TL;DR ClickHouse is built to run fast on Parquet, the storage format behind open table formats like Iceberg and Delta Lake, and it has been optimizing for it for years.
This post takes you deep inside the query engine to show how it queries Parquet files directly (no ingestion required), faster than many systems can query their own native formats, and what’s coming next to make it even faster.
It’s the first in a new series on how ClickHouse powers fast Lakehouse analytics from the ground up.
Spoiler: ClickHouse isn’t getting ready for the Lakehouse, it’s already there.
A Lakehouse-ready engine, by accident and by design
Sometimes, the future catches up with what you were already doing.
ClickHouse wasn’t built for the Lakehouse (Iceberg and Delta Lake formats were created when ClickHouse was already a mature DBMS), but it turns out to be a great fit. With first-class support for Parquet and direct file querying, it has long supported many Lakehouse-style patterns natively.
The ClickHouse query engine has always treated querying data in any format, including Parquet, from any location, including object storage, as a core capability. Whether loading data or querying it directly without ingestion, it’s simply how things have always worked.
Today’s Lakehouse architecture puts a name to what ClickHouse has already been doing for years: run anywhere, query anything, and access data from anywhere.
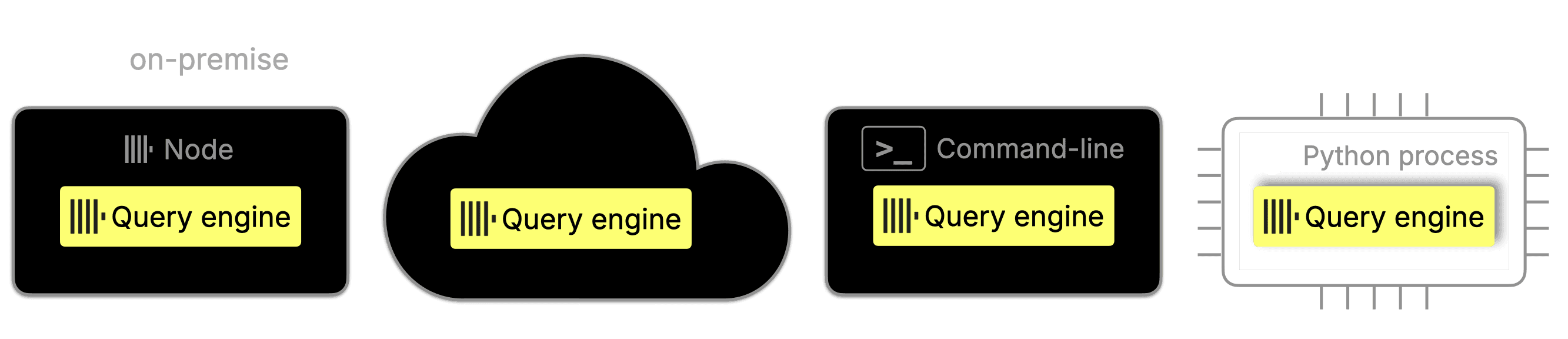
Run anywhere: The engine can be operated in on-premise, cloud, standalone, or in-process modes:
Query anything: While it’s optimized for its native MergeTree tables, ClickHouse can also query external formats directly, without ingesting them first. Most databases require you to load files like Parquet into their own native format before running queries. ClickHouse can fully skip that step; the ClickHouse query engine can directly query over 70 file formats out of the box, with no restrictions. You get full SQL support, including joins, window functions, and 160+ aggregation functions, all without needing to ingest the data first. Supported formats include Parquet, JSON, CSV, Arrow, and many more:

Access data from anywhere: With 80+ built-in integrations, the engine connects seamlessly to external systems and storage platforms, including S3/GCP/Azure object stores.
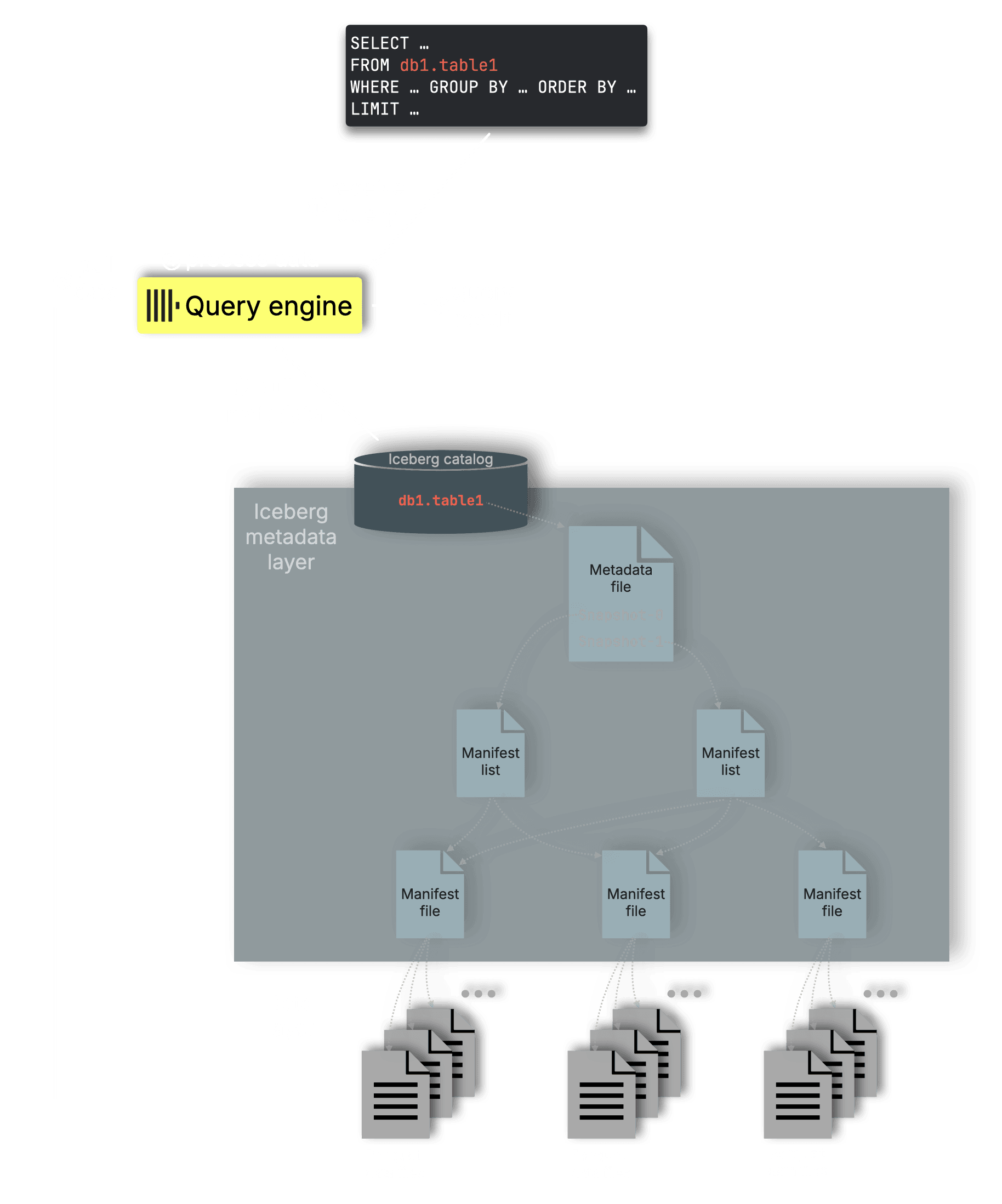
These features make ClickHouse a great fit for data lakes, letting you query open table formats like Apache Iceberg, which store data mainly in Parquet files, usually on object storage like S3, GCS, or similar:
And thanks to its flexible run modes, the ClickHouse query engine can be deployed wherever your Lakehouse lives: close to your object store, inside multi-tenant SaaS environments, embedded in Python workflows for interactive analysis in notebooks using pandas dataframes, or even as stateless workers in environments like AWS Lambda.
Inside the engine: How ClickHouse queries Parquet
Let’s take a closer look at how ClickHouse handles one of the Lakehouse’s most important building blocks: Parquet.
- How effectively can the ClickHouse engine directly query Parquet files today?
- Out of curiosity, how does its performance compare with native MergeTree tables?
- Are there even faster external formats among the 70+ that ClickHouse supports?
- And what’s coming next to make it even better?
This post answers all of the above and kicks off a new blog series on ClickHouse as a fast, flexible Lakehouse engine. We begin with the Parquet data layer that underpins open table formats like Iceberg and Delta Lake.
We’ll start by examining how the current Parquet reader works and what makes it fast. Then, we’ll benchmark its performance on real analytical queries, highlighting both current capabilities and upcoming improvements.
As mentioned in the introduction, the ClickHouse query engine supports direct querying of 70+ file formats, including Parquet, without ingestion. Format-specific readers plug into the engine, as shown below:
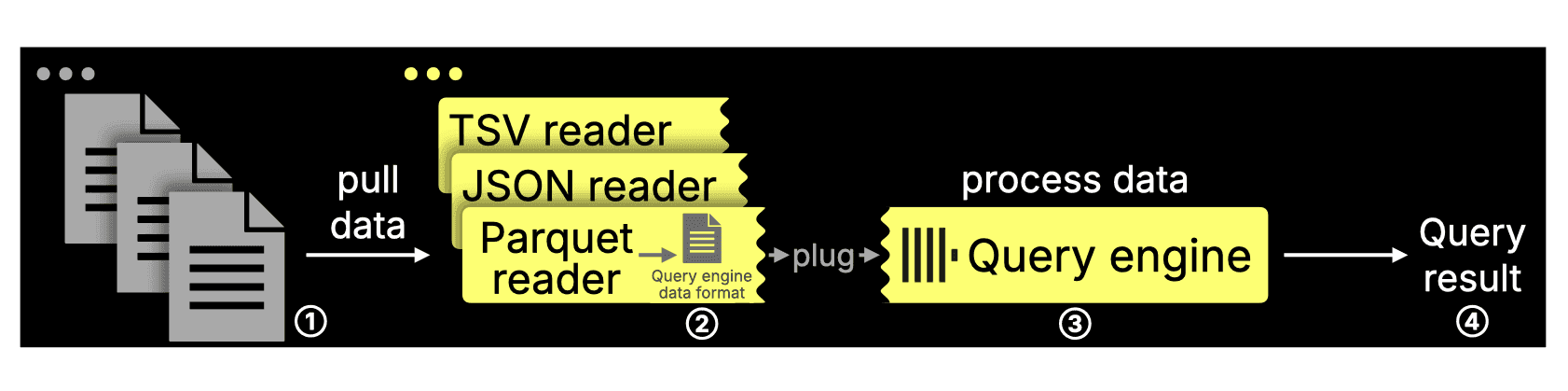
When querying ① external files, the format-specific reader reads and parses the data, ② converts it into ClickHouse’s in-memory format, and passes it to the query engine, which ③ processes it into the ④ final result.
In the rest of this section, we’ll focus on the Parquet reader. Combined with the ClickHouse query engine, it’s the key component behind the high performance of direct Parquet file queries.
How the Parquet reader works today and what’s next
Fun fact: While MergeTree remains the native data storage format, ClickHouse has been actively tuning and optimizing for Parquet for over three years. It’s all part of our goal to make ClickHouse the fastest engine in the world for querying Parquet at scale.
The current Parquet reader uses the Arrow library to parse files into Arrow format, then copies the data into ClickHouse’s native in-memory format for execution. In the next sections, we’ll explore the capabilities of this reader.
A new native Parquet reader is already in the works, designed to eliminate the Arrow layer entirely and read files directly into ClickHouse’s native in-memory format. It also brings better parallelism and I/O efficiency. The project is fittingly called Yet Another Parquet Reader, because, well, it is. This is ClickHouse’s third native Parquet reader implementation. The first (input_format_parquet_use_native_reader) was started but never completed. The second (v2) made it to a pull request, but stalled before reaching production. And now, v3 is underway.
We could’ve waited to publish this post until the new reader was finished, but benchmarking the current reader gives us a great baseline. In a future follow-up, we’ll highlight how the new reader improves performance and efficiency.
Parquet file query performance in ClickHouse is primarily determined by two factors:
-
Level of parallelism: The more files, and the more non-overlapping regions within those files, that ClickHouse can read and process in parallel, the higher the throughput and the faster the queries complete.
-
Degree of I/O reduction: The less unnecessary work (such as scanning and processing irrelevant data) is done, the faster queries complete.
In the next two sections, we’ll break down how the query engine and current Parquet reader work together to achieve parallelism and I/O reduction, and highlight upcoming improvements in the native reader. We’ll also cover tuning settings that let you influence these behaviors for performance tuning.
Parallelism: How the engine scales
Before explaining how ClickHouse currently achieves parallelism when querying Parquet files, we first need to briefly look at the physical on-disk structure of a Parquet file. The way Parquet organizes data fundamentally determines how efficiently the data can be split into independent units of work, and thus how much parallelism can be applied during query execution.
The following diagram shows a simplified view of how data from a web analytics dataset (used later in our benchmark) is organized on disk when stored as Parquet files:
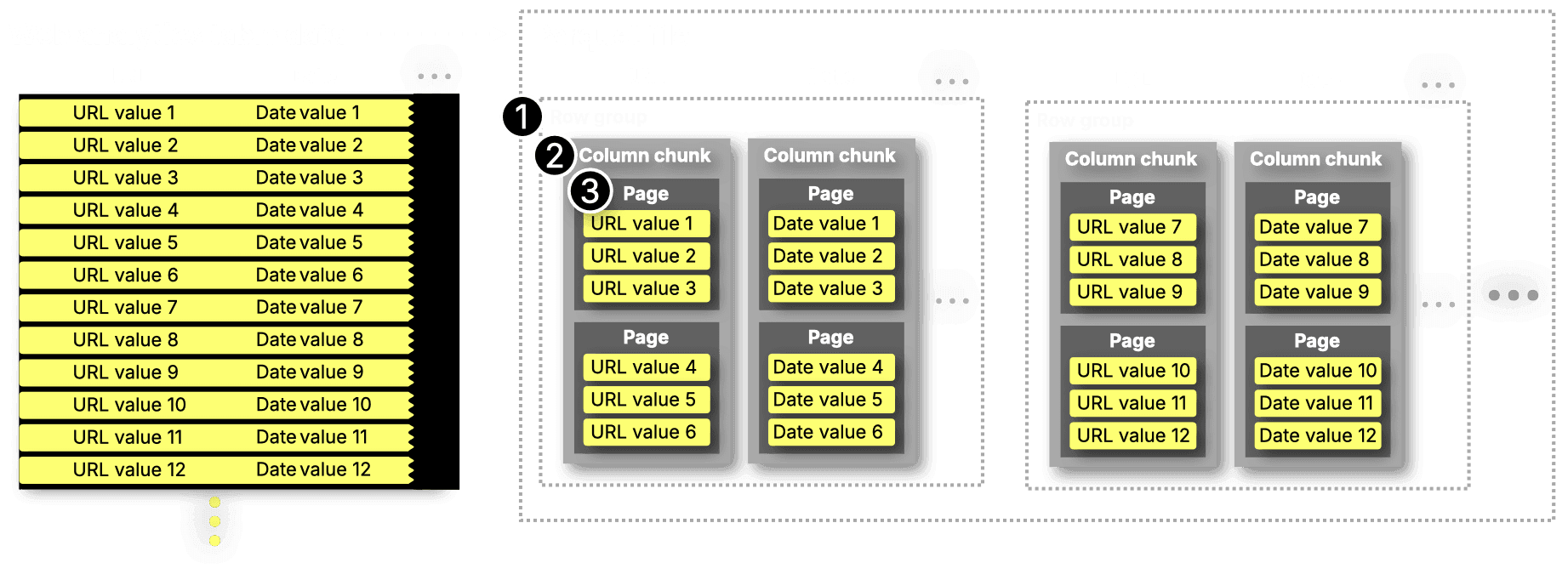
In Parquet, our test dataset, consisting logically of rows and columns, is stored in one or more files. Each file organizes the data hierarchically as follows:
① Row groups: The stored data is divided into one or more horizontal partitions called row groups. By default, when Parquet files are written with ClickHouse, each row group contains 1 million rows or ~500 MB of data (before compression).
② Column chunks: Each row group is further divided vertically into column chunks, one for each column in the dataset. Each chunk stores the values for that column across all rows in the row group.
③ Data pages: Inside each column chunk, the actual values are stored in data pages. By default, ClickHouse writes data pages of 1 MB (before compression). A page stores a fixed or variable number of encoded and compressed values, depending on the column’s data type and the encoding scheme used.
Note: For readability, the diagram above shows row groups containing six rows and data pages containing three values per column.
With the data layout clear, we can now look at how the ClickHouse query engine, together with the current Parquet reader, parallelizes data processing across available CPU cores to maximize query performance.
ClickHouse doesn’t just run anywhere and query anything, it also parallelizes almost everything, especially when querying Parquet. The following diagram shows how different layers of parallelism come together within the Parquet reader and the ClickHouse query engine during query execution:
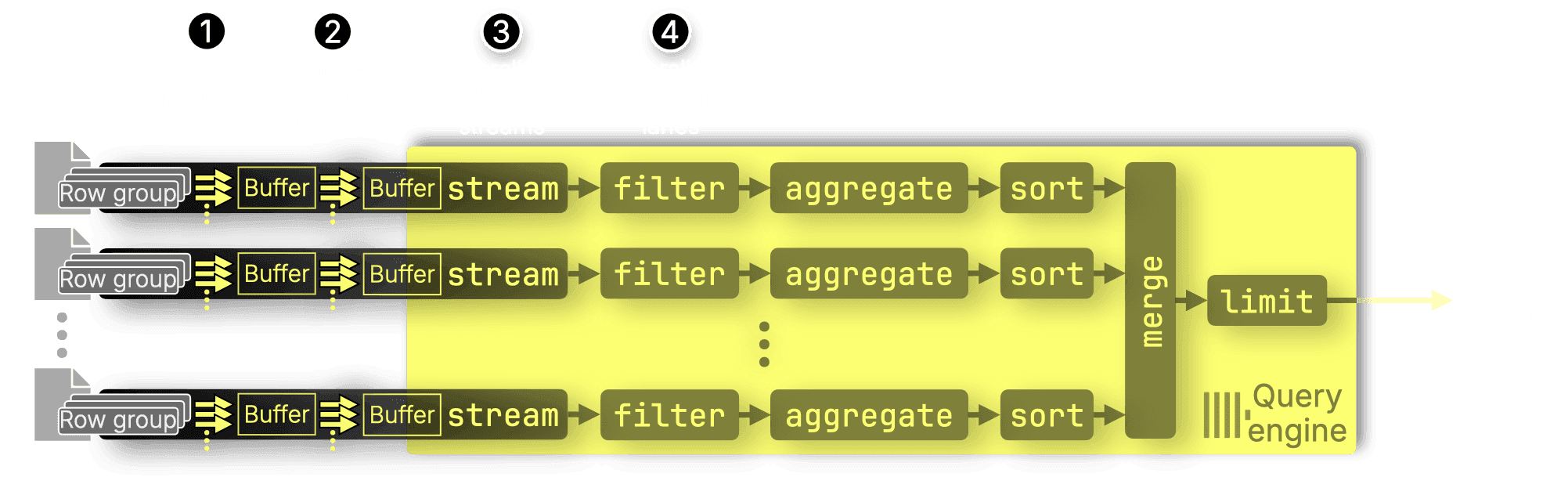
① Parallel prefetch threads: Within a Parquet file, the Parquet file reader reads multiple row groups in parallel (intra-file, inter–row group parallelism). By default, row group prefetching is enabled with four parallel prefetch threads (controlled by the max_download_threads setting) and kicks in either when parsing reaches its maximum parallelism (explained below) or when parsing would otherwise stall, such as when data must first be loaded over a network connection.
② Parallel parsing threads: Parsing threads read and parse data from multiple row groups within the same file in parallel (intra-file, inter–row group parallelism). If prefetching is active, they read from the prefetch buffer; otherwise, they read directly from the file. The number of parsing threads (across all file streams, see below) is controlled by the max_parsing_threads setting, which by default matches the number of available CPU cores.
③ Parallel file streams: Different Parquet files are processed concurrently, each with their own parallel prefetch and parsing threads, to maximize throughput across files (inter-file parallelism). The number of file streams is determined dynamically during query compilation (see below).
④ Parallel processing lanes: As data is passed from the Parquet reader component to the query engine block-wise and in a streaming fashion, filtering, aggregation, and sorting happen across independent lanes for maximum concurrency (inter- and intra-operator parallelism). The number of parallel processing lanes is determined by the max_threads setting, which by default matches the number of CPU cores available to the ClickHouse query engine.
Whether you’re querying many small files or a single large file, ClickHouse automatically balances the Parquet file processing such that query execution remains efficient. To achieve this, the file path pattern used to select Parquet files (e.g. with the file table function) is resolved during query compilation, and the number of matching files (num_files) directly influences the physical query plan:
- Many small files are parsed with one thread per file across many file streams.
- A single large file is parsed with many threads operating in parallel on a single stream.
The calculations for this follow simple rules:
-
Number of parallel file streams =
min(max_threads, num_files) -
The available parallel parsing threads (
max_parsing_threads) is then evenly spread over the file streams with this formula:max(max_parsing_threads / num_files, 1)Here,/denotes integer division (rounding down), andmax()ensures that at least one parsing thread is assigned per file.
Let’s briefly look at three examples to see how this balancing of file streams and parsing threads works in practice.
Parallelism in practice: 3 examples
In the following, we use the EXPLAIN clause to inspect the physical operator plan—also known as the “query pipeline”—for three different runs of ClickBench query 11, executed over a web analytics dataset (used later in our benchmark) stored as Parquet files. This query filters, aggregates, and sorts the data before applying a LIMIT. With the graph option, ClickHouse outputs the plan in DOT format, which can be rendered to a PDF using Graphviz.
Example 1: One Parquet file, 4 cores
As a first example, we set max_threads and max_parsing_threads to 4 (simulating a 4-core machine and keeping the plan readable) and use a path pattern matching exactly one Parquet file:
clickhouse local --query "
EXPLAIN Pipeline graph = 1, compact = 0
SELECT MobilePhoneModel, COUNT(DISTINCT UserID) AS u
FROM file('./output/Parquet/100000000/1000000/sorted/zstd/chunk_00.parquet')
WHERE MobilePhoneModel <> ''
GROUP BY MobilePhoneModel
ORDER BY u DESC LIMIT 10
SETTINGS max_threads = 4, max_parsing_threads = 4;
" | dot -Tpdf > pipeline.pdf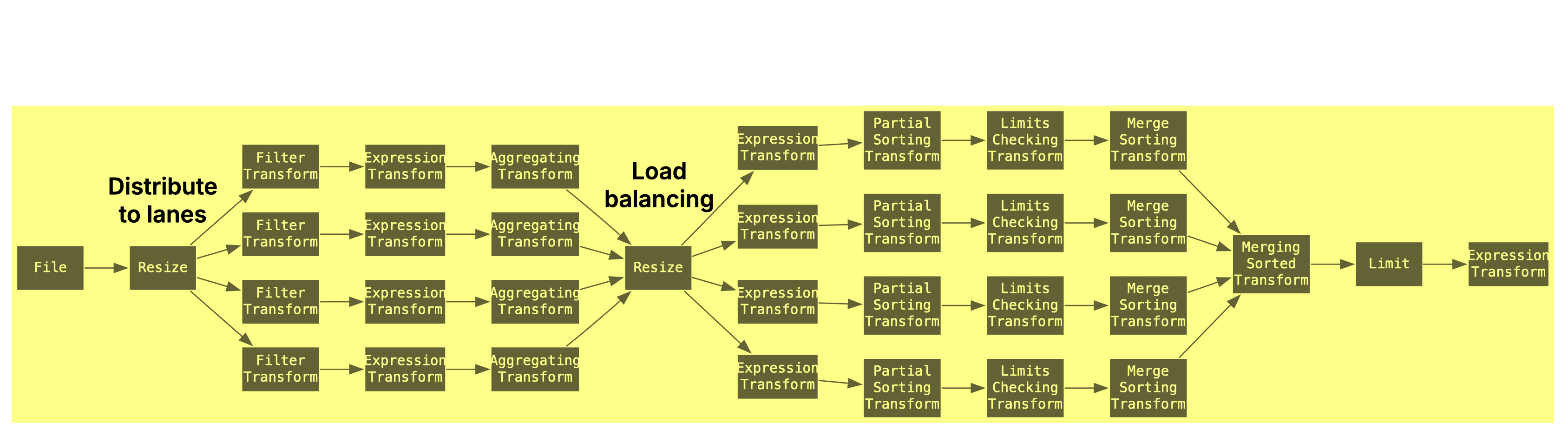
As you can see, the query engine uses one file stream (based on the min(max_threads = 4, num_files = 1) formula), and 4 parallel processing lanes (max_threads = 4) for running the query over the data of one Parquet file.
The visualization above flows left to right. A Resize operator evenly distributes parsed file data across four processing lanes, where filtering and partial aggregation is performed. A second Resize rebalances the streams to maintain even CPU utilization, crucial when data ranges have different predicate selectivities, which could otherwise overload some lanes and leave others idle. This dynamic redistribution ensures faster lanes assist slower ones, improving overall performance. Sorting proceeds in three stages:
PartialSortingTransformsorts individual blocks in each lane.MergeSortingTransformmaintains a local sorted stream per lane via 2-way merges.MergingSortedTransformperforms a k-way merge across lanes, followed by aLIMITto produce the final result.
There’s no direct logging or easy way to introspect the number of parallel parsing threads per file. However, based on the formula in the source code: max(max_parsing_threads / num_files, 1), we can infer that with one file and max_parsing_threads = 4, multiple row groups are parsed in parallel using four threads.
Example 2: Two Parquet files, 4 cores
In the second example, we keep max_threads and max_parsing_threads set to 4 but change the file path pattern to match exactly 2 Parquet files:
clickhouse local --query "
EXPLAIN Pipeline graph = 1, compact = 0
SELECT MobilePhoneModel, COUNT(DISTINCT UserID) AS u
FROM file('./output/Parquet/100000000/1000000/sorted/zstd/chunk_0{0..1}.parquet')
WHERE MobilePhoneModel <> ''
GROUP BY MobilePhoneModel
ORDER BY u DESC LIMIT 10
SETTINGS max_threads = 4, max_parsing_threads = 4;
" | dot -Tpdf > pipeline.pdf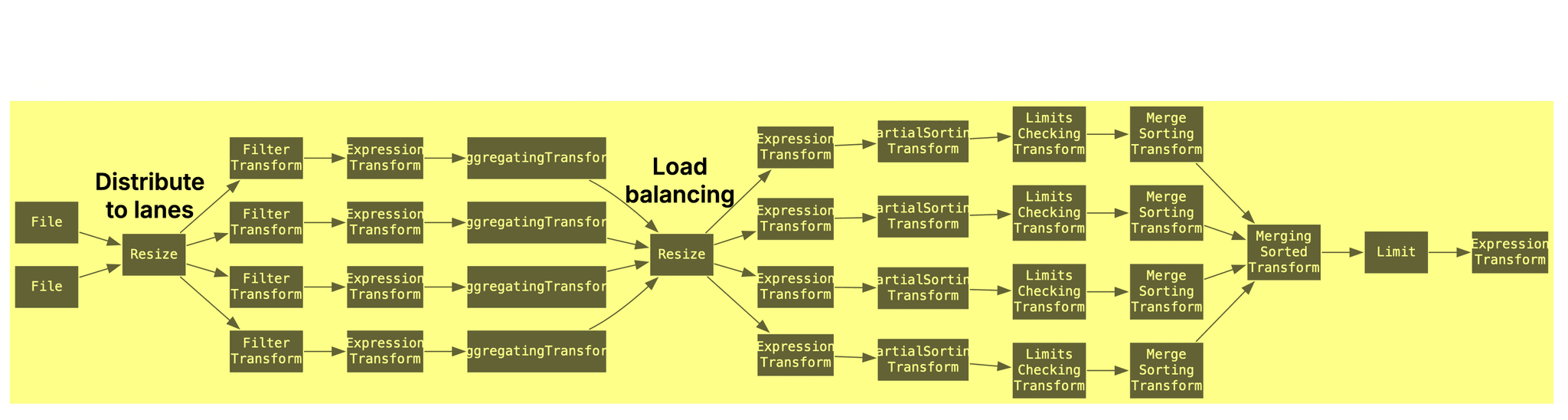
Now the query engine uses two parallel file streams ( = min(max_threads = 4, num_files = 2) , and 4 parallel processing lanes (max_threads = 4) for running the query over the data of two Parquet files.
The number of parallel parsing threads per file stream is 2 instead of 4 though (max(max_parsing_threads = 4 / num_files = 2, 1)).
Example 3: 100 Parquet files, 32 cores
Finally we show an example without artificially restricted max_threads and max_parsing_threads thresholds. On our test machine with 32 CPU cores both are set to 32 by default. The file path pattern matches all 100 Parquet files of the example dataset:
clickhouse local --query "
EXPLAIN Pipeline graph = 1, compact = 0
SELECT MobilePhoneModel, COUNT(DISTINCT UserID) AS u
FROM file('./output/Parquet/100000000/1000000/sorted/zstd/chunk_*.parquet')
WHERE MobilePhoneModel <> ''
GROUP BY MobilePhoneModel
ORDER BY u DESC LIMIT 10;
" | dot -Tpdf > pipeline.pdf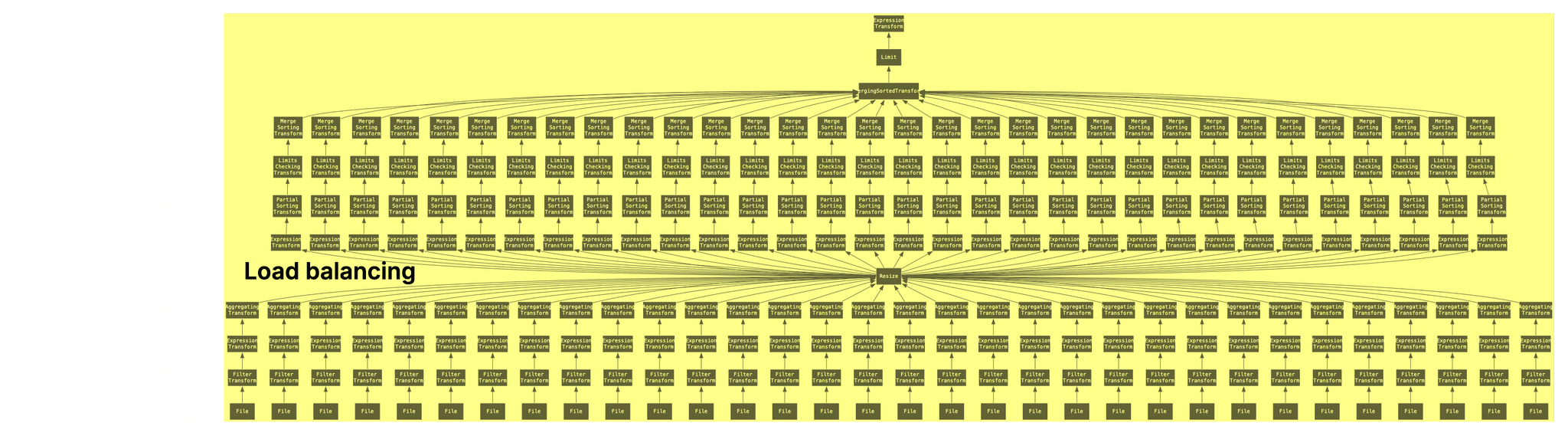
Scaling out: Cluster-wide execution
So far, we’ve shown how a single ClickHouse query engine instance parallelizes Parquet processing across CPU cores. In parallel cluster engine mode, the query engine distributes the work across all available CPU cores of all available nodes, scaling parallelism across the entire cluster:
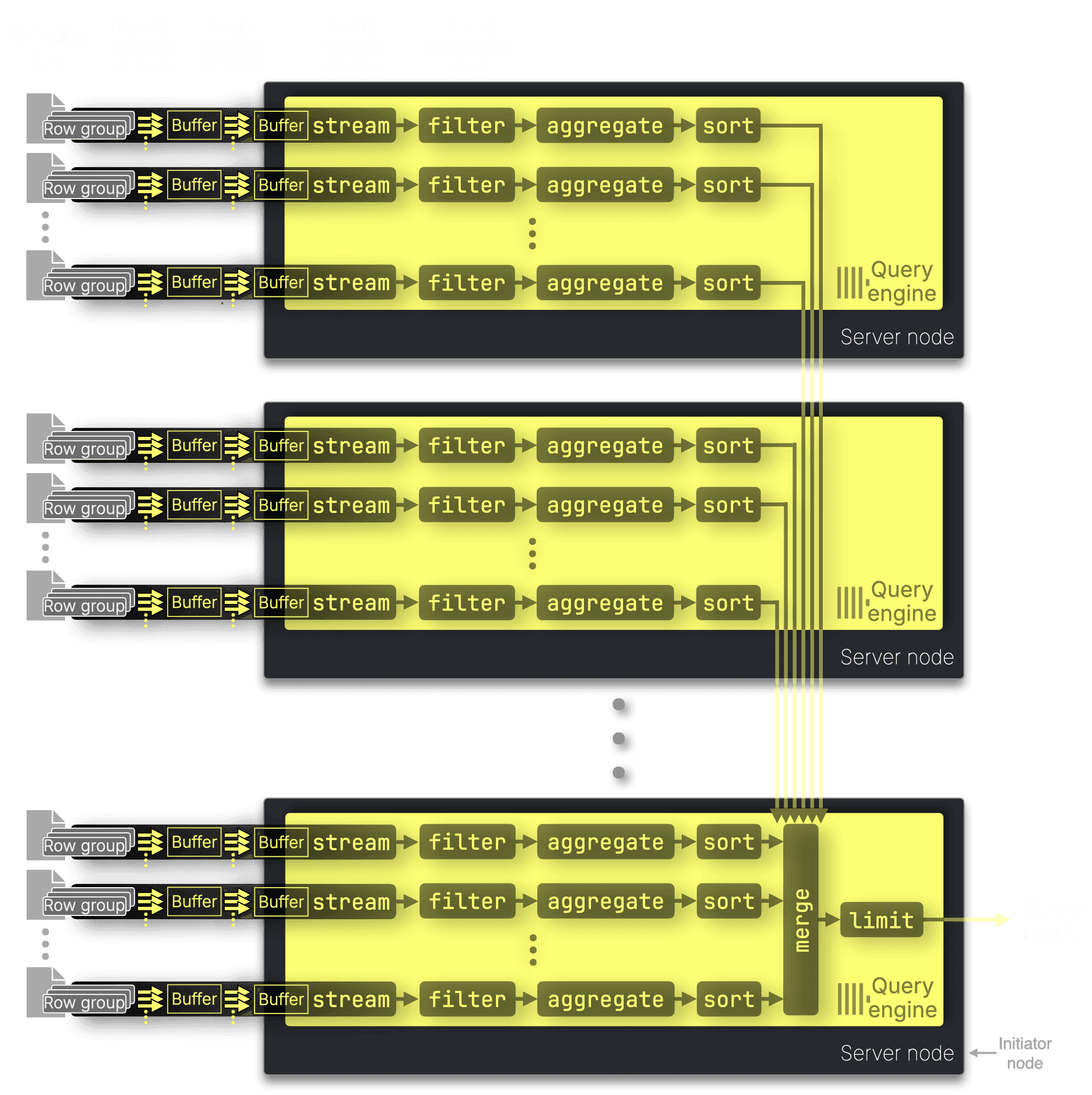
The query engine on the initiator node—the server that receives the query—resolves the file glob pattern, connects to engines on the other nodes, and dynamically assigns files. As remote nodes finish processing, they request more files from the initiator until all files are processed.
What’s next for performance: smarter and finer-grained parallelism
The upcoming native Parquet reader not only removes the Arrow dependency, eliminating the in-memory copy from Arrow data into ClickHouse’s internal format, saving time and memory, but also enables more fine-grained and adaptive parallelism:
-
Column-level parallelism within row groups: Instead of only processing entire row groups in parallel, the new reader can read different columns from the same row group concurrently, enabling better CPU utilization when fewer row groups are available.
-
Merged I/O requests: By pre-registering expected file ranges, the reader can detect small, adjacent I/O operations and merge them into fewer, larger read requests, improving throughput, especially on high-latency storage.
-
Parallelism-aware scheduling: The engine can assign different degrees of parallelism depending on the stage and memory footprint, e.g., using high parallelism for small structures like Bloom filters, and more conservative parallelism for bulk column data to reduce memory pressure.
These changes are designed to better exploit system resources and maintain throughput consistency across workloads of varying size and complexity.
With parallelism covered, we now turn to the second key factor for fast Parquet queries in ClickHouse: minimizing unnecessary I/O. The less irrelevant data we scan, parse, or process, the faster queries run. In the next section, we’ll look at the I/O reduction techniques ClickHouse applies today, and those coming soon with the native reader.
I/O reduction: What we skip, and how
To understand how ClickHouse minimizes unnecessary reads, let’s look at the I/O reduction techniques enabled by Parquet’s file structure.
Column projection
Parquet is a columnar format, so the reader and ClickHouse query engine only access the columns needed by a query.
Compression and encoding
By encoding data (e.g., using dictionaries or run-length encoding) and compressing it column-by-column, Parquet reduces the amount of data stored and read from disk. This not only saves space but also speeds up queries. ClickHouse can scan less data, decompress only what’s needed, and skip entire sections based on encoded metadata (see below).
Parquet supports a variety of encoding and compression schemes at the page level:
-
Page encoding: Parquet defines several encoding schemes for efficient value storage. Common examples include dictionary encoding (see below) and run-length encoding.
-
Page compression: After encoding, pages can be compressed using algorithms like Snappy, LZ4, and ZSTD to further reduce file size and I/O.
Predicate pushdown
Parquet enables coarse-grained predicate pushdown through metadata stored at multiple levels of granularity. This metadata wasn’t shown earlier; the diagram below now includes it, again using our web analytics dataset for illustration. Again, for clarity, it shows row groups with just six rows and data pages with only three values per column:
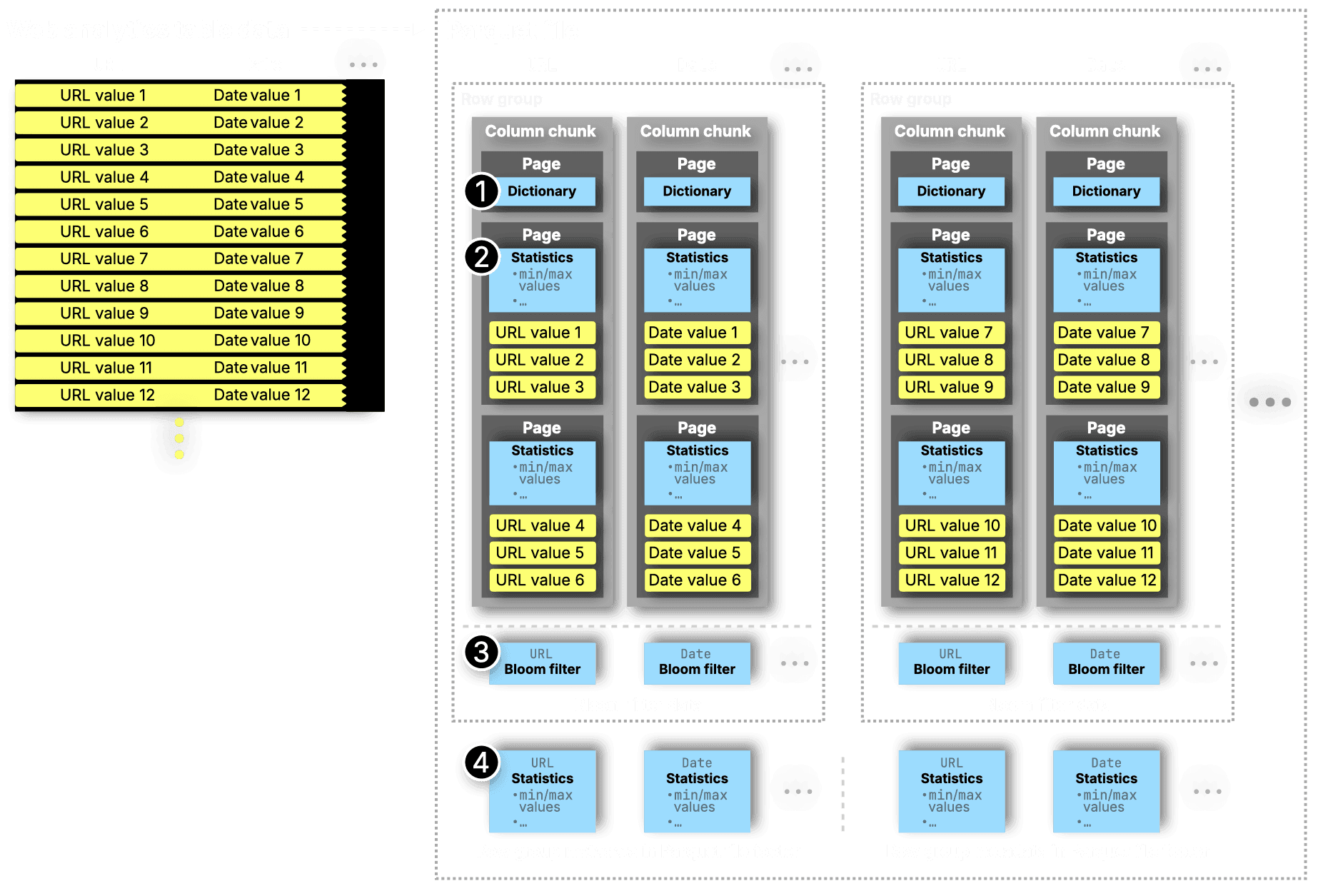
Below, we describe the metadata elements added in the diagram above in more detail.
① Column chunk-level dictionary filtering: For low-cardinality columns, Parquet uses dictionary encoding. Each column chunk includes a dictionary page that maps unique values. When queries filter on a specific value, like WHERE status = 'cancelled', readers can check the dictionary first to decide whether the chunk contains that value and can be skipped entirely if not.
② Page-level min/max filtering: Parquet pages can include statistics such as the minimum and maximum values for the column data stored on each page. When queries filter on a specific range, like WHERE amount > 1000, readers can use these stats to skip over pages where all values fall below the threshold. This is especially effective on sorted data, where large blocks can often be ruled out early.
③ Column chunk-level bloom filters: Optionally, Parquet files may include a Bloom filter per column per row group. Readers can use these filters to efficiently check whether a value might exist and skip reading column data when it definitely doesn’t.
④ Column chunk-level min/max filtering: Similar to page-level stats, Parquet can store min/max statistics at the row group level per column. This allows readers to skip entire columns within a row group if they’re guaranteed to be irrelevant for a query.
So, how much of this does the ClickHouse Parquet reader support today?
The current Parquet reader in ClickHouse supports
③ Bloom filters (enabled via input_format_parquet_bloom_filter_push_down setting) and
④ row group–level min/max filtering (controlled via input_format_parquet_filter_push_down setting).
The upcoming native reader will add support for
① dictionary filtering and
② page-level min/max filtering.
In addition to these built-in Parquet optimizations, the new native reader will also integrate ClickHouse-specific I/O reduction techniques—most notably PREWHERE and lazy materialization—to further reduce unnecessary reads and improve performance.
With that, we’ve covered how the current Parquet reader in ClickHouse achieves performance through parallelism and I/O reduction, and what improvements are on the horizon. Now that we understand how the current Parquet reader works, let’s see how it performs on real-world analytical queries.
Benchmarking Parquet query performance
In our previous FastFormats benchmark, we evaluated how quickly different formats can be ingested into a ClickHouse table when the data is pushed (by a client) to the ClickHouse server.
This time, we look at the flip side: how fast can the ClickHouse query engine query these formats directly, without ever ingesting them:

Benchmark setup: Hardware, dataset, and software
We used the same environment as in the FastFormats benchmark, with the following setup:
-
Hardware: AWS EC2 m6i.8xlarge instance (32 vCPUs, 128 GiB RAM, 1 TiB gp3 SSD)
-
Dataset: Anonymized web analytics dataset (same as in ClickBench)
-
ClickHouse version: 25.4.1 running on Ubuntu Linux 24.04
Generating files from the dataset
We reused the same FastFormats benchmarking mechanics to automatically generate various combinations of:
- File size (and number of files)
- Format (e.g., Parquet, JSON, Arrow, etc.)
- Pre-sorting (matching the original table’s sorting key, which benefits some queries)
- Compression (LZ4, ZSTD, or none)
Specifically, for each tested format, we split the 100 million rows of the dataset into:
- 100 files, each with 1 million rows
- 6 file versions: all combinations of with/without pre-sorting and with/without compression (LZ4, ZSTD)
Running the queries: ClickBench for files
We extended the benchmark to automatically run all 43 official ClickBench queries sequentially and in isolation on each generated file set, essentially running ClickBench (by using the file table function) over file-based formats. Like in ClickBench, each query was run three times, with the OS page cache cleared once before the first run. The first run was used for the cold runtime; for the hot runtime, we took the minimum of the second and third runs.
Query engine modes
To access detailed runtime metrics beyond just execution time and memory usage, we ran all queries using the ClickHouse engine in server mode, i.e., with clickhouse-client connecting to a clickhouse-server process. While we could have used the engine standalone via clickhouse-local for file-based queries, using the server allowed us to capture rich statistics via the query log system table. Importantly, all queries were still executed directly over the file-based data; no data was ingested into tables (except for the additional merge tree benchmark, see below). And regardless of the engine mode used, it’s always the same query engine and code path under the hood.
What we measured
Using the query log, we tracked the following metrics for each query:
- Runtime: how long each query took to run
- Memory usage: peak memory usage during execution
- Read rows: number of rows read from the dataset
- Read bytes: total data read from the dataset
- Threads participating: number of threads involved in execution
- Peak threads usage: max number of threads running concurrently
- DiskReadElapsedMicroseconds: time spent waiting on the read syscall
Real-world performance: Parquet vs the rest
Let’s now see how the current Parquet reader’s parallel processing and I/O reduction optimizations translate into real-world performance on representative analytical queries. We’ll start by looking at how a single representative ClickBench query performs, then zoom out to the full results across all 43 queries.
Apples vs. oranges
For comparison, we also tested query performance on the same hardware using a native MergeTree table, with the query engine running in server mode.
We’re aware that comparing Parquet to MergeTree isn’t entirely apples to apples. Parquet is a general-purpose file format, while MergeTree is a purpose-built table engine with deep integration and years of performance tuning. We don’t expect Parquet to outperform MergeTree.
A more direct comparison would be MergeTree vs. open table formats like Iceberg or Delta Lake, which build additional metadata and potentially indexing layers on top of Parquet. But that’s a topic for future posts. Here, we’re focusing on the foundations, how well ClickHouse queries Parquet files directly, and where performance stands today. As we continue investing in these Lakehouse foundations and aim for market-leading performance, the gap will only keep closing.
Query 41: Runtime, parallelism, and I/O
The chart below compares 8 selected input formats by cold and hot runtime, number of concurrent processing threads (tracked via peak_threads_usage field in the query log), and, most importantly, the amount of data processed to run ClickBench query 41 directly on file-based data.
Query 41 is a typical analytical workload that filters, aggregates, sorts, and applies a LIMIT. For all formats, the dataset was stored pre-sorted and ZSTD-compressed on disk.
As a baseline—though it’s apples vs. oranges—we also include results for the same query run on a native MergeTree table with the same pre-sorted, ZSTD-compressed layout:
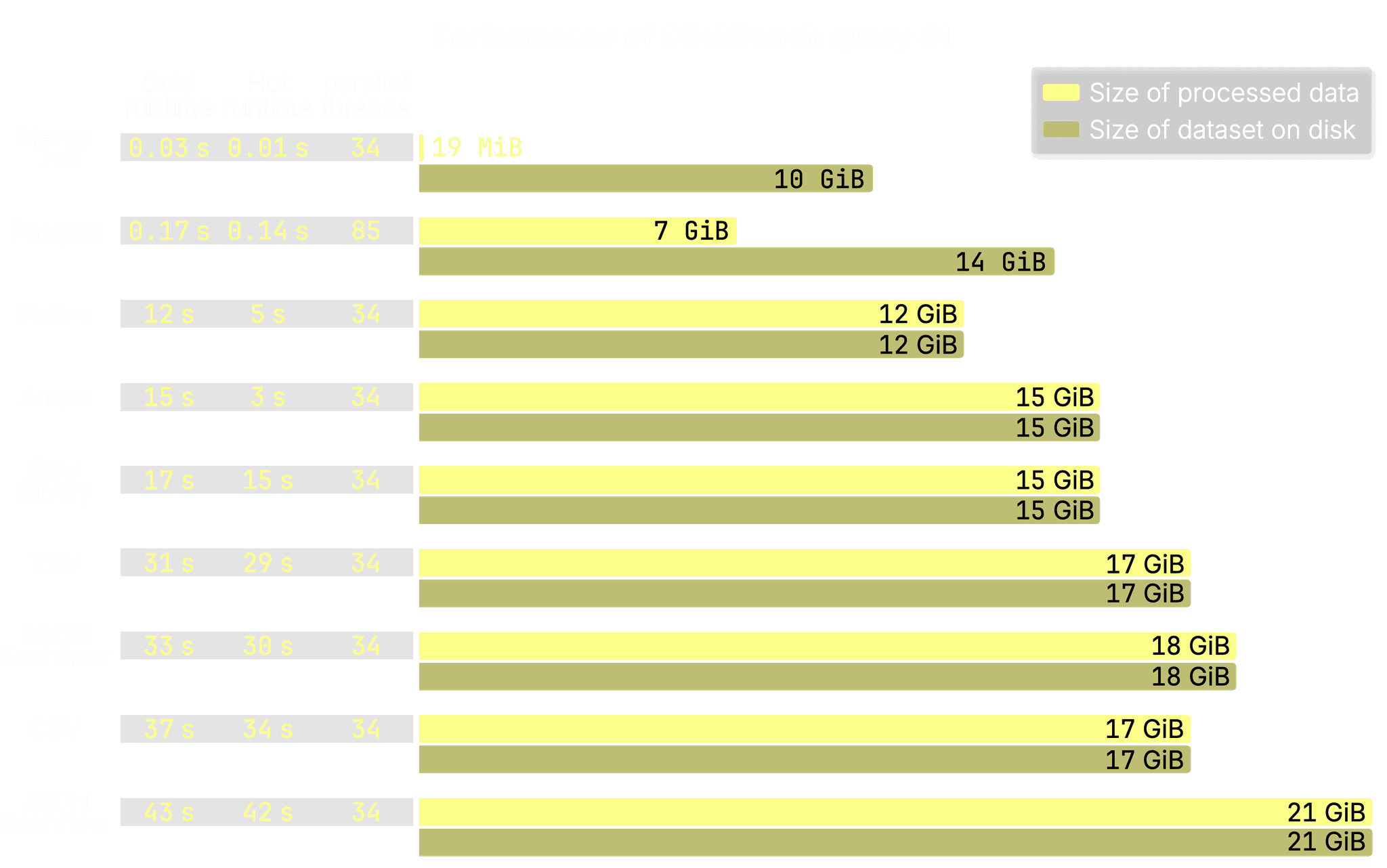
The chart’s main focus is on how much of the total data the query engine had to process to execute the query. The entries in the chart are sorted by cold runtime (fastest first), and three key observations stand out:
-
MergeTree: As ClickHouse’s native format, MergeTree enables the most aggressive I/O reduction, leveraging the full stack of optimizations, including PREWHERE and lazy materialization. In this query, only 19 MiB of data was processed out of 10 GiB total, thanks largely to the sparse primary index, which efficiently scans index entries for multiple compound primary key predicate columns at once and selects matching row groups based on the physical data order on disk. This results in extremely low query latency, just 30 milliseconds cold and 10 milliseconds hot. Which was expected for a highly optimized table engine.
-
Parquet: When querying Parquet files directly, ClickHouse already cuts I/O roughly in half using predicate pushdowns (min/max stats and Bloom filters). However, current limitations—such as the absence of PREWHERE and lazy materialization—mean there is still room for improvement. Still, it performs well: in this query, 7 GiB out of 14 GiB was processed, and thanks to high parallelism (85 concurrent threads), it completed in 170 milliseconds cold and 140 milliseconds hot, roughly 5× slower than MergeTree, but still very fast for a file format.
-
Other formats: Most of the other input formats (e.g., CSV, JSON, Arrow) are primarily intended for easy data loading, or in the case of Native, for efficient inter-system data transport, not for direct analytical querying. As a result, ClickBench query 41 took 30–43 s cold and 29–42 s hot. While it’s technically possible to implement I/O reduction techniques like column projection for these formats, ClickHouse doesn’t currently do so, because these formats aren’t typically considered for direct analytical use at scale. In practice, this means the full dataset (up to 21 GiB) often needs to be scanned and parsed.
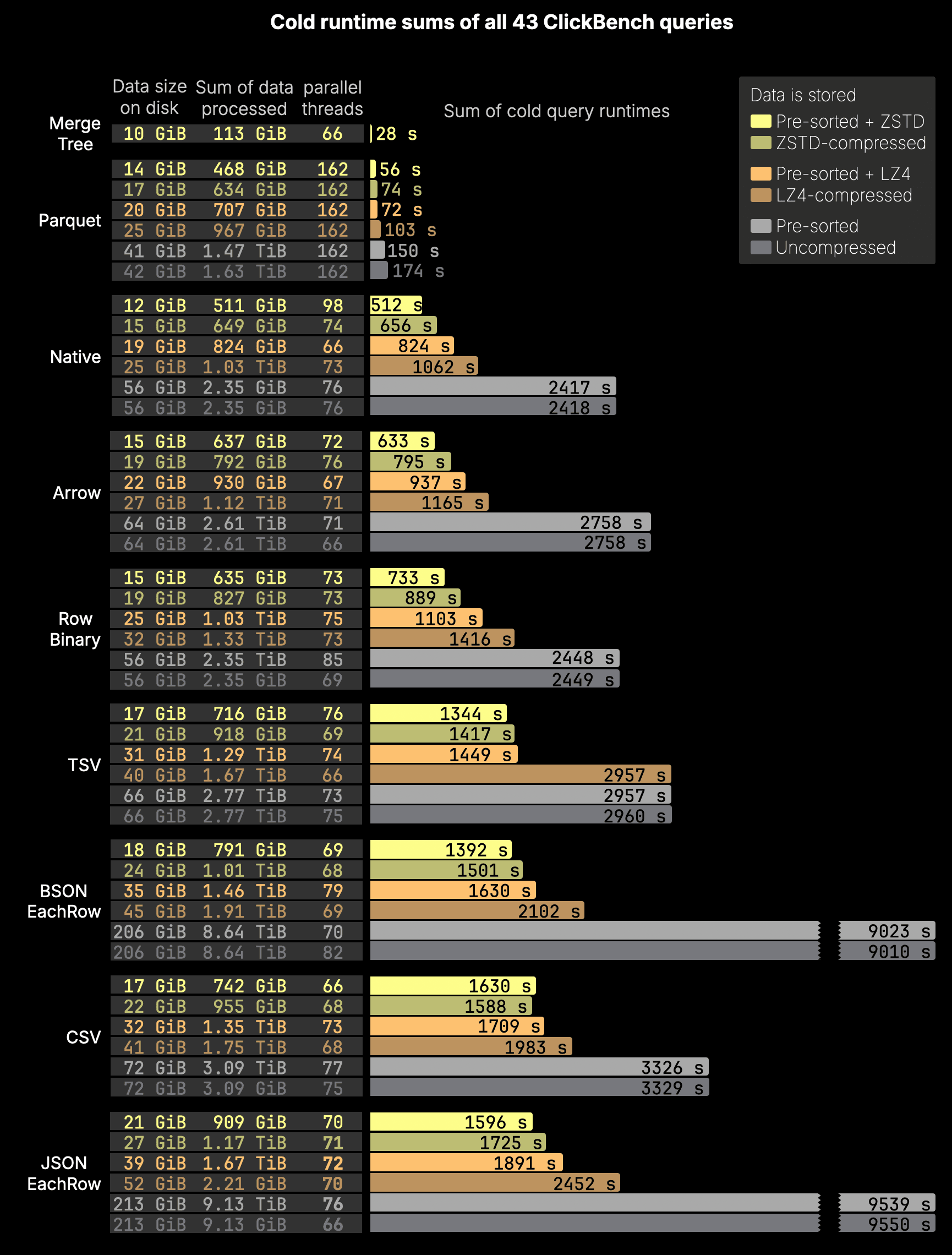
All 43 queries: Total runtime comparison
To complete the picture, the chart below focuses on the total runtimes across all 43 ClickBench queries run directly over the same file formats as in the previous chart. To keep things concise, we report only the runtime sums. As before, the queried dataset was stored on disk pre-sorted and ZSTD-compressed for each format.
For comparison, just out of curiosity, we again include a native MergeTree table using the same layout as the file-based formats.
All results in this chart use the pre-sorted, ZSTD-compressed version of each format, as this configuration consistently delivered the fastest runtimes across all tested combinations (with or without pre-sorting, and with no compression, LZ4, or ZSTD). If you’re curious, we’ve published the full results for all combinations here, along with a summary chart for cold runtime sums.
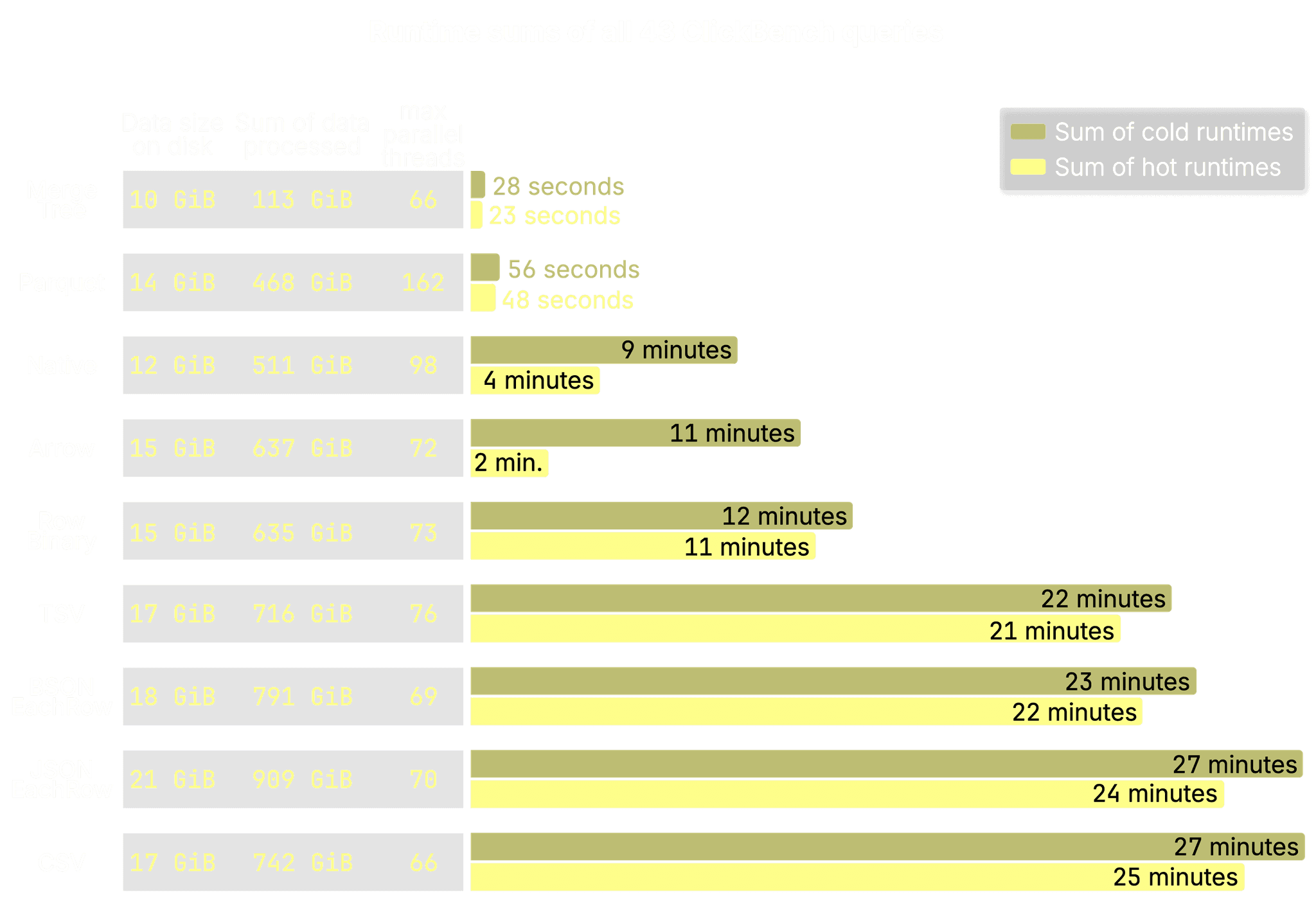
The total cold runtime sums across all 43 ClickBench queries confirm the same performance pattern seen with query 41:
-
MergeTree: With just 113 GiB of data processed across all queries, MergeTree is by far the most efficient, completing in only 28 seconds cold, a result of aggressive I/O reduction using the full stack of native optimizations. As expected.
-
Parquet: Despite currently lacking support for PREWHERE and lazy materialization, the current reader performs well. Thanks to metadata-based predicate pushdowns and high parallelism (up to 162 concurrent processing threads for a query), it completes the full 43-query workload in just 56 seconds cold, processing 468 GiB of data. That’s a substantial reduction from the 602 GiB that would have been scanned without any filtering if each of the 43 queries had read the full 14 GiB dataset from disk. While it’s nearly 2× slower than MergeTree (28 s cold), it still delivers fast performance for a file-based format, demonstrating the effectiveness of Parquet’s built-in optimizations like min/max stats and Bloom filters.
-
Other formats: Formats like Native, Arrow, CSV, and JSONEachRow show significantly higher I/O and slower runtimes, taking between 9 and 27 minutes cold to complete the full 43-query workload. These formats lack predicate pushdowns and ClickHouse-native I/O reduction features, typically requiring the entire dataset to be scanned and parsed. In comparison, that’s 10–30× slower than Parquet (56 s cold) and 20–60× slower than MergeTree (28 s cold).
Not shown in the chart above, but perhaps most notably, the ClickHouse query engine, when querying Parquet files directly, outperforms many popular data stores even when they query their own native formats. On identical hardware, engines like Postgres, Elasticsearch, MongoDB, MySQL, and others take significantly longer in both cold and hot runtimes to complete the same ClickBench workload over their preferred table layouts.
Wrapping up
This post took you deep inside the ClickHouse query engine to show how it queries Parquet, the columnar storage format that underpins open table formats like Iceberg and Delta Lake, and where its performance stands today.
We showed that the ClickHouse query engine is Lakehouse-ready, not just by design, but almost by accident. Its ability to query external files directly, without prior ingestion, has been a core capability from the start.
ClickHouse has been optimized for Parquet for years. Our goal is simple: make it the fastest engine in the world for querying Parquet at scale.
The current Parquet reader already delivers strong performance, applying parallelism across every layer, from file reads and parsing to filtering, sorting, and aggregation, and using metadata like min/max statistics and Bloom filters to skip unnecessary work.
The performance gap is real: ClickHouse already queries Parquet files directly faster than many popular systems do with their own native formats.
And it’s getting faster. A new native Parquet reader is on the way, bringing support for dictionary-based filtering, page-level min/max stats, and ClickHouse-specific optimizations like PREWHERE and lazy materialization.
Finally, we benchmarked Parquet alongside other file formats, and even against native MergeTree. It’s not a direct comparison (Parquet is a file format, MergeTree a purpose-built table engine), but it’s telling: our query engine’s performance over Parquet came closest to MergeTree. That makes ClickHouse not just fast for Parquet, it makes it a solid foundation for Lakehouse architectures.
This post is the first in a series. Next, we’ll explore how ClickHouse handles the higher layers of the Lakehouse stack. Yes, those layers already exist. ClickHouse isn’t getting ready for the Lakehouse, it’s already there. Stay tuned.
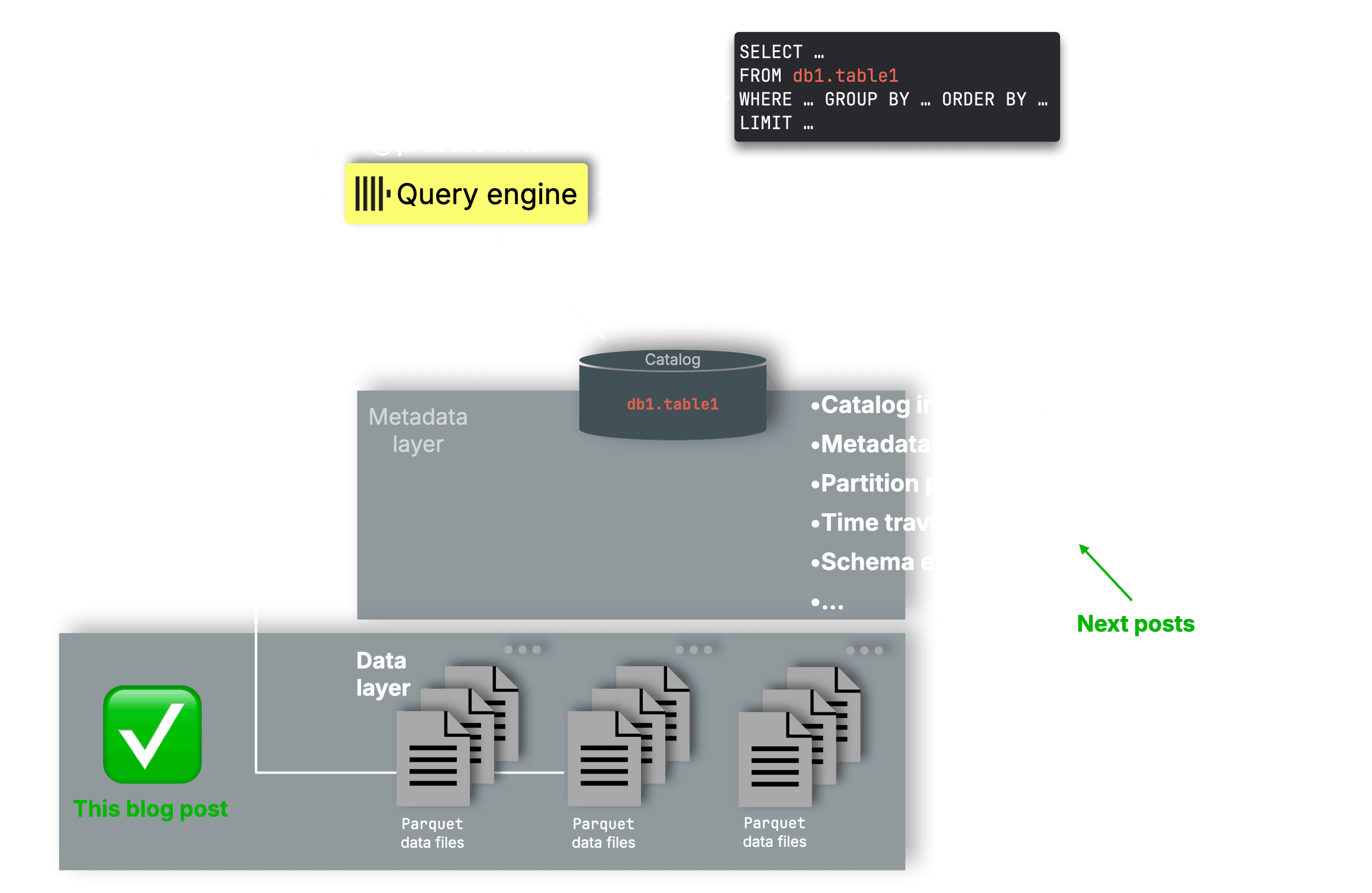




{kind=link}