Welcome to the first ClickHouse newsletter of 2025. This month, we have Apache Iceberg REST catalog and schema evolution in the 24.12 release. We learn how to build a product analytics solution and implement the Medallion architecture with ClickHouse. And we have videos from The All Things Open Conference!
Inside this issue
- Featured Community Member
- Upcoming events
- 24.12 Release
- Building a product analytics solution with ClickHouse
- Optimizing bulk inserts for partitioned tables
- From zero to scale: Langfuse's infrastructure evolution
- Building a Medallion architecture with ClickHouse
- Building a Medallion architecture for Bluesky data
- Quick reads
- Video corner
- Post of the month
Featured community member
This month's featured community member is Jason Anderson, Head of Data at Skool, a community platform.

Jason Anderson is an experienced data and technology professional with a background in leading teams and developing data-driven solutions. He previously served as Head of Data at Mythical Games and Partner at Comp Three, focusing on machine learning, analytics, and cloud architecture. His career includes roles at IBM and PolySat, where he contributed to cloud services and satellite software development.
Jason recently presented his work at Skool at the ClickHouse Los Angeles meetup. Jason explained how they moved from Postgres to ClickHouse to process 100M+ rows daily while delivering lightning-fast queries. There is also a blog post that explains Skool’s use of ClickHouse in more detail.
Upcoming events
Global events
- Release call 25.1 - Jan 28
Free training
- ClickHouse Query Optimization Workshop - Jan 22
- Using ClickHouse for Observability - Jan 29
- ClickHouse Developer In-Person Training - London, England - Feb 4-5
- In-Person ClickHouse Training - Feb 10
- ClickHouse Query Optimization Workshop (APJ-friendly timing) - Feb 12
Events in EMEA
- Meetup in London - Feb 5
- Meetup in Dubai - Feb 10
Events in APAC
- Alibaba Developer Summit Jakarta - Jan 21
- Meetup in Tokyo - Jan 23
- Meetup in Mumbai - Feb 1
- Meetup in Bangalore - Feb 8
- Developers Summit Tokyo - Feb 13-14
24.12 release

The final release in 2024 introduced support for the Iceberg REST catalog and schema evolution. Daniel Weeks, co-creator of Apache Iceberg, made a guest appearance in the 24.12 community call, so be sure to check out the recording.
There were also Enum usability improvements, an experimental feature to sort a table by a column in reverse order, JSON subcolumns as a table’s primary key, automatic JOIN reordering, optimization of JOIN expressions, and more!
Building a product analytics solution with ClickHouse

Product analytics involves collecting, analyzing, and interpreting data on how users interact with a product.
Chloé Carasso leads product analytics at ClickHouse and wrote a blog post explaining how we built our in-house product analytics platform.
Chloe explains why we decided to build something ourselves rather than buy an off-the-shelf solution and shares some ideas on designing and operating a ClickHouse-powered analytics solution if you're interested in this path. She also shares common queries that she runs, including cohort analysis, user paths, and measuring retention/churn.
Optimizing bulk inserts for partitioned tables
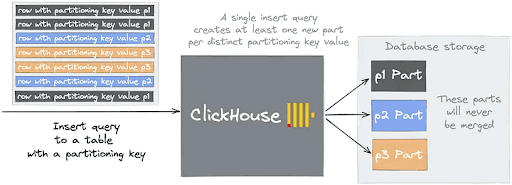
Jesse Grodman, a Software Engineer at Triple Whale, shares some tips for quickly loading data into a highly partitioned ClickHouse table.
We start writing data directly into the table from S3 files, but that results in many small parts, which isn’t ideal from a querying standpoint and can result in the too many parts error. He explores various ways to work around this problem, including sorting the data by partition key as part of the ingestion query, which results in an out-of-memory error.
Jesse discovers that sorting the data by partition key before writing it into ClickHouse works much better. He also tries first loading the data into an unpartitioned table and then populating the partitioned table afterward, doing the sorting in ClickHouse.
From zero to scale: Langfuse's infrastructure evolution
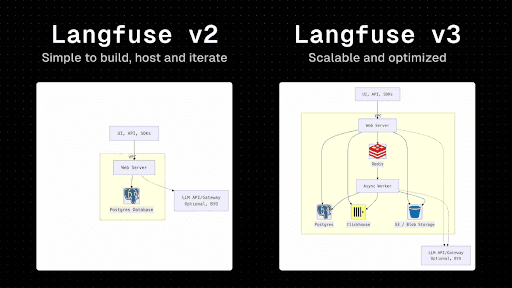
Langfuse is an open-source LLM observability platform that participated in the Y Combinator Winter 2023 batch. The initial release of their product was written on Next.js, Vercel, and Postgres. This allowed them to get the release out of the door quickly, but they ran into problems when trying to scale the system.
In the blog post, they explain their journey to solving these problems, which involved an extensive infrastructure redesign. A Redis queue was introduced to handle spiky ingestion traffic, and they sped up analytics queries with help from a ClickHouse ReplacingMergeTree table.
Building a Medallion architecture with ClickHouse

The medallion architecture is a data design pattern that logically organizes data in a lakehouse. It aims to incrementally and progressively improve the structure and quality of data as it flows through each layer of the architecture (from Bronze ⇒ Silver ⇒ Gold layer tables).
The ClickHouse Product Marketing Engineering (PME) team was curious whether the architecture could be applied to a real-time data warehouse like ClickHouse and wrote a blog post describing their experience.
Building a Medallion architecture for Bluesky data

Following the introductory post to the Medallion architecture, the ClickHouse PME team applied this design pattern to data from the BlueSky social network.
This was a perfect dataset for this experiment, as many of the records had malformed or incorrect timestamps. The dataset also contained frequent duplicates.
The blog goes through a workflow that addresses these challenges, organizing this dataset into the Medallion architecture’s three distinct tiers: Bronze, Silver, and Gold. The team also heavily uses the recently released JSON type.
Quick reads
- Hellmar Becker recently joined ClickHouse and has been taking it through its paces. In his first blog post, he explores array processing functions, and in the second, we learn how to do linear algebra in ClickHouse.
- Hardik Singh Behl explores how to integrate ClickHouse into a Spring Boot application. He first configures the application and establishes a database connection before performing a few CRUD operations.
- Andrei Tserakhau shows how to transfer data from MySQL to ClickHouse using Transfer, an open-source cloud-native ingestion engine.
- Shivji kumar Jha explores how Postgres and ClickHouse can work together as a unified data management solution, balancing transactional reliability with high-speed analytics.
Video corner
- We had two ClickHouse speakers at the All Things Open 2024 conference. Tanya Bragin explored how open source technologies and datalake standards are transforming the modern data stack by offering alternatives to monolithic cloud data warehouses.
- Zoe Steinkamp explained how columnar databases are revolutionizing data warehousing and analytics by offering superior performance over traditional row-based systems. Zoe also demonstrated how we can build efficient analytics applications with tools like Apache Arrow, Parquet, and Pandas while reducing costs and improving query performance./li>
- Mark explained the various deployment modes of ClickHouse, including ClickHouse Server, clickhouse-local, and chDB.
- Avi Press explains how Scarf has built a ClickHouse-backed data pipeline that handles ~25GB of data and 50 million events every day.
Post of the month
Our favorite post this month was by Dmytro Shevchenko: