TL;DR
We’ve built a distributed cache for cloud object storage: a shared, low-latency layer that gives all compute nodes fast access to hot data.
This post looks under the hood: how hot data caching worked before, why object storage made it hard, and how the new architecture fixes it. Benchmarks included.
→ We’re now opening registration for the distributed cache private preview. Sign up here to request access.
What if hot data just stayed hot?
Imagine a database where you can freely scale up by swapping in larger compute nodes, or scale out by adding more, without ever worrying about losing access to cached hot data. Now imagine every node instantly benefiting from work done by others. No cold starts. No repeated reads from storage. No wasted effort.
Sounds like a dream? In today’s decoupled cloud databases, maintaining continuity of hot data is a real challenge.
We’re announcing a distributed cache for ClickHouse Cloud, a shared caching layer that solves a long-standing challenge: keeping hot data close to compute, even as nodes scale up, down, or shift.
We’ll walk you through the evolution of caching in ClickHouse, how the distributed cache works, and what it unlocks for performance and elasticity.
And at the end, we’ll benchmark it against prior approaches, including a self-managed server with SSDs. (Spoiler: we beat that. Even on a cold start.)
To understand why caching hot data close to the query engine matters and why we built a distributed cache, we first need to look at what’s being cached.
What is “hot table data” and why does it matter?
ClickHouse has built-in caches for almost everything: DNS entries, input file schemas, table metadata, sparse primary index data and mark files, uncompressed table data, compiled expressions, table data matching query conditions, and even full query results. Each of these plays a role in accelerating query execution and may be explored in future posts.
In this post, we focus on one of the most impactful techniques: caching hot table data in memory.
This works hand-in-hand with ClickHouse’s layered I/O optimizations, which aggressively minimize how much data needs to be read at all. Once those optimizations kick in, only the necessary data—the hot table data—is streamed into memory and processed by the query engine. To make that streaming faster, especially for repeated queries, ClickHouse caches the hot table data before execution begins, ideally in local RAM, as close to the query engine as possible.
Why does this matter?
Reading from memory is massively faster than reading from disk. We’re talking nanoseconds vs. milliseconds, and ~100 GB/sec vs. a few GB/sec. That’s a million-fold improvement in latency, and orders of magnitude in throughput.
We’ll break those numbers down later. But first, let’s define what “hot table data” means in practice.
The diagram below shows a simplified query running over a table:
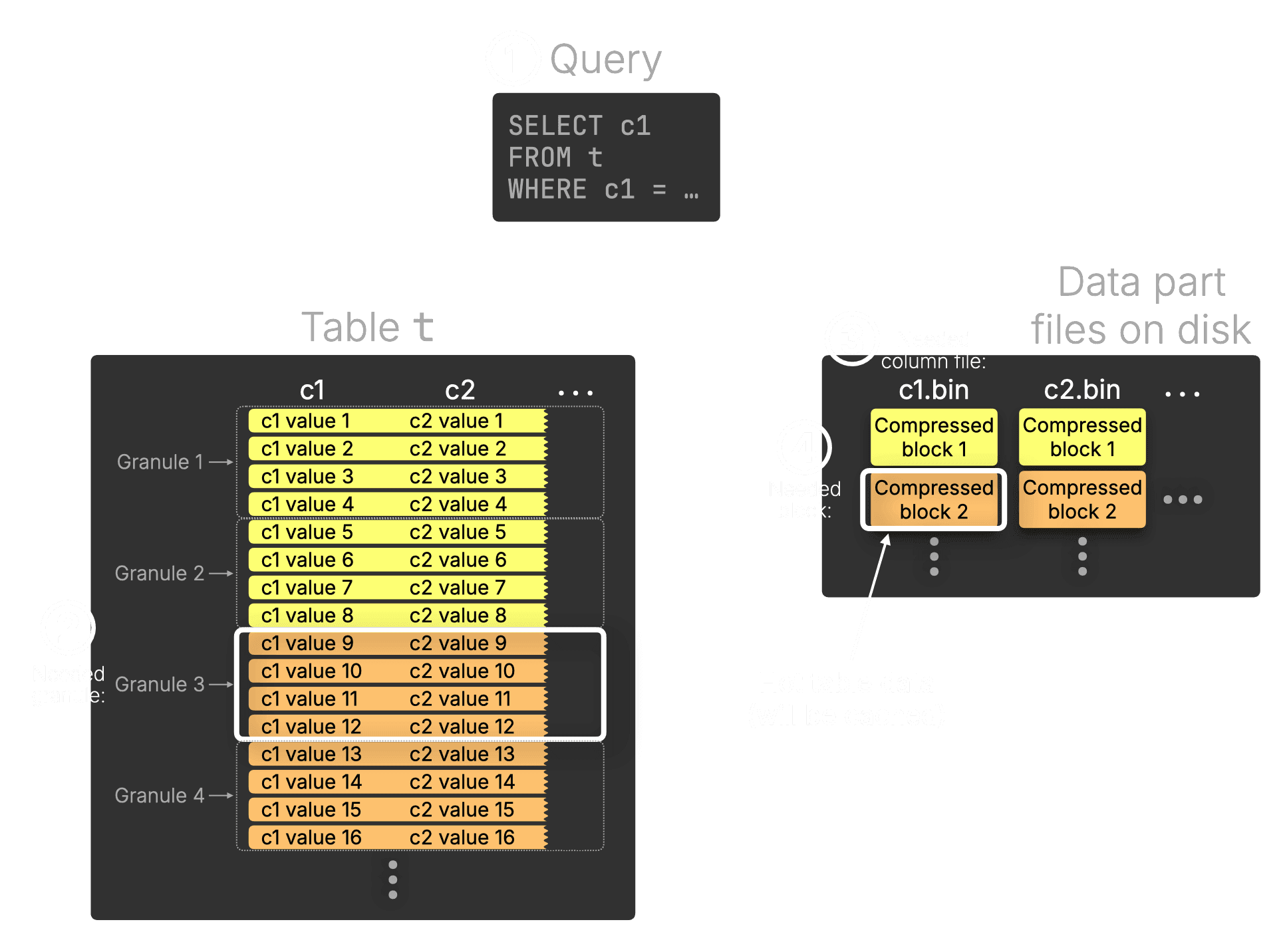
① Query
A SELECT targets column c1, with a WHERE clause filtering specific rows.
② Needed granule
The table is divided into granules, ClickHouse’s smallest query processing units, each covering 8,192 rows by default. In this simplified diagram, we show 4 rows per granule. Through index analysis, Granule 3 is selected as potentially containing matching rows for the query.
③ ④ Needed column file and block
Each column on disk is stored as a separate file (inside a data part directory), made up of compressed blocks, with each block spanning multiple granules. In this example, each block covers 2 granules. The query engine identifies c1.bin as the column file to read from and determines that block 2 of this file contains the selected granule. This block is therefore the hot table data for this query.
What is “hot table data”?
Technically speaking, the hot data for a query refers to column file segments, the ranges of compressed blocks containing the granules selected for query processing. These segments are read from disk and cached in memory to accelerate future queries.
Get started today
Interested in seeing how ClickHouse works on your data? Get started with ClickHouse Cloud in minutes and receive $300 in free credits.
Sign upThe evolution of hot data caching in ClickHouse
Over time, ClickHouse caching of hot table data has evolved through three major stages:
-
It began with the OS page cache on local disk, simple and fast, but tightly coupled to individual machines.
-
In the cloud, we introduced a local filesystem cache to bridge the gap between object storage and in-memory execution.
-
Now, we’ve taken the next step: turning that filesystem cache into a shared network service. The new distributed cache encapsulates the same caching logic, but makes it available to all compute nodes, bringing consistency, elasticity, and instant access to hot data.
Let’s walk through each stage and see how they led us to the distributed cache.
Stage 1: Local OS page cache
In traditional shared-nothing ClickHouse clusters, where sharding is used to scale out, each server stores and accesses only its own data on local disk. In this setup, ClickHouse relies on the operating system’s page cache, which transparently and automatically caches the column file segments loaded from disk during query processing.
The following animation illustrates how this works (click to view in fullscreen):
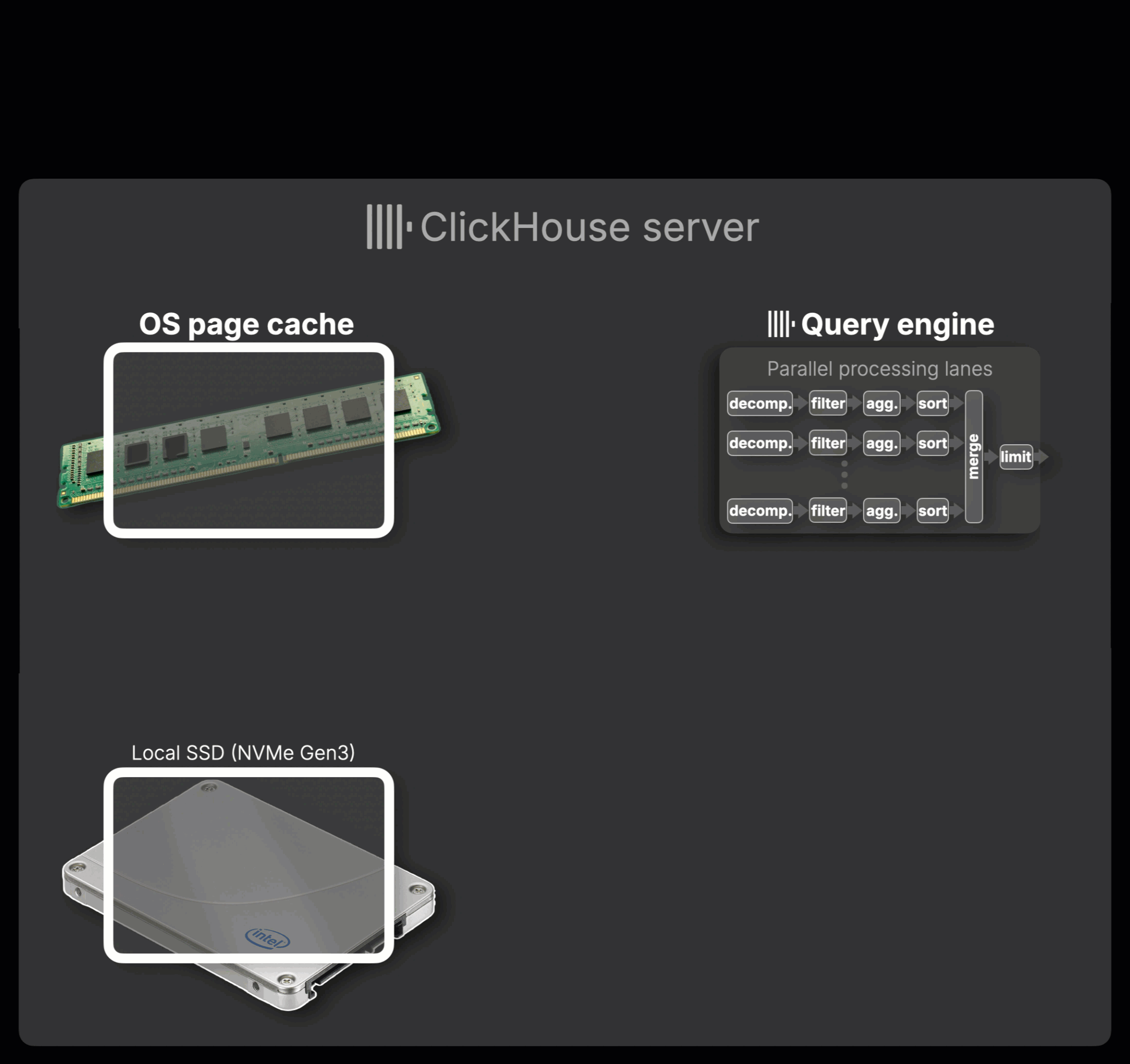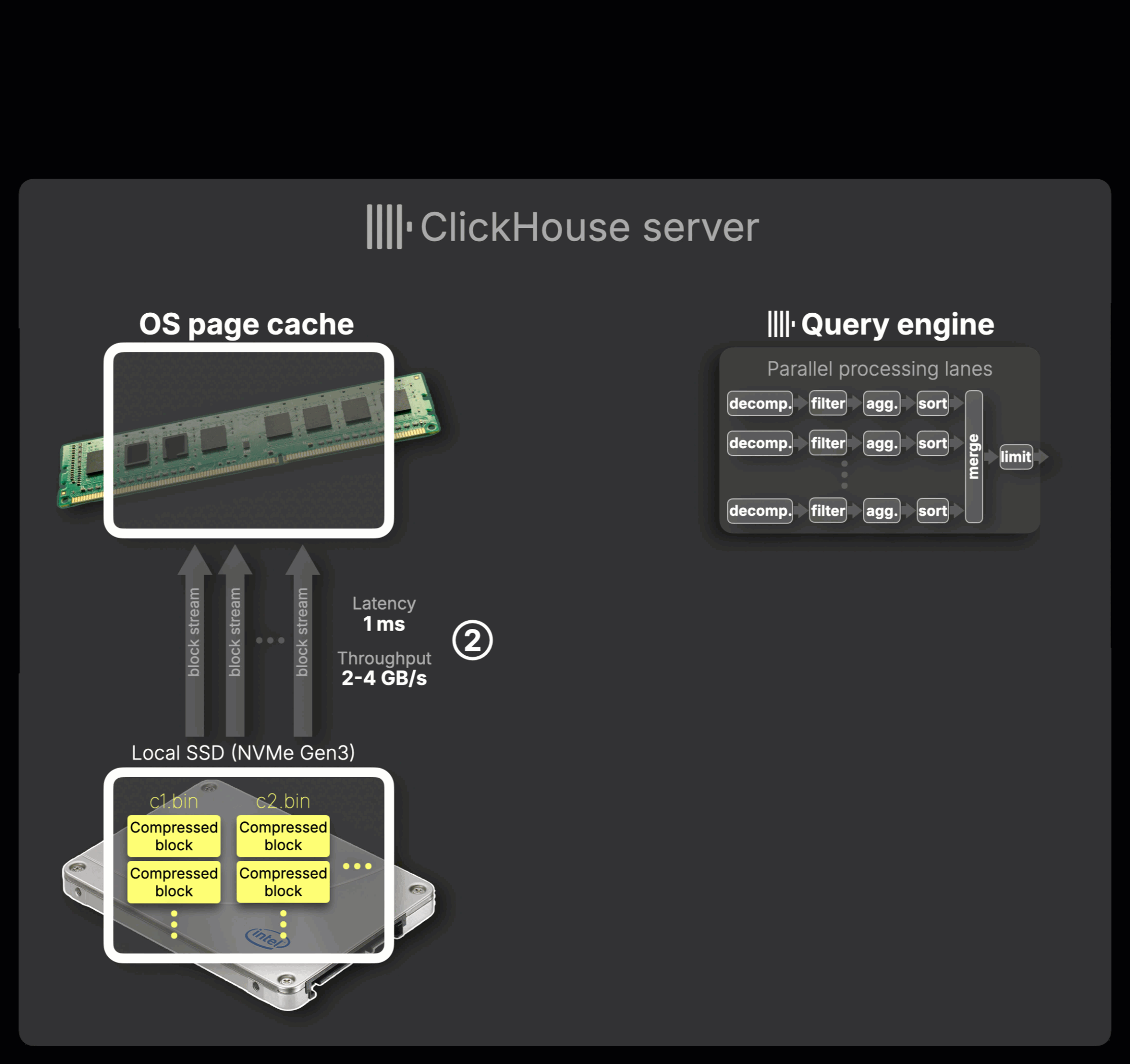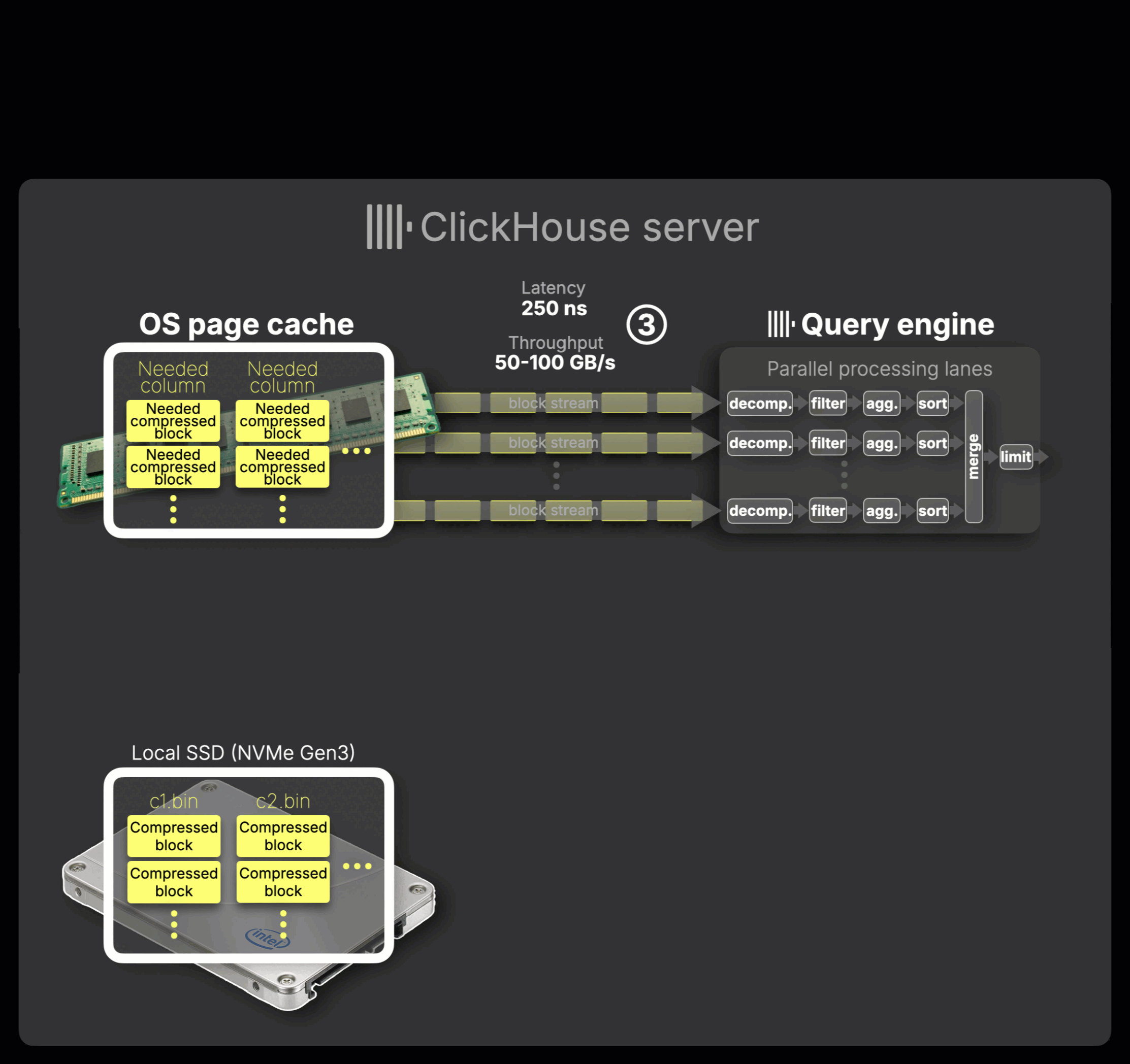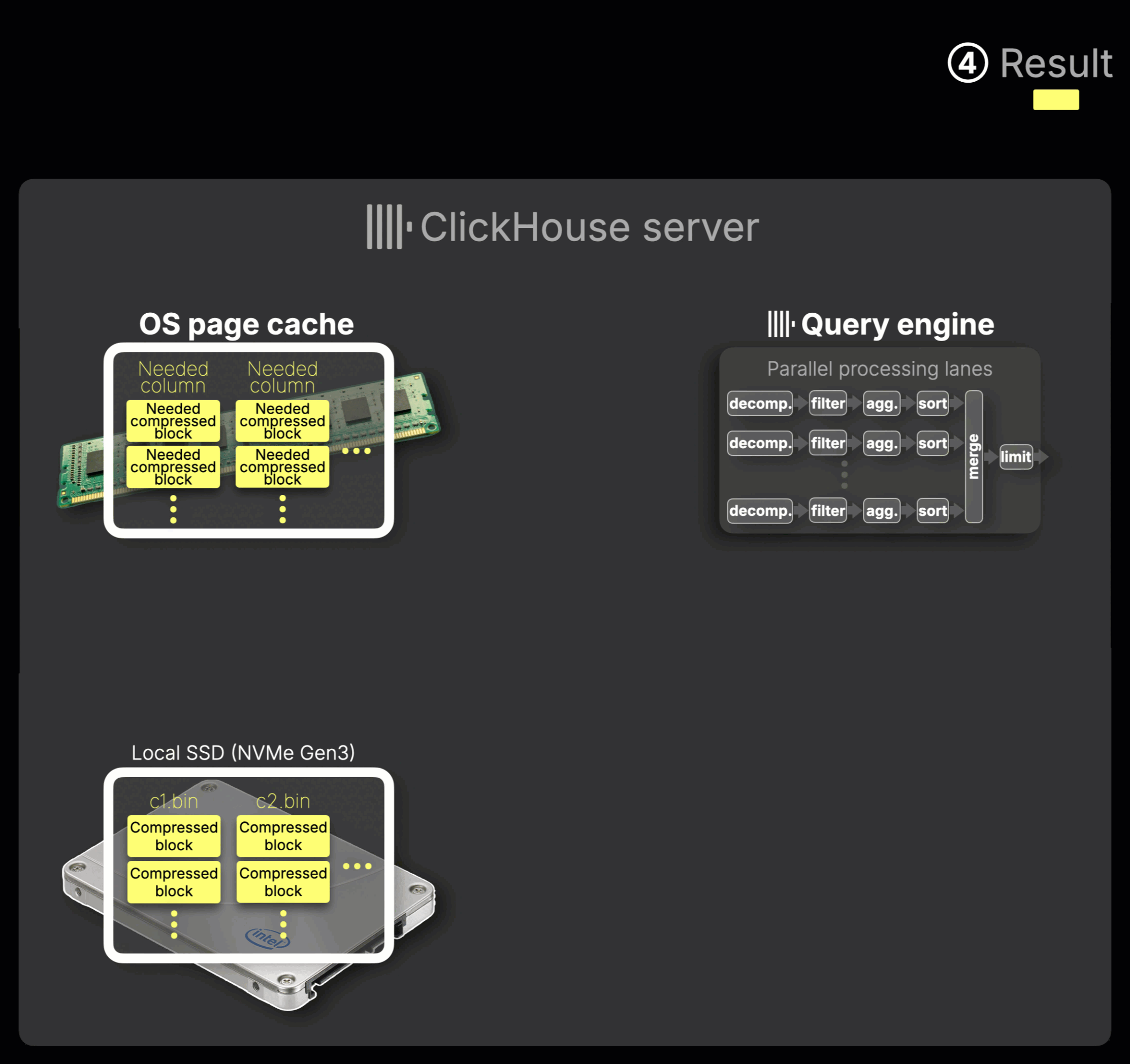
① Query arrives:
A query reaches the ClickHouse server. The server analyzes index files to determine which compressed column blocks are needed to satisfy the query.
② Data loading:
If the needed blocks aren’t already cached, they are read from local SSD (e.g., NVMe Gen3) and automatically placed into the OS page cache.
③ In-memory processing:
Compressed blocks are streamed from the OS page cache into the query engine at 50–100 GB/s, limited by memory bandwidth rather than disk. ClickHouse processes the data entirely in memory, block by block, in a streaming fashion. It uses multiple independent parallel lanes to decompress, filter, aggregate, and sort the data.
The number of these lanes is controlled by the max_threads setting, which by default matches the number of available CPU cores.
This same setting also determines how many concurrent streams are used to read data from disk when it’s not already cached, enabling parallel loading and maximizing throughput, as shown in the animation.
④ Result generation:
The processed data is merged and limited as needed, and the final query result is returned to the client.
In-memory caching strategies
ClickHouse relies on the OS page cache, which works transparently for both reads and writes. This enables read-through caching, keeping data in memory after it’s read, and write-through caching, where newly written data is cached immediately, making it queryable without hitting disk. As long as the data fits in RAM, it stays cached; otherwise, the OS evicts the least recently used pages to make room for new ones.
To further reduce latency, ClickHouse also offers an optional uncompressed blocks cache. This keeps uncompressed versions of frequently accessed blocks in memory, eliminating decompression overhead for hot data. While decompression is fast, skipping it entirely can reduce latency and increase throughput in case of frequent short queries.
This cache is off by default, as uncompressed blocks use significantly more memory than compressed ones, especially given ClickHouse’s typically high compression ratios.
Interestingly, as Alexey Milovidov shows in this presentation, in-memory processing of compressed data can often be faster than in-memory processing of uncompressed data.
These optimizations work well when data lives on local disks in traditional shared-nothing deployments. But what happens when the storage isn’t local anymore?
Stage 2: Local cache on cloud compute nodes
In ClickHouse Cloud, caching works differently than in traditional shared-nothing clusters. Compute and storage are decoupled, and all compute nodes read from the same shared object storage. Instead of managing separate shards, they act as replicas reading from a single, virtually limitless shard.
But shared storage brings new challenges, especially when it comes to performance.
The real bottleneck of object storage: latency
While object storage can offer decent throughput, its high access latency is often the real performance bottleneck. To mitigate this, ClickHouse Cloud uses compute nodes with directly attached SSDs that act as a local filesystem cache, providing a middle ground between slow-but-durable object storage and fast-but-volatile memory.
Here’s how these layers compare:
| Layer | Latency (99.99%) | IOPS | Throughput |
|---|---|---|---|
| S3 | 500 ms | 5K | 2 GB/sec |
| SSD | 1 ms | 100K | 4 GB/sec |
| Memory | 250 ns | 100M | 100 GB/sec |
Completely separate from the distributed cache work described in this post, we are also experimenting with integrating the Amazon S3 Express One Zone storage class, the fastest cloud object storage class on AWS, offering single-digit millisecond latency, into both our primary storage and caching layers to explore potential performance and cost improvements. Read more →
As the table shows, memory is millions of times faster than S3 in tail latency (99.99th percentile) and orders of magnitude faster in throughput. SSDs sit in the middle, much faster than S3 but still far behind memory.
And while the throughput gap between S3 and SSD (on typical EC2 machines, like m7gd.16xlarge) may look small—2 GB/s vs. 4 GB/s in typical ClickHouse Cloud setups—that already reflects heavy optimization.
Raw S3 throughput is typically just a few hundred MB/s per thread. ClickHouse uses multi-threaded reads and asynchronous prefetching to achieve multi-GB/s performance. For more details, see Kseniia’s deep-dive talk, she’s the core developer behind the filesystem cache described in this section.
But even so, the latency gap is massive: hundreds of milliseconds vs. microseconds or nanoseconds. Unlike throughput, latency is much harder to hide or parallelize. No amount of multi-threaded reading helps when each read still takes hundreds of milliseconds. Object storage is just slow to access. Full stop.
That’s why latency becomes the dominant bottleneck in many real-world analytical queries. You simply can’t fan out enough I/O to hide the delay.
- Short-running queries often touch just a few compressed blocks.
- Scattered access patterns involve many small, disjoint reads.
In both cases, bandwidth doesn’t help, latency is the limit.
That’s why caching hot data close to the query engine is so critical, not just for bandwidth, but for speed that feels instant. The filesystem cache does exactly that, shielding queries from the high latency of object storage.
Filesystem cache: beyond hot data
In addition to caching hot table data, the disk-based filesystem cache in ClickHouse Cloud also:
-
Caches table metadata, such as secondary data skipping indexes and mark files.
-
Stores intermediate query data for aggregation, sorting, and joins (i.e., spill-to-disk).
-
Caches external files from remote sources (e.g., when querying Parquet files).
How the filesystem cache works
The filesystem cache handles both reads and writes:
-
Write-through caching: When new data is written, it’s stored in both the filesystem cache and object storage. This includes not just inserts, but also merged parts produced during background merges. While this ensures durability, it doesn’t mask object storage’s write latency. Fortunately, the OS page cache automatically holds recently written files in memory, creating a fast two-level cache: SSD + RAM.
-
Read-through caching: When data is streamed from object storage (e.g., S3), it’s saved to the local filesystem cache. This avoids repeat downloads and gives future queries local-disk-speed access to remote data.
If the cache disk fills up, the filesystem cache evicts the least recently used data to make room. And because column files in ClickHouse table parts are immutable, there’s generally no need for explicit cache invalidation.
The animation below shows how read-through caching works in practice (click to view in fullscreen):

The high-level flow of hot table data in ClickHouse Cloud resembles that of traditional shared-nothing servers, but with important differences:
① Query arrives
A query is routed to a compute node in ClickHouse Cloud. Unlike traditional servers, this node accesses shared data stored in object storage (e.g., S3) rather than local disk.
② Data loading from object storage
If the required data is not already cached, it is streamed from shared object storage, using multi-threaded reads and asynchronous prefetching, as shown in the animation above, and written to the disk-based filesystem cache.
③ Memory caching
As blocks are loaded from the filesystem cache, the OS page cache automatically accelerates future access, just like on traditional local-disk setups.
④ ⑤ In-memory execution
The query engine processes data in parallel, block by block, streaming from the OS page cache into execution lanes at ~50–100 GB/s, limited by memory bandwidth.
Why we needed something better
The animation below illustrates a fundamental limitation of traditional hot data caching in ClickHouse Cloud (click to view in fullscreen):
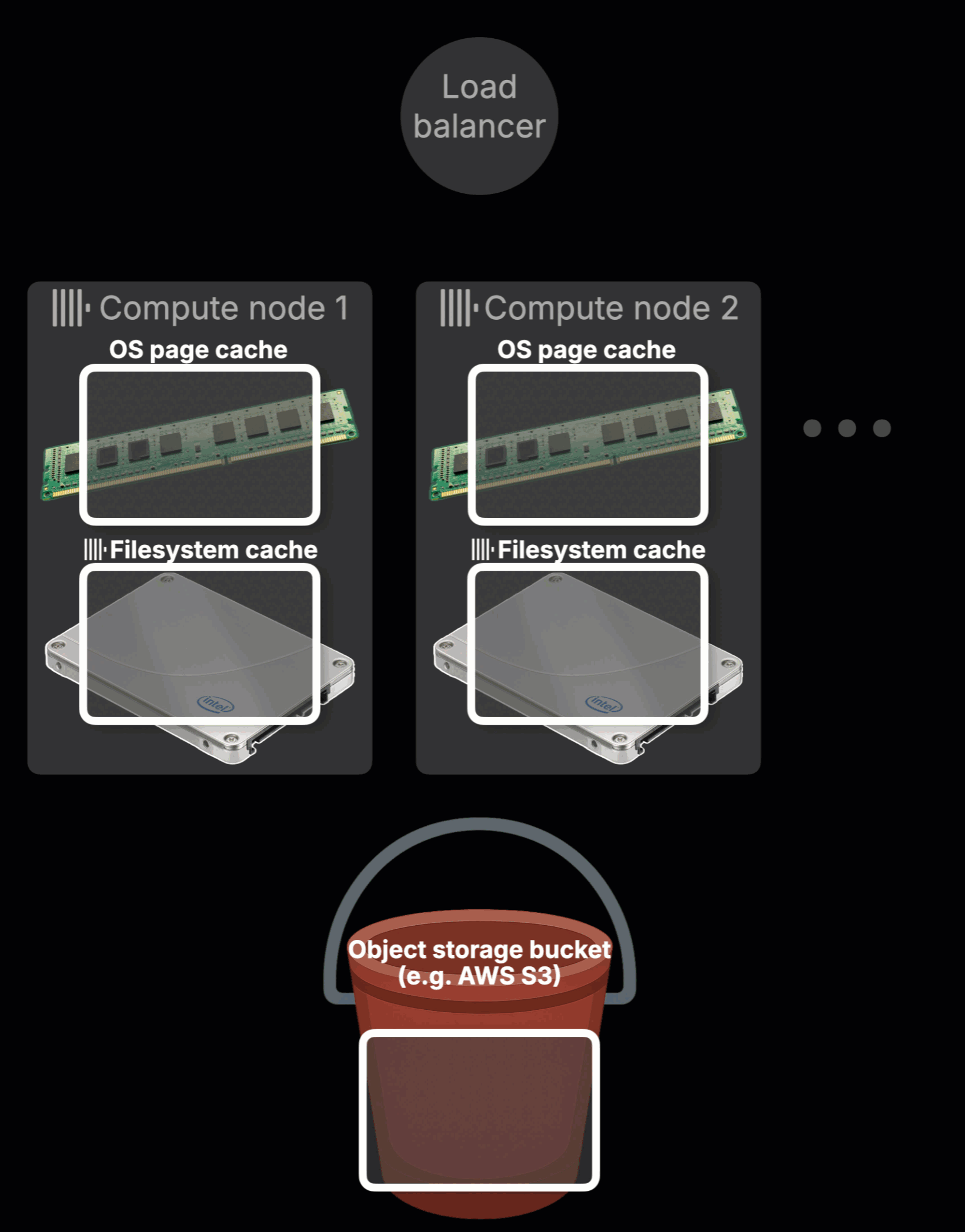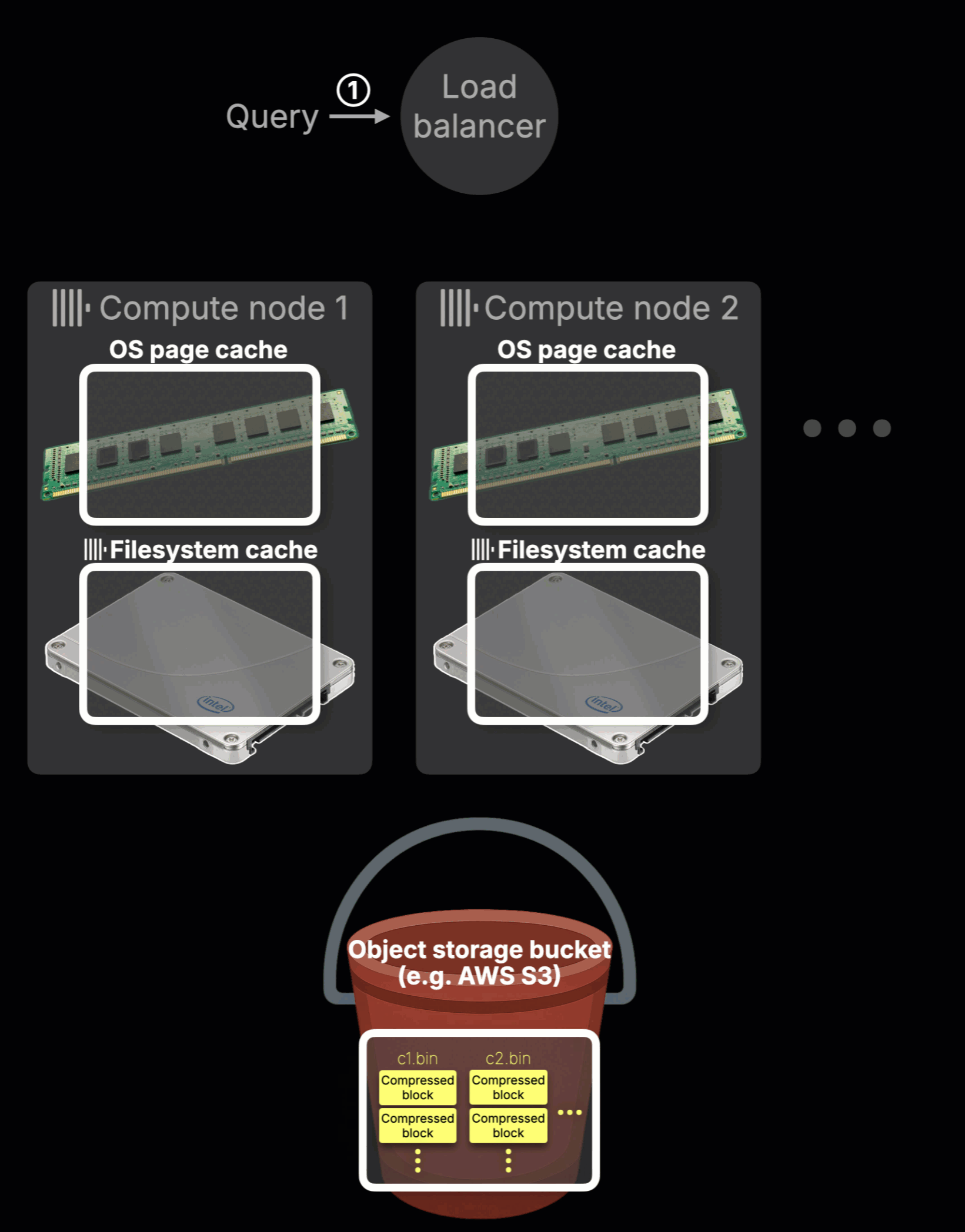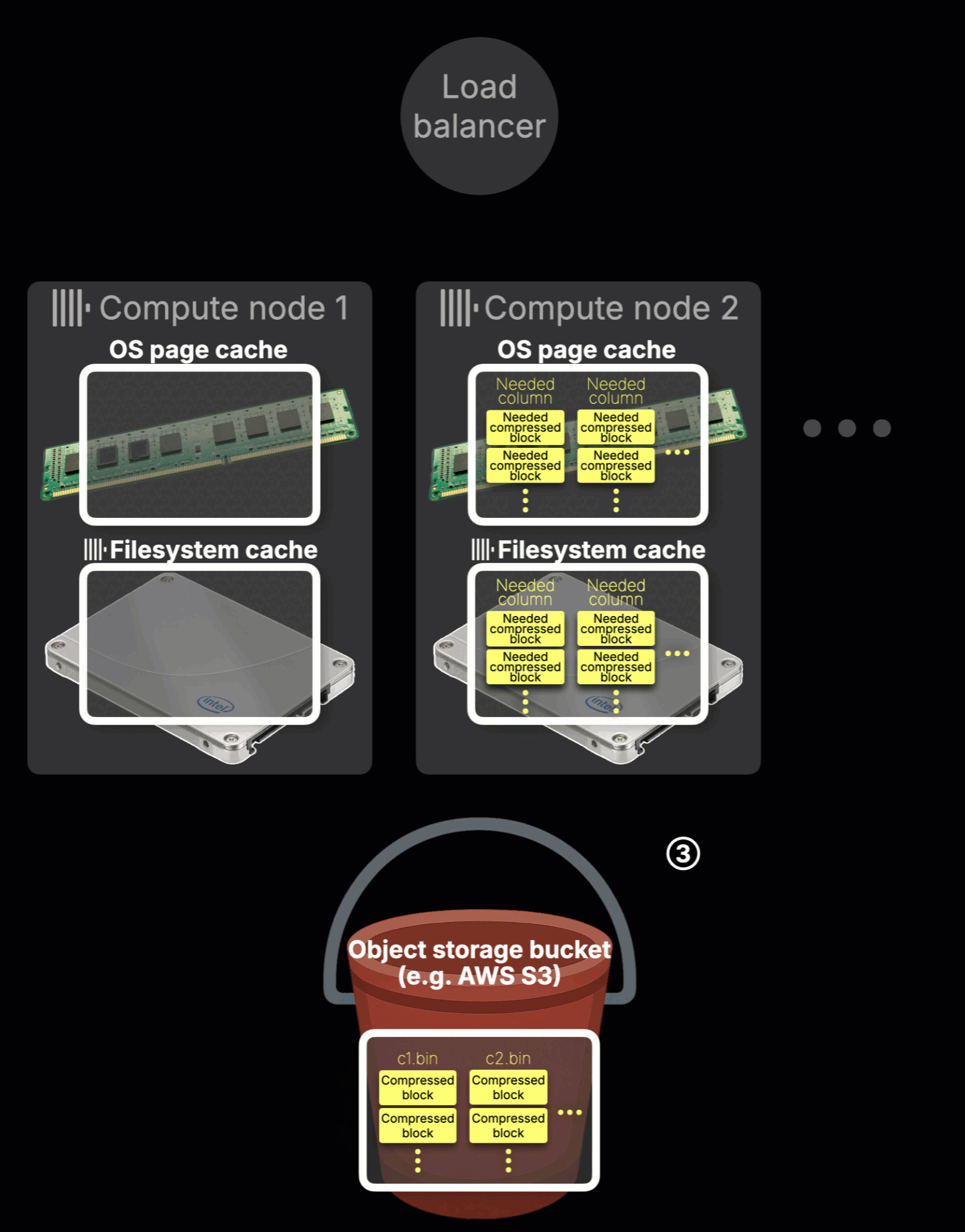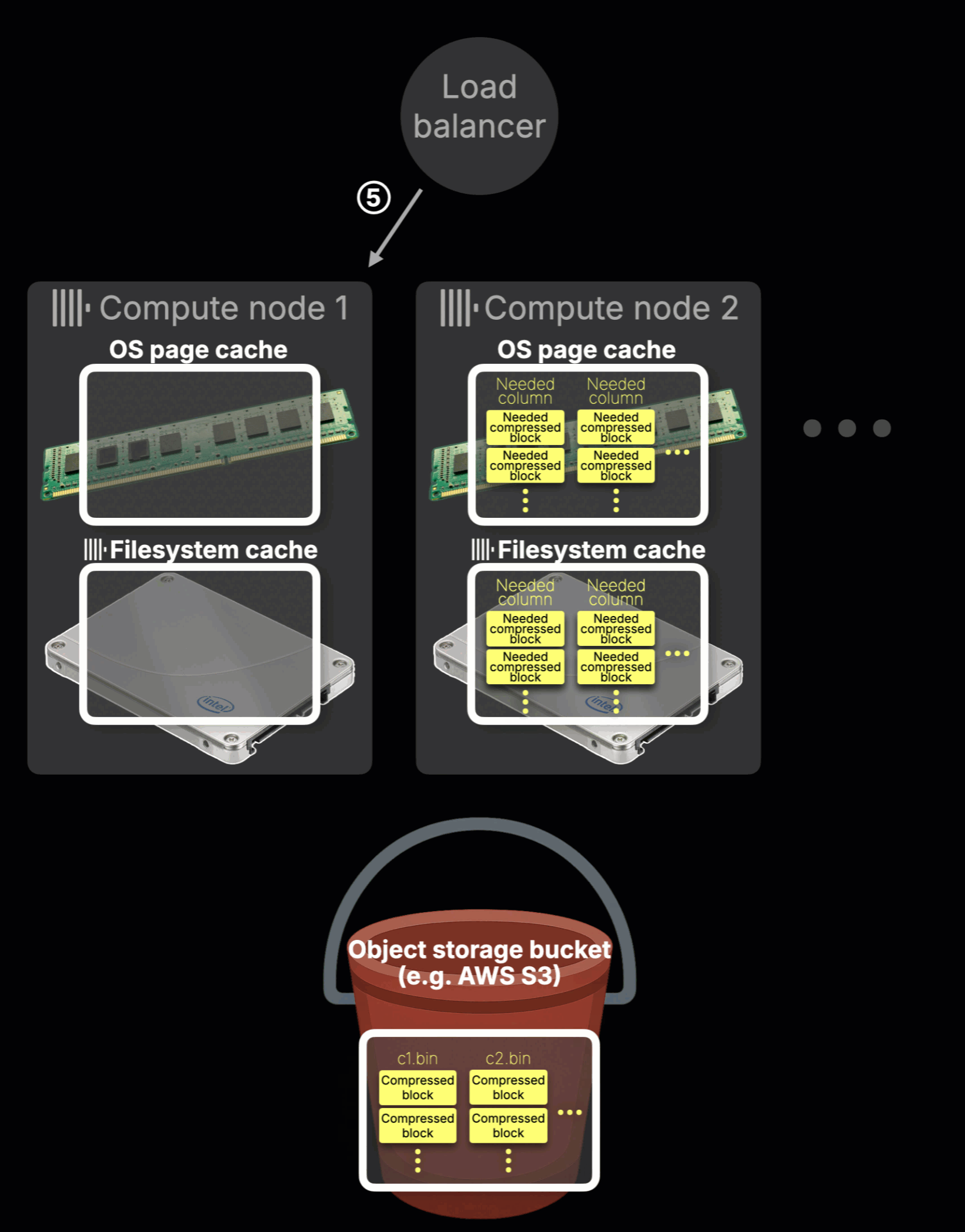
Here’s what the animation shows:
Query routing (①–②)
A query arrives at the ClickHouse Cloud load balancer and is routed to a compute node (e.g., node 2, both node 1 and node 2 start with a cold cache for this query).
Local caching (③)
Node 2 processes the query, fetches the required hot table data from object storage, and stores it in its local filesystem cache and OS page cache.
Cache isolation
If a ④ later query is ⑤ routed to node 1, it has no access to the data cached by node 2. It must re-fetch the same data from object storage and warm up its own cache from scratch.
Local, per-node filesystem caches work well for single-node stability. But in a world of elastic, stateless compute, they fall short:
- Hot data isn’t portable: Each node has its own isolated cache.
- Caching effort isn’t shared: Work done on one node can’t help others.
- Scaling means starting over: Adding or replacing nodes discards all hot data.
In practice, that means:
- You scale up to a larger node, but it starts cold with no cached data.
- You add a node to scale out, but it has to re-fetch everything from object storage.
- Queries that were fast seconds ago stall while waiting for data to stream in again.
- Hot data becomes cold the moment your compute topology changes.
In short, local caching improves repeat performance, but only for the node that did the work. To make caching effective in a cloud-native world, we needed something shared.
Stage 3: The distributed cache
Isolated caches, repeated work, and cold starts blocked cloud-native elasticity. So we built the distributed cache: a shared network service that wraps the filesystem cache and makes hot data fast accessible across all ClickHouse compute nodes. Instead of rebuilding caches locally, nodes now send read and write requests to a single, shared cache.
Let’s look under the hood and see what makes the distributed cache fast, scalable, and cloud-ready.
A new layer in the stack: the network
ClickHouse Cloud turns the local filesystem cache into a shared network service, something that’s feasible thanks to the high bandwidth and low latency of modern networks.
In AWS, intra-zone network latency can be as low as 100–250 µs, hundreds of times faster than S3’s ~500 ms tail latency. Network throughput typically ranges from 1.5 to 12.5 GB/s, often matching or exceeding local SSD performance. High-throughput instances can reach up to 100 Gbps (12.5 GB/s), and specialized configurations can go even further.
Here’s how the network layer compares to other storage tiers on latency and throughput:
| Layer | Latency | IOPS | Throughput |
|---|---|---|---|
| S3 | 500 ms | 5K | 2 GB/sec |
| SSD | 1 ms | 100K | 4 GB/sec |
| Network | 100–250 µs | 1.5–12.5 GB/sec | |
| Memory | 250 ns | 100M | 100 GB/sec |
Thanks to these characteristics, the distributed cache, accessed over the network, delivers latencies that fall neatly between SSD and memory. And like the local filesystem cache before it, it solves the core bottleneck of object storage: latency.
It also scales. Because hot table data is now distributed across multiple cache nodes, ClickHouse can fetch blocks in parallel, maximizing throughput. With enough nodes, this compound throughput can rival memory speeds, tens or even hundreds of GB/sec (more on how this works in a bit).
Like its predecessor, the distributed cache brings hot data closer to the query engine, first to SSDs, then straight into compute node RAM, powering the low-latency execution real-time analytics demand.
Built for stateless compute
This architecture allows ClickHouse compute nodes to be diskless, stateless machines, while the distributed cache nodes are disk-optimized and purpose-built to manage and serve hot data at high throughput with low latency.
Per-zone deployment
The distributed cache runs per availability zone to avoid cross-zone traffic and its costs. It can operate as zone-local (lower latency) or cross-zone (higher hit rate, but more latency and cost). The cache is shared across multiple ClickHouse Cloud services, but each is fully isolated with proper authentication and encryption.
Beyond table data
The distributed filesystem cache also serves the same additional roles as the local cache did before: caching table metadata (like secondary data skipping indexes and mark files), storing temporary data (e.g., spill-to-disk), and caching external files (including data lake table files).
How it works
Just like the local per-node filesystem cache before it, the distributed cache uses both read-through caching (to populate itself during queries) and write-through caching (to keep new data hot and query-ready after inserts, and table part merges).
The next animation illustrates read-through caching for the distributed cache in ClickHouse Cloud (click to view in fullscreen):

① Query arrives:
A query reaches the ClickHouse Cloud service. A load balancer selects which compute node will process it.
② Node selection:
The query is routed to a compute node (e.g., node 2). Both node 1 and node 2 have a cold cache for this query initially.
③ Cache lookup and load:
If the needed data isn’t in the compute node’s memory (see “Userspace page cache” below), it’s fetched from the distributed cache. This service runs across multiple dedicated cache nodes in the same availability zone. Each node owns a portion of the hot table data (via consistent hashing), fetches missing blocks from object storage, stores them on local SSD, and transparently, in memory via the OS page cache.
④ Parallel data fetch:
The compute node pulls needed blocks from multiple cache nodes in parallel. As discussed earlier, warm cache data can be fetched with access latencies between SSD and memory, and aggregate throughput can exceed local SSDs, reaching 50–100 GB/s or more.
Instant cache reuse by other nodes
Once warm, the real power of the distributed cache is that any compute node can instantly reuse cached data. If ⑤ the next query is ⑥ routed to another node (e.g., node 1), it can fetch the hot data from the low-latency distributed cache, no high-latency object storage access required.
RAM caching with the userspace page cache
RAM is still the fastest layer, so caching hot data in memory is essential for query speed. Since ClickHouse Cloud compute nodes no longer use local disks for caching, and thus can’t rely on the OS page cache, we introduced the userspace page cache: an in-memory layer for caching data read from or written to the distributed cache or remote files.
This completes the picture: a fully decoupled caching architecture that delivers low latency, scales with parallelism, and supports stateless compute.
Now let’s see how the full caching stack performs, compared to both traditional setups and prior ClickHouse Cloud stages.
Benchmarking hot data caching in ClickHouse
We tested each caching stage to see how it performs in practice.
The distributed cache is still in testing and not fully optimized or scaled, so the results shown here do not yet reflect final production performance.
We tested two queries on the same dataset:
-
Throughput-bound query – A full table scan that tests aggregate read bandwidth.
-
Latency-sensitive query – A small query with scattered, disjoint reads that stress access latency.
We ran these benchmarks across all three cache stages:
-
A shared-nothing self-managed server with SSD.
-
ClickHouse Cloud with traditional local filesystem caching.
-
ClickHouse Cloud with the new distributed filesystem cache.
All setups used similar hardware:
-
Self-managed server: m6i.8xlarge EC2 instance (32 cores, 128 GB RAM).
-
ClickHouse Cloud compute nodes: 30 cores and 120 GB RAM per node.
-
Distributed cache backend: 8 dedicated cache nodes per availability zone.
To ensure hot queries hit only cached data, we used the Amazon reviews dataset, which fits entirely in RAM in compressed form (32 GB):
SELECT
formatReadableQuantity(sum(rows)) AS rows,
round(sum(data_uncompressed_bytes) / 1e9) AS data_size_gb,
round(sum(data_compressed_bytes) / 1e9) AS compressed_size_gb
FROM system.parts
WHERE active AND database = 'amazon' AND table = 'amazon_reviews';┌─rows───────────┬─data_size_gb─┬─compressed_size_gb─┐
│ 150.96 million │ 76 │ 32 │
└────────────────┴──────────────┴────────────────────┘Throughput benchmark: Full table scan
We ran a full table scan using:
SELECT count()
FROM amazon.amazon_reviews
WHERE NOT ignore(*);This scan touches all compressed columns, perfect for testing end-to-end cache throughput.
The next chart shows the results:
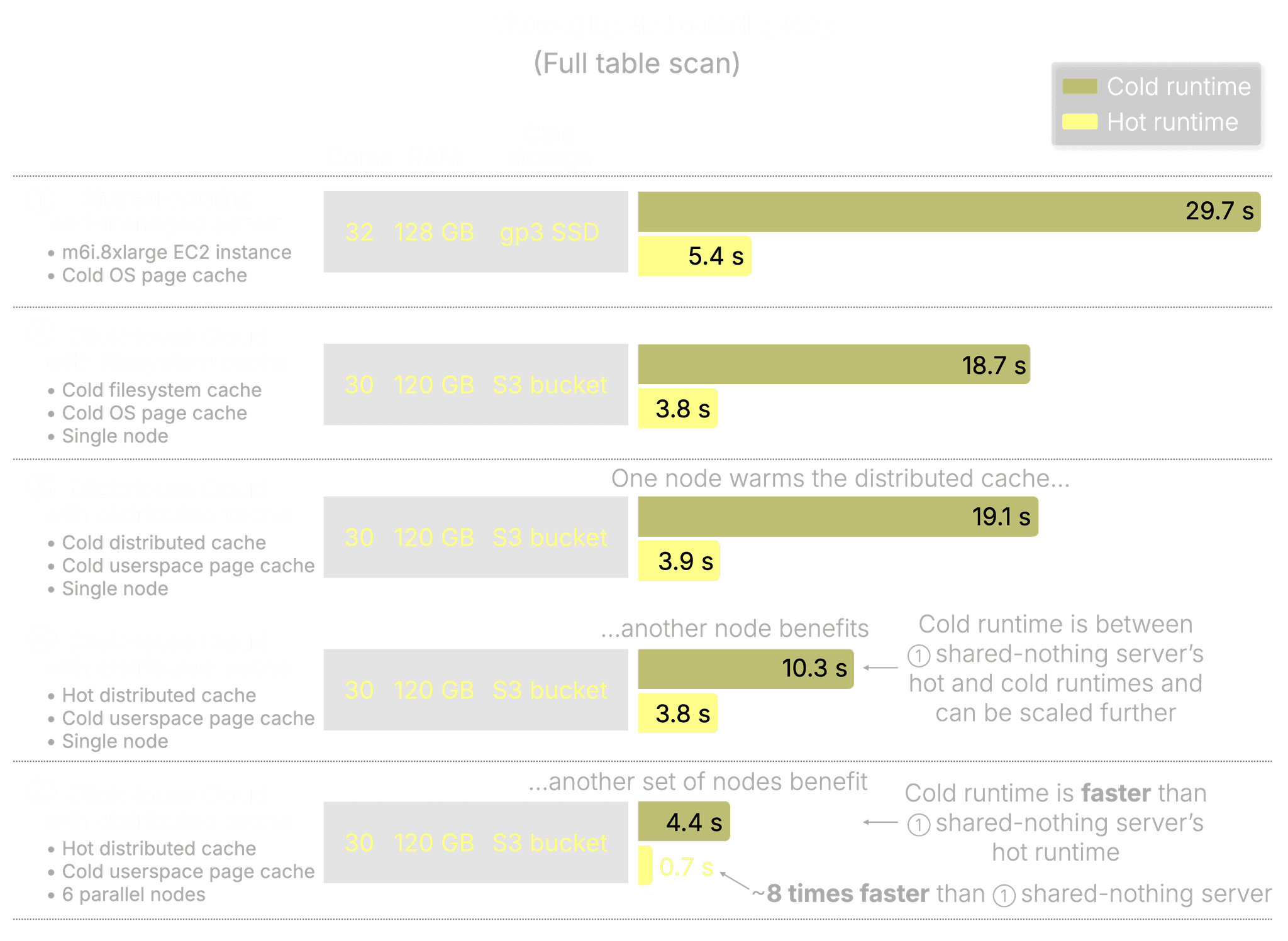
Each of the five configurations below runs the same full table scan. Here’s what they show:
① Shared-nothing self-managed server
Our baseline for SSD + OS page cache. The SSD is a gp3 EBS volume with 16k IOPS and 1000 MiB/s max throughput, the fastest EBS option for this m6i.8xlarge EC2 instance.
-
Cold run: 29.7 s – Full scan from SSD with no cache hits.
-
Hot run: 5.4 s – OS page cache holds all hot data in memory.
② ClickHouse Cloud with local filesystem cache
A single compute node with directly attached SSD acting as a local cache for S3.
-
Cold run: 18.7 s – Despite fetching from object storage, multi-threaded reads and prefetching outperform the full SSD scan in the self-managed setup.
-
Hot run: 3.8 s – OS page cache keeps hot data in memory for fast execution. Note: Core count is similar to ①, with slight performance differences based on CPU model.
③ Distributed cache (initial warm-up)
A single node loads data into a cold distributed cache and its own userspace page cache.
-
Cold run: 19.1 s – Similar to ②.
-
Hot run: 3.9 s – Userspace page cache holds all hot data in memory.
④ Distributed cache (subsequent node)
A second node with a cold userspace page cache fetches hot data from the already-hot distributed cache.
-
Cold run: 10.3 s – No need to hit object storage. Fetches from the distributed cache over the network.
Notably, this is nearly 2× faster than fetching from S3, and around 3× faster than the self-managed SSD setup. This performance can scale even further by adding more cache nodes, increasing parallelism, and saturating available network bandwidth. -
Hot run: 3.8 s – Identical to previous hot userspace page cache setups.
⑤ Distributed cache (6 subsequent parallel nodes)
Six cold-start compute nodes query in parallel, all reading from the hot distributed cache.
-
Cold run: 4.4 s – Faster than ①’s hot run.
-
Hot run: 0.7 s – 8× faster than ①’s hot run thanks to superlinear scaling from parallel reads and shared cache state.
We simply added additional stateless compute nodes to the cluster. That’s it. On a self-managed shared-nothing setup, achieving this level of parallelism would require manual re-sharding and redistributing data across nodes, a complex and time-consuming operation. Scaling back down would require the same all over again. In ClickHouse Cloud, it’s just elastic scaling.
Shared cache + elastic compute = performance that leaves local SSDs behind, even on a cold start.
Latency benchmark: Scattered reads
When queries get smaller, latency, not throughput, becomes the bottleneck. This benchmark uses a small query with scattered, disjoint reads, too little data to saturate I/O, making latency the dominant factor:
SELECT *
FROM amazon.amazon_reviews
WHERE review_date in ['1995-06-24', '2015-06-24', …]
FORMAT Null;For such a query, ClickHouse can’t fan out enough I/O requests to hide latency with bandwidth. Performance depends on how quickly each small read completes.
These are the results:
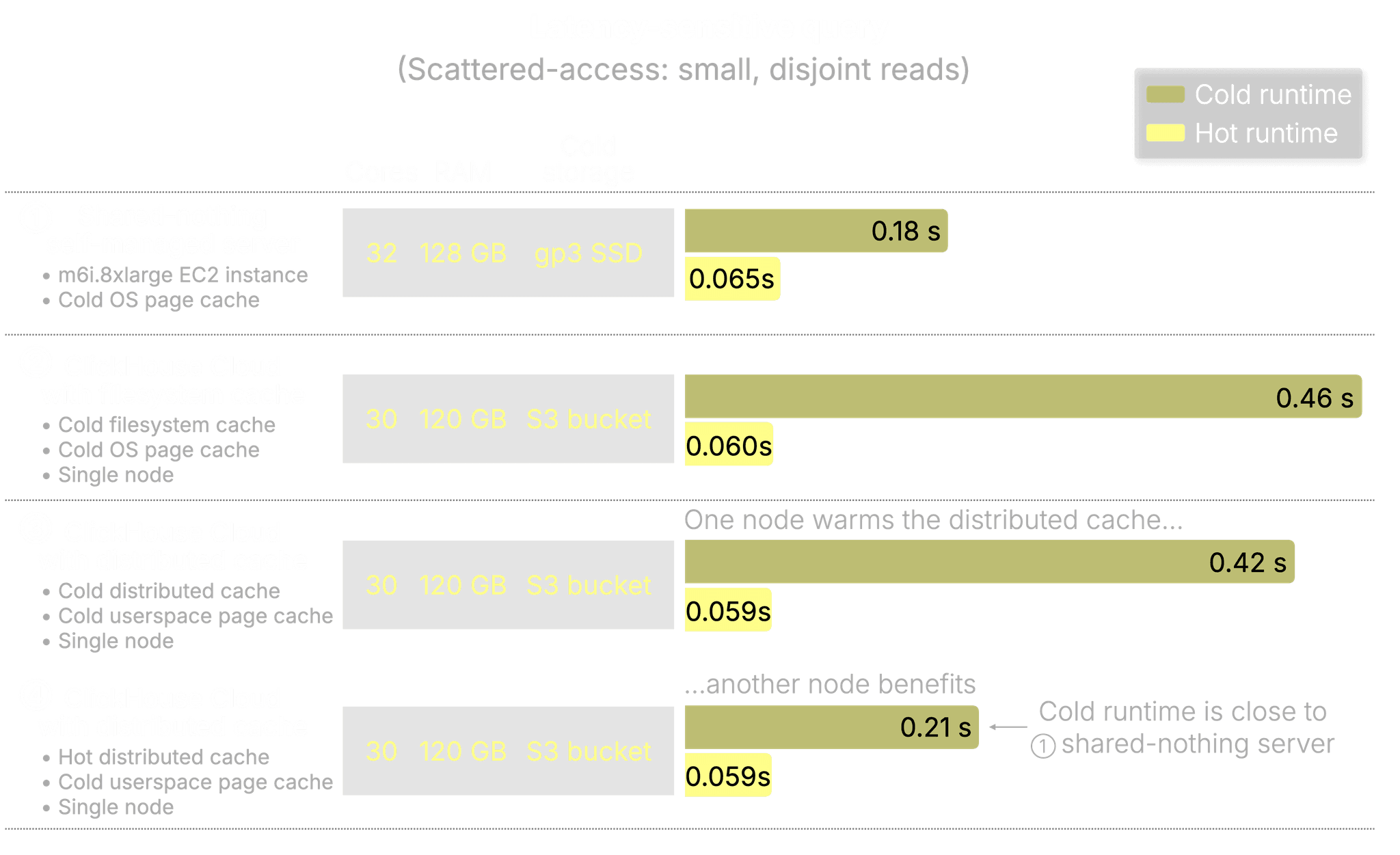
Let’s break down how each setup performed on the latency-sensitive benchmark:
① Shared-nothing self-managed server
The baseline for low-latency access: SSD + OS page cache.
-
Cold run: 0.18 s – Direct reads from SSD.
-
Hot run: 65 ms – Memory-speed access via the OS page cache.
② ClickHouse Cloud with local filesystem cache
One compute node with a local SSD caching S3, plus OS page cache.
- Cold run: 0.46 s – Slower than ① due to initial S3 latency.
Unlike the throughput benchmark above, where multi-threaded reads and prefetching helped ClickHouse Cloud outperform the SSD-based server despite reading from S3, that advantage disappears here. With small, scattered reads, there’s often not enough data to fan out efficiently across I/O threads. Even if the reads are issued in parallel, query performance ends up gated by the tail latency, the slowest individual read. In this case, latency—not bandwidth—becomes the bottleneck, making S3 slower than SSD.
- Hot run: 60 ms – Nearly identical to ①.
③ Distributed cache (initial warm-up)
Both the distributed cache and userspace page cache start cold.
④ Distributed cache (subsequent node)
The distributed cache is hot, but this compute node’s userspace page cache is still cold.
-
Cold run: 0.21 s – Data is pulled from the distributed cache over the network, bypassing S3 entirely.
This is almost as fast as the self-managed shared-nothing server with SSD, without storing anything locally. -
Hot run: 59 ms – Matches the fastest possible path.
We hit both SSD-speed and memory-speed latency with zero local storage.
Impact and what’s next
By decoupling caching from compute, the distributed cache gives ClickHouse Cloud fast, consistent access to hot data across elastic, stateless compute nodes.
It brings:
-
Faster warm-ups: Any compute node can fetch cached data from the distributed cache with much lower latency than object storage, no need to re-download from storage on cold starts.
-
Shared caching effort: Work done by one node benefits all others.
-
Elastic scaling: Add, remove, or resize compute nodes at will, without losing cached data.
-
Stateless compute: No need to persist data locally or rebuild caches after restarts.
Benchmarks on a test dataset demonstrate how this translates into real performance gains, with two key wins:
-
Throughput: In full-table scans, cold queries ran up to 4× faster than a self-managed SSD setup, thanks to shared caching and parallel fetch across compute nodes.
-
Latency: For small scattered reads, cold queries matched SSD performance; hot queries hit sub-60 ms memory-speed latency. All without local storage.
These results show that cloud-native caching can deliver SSD-grade performance, or better, without relying on local disks. It’s a foundational shift that makes ClickHouse Cloud faster, more elastic, and simpler to operate, especially in dynamic, high-concurrency environments.
The distributed cache currently supports S3 and GCS. Support for Azure Blob Storage is on the way.
Ready to try it? We’re now opening access to the distributed cache private preview. Get early access and help shape the future of low-latency analytics.



