While the weather in the Northern Hemisphere seems undecided about Spring, there's no confusion about it being time for the March ClickHouse newsletter.
This month, the Postgres CDC connector for ClickPipes went into Public Beta, and we announced general availability for Bring Your Own Cloud on AWS. We’ve got the latest on ClickHouse support for Apache Iceberg, how to build a ClickHouse-based data warehouse for contact center analytics, visitor segmentation with Theta Sketches, and more!
Featured community member: Matteo Pelati #
This month's featured community member is Matteo Pelati, Co-Founder at LangDB.

Before founding LangDB, Matteo held senior leadership positions at Goldman Sachs as Global Head of Product Data Engineering and at DBS Bank as Executive Director of Data Platform Technology, where he led a team of over 130 engineers building bank-wide data platforms.
LangDB is a full-featured and managed AI gateway that provides instant access to 250+ LLMs with enterprise-ready features. It uses ClickHouse as its foundational data store, where all AI gateway data, traces, and analytics are stored. It also leverages ClickHouse's custom UDF functionality to enable direct AI model calls from SQL queries, seamlessly integrating structured data analytics and AI capabilities.
Mateo recently presented on LangDB at the ClickHouse Singapore meetup, where he demonstrated how organizations can leverage this integration to build sophisticated AI applications while maintaining complete control over their data infrastructure and analytics pipeline.
Upcoming events #
It’s just over two months until our biggest event of the year - Open House, The ClickHouse User Conference in San Francisco on May 28-29.
Join us for a full day of technical deep dives, use case presentations from top ClickHouse users, founder updates, and conversations with fellow ClickHouse users. Whether you're new to ClickHouse or an experienced user, there's something for everyone.
Global events #
- v25.3 Community Call - Mar 20
Free training #
- In-Person ClickHouse Developer - Sydney - March 24-25
- Treinamento Presencial ClickHouse Developer - São Paulo, Brasil, March 25-26
- In-Person ClickHouse Developer - Melbourne - March 27-28
- In-Person ClickHouse Developer Fast Track - Bangalore - April 1
- BigQuery to ClickHouse Workshop - Virtual - April 1
- ClickHouse Developer In-Person Training - Vienna, Austria - April 7-8
- Using ClickHouse for Observability - Virtual - April 15
- ClickHouse Fundamentals - Virtual - April 22
Events in AMER #
- ClickHouse Meetup @ Klaviyo, Boston - March 25
- ClickHouse Meetup in São Paulo - March 25
- ClickHouse Meetup @ Braze, New York - March 26
- ClickHouse Launching Meetup in DC - March 27
- Google Next, Las Vegas - April 9
- Open House User Conference, San Francisco - May 28-29
Events in EMEA #
- ClickHouse Meetup in Zurich - March 24
- ClickHouse Meetup in Budapest - March 25
- KubeCon 2025, London - April 1-4
- ClickHouse Meetup in Oslo - April 8
- AWS Summit 2025, Paris - April 9
- AWS Summit 2025, Amsterdam - April 16
- AWS Summit 2025, London - April 30
Events in APAC #
- ClickHouse Delhi Meetup, India - Mar 22
- ClickHouse Sydney Meetup - April 1
- Latency Conference, Australia - Apr 3-4
- TEAMZ Web3/AI Summit, Japan - Apr 16-17
25.2 release #

ClickHouse 25.2 delivers more performance gains for joins. The parallel hash join system has been further optimized to ensure 100% CPU core utilization. Tom Schreiber explains how this was achieved.
The release also introduces Parquet Bloom filters, a new backup database engine, integration with the Delta Rust Kernel, enhanced HTTP streaming capabilities for real-time data consumption, and more!
Postgres CDC connector for ClickPipes is now in Public Beta #

The Postgres CDC connector for ClickPipes is now in public beta, enabling seamless replication of PostgreSQL databases to ClickHouse Cloud with just a few clicks.
The connector features high-performance capabilities, including parallel snapshotting for 10x faster initial loads and near real-time data freshness.
Successful implementations are already running at organizations like Syntage and Neon, handling terabyte-scale migrations. During the public beta period, this powerful integration tool is available free of charge to all users.
ClickHouse & Grafana for High Cardinality Metrics #
Tomer Ben David explores how ClickHouse and Grafana can effectively handle high cardinality metrics - a common challenge when tracking data across numerous unique dimensions like individual user sessions, container IDs, or geographical locations.
The article details how ClickHouse's columnar storage, vectorized query execution, and efficient compression capabilities make it ideal for processing large volumes of granular data. Grafana provides powerful visualization, templating features, and alerting to make this data actionable.
Tomer also offers practical strategies for managing high cardinality, including data aggregation techniques, dimensionality reduction, and pre-aggregation at the source.
Climbing the Iceberg with ClickHouse #

Melvyn Peignon explores ClickHouse's evolving role in the data lake and lakehouse ecosystem, highlighting three key integration patterns: data loading from data lakes, ad-hoc querying, and frequent querying of lake data.
He also outlines ClickHouse's 2025 roadmap for lakehouse integration, focusing on three main areas: enhancing user experience for data lake queries through expanded catalog integrations, improving capabilities for working with data lakes, including write support for Iceberg and Delta formats, and developing an Iceberg CDC Connector in ClickPipes.
How Cresta Scales Real-Time Insights with ClickHouse #
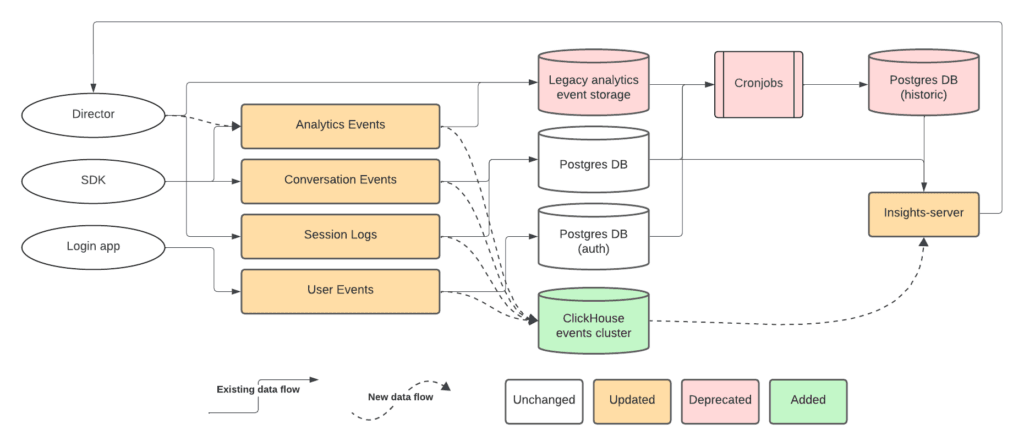
Xiaoyi Ge, Daniel Hoske, and Florin Szilagyi wrote a blog post describing Cresta’s implementation of ClickHouse as its primary data warehouse solution for processing contact center analytics. After migrating from PostgreSQL, it achieved a 50% reduction in storage costs while handling tens of millions of daily records across three dedicated clusters for real-time aggregation, raw event storage, and observability.
The platform now powers Cresta's Director UI, enabling enterprise customers to query billions of records with flexible time ranges while maintaining responsive performance for real-time contact center insights.
They also shared key optimization strategies, including careful schema design to align with query patterns, leveraging materialized views for frequent queries, and utilizing ClickHouse's sparse indexes and bloom filters to accelerate specific queries.
Announcing General Availability of ClickHouse BYOC (Bring Your Own Cloud) on AWS #

BYOC (Bring Your Own Cloud) on AWS is generally available, allowing enterprises to run ClickHouse Cloud while keeping all their data within their own AWS VPC environment.
This deployment model, part of a five-year strategic collaboration with AWS, enables organizations to maintain complete data control and security compliance while benefiting from ClickHouse's managed service capabilities.
Postgres to ClickHouse: Data Modeling Tips V2 #

Lionel Palacin and Sai Srirampur provide a comprehensive guide on migrating data from PostgreSQL to ClickHouse using Change Data Capture (CDC). The article explains how ClickPipes and PeerDB enable continuous tracking of inserts, updates, and deletes in Postgres, replicating them to ClickHouse for real-time analytics while maintaining data consistency through ClickHouse's ReplacingMergeTree engine.
The authors detail several strategies for optimizing performance, including deduplication approaches using the FINAL keyword, views, and materialized views. They also explore advanced topics like custom ordering keys, JOIN optimizations, and denormalization techniques using refreshable and incremental materialized views.
Quick reads #
- Coroot has added support for the ClickHouse native and ZooKeeper protocols, making it much easier to observe these distributed systems.
- Keshav Agrawal demonstrates how to build a scalable real-time data pipeline combining Go for data generation, Kafka for message queuing, ClickHouse for high-performance storage, and Apache Superset for visualization, providing a complete solution for processing both streaming and batch data.
- After finding Grafana's Loki inadequate for web log analysis, Scott Laird documents his migration to ClickHouse. His guide provides step-by-step instructions for setting up ClickHouse with proper authentication, creating an appropriate schema for Caddy's JSON logs, and configuring Vector as the data pipeline middleware to transform and stream logs into ClickHouse.
- A tutorial by sateesh.py demonstrates how to build a modern ETL pipeline combining Apache Spark for data processing, MinIO for S3-compatible storage, Delta Lake for data storage, and ClickHouse for fast analytical querying, complete with code examples.
- Hellmar Becker demonstrates how to use ClickHouse's theta sketches for visitor segmentation and set operations, efficiently counting unique visitors across different content segments while also performing more complex operations like intersections and unions.
Post of the month #
My favorite post this month was by Chris Elgee, who likes ClickHouse’s compression functionality.