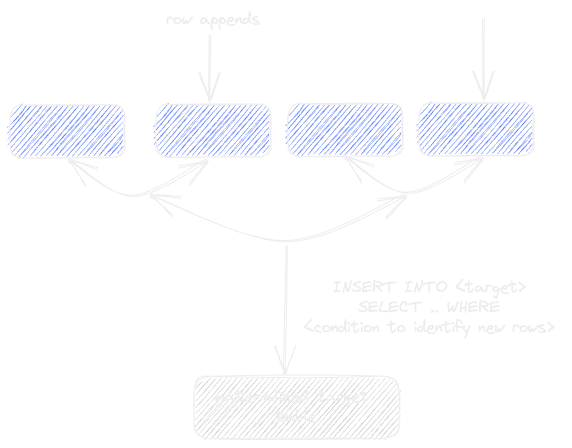
Things get a little more complex if the source tables are subject to updates and duplicates. In this case, users might stream new rows into a temporary table (1). The target table could then be streamed into a new table, with a check to omit results in the temporary table (2) - this assumes the presence of a unique row identifier (id below). Rows from the temporary table are then inserted into the new table (3). This new table could subsequently be exposed as the latest version of the model, e.g., with an EXCHANGE statement link. This rather complex process is shown below:
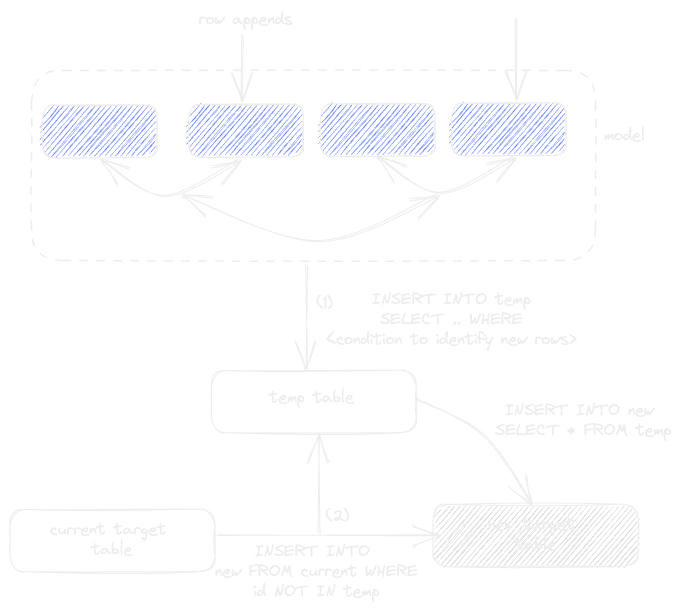
This process requires a complete copy of the data to be made in order to update the target table. This was historically preferred in ClickHouse to delete Mutations, which incur a higher resource cost than simple appends. However, the arrival of lighter-weight deletes opens the potential to simplify this process. Below we show how new rows are still streamed into a temporary table (1). However, this temporary table can now be used to remove rows from the existing target table (using the new DELETE syntax) before inserting the new rows. This avoids copying data and provides a faster means of updating a materialized model.
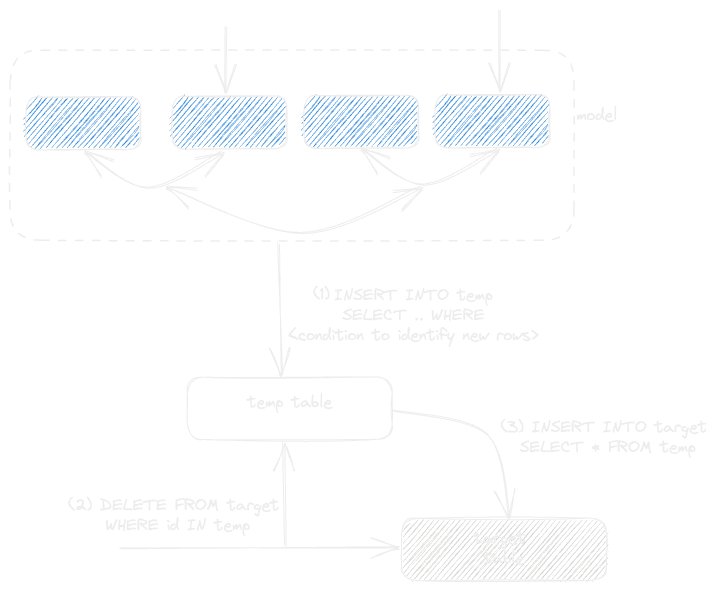
Note: the temporary table here can potentially just be a subquery. The use of a table ensures the process isn’t memory bound.
The above logic is still quite complex: surely there is a way to encapsulate this process and make it simpler? Readers of this newsletter, who are also dbt users, will immediately recognize the above use case as "Incremental Materializations" - a simple model type in dbt. Hence, the dbt-clickhouse plugin utilizes the exact processes above, with the lightweight deletes approach now recommended.
The use cases for Lightweight deletes go beyond incremental models...support for processing Kafka tombstone messages anyone? We'd love to hear how Lightweight deletes have changed your workflows!
Reading List
Some of our favorite reads that you may have missed include:
- A Deep Dive into Apache Parquet with ClickHouse - Part 1 - Since its release in 2013 as a columnar storage for Hadoop, Parquet has become almost ubiquitous as a file interchange format that offers efficient storage and retrieval. In this blog series, we explore how ClickHouse can be used to read and write this format before diving into the Parquet in more detail. For more experienced Parquet users, we also discuss some optimizations that users can make when writing Parquet files using ClickHouse to maximize compression, as well as some recent developments to optimize read performance using parallelization.
- My Journey as a Serial Startup Product Manager - In this post our VP of Product, Tanya Bragin, shares the story of her career. In her own words, “I often get questions about how I decided to become a product manager at startups, and what I learned over the years. The truth is, I had no such plan in life - I fell into the product management career somewhat by accident. But I have learned a few things along the way, and I will attempt to summarize the highlights in this blog.”
- Speeding up LZ4 in ClickHouse - This blog was originally posted in 2019. We edited and reposted in tribute to the authors of the LZ family of algorithms: Abraham Lempel and Jacob Ziv, who recently passed away. It can be tempting to think that every new feature is novel. That every new release is set to change the market. However, we -- as an industry -- stand on the shoulder of giants. Jacob's contributions to information theory (beyond compression algorithms) are, and remain, an inspiration to generations of practitioners and researchers.
- Building Real-time Analytics Apps with ClickHouse and Hex - As the world’s fastest analytical database, we are always looking for tools that help our users quickly and easily realize their dream of building applications on top of ClickHouse. So when Hex.tech announced the availability of ClickHouse as a data source, we were excited to see the potential for building real-time applications. In this blog post, we explore how we collected data and built a simple proof of concept for our application “ClickHub” using Hex.tech.
Upcoming Events
Mark your calendars for the following events:
ClickHouse v23.4 Release Webinar
Wednesday, April 26 @ 9 AM PDT / 6 PM CEST
Register here
Introduction to ClickHouse Cloud Workshop in NYC (space is limited!)
Wednesday, April 26 @ 10 AM EDT
Register here
ClickHouse Spring Meetup in Manhattan
Wednesday, April 26 @ 5:30 PM EDT
Register here
Supabase + ClickHouse: Combining the Best of the OLTP and OLAP Worlds
Tuesday, May 2 @ 8:00 AM PDT
Register here
Introduction to ClickHouse Workshop @ AWS Munich (space is limited!)
Wednesday, May 3 @ 9 AM CEST
Register here
Building Real-time Analytics Apps with ClickHouse and Hex
Wednesday, May 10 @ 9 AM PDT / 6 PM CEST
Register here
ClickHouse Meetup in Berlin
Tuesday, May 16 @ 6 PM CEST
Register here
ClickHouse Meetup in Barcelona
Tuesday, May 23 @ 6 PM CEST
Register here
Thanks for reading, and we’ll see you next month!


