TL;DR
ClickHouse sidesteps the performance challenges of row-level updates by treating updates as inserts. In this first post of our update deep-dive, we explore purpose-built engines that make it fast.
In Part 2, we show how we brought SQL-style UPDATE to ClickHouse, without compromising performance.
-
This part: Purpose-built engines
Learn how ClickHouse sidesteps slow row-level updates using insert-based engines like ReplacingMergeTree, CollapsingMergeTree, and CoalescingMergeTree. -
Part 2: Declarative SQL-style UPDATEs
Explore how we brought standard UPDATE syntax to ClickHouse with minimal overhead using patch parts. -
Part 3: Benchmarks
See how fast it really is. We benchmarked every approach, including declarative UPDATEs, and got up to 1,000× speedups. -
Bonus: ClickHouse vs PostgreSQL
We put ClickHouse’s new SQL UPDATEs head-to-head with PostgreSQL on identical hardware and data—parity on point updates, up to 4,000× faster on bulk changes.
Making updates fast without using UPDATE
Column stores weren’t built for row-level updates.
ClickHouse was no exception: it’s designed for speed at scale, optimized for fast inserts and lightning-fast analytics, not for modifying individual rows.
But real-world workloads don’t always play by the rules.
ClickHouse users often deal with fast-changing data: IoT (sensor readings), e-commerce (orders and inventory), finance (payment status), gaming (player stats), and CRM/HR (user or employee profiles), data that needs to be corrected, updated, or deleted. Rather than force slow UPDATE operations into a system designed for big reads, we took a different path:
We sidestepped the update problem by treating updates as inserts.
This isn’t a workaround; it’s a deliberate design choice. Engines such as ReplacingMergeTree, CoalescingMergeTree, and CollapsingMergeTree let ClickHouse handle updates and deletes by writing new rows instead of modifying existing ones. They exploit ClickHouse’s high insert throughput and background merge process, avoiding the performance penalties of in-place updates.
These engines still solve real problems at scale and are often the best fit for high-ingest, rapidly mutating workloads. They also inspired the next generation of update mechanics, so understanding how they work helps explain how ClickHouse makes SQL-style updates fast, too.
What this series covers
-
In this post (Part 1), we’ll explore how purpose-built engines work, and why they’re still so effective.
-
In Part 2, we’ll turn to declarative, standard SQL-style UPDATE, powered by a new mechanism called patch parts.
-
And in Part 3, we’ll benchmark all approaches to see how they stack up.
To understand how ClickHouse makes updates fast, it helps to start with why updates are hard in column stores to begin with.
Why updates are hard in column stores
In database systems, updates and analytics pull in opposite directions; what’s fast for one tends to be slow for the other.
In row stores (like PostgreSQL or MySQL):
-
Each row is stored contiguously on disk.
-
This makes updates easy, you can overwrite a row in place.
-
But analytical queries suffer: even if you need just two columns, the entire row must be loaded into memory.
In column stores (like ClickHouse):
-
Each column is stored in a separate file.
-
This makes analytics blazing fast, only the columns you query are read.
-
But updates are harder because each column is stored separately, modifying a row means touching multiple files and rewriting fragments.
This tradeoff has long made efficient row-level updates a challenge for columnar systems.
Let’s look at the first ClickHouse solution: purpose-built engines that tackle updates differently, by avoiding them entirely.
Inserts are so fast, we turned updates into inserts
The core idea is simple: ClickHouse is especially optimized for insert workloads. Because there are no global structures to lock or update (e.g., a global B++ index), inserts are fully isolated, run in parallel without interfering with each other, and hit disk at full speed (in one production setup, over 1 billion rows per second). This also means insert performance stays constant, no matter how large the table grows. Additionally, inserts stay lightweight: all the extra work, like resolving record updates, is decoupled and deferred to background merges.
The trick: because inserts are so fast and efficient, ClickHouse can treat updates (and even deletes) as just more inserts.
In high-throughput scenarios like IoT, the classic SQL-style UPDATE can be inefficient: even in a typical RDBMS, an UPDATE requires locating the row with the previous state, rewriting it, and often locking or rewriting more data than necessary.
With purpose-built engines like ReplacingMergeTree, CoalescingMergeTree, and CollapsingMergeTree, ClickHouse uses a more efficient inserts-only model that skips locating the row with the previous state entirely. Even updates and deletes are expressed as fast, lightweight inserts, while the actual data modifications happen later via background merges.
Why this works so well: ClickHouse is already continuously merging smaller data parts into larger ones in the background; it’s right there in the name, MergeTree. These merges load the relevant data into memory, consolidate it, and write out a new part. Since the engine is already doing this work, handling updates or deletes during a merge adds minimal overhead. Keeping only the latest version of a row or removing a canceled one is practically free.
This lightweight, insert-and-merge flow is only possible because of how ClickHouse organizes data on disk: into sorted and immutable data parts that are constantly merged in the background.
Understanding parts and merges
To understand how ClickHouse makes updates fast, and to follow the diagrams and mechanics in this (and the next) post, it helps to know what everything is built on: parts.
Inserts create sorted and immutable parts
Every time you insert data into a ClickHouse table, it’s written as a self-contained, immutable data part on disk.
Each part contains rows (stored by column) and is named to reflect where it fits in the insert and merge history. For example, after this insert into an initially empty orders table with columns order_id, item_id, quantity, price, and discount:
INSERT INTO orders VALUES
(1001, 'kbd', 10, 45.00, 0.00),
(1001, 'mouse', 6, 25.00, 0.00);ClickHouse creates a new part named all_1_1_0:

Inside the part, rows are physically sorted on disk by the table’s sorting key, in this case, (order_id, item_id). That’s true for every part in a MergeTree table and is critical for how ClickHouse can merge parts efficiently without random I/O or re-sorting.
How to read a part name
Each part name follows the format partition_minBlock_maxBlock_mergeLevel. In this case:
-
all – partition ID (default in this case)
-
1 – minimum block number in the part (explained below)
-
1 – maximum block number in the part (also explained below)
-
0 – merge level (0 = initial insert, higher = merged)
What’s inside a part
Under the hood, this part is a folder on disk named all_1_1_0. It contains one file per column in the table: order_id, item_id, quantity, price, and discount. Each of these files is compressed and stores the column’s values for the rows in that part.
We’ve sketched these column files in the diagram above to show how the data is laid out inside the part.
How blocks make up a part
ClickHouse inserts data in blocks of rows, and each block is assigned a monotonically increasing block number. A part contains one or more of these blocks, either from a single insert or from merging multiple parts. The minBlock and maxBlock in the part name reflect the range of blocks in that part.
Merges happen in the background
As new inserts arrive, ClickHouse doesn’t modify existing parts, it simply writes more. In the background, it merges them into larger parts to control part counts and consolidate data.
Merges are fast thanks to sorted parts
ClickHouse can merge parts with remarkable efficiency because all parts are already sorted by the same columns. When two parts are merged, the engine simply interleaves their data in a single linear scan of both parts, no re-sorting, no random access, no temporary buffers are required.
This is known as a single merge pass: ClickHouse reads both parts in order, compares rows on the fly, and writes out a new, merged part. It’s one of the core reasons merges are so fast and lightweight.
That efficiency makes it possible to handle updates and deletes during merges with minimal overhead, they just become part of the same scan-and-write process.
Now that we understand the foundation, let’s see it in action, starting with the most straightforward engine: ReplacingMergeTree.
ReplacingMergeTree: Replace rows by inserting new ones
To demonstrate ReplacingMergeTree, we’ll use a simple orders table from a hardware store scenario:
CREATE TABLE orders (
order_id Int32,
item_id String,
quantity UInt32,
price Decimal(10,2),
discount Decimal(5,2)
)
ENGINE = ReplacingMergeTree
ORDER BY (order_id, item_id);To update a row, simply insert a new version with the same sorting key (order_id, item_id). During background merges, ClickHouse will retain the most recent version (the one inserted last).
For example, imagine a customer ① initially ordered 10 keyboards and 6 mice at full price:
INSERT INTO orders VALUES
(1001, 'kbd', 10, 45.00, 0.00),
(1001, 'mouse', 6, 25.00, 0.00);Later, they increased their mice order to 60 units, qualifying for a 20% bulk discount. Instead of modifying the old row, we ② insert a new one with the updated quantity and discount:
INSERT INTO orders VALUES
(1001, 'mouse', 60, 25.00, 0.20);The diagram below shows the data parts created by the initial insert (①) and the update insert (②). During the next background merge ③, ClickHouse automatically keeps the latest version and discards the outdated one:
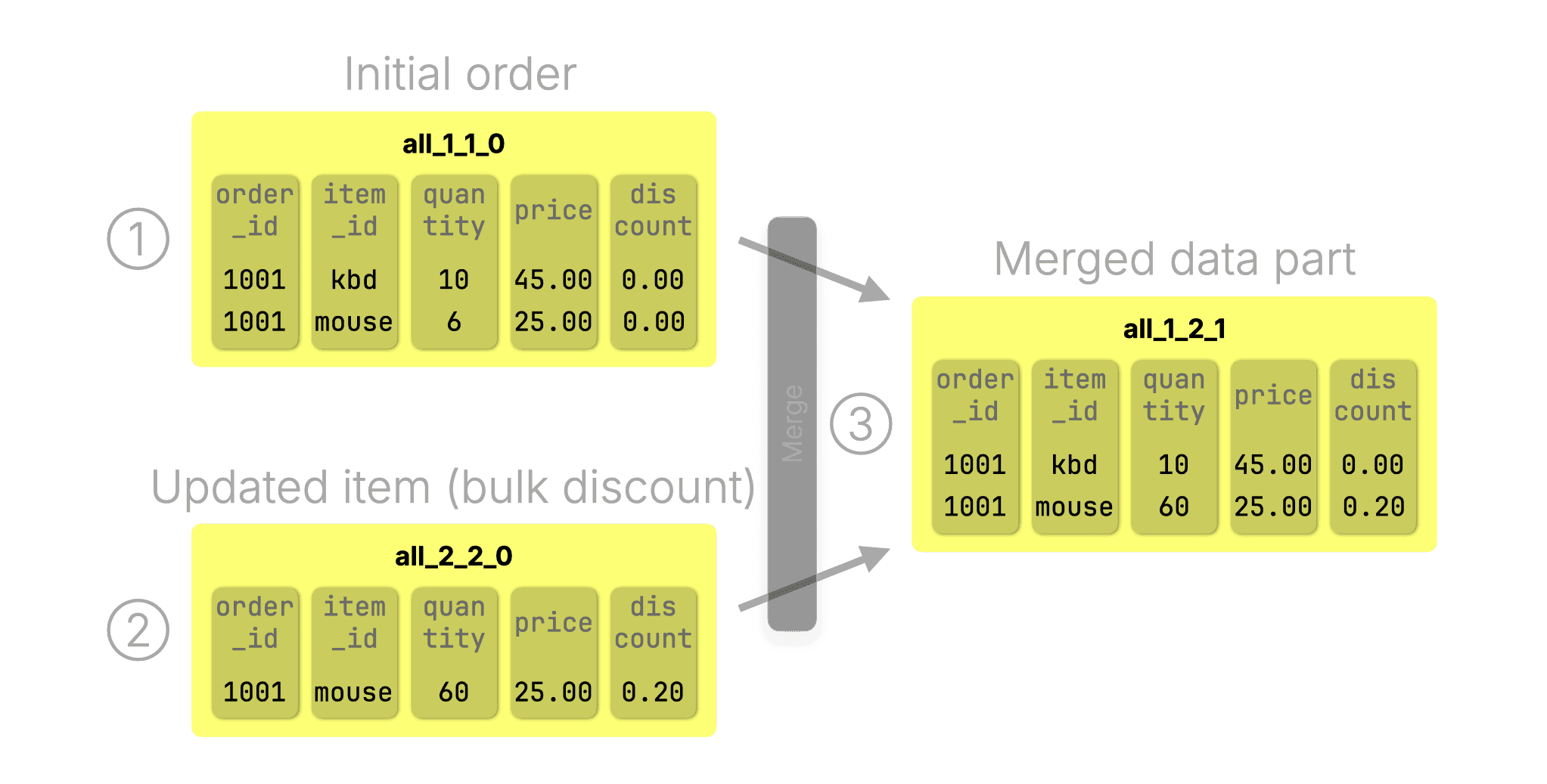
After the merge, parts ① and ② are discarded, and part ③ becomes the active data part for the table.
What if you only want to change a few columns? That’s where CoalescingMergeTree comes in.
CoalescingMergeTree: Consolidate partial updates automatically
CoalescingMergeTree works just like ReplacingMergeTree, but with one key difference: it supports partial updates. Instead of providing the full row, you can insert only the changed columns.
We are using the same orders table:
CREATE TABLE orders (
order_id Int32,
item_id String,
quantity Nullable(UInt32),
price Nullable(Decimal(10,2)),
discount Nullable(Decimal(5,2))
)
ENGINE = CoalescingMergeTree
ORDER BY (order_id, item_id);Note: The non-key columns are marked as Nullable so we can skip them during partial updates. This lets us insert only the fields that have changed, and leave the rest as NULL.
Again, a customer ① initially ordered 10 keyboards and 6 mice at full price:
INSERT INTO orders VALUES
(1001, 'kbd', 0, 45.00, 0.00),
(1001, 'mouse', 6, 25.00, 0.00);② We insert a new row with partial updates (quantity and discount):
INSERT INTO orders VALUES
(1001, 'mouse', 60, NULL, 0.20);A background merge of ① the initial insert and ② the update insert produces ③ a new active data part where ClickHouse keeps the latest non-null value for each column, consolidating sparse updates into a complete row. After the merge, parts ① and ② are discarded, just like in ReplacingMergeTree:
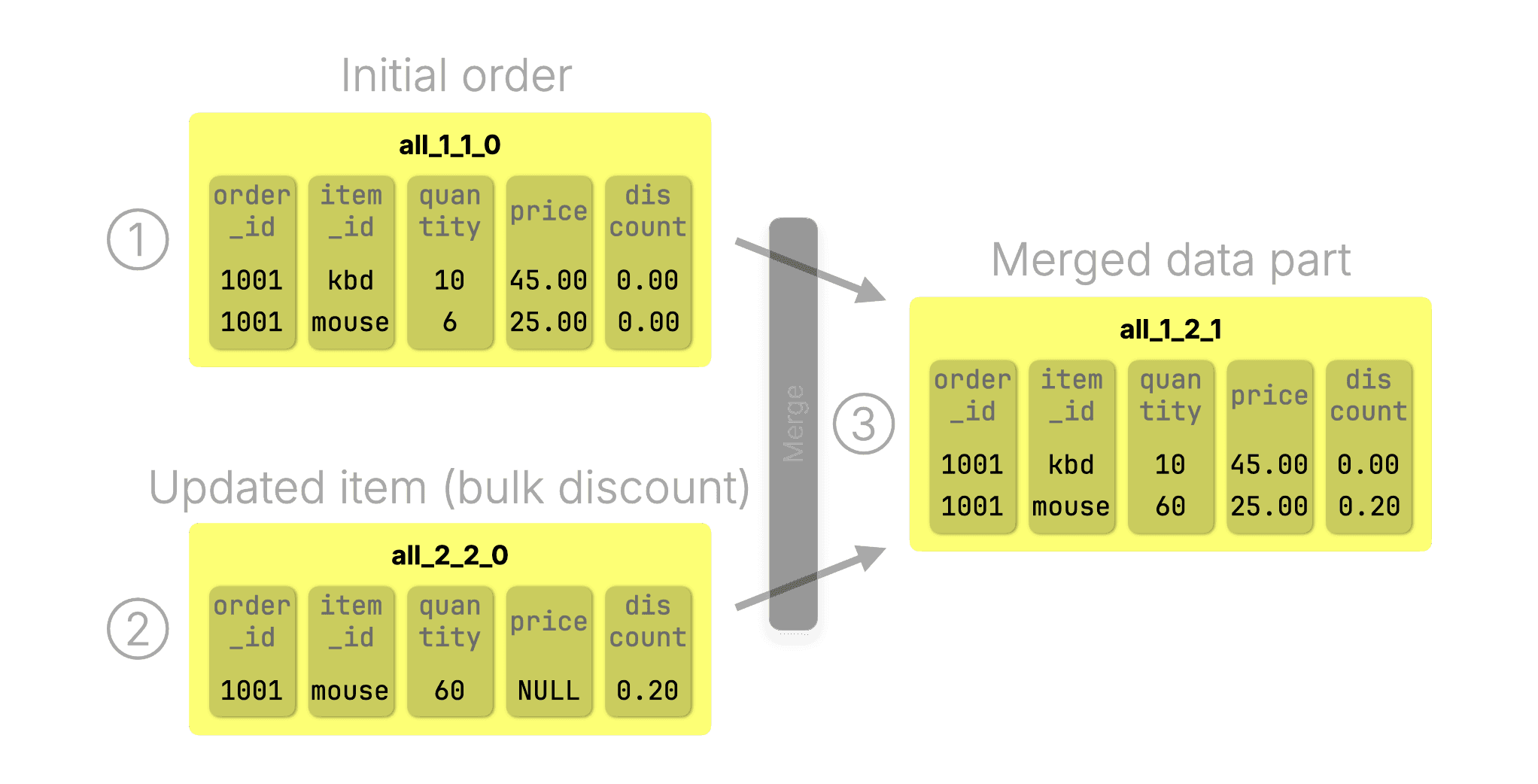
Learn about typical use cases and what’s happening under the hood in CoalescingMergeTree.
And what about deletes? CollapsingMergeTree handles them with a clever twist.
CollapsingMergeTree: Delete a row by inserting a row
CollapsingMergeTree lets you delete data without ever issuing a DELETE. Instead, you insert a special “cancelling” row that marks the original as invalid.
Here’s the same simple orders table again, this time with an additional is_valid column used as the engine’s sign parameter:
CREATE TABLE orders (
order_id Int32,
item_id String,
quantity UInt32,
price Decimal(10,2),
discount Decimal(5,2),
is_valid UInt8 -- only required for CollapsingMergeTree
)
ENGINE = CollapsingMergeTree(is_valid)
ORDER BY (order_id, item_id);① The initial order:
INSERT INTO orders VALUES
(1001, 'kbd', 10, 45.00, 0.00, 1),
(1001, 'mouse', 6, 25.00, 0.00, 1);② We remove an item by inserting a matching row (only the sorting key columns matter, rest can be NULL) with is_valid = -1:
INSERT INTO orders VALUES
(1001, 'mouse', NULL, NULL, NULL, -1);During the ③ next merge, ClickHouse finds both the +1 and -1 rows for the same sorting key (order_id, item_id) and collapses them, removing both rows and discarding parts ① and ② in the process:
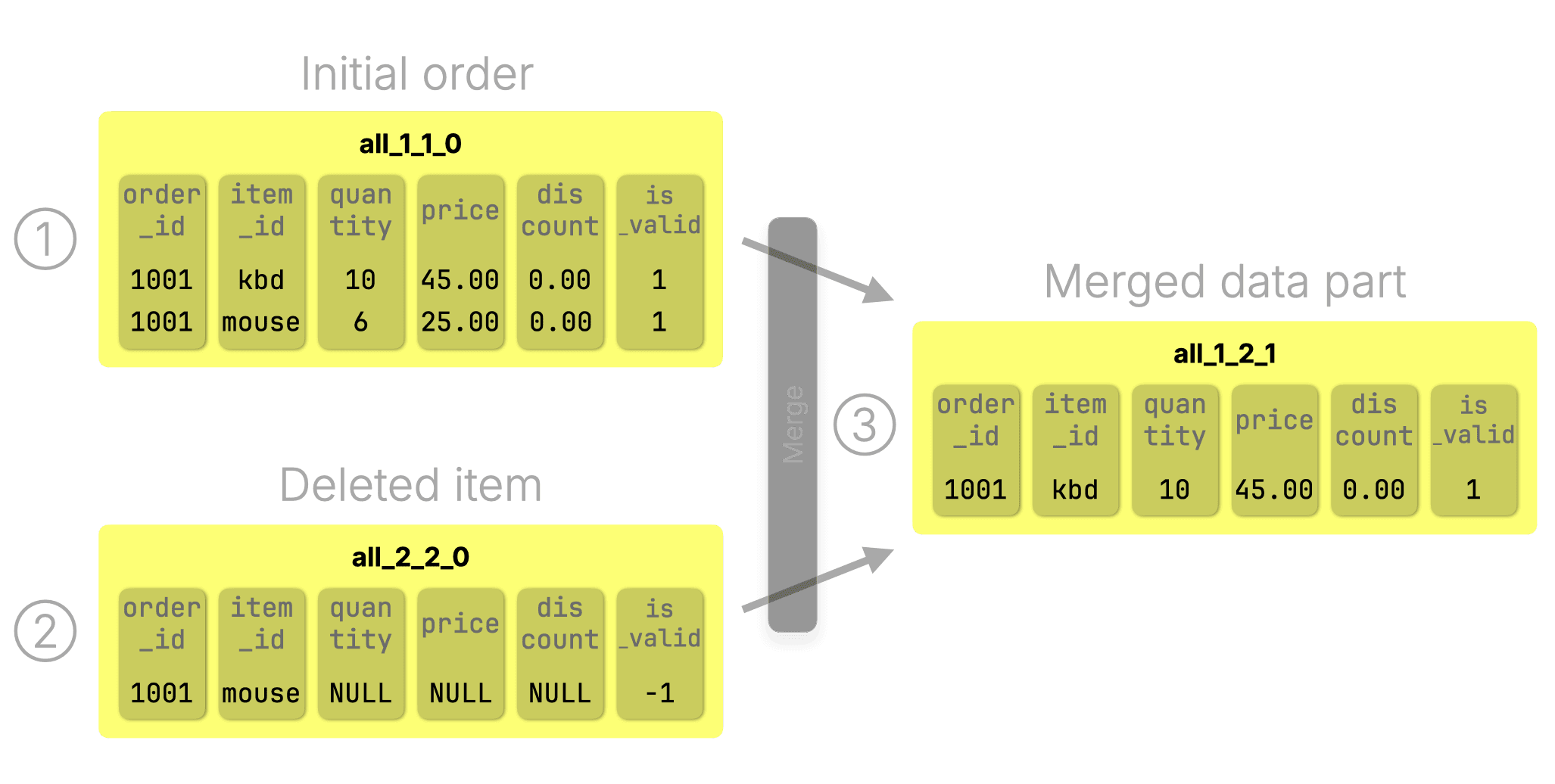
This same mechanism also supports updates: to update a row, you insert a cancelling row followed by a new one with the updated values. During the next background merge, ClickHouse collapses the old and cancelling rows and retains only the new version.
This even allows you to update sorting key values, a unique capability of CollapsingMergeTree that’s not possible with ReplacingMergeTree or CoalescingMergeTree.
And it’s not just upades and deletes, all three engines also support UPSERTs.
Bonus: built-in UPSERT behavior
All three engines, ReplacingMergeTree, CoalescingMergeTree, and CollapsingMergeTree, support what is effectively an UPSERT (insert-or-update) operation: insert a new row, and if a match exists (by sorting key), the engine will apply the right logic to update.
This kind of insert-or-update pattern is a powerful capability, something standard UPDATE doesn’t support directly.
SQL does define a MERGE command for this, but it’s verbose and less efficient in practice. In ClickHouse, it’s just a fast insert.
This insert-based model gives us efficient updates, deletes, and upserts. But what if you need the query side to catch up before merges do?
Getting up-to-date results with FINAL
All three engines described above use merges to consolidate data in the background. That makes insert-based updates and deletes highly efficient, but also eventually consistent: merges may lag behind when ingest is heavy (i.e., merges run continuously, but inserts may outpace them, think of it as a lagging consolidation window).
To ensure query accuracy despite this, ClickHouse lets you apply the table engine’s merge logic on the fly using the FINAL modifier:
SELECT * FROM orders FINAL;This doesn’t trigger a real merge on disk; instead, it performs an in-memory consolidation of all relevant data parts as they existed when the query began, returning fully merged rows.
It works consistently across all three engines:
- With ReplacingMergeTree, it keeps the latest version of each row.
- With CoalescingMergeTree, it coalesces sparse updates into full rows.
- With CollapsingMergeTree, it applies the cancelation logic to collapse deletes and provide updates.
FINAL gives you predictable, up-to-date results when you need them, while preserving the raw speed of insert-based processing.
No need to fear FINAL
ClickHouse optimizes FINAL with intelligent in-memory algorithms, selective part processing (skipping unnecessary merges), and vectorized execution, making on-the-fly consolidation fast, even on large datasets. ClickHouse avoids merging part ranges that don’t contain conflicting rows, skipping unnecessary work. Columns are processed independently and in parallel, reducing memory usage and boosting performance, especially on wide tables.
So you get the right answer. But is it really an UPDATE? Let’s take a step back.
How different is this from a “real” update?
If you zoom out, you’ll notice something familiar. ClickHouse updates follow the same rhythm as a traditional row-store: write a new version, then read the new version:
| Traditional row store | ClickHouse |
|---|---|
| Overwrites the old row in place | Appends a new version next to the old one |
| Queries read the new version immediately | Queries read the new version immediately |
| Old version is gone once the write commits | Old version is removed later during background merges |
So while the mechanics are different, especially in how cleanup is deferred, the update semantics are strikingly similar.
However: to get that familiar result, you have to think like a ClickHouse engineer. That means understanding background merges, knowing when to use FINAL, and choosing the right engine. You also have to model each update as a new row insert, and often shape your schema around engine-specific behaviors. For example, ReplacingMergeTree only lets you update rows by their sorting key, and if that key changes, you’ll need to recreate the table.
That’s not how users coming from traditional SQL databases expect updates to work.
From engine semantics to SQL simplicity
These purpose-built engines are incredibly efficient, but they come with tradeoffs. They offer speed and flexibility, but not the simplicity of standard SQL. Users have to reason about merges, sorting keys, and engine-specific behaviors.
So ClickHouse evolved.
In Part 2, we’ll show how we brought fast SQL-style UPDATE to ClickHouse, without compromising performance.
We’ll walk through the full evolution: from classic “heavy” mutations, to lightweight on-the-fly updates, and finally to fast, declarative updates powered by patch parts, a scalable new mechanism inspired by the engines we just explored, but fully generalized and wrapped in familiar SQL syntax.
It’s everything users expect from UPDATE, just optimized the ClickHouse way.



