Google BigQuery is a serverless cloud data warehouse that enables scalable analysis over petabytes of data. Well-integrated into the GCP ecosystem, BigQuery has been applied to a wide range of reporting and batch analytical use cases.
There is a growing number of scenarios where users need sub-second interactive performance on top of high-throughput streaming data sources. In working to meet these requirements, we increasingly see users deploying ClickHouse alongside BigQuery to speed up queries powering customer-facing applications and internal analytics. As a result, ClickHouse and BigQuery serve as complementary technologies to businesses building a modern analytics stack.
In this post, we explore options for synchronizing data between BigQuery and ClickHouse. This includes both moving data in bulk as well as continuously appending new data using BigQuery scheduled queries and Google DataFlow (a runner for Apache Beam). We also introduce you to basic data analytics using ClickHouse.
Comparing ClickHouse and BigQuery use cases #
BigQuery excels at delivering predictable performance on a diverse range of query access patterns over petabytes of data. Its ability to share compute, shuffle data, and spill to disk means even the most complex deep-analytical queries are served in an acceptable time for analysts and business reports. These capabilities are ideal for ad-hoc querying in low(er) queries-per-second (QPS) scenarios associated with classic data warehousing, especially when query access patterns are unknown or highly variable.
In contrast, ClickHouse is optimized for use cases that require:
- Sub-second analytical queries for user-facing applications, where the access patterns are known and predictable. This can sometimes be a subset of the data in Big Query or even the entire dataset for a set of focused analytical queries. Note that whilst never “slow”, BigQuery typically delivers performance in the order of seconds, making building dynamic real-time applications more challenging.
- Potentially unbounded queries per second as the application usage grows. ClickHouse is designed to serve queries with high concurrency and without enforced limits on the number of parallel queries.
- Support for high insert rates while still achieving low-latency concurrent queries on recent data, for which data warehouses like BigQuery have not traditionally been optimized.
These properties are commonly required in external or internal facing applications needing to surface near-real time analytics.
Pricing models can also be a factor in making technology choices. BigQuery charges for the amount of data scanned, which works well for ad-hoc analytical queries, but can be seen as costly for real-time analytical workloads. Instead, ClickHouse is open source and can be deployed on your own infrastructure, or hosted in ClickHouse Cloud which charges only based on consumed compute and storage. Note that some of these pricing challenges can be addressed by reserving BigQuery slots, but this requires high thresholds of usage not realistic for all users.
Setup & Dataset #
Examples in this blog post utilize ClickHouse Cloud, which has a free trial that allows the completion of the scenarios we cover. We utilize a publicly available cloud environment on sql.clickhouse.com, which has a total of 720 GB of memory and 180 vCPUs. All instructions are also compatible with self-managed ClickHouse deployments running the latest version (23.1).
We use the Ethereum Cryptocurrency dataset available in BigQuery’s public project for our dataset. We defer exploring this dataset in detail to a later blog post, but recommend reading Google’s blog on how this was constructed and the subsequent post on querying this and other crypto datasets. No prior experience with crypto is required for reading this blog post, but for those interested, the Introduction to Ethereum provides a useful overview. Google has documented a number of great queries on top of this dataset, which we reference later in the blog, and we have collated equivalent ClickHouse queries here and welcome contributions.
In summary, our dataset consists of 4 tables. This is a subset of the full data but is sufficient for most common questions:
- Blocks - Blocks are batches of transactions with a hash of the previous block in the chain.
- Transactions - Transactions are cryptographically signed instructions from accounts. An account will initiate a transaction to update the state of the Ethereum network, e.g. transferring ETH from one account to another.
- Traces - Internal transactions that allow querying all Ethereum addresses with their balances.
- Contracts - A "smart contract" is simply a program that runs on the Ethereum blockchain.
For users wanting to bypass BigQuery to insert this dataset, it can be generated using the excellent Ethereum ETL tooling for which a PR has been submitted supporting ClickHouse as a destination. The above tables represent a subset and address the most common queries while providing significant volume. Alternatively, this data is available in BigQuery’s public project - users only pay for querying this data, according to the data scanned, with 1TB free per month. This data is continuously updated and maintained by Google, with updates typically only 4 minutes behind the live blockchain. To allow users to reproduce examples, we have made this data available in sql.clickhouse.com for querying as well as in the public bucket gs://clickhouse_public_datasets/ethereum.
Assumptions #
When selecting which data to store in ClickHouse vs BigQuery, we typically see users identifying the most commonly utilized queries that would be used by a real-time analytics application. For streaming analytical data, this usually constitutes a subset of the data based on a time dimension.
For the remainder of this blog, we make the following assumptions:
- Data is continuously generated and stored in BigQuery, with a requirement to continuously stream new rows to ClickHouse.
- Data is append-only and immutable. There is no requirement to selectively update rows, though dropping older data is expected and described below.
- Either a time dimension or an incrementing numeric identifier exists on the data that allows new rows for copying to ClickHouse to be identified.
Ethereum Blockchain data inherently satisfies these properties. In our case, we utilize the block timestamp. Below we address both migrating the historical data from Big Query to ClickHouse, as well handling appending new data continuously.
Differences between BigQuery and ClickHouse Data Types and Schemas #
Users moving data between ClickHouse and BigQuery will immediately notice that ClickHouse offers more granular precision with respect to numerics. For example, BigQuery offers the numeric types INT64, NUMERIC, BIGNUMERIC and FLOAT64. Contrast these with ClickHouse, which offers multiple precisions for decimals, floats, and ints. With these, ClickHouse users can optimize storage and memory overhead, resulting in faster queries and lower resource consumption. Below we map the equivalent ClickHouse type for each BigQuery type:
| BigQuery | ClickHouse |
|---|---|
| ARRAY | Array(t) |
| NUMERIC | Decimal(P, S), Decimal32(S), Decimal64(S), Decimal128(S) |
| BIG NUMERIC | Decimal256(S) |
| BOOL | Bool |
| BYTES | FixedString |
| DATE | Date32 (with narrower range) |
| DATETIME | DateTime, DateTime64 (narrow range, higher precision) |
| FLOAT64 | Float64 |
| GEOGRAPHY | Geo Data Types |
| INT64 | UInt8, UInt16, UInt32, UInt64, UInt128, UInt256, Int8, Int16, Int32, Int64, Int128, Int256 |
| INTERVAL | NA supported as expression or through functions |
| JSON | JSON |
| STRING | String (bytes) |
| STRUCT | Tuple, Nested |
| TIME | DateTime64 |
| TIMESTAMP | DateTime64 |
When presented with multiple options for ClickHouse types, consider the actual range of the data and pick the lowest required. Also, consider utilizing appropriate codecs for further compression.
The current schema for a BigQuery table can be retrieved with the following query:
SELECT table_name, ddl FROM `bigquery-public-data`.crypto_ethereum.INFORMATION_SCHEMA.TABLES
WHERE table_name = 'blocks';
The original BigQuery schemas can be found here. Using the results from the above queries, we can create a ClickHouse table with appropriate types based on the known ranges of each column. You can run an additional query to identify the data range and cardinality, for example:
SELECT
MAX(number) AS max_number,
MIN(number) AS min_number,
MAX(size) AS max_size,
MIN(size) AS min_size
FROM bigquery-public-data.crypto_ethereum.blocks
max_number min_number max_size min_size
16547585 0 1501436 514
We make some basic optimizations to these schemas with appropriate types and codecs to minimize storage, but leave a full analysis to a later blog dedicated to this dataset. The schema for blocks:
CREATE TABLE ethereum.blocks
(
`number` UInt32 CODEC(Delta(4), ZSTD(1)),
`hash` String,
`parent_hash` String,
`nonce` String,
`sha3_uncles` String,
`logs_bloom` String,
`transactions_root` String,
`state_root` String,
`receipts_root` String,
`miner` String,
`difficulty` Decimal(38, 0),
`total_difficulty` Decimal(38, 0),
`size` UInt32 CODEC(Delta(4), ZSTD(1)),
`extra_data` String,
`gas_limit` UInt32 CODEC(Delta(4), ZSTD(1)),
`gas_used` UInt32 CODEC(Delta(4), ZSTD(1)),
`timestamp` DateTime CODEC(Delta(4), ZSTD(1)),
`transaction_count` UInt16,
`base_fee_per_gas` UInt64
)
ENGINE = MergeTree
ORDER BY timestamp
The other table schemas can be found here. Note that we don’t make our columns Nullable, despite them being so in the original BigQuery schema. For most queries, there is no need to distinguish between the default value and the Null value. By using default values, we avoid Nullable's additional UInt8 column overhead. We have also selected primary keys for these tables to optimize expected queries. Finally, given that BigQuery charges for data storage based on either the physical or logical size, it is worth recording the sizes of these respective tables. This information can be obtained from either the UI when selecting on the table and inspecting the details, or with a simple query:
SELECT
table_name, total_rows, round(total_physical_bytes / power(1024, 3),2) as total_physical_gb, round(total_logical_bytes /power(1024, 3),2) as total_logical_gb
FROM
`<project id>.region-<region>.INFORMATION_SCHEMA.TABLE_STORAGE` WHERE table_name IN ('transactions', 'contracts', 'blocks', 'traces') AND table_schema='crypto_ethereum'
Note that this query cannot be executed on the bigquery-public-data project and requires the tables to be copied to your own project.
This table shows dataset statistics as stored in BigQuery captured on 1st February 2023. BigQuery “physical” and “logical” sizes are broadly equivalent to ClickHouse “compressed” and “uncompressed” sizes, respectively.
| table_name | total_rows | total_physical_gb | total_logical_gb |
|---|---|---|---|
| transactions | 1,852,951,870 | 332.62 | 695.99 |
Bulk loading via Google Cloud Storage (GCS) #
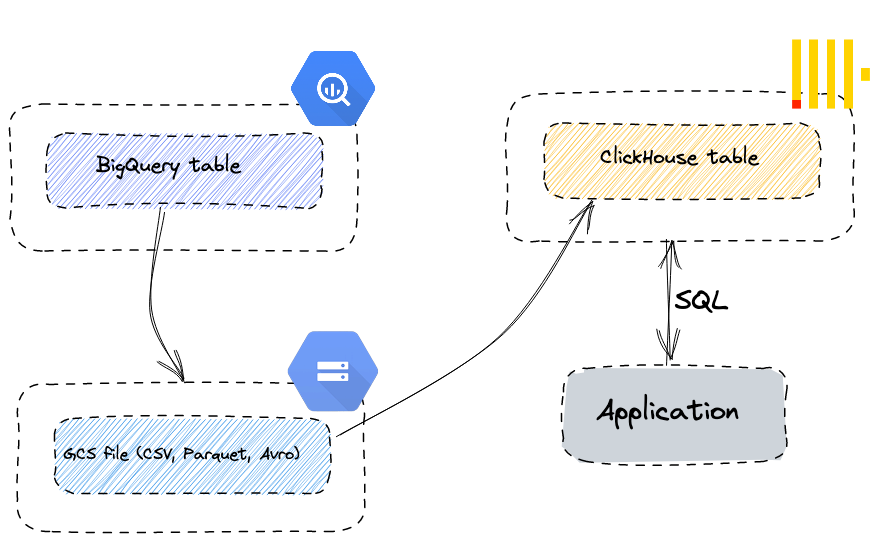
BigQuery supports exporting data to Google's object store (GCS). In this example, export public tables blocks, traces, transactions, and contracts to GCS, and then import the data into ClickHouse Cloud. We use the s3 table function since GCS is interoperable with Amazon’s Simple Storage Service (S3). This approach has a number of advantages:
- BigQuery export functionality supports a filter for exporting a subset of data.
- BigQuery supports exporting to Parquet, Avro, JSON, and CSV formats and several compression types - all supported by ClickHouse.
- GCS supports object lifecycle management, allowing data that has been exported and imported into ClickHouse to be deleted after a specified period.
- Google allows up to 50TB per day to be exported to GCS for free. Users only pay for GCS storage.
- Exports produce multiple files automatically, limiting each to a maximum of 1GB of table data. This is beneficial to ClickHouse since it allows imports to be parallelized.
Before trying the following examples, we recommend users review the permissions required for export and locality recommendations to maximize export and import performance.
Exporting Data to GCS #
For our example, we utilize the BigQuery SQL interface - see alternatives such as bq here. Below we export the blocks table to a specified GCS bucket using the EXPORT DATA statement. While in the example below, we export the entire dataset, the SELECT statement allows a subset to be potentially exported.
EXPORT DATA
OPTIONS (
uri = 'gs://clickhouse_public_datasets/ethereum/blocks/*.csv.gz',
format = 'CSV',
compression = 'GZIP',
overwrite = true,
header = true,
field_delimiter = ',')
AS (
SELECT *
FROM bigquery-public-data.crypto_ethereum.blocks
ORDER BY number ASC
);
We export to CSV and request the files be compressed using GZIP. For the block data, this can take around 1 minute. We also have a * character in our uri parameter. This ensures the output is sharded into multiple files, with a numerically increasing suffix, should the export exceed 1GB of data.
Importing Data into ClickHouse from GCS #
Once the export is complete, we can import this data into a ClickHouse table. Note we pre-create the table before running the following INSERT INTO the blocks table.
SET parallel_distributed_insert_select = 1
INSERT INTO blocks
SELECT number, hash, parent_hash, nonce, sha3_uncles, logs_bloom, transactions_root, state_root, receipts_root, miner, difficulty, total_difficulty, size, extra_data, gas_limit, gas_used, timestamp, transaction_count, base_fee_per_gas
FROM s3Cluster('default', 'https://storage.googleapis.com/clickhouse_public_datasets/ethereum/blocks/*.gz', 'CSVWithNames', 'timestamp DateTime, number Int64, hash String, parent_hash String, nonce String, sha3_uncles String, logs_bloom String, transactions_root String, state_root String, receipts_root String, miner String, difficulty Decimal(38, 0), total_difficulty Decimal(38, 0), size Int64, extra_data String, gas_limit Int64,gas_used Int64,transaction_count Int64,base_fee_per_gas Int64')
0 rows in set. Elapsed: 22.712 sec. Processed 16.54 million rows, 19.52 GB (728.29 thousand rows/s., 859.50 MB/s.)
We utilize the s3Cluster function, which is the distributed variant of the s3 function and allows the full cluster resources in ClickHouse Cloud to be utilized for reading and writing. The setting parallel_distributed_insert_select=1 ensures that insertion is parallelized and data is inserted into the same node from which it is read (skipping the initiator node on writes).
In the above example, we don’t provide authentication keys as the bucket is public. Using private buckets is supported, if the user generates HMAC keys for the bucket - either at a service or user level. The Access key and Secret can be substituted for the aws_access_key_id, aws_secret_access_key, respectively. In the secure example below we query the data in place - a typical access pattern for adhoc analysis:
SELECT max(number) AS max_block_number
FROM s3('https://storage.googleapis.com/clickhouse_public_datasets/ethereum/blocks/*.csv.gz', 'CSVWithNames')
┌─max_block_number─┐
│ 16542640 │
└──────────────────┘
1 row in set. Elapsed: 15.926 sec. Processed 16.54 million rows, 148.88 MB (1.04 million rows/s., 9.35 MB/s.)
The above use of CSV is suboptimal as an exchange format. Parquet, as a column-oriented format, represents a better interchange format since it is inherently compressed and faster for BigQuery to export and ClickHouse to query. If using Parquet, you will need to map Nullable columns to non-Null equivalents due to the above schema choices (or use Nullable columns in ClickHouse). For example, below we use the ifNull function to map null values of base_fee_per_gas to 0. Additional compression algorithms available, when exporting to Parquet may improve the process further, but we will leave this exercise to the reader.
INSERT INTO blocks
SELECT number, hash, parent_hash, nonce, sha3_uncles, logs_bloom, transactions_root, state_root, receipts_root, miner, difficulty, total_difficulty, size, extra_data, gas_limit, gas_used, timestamp, transaction_count, ifNull(base_fee_per_gas, 0) AS base_fee_per_gas
FROM s3Cluster('default', 'https://storage.googleapis.com/bigquery_ethereum_export/blocks/*.parquet', 'GOOGR2DYAAX6RVODIMREAVPB', '+tNQdQQ0DCEItWQlJseXcidKSG6pOU65o1r0N17O')
We repeated the above exercise for each of our tables, recording the timings below using Parquet format. Using this method, we were able to transfer 4TB from BigQuery to ClickHouse in less than an hour!
| Table | Rows | Files Exported | Data Size | BigQuery Export | Slot Time | ClickHouse Import |
|---|---|---|---|---|---|---|
| blocks | 16,569,489 | 73 | 14.53GB | 23 secs | 37 min | 15.4 secs |
| transactions | 1,864,514,414 | 5169 | 957GB | 1 min 38 sec | 1 day 8hrs | 18 mins 5 secs |
| traces | 6,325,819,306 | 17,985 | 2.896TB | 5 min 46 sec | 5 days 19 hr | 34 mins 55 secs |
| contracts | 57,225,837 | 350 | 45.35GB | 16 sec | 1 hr 51 min | 39.4 secs |
| Total | 8.26 billion | 23,577 | 3.982TB | 8 min 3 sec | > 6 days 5 hrs | 53 mins 45 secs |
ClickHouse storage efficiency vs. BigQuery #
As shown below, ClickHouse achieves around 8x compression, improving upon BigQuery storage efficiency by up to 30%.
SELECT table,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,
round(sum(data_uncompressed_bytes) / sum(data_compressed_bytes), 2) AS ratio
FROM system.columns
WHERE database = 'ethereum'
GROUP BY table
ORDER BY sum(data_compressed_bytes) DESC
┌─table────────┬─compressed_size─┬─uncompressed_size─┬─ratio─┐
│ traces │ 509.39 GiB │ 3.85 TiB │ 7.74 │
│ transactions │ 228.52 GiB │ 1.14 TiB │ 5.09 │
│ blocks │ 5.37 GiB │ 15.62 GiB │ 2.92 │
│ contracts │ 2.98 GiB │ 15.78 GiB │ 5.3 │
└──────────────┴─────────────────┴───────────────────┴───────┘
Summarizing below, we can see ClickHouse achieves around 30% better compression than BigQuery.
| Table | BigQuery Logical Size | BigQuery Physical Size | BigQuery Compression Ratio | ClickHouse UnCompressed Size | ClickHouse Compressed Size | ClickHouse Compression Ratio |
|---|---|---|---|---|---|---|
| transactions | 695.99 GB | 332.62 GB | 2.09 | 1.14TiB | 228.52 GB | 5.09 |
| blocks | 17.05 GB | 6.25 GB | 2.73 | 15.62GB | 5.37 GB | 2.92 |
| traces | 4212.71 GB | 738.45 GB | 5.7 | 3.85 TiB | 509.39 GB | 7.74 |
| contracts | 51.33 GB | 3.54 GB | 14.5 | 15.78 GB | 2.98 GB | 5.3 |
Using Scheduled Queries #
The above approach works well for bulk data loading, which is good for development and experimentation. But it does not address the fact that our BigQuery tables are receiving new data. So for production, we need another approach, which handles appending new data continuously.
Scheduling Data Export #
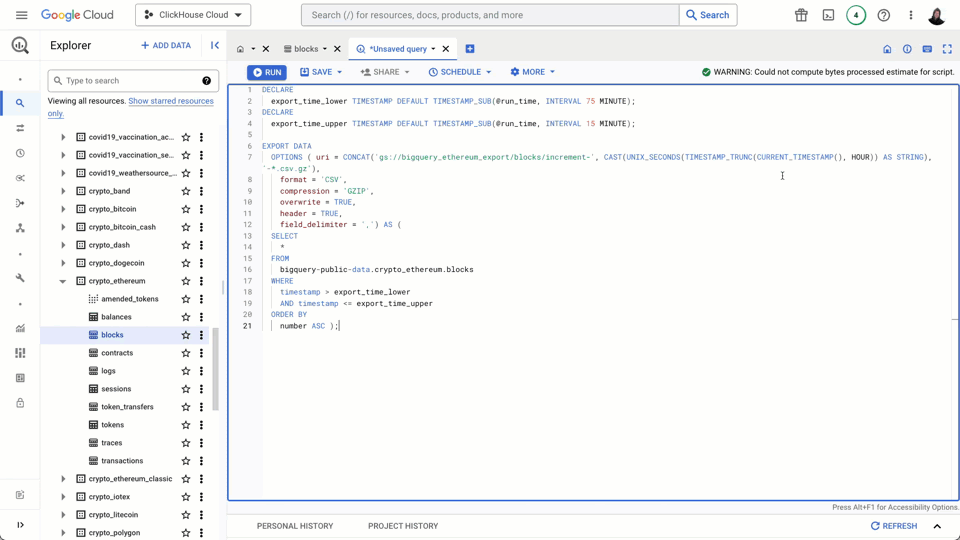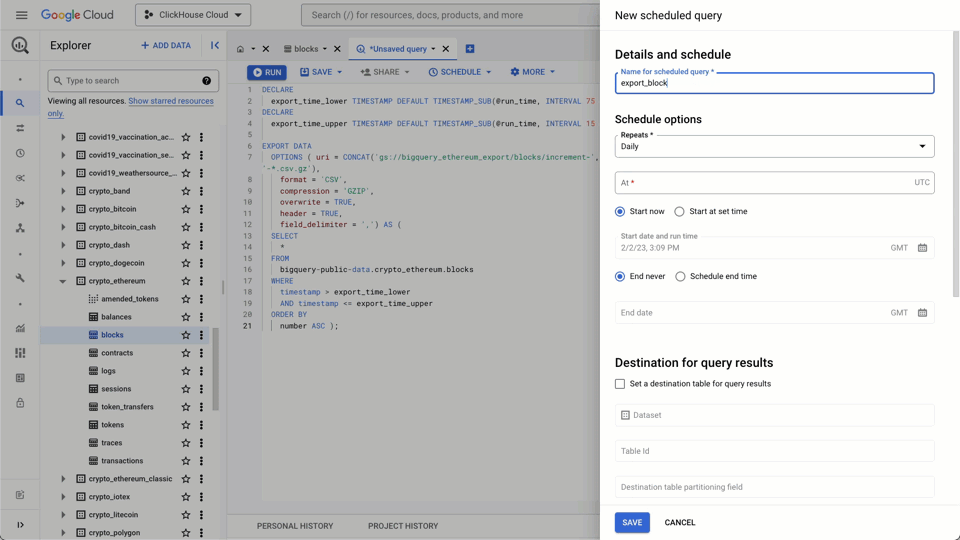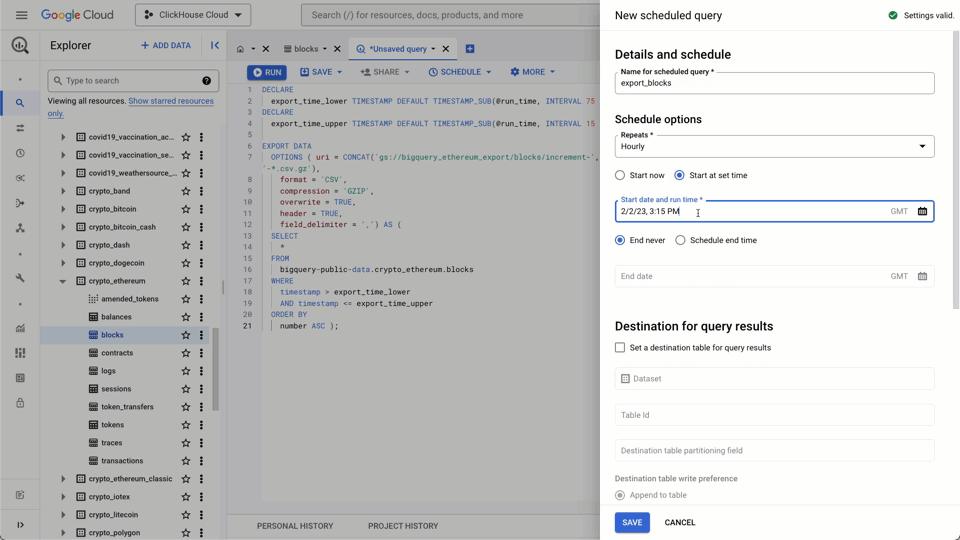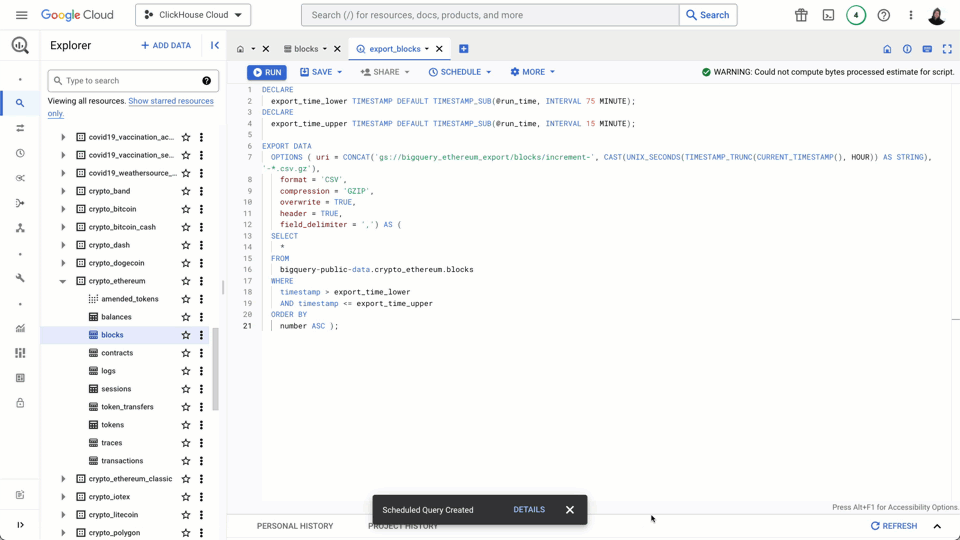
One approach is to simply schedule a periodic export using Big Query’s scheduled query functionality. Provided you can accept some delay in the data being inserted into ClickHouse, this approach is easy to implement and maintain.
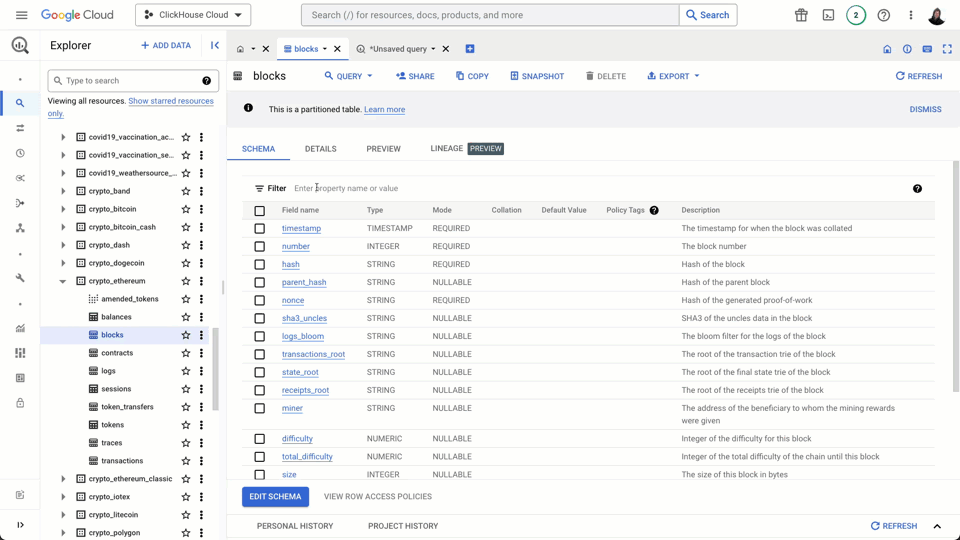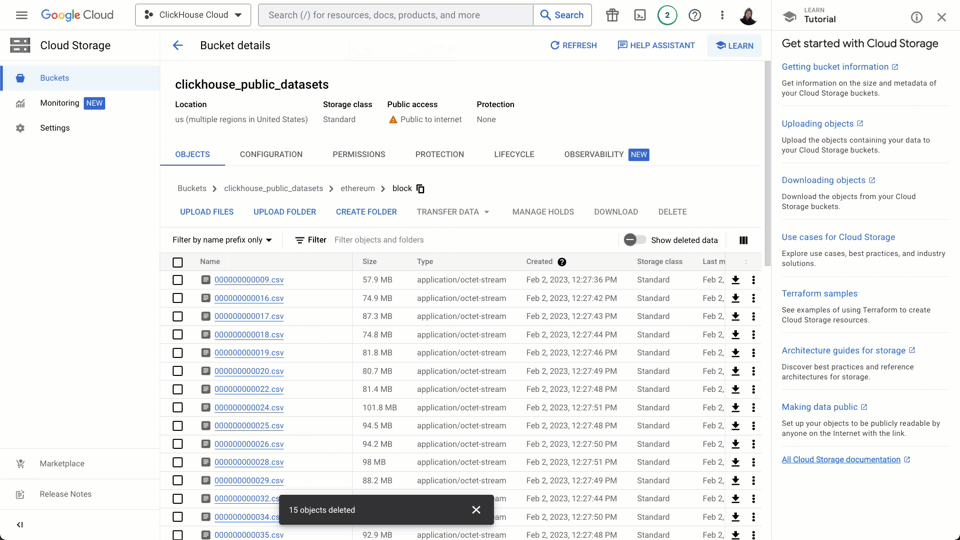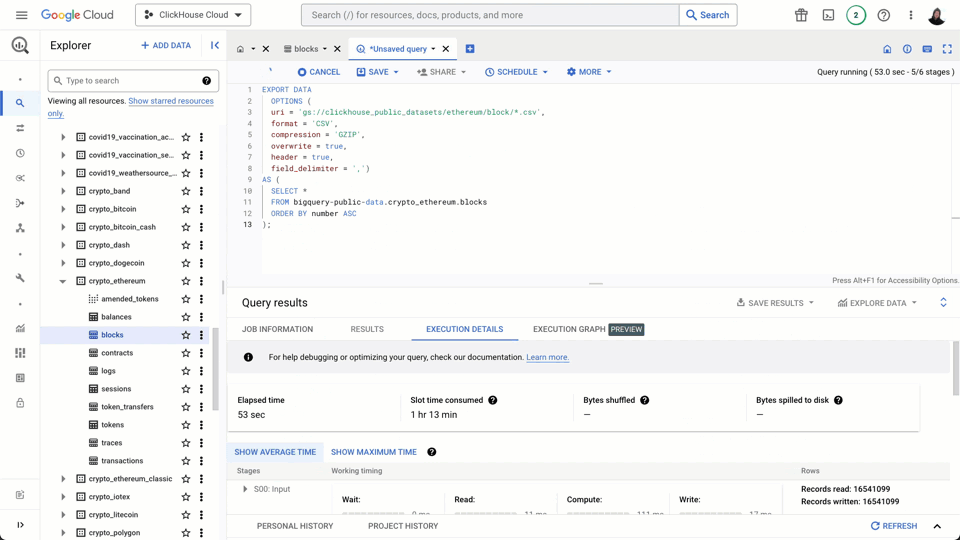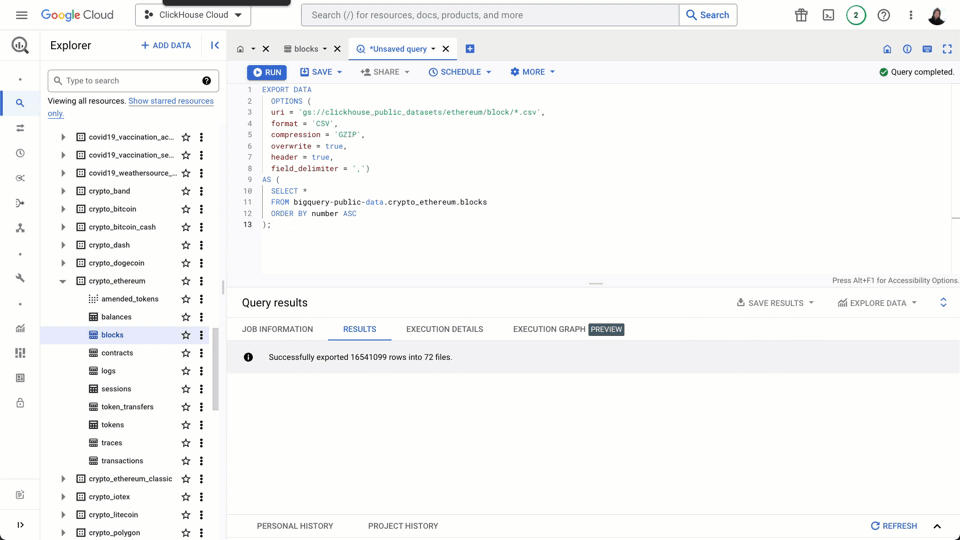
For our example, we will schedule our export every hour. Every hour, we export the last 60 minutes of data. However, we offset this window to allow for a delay in blocks being committed to the blockchain and appearing in BigQuery. Typically this doesn’t exceed more than 4 minutes, we utilize 15 minutes to be safe. Every time we run an export, we are therefore exporting all rows from now-75mins to now-15mins. This is visualized below:
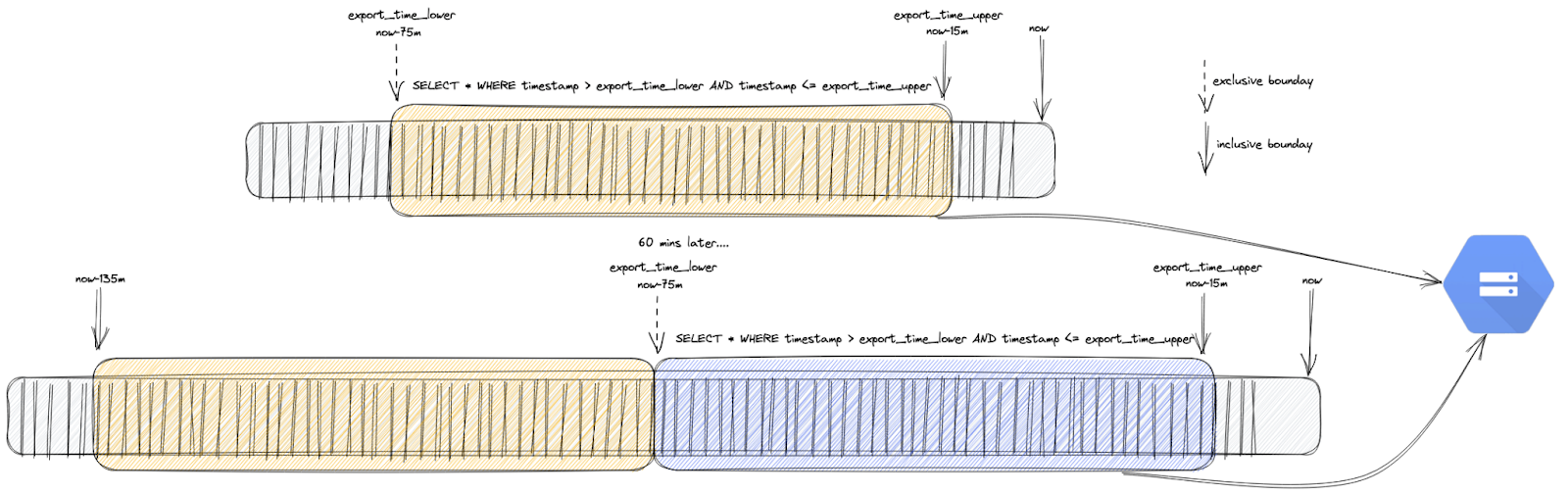
In order to make sure that our window queries do not miss any data, we need to key our interval calculation off scheduled time, available via a variable called [run_time](https://cloud.google.com/bigquery/docs/scheduling-queries), as opposed to execution time, which may vary slightly.
We can now schedule the following query to run every hour to export the Ethereum block data. Ensure you schedule your first export job to start at least 75 minutes after your import to avoid duplicates!
DECLARE
export_time_lower TIMESTAMP DEFAULT TIMESTAMP_SUB(@run_time, INTERVAL 75 MINUTE);
DECLARE
export_time_upper TIMESTAMP DEFAULT TIMESTAMP_SUB(@run_time, INTERVAL 15 MINUTE);
EXPORT DATA
OPTIONS ( uri = CONCAT('gs://clickhouse_public_datasets/ethereum/blocks/increment-', CAST(UNIX_SECONDS(TIMESTAMP_TRUNC(CURRENT_TIMESTAMP(), HOUR)) AS STRING), '*.parquet'),
format = 'PARQUET', overwrite = true) AS (
SELECT
*
FROM
bigquery-public-data.crypto_ethereum.blocks
WHERE
timestamp > export_time_lower
AND timestamp <= export_time_upper
ORDER BY
number ASC );
This incremental export completes much faster (a few minutes in most cases), because BigQuery tables, partitioned by the timestamp column, enable these filtering clauses to run quickly.
A few details about the query syntax:
- The above query only exports blocks. The equivalent queries for the other tables are very similar, except the column
block_timestampwas used instead oftimestamp. - Export files have an
increment-prefix. This allows us to target only incremental files during import (see below). - We include the current time as epoch seconds in the filename, using the expression
CAST(UNIX_SECONDS(TIMESTAMP_TRUNC(CURRENT_TIMESTAMP(), HOUR)) AS STRING). This allows us to target specific files during import (see below).
Scheduling Data Import #
At the time of writing, ClickHouse does not have a built-in way of scheduling imports (proposal is in discussion), but we can schedule this import using an external job. This can be achieved in a number of ways – using lambda functions, Cloud Run, or even incremental materializations in dbt – but for simplicity of demonstration, we use a simple cron.
The following bash script can be run by a cron job periodically after exports are completed. This example handles the blocks table, but can easily be adapted to the other tables.
#!/bin/bash
max_date=$(clickhouse-client --query "SELECT toInt64(toStartOfHour(toDateTime(max(block_timestamp))) + toIntervalHour(1)) AS next FROM ethereum.transactions");
clickhouse-client --query "INSERT INTO blocks SELECT number, hash, parent_hash, nonce, sha3_uncles, logs_bloom, transactions_root, state_root, receipts_root, miner, difficulty, total_difficulty, size, extra_data, gas_limit, gas_used, timestamp, transaction_count, ifNull(base_fee_per_gas, 0) AS base_fee_per_gas
FROM s3(''https://storage.googleapis.com/clickhouse_public_datasets/ethereum/blocks/increment-' || toString(${max_date}) || '-*.parquet')"
The first line here identifies the current max time for the data in ClickHouse. We round this to the hour using the toStartOfHour function and add one hour before converting the value to an Int64. This gives us an epoch seconds value. When appended with our increment- prefix this identifies the file for the current hour when the cron job executes. The next line performs a simple import of this file into the table using the s3 function.
An alternative to this approach would be to import all increment-* rows containing data with a timestamp greater than max_date i.e., WHERE timestamp > ${max_date}. This would, however, require us to scan all incremental files. While initially fast, this is subject to performance degradation over time as the number of files increases.
Filling gaps #
If we perform the bulk import and then schedule the above import and export queries, we will invariably have a “gap” in our data for the period between the bulk load completion and the incremental load starting. Note again the importance of scheduling the incremental export to start 75 minutes after the import of the bulk data to avoid duplicates.
This gap is easily addressed with the following steps. We outline these for the blocks dataset, but the process is the same for the other tables using the block_timestamp column. Note that we do this before loading the incremental data into ClickHouse.
- Identify the lower bound of our “gap” by querying for the max timestamp of the data in ClickHouse.
SELECT max(timestamp)
FROM blocks
┌──────max(timestamp)─┐
│ 2023-02-02 13:34:11 │
└─────────────────────┘
- Assuming the above query has been scheduled and an incremental import has been completed, identify the minimum timestamp in the exported files, i.e., the upper bound of our “gap”.
SELECT min(timestamp)
FROM s3('https://storage.googleapis.com/bigquery_ethereum_export/blocks/increment-*.parquet')
┌─────────────min(timestamp)─┐
│ 2023-02-02 14:22:47.000000 │
└────────────────────────────┘
- Export the data between the time ranges identified in (2). Utilize a prefix that allows them to be easily identified, e.g.,
gap.
EXPORT DATA
OPTIONS ( uri = CONCAT('gs://bigquery_ethereum_export/blocks/gap-*.parquet'),
format = 'PARQUET',
overwrite = TRUE) AS (
SELECT * FROM
bigquery-public-data.crypto_ethereum.blocks
WHERE
timestamp > '2023-02-02 13:34:11' AND timestamp < '2023-02-02 14:22:47'
ORDER BY
number ASC );
- Import these files into the table using the correct
gap-prefix.
INSERT INTO blocks SELECT number, hash, parent_hash, nonce, sha3_uncles, logs_bloom, transactions_root, state_root, receipts_root, miner, difficulty, total_difficulty, size, extra_data, gas_limit, gas_used, timestamp, transaction_count, ifNull(base_fee_per_gas, 0) AS base_fee_per_gas
FROM s3('https://storage.googleapis.com/bigquery_ethereum_export/blocks/gap-*.parquet')
Handling Failures #
The above approach requires manual intervention if exports fail. The import job is more robust and will never import the same file multiple times. If the latest file is imported, or the current hour file has failed to export, no operation is performed. Should exports fail and then be fixed, this script can be run as many times as required to fill the missing hours and catch up.
In its current form, the earlier script means Ethereum data in ClickHouse is at most 85 minutes behind the blockchain - assuming we execute our cron 10 minutes after the incremental export finishes. We could adapt our above process, reducing exports to minutes. This would require us to adapt our above import script, likely using a filter - an exercise left to the reader, or consider another tool…
Using Dataflow for Streaming Data between BigQuery and ClickHouse #
Google Cloud Dataflow is a fully managed service (a Runner) for executing Apache Beam pipelines within the Google Cloud Platform ecosystem. Apache Beam is an open-source unified programming model (developed by Google) to define and execute data processing pipelines, including ETL, batch, and stream (continuous) processing. Based on the Dataflow model paper, Dataflow allows users to develop pipelines in either Python, Go or Java and deploy these to GCE to run. These pipelines consist of I/O connectors that connect to data sources and provide read (source) and write (sink) operations, as well as transform operations that facilitate data processing. The key is this framework provides primitives that allow these pipelines and their operations to be executed in parallel in either a batch or a streaming manner. We strongly recommend users read the basic concepts if interested in this approach.
While other datasets may need more transformational logic, we simply want to stream data between BigQuery and ClickHouse. Other than grouping rows into batches (for efficient ClickHouse insertion), no other transformations are required. BigQuery is supported by a core I/O connector which provides a simple source interface for reading rows. ClickHouse is supported in Apache Beam through an official IO connector for the Java SDK only. Currently, this only offers sink support and requires the target table to exist. While the python SDK does not have built-in support for ClickHouse, Beam provides an easy way to write a sink connector via a ParDo transform. Apache Beam’s support for external libraries allows us to use the ClickHouse python client to perform the insertion to ClickHouse. Finally, a simple BatchElements transformation allows us to produce group rows before insertion into ClickHouse. We show the important parts of a basic implementation below to show the potential of this approach. Full example here.
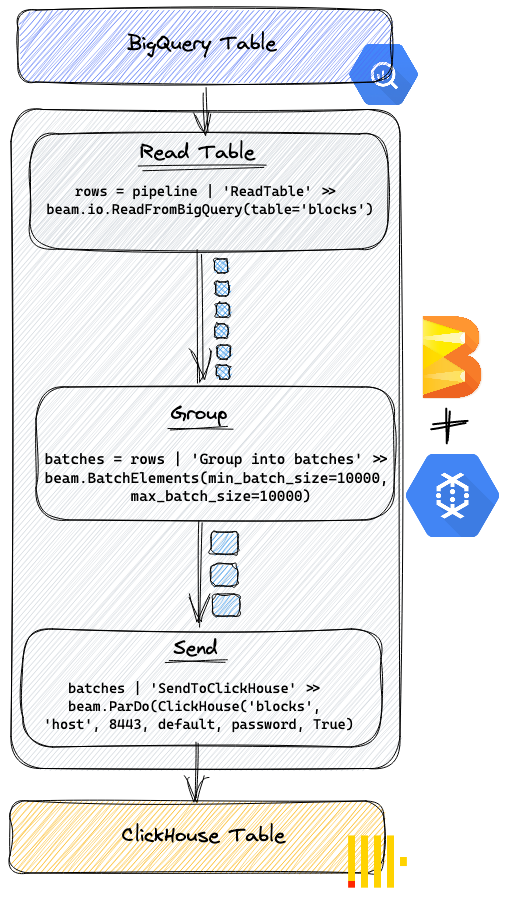
Executing this pipeline to migrate the blocks table would require the python code to be run as shown below. This assumes you have configured your machine to use Google Dataflow and have the required permissions:
python -m sync_clickhouse --target_table ethereum.blocks --clickhouse_host <clickhouse_host> --clickhouse_password <password> --region us-central1 --runner DataflowRunner --project <GCE project> --temp_location gs://<bucket> --requirements_file requirements.txt
Note the need to also provide the dependencies via a requirements.txt and a GCS bucket in which data can be cached, as the BigQuery connector works by exporting data to a bucket and using this as an intermediary store - a bit like our earlier approach. The GCE console provides a nice visualization of the process.
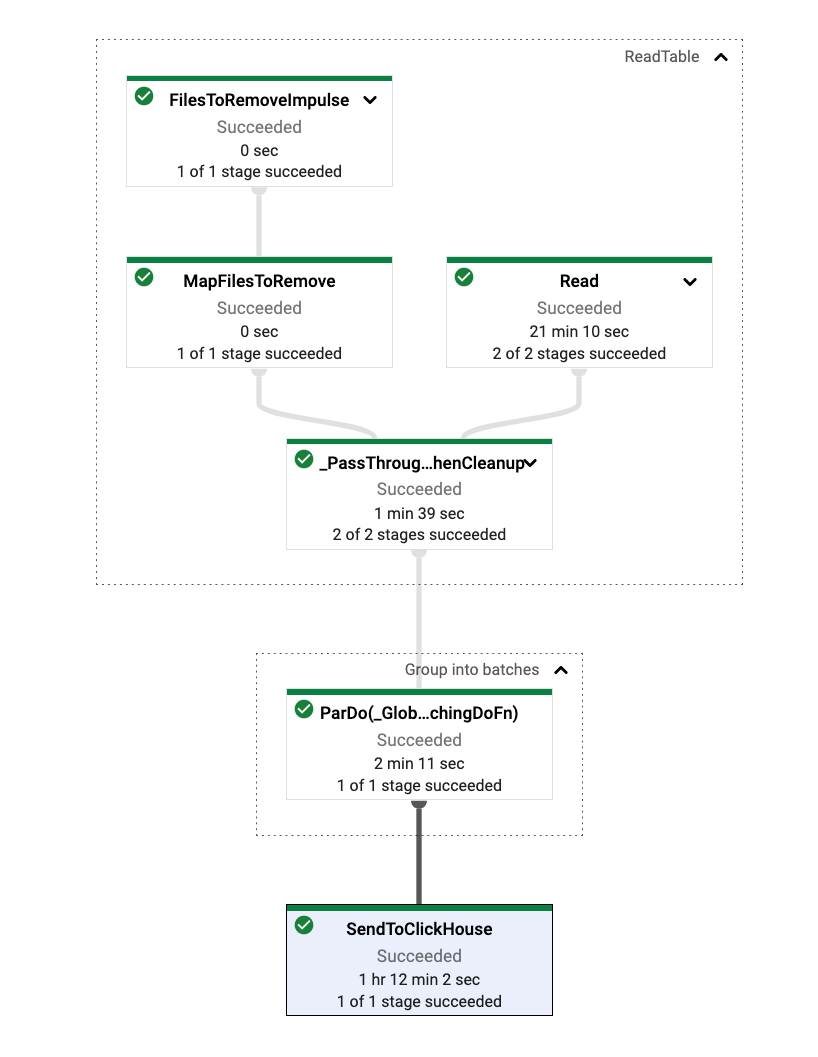
The above approach has the following limitations, and we leave these improvements as an exercise for the reader:
- Ideal solution would utilize a streaming pipeline that runs forever as more data is added to the source. However, a streaming pipeline requires an unbounded source, and since the BigQuery source is bounded, it cannot be used in streaming pipelines. Instead, we use a batch pipeline runs until completion based on a snapshot and then stops. The easiest solution here is to have the pipeline identify the current max timestamp in ClickHouse on start, and use this as filter criteria to BigQuery. The pipeline can then easily be scheduled to run using Cloud Scheduler.
- Our ClickHouse connector has to structure the rows into a 2-dimensional array for use with the ClickHouse python client. This work could also be done as a parallelized ParDo.
- We batch using the BatchElements transform with a fixed size of 10000k. Other datasets may need to adapt this. Note that this transformation can also do adaptive batching.
- We provide dependencies through a requirements.txt file. This is the simplest means to get started, but isn’t recommended in production settings.
Note on Continuous Data Loading #
Our approaches to implementing continuous data loading for this specific dataset could in reality be achieved a little more easily, as Google have made it available through other means. The Ethereum data is published by Google on a public Pub/Sub topic where the data can be consumed as it is made available. Whilst we we would still utilize the techniques below to load the historical Ethereum data to ClickHouse but then would probably write either a Google Dataflow job or utilize Vector, which supports both pub/sub as a source and ClickHouse as a sink. Other approaches to this problem may exist and and we welcome suggestions.
Dropping Older Data in ClickHouse #
For most deployments, ClickHouse’s superior data compression means that you can store data in a granular format for long periods of time. For our specific Ethereum dataset, this is probably not particularly beneficial since we likely need to preserve the full history of the blockchain for many queries, e.g., computing account balances.
However, there are simple and scalable approaches to dropping older data that may be applicable to other datasets. For instance, it is possible to use TTL features to expire older data in ClickHouse at either a row or column level. This can be made more efficient by partitioning the tables by date, allowing the efficient deleting of data at set intervals. For the purposes of example, we have modified the schema for the blocks table below to partition by month. Rows older than five years are, in turn, expired efficiently using the TTL feature. The set setting ttl_only_drop_parts ensures a part is only dropped when all rows in it are expired.
CREATE TABLE blocks
(
...
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(timestamp)
ORDER BY timestamp
TTL timestamp + INTERVAL 60 MONTH DELETE
SETTINGS ttl_only_drop_parts=1
Note that partitioning can both positively and negatively impact queries and should be more considered a data management feature than a tool for optimizing query performance.
Running Queries in ClickHouse #
This dataset warrants an entire blog on possible queries. The author of the etherium-etl tool used to load this data into BigQuery has published an excellent list of blogs focused on insights with respect to this dataset. In a later blog, we’ll cover these queries and show how they can be converted to ClickHouse syntax, and how some can be significantly accelerated. For now, we present a few of the simpler queries to get started.
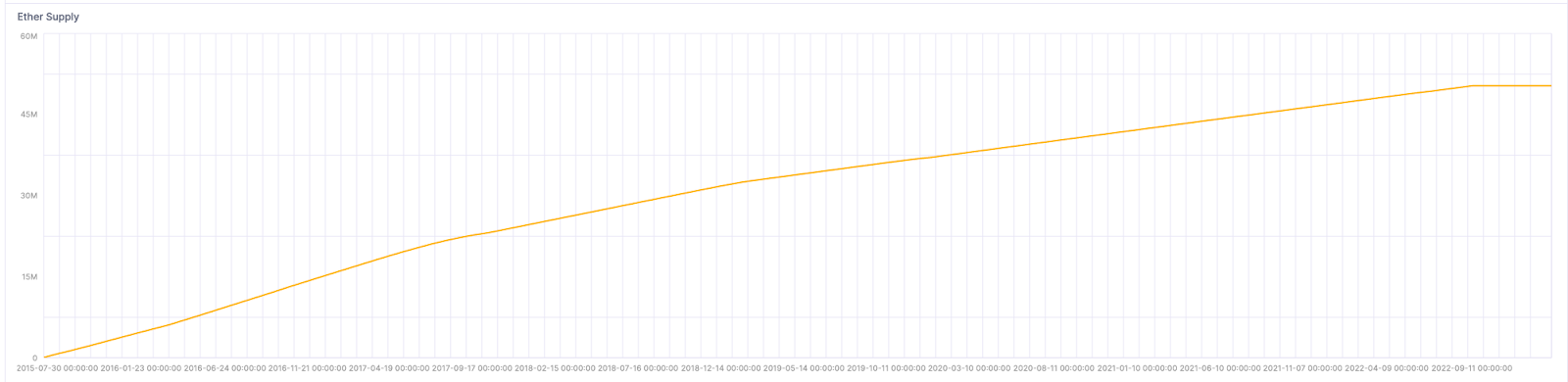
Ether supply by day #
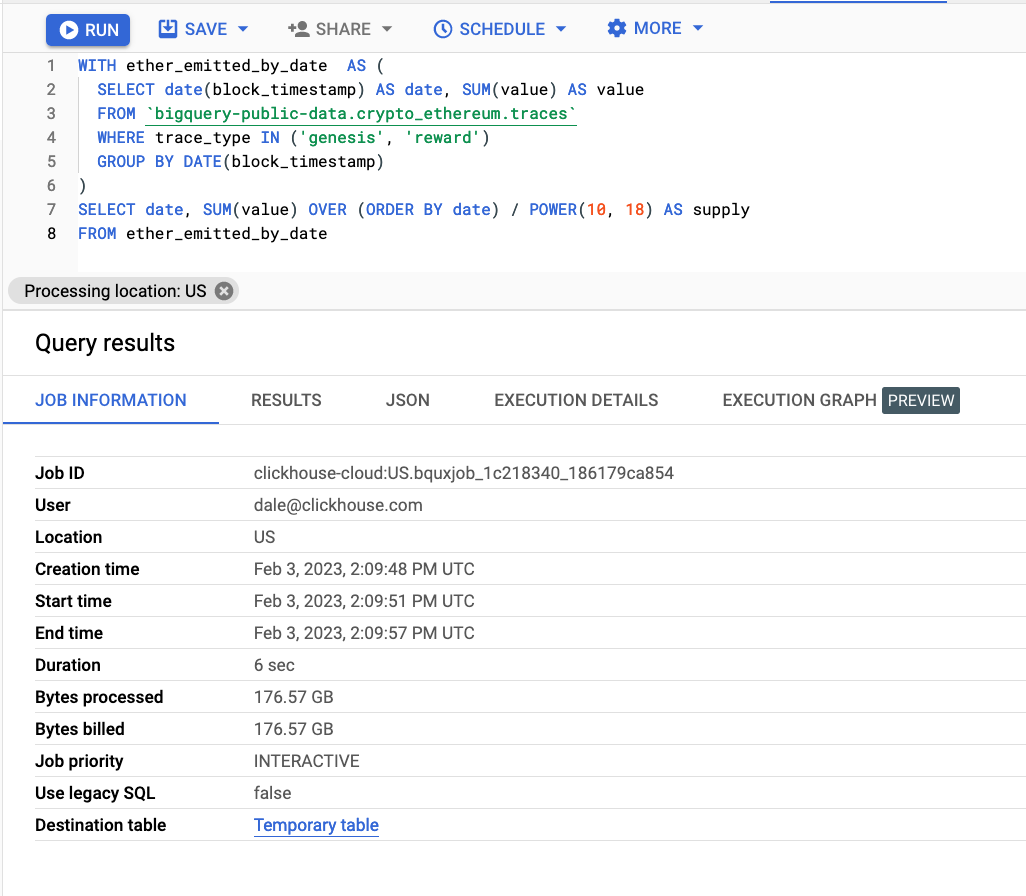
The original BigQuery query, documented as part of Awesome BigQuery views and discussed here, executes in 6 seconds. The optimized ClickHouse query runs in 0.009s, a big difference when comparing ClickHouse to BigQuery.
ALTER TABLE traces ADD PROJECTION trace_type_projection (
SELECT trace_type,
toStartOfDay(block_timestamp) as date, sum(value) as value GROUP BY trace_type, date
)
ALTER TABLE traces MATERIALIZE PROJECTION trace_type_projection
WITH ether_emitted_by_date AS
(
SELECT
date,
sum(value) AS value
FROM traces
WHERE trace_type IN ('genesis', 'reward')
GROUP BY toStartOfDay(block_timestamp) AS date
)
SELECT
date,
sum(value) OVER (ORDER BY date ASC) / power(10, 18) AS supply
FROM ether_emitted_by_date
┌────────────────date─┬────────────supply─┐
│ 1970-01-01 00:00:00 │ 72009990.49948001 │
│ 2015-07-30 00:00:00 │ 72049301.59323001 │
│ 2015-07-31 00:00:00 │ 72085493.31198 │
│ 2015-08-01 00:00:00 │ 72113195.49948 │
│ 2015-08-02 00:00:00 │ 72141422.68698 │
...
3 rows in set. Elapsed: 0.009 sec. Processed 11.43 thousand rows, 509.00 KB (1.23 million rows/s., 54.70 MB/s.)
Note that this query has been optimized with a projection - one of the many tools in ClickHouse we can use to optimize for a specific workload.
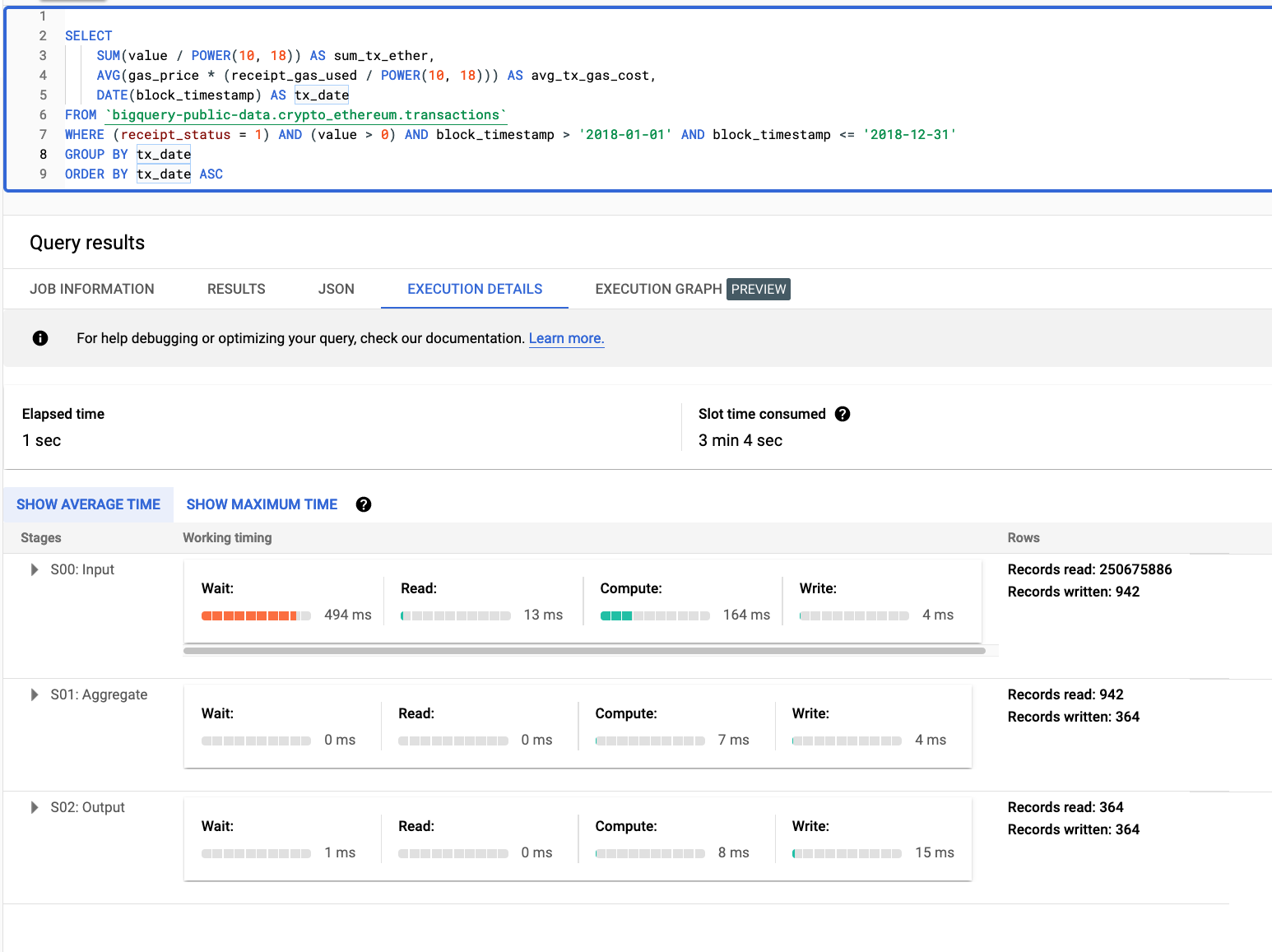
Average Ether costs over time #
Extracted from the most popular notebook for this dataset on Kaggle. We originally rewrote this query to include a left anti-join, although this doesn’t appear to be required. The more optimized version of the query is therefore used:
SELECT
SUM(value / POWER(10, 18)) AS sum_tx_ether,
AVG(gas_price * (receipt_gas_used / POWER(10, 18))) AS avg_tx_gas_cost,
toStartOfDay(block_timestamp) AS tx_date
FROM transactions
WHERE (receipt_status = 1) AND (value > 0) AND (block_timestamp > '2018-01-01') AND (block_timestamp <= '2018-12-31')
GROUP BY tx_date
ORDER BY tx_date ASC
┌───────sum_tx_ether─┬───────avg_tx_gas_cost─┬─────────────tx_date─┐
│ 8246871.766893768 │ 0.0005370300954867644 │ 2018-01-01 00:00:00 │
│ 13984780.926949782 │ 0.0005844979818261873 │ 2018-01-02 00:00:00 │
│ 13975588.850788314 │ 0.0006050748915709839 │ 2018-01-03 00:00:00 │
│ 20231765.935660254 │ 0.0007000256320466776 │ 2018-01-04 00:00:00 │
364 rows in set. Elapsed: 0.673 sec. Processed 250.90 million rows, 8.28 GB (373.01 million rows/s., 12.31 GB/s.)

10 most popular Ethereum collectibles (ERC721) #
This query is promoted by the datasets listed in the BigQuery market place and can be loaded here.
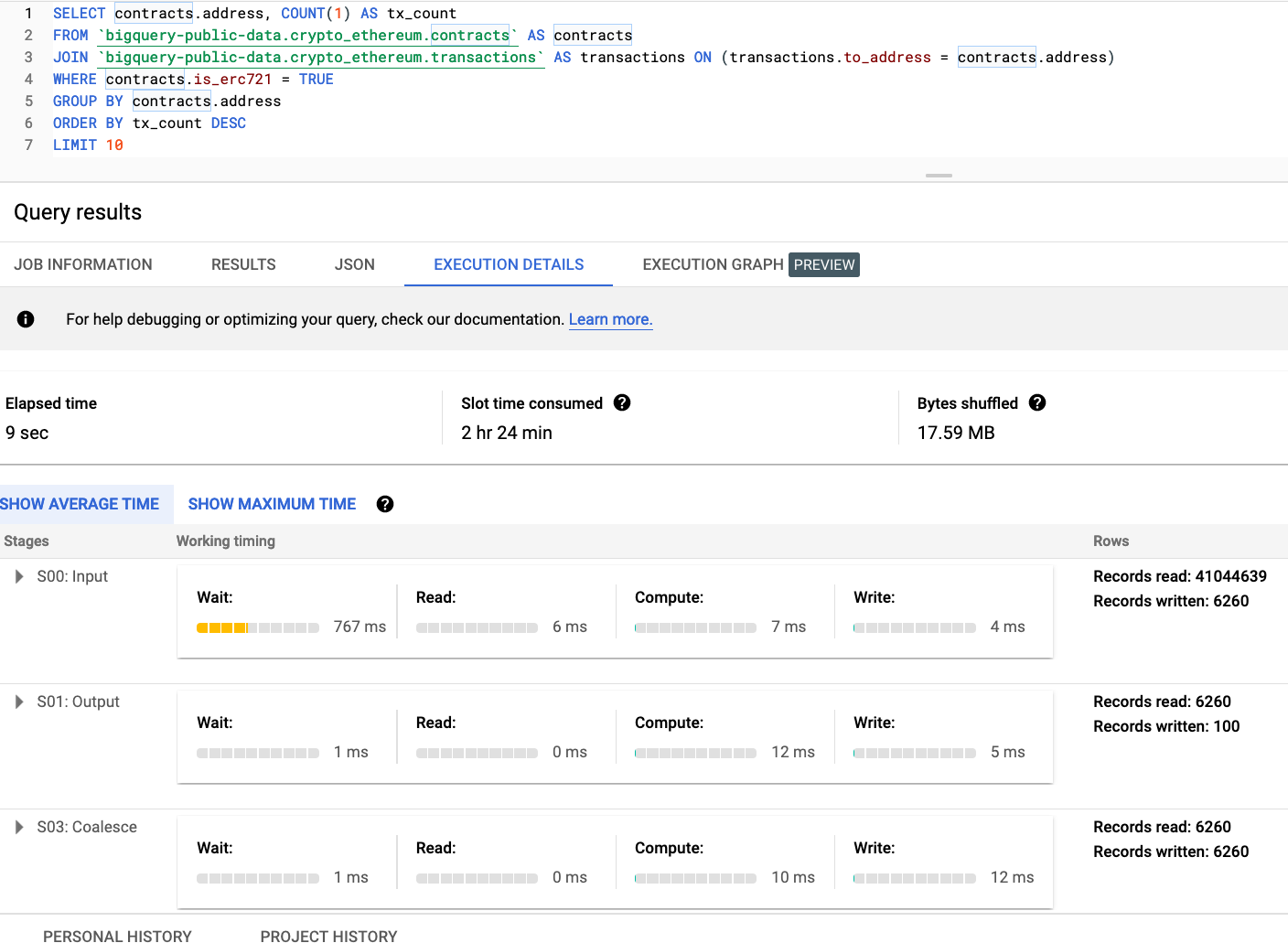
SELECT to_address, count() AS tx_count
FROM transactions
WHERE to_address IN (
SELECT address
FROM contracts
WHERE is_erc721 = true
)
GROUP BY to_address
ORDER BY tx_count DESC
LIMIT 5
┌─to_address─────────────────────────────────┬─tx_count─┐
│ 0x06012c8cf97bead5deae237070f9587f8e7a266d │ 4949539 │
│ 0x06a6a7af298129e3a2ab396c9c06f91d3c54aba8 │ 646405 │
│ 0xd73be539d6b2076bab83ca6ba62dfe189abc6bbe │ 443184 │
│ 0x1a94fce7ef36bc90959e206ba569a12afbc91ca1 │ 181073 │
│ 0xf5b0a3efb8e8e4c201e2a935f110eaaf3ffecb8d │ 148123 │
└────────────────────────────────────────────┴──────────┘
10 rows in set. Elapsed: 0.804 sec. Processed 374.39 million rows, 19.09 GB (465.46 million rows/s., 23.74 GB/s.)
The latency of all three of these queries has been improved by offloading their execution to ClickHouse, to varying degrees. The improvement in latency will vary, with queries whose access pattern is known and focused on analytics over a single table benefiting the most. The queries above are perfect examples of this and can be imagined powering an application. In these cases, specific ClickHouse features such as primary keys and projections can be exploited to deliver performance improvements greater than 10x.
Conclusion #
In this blog post, we have explored how data can be moved to ClickHouse from BigQuery for analysis and how these two technologies complement each other. We have shown a number of approaches to loading data and keeping it in sync, and how to leverage ClickHouse for real-time analytics on top of this data. In later posts, we’ll explore this Ethereum dataset in more detail.
In the meantime, we have made this dataset available in a public ClickHouse deployment for exploration (sql.clickhouse.com), as well as a the public GCS bucket gs://clickhouse_public_datasets/ethereum. You are welcome to try it by downloading a free open-source version of ClickHouse and deploying it yourself or spinning up a ClickHouse Cloud free trial. ClickHouse Cloud is a fully-managed serverless offering based on ClickHouse, where you can start building real-time applications with ease without having to worry about deploying and managing infrastructure.
Resources #
We recommend the following resources with respect to Ethereum and querying this dataset.
- How to replay time series data from Google BigQuery to Pub/Sub
- Evgeny Medvedev series on the blockchain analysis
- Ethereum in BigQuery: a Public Dataset for smart contract analytics
- Awesome BigQuery Views for Crypto
- How to Query Balances for all Ethereum Addresses in BigQuery
- Visualizing Average Ether Costs Over Time
- Plotting Ethereum Address Growth Chart in BigQuery
- Comparing Transaction Throughputs for 8 blockchains in Google BigQuery with Google Data Studio
- Introducing six new cryptocurrencies in BigQuery Public Datasets—and how to analyze them



