Large-scale data engineering requires structuring, transforming, and analyzing datasets efficiently. The Medallion architecture—a design pattern for a data workflow for organizing and improving data quality through tiered transformations—has been a widely adopted approach for managing complex datasets. Traditionally implemented using tools like Spark and Delta Lake, this workflow ensures that raw, “messy” data can be systematically refined into clean, high-quality datasets ready for end-user analysis and applications.
In this blog post, we explore how the Medallion architecture can be implemented entirely using native ClickHouse constructs, eliminating the need for any external frameworks or tooling. With its leading query performance, support for a wide range of data formats, and built in features for managing and transforming data, ClickHouse can be used to efficiently implement each stage of the architecture.
While this post aims to show how the three stages of the Medallion architecture can be theoretically constructed with ClickHouse, a subsequent post will practically demonstrate this using a live feed of the Bluesky dataset. This dataset contains many common data challenges, including malformed events, high duplication rates, and timestamp inconsistencies, and is well suited to showcase the processes described below.
What is the Medallion architecture?
The Medallion architecture is a widely used data workflow for organizing data into a tiered structure, where data quality is progressively improved as it progresses through the stages. While widely applied in data lake houses, this architecture can also be applied to real time data warehouses as a means to enable efficient data management and transformation.

The architecture comprises three layers (or stages), each serving distinct purposes in the data pipeline:
- Bronze layer - This layer acts as the landing area for raw, unprocessed data directly from the source system: simply put a "staging area". This data is stored in its original structure with minimal transformations and additional metadata. This layer is optimized for fast ingestion, and can provide an historical archive of source data that is always available for reprocessing or debugging.
Whether the bronze layer should store all data is a point of contention, with some users preferring to filter the data and apply transformations, e.g., flattening JSON, renaming fields, or filtering out poorly formed data. We're not overly opinionated here but recommend optimizing the storage for consumption by the silver layer only - not other consumers.
-
Silver layer - Here, data is cleansed, deduplicated, and conformed to a unified schema, with raw data from the previous Bronze layer being enriched and transformed to provide a more accurate and consistent view. This data can be consistent and usable for enterprise-wide use cases such as machine learning and analytics. The data model should emerge at this layer with a focus placed on ensuring primary and foreign keys are consistent to simplify future joins. While not common, applications and downstream consumers can read from this layer. These are typically business-wide applications that need the entire cleansed dataset, e.g., ML workflows. Importantly, data quality will not improve after this stage only the ease at which it can be queried efficiently.
-
Gold layer - This later aims to have fully curated, business-ready, and project-specific datasets that make the data more accessible (and performant) to consumers. These datasets are often denormalized, or pre-aggregated, for optimal read performance and may have been composed of multiple tables from the previous silver stage. The focus here is on applying final transformations and ensuring the highest data quality for consumption by end-users or applications, such as reporting and user-facing dashboards.
This layered approach to data pipelines aims to efficiently address challenges like data quality, duplication and schema inconsistencies. By transforming raw data incrementally, the Medallion architecture aims to ensure a clear lineage and progressively refined datasets that are ready for analysis or operational use.
While we find the naming of the medallion architecture could be better since it does not directly convey the contents of the layers, there are useful processes to extract from each layer and the discipline it helps enforce.
Medallion architecture with ClickHouse
In this section, we propose how each layer of the Medallion architecture can be implemented using ClickHouse and how native features can be used to move data between them. This represents a flexible and evolving approach based on our internal experience and insights from our users, and we welcome feedback to refine these practices further.
Bronze layer with ClickHouse
The Bronze layer serves as the entry point for raw, unprocessed data, optimized for high-throughput ingestion using ClickHouse’s flexible and performant constructs. Potentially acting as a historical archive, it can preserve raw data for lineage, debugging, or reprocessing without requiring complete cleansing or deduplication upfront. This focus on performance and flexibility establishes a robust foundation for downstream refinement and transformation in subsequent stages.
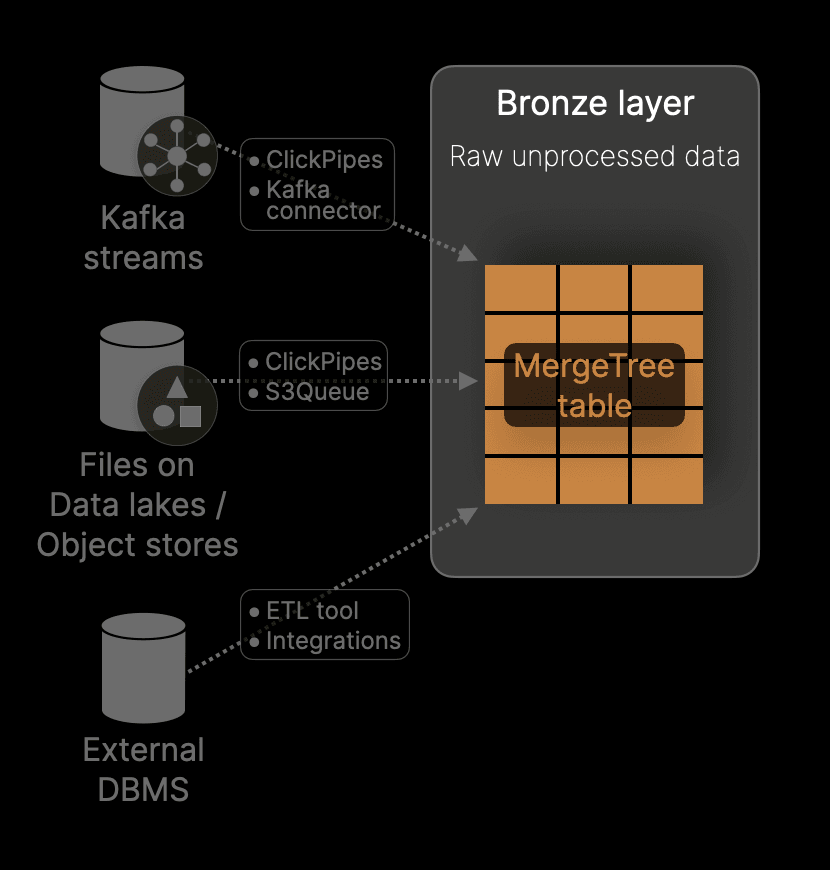
Key features of the Bronze layer when implemented with ClickHouse include:
Ingestion from sources
Data can be ingested into this layer directly via clients, ELT tools like Fivetran, or by consuming streams from Kafka using ClickPipes or the ClickHouse Kafka connector. S3Queue and ClickPipes, in ClickHouse Cloud, provide additional options for reading data incrementally from S3 buckets in over 70 data formats (optionally compressed), including Parquet and lake formats such as Iceberg. This approach of using S3 as a staging area is particularly common when processing larger semi-structured data whose schema is less consistent.
Optimization for fast inserts
Our Bronze layer is typically implemented using a MergeTree, which is designed to handle fast inserts efficiently. The table's schema and ordering key are designed to support efficient insert operations while also enabling performant reads in case data needs to be replayed (to the silver layer) or explored for data quality issues. Given this layer will not serve consumers, we recommend optimizing the ordering key for efficient full data scans i.e. use an ordering key consistent with the read order - usually time.
Support for semi-structured JSON data
The new JSON type in ClickHouse is a critical feature for handling semi-structured data in the Bronze layer. This type allows the ingestion of dynamic and unpredictable schemas without the need for strict enforcement upfront, making it particularly valuable for datasets with inconsistent or evolving structures. By supporting highly dynamic JSON, the Bronze layer becomes an effective landing area for raw data, accommodating scenarios where schema consistency is not guaranteed. Note that the JSON type allows filtering rules to be applied with control over which object paths are preserved. Users may also wish to filter out all invalid JSON prior to storage in this layer and possibly flatten complex structures.
The use of this type is not limited to the Bronze layer, with valid applications in other layers, e.g., for columns containing dynamic schemas by design, e.g., user tags.
Materialized Columns for basic processing
Materialized columns offer a powerful mechanism for extracting and transforming specific fields during ingestion. While limited in scope, they enable efficient processing of JSON data by creating derived columns for commonly queried attributes. This approach is especially useful in cases where the JSON data includes irregular paths or structures, allowing for basic pre-processing without the overhead of full schema enforcement. These extracted columns are also commonly used for subsequent conditional filtering.
Partitioning and data retention
Bronze layer tables can be partitioned to optimize query performance and enable efficient data management. TTL rules are recommended to expire older data that is no longer required, ensuring compliance and efficient storage use.
Silver layer with ClickHouse
The Silver layer represents the next stage in the Medallion workflow, transforming raw data from the Bronze layer into a more consistent and well-structured form. This layer addresses data quality issues such as filtering out invalid rows, standardizing schemas, and performing transformations. With ClickHouse, we typically see bronze tables directly mapped to silver equivalents, but with a cleaner, enriched dataset that serves as a foundation for advanced presentation in the Gold layer.
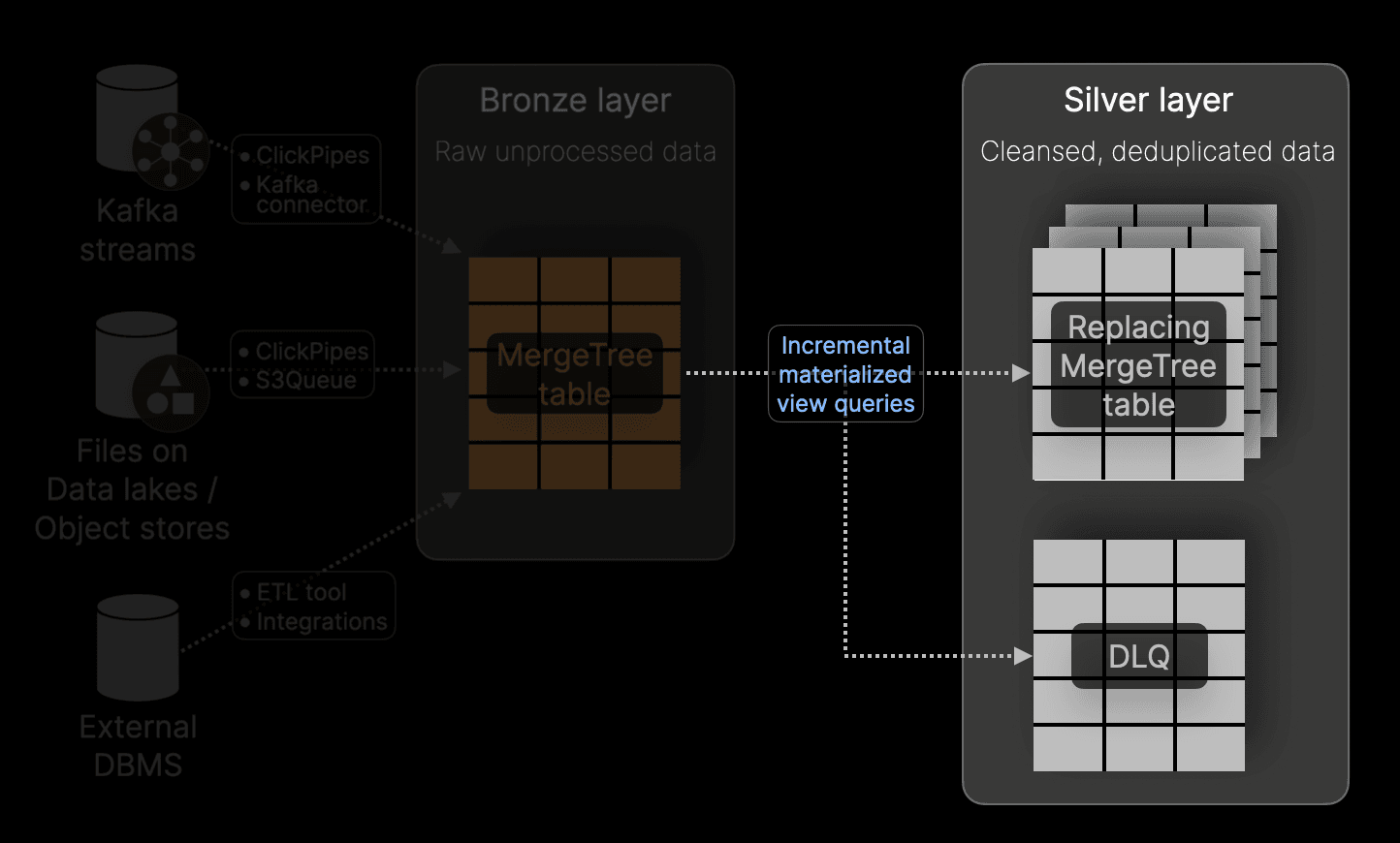
Incremental materialized views
The Silver layer is typically populated using Incremental Materialized Views attached to the Bronze layer. These execute queries on newly inserted data blocks to the Bronze layer, which apply filtering, transformations, and schema normalization before writing the results to Silver layer tables for persistence. These views enable efficient and continuous data transformation, and by attaching multiple views, users can create different versions of the data, each targeting specific Silver layer tables for distinct downstream use cases. Additionally, invalid or unprocessable rows can be redirected to a dead letter queue via separate Materialized Views, allowing inspection and potential recovery without polluting the main dataset.
Handling deduplication and CDC
For use cases requiring deduplication or handling Change Data Capture (CDC) streams, a ReplacingMergeTree table engine can be employed. The ordering key for this engine is used to perform deduplication (with unique value sets identifying a row), with updates amortized as versioned inserts -- particularly useful in CDC scenarios. Note that the ReplacingMergeTree performs merge time deduplication and thus is eventually consistent only, requiring the use of the FINAL operator at query time to ensure zero duplicates in results. Generally, we recommend downstream applications read cautiously from this layer since this clause can incur significant query time overhead.
Partitioning and data retention
Similar to the Bronze layer, Silver layer tables can be partitioned to optimize query performance and data management with TTL. Partitioning can also enable improved performance when reading from ReplacingMergeTree tables with FINAL. We recommend users follow best practices, such as optimizing merge operations to maintain performance. Since this layer doesn't act as a long-term archive and may not be used as a source in downstream use cases, data can potentially be retained in this layer for shorter periods of time than the Bronze and Gold layers, with partitioning potentially over shorter periods.
Gold layer with ClickHouse
The Gold layer represents the final stage in the Medallion architecture, where data is curated into fully denormalized, business-ready datasets optimized for consumption by end-user applications and analytics. Populated from the Silver layer using Refreshable Materialized Views, which perform complex transformations, including joins and aggregations. This ensures that data is in its most usable form, minimizing the need for query time joins and even aggregations, though ClickHouse's sub-second performance also makes real-time star schema joins a viable alternative to strict denormalization. Gold layer tables are designed to deliver high performance, supporting downstream applications with minimal latency and maximum efficiency.
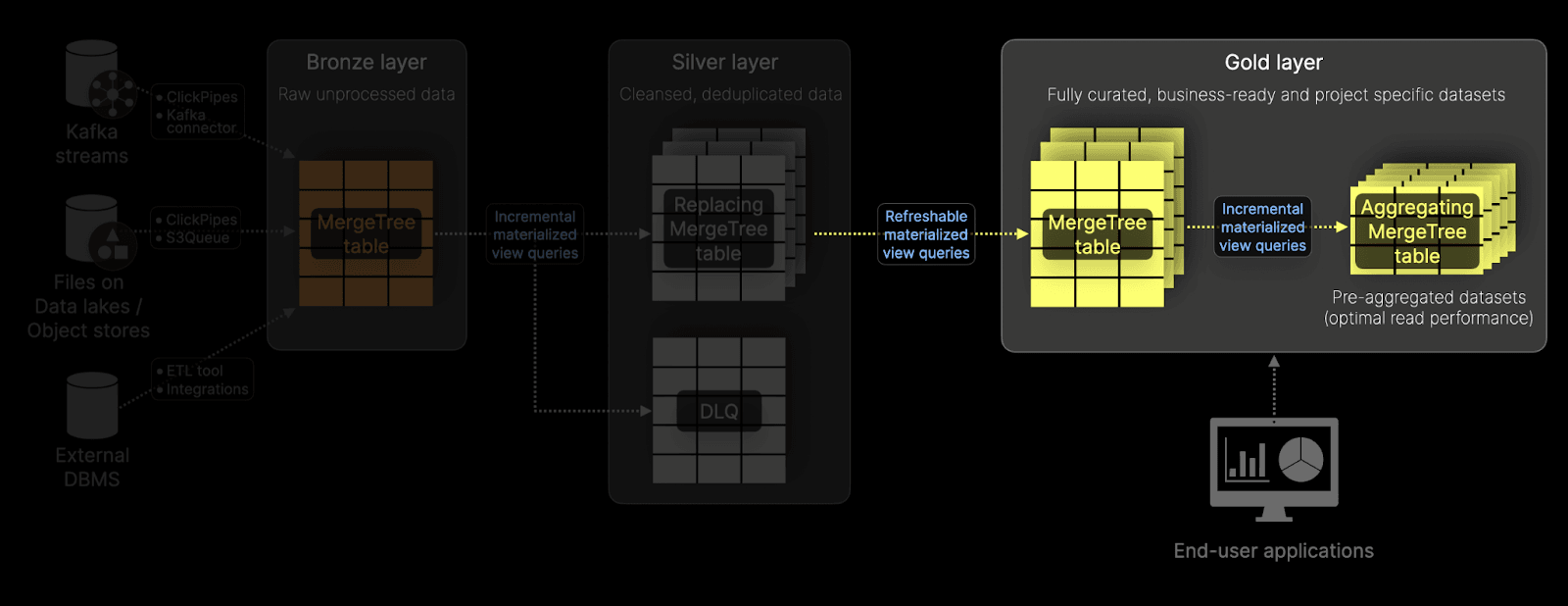
Refreshable Materialized Views
Unlike Incremental Materialized Views used to populate the Silver layer, the Gold layer is populated with Refreshable Materialized Views. These views execute periodically against silver layer tables and enable advanced transformations, such as complex joins, that denormalize the data before it is written to Gold layer tables. When sourcing data from Silver layer tables employing ReplacingMergeTree, these views can execute queries with the FINAL operator to ensure that fully deduplicated data is inserted into the Gold layer. This approach ensures the highest data quality while preserving the flexibility to handle advanced query requirements.
Table design for downstream applications
Tables in the Gold layer are typically implemented using standard MergeTree tables, with ordering keys specifically optimized for the access patterns of downstream applications. These denormalized datasets are structured to minimize the need for additional joins, enabling applications to perform fast, efficient reads. By tailoring the schema and keys to the requirements of end-user queries, these tables provide seamless integration into reporting tools, dashboards, and interactive user experiences.
Incremental Materialized Views for precomputed aggregations
In addition to storing denormalized datasets, the Gold layer often includes Incremental Materialized Views for precomputing aggregations. These views execute GROUP BY queries on new inserts to the Gold layer tables, writing the intermediate aggregation results to target tables using the AggreatingMergeTree engine. Shifting computation from query time to insert significantly reduces query latency. Downstream queries, in turn, only need to merge smaller intermediate states, making them highly performant and suitable for powering user-facing applications with rich filtering and aggregation capabilities.
Our demo application ClickPy heavily exploits materialized views to provide visualization and filtering capabilities over a trillion row Python PYPI dataset. See the clickPy GItHub repository for further details.
The complete Medallion architecture with ClickHouse
Assembling each of the stages above, we have our complete ClickHouse-powered Medallion architecture:
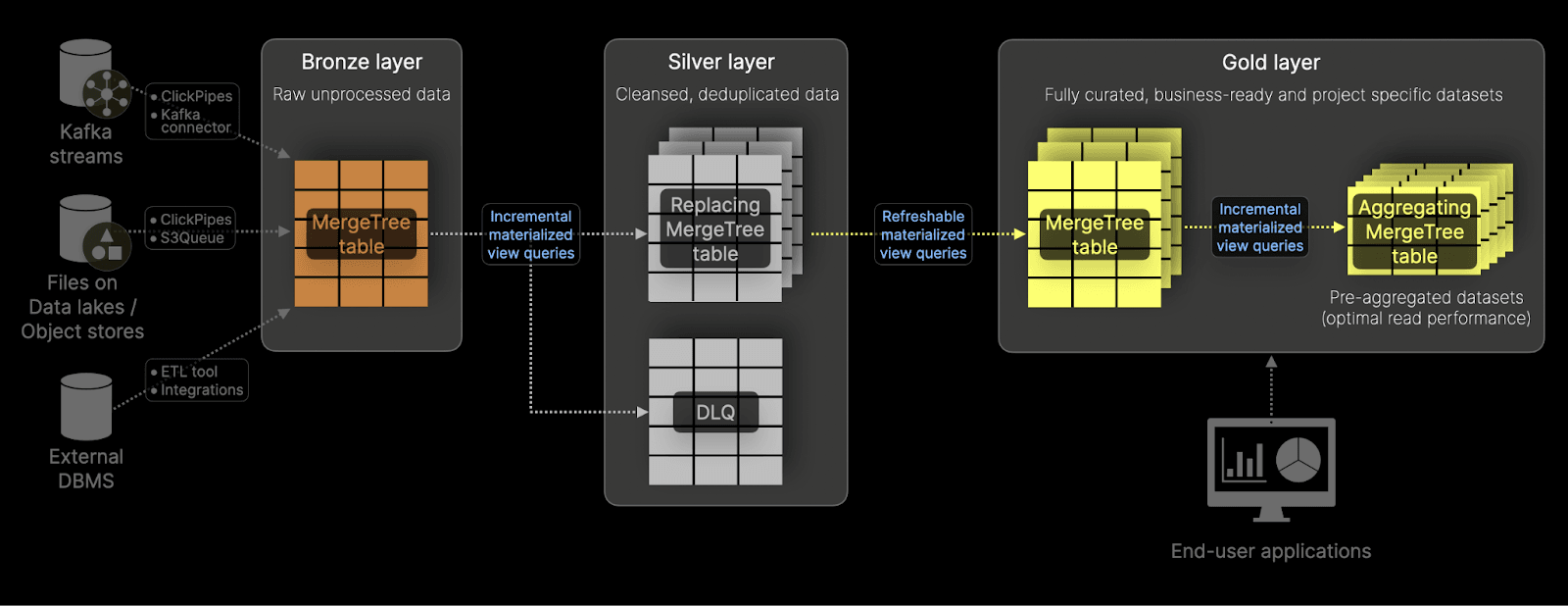
This Medallion architecture, implemented with ClickHouse, offers a structured approach to managing data pipelines through tiered transformations. Through the support of over 70 file formats, raw data can be directly ingested into the Bronze layer using either the s3Queue or Clickpipe features (in ClickHouse Cloud) before being incrementally refined and enriched in the Silver layer and finally curated in the Gold layer for optimal consumption by applications and analytics. Leveraging ClickHouse's MergeTree tables (Incremental/Refreshable) Materialized Views and support for diverse file formats, this architecture enables data ingestion, transformation, and delivery without relying on external tools.
Note that users aren't tied to deploying all three stages of this architecture and can drop any of the layers. For example, users may wish to skip the Silver stage if data is delivered with minimal data quality issues and no duplicates.
While the benefits here are compelling, with a clear methodology and set of tools to deliver clean, optimized data to end users and applications, this architecture does have some drawbacks.
Gold tables inherently present the same data in many ways, each optimized for its consuming application, resulting in a need to replicate data. However, associated data replication costs can be mitigated through the use of object storage for MergeTree tables with the separation of storage and computing.
Additionally, the architecture requires the management of multiple tiers introducing additional complexity in data pipelines. This requires monitoring, achievable through ClickHouse system tables that provide visibility into the state of Materialized Views and the data migration processes, while tools like Grafana can alert on issues such as view failures or data discrepancies thanks to the ClickHouse data source.
Harder to mitigate is the inherent delay in data availability that this architecture incurs due to the need for data to move systematically through each layer. As a result this architecture is more challenging to optimize in real-time use cases, where data availability is critical.
Closing thoughts & conclusion
The Medallion architecture with ClickHouse demonstrates a powerful, self-contained approach to managing data workflows, enabling ingestion, transformation, and consumption. By leveraging ClickHouse's native features, organizations can build efficient, scalable pipelines that deliver clean, optimized datasets for analytics and applications.
The standout feature of the ClickHouse implementation is its self-contained approach. All data ingestion, transformation, and consumption occur natively within ClickHouse without requiring external tooling.
In our next blog, we'll show the steps building a practical deployment of the Medallion architecture for Bluesky data, hosted on sql.clickhouse.com, where you'll be able to explore and query each tier of the architecture directly. Stay tuned!
Get started with ClickHouse Cloud today and receive $300 in credits. At the end of your 30-day trial, continue with a pay-as-you-go plan, or contact us to learn more about our volume-based discounts. Visit our pricing page for details.



