This blog was originally posted in 2019. We are re-posting in tribute to the authors of the LZ family of algorithms: Abraham Lempel and Jacob Ziv, who recently passed away.
It can be tempting to think that every new feature is novel. That every new release is set to change the market. However, we -- as an industry -- stand on the shoulder of giants. Jacob's contributions to information theory (beyond compression algorithms) are, and remain, an inspiration to generations of practitioners and researchers.
Introduction
When you run queries in ClickHouse, you might notice that the profiler often shows the LZ_decompress_fast function near the top. What is going on? This question had us wondering how to choose the best compression algorithm.
ClickHouse stores data in compressed form. When running queries, ClickHouse tries to do as little as possible in order to conserve CPU resources. In many cases, all the potentially time-consuming computations are already well optimized, plus the user wrote a well-thought-out query. Then all that's left to do is to perform decompression.

So why does LZ4 decompression becomes a bottleneck? LZ4 seems like an extremely light algorithm: the data decompression rate is usually from 1 to 3 GB/s per processor core, depending on the data. This is much faster than the typical disk subsystem. Moreover, we use all available CPU cores, and decompression scales linearly across all physical cores.
However, there are two points to keep in mind. First, compressed data is read from disk, but the decompression speed is given in terms of the amount of uncompressed data. If the compression ratio is large enough, there is almost nothing to read from the disks. But there will be a lot of decompressed data, and this naturally affects CPU utilization: in the case of LZ4, the amount of work necessary to decompress data is almost proportional to the volume of the decompressed data itself.
Second, if data is cached, you might not need to read data from disks at all. You can rely on page cache or use your own cache. Caching is more efficient in column-oriented databases, since only frequently used columns stay in the cache. This is why LZ4 often appears to be a bottleneck in terms of CPU load.
This brings up two more questions. First, if decompression is slowing us down, is it worth compressing data to begin with? But this speculation is irrelevant in practice. ClickHouse offers several compression options, principally — LZ4 and Zstandard. LZ4 is used by default. Switching to Zstandard makes compression stronger and slower. But there wasn't an option to completely disable compression, since LZ4 is assumed to provide a reasonable minimal compression that can always be used. (Which is exactly why I love LZ4.)
But then a mysterious stranger appeared in the ClickHouse telegram support group who said that he has a very fast disk subsystem (with NVMe SSD) and decompression is the only thing slowing his queries down, so it would be nice to be able to store data without compression. I replied that we don't have this option, but it would be easy to add. A few days later, we got a pull request implementing the compression method none. I asked the contributor to report back on how much this option helped to accelerate queries. The response was that this new feature turned out to be useless in practice, since the uncompressed data started to take up too much disk space and didn't fit into those NVMe drives.
The second question that arises is that if there is a cache, why not use it to store data that is already decompressed? This is a viable possibility that will eliminate the need for decompression in many cases. ClickHouse also has a cache like this: the cache of decompressed blocks. But it's a pity to waste a lot of RAM on this. So usually it only makes sense to use on small, sequential queries that use nearly identical data.
Our conclusion is thus that it's always preferable to store data in a compressed format. Always write data to disk in compressed format. Transmit data over the network with compression, as well. In my opinion, default compression is justifiable even when transferring data within a single data center in a 10 GB network without oversubscription, while transferring uncompressed data between data centers is just unacceptable.
Why LZ4?
Why choose LZ4? Couldn't we choose something even lighter? Theoretically, we could, and this is a good thought. But let's look at the class of algorithms that LZ4 belongs to.
First of all, it's generic and doesn't adapt to the data type. For example, if you know in advance that you will have an array of integers, you can use one of the VarInt algorithms, and this will use the CPU more effectively. Second, LZ4 is not overly dependent on data model assumptions. Let's say you have an ordered time series of sensor values and an array of floating-point numbers. If you consider this, you can calculate deltas between these numbers and then compress them with a generic algorithm, which will result in a higher compression ratio.
You won't have any problems using LZ4 with any byte arrays or files. Of course, it does have a specialization (more on that later), and in some cases, its use is pointless. But if we call it a general-purpose algorithm, we'll be fairly close to the truth. We should note that thanks to its internal design, LZ4 automatically implements the RLE algorithm as a special case.
However, the more important question is whether LZ4 is the most optimal algorithm of this class in terms of overall speed and strength of compression. Optimal algorithms are called the Pareto frontier, which means that no other algorithm is definitively better in one way and not worse in other ways (and on a wide variety of datasets, as well). Some algorithms are faster but result in a smaller compression ratio, while others have stronger compression but are slower to compress or decompress.
To be honest, LZ4 is not really the Pareto frontier — there are some options available that are just a tiny bit better. For instance, look at LZTURBO from a developer nicknamed powturbo. There is no doubt about the reliability of the results, thanks to the encode.su community (the largest and possibly the only forum on data compression). Unfortunately, the developer does not distribute the source code or binaries; they are only available to a limited number of people for testing or for a lot of money. Also, take a look at Lizard (previously LZ5) and Density. They might work slightly better than LZ4 when you select a certain compression level. Another really interesting option is LZSSE. But finish reading this article before you check it out.
How LZ4 works
Let's look at how LZ4 works in general. This is one of the implementations of the LZ77 algorithm. L and Z represent the developers' names (Lempel and Ziv), and 77 is for 1977, when the algorithm was published. It has many other implementations: QuickLZ, FastLZ, BriefLZ, LZF, LZO, and gzip and zip if low compression levels are used.
A data block compressed using LZ4 contains a sequence of entries (commands or instructions) of two types:
- Literals: "Take the following N bytes as-is and copy them to the result".
- Match: "Take N bytes from the decompressed result starting at the offset value relative to the current position".
Example. Before compression:
Hello world HelloAfter compression:
literals 12 "Hello world " match 5 12If we take a compressed block and iterate the cursor through it while running these commands, we will get the original uncompressed data as the result.
So that's basically how data is decompressed. The basic idea is clear: to perform compression, the algorithm encodes a repeated sequence of bytes using matches.
Some characteristics are also clear. This byte-oriented algorithm does not dissect individual bytes; it only copies them in their entirety. This is how it differs from entropy encoding. For instance, zstd is a combination of LZ77 and entropy encoding.
Note that the size of the compressed block shouldn't be too large. The size is chosen to avoid wasting a lot of RAM during decompression, to avoid slowing down random access too much in the compressed file (which consists of a large number of compressed blocks), and sometimes so the block will fit in a CPU cache. For example, you can choose 64 KB so that the buffers for compressed and uncompressed data will fit in the L2 cache with half still free.
If we need to compress a larger file, we can concatenate the compressed blocks. This is also convenient for storing additional data (like a checksum) with each compressed block.
The maximum offset for the match is limited. In LZ4, the limit is 64 kilobytes. This amount is called the sliding window. This means that matches can be found in a window of 64 kilobytes preceding the cursor, which slides with the cursor as it moves forward.
Now let's look at how to compress data, or, in other words, how to find matching sequences in a file. You can always use a suffix trie (it's great if you've actually heard of this). There are methods that guarantee that the longest match is located in the preceding bytes after compression. This is called optimal parsing, and it provides nearly the best compression ratio for a fixed-format compressed block. But there are better approaches, such as finding a good-enough match that is not necessarily the longest. The most efficient way to find it is using a hash table.
To do this, we iterate the cursor through the original block of data and take a few bytes after the cursor (let's say 4 bytes). We hash them and put the offset from the beginning of the block (where the 4 bytes were taken from) into the hash table. The value 4 is called "min-match" — using this hash table, we can find matches of at least 4 bytes.
If we look at the hash table and it already has a matching record, and the offset doesn't exceed the sliding window, we check to see how many more bytes match after those 4 bytes. Maybe there are a lot more matches. It is also possible that there is a collision in the hash table, and nothing matches, but this is not a big deal. You can just replace the value in the hash table with a new one. Collisions in the hash table will simply lead to a lower compression ratio since there will be fewer matches. By the way, this type of hash table (with a fixed size and no resolution of collisions) is called a "cache table". This name makes sense because, in the event of a collision, the cache table simply forgets about the old entry.
A challenge for the careful reader. Let's assume that the data is an array of UInt32 numbers in little endian format that represents a part of a sequence of natural numbers: 0, 1, 2… Explain why this data isn't compressed when using LZ4 (the size of the compressed data isn't any smaller compared to the uncompressed data).
How to speed everything up
So I want to speed up LZ4 decompression. Let's see how the decompression loop looks like. Here it is in pseudocode:
while (...)
{
read(input_pos, literal_length, match_length);
copy(output_pos, input_pos, literal_length);
output_pos += literal_length;
read(input_pos, match_offset);
copy(output_pos, output_pos - match_offset,
match_length);
output_pos += match_length;
}LZ4 format is designed so that literals and matches alternate in a compressed file. Obviously, the literal always comes first (because there's nowhere to take a match from at the very beginning). Therefore, their lengths are encoded together.
It's actually a little more complicated than this. One byte is read from the file, and then it's split into two nibbles (half-bytes) which contain the encoded numbers 0 to 15. If the corresponding number is not 15, it is assumed to be the length of the literal and match, respectively. And if it is 15, the length is longer, and it is encoded in the following bytes. Then the next byte is read, and its value is added to the length. If it is equal to 255, the same thing is done with the next byte.
Note that the maximum compression ratio for LZ4 format does not reach 255. And another useless observation is that if your data is very redundant, using LZ4 twice will improve the compression ratio.
When we read the length of a literal (and then the match length and the match offset), just copying two blocks of memory is enough to decompress it.
How to copy a memory block
It would seem that you could just use the memcpy function, which is designed to copy memory blocks. But this is not the optimal approach and not really appropriate.
Using memcpy isn't optimal because:
- It is usually located in the libc library (and the libc library is usually dynamically linked, so the memcpy call will be made indirectly via PLT).
- It is not inlined by compiler if the size argument is unknown at compile time.
- It puts out a lot of effort to correctly process the leftovers of a memory block that are not multiples of the machine word length or register.
The last point is the most important. Let's say we asked the memcpy function to copy exactly 5 bytes. It would be great to copy 8 bytes right away, using two movq instructions.
Hello world Hello wo...
^^^^^^^^ - src
^^^^^^^^ - dst
But then we'll be copying three extra bytes, so we'll be writing outside of buffer bounds. The memcpy function doesn't have permission to do this, because it could overwrite some data in our program and lead to a memory stomping bug. And if we wrote to an unaligned address, these extra bytes could land on an unallocated page of virtual memory or on a page without write access. That would give us a segmentation fault (this is good).
But in our case, we can almost always write extra bytes. We can read extra bytes in the input buffer as long as the extra bytes are located entirely inside it. Under the same conditions, we can write the extra bytes to the output buffer, because we will still overwrite them on the next iteration.
This optimization is already in the original implementation of LZ4:
inline void copy8(UInt8 * dst, const UInt8 * src)
{
memcpy(dst, src, 8); /// Note that memcpy isn't actually called here.
}
inline void wildCopy8(UInt8 * dst, const UInt8 * src, UInt8 * dst_end)
{
do
{
copy8(dst, src);
dst += 8;
src += 8;
} while (dst < dst_end);
}To take advantage of this optimization, we just need to make sure that we are far enough away from the buffer bounds. This shouldn't cost anything, because we are already checking for buffer overflow. And processing the last few bytes, the "leftover" data, can be done after the main loop.
However, there are still a few nuances. Copying occurs twice in the loop: with a literal and a match. However, when using the LZ4_decompress_fast function (instead of LZ4_decompress_safe), the check is performed only once, when we need to copy the literal. The check is not performed when copying the match, but the specification for the LZ4 format has conditions that allow you to avoid it:
- The last 5 bytes are always literals.
- The last match must start at least 12 bytes before the end of block.
- Consequently, a block with less than 13 bytes cannot be compressed.
Specially selected input data may lead to memory corruption. If you use the LZ4_decompress_fast function, you need protection from bad data. At the very least, you should calculate checksums for the compressed data. If you need protection from hackers, use the LZ4_decompress_safe function. Other options: take a cryptographic hash function as the checksum (although this is likely to destroy performance); allocate more memory for buffers; allocate memory for buffers with a separate mmap call and create a guard page.
When I see code that copies 8 bytes of data, I immediately wonder why exactly 8 bytes. You can copy 16 bytes using SSE registers:
inline void copy16(UInt8 * dst, const UInt8 * src)
{
#if __SSE2__
_mm_storeu_si128(reinterpret_cast<__m128i *>(dst),
_mm_loadu_si128(reinterpret_cast<const __m128i *>(src)));
#else
memcpy(dst, src, 16);
#endif
}
inline void wildCopy16(UInt8 * dst, const UInt8 * src, UInt8 * dst_end)
{
do
{
copy16(dst, src);
dst += 16;
src += 16;
} while (dst < dst_end);
}The same thing works for copying 32 bytes for AVX and 64 bytes for AVX-512. In addition, you can unroll the loop several times. If you have ever looked at how memcpy is implemented, this is exactly the approach that is used. (By the way, the compiler won't unroll or vectorize the loop in this case, because this will require inserting bulky checks.)
Why didn't the original LZ4 implementation do this? First, it isn't clear whether this is better or worse. The resulting gain depends on the size of the blocks to copy, so if they are all short, it would be creating extra work for nothing. And secondly, it ruins the provisions in the LZ4 format that help avoid an unnecessary branch in the internal loop.
However, we will keep this option in mind for the time being.
Tricky copying
Let's go back to the question of whether it's always possible to copy data this way. Let's say we need to copy a match, that is, take a piece of memory from the output buffer that is located at some offset behind the cursor and copy it to the cursor position.
Imagine a simple case when you need to copy 5 bytes at an offset of 12:
Hello world ...........
^^^^^ - src
^^^^^ - dst
Hello world Hello wo...
^^^^^ - src
^^^^^ - dst
But there is a more difficult case, when we need to copy a block of memory that is longer than the offset. In other words, it includes some data that has not yet been written to the output buffer.
Copy 10 bytes at an offset of 3:
abc.............
^^^^^^^^^^ - src
^^^^^^^^^^ - dst
abcabcabcabca...
^^^^^^^^^^ - src
^^^^^^^^^^ - dst
We have all the data during the compression process, and such a match may well be found. The memcpy function is not suitable for copying it, because it doesn't support the case when ranges of memory blocks overlap. The memmove function won't work either, because the block of memory that the data should be taken from has not been fully initialized yet. We need to copy the same way as if we were copying byte by byte.
op[0] = match[0];
op[1] = match[1];
op[2] = match[2];
op[3] = match[3];
...Here's how it works:
abca............
^ - src
^ - dst
abcab...........
^ - src
^ - dst
abcabc..........
^ - src
^ - dst
abcabca.........
^ - src
^ - dst
abcabcab........
^ - src
^ - dst
In other words, we must create a repeating sequence. The original implementation of LZ4 used some surprisingly strange code to do this:
const unsigned dec32table[] = {0, 1, 2, 1, 4, 4, 4, 4};
const int dec64table[] = {0, 0, 0, -1, 0, 1, 2, 3};
const int dec64 = dec64table[offset];
op[0] = match[0];
op[1] = match[1];
op[2] = match[2];
op[3] = match[3];
match += dec32table[offset];
memcpy(op+4, match, 4);
match -= dec64;It copies the first 4 bytes one by one, skips ahead by some magic number, copies the next 4 bytes entirely, and moves the cursor to a match using another magic number. The author of the code (Yan Collet) somehow forgot to leave a comment about what this means. In addition, the variable names are confusing. They are both named dec...table, but one is added and the other is subtracted. In addition, one of them is unsigned, and the other is int. However, the author recently improved this place in the code.
Here's how it actually works. We copy the first 4 bytes one at a time:
abcabca.........
^^^^ - src
^^^^ - dst
Now we can copy 4 bytes at once:
abcabcabcab.....
^^^^ - src
^^^^ - dst
We can continue as usual, copying 8 bytes at once:
abcabcabcabcabcabca.....
^^^^^^^^ - src
^^^^^^^^ - dst
As we all know from experience, sometimes the best way to understand code is to rewrite it. Here's what we came up with:
inline void copyOverlap8(UInt8 * op, const UInt8 *& match, const size_t offset)
{
/// 4 % n.
/// Or if 4 % n is zero, we use n.
/// It gives an equivalent result, but is more CPU friendly for unknown reasons.
static constexpr int shift1[] = { 0, 1, 2, 1, 4, 4, 4, 4 };
/// 8 % n - 4 % n
static constexpr int shift2[] = { 0, 0, 0, 1, 0, -1, -2, -3 };
op[0] = match[0];
op[1] = match[1];
op[2] = match[2];
op[3] = match[3];
match += shift1[offset];
memcpy(op + 4, match, 4);
match += shift2[offset];
}As expected, this doesn't change the performance at all. I just really wanted to try optimization for copying 16 bytes at once.
However, this complicates the "special case" and causes it to be called more often (the offset < 16 condition is performed at least as often as offset < 8). Copying overlapping ranges with 16-byte copying looks like this (only the beginning shown):
inline void copyOverlap16(UInt8 * op, const UInt8 *& match, const size_t offset)
{
/// 4 % n.
static constexpr int shift1[]
= { 0, 1, 2, 1, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4 };
/// 8 % n - 4 % n
static constexpr int shift2[]
= { 0, 0, 0, 1, 0, -1, -2, -3, -4, 4, 4, 4, 4, 4, 4, 4 };
/// 16 % n - 8 % n
static constexpr int shift3[]
= { 0, 0, 0, -1, 0, -2, 2, 1, 8, -1, -2, -3, -4, -5, -6, -7 };
op[0] = match[0];
op[1] = match[1];
op[2] = match[2];
op[3] = match[3];
match += shift1[offset];
memcpy(op + 4, match, 4);
match += shift2[offset];
memcpy(op + 8, match, 8);
match += shift3[offset];
}Can this function be implemented more effectively? We would like to find a magic SIMD instruction for such complex code, because all we want to do is write 16 bytes, which consist entirely of a few bytes of input data (from 1 to 15). Then they just need to be repeated in the correct order.
There is an instruction like this called pshufb (packed shuffle bytes) that is part of SSSE3 (three S's). It accepts two 16-byte registers. One of the registers contains the source data. The other one has the "selector": each byte contains a number from 0 to 15, depending on which byte of the source register to take the result from. If the selector's byte value is greater than 127, the corresponding byte of the result is filled with zero.
Here is an example:
xmm0: abc.............
xmm1: 0120120120120120
pshufb %xmm1, %xmm0
xmm0: abcabcabcabcabcaEvery byte of the result is filled with the selected byte of the source data — this is exactly what we need! Here's what the code looks like in the result:
inline void copyOverlap16Shuffle(UInt8 * op, const UInt8 *& match, const size_t offset)
{
#ifdef __SSSE3__
static constexpr UInt8 __attribute__((__aligned__(16))) masks[] =
{
0, 1, 2, 1, 4, 1, 4, 2, 8, 7, 6, 5, 4, 3, 2, 1, /* offset = 0, not used as mask, but for shift amount instead */
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, /* offset = 1 */
0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1,
0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2, 0,
0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3,
0, 1, 2, 3, 4, 0, 1, 2, 3, 4, 0, 1, 2, 3, 4, 0,
0, 1, 2, 3, 4, 5, 0, 1, 2, 3, 4, 5, 0, 1, 2, 3,
0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1,
0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7,
0, 1, 2, 3, 4, 5, 6, 7, 8, 0, 1, 2, 3, 4, 5, 6,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 0, 1, 2, 3, 4,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 1, 2, 3,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 0, 1, 2,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 0, 1,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 0,
};
_mm_storeu_si128(reinterpret_cast<__m128i *>(op),
_mm_shuffle_epi8(
_mm_loadu_si128(reinterpret_cast<const __m128i *>(match)),
_mm_load_si128(reinterpret_cast<const __m128i *>(masks) + offset)));
match += masks[offset];
#else
copyOverlap16(op, match, offset);
#endif
}Here _mm_shuffle_epi8 is an intrinsic, which compiles to the pshufb CPU instruction.
Can we perform this operation for more bytes at once using newer instructions? After all, SSSE3 is a very old instruction set that has been around since 2006. AVX2 has an instruction that does this for 32 bytes at once, but separately for individual 16-byte lanes. This is called vector permute bytes, rather than packed shuffle bytes — the words are different, but the meaning is the same. AVX-512 VBMI has another instruction that works for 64 bytes at once, but processors that support it have only appeared recently. ARM NEON has similar instructions called vtbl (vector table lookup), but they only allow writing 8 bytes.
In addition, there is a version of the pshufb instruction with 64-bit MMX registers in order to form 8 bytes. It is just right for replacing the original version of the code. However, I decided to use the 16-byte option instead (for serious reasons).
At the Highload++ Siberia conference, an attendee came up to me after my presentation and mentioned that for the 8-byte case, you can just use multiplication by a specially selected constant (you will also need an offset) — this hadn't even occurred to me before!
How to remove a superfluous if statement
Let's say I want to use a variant that copies 16 bytes. How can I avoid having to do an additional check for buffer overflow?
I decided that I just wouldn't do this check. The comments on the function will say that the developer should allocate a block of memory for a specified number of bytes more than it is required, so that we can read and write unnecessary garbage there. The interface of the function will be harder to use, but there is a different issue.
Actually, there could be negative consequences. Let's say the data that we need to decompress was formed from blocks of 65,536 bytes each. Then the user gives us a piece of memory that is 65,536 bytes for the decompressed data. But with the new function interface, the user will be required to allocate a memory block that is 65,551 bytes, for example. Then the allocator may be forced to actually allocate 96 or even 128 kilobytes, depending on its implementation. If the allocator is very bad, it might suddenly stop caching memory in "heap" and start using mmap and munmap each time for memory allocation (or release memory using madvice). This process will be extremely slow because of page faults. As a result, this little bit of optimization might end up slowing everything down.
Is there any acceleration?
So I made a version of the code that uses three optimizations:
- Copying 16 bytes instead of 8.
- Using the shuffle instructions for the
offset < 16case. - Removed one extra if.
I started testing this code on different sets of data and got unexpected results.
Example 1:
Xeon E2650v2, Browser data, AppVersion column.
Reference: 1.67 GB/sec.
16 bytes, shuffle: 2.94 GB/sec (76% faster).
Example 2:
Xeon E2650v2, Direct data, ShowsSumPosition column.
Reference: 2.30 GB/sec.
16 bytes, shuffle: 1.91 GB/sec (20% slower).I was really happy at first, when I saw that everything had accelerated by such a large percentage. Then I saw that nothing was any faster with other files. It was even a little bit slower for some of them. I concluded that the results depend on the compression ratio. The more compressed the file, the greater the advantage of switching to 16 bytes. This feels natural: the larger the compression ratio, the longer the average length of fragments to copy.
To investigate, I used C++ templates to make code variants for four cases: using 8-byte or 16-byte chunks, and with or without the shuffle instruction.
template <size_t copy_amount, bool use_shuffle>
void NO_INLINE decompressImpl(
const char * const source,
char * const dest,
size_t dest_size)Completely different variants of the code performed better on different files, but when testing on a desktop the version with shuffle always won. Testing on a desktop is inconvenient because you have to do this:
sudo echo 'performance' | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
kill -STOP $(pidof firefox) $(pidof chromium)Then I went on one of the old "development" servers (with the Xeon E5645 processor), took even more datasets, and got almost the opposite results, which totally confused me. It turns out that the choice of optimal algorithm depends on the processor model, in addition to the compression ratio. The processor determines when it is best to use the shuffle instruction, as well as the threshold for when to start using 16-byte copying.
By the way, when testing on our servers, it made sense to do this:
sudo kill -STOP $(pidof python) $(pidof perl) $(pgrep -u skynet) $(pidof cqudp-client)Otherwise, the results will be unstable. Also watch out for thermal throttling and power capping.
How to choose the best algorithm
So we have four variants of the algorithm, and we need to choose the best one for the conditions. We could create a representative set of data and hardware, then perform serious load testing and choose the method that is best on average. But we don't have a representative dataset. For testing, I used a sample of Web Analytics Data and flights in the United States. But this isn't sufficient because ClickHouse is used by hundreds of companies around the world. By over-optimizing one dataset, we might cause a drop in performance with other data and not even realize it. And if the results depend on the processor model, we'll have to explicitly write the conditions in the code and test it on each model (or consult the reference manual on timing instructions, what do you think?). In either case, this is too time-consuming.
So I decided to use another method, which is obvious to colleagues who studied at our School of Data Analysis: "multi-armed bandits". The point is that the variant of the algorithm is chosen randomly, and then we use statistics to progressively choose the variants that perform better.
Many blocks of data need to be decompressed, so we need independent function calls for decompressing data. We could choose one of the four algorithms for each block and measure its execution time. An operation like this usually costs nothing in comparison with processing a block of data, and in ClickHouse, a block of uncompressed data is at least 64 KB. (Read this article about measuring time).
To get a better understanding of how the "multi-armed bandits" algorithm works, let's look at where the name comes from. This is an analogy with slot machines in a casino which have several levers that a player can pull to get some random amount of money. The player can pull the levers multiple times in any order. Each lever has a fixed probability for the corresponding amount of money given out, but the player does not know how it works and can only learn it from experience playing the game. Once they figure it out, they can maximize their winnings.
One approach to maximizing the reward is to evaluate the probability distribution for each lever at each step based on the game statistics from previous steps. Then we mentally "win" a random reward for each lever based on the distributions received. Finally, we pull the lever that had the best outcome in our mental game. This approach is called Thompson Sampling.
But we are choosing a decompression algorithm. The result is the execution time in picoseconds per byte: the fewer, the better. We will consider the execution time to be a random variable and evaluate its distribution using mathematical statistics. The Bayesian approach is often used for tasks like this, but it would be cumbersome to insert complex formulas into C++ code. We can use a parametric approach and say that a random variable belongs to a parametric family of random variables and then evaluate its parameters.
How do we select the family of random variables? As an example, we could assume that the code execution time has a normal distribution. But this is absolutely wrong. First, the execution time can't be negative, and normal distribution takes values everywhere on the number line. Second, I assume that the execution time will have a heavy "tail" on the right end.
However, there are factors that could make it a good idea to estimate normal distribution only for the purposes of Thompson Sampling (despite the fact that the distribution of the target variable is not necessarily normal). The reason for this is that it is very easy to calculate the mathematical expectation and the variance, and after a sufficient number of iterations, a normal distribution becomes fairly narrow, similar to the distributions that we would have obtained using other methods. If we aren't too concerned with the convergence rate at the first steps, these details can be ignored.
This may seem like a somewhat ignorant approach. Experience has shown us that the average time for query execution, website page loading, and so on is "garbage" that isn't worth calculating. It would be better to calculate the median, which is a robust statistic. But this is a little more difficult, and as I will show later, the described method justifies itself for practical purposes.
At first, I implemented the calculation of the mathematical expectation and variance, but then I decided that this was too good, and I needed to simplify the code to make it "worse":
/// For better convergence, we don't use proper estimate of stddev.
/// We want to eventually separate the two algorithms even in cases
/// when there is no statistical significant difference between them.
double sigma() const
{
return mean() / sqrt(adjustedCount());
}
double sample(pcg64 & rng) const
{
...
return std::normal_distribution<>(mean(), sigma())(rng);
}I wrote it so that the first few iterations were not taken into account, to eliminate the effect of memory latencies.
The result is a test program that can select the best algorithm for the input data, with optional modes that use the reference implementation of LZ4 or a specific version of the algorithm.
So there are six options:
- Reference (baseline): original LZ4 without our modifications
- Variant 0: copy 8 bytes at a time without shuffle.
- Variant 1: copy 8 bytes at a time with shuffle.
- Variant 2: copy 16 bytes at a time without shuffle.
- Variant 3: copy 16 bytes at a time with shuffle.
- The "bandit" option, which selects the best of the four optimized variants.
Testing on different CPUs
If the result strongly depends on the CPU model, it would be interesting to find out exactly how it is affected. There might be an exceptionally large difference on certain CPUs.
I prepared a set of datasets from different tables in ClickHouse with real data, for a total of 256 different files each with 100 MB of uncompressed data (the number 256 was coincidental). Then I looked at the CPUs of the servers where I can run benchmarks. I found servers with the following CPUs:
- Intel® Xeon® CPU E5-2650 v2 @ 2.60GHz
- Intel® Xeon® CPU E5-2660 v4 @ 2.00GHz
- Intel® Xeon® CPU E5-2660 0 @ 2.20GHz
- Intel® Xeon® CPU E5645 @ 2.40GHz
- Intel Xeon E312xx (Sandy Bridge)
- AMD Opteron(TM) Processor 6274
- AMD Opteron(tm) Processor 6380
- Intel® Xeon® CPU E5-2683 v4 @ 2.10GHz
- Intel® Xeon® CPU E5530 @ 2.40GHz
- Intel® Xeon® CPU E5440 @ 2.83GHz
- Intel® Xeon® CPU E5-2667 v2 @ 3.30GHz
The most interesting part comes next — the following processors were also made available:
- AMD EPYC 7351 16-Core Processor, a new AMD server processor at the time.
- Cavium ThunderX2, which is AArch64, not x86. For these, my SIMD optimization needed to be reworked a bit. The server has 224 logical and 56 physical cores.
There are 13 servers in total, and each of them runs the test on 256 files in 6 variants (reference, 0, 1, 2, 3, adaptive). The test is run ten times, alternating between the options in random order. It outputs 199,680 results that we can compare.
For example, we can compare different CPUs with each other. But we shouldn't jump to conclusions from these results because we are only testing the LZ4 decompression algorithm on a single core (this is a very narrow case, so we only get a micro-benchmark). For example, the Cavium has the lowest performance per single core. But I tested ClickHouse on it myself, and it wins out over Xeon E5-2650 v2 on heavy queries due to the greater number of cores, even though it is missing many optimizations that are made in ClickHouse specifically for the x86.
┌─cpu───────────────────┬──ref─┬─adapt─┬──max─┬─best─┬─adapt_boost─┬─max_boost─┬─adapt_over_max─┐
│ E5-2667 v2 @ 3.30GHz │ 2.81 │ 3.19 │ 3.15 │ 3 │ 1.14 │ 1.12 │ 1.01 │
│ E5-2650 v2 @ 2.60GHz │ 2.5 │ 2.84 │ 2.81 │ 3 │ 1.14 │ 1.12 │ 1.01 │
│ E5-2683 v4 @ 2.10GHz │ 2.26 │ 2.63 │ 2.59 │ 3 │ 1.16 │ 1.15 │ 1.02 │
│ E5-2660 v4 @ 2.00GHz │ 2.15 │ 2.49 │ 2.46 │ 3 │ 1.16 │ 1.14 │ 1.01 │
│ AMD EPYC 7351 │ 2.03 │ 2.44 │ 2.35 │ 3 │ 1.20 │ 1.16 │ 1.04 │
│ E5-2660 0 @ 2.20GHz │ 2.13 │ 2.39 │ 2.37 │ 3 │ 1.12 │ 1.11 │ 1.01 │
│ E312xx (Sandy Bridge) │ 1.97 │ 2.2 │ 2.18 │ 3 │ 1.12 │ 1.11 │ 1.01 │
│ E5530 @ 2.40GHz │ 1.65 │ 1.93 │ 1.94 │ 3 │ 1.17 │ 1.18 │ 0.99 │
│ E5645 @ 2.40GHz │ 1.65 │ 1.92 │ 1.94 │ 3 │ 1.16 │ 1.18 │ 0.99 │
│ AMD Opteron 6380 │ 1.47 │ 1.58 │ 1.56 │ 1 │ 1.07 │ 1.06 │ 1.01 │
│ AMD Opteron 6274 │ 1.15 │ 1.35 │ 1.35 │ 1 │ 1.17 │ 1.17 │ 1 │
│ E5440 @ 2.83GHz │ 1.35 │ 1.33 │ 1.42 │ 1 │ 0.99 │ 1.05 │ 0.94 │
│ Cavium ThunderX2 │ 0.84 │ 0.87 │ 0.87 │ 0 │ 1.04 │ 1.04 │ 1 │
└───────────────────────┴──────┴───────┴──────┴──────┴─────────────┴───────────┴────────────────┘- ref, adapt, max - The speed in gigabytes per second (the value that is the reverse of the arithmetic mean of time for all launches on all datasets).
- best - The number of the best algorithm among the optimized variants, from 0 to 3.
- adapt_boost - The relative advantage of the adaptive algorithm compared to the baseline.
- max_boost - The relative advantage of the best of the non-adaptive variants compared to the baseline.
- adapt_over_max - The relative advantage of the adaptive algorithm over the best non-adaptive one.
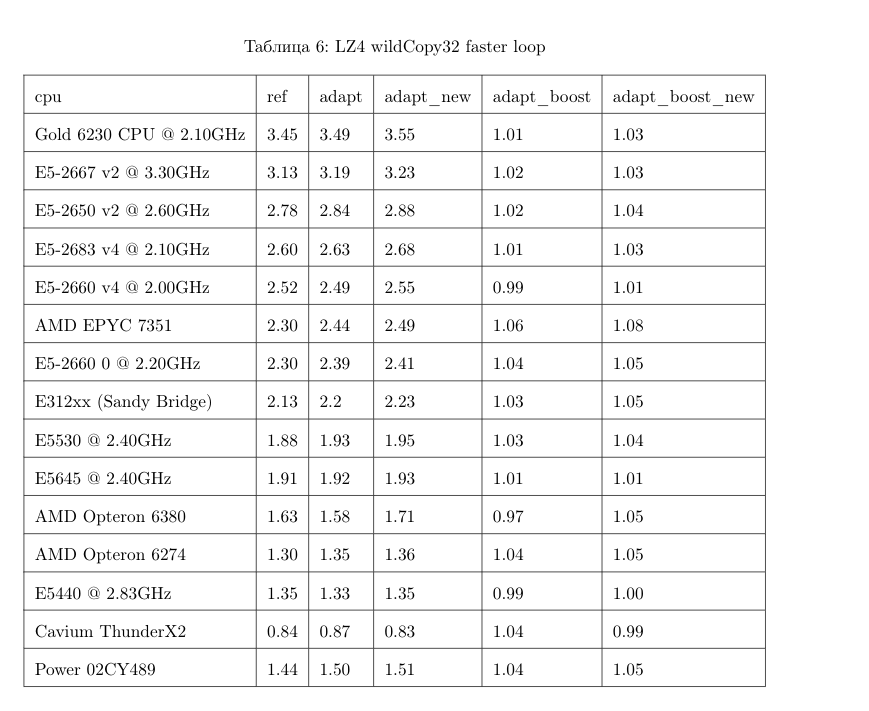
The results show that we were able to speed up decompression by 12-20% on modern x86 processors. Even on ARM we saw 4% improvement, despite the fact that we didn't optimize much for this architecture. It is also clear that on average for different datasets, the "bandit" algorithm comes out ahead of the pre-selected best variant on all processors (except for very old Intel CPUs).
Conclusion
In practice, the usefulness of this work is dubious. Yes, LZ4 decompression was accelerated on average by 12-20%, and on some datasets, the performance more than doubled. But in general, this doesn't have much effect on query execution time. It's difficult to find real queries that gain more than a couple of percents in speed.
At the time, we decided to use ZStandard level 1 instead of LZ4 on several clusters intended for executing long queries; because it is more important to save IO and disk space on cold data. Keep this in mind if you have a similar workload.
We observed the greatest benefits from optimizing decompression in highly compressible data, such as columns with mostly duplicate string values. However, we have developed a separate solution specifically for this scenario that allows us to significantly speed up queries over this kind of data.
Another point to remember is that optimization of decompression speed is often limited by the format of the compressed data. LZ4 uses a very good format, but Lizard, Density, and LZSSE have other formats that can work faster. Perhaps instead of trying to accelerate LZ4, it would be better to just integrate LZSSE into ClickHouse.
It's unlikely that these optimizations will be implemented in the mainstream LZ4 library: in order to use them, the library interface would have to be modified. In fact, this is often the case with improving algorithms — optimizations don't fit into old abstractions, and they have to be revised. However, variable names have already been corrected in the original implementation. For instance, inc and dec tables have been corrected. In addition, the original implementation accelerated decompression by the same 12-15% by copying 32 bytes instead of 16, as discussed above. We tried the 32-byte option ourselves, and the results were not that great, but they were still faster.
If you look at the profile at the beginning of the article, you may notice that we could have removed one extra copying operation from the page cache to userspace (either using mmap, or using O_DIRECT and userspace page cache, but both options are problematic). We also could have slightly improved the checksum calculation (CityHash128 is currently used without CRC32-C, but we could use HighwayHash, FARSH, or XXH3). Acceleration of these two operations is useful for weakly compressed data since they are performed on compressed data.
In any case, the changes were incorporated into master, and the ideas that resulted from this research have been applied in other tasks.




{kind=link}