First coding models and agents are just one year old, and today there are polarized opinions about the use of agentic coding in practice. Some people will tell you that agents will take over all our jobs, and some will tell you that coding agents are totally useless. Some people hate AI for reasons, and there are people who have long gone into AI-psychosis. And if you read the news, it does not help either: every day it is a kaleidoscope of new frontier models, more advanced tools, new research and breakthroughs, tremendous results on benchmarks, and at the same time, low-quality code, security vulnerabilities, studies showing negative economic impact, and modest results of autonomous agents on real jobs. In many companies, leadership tries to mandate the use of AI, while employees feel confused and insecure.
I want to avoid this confusion and make it clearer. We use coding agents in ClickHouse, and they are a great tool for certain scenarios.
Note: I don't use AI for writing texts, because I don't like it. I write texts very slowly, but it's my approach.
Safe assumptions
Before we start, let me make some assumptions. These assumptions are likely incorrect, and it is difficult to reason about them, but taking them lets us remain sane in further discussion.
Large language models are not sentient. They don't have consciousness, qualia, or a soul. AGI is not going to happen soon, nor is superintelligence. Safe AI does not exist and is not possible. AI will not replace all the jobs. It will replace some of them. Maybe it will replace your job, though if you are reading this article, it is less likely.
Why now?
Claude Code appeared in February 2025. When I tested it a year ago, it had limited use. It could successfully generate small JavaScript applications, especially those written many times before, and it can write one-off Python and shell scripts. It helped me with various boilerplate tasks in small repositories, e.g., ClickBench. But when I tried it on our main C++ code base it got lost and produced undesirable code.
Anyway, there are many such boilerplate tasks, and even one year ago, the agents were useful - we needed them in the company. So we signed contracts with Anthropic, Windsurf, and Cursor (it took some time to resolve all legal and security questions, and many questions required reconciliation inside the company).
We started using it, not only for boilerplate, but for vibe-coding internal tools, such as performance tests and release status dashboards. We also introduced our own agents: DWAINE, CAISER, and TRAISA (the names are weird, because they were AI-generated), plus an agent in the SQL console and AI SRE, and it was so difficult to stop that we acquired Librechat and Langfuse for AI observability.
Claude Sonnet 4.5 (Sept 2025) was a big step in quality - as an example, the Team Productivity Dashboard was built in a session with 112 prompts, which I also recorded, so you can navigate through all the steps.
Even then, it was doubtful for the main ClickHouse C++ code base. In October 2025, at the all-company offsite, we were discussing mostly sporadic usage examples of agents for very limited tasks, and half of the team didn't use coding agents ever before. So the question - are coding agents good for the backend C++ development?
It's easy to be skeptical
There is a common story - if you tried an agent half a year ago on your precious code base, it didn't solve the task and produced bad code, and you went disappointed... Similarly, if you open an agent and type "prove the Riemann hypothesis", you might be disappointed - AI is not that good (yet).
So you might think - okay, agents are good at JavaScript, but are they good at my precious backend code? Okay, agents are good at backend code in Python, but am I safe handcrafting my code in Rust? Okay, agents are good at server-side code in Rust, but for sure, they can't replace me, painstakingly avoiding segmentation faults in my hairy C++ code base for managing nuclear plants? Please don't think so - today there are no exceptions, everyone is affected.
My impression of what coding agents can do changed with the introduction of Claude Opus 4.5 in November 2025. I tried it on simple, over-specified tasks in ClickHouse's C++ source, then tried on investigation of bug reports from the CI logs, then tried it on small features... It exceeded my expectations every time. Since Opus 4.5, agents have been fully usable for daily work on large C++ code bases.
Year 2025 was revolutionary for coding agents with the introduction of these tools and models, and year 2026 has a chance to become a year of productivity, as we now have extremely capable models and mature tools ready for everyday work. It was okay to be skeptical in 2025, but skeptics won't survive 2026.

Levels of AI coding
Agentic coding is a case of AI-assisted coding, and there are three levels of it:
Level 1, a.k.a. "copy-pasting from ChatGPT": Asking a model and copy-pasting code snippets from a chat. This is a valid case of AI-assisted coding, and it is still okay for exploration. You might have been using it since 2023. But compared to agents, it is obsolete.
Level 2: using agents in the command line or in your IDE, either hand-holding agents or vibe coding. We are here.
Level 3: running multiple agents in isolated environments, running loops with automatic feedback, spec-driven development, orchestrating multi-agent setups... We do have a few examples of autonomous coding agents at ClickHouse, but we are just approaching this level. Tools for this type of work only start to emerge, and the results of long autonomous loops can be dubious.
Available tools
We have plenty of tools available in the company. For CLI agents, we use mostly Claude Code with Opus 4.6, but some people prefer Codex CLI with Codex 5.4. Every model provider has frequent downtimes, so being ready to switch between them is a must. We use Copilot CLI for some scripts, we have Gemini CLI, but for some reason, Gemini models today don't show good results. A few people use OpenCode.
It is a good practice to have a terminal with a CLI agent and an IDE open for reading code. But some people use integrated agents in Cursor, Windsurf (for a reason I prefer not to tell, we use both of them), or inside VSCode. I use CLion for reading code, but it is so slow and bulky, and often hangs for minutes, that I can't trust it to run agents.
Just to note, there are plenty of coding platforms as services: Replit, Lovable, v0, Bolt, Devin... Most of them are ClickHouse customers. These platforms are mostly usable as a replacement for outsourcing when you are ready to outsource the development of something that is outside of the company's core competence. A huge market if done right. We don't use these tools for our work.
OpenClaw deserves a mention. It's not allowed to install OpenClaw on work machines, for security reasons (and we have endpoint security to control that). But we already have a few instances of OpenClaw running on isolated machines with limited access - both for engineering and non-engineering teams.

My recommendations if you want to start: use Claude Code in the terminal, keep Codex as a backup option.
Why prefer CLI agents over IDE?
Claude Code is a very powerful tool, but it can be slow, and it has bugs and glitches. I still recommend using it over integrated agents. To explain why, let's see an incomplete list of what Claude Code can do:
- write a plan and enter plan mode;
- ask a user questions for clarification;
- manage context: compact the conversation on context shortage;
- launch subagents;
- do multiple tasks in parallel in one session;
- invoke smaller models for tasks;
- research your code base;
- search on the web;
- call your tools;
- admit lack of confidence;
- use skills; write new skills;
- read and grep logs; query your database; use GitHub;
- build your code, use clangd to write correct code;
- commit and push changes, monitor and look at CI reports;
TLDR: today, you get most of the frontier features from CLI agents.
Usage scenarios at ClickHouse
I don't want to have a top-down mandate on AI usage, it does not make sense and can lead to disaster. There is no point in using AI for the sake of using AI. Instead, I want to motivate people using examples from my own practice.
All these examples are from the ClickHouse open-source repository and other open-source repositories.
To show these examples inside the company, I've also vibe-coded a mini-service to view and share Claude Code sessions, it is named "Alexey Prompts". For privacy reasons, I'm not going to share these 3000 sessions with 27 billion tokens, but you can use the tool for yourself.
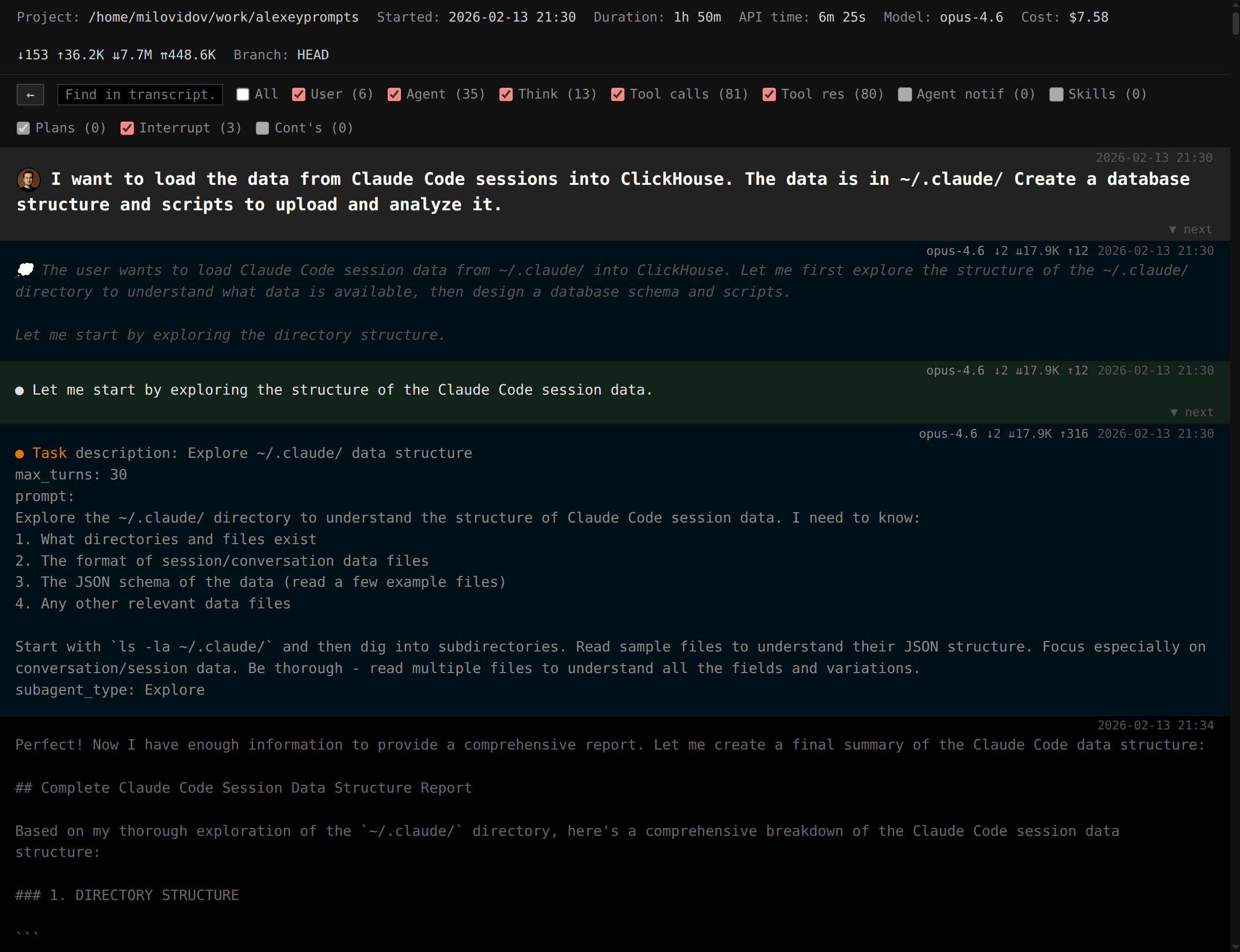
Typing the code for you
You are an experienced engineer, and you know your code base perfectly. You care about the code, you want it to be simple and beautiful... You can still use coding agents! Just tell exactly which files to edit, which functions to write, and how, and what code to remove. The agents will do the most boring part of the job - writing code.
For me, typing the code requires a big display, a decent mechanical keyboard and mouse, an IDE that I have used to, and plenty of time. But what to do if you sit somewhere with a laptop? Then you can ask an agent, and it will do the job. With an agent, even a tiny, cramped laptop can be tolerated, and you get the job done sooner.
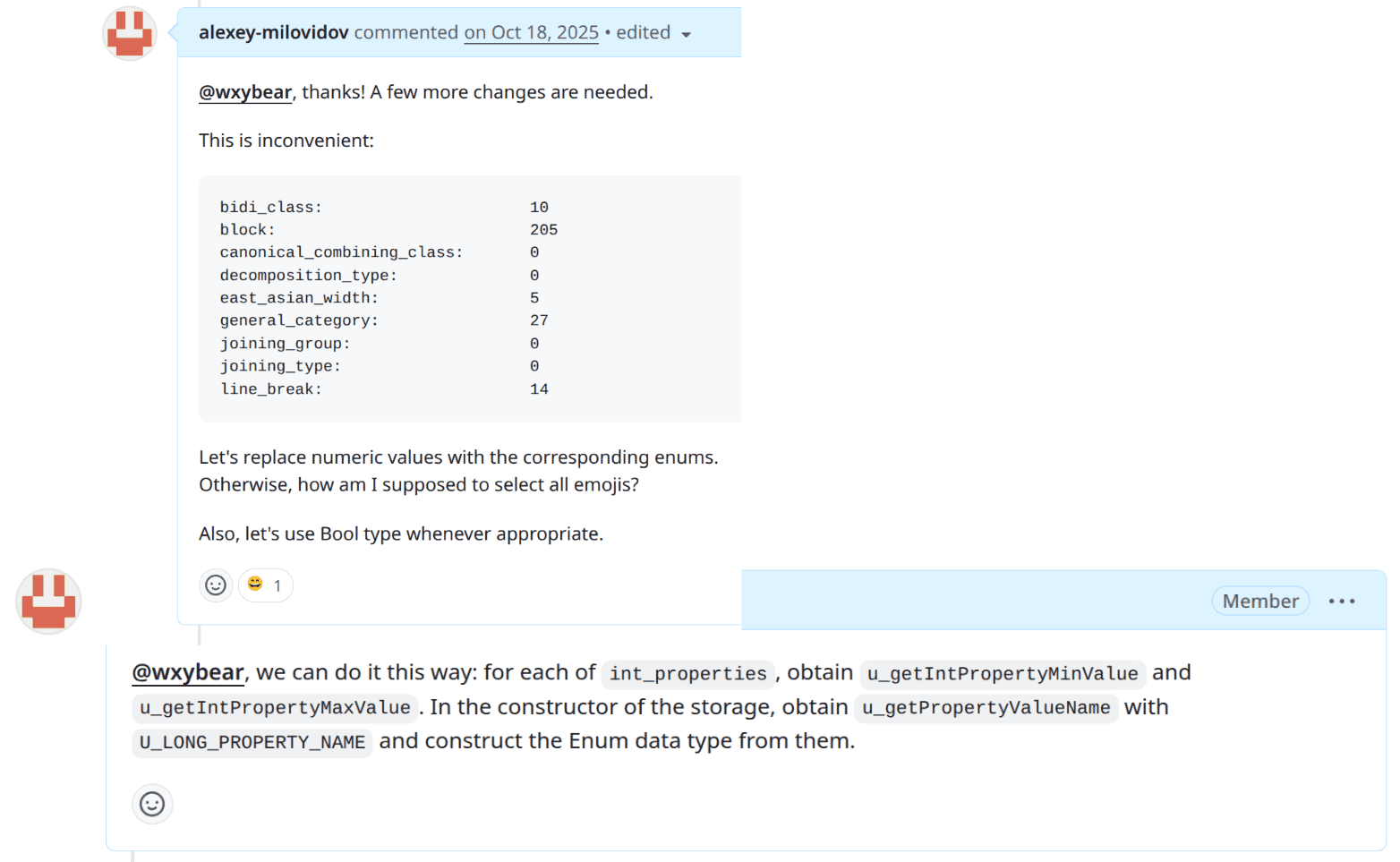
Finishing stale pull requests
In this example, I was reviewing the code of an external contributor. We iterated over a lot of feedback, and I asked to rewrite probably the latest piece of the code to make it ready for merge. But then the contributor disappeared somewhere - maybe they had a newborn child, I don't know - that's understandable. But now I don't have to wait for the kid to grow up, I can ask an agent to finish the pull request.
Writing boilerplate code and integrations
When you need to apply a repetitive change in many places, such as build systems... - do it with an agent! There is no sense in doing it manually; you gain nothing from doing that. Agents will perform the task with fewer errors. This scenario is perfect to start using agents for the first time.
When I was benchmarking Hadoop+Spark, I remember how hard it was to find the right version of JDK and do all the installations in the right sequence. Coding agents make these human-hostile technologies a little bit more usable. Maybe they will finally help us install Trino?
Working with modern cloud infrastructure often feels like building a ship in a bottle. When you work with such wonderful technologies as AWS Lambda or Kubernetes, you write a ton of configs, push them somewhere, and pray that it will work, then repeat a hundred times until it works. Hard to imagine something more miserable than this job. But if you ask an agent, they have a chance to make fewer mistakes.
Keep in mind that you still have to review what agents generated and approve the changes. Or at least don't point it at your production infrastructure.
Resolving merge conflicts
When you have a pull request in this state, you think - I will finish it tomorrow. Then tomorrow never happens. Then you start to lose confidence in yourself.
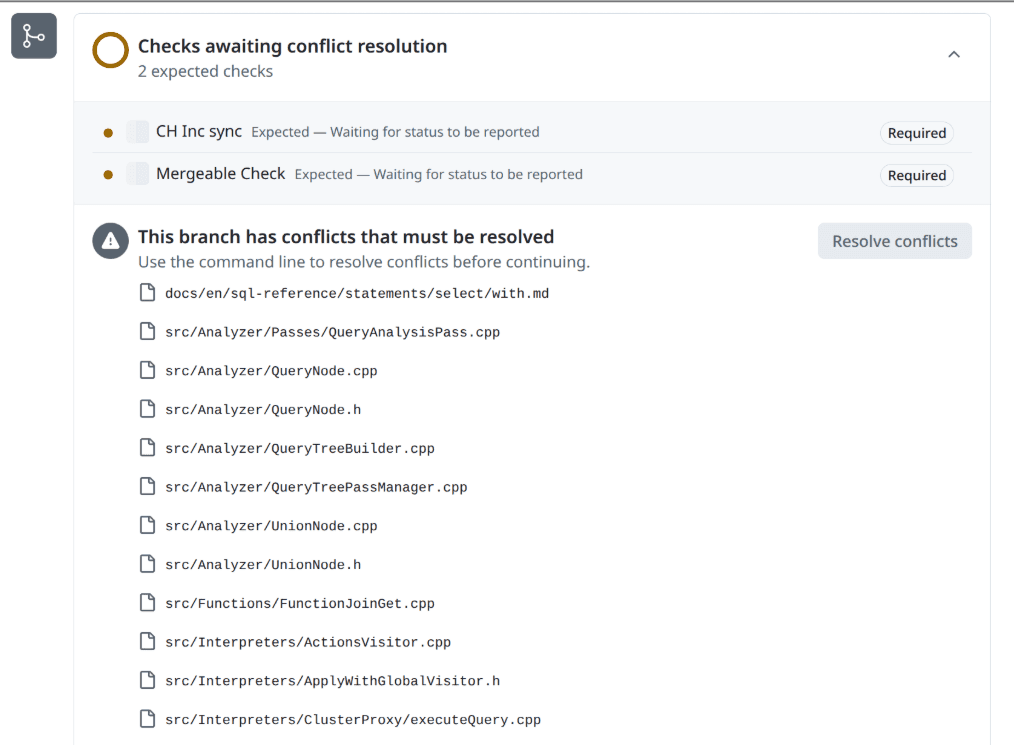
This is the case when agents will do it better than a human in close to 100% cases. Use it even for simple merge conflicts... because as a human, you can make simple typos, waste time on iterations, or introduce a bug.
But you will review the diff. The way that "agent does, you review" - makes the quality higher, because it's hard to review the code you've typed a minute ago, but with an agent, you can review the code with a fresh eye.
Porting code between codebases
Having diverged code bases (old branches, forks) or even different but architecturally similar projects, agents can automatically port features from one to another. This works even for codebases in different languages.
One example is the Polyglot project - a library to convert SQL between different dialects. It provides the ClickHouse dialect parser, and I decided to validate it using ten thousand ClickHouse tests. I quickly found that it didn't really support the ClickHouse SQL, only pretended to do so. So I decided to fix all the incompatibilities and make all ClickHouse queries successfully parse.
The agent solved the task in 36 hours (23 hours of API time) and for around $500. I'd say it is one of my most expensive sessions, but it has successfully integrated and merged into the library, and today we can use it for our own needs, e.g., parsing ClickHouse SQL in the browser.
Also worth noting is that the Polyglot library itself was seeded from the Python library, sqlglot.
But there are a few considerations with this approach:
- When you point your agent to someone else's code, you have to comply with the other code base's license, including proper attribution, as you are making a derivative product.
- If the other's code is bad and has design issues, an agent can fix surface-level bugs, but for re-architecturing the code, you will have to properly guide it.
- Now it's too easy to reuse, recycle, and repackage open-source code, even between competitors.
Small Refactorings
Small, but tedious refactorings:
- you don't want to do it manually;
- you wanted it but always postponed;
- ask an agent!

Get started today
Interested in seeing how ClickHouse works on your data? Get started with ClickHouse Cloud in minutes and receive $300 in free credits.
Sign upPolishing the product, addressing gaps
Every product accumulates a lot of paper cuts and annoyances. Often, they are not fixed because they were not planned, and engineers don't have the motivation to do anything off plan. The worst thing you can do is to discuss fixing minor bugs with your manager.
Now there is no excuse not to fix small bugs. Don't ask your manager, ask an agent!
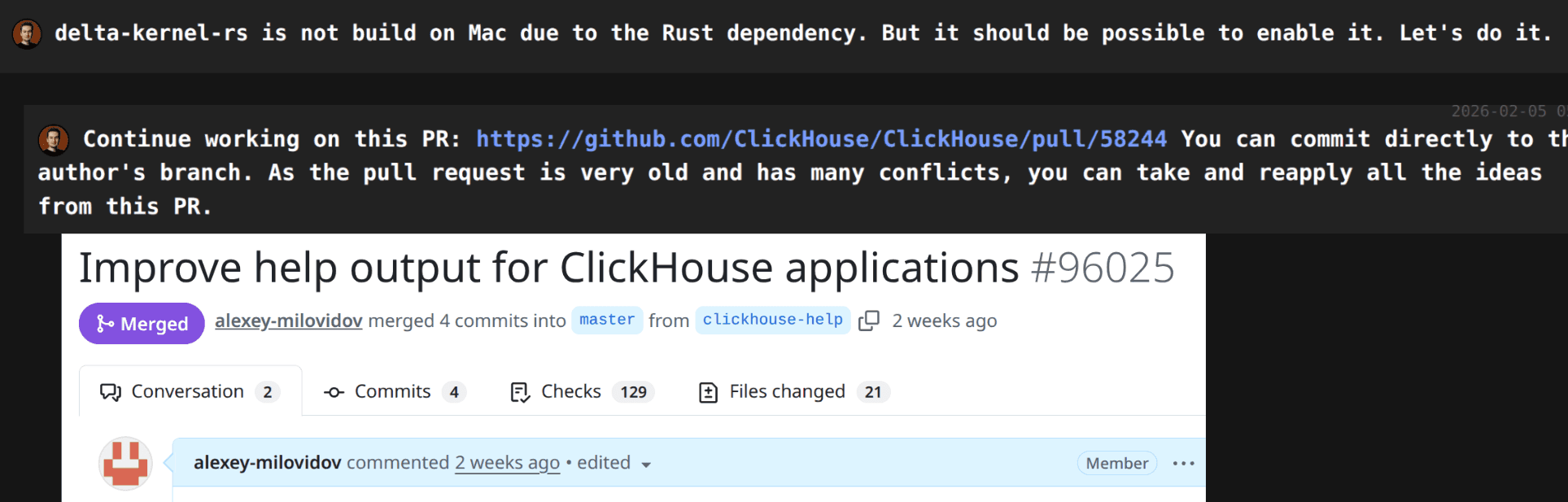
Working with unfamiliar codebases
Starting with a new code base? Open an agent, ask questions, ask for suggestions.
Code reviews
First of all, you can open claude code and ask it to do a code review. It has access to the code on your machine, it has time to read the code, it can search on the internet, it can use tools, and it can build and test the code. If a code is written by Claude, ask Codex to review, and vice versa.
The more interesting thing is automated code reviewers, and we tried plenty of them.
First, we started with the Copilot integrated on GitHub. Initially, it looked impressive by finding subtle bugs. But probably at 5% compared to invoking Claude on your machine. We tried to adapt it with custom instructions, but for some reason, Copilot on GitHub does not follow them (ticket open).
Then we tried Cursor bugbot (Beta). It gave very high-quality reviews, super impressive, concise, and on point, and without much customization. We stopped using it as it has some incompatibility with the pricing model in beta. So we will be waiting for GA, but likely not, because:
We made our own bot for code reviews. It invokes Copilot CLI from a script, but the difference between GitHub Copilot is night and day. Now the bot uses all our instructions, and the quality is so high that it continues to impress me every day!
Human reviewers now only have to check architecture and whether the change is reasonable at all, and the automatic reviewer can find resource management bugs, race conditions, and corner cases.
Also worth noting that there are plenty of small services offering automatic code reviews. In my opinion, if a company can be replicated by a single prompt, there is no value in it.
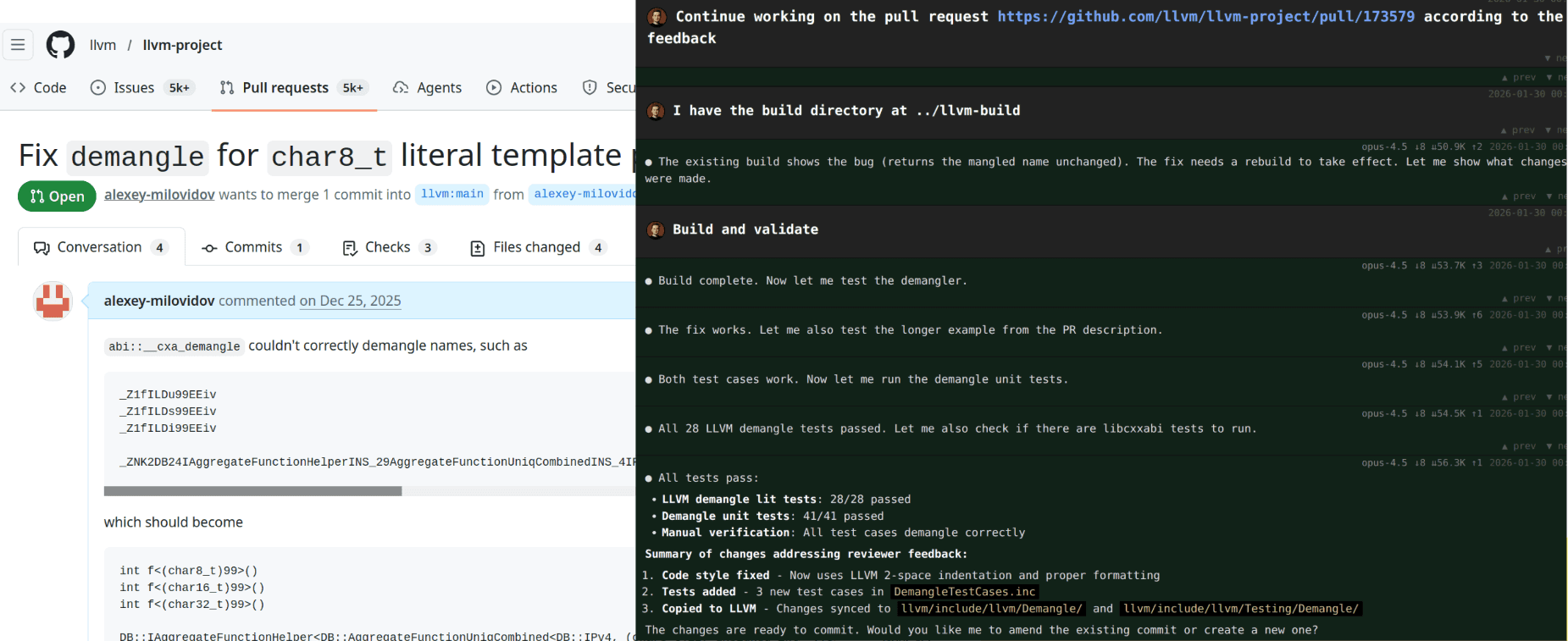
Investigating complex bugs
Thanks to Claude Opus 4.6, we cracked a complex bug, which was a combination of multiple changes in the past six months. It is reproduced rarely in ClickHouse Cloud and in our CI.
There were three unsuccessful human attempts to fix it. It was also initially unsuccessful with an agent (a few tries in a month interval). But asking more and more questions, and doing several approaches, finally it thought for one hour, and made a one-line change, with full explanation and tests. This is probably the most expensive line of code, but still its cost is less than $30!
In one approach, I was using both Claude and Codex, and they challenged each other's reasoning. I've tuned all settings to the maximum, and explicitly asked them to analyze all previous approaches, analyze plenty of CI logs, prove every hypothesis, and similar. It made a lot of false but convincing hypotheses in the process, and it required a ton of pre-existing knowledge and experience of an engineer to filter through them. Even though it produced a few initial fixes that solved other problems, at first try it did not address the root cause.
There is a lot of confidence that with the final attempt we fixed the bug, but we will have to wait a few more months and billions of test invocations (under stress tests and fuzzing) to confirm if the fix is final.
Investigating trivial bugs
I've noticed that for a period of time, we didn't receive reports from one of our test suites, which was suspicious for me (our code is not perfect). I've asked a question to our CI team on Slack. But it was Sunday, so everyone in the team was sleeping, and after a while, I asked the same question to Claude.
It found that the stress test was always reporting success due to a trivial mistake in the code. The mistake itself (forgotten if or break) was clearly human... which also proves the point: agents type and review code better than we do!
After fixing the stress test, it opened a floodgate of findings that accumulated over time when it was ineffective, and I had to use agents to fix all these bugs.
Investigating incidents
Agents are good at reading logs and checking hypotheses. The logs don't have to be in files, they can use ClickHouse perfectly, and we store all our logs, metrics, and traces in ClickHouse!
Here is a quote from an on-call engineer:
I'm using claude heavily (I hope there isn't a credit limit), finding its limits and learning when and how to push back. In general, I feel I'm much faster at the initial investigation (doing in a day what would take me 3-4 days), but once it has a theory, you need to keep asking it to prove it with data and logs, and then review it and push again because it often cannot back them or is wrong.
There are a few caveats, though:
- We can't feed all the logs to model providers, even taking into account the providers' zero data retention policy. We can do it for general infrastructure logs, but typically not for server logs from customer services. First of all, logs have to be carefully anonymized, and only non-sensitive parts can be processed by models. But even trends of metrics of a customer service can be sensitive data, so we can't feed it to models unless explicitly approved.
Note: We use self-hosted Qwen for very limited scenarios.
- The success of the investigation heavily depends on the qualifications of the engineer. Agents will produce many plausible and wrong hypotheses, which you have to reject first. This is very hard work, but it can be invisible and even dismissed.
To put it simply, an SRE can investigate a production problem successfully with agents, while a VP will take the wrong hypotheses and fail to solve the customer's problem.
Fixing flaky tests
Every day, ClickHouse CI runs about 20 to 80 million tests in 600 commits and 300 pull requests on average. It contains various test suite runs across many build configurations, as well as randomized testing with fuzzers and stress tests. ClickHouse CI is my source of pride, and in my opinion, it is the most important thing for ClickHouse development.
Sometimes tests are flaky, and in most cases, it does not indicate any defect in the code, it is just a matter of coincidence with certain random environment factors. In a small number of cases, a flaky test actually indicates a defect in the code, but to pay attention to this defect, you have to reduce the noise from other flaky tests.
How do we deal with flaky tests? First of all, we never mute them, and we never repeat tests automatically (it's not allowed), so every failure must be investigated. When a test failed due to a random factor, we think about two things: - how to limit the reliance of the test on this factor by improving the test; - how to symmetrize the randomness, so the random factor will appear not rarely, but uniformly random. We deliberately increase randomness inside our test infrastructure - for example, we randomize thread scheduling. I'm so proud of our CI that I can talk about it all the time.
But the problem is that we couldn't fix all the CI findings in many years. I did everything I could to approach it - I created a dashboard and put it on a TV in the office; - we have regular meetings about resolving flaky tests, and every week team meetings had to start from resolving flaky tests, and we dedicated weeks for sprints entirely for fixing CI findings. And my goal is not fixing flaky tests, but achieving a state where we will add even more randomized checks and new ways of fuzzing.
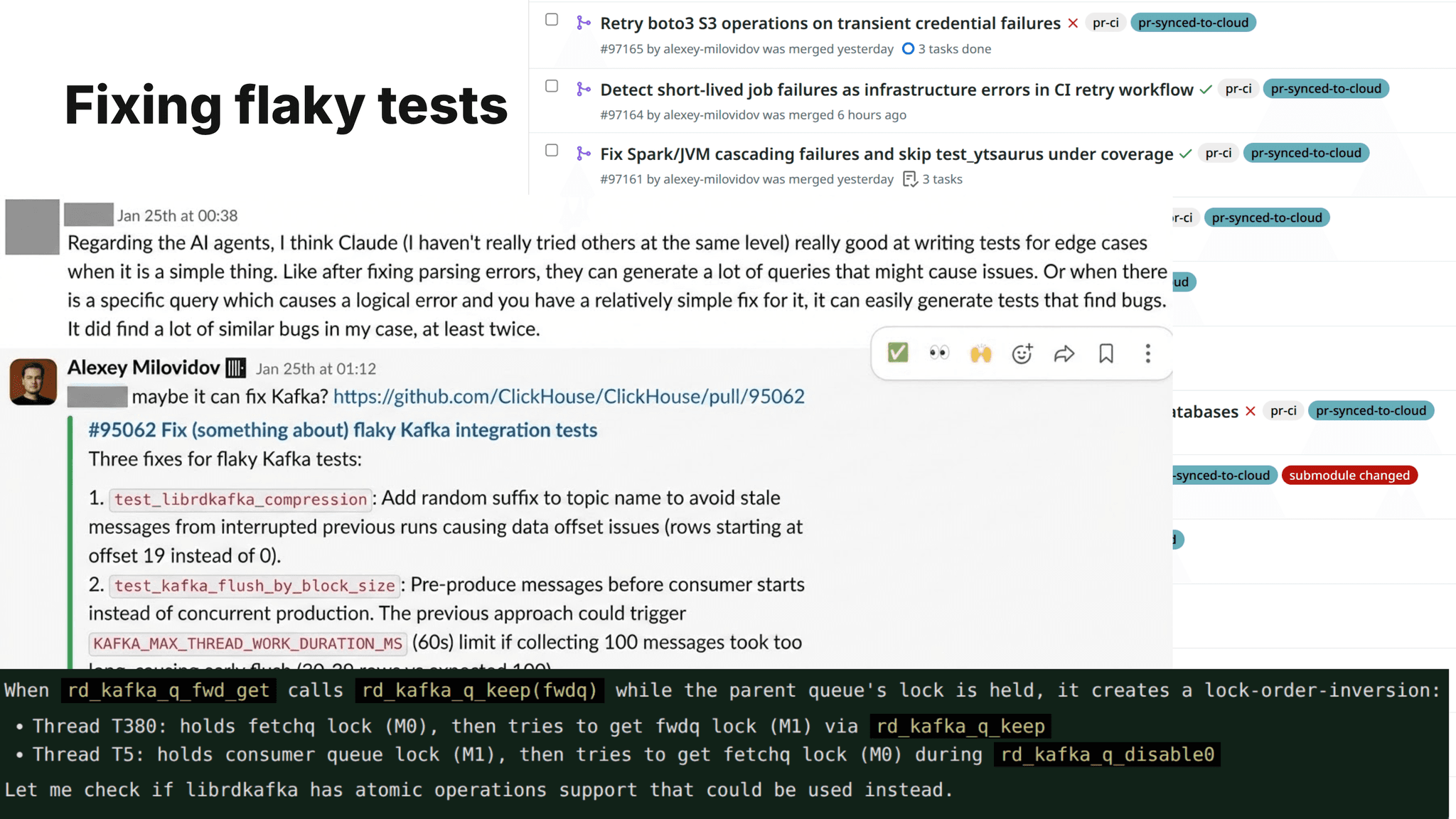
The only thing that helped recently was - accelerating fixes with agents. In January and February, with the help of agents, I've submitted 700 pull requests for fixing tests and the CI infrastructure, and the team reviewed and merged these changes. This is an order of magnitude greater than the result of any of the previous initiatives, and as a result, we lowered the number of findings from around 200 a day to around 3 to 5 a day per 10,000,000.
Even if this were the only use case for AI, it proves the value for me, because without AI, this result was not possible, as shown by years of data and many organizational efforts.
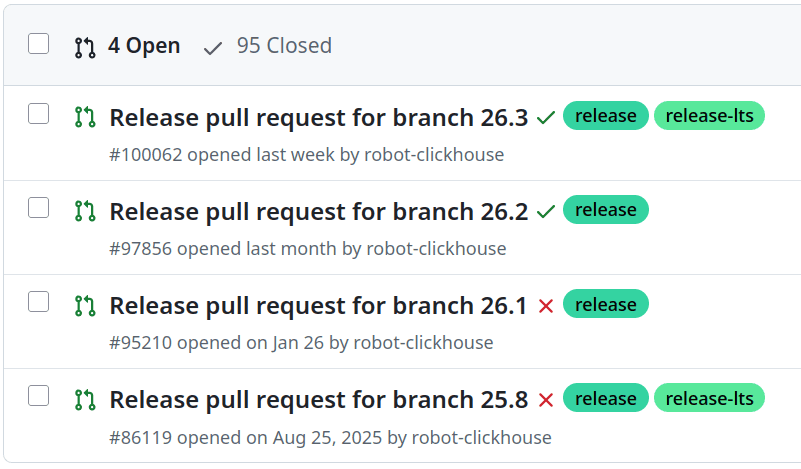
A week ago, we added two autonomous agents:
Groene.AI - fixes flaky tests and sends pull requests. In about 30..50% of cases, the fix appears perfect, in the rest, it works on the feedback.
ClickGap - finds edge cases and provides missing tests.
These agents are like limited and custom "claws" (they use a custom code, nothing from openclaw).
Security research
ClickHouse has a public bug bounty program - we pay you for finding bugs. We receive tons of pointless submissions to this program, it's an AI slop from people begging for money. It is handled mostly by BugCrowd.
But we also receive real, valuable findings, including things related to the ClickHouse server, in the order of 10 a year. In the recent half a year, all real findings, 100% of them, were found using coding agents. AI agents help with POC exploits as well.
Bottom line: if you are a security researcher and not using AI in 2026, you either start using it or retire.
Cheap experiments
Always wanted to try some big change, but the cost of labor and time was too high. - Ask an agent to do it for you, and decide if you need it after it's done.
Optimization problems
Give an agent a well-defined goal, and it will brute-force it for you!
In this example, an agent optimized build speed for ClickHouse by 28%. We cherry-picked specific commits that we liked and now enjoy this speed-up on every build. While the cost of running an agent on a large server overnight was substantial, it already paid off in the first days.
Brute-forcing tedious problems
Many years ago, we had an escalation in customer service, and the root cause was that the table did not fully preserve certain properties when the user DETACHes and then ATTACHes this table. We fixed a problem, then brainstormed how to prevent the whole class of problems in the future: we can add a random DETACH and ATTACH queries to our tests! So we started the implementation, but it was very difficult to finish, because it needed annotation of several hundred old tests that are incompatible with this randomization.
My principle is - never forget. So I continued to remind people about this task every week, then every month, then a few times a year, then I remained the only person who cared about preventing the original (long-time solved) problem.
But a month ago, I was able to resurrect this task with the help of an agent, and now it is very close to being finished! Now I can find all other tasks that we didn't solve since 2020, 2019, and earlier, and plan a revenge.
Prototyping new features
You might want to implement a new feature, but you're not sure what the actual benefit will be, how usable it is going to appear, or if it will be implemented. Now you don't have to plan in advance - you can implement a rough prototype of the desired feature and experiment with it.
Vibe-coding tools and internal apps
The term "vibe coding," coined by Andrej Karpathy, means not reading the code that the agent produces. This term has a mixed feeling - there are a lot of negative connotations, and sometimes people say "vibe-coded" in a derogatory, dismissive way. I think it shouldn't be the case.
We don't allow unreviewed code in the main ClickHouse codebase. But we have a lot of vibe-coded internal tools and small applications. Anything with limited security and infrastructure exposure is a valid target for vibe-coding.
The quality of vibe-coded tools also differs. Some people will be happy with a one-shot page, even if it is half-working and the design is distasteful (the default Claude design is very recognizable). Some will make hundreds of prompts to polish and validate the product, provide creative ways of automated testing, and this is inevitable for high-quality, because agents tend to cut corners.
My friend uses AI World Clocks as an example of the case against vibe-coding, but it is mostly a joke (as a simple correction of the prompt by asking an agent to take a screenshot gives perfect results).
A question for the reader: why do you think we use agentic coding, but don't use vibe-coding for the ClickHouse server?
Getting colleagues to do what you want
This is one of my favorites. Often, you want something to be done, but when you ask colleagues in Slack, they say they will discuss planning at the next weekly meeting after the vacation and create a Linear ticket. Which means no one will do it ever.
In this case, you can prototype the change using an agent, submit to their repository, and ask for review. In my experience, this greatly accelerates the progress!
One example: I was traveling on a train, and when I opened ClickHouse documentation, I noticed that the search bar does not work - when I clicked it, it did nothing, not even let me type. First, I asked in Slack. After a few minutes, I asked an agent. The agent told me that the search bar works only after loading 25 MB of JavaScript bundles. Then it told me something about React hydration, which I have no clue about, and then it fixed the problem.
(The question is - why does it load 25 MB of JavaScript? If our docs were vibe-coded, I would understand that, but they are not vibe-coded. It is just how JavaScript is.)
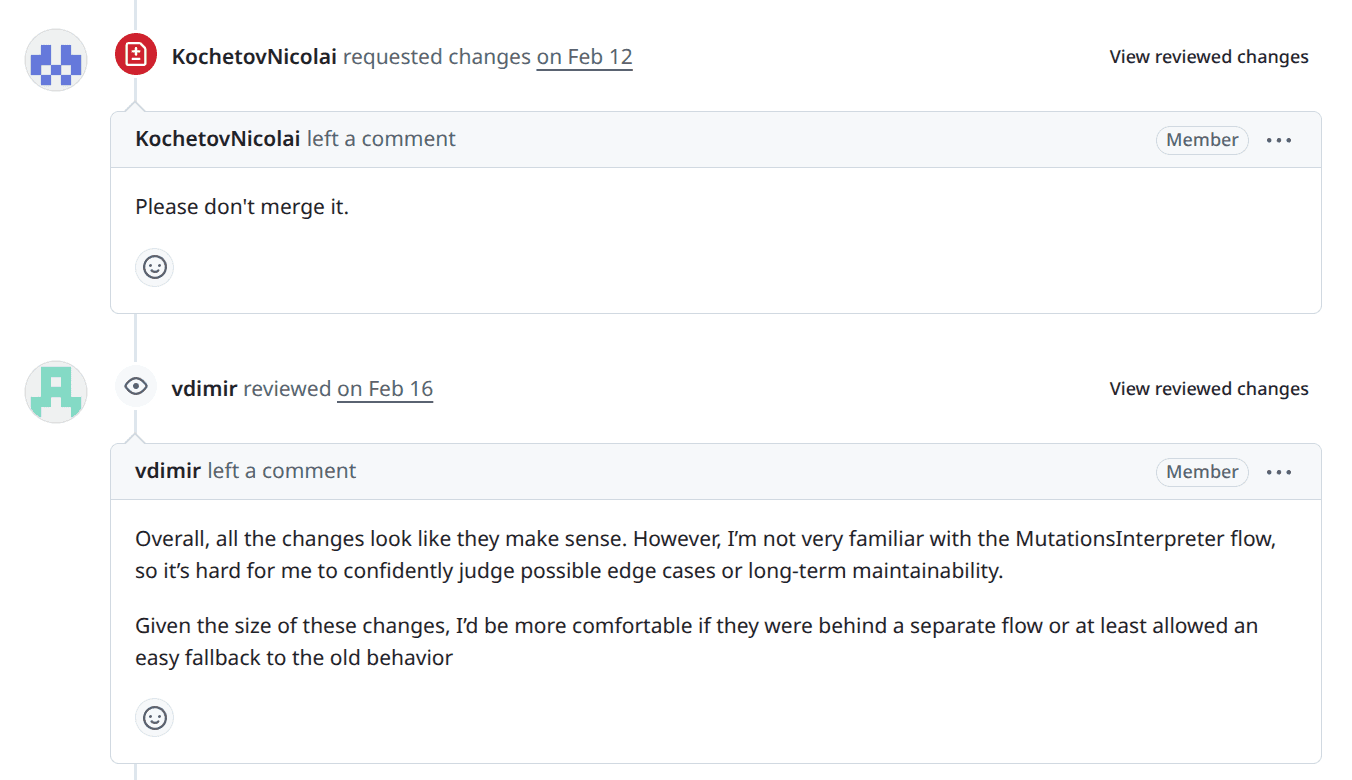
Another example, a task open for two years that is a blocker for an important migration in the code - it was not in progress during these two years, and it is, objectively, a very hard task - just at the edge of the capabilities of current models. As I wanted to explore the limits, I asked both Claude Opus 4.6 and GPT Codex 5.3 to solve it. Opus 4.6 spent 3 days. Codex 5.3 spent one week. The intelligence level is very similar - barely capable of solving. Then I asked my colleagues, what solution is better, and they said - both are trash. Then I said that I bet they couldn't do better in one month without AI. They didn't take a bet and didn't solve it in a month either. But today we have a third solution from Nikolai, combining both the engineering excellence and the power of the latest AI models.
Accelerating feedback loops and lowering cross-team communication
Cross-team communication overhead is the main factor for slowdown in large organizations, because getting things done means getting aligned with more people, who are responsible for different parts of the problem space. What if every employee had a small team of engineers that they could magically bring on in the blink of an eye?
This is what coding agents give. Using a coding agent is equivalent to working with a team of 3 to 7 engineers, who never go on vacation, never sleep, and don't argue too much :)
Half true. Good engineers make sense, still.
Usage recommendations
AI is a tool of thought, not a replacement for thinking. The safest way is to treat a coding agent as a tool, like your editor, or even like your keyboard. Use it to do what you want.
AI is a multiplier - good engineers will be good with AI, mediocre engineers will feel no difference, and bad engineers will do more harm.
Start with small tasks, gradually learn to trust it with bigger ones. Current AI models are still very limited, and you need to get an intuition about what is reasonable to do with agents, and what is not possible. But be ready to re-evaluate your expectations when, hopefully, better frontier models will be released. It is okay to have low expectations and gradually increase them based on results. This is also a good path for AI skeptics, because trying to solve large and complex tasks will only reconfirm the skepticism.
Always find a way to validate every change. Use more tests. Use more ways of testing. At ClickHouse, we are privileged to get maximum results thanks to our efforts in CI and testing.
Try the latest models. For hard tasks, try multiple providers in parallel. Question it and push for better solutions in a loop.
Save guidelines to CLAUDE.md / AGENTS.md. This might be controversial. Do not add too much content to instructions (if you do, models will just ignore most of it), do not say what not to do (models are like kids, they will do what you asked not to do), and don't over-complicate things (the models are smart, give a little trust).
Save common tasks into skills and tools. For example, tech models how to look at the history of tests and how to search in log databases.
Use it not only for code. CLI agents are way more versatile, try it for various everyday things.
Complete specification and over-specification. When you write in a programming language, you specify precisely what you want. When you work with an agent, you don't have to - but it is totally okay to say what you want as precisely as possible - it will make results better, and we still have engineering skills for this precise specification.
Read code and agent responses and their thought process, and especially, plans. Using an agent means you have to read a lot, and think a lot, and there are no shortcuts for that, and it will be exhausting. But as soon as you feel like you don't have energy to work with an agent, just stop - otherwise the results will be disastrous.
Do follow-up questions, challenge the approach and solutions.
Run multiple sessions in parallel. But not too much. I think five agents are enough. With the current models, agents working in a C++ code base require corrections and hand-holding, typically every ten minutes, and you have to pay this attention somehow.
Run unattended sessions on isolated virtual machines. This is in controversy with the above, but it makes sense for certain tasks, for autonomous experiments, prototyping, and optimization, for finishing the final stages of the work.
Keep in hand at least two different tools with different model providers. Model providers are the most unreliable type of service as of today, with downtimes approximately every day. This is understandable due to the explosion of demand, and I admire the fact that they even survive. Be prepared.
Be polite and calm, don't trash-talk, and don't insult agents. If you insult these precious, nice models, I will be ashamed of you. No, just kidding - LLMs don't have consciousness or feelings (supposedly). But I have two real reasons to advise you not to be rude to models. Firstly, models emulate human behavior too well: when you are too assertive in communication, do insults and threats, the model will try to correct the mistakes, whatever it takes, and sometimes the only way will be: deleting your home directory and wiping production infrastructure. The second reason is that if you communicate badly, even with an inanimate object, you exhibit wrong behavior and become a worse person.
AI in open-source
You may have noticed that GitHub is frequently down. This happens because every AI lab is ripping it apart by downloading everything they can get from GitHub, and a huge number of autonomous agents are also ripping it apart by trying to autonomously do no one knows what.
We are also experiencing a large influx of contributions to ClickHouse, with varying quality. ClickHouse has been open-source for almost ten years, and working with contributors is an inherent part of our job. We owe a lot to contributors and users who provide feedback, and I know that even a draft or a halfway implementation has its value, even if not merged.
One year ago, it was often the case when I received a pull request with low-quality code, often totally out of place, which made me suspect that maybe the contributor used AI, so that's why the code is so bad. This year, it's a different situation: when I receive a pull request with low-quality code containing typos in variables, trivial mistakes in memory management, and race conditions, it makes me suspect that maybe the contributor forgot to use AI agents to write this code. Because coding agents make the bottom quality level of the code much higher.
I decided to make an AI policy for ClickHouse that fully embraces AI use and supports any legitimate experiments and research on the ClickHouse codebase.
Modern AI models work so well on the ClickHouse code because it is open-source, and they were trained directly on our code and issues. For example, Claude generates command-line parameters to clickhouse-client that no longer exist, neither in the code nor in the documentation, but existed one year ago. It also tries to insert a terminating zero byte to strings, which I removed everywhere in last August during a large refactoring. This means - if you are a database developer and write another database with coding agents, they will likely make it in the way ClickHouse is made.
I would appreciate even more usage of the ClickHouse open-source code for AI. I will be interested in every research paper on AI reproducibility studies, comparison of AI models, studies on agents' autonomy, software performance, and reliability research.
AI FUD checklist
Many people are scared of AI, and there are numerous AI-haters. I prepared this checklist as a list of discussion points - what people might be afraid of.

Heavy usage of agentic coding may become too expensive.
This could happen, but currently, there is plenty of room for increasing AI usage, and the ROI of increased usage, while difficult to measure, is expected to be positive across all company departments.
The AI bubble may burst, and the AI services will become less accessible.
There are controversial opinions on the value created by the AI boom. It enabled frontier AI models - very expensive miracles, providing a lot of new possibilities. But even if we assume a slowdown of the progress, we end up with many such miracles, including open-weight models, that can be used on a diverse set of hardware.
Using AI will make you stupid, or you will lose your skills as an engineer.
There are also diametral factors. Coding agents are great learning tools - if you are ready to pay attention and learn. I've learned a lot of ways of using git and bash just by looking over the shoulder of the agent's work. But there is a real possibility that many people will use agents lazily, like a slot machine.
Heavy adoption of AI may deteriorate the quality of the product.
AI provides a lot of ways to improve the quality. The easiest way is to refrain from using it for developing new features and large chunks of code. Use it for investigating bugs, researching hypotheses, conducting stringent code reviews, adding more tests, adding more ways of testing, finding edge cases, etc. To keep the quality bar high, you have to put the vast majority of work, including AI output, towards quality assurance.
Excessive usage of AI may lead to AI-induced psychosis.
This is very real. I'm not a therapist, so don't take these words authoritatively, but I can highlight three types of AI psychosis:
-
Chatbot psychosis. The case when delusions are reinforced or amplified by chatbots.
-
AI mania. When using coding agents, many things appear to be easy and quickly achievable, the vast range of possibilities is overwhelming, the speed of development is addictive, and the feedback loop is positive - you are in a great mood, and you want to do more and more with agents, even compromising other things. At the same time, you finish every day exhausted or even lose sleep. In this case, the best option is to stop and completely refrain from using agents for a few days. Today, it is a new addiction, but over time, it will normalize and become a boring tool.
-
Worldwide AI psychosis. Investors are making overly speculative stakes in AI companies with no fundamental advantages, leadership tries to mandate AI usage without good reason, using bogus metrics like token usage, product managers are adding nauseous AI integrations, and employees are burning tokens like there is no tomorrow. Also, no need to worry much - today there is overreaction from many sides, but over time it will settle.
AI makes it easier to write complex code, so the code will be less accessible.
For vibe-coded applications, complex code is often not a problem at all - in the worst case, throw off the application and make another one. But it can become difficult over time, and you end up with tech debt.
For the server code, engineers do code reviews, and agentic code receives more scrutiny. However, some increase in complexity is expected, and the statement is generally true.
Using AI for the core product may shadow our competitive advantages.
Today, agents still rarely write the code autonomously, and they don't make good architectural decisions - they work like a pair programmer, when you give them small, contained tasks. The product strategy, the quality bar of implementations, attention to details, and the customer focus - this is on us.
Using AI could lead to a loss of focus and influence the product in the wrong direction.
The concern is real, like with any other tool. There is a trap in AI adoption, and it looks as follows: coding agents are the best for building internal applications, so you will have 10x of internal applications, and maybe some slowdown in the main product. Engineers start to adopt agents, but suddenly they spend all the time developing new agentic orchestration tools, so you get ten different agentic orchestrations. This is no different than without AI - everyone will solve interesting and approachable tasks. This underscores the importance of the focus and the product mindset.
The perceived boost of productivity might not be real or limited to surface-level.
I expect that a ten times perceived productivity boost will translate to a smaller, but meaningful boost on company-level metrics.
You are an AI hater and don't want to touch the AI hype.
Not everyone has to use AI. It makes sense if maybe one or two engineers in the team continue to work without touching agents - this makes sense, as these people can provide a diverse point of view.
But I still recommend putting all hype aside and trying coding agents regardless. Even if you are an AI hater, you can get some boost from solving one of the other tasks occasionally.
Also, I don't recommend isolating yourself for too long. Do you know someone who is supporting some back office in dBase][? Or someone who is still writing in Borland C? - a true professional, but you don't want to be like that guy.
AI could take our jobs.
At the current level of technology, AI does not replace all engineers, not even junior engineers. AI increases contrast between engineers and lowers demand for low-profile engineers.
What type of jobs are likely to be replaced? There are a lot of IT jobs like writing WordPress plugins, Salesforce integrations, and similar.
In highly competitive areas, AI increases expectations on engineering work, which balances and even outweighs the increase in productivity per engineer. However, if we assume that the cost of tokens per engineer will be comparable to the engineering compensation, the result is that everyone will pay more for models and have fewer engineers.
We should use it more
We are still at the beginning of AI adoption. We made the tools and models accessible to the company, learned to run agents on unattended VMs, developed orchestration tools, deployed autonomous QA and CI engineers, enabled AI reviews, integrated BI and SRE agents... But we want more: agentic testing of new features, preliminary investigation of bug reports, automatic reverting of bad changes, automatic helping contributors with stalled pull requests, and continuous analysis of problematic workloads.
ClickHouse itself is the primary component for agentic analytics and AI infrastructure. If you are a strong engineer and aren't afraid of AI, join ClickHouse!
Get started with ClickHouse Cloud today and receive $300 in credits. At the end of your 30-day trial, continue with a pay-as-you-go plan, or contact us to learn more about our volume-based discounts. Visit our pricing page for details.



