
Introduction
As a company dedicated to the ethos of open-source, it is important that we accept not only requests from the community but also features and new integrations.
Last week we delivered a webinar on such a project - the dbt-clickhouse plugin.
Initially created by a community contributor to address their needs and released in the spirit of OSS, this plugin has seen increasing adoption as users utilize dbt's capabilities with ClickHouse.
In this blog post, we explore dbt, the value it potentially brings when combined with ClickHouse, and a small tale of evolving support for more advanced capabilities leveraging new capabilities recently released in ClickHouse.
What is dbt?
dbt (data build tool) enables analytics engineers to transform data in their warehouses by simply writing select statements. dbt handles materializing these select statements into objects in the database in the form of tables and views - performing the T of Extract Load and Transform (ELT). Users can create a model defined by a SELECT statement.
Within dbt, these models can be cross-referenced and layered to allow the construction of higher-level concepts. The boilerplate SQL required to connect models is automatically generated. Furthermore, dbt identifies dependencies between models and ensures they are created in the appropriate order using a directed acyclic graph (DAG).
In summary, users can define a model representing a concept, e.g., a summary of actor appearances as SQL. These models can then be materialized* as either views or tables. These models can then be combined to produce more complex models.
In our recent webinar, we presented the following data schema for IMDB movie data. From this, we utilize dbt to create two models: one summarizing directors and another providing an overview of every actor, e.g., the number of movie appearances, their average rating, the director they have mostly worked with, etc. In this case, the actor's model is dependent on the director's model. dbt allows these models to be defined as SQL statements, with a Jinja templating language to connect and reference them. Note how some data sources aren’t even in ClickHouse, with the movie_genres and movie_director tables in S3 and Postgres respectively. This final model is then represented in ClickHouse as either a view or table named actor_summary.
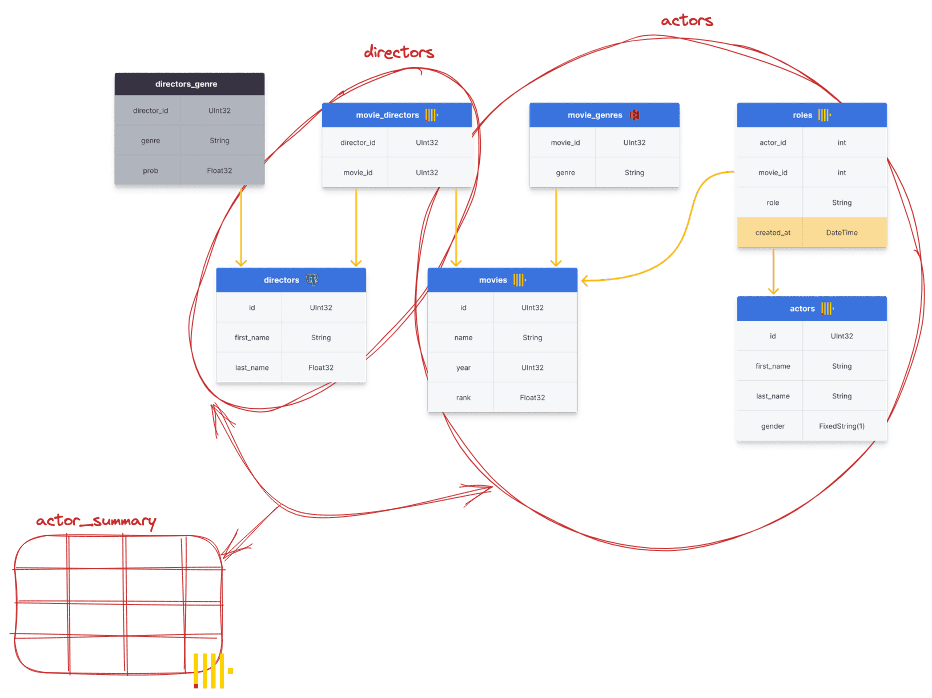
How is this supported in ClickHouse?
dbt supports an adapter plugin API to allow users to connect to data platforms that are not included in the core offering. In early 2021 a member of the ClickHouse community, Dmitriy Sokolov, created a plugin to support ClickHouse for his requirements and kindly open-sourced his work. In response to growing adoption and a little over a year later, this project was transferred to ClickHouse and officially made a vendor-supported plugin. We continue to invest in this plugin to support the dbt latest features and utilize the best practices of ClickHouse to expose this functionality.
We test this plugin rigorously against ClickHouse Cloud and ensure the current dbt plugin test suite passes.
How is it useful to ClickHouse users?
We primarily see users using dbt with ClickHouse for a number of tasks:
- Data analysts serving requests for views on the data, e.g., to the business for BI purposes or data scientists who need a specific view for their latest model. It is essential to manage these views and models and ensure they are tracked, minimized, tested, documented, and versioned.
- Users have data in various systems, such as Postgres, MySQL, and S3, and wish to model these data as a set of tables or views in ClickHouse. Using ClickHouse’s table functions and engines, users create dbt models to manage this data migration process. They, in turn, benefit from dbt representing these data integration tasks as code which can then be versioned, documented, and tested - again using dbt features.
- User’s often need to migrate data from other OLTP databases, such as Postgres, to ClickHouse to serve real-time analytical workloads. In simple cases, this can be achieved using native ClickHouse table functions. However, ClickHouse tables represented by many source tables subject to updates typically require Change data capture processes. Dbt can assist with the management and modeling of the queries required in this process.
- Users may alternatively need to track changes to rows in ClickHouse - a form of change capture- to answer questions concerning a former state in the database. Dbt offers features such as incremental models and snapshots that can assist with these requirements.
Model types
The process of persisting the results of a model’s SQL query is known as “materializing the model”. Models can be materialized in a number of ways. The clickhouse-dbt plugin ensures this is achieved using the most appropriate ClickHouse functionality and best practices:
- View Materialization - the simplest and default approach. Here the model is simply created in ClickHouse using the CREATE VIEW AS as syntax. Changes to the model cause the view to be recreated when dbt is run.
- Table Materialization- The results from the model’s SQL query are streamed into a new table with the appropriate schema, using the
INSERT INTO table SELECT <model_query>statement. The user pays the storage cost of representing the model as a table for the benefit of improved performance. - Incremental materialization- Provides a means to materialize a model as a table but maintain updates. Subsequent runs of the model identify changes in the source data using a unique key field and condition (e.g., based on a timestamp), and ensure this is reflected in the target table in ClickHouse. This is extremely powerful for the event-type data associated with ClickHouse.
- Ephemeral materialization - Represents the model as a CTE, which can then be referenced in other models.
Models of different types can be combined to produce more complex models, allowing component parts to be tested and documented. A simple table materialization for the actors model, as used on the webinar, is shown below:
{{ config(order_by='director_id', engine='MergeTree()', materialized='table') }}
WITH directors AS (
SELECT directors.id as director_id, movie_id, first_name, last_name FROM {{ source('imdb', 'movie_directors') }} OUTER JOIN {{ source('imdb', 'directors') }} ON {{ source('imdb', 'movie_directors') }}.director_id = {{ source('imdb', 'directors') }}.id
)
select *
from directorsFor further details, see the webinar recording or our documentation, which contains similar examples.
Recent developments
Incremental materializations represent the most complex model type to implement in ClickHouse. Historically ClickHouse has had only limited support for updates and deletes in the form of asynchronous mutations. These need to be used carefully since they rewrite all of the affected data parts and can be extremely IO-intensive as a result.
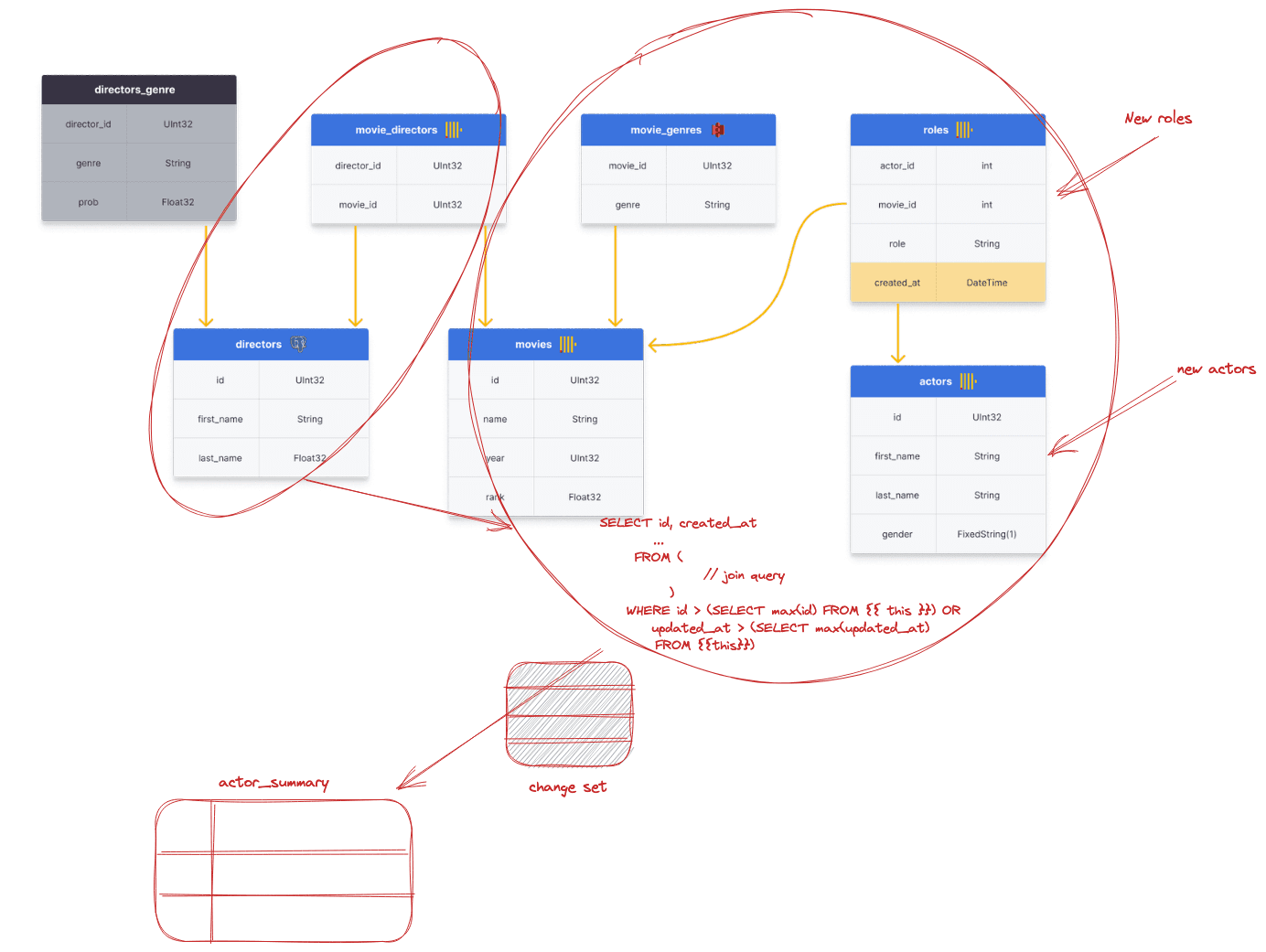
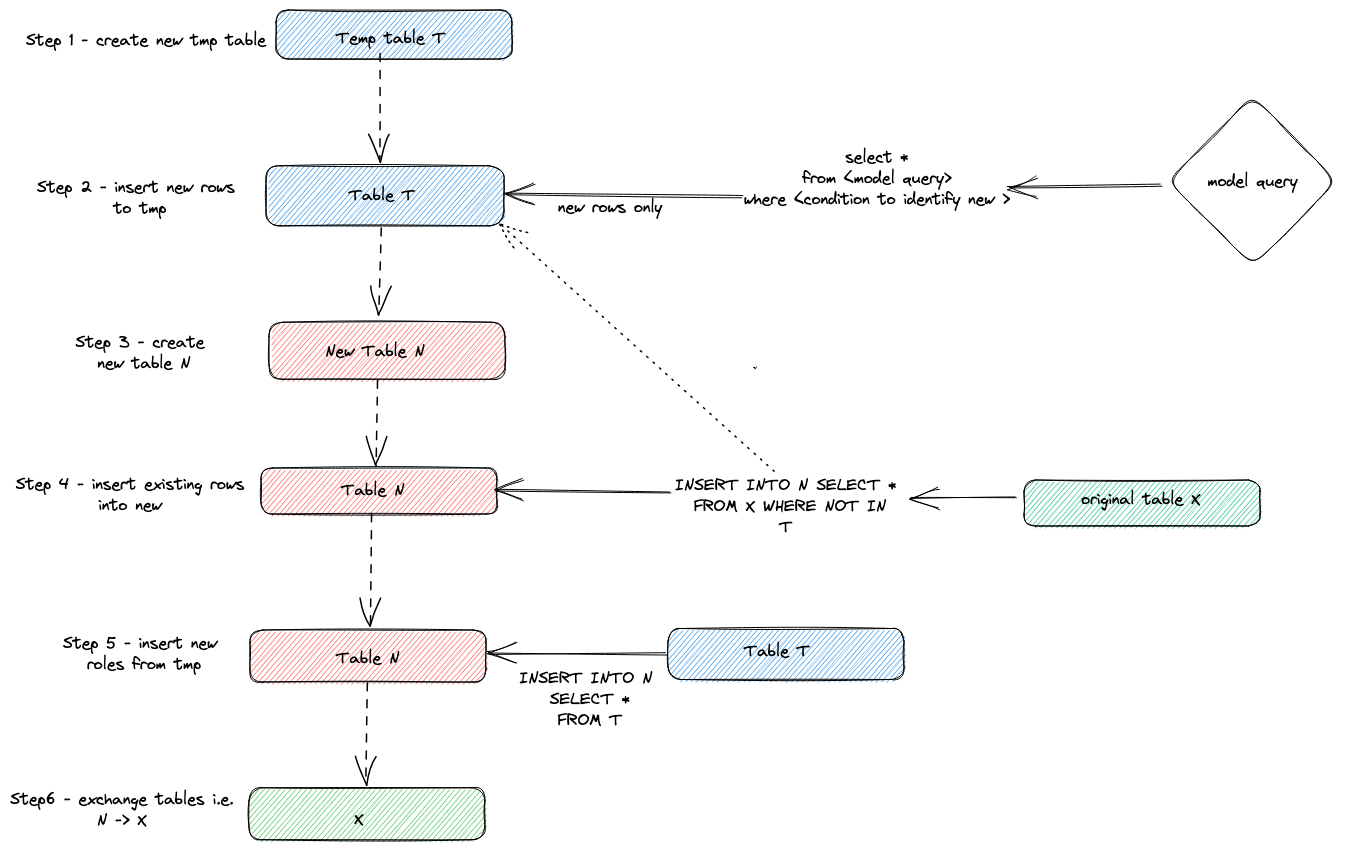
Suppose we have an original table, X, which represents a materialized model. To implement the incremental semantics required by dbt, dbt-clickhouse, by default, creates a new temporary table T with the new records identified by a condition the user specifies e.g. select max(updated_at) from {{this}}. A new table, N, is then created with the same schema as the original. Data is streamed into table N from the original table, using an INSERT INTO SELECT with a check to ensure the records aren't in T. Finally, we stream the records from T into N and do an atomic table exchange with X and N to expose the new realized model. This is visualized below:
While this approach works, it involves a complete duplication of the data being created for each dbt run and capture of the changes. Ideally, we would avoid this overhead and only write the new record,s. The above process is complicated as it supports duplicates and updates in the source data. If the user is comfortable with handling duplicates themselves in ClickHouse or is confident their source data is immutable and append-only, the incremental model can be configured to use an append-only strategy. In this case, the changes are simply identified in the source data and streamed directly into the existing table, as shown below
While improving the situation for a subset of cases, we remain dissatisfied with the current solution for the case where duplicates were a possibility. Fortunately, in 22.8 ClickHouse added lightweight deletes as an experimental feature. Lightweight deletes are significantly faster than ALTER TABLE ... DELETE operations because they don't require rewriting ClickHouse data parts. “Tombstones” are simply added to deleted rows which allow records to be automatically excluded at query time. These deleted records are, in turn, merged away during normal merge processes. Armed with deletes that don’t consume as much IO and threaten cluster stability, we could add a new approach known as delete+insert to incremental materializations.
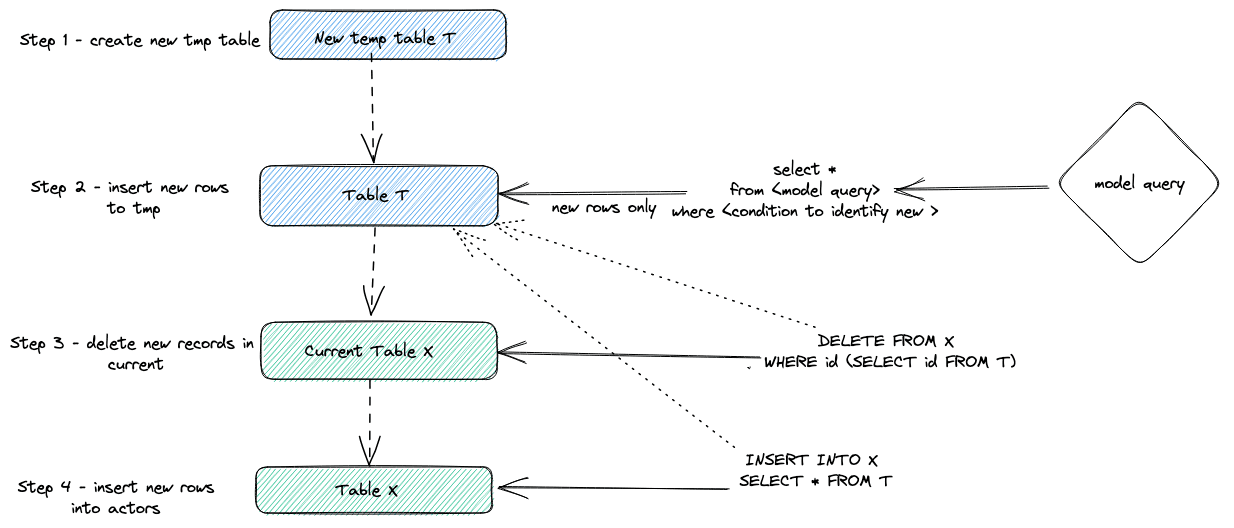
In summary, this approach:
- Creates a temporary table
T. Rows that have changed are streamed into this table. ADELETEis issued against the current tableX, deleting rows by id based on the values inT. - The rows from
Tare inserted into the current tableXusing anINSERT INTO X SELECT * FROM T.
We visualize this below:
Our testing suggests this approach performs significantly better than the "legacy" strategy. However, there are important caveats to using this strategy:
- The setting
allow_experimental_lightweight_deletemust be enabled on your ClickHouse server or included in the custom_settings for your ClickHouse profile. - As suggested by the setting name, lightweight delete functionality is still experimental and is not quite considered production-ready, so usage should be limited to datasets that are easily recreated.
- This strategy operates directly on the affected table/relation (without creating any intermediate or temporary tables), so if there is an issue during the operation, the data in the incremental model is likely to be in an invalid state
While the first two of these issues are likely to be addressed soon with lightweight deletes expected to GA soon, the latter requires further development work. What about transactions, you say? Well, that's a good idea…
Conclusions
In this post, we have introduced dbt and the ClickHouse plugin. We have covered the value of dbt to ClickHouse users and discussed some of the key features before presenting recent developments based on new capabilities in ClickHouse. For more details, we recommend the recent webinar and examples in our documentation. Happy modeling.


