Another month goes by, which means it’s time for another release!
ClickHouse version 25.2 brings 12 new features 🐣, 15 performance optimizations 🥚, and 72 bug fixes 🌷.
This release brings improved parallel hash join performance, Parquet bloom filter writing, transitive condition inference for queries, a backup database engine, delta rust kernel integration, and more!
New Contributors
A special welcome to all the new contributors in 25.2! The growth of ClickHouse's community is humbling, and we are always grateful for the contributions that have made ClickHouse so popular.
Below are the names of the new contributors:
Artem Yurov, Gamezardashvili George, Garrett Thomas, Ivan Nesterov, Jesse Grodman, Jony Mohajan, Juan A. Pedreira, Julian Meyers, Kai Zhu, Manish Gill, Michael Anastasakis, Olli Draese, Pete Hampton, RinChanNOWWW, Sameer Tamsekar, Sante Allegrini, Sergey, Vladimir Zhirov, Yutong Xiao, heymind, jonymohajanGmail, mkalfon, ollidraese
Hint: if you’re curious how we generate this list… here.
Faster parallel hash join
Contributed by Nikita Taranov
As part of our ongoing commitment to improving join performance, each release brings meticulous low-level optimizations. In the previous release, we optimized the probe phase of parallel hash joins. In this release, we revisited the build phase once more, eliminating unnecessary CPU thread contention for fully unthrottled performance.
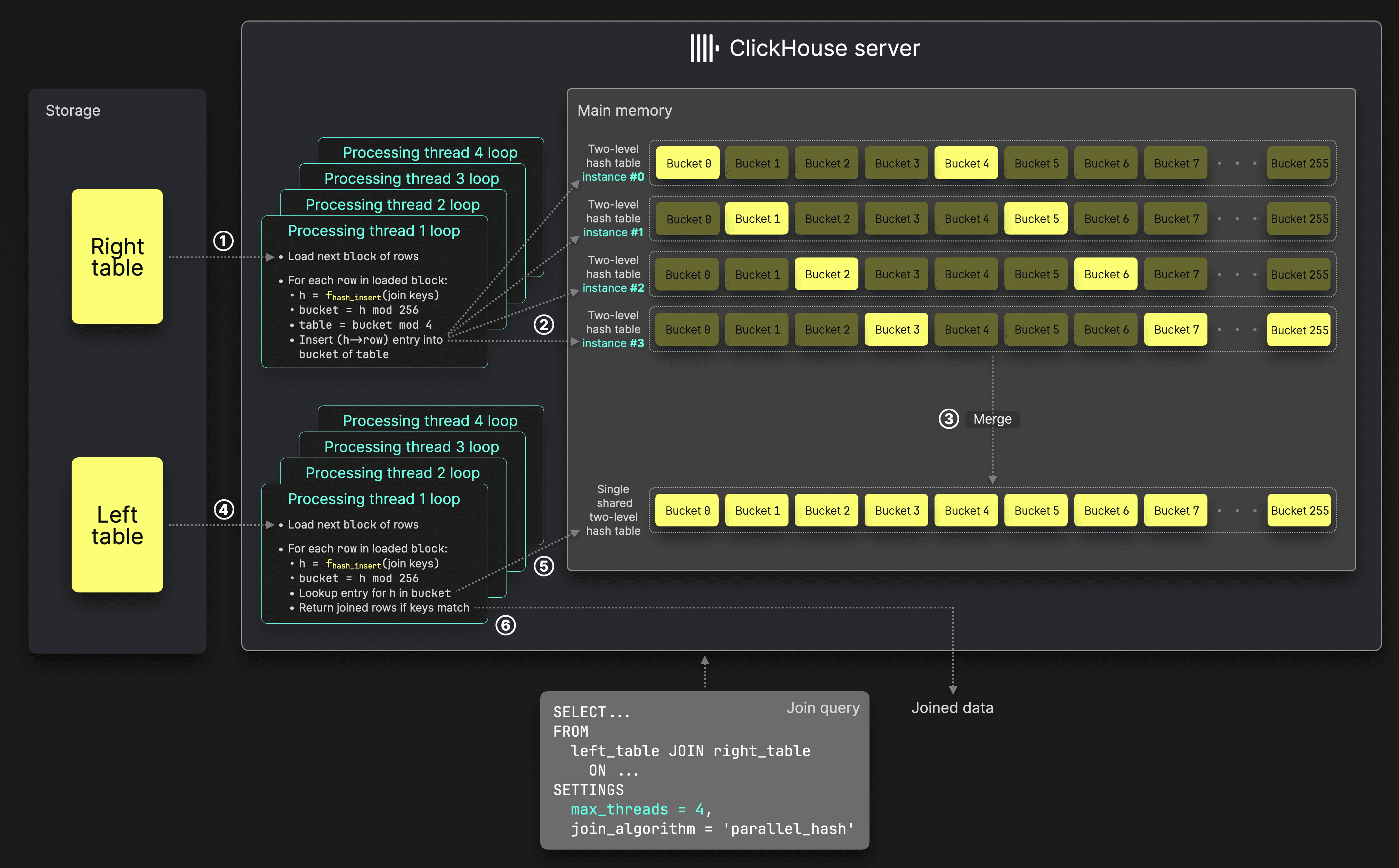
In our previous release post, we provided a detailed explanation of how the build and probe phases of the parallel hash join algorithm. As a reminder, during the build phase, N threads concurrently insert data from the right table of the join into N hash tables in parallel, row-block by row-block. Once that phase is complete, the probe phase begins, where N concurrent threads process rows from the left table, performing lookups into the hash tables populated during the build phase.
The value of N is determined by the max_threads setting, which defaults to the number of available CPU cores on the ClickHouse server executing the join.
Additionally, ClickHouse offers two settings to control the size of hash tables in hash-based joins: max_rows_in_join and max_bytes_in_join. By default, both are set to 0, allowing unlimited hash table size. These limits help manage memory usage during joins, preventing excessive allocation. If a limit is reached, users can configure ClickHouse to either abort with an exception (the default behavior) or return partial results based on the processed data.
The following diagram refers to the full diagram from the previous post and illustrates the parallel hash join’s build phase (with max_threads set to 4), highlighting where these size limits are enforced to control memory usage:

Each processing thread runs a loop:
① Load the next block of rows from the input table, and ② insert its rows into the hash tables as previously explained.
If ③ max_rows_in_join or max_bytes_in_join is set, the processing thread ④ retrieves the total row count and byte size from all hash table instances. To prevent concurrent modifications, the current processing thread locks the mutex of each hash table sequentially, making other threads wait until the count is complete. If the row count or byte size exceeds the thresholds, the join is aborted.
Until this version, the hash table size check in step ④ was always executed, even when no limit was set, causing threads to wait for each other and utilize only about 50% of CPU time.
With the new check in step ③, this contention is eliminated, allowing the parallel hash join to fully utilize all CPU cores and complete faster.
To better illustrate the improvement, we use a synthetic join query, which makes it easier to simulate a very large right-hand side table, focusing primarily on the build phase rather than the probe phase. Additionally, we prevent ClickHouse from automatically selecting the smaller table for the build phase by setting query_plan_join_swap_table to 0:
SELECT *
FROM
numbers_mt(100_000) AS left_table
INNER JOIN
numbers_mt(1_000_000_000) AS right_table
USING number
FORMAT Null
SETTINGS query_plan_join_swap_table = 0;Running this join query on ClickHouse 25.1 on our test machine with 32 CPU cores and 128 GB RAM, we observe via htop that all 32 cores are active, but none of the cores is fully utilized:

The query finishes in 12.275 seconds:
0 rows in set. Elapsed: 12.275 sec. Processed 1.00 billion rows, 8.00 GB (81.48 million rows/s., 651.80 MB/s.)
Peak memory usage: 64.25 GiB.Running the same join query on ClickHouse 25.2 on the same machine shows that the parallel hash join’s processing threads fully utilize all available CPU time across all 32 cores:

Therefore the query finishes faster in 6.345 seconds:
0 rows in set. Elapsed: 6.345 sec. Processed 1.00 billion rows, 8.00 GB (157.61 million rows/s., 1.26 GB/s.)
Peak memory usage: 64.07 GiB.Stay tuned for even more join performance improvements in the next release—and the ones after that!
Writing Bloom filters for Parquet
Contributed by Michael Kolupaev
This version sees the introduction of Bloom filters when writing Parquet files. From the Parquet documentation:
A Bloom filter is a compact data structure that overapproximates a set. It can respond to membership queries with either “definitely no” or “probably yes”, where the probability of false positives is configured when the filter is initialized. Bloom filters do not have false negatives.
Bloom filters work well when they can help filter out some row groups in the Parquet file that can’t be done by row group metadata.
Let’s see how it works using the hits dataset from the ClickBench benchmarking tool. We’ll first create a table using the command in the ClickBench repository.
Next, let’s download the following file:
wget --continue 'https://datasets.clickhouse.com/hits_compatible/hits.tsv.gz'
gzip -d hits.tsv.gzAnd ingest it into ClickHouse:
INSERT INTO hits
SELECT *
FROM file('hits.tsv');Next, we’ll export the data to a Parquet file that contains Bloom filters:
SELECT *
FROM hits
INTO OUTFILE 'hits.parquet'And now one without Bloom filters:
SELECT *
FROM hits
INTO OUTFILE 'hits_old.parquet'
SETTINGS output_format_parquet_write_bloom_filter = 0;Let’s have a look at the files that we’ve created on disk:
du -h *.parquet10G hits.parquet
9.1G hits_old.parquetThe Bloom filters have increased the file size by roughly 10%.
Let’s give it a try on a simple query that counts the number of rows for a given user:
SELECT count()
FROM file('hits_old.parquet')
WHERE UserID = 8511964386843448775;┌─count()─┐
1. │ 89 │
└─────────┘
1 row in set. Elapsed: 0.184 sec. Processed 60.28 million rows, 5.51 GB (327.86 million rows/s., 29.97 GB/s.)
Peak memory usage: 90.01 MiB.SELECT count()
FROM file('hits.parquet')
WHERE UserID = 8511964386843448775;┌─count()─┐
1. │ 89 │
└─────────┘
1 row in set. Elapsed: 0.123 sec. Processed 85.22 million rows, 8.30 GB (692.02 million rows/s., 67.40 GB/s.)
Peak memory usage: 87.37 MiB.This query has a 30-40% speed improvement. The speed improvement is better when the UserID matches fewer rows, possibly because those rows are spread out across fewer row groups, which means the query engine can ignore much of the Parquet file when querying.
Transitive conditions inference
Contributed by ShiChao Jin
Starting from version 25.2, ClickHouse supports transitive inference on comparison chains, meaning that for queries like WHERE a < b AND b < c AND c < 5, it will automatically deduce and utilize additional conditions (a < 5 AND b < 5) to enhance filtering efficiency.
This means the following query on the hits table (which is ordered by (CounterID, EventDate, UserID, EventTime, WatchID)) will use the primary key on the EventDate field.
select uniq(UserID)
FROM hits
WHERE LocalEventTime > '2013-07-09'
AND EventDate > LocalEventTime;┌─uniq(UserID)─┐
│ 2690891 │ -- 2.69 million
└──────────────┘Let’s first prefix the query with EXPLAIN indexes=1 in 25.1:
┌─explain───────────────────────────────────┐
│ Expression ((Project names + Projection)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Expression │
│ ReadFromMergeTree (default.hits) │
│ Indexes: │
│ PrimaryKey │
│ Condition: true │
│ Parts: 24/24 │
│ Granules: 12463/12463 │
└───────────────────────────────────────────┘We can see that the query engine scans all granules to compute a response.
How about 25.2?
┌─explain─────────────────────────────────────────────┐
│ Expression ((Project names + Projection)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Expression │
│ ReadFromMergeTree (default.hits) │
│ Indexes: │
│ PrimaryKey │
│ Keys: │
│ EventDate │
│ Condition: (EventDate in [15896, +Inf)) │
│ Parts: 3/3 │
│ Granules: 7807/12377 │
└─────────────────────────────────────────────────────┘This time, the primary key index is used to reduce the number of granules scanned,
This feature has been backported, so you'll have this functionality if you download the latest patch version for several versions.
Backup database engine
Contributed by Maksim Kita
ClickHouse now supports a Backup database engine. This lets us instantly attach tables/databases from backups in read-only mode.
To enable backups in ClickHouse, we’re going to include the following config file:
storage_configuration:
disks:
backups:
type: local
path: /tmp/
backups:
allowed_disk: backups
allowed_path: /tmp/config.d/backup_disk.yaml
We’re then going to backup a database that contains the hits table:
BACKUP DATABASE default
TO File('backup1')┌─id───────────────────────────────────┬─status─────────┐
1. │ 087a18a7-9155-4f72-850d-9eaa2034ca07 │ BACKUP_CREATED │
└──────────────────────────────────────┴────────────────┘We can now create a Backup table engine pointing at the backup location:
CREATE DATABASE backup
ENGINE = Backup('default', File('backup1'));We can list the tables like this:
SHOW TABLES FROM backup;And we can query it like this:
SELECT count()
FROM backup.hits
WHERE UserID = 8511964386843448775;┌─count()─┐
1. │ 89 │
└─────────┘
1 row in set. Elapsed: 0.034 sec. Processed 16.63 million rows, 133.00 MB (488.05 million rows/s., 3.90 GB/s.)
Peak memory usage: 475.41 KiB.Integration with the Delta Rust Kernel
Contributed by Kseniia Sumarokova
This version also sees a new implementation of Delta Lake support in ClickHouse with the help of a library from Databricks.
This is in experimental mode at the moment.
CREATE TABLE t
ENGINE = DeltaLake(
s3,
filename = 'xyz/',
url = 'http://minio1:9001/test/'
)
SETTINGS allow_experimental_delta_kernel_rs = 1;WithProgress formats for HTTP event streaming
Contributed by Alexey Milovidov
In 25.1, we introduced the JSONEachRowWithProgress and JSONStringsEachRowWithProgress output formats to improve support for streaming events over HTTP.
In 25.2, we added two more formats: JSONCompactEachRowWithProgress and JSONCompactStringsEachRowWithProgress.
These formats stream newline-delimited JSON events as soon as they appear, where each event is one of the following:
- progress
- meta
- row
- totals
- extremes
- exception
This fully supports chunked transfer encoding and HTTP compression (gzip, deflate, brotli, zstd).
Let’s have a look at these events by querying the hits table over the ClickHouse HTTP interface:
curl http://localhost:8123/ -d "SELECT CounterID, count() FROM hits GROUP BY ALL WITH TOTALS ORDER BY count() DESC LIMIT 10 FORMAT JSONCompactEachRowWithProgress"{"progress":{"read_rows":"99997497","read_bytes":"399989988","total_rows_to_read":"99997497","elapsed_ns":"30403000"}}
{"meta":[{"name":"CounterID","type":"Int32"},{"name":"count()","type":"UInt64"}]}
{"row":[3922, "8527070"]}
{"row":[199550, "7115413"]}
{"row":[105857, "5783214"]}
{"row":[46429, "4556155"]}
{"row":[225510, "4226610"]}
{"row":[122612, "3574170"]}
{"row":[244045, "3369562"]}
{"row":[233773, "2941425"]}
{"row":[178321, "2712905"]}
{"row":[245438, "2510103"]}
{"totals":[0, "99997497"]}
{"rows_before_limit_at_least":6506}Such events enable real-time result consumption as they arrive.
A good example is ClickHouse’s embedded Web UI (/play endpoint), now enhanced with:
- A real-time progress bar like in
clickhouse-client, updating as data arrives. - A dynamic result table, displaying results instantly in a streaming fashion.

Under the hood, the web ui uses the ClickHouse HTTP interface, instructing the server to stream results via the JSONStringsEachRowWithProgress format as observed for the query above by using the browser's web inspector:

We recommend watching Alexey’s demo in the last release webinar for a detailed walkthrough!




{kind=link}