We are as excited as the rest of the data community about the recent surge in popularity of the BlueSky social network and its API, which lets you access the flood of content being published.
This dataset contains a high-volume stream with thousands of JSON events per second, and we thought it’d be fun to make the data available for the community to query.
Just interested in querying Bluesky!?!
For users just interested in ingesting Bluesky data quickly into ClickHouse, we suggest jumping to here. Example analytical queries and instructions for using this data can then be found here.
While exploring the data, we realized that many events had malformed or incorrect timestamps. The dataset also contains frequent duplicates. Therefore, we can’t just import the data and call it a day - we will need to do some cleanup.
This is a perfect opportunity to try out the Medallion architecture we discussed in a recent blog. This post will bring those concepts to life with a practical example.
We’ll build a workflow that addresses these challenges, organizing this dataset into three distinct tiers: Bronze, Silver, and Gold. We'll adhere to the principles of the Medallion architecture and heavily use the recently released JSON type. Each tier will be available for public querying in our demo environment at sql.clickhouse.com, where readers can explore and interact with the results firsthand. We’ve even provided some example analytical queries to get you started!
What is Bluesky?
For those of you who aren't as active on social media, you may have missed the recent rise of Bluesky, which is currently accumulating almost 1 million users a day. Bluesky is a social network like X, but unlike them, it's fully open-source and decentralized!
Bluesky, built on the AT Protocol (ATProto), is a decentralized social media platform that allows users to host their content independently. By default, data resides on the Bluesky Personal Data Server (PDS), but users can choose to host these servers (and their content) themselves. This approach reflects a shift back to the principles of the early web, where individuals had control over their content and connections instead of relying on centralized platforms that dominate and own user data.
Each user's data is managed in a lightweight, open-source framework, with a single SQLite database handling storage. This setup enables interoperability and ensures that content ownership remains with the individual, even if a central platform goes offline or changes its policies. We recommend this article for users interested in the underlying architecture and its evolution.
Most importantly for us, like Twitter of old, Bluesky offers a free way to retrieve events e.g. posts, in real-time, unlocking potentially a huge dataset for analytics as the network grows in popularity.
Reading Bluesky data
To ingest Bluesky data, we use the recently released Jetstream API, which simplifies the consumption of Bluesky events by providing JSON-encoded streams. Unlike the original firehose, which requires handling binary CBOR data and CAR files, Jetstream reduces complexity, making it accessible for developers working on real-time applications. This API aligns perfectly with our use case, allowing us to filter and process thousands of events per second from Bluesky posts while addressing common challenges like malformed data and high duplication rates.
For our implementation, we connect to a public Jetstream instance, consuming a continuous stream of JSON-encoded events for ingestion. For this, we use a simple bash that processes the live stream of JSON events from Jetstream. The full script can be found here. In summary, this:
- Checks a GCS bucket for the most recent .csv.gz file, extracts its timestamp (used as the cursor), and uses it to resume the Jetstream subscription from the correct position. This ensures data continuity and minimizes duplication.
- The
websocattool is used to connect to the Jetstream API, subscribe to events, and pipe the JSON stream for processing. ThewantedCollectionsparameter filters for relevant events, and thecursorensures incremental data retrieval i.e.websocat -Un --max-messages-rev $MAX_MESSAGES "$WS_URL/subscribe?wantedCollections=app.*&cursor=$cursor" > "$OUTPUT_FILE" - Incoming JSON data is split into chunks of 500k lines, with each chunk representing a file with the last timestamp used as the file identifier. We use
clickhouse-localto convert the file to CSV and compress this togzfile, before uploading the file to a GCS bucket usinggsutil.
This script runs within a ClickHouse Docker container, executing every 3 minutes using a Google Cloud Run Job.
Note that the files are naturally ordered with their names using the timestamp of their last event. This is essential for the later efficient incremental reading of the GCS bucket. This script also doesn’t guarantee that all Bluesky events will be captured.
Sampling the data
At the time of writing this post, we have almost 1.5 billion row events captured after collecting data for around 21 days. We can use the gcs ClickHouse function to query the data in place and identify the total number of raw rows.
clickhouse-cloud :) SELECT count()
FROM gcs('https://storage.googleapis.com/pme-internal/bluesky/*.gz', '', '', 'CSVWithNames')
┌────count()─┐
│ 1484500000 │ -- 1.48 billion
└────────────┘
1 row in set. Elapsed: 72.396 sec. Processed 1.48 billion rows, 205.07 GB (20.51 million rows/s., 2.83 GB/s.)
Peak memory usage: 4.85 GiB.We can sample the data using the same function, casting each row to the JSON type and using the PrettyJSONEachRow format to obtain a readable result.
SET allow_experimental_json_type = 1
SELECT data::'JSON' AS event
FROM gcs('https://storage.googleapis.com/pme-internal/bluesky/*.gz', '', '', 'CSVWithNames')
LIMIT 1
FORMAT PrettyJSONEachRow
{
"account": {
"active": true,
"did": "did:plc:kjealuouxn3l6v4byxh2fhff",
"seq": "706717212",
"time": "2024-11-27T18:00:02.429Z"
},
"did": "did:plc:kjealuouxn3l6v4byxh2fhff",
"kind": "account",
"time_us": "1732730402720719"
}
1 row in set. Elapsed: 0.233 sec.While the above provides some insight into the event structure, it does not fully capture the data's complexity, variability, and inconsistency. The kind column largely dictates the subsequent structure with the API delivering commit, identity, and account event types. Full details of these event types can be found here, but in summary, these represent:
commit: A commit event indicates either a create, update, or delete of a record. This should represent most events and include posts, likes, and follows.identity: An account's identity was updated.account: An account's status was updated.
We'll explore this data further once it is loaded into the Bronze layer.
Challenges with Bluesky data
The Bluesky data, as it's delivered by JetStream API has a number of challenges, including:
- Malformed JSON - We occasionally see malformed JSON events. While these are rare these can disrupt the processing of a file. We exclude these using the function
isValidJSON, limiting ingestion into the Bronze layer to those rows which return 1. - Inconsistent structure - While the crawl timestamp is consistent for each event (the
time_usfield), the JSON path containing the time for when the event occurred depends on the event type. Our workflow needs to extract a consistent timestamp column based on these conditions. A simple analysis suggests that:commit.record.createdAtcan be used for commit eventsidentity.timefor identity eventsaccount.timefor account events
- Future or invalid timestamps - Some events have future timestamps. For example, 42k commit events had future times when sampling the events at the time of writing. A further 4 million commit events had timestamps before even the launch of Bluesky as a service.
- Repeated structures - There are cases where the JSON contains what appear to be deeply recursive structures. This produces over 1800 unique JSON paths, most of which likely add little value to the content.
- Duplicates - Despite our efforts to maintain a cursor, the Jetstream API produces duplicates (where the content is identical except the crawl timestamp). Surprisingly, these can occur over a wide time range - in some cases up to 24 hours apart. An important observation when exploring the data was that most duplicates occur within a 20 minute time window.
The above does not represent an exhaustive list of data quality issues - we continue to discover challenges with the data! However, for example, purposes and in the interest of brevity, we focus on the above for our example Medallion workflow.
The JSON data type
JSON plays a key role in implementing the Medallion architecture for Bluesky data, enabling the system to store highly dynamic and semi-structured nature in the bronze layer. The new JSON data type in ClickHouse, introduced in version 24.8, addressed key challenges faced by earlier implementations.
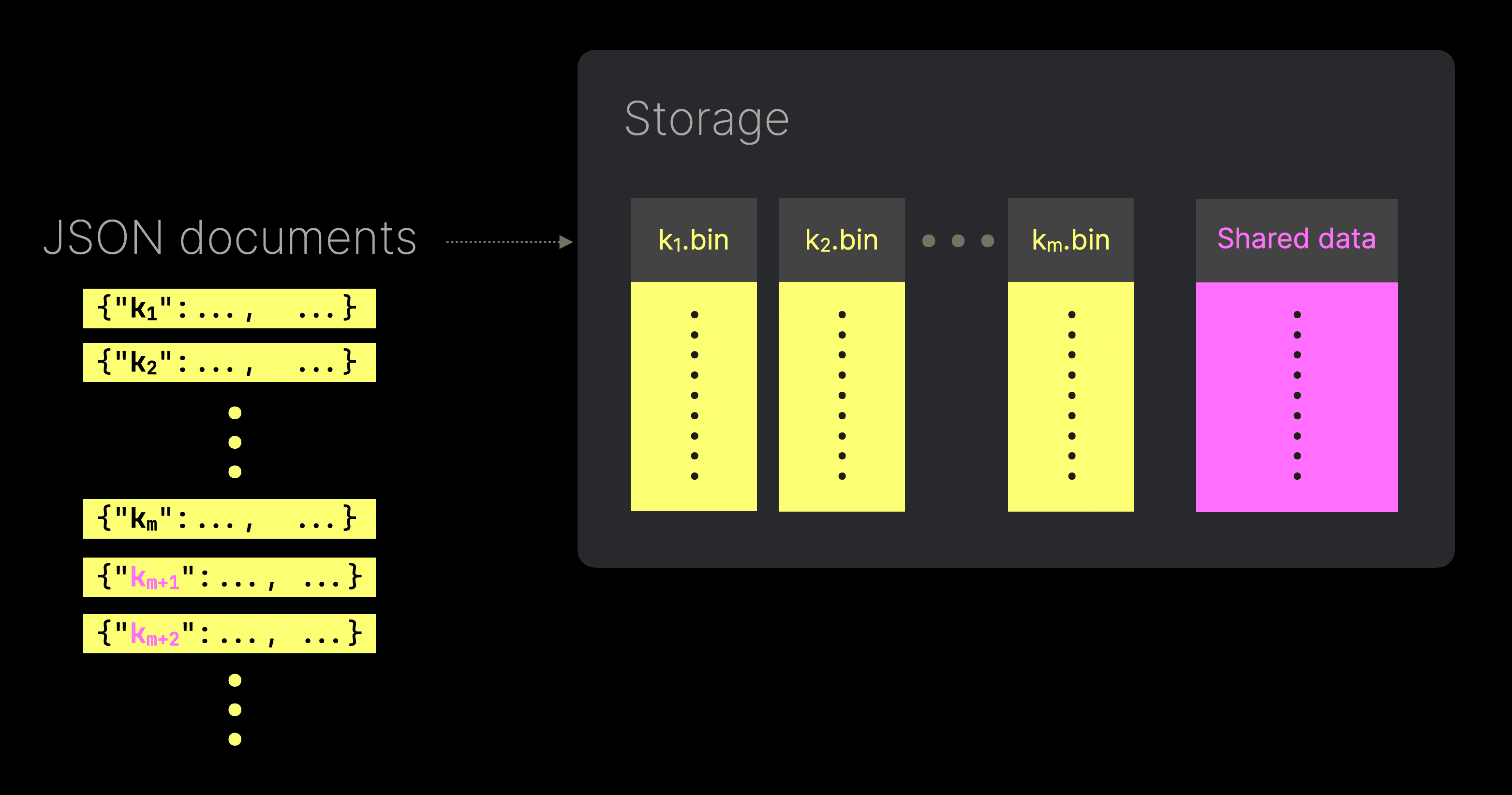
Unlike traditional approaches that infer a single type for each JSON path, often leading to type enforcement or coercion, ClickHouse’s JSON type stores values for each unique path and type in separate sub-columns. This ensures efficient storage, minimizes unnecessary I/O, and avoids the pitfalls of query-time type casting.
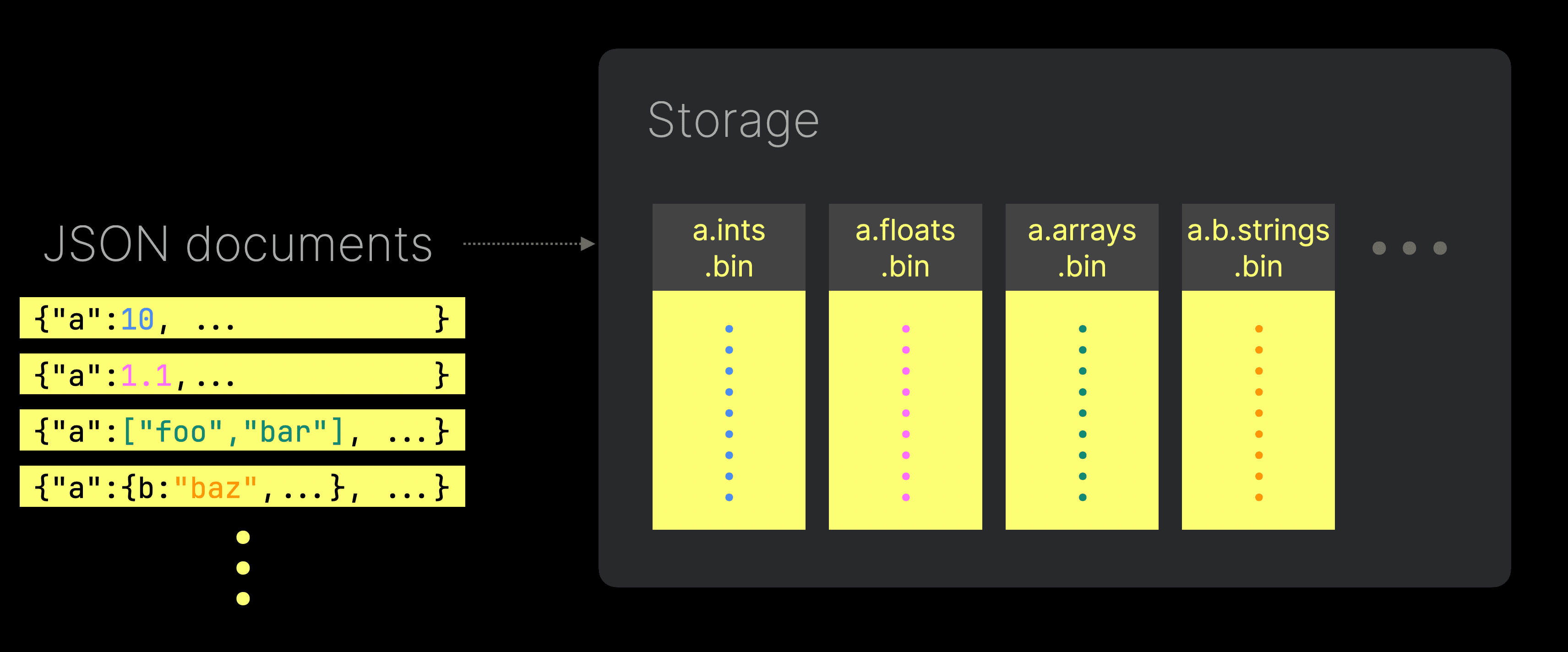
For example, when two JSON paths are inserted with differing types, ClickHouse stores the values of each concrete type in distinct sub-columns. These sub-columns can be accessed independently, minimizing unnecessary I/O. Note that when querying a column with multiple types, its values are still returned as a single columnar response.
Additionally, by leveraging offsets, ClickHouse ensures that these sub-columns remain dense, with no default values stored for absent JSON paths. This approach maximizes compression and further reduces I/O.
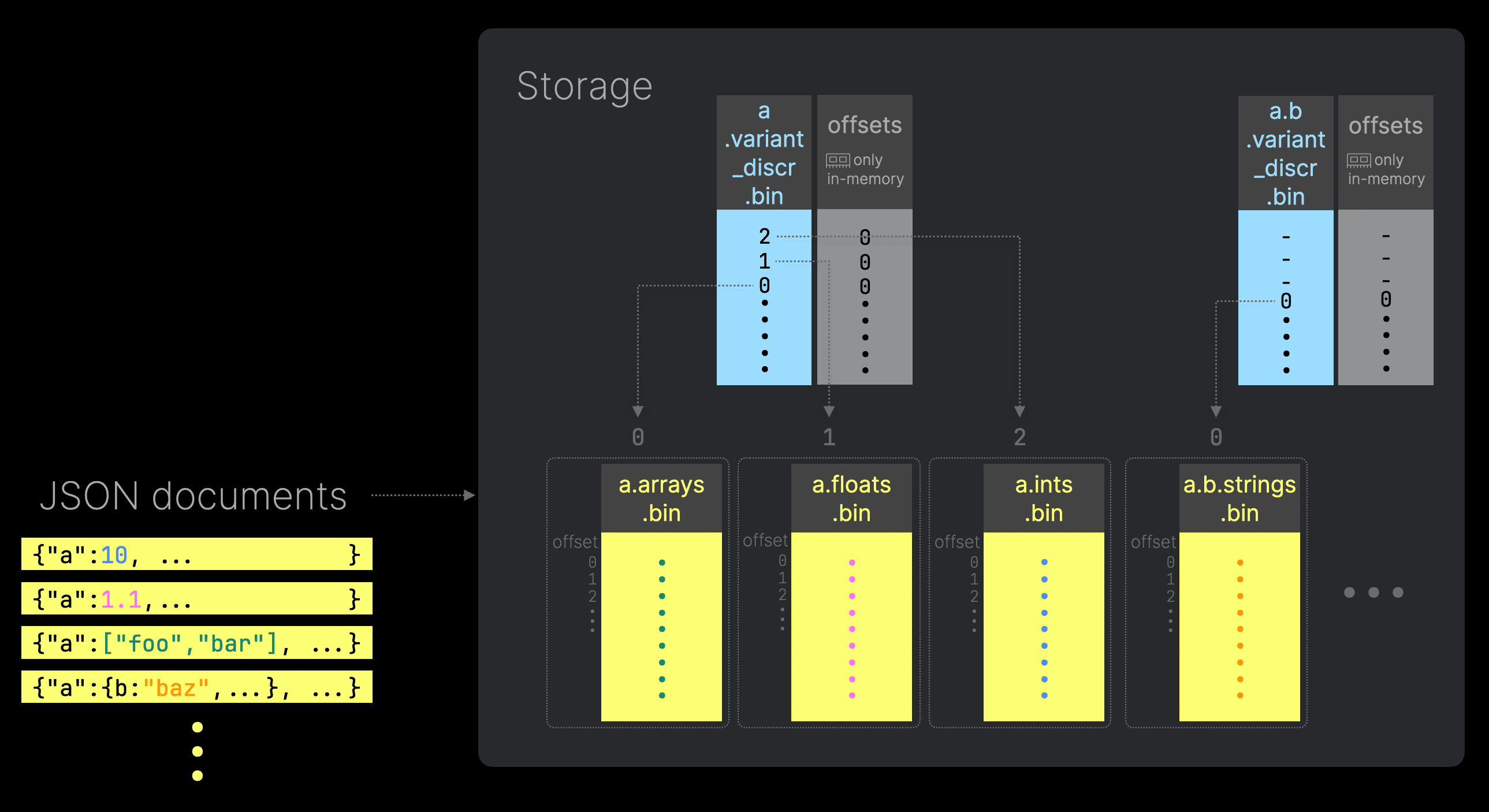
Furthermore, the type does not suffer from sub-column explosion issues resulting from a higher number of unique JSON paths. This is particularly important in the Bluesky data, which has over 1800 unique paths if no filtering is applied. Note that this doesn’t prevent storage of these paths; rather, it simply stores new paths in a single shared data column if limits are exceeded (with statistics to accelerate queries).
This optimized handling of JSON ensures that complex, semi-structured datasets like Bluesky’s can be efficiently stored in the Bronze layer of the architecture. For users curious about the implementation of this new column type, we recommend reading our detailed blog post here.
Bronze layer for raw data
While the original description of the Bronze layer doesn’t promote any filtering or transformation, we are less dogmatic here and believe that minimal filtering and data transformations, which are not destructive, can be useful in issue investigation and allowing data to be replayed in the future. For transformations, we recommend limiting these to those achievable with the Materialized columns as shown below in our Bronze layer schema:
CREATE TABLE bluesky.bluesky_raw
(
`data` JSON(SKIP `commit.record.reply.root.record`, SKIP `commit.record.value.value`),
`_file` LowCardinality(String),
`kind` LowCardinality(String) MATERIALIZED getSubcolumn(data, 'kind'),
`scrape_ts` DateTime64(6) MATERIALIZED fromUnixTimestamp64Micro(CAST(getSubcolumn(data, 'time_us'), 'UInt64')),
`bluesky_ts` DateTime64(6) MATERIALIZED multiIf(getSubcolumn(data, 'kind') = 'commit', parseDateTime64BestEffortOrZero(CAST(getSubcolumn(data, 'commit.record.createdAt'), 'String')), getSubcolumn(data, 'kind') = 'identity', parseDateTime64BestEffortOrZero(CAST(getSubcolumn(data, 'identity.time'), 'String')), getSubcolumn(data, 'kind') = 'account', parseDateTime64BestEffortOrZero(CAST(getSubcolumn(data, 'account.time'), 'String')), toDateTime64(0, 6)),
`dedup_hash` String MATERIALIZED cityHash64(arrayFilter(p -> ((p.1) != 'time_us'), JSONExtractKeysAndValues(CAST(data, 'String'), 'String')))
)
ENGINE = ReplacingMergeTree
PRIMARY KEY (kind, bluesky_ts)
ORDER BY (kind, bluesky_ts, dedup_hash)Some important notes on this schema:
- JSON type - The
datacolumn uses the new JSON type and contains the entire event. We use theSKIPclause to exclude specific paths from the JSON, which analysis showed was responsible for the repetition in structure noted earlier. - Metadata preservation - The
_filecolumn will contain a reference to the file the row originated from. - Materialized columns - The rest of our columns are materialized and computed from the data column at insert time. The
scrape_tscontains the time at which the event was delivered and is extracted from the JSON fieldtime_us. Ourkindcolumn describes the event type, as noted earlier. Thebluesky_tscolumn performs conditional logic, extracting the event timestamp based on thekind- this handles our inconsistency in structure and ensures all events have a consistent timestamp. Finally, we compute the hash of the event in the columndedup_hash. For this, we produce an array of all JSON paths and their values, excluding thetime_us(which differs across duplicate events), using the functionJSONExtractKeysAndValues. The cityHash64 function consumes this array, producing a unique hash. - ReplacingMergeTree - The ReplacingMergeTree engine is used here to eliminate duplicate entries sharing the same sorting key values (
ORDER BY), with deduplication occurring asynchronously during background merges. These merges happen at indeterminate times and cannot be directly controlled - deduplication is eventual only, therefore. In our schema, theORDER BYkey includeskindandbluesky_ts, allowing efficient reads and ensuring strong compression by clustering rows with similar attributes. We appenddedup_hashto uniquely identify rows for deduplication without including it in thePRIMARY KEY. This latter configuration is an optimization that prevents the index fordedup_hashfrom being loaded into memory - a sensible choice as we do not query directly on the hash. A detailed guide on the ReplacingMergeTree can be found here.
Our Bronze layer performs minimal data transformation through materialized columns while providing data deduplication capabilities. Importantly, the choice of ReplacingMergeTree here is optional and decoupled from future layers. Users may prefer a standard MergeTree to inspect duplicates. Our choice here is mainly driven by a desire to minimize storage overhead.
Ingesting data from object storage
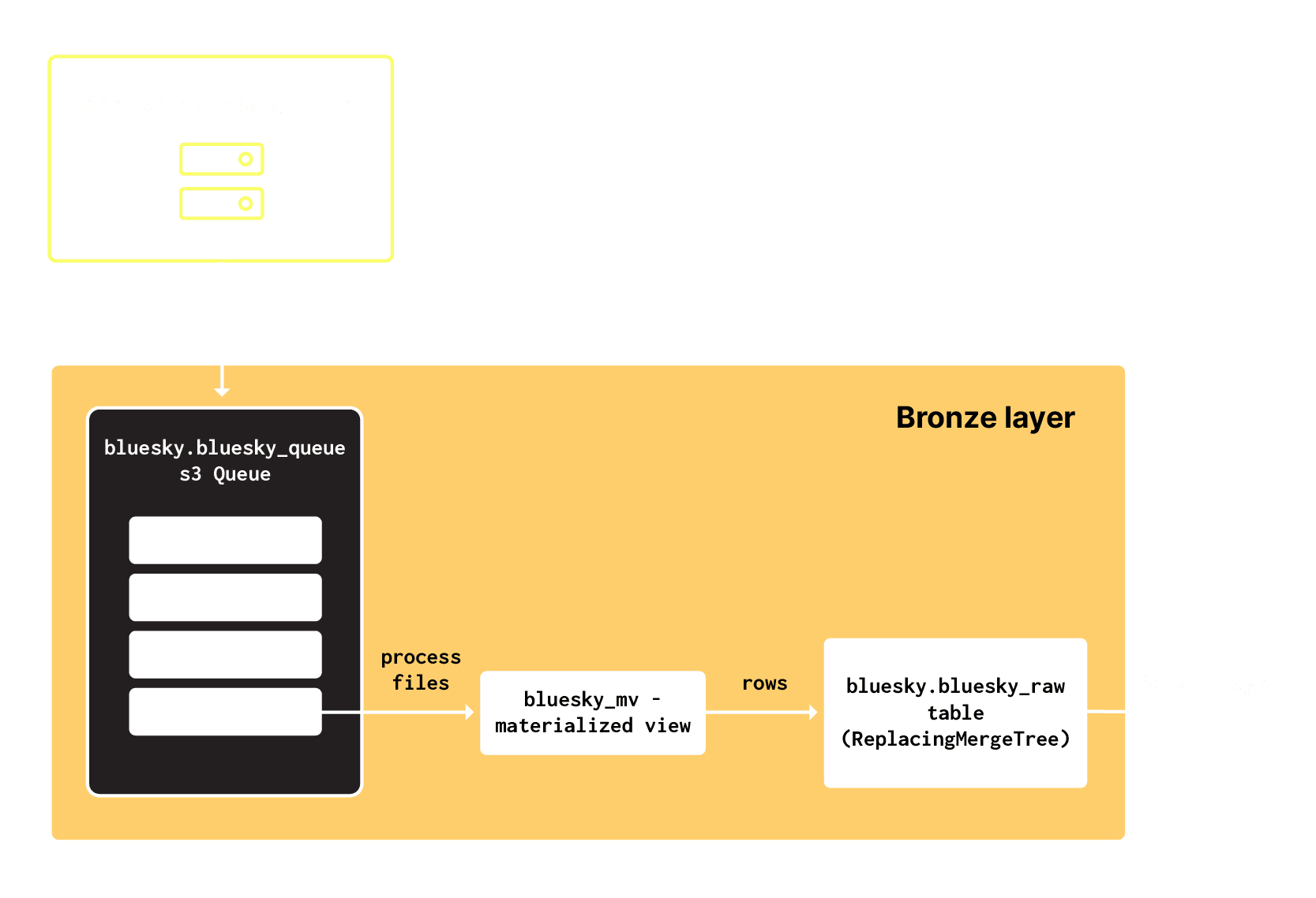
As described above, our ingestion pipeline uses the websocat tool to stream data from the JetStream API, storing events as .csv.gz files in Google Cloud Storage (GCS). This intermediate step provides a few benefits: it enables data replay, retains an original copy of the raw data, and mirrors how many users ingest data from object storage.
To read these files from GCS into our Bronze bluesky_raw table, we use the S3Queue table engine. This engine reads data from S3-compliant object storage, automatically processing new files as they are added to a bucket, and inserts them into a designated table through a materialized view. Creating this table requires a little DDL:
CREATE TABLE bluesky.bluesky_queue
(
`data` Nullable(String)
)
ENGINE = S3Queue('https://storage.googleapis.com/pme-internal/bluesky/*.gz', '', '', 'CSVWithNames')
SETTINGS mode = 'ordered', s3queue_buckets = 30, s3queue_processing_threads_num = 10;Note how we specify the GCS bucket containing the gzipped files and how each row is defined as being a String via the schema declaration. Importantly, we enable "ordered mode" via the setting mode = 'ordered. This forces files to be processed in lexicographic order, ensuring sequential ingestion. While this means files added with earlier sort orders are ignored, it maintains efficient and incremental processing and avoids the need to perform large set differences as required if files have no natural ordering.
Our earlier use of timestamps for files ensures our data is processed in order and new files can be identified quickly by the S3Queue table engine.
Our sql.clickhouse.com environment into which we are loading this data has three nodes, each with 60 vCPUs. The setting s3queue_processing_threads_num assigns the number of threads for file processing per server. In addition, the ordered mode also introduces the setting s3queue_buckets. As recommended, we set this to equal a multiplication of the number of replicas (3) by the number of processing threads (10).
To consume rows from this queue, we need to attach an Incremental Materialized View. This view reads from the queue, executing a SELECT statement on the rows with the result sent to our bronze layer table bluesky_raw.
CREATE MATERIALIZED VIEW bluesky.bluesky_mv TO bluesky.bluesky_raw
(
`data` Nullable(String)
)
AS SELECT
data,
_file
FROM bluesky.bluesky_queue
WHERE isValidJSON(data) = 1Note that we perform basic filtering at this layer, limiting rows sent to our bronze table to valid JSON by filtering with sValidJSON(data) = 1 and including the metadata column _file to ensure we have a record of each row's origin gzip file.
Streaming Bluesky directly to ClickHouse
Note that ClickHouse can directly stream data via JSON input formats, as demonstrated recently by our CTO Alexey Milovidov. This can be achieved by combining the JSON data type and JSON input format. For example,
websocat -n "wss://jetstream1.us-east.bsky.network/subscribe?wantedCollections=app.*" | pv -l | split -l 1000 --filter='clickhouse-client --host sql-clickhouse.clickhouse.com --secure --password "" --query "INSERT INTO bluesky.bluesky_raw (data) FORMAT JSONAsObject"'ClickPipes for ClickHouse Cloud
While the S3Queue table engine allows us to stream data from object storage to ClickHouse, it does come with limitations. As well as being restricted to S3-compliant storage, it offers at least once semantics only. Users of ClickHouse Cloud may prefer ClickPipes - a managed data ingestion offering which provides exactly-once semantics, supports more sources e.g. Kafka and decouples ingestion resources from the cluster. This can be used to replace S3Queue in the above architecture with minimal setup through a guided wizard.
Querying the Bronze layer
While we don’t recommend exposing your bronze table to downstream consumers, our choice of ordering key does allow us to perform efficient data exploration and identify any further quality issues or for data to be replayed through later layers if required.
We noted how at merge time, the ReplacingMergeTree identifies duplicate rows, using the values of the ORDER BY columns as a unique identifier, and retains only the highest version. This, however, offers eventual correctness only - it does not guarantee rows will be deduplicated, and you should not rely on it. To ensure correct answers, users will need to complement background merges with query time deduplication and deletion removal. This can be achieved using the FINAL operator. This incurs a resource overhead and will negatively impact query performance - another reason we don’t recommend exposing Bronze tables to consumers.
We omit the FINAL operator on the above queries, accepting the low number of duplicates in a data exploration exercise. The commit events represent the majority of the data:
SELECT kind, formatReadableQuantity(count()) AS c
FROM bluesky_raw
GROUP BY kind
FORMAT PrettyCompactMonoBlock
┌─kind─────┬─c──────────────┐
│ commit │ 614.55 million │
│ account │ 1.72 million │
│ identity │ 1.70 million │
└──────────┴────────────────┘
3 rows in set. Elapsed: 0.124 sec. Processed 617.97 million rows, 617.97 MB (5.00 billion rows/s., 5.00 GB/s.)
Peak memory usage: 139.03 MiB.Within these commit events, we can inspect the event types using the JSON type path syntax:
SELECT
data.commit.collection AS collection,
count() AS c,
uniq(data.did) AS users
FROM bluesky_raw
WHERE kind = 'commit'
GROUP BY ALL
ORDER BY c DESC
LIMIT 10
FORMAT PrettyCompactMonoBlock
┌─collection───────────────┬─────────c─┬───users─┐
│ app.bsky.feed.like │ 705468149 │ 7106516 │
│ app.bsky.graph.follow │ 406406091 │ 8629730 │
│ app.bsky.feed.post │ 137946245 │ 4323265 │
│ app.bsky.feed.repost │ 90847077 │ 2811398 │
│ app.bsky.graph.block │ 25277808 │ 1523621 │
│ app.bsky.graph.listitem │ 8464006 │ 166002 │
│ app.bsky.actor.profile │ 8168943 │ 4083558 │
│ app.bsky.graph.listblock │ 643292 │ 216695 │
│ app.bsky.feed.threadgate │ 559504 │ 94202 │
│ app.bsky.feed.postgate │ 275675 │ 38790 │
└──────────────────────────┴───────────┴─────────┘
10 rows in set. Elapsed: 19.923 sec. Processed 1.38 billion rows, 122.00 GB (69.50 million rows/s., 6.12 GB/s.)
Peak memory usage: 1003.91 MiB.We can see that the majority of events appear to be likes and follows, as one might expect.
Silver layer for clean data
The Silver layer represents the next stage in the Medallion workflow, transforming raw data from the Bronze layer into a more consistent and well-structured form. This layer addresses data quality issues, performing more filtering, standardizing schemas, performing transformations, and ensuring all duplicates are removed. With ClickHouse, we typically see bronze tables directly mapped to silver equivalents.
We know duplicates will have the same bluesky_ts (and other columns), only different scrape_ts values, with the latter potentially much later - although we established earlier that the majority of duplicates occur within a 20-minute window. To ensure no duplicates are delivered to our gold layer, we introduce the concept of a finite duplication window in our silver layer. Events will be assigned to these duplication windows, which will be offset from the current time based on their bluesky_ts value. These “windows” will periodically be flushed to our gold layer, with a guarantee that only one copy of each event is transferred.
These duplication windows mean we don’t need to de-duplicate events over an infinite period. This can save significant resources and make the problem more manageable - as we show this can be efficiently implemented in ClickHouse.
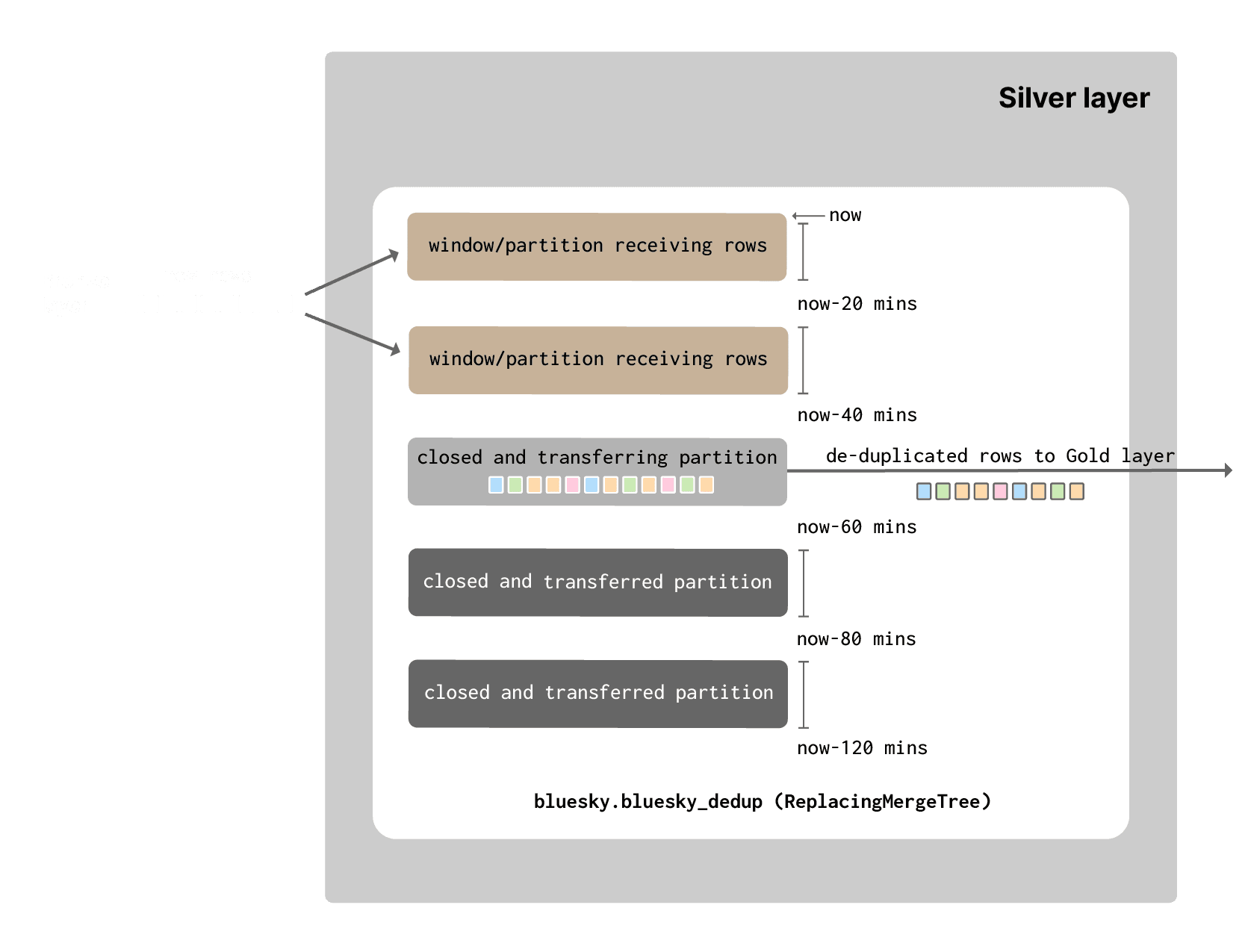
Assigning events to a deduplication window, which tracks real-time and is periodically flushed, relies on data being delivered promptly without a significant delay.
We can establish by querying our bronze table that:
- 90% of events have a
bluesky_tsthat is within 20 minutes from their arrival time in the bronze tier. Here, we assume the "arrival time" is the time extracted from the filename on GCS. This relies on:- The processing of 1m messages at a time does not introduce a significant delay.
- The processing and read time from the S3Queue is not significant. We can check this processing time using the system tables.
- The time extracted from the filename is close to the upload time. We can confirm this with a query against GCS.
- For over 94% of events the difference between the
scrape_tsand thebluesky_tsis less than 20 minutes (in 90% of cases it's even less than 10s). This implies thescrape_tsis also not significantly delayed from the arrival time.
Knowing that our events are typically delivered within 20 min of their bluesky_ts, we can reliably create deduplication windows in our silver tier. To do this, we create a partition in ClickHouse for every 20-minute interval - a partition effectively equates to a window. Events are assigned to each partition based on which interval they fall into, using the toStartOfInterval(bluesky_ts, toIntervalMinute(20)) function. Our resulting silver table schema:
CREATE TABLE bluesky.bluesky_dedup
(
`data` JSON(SKIP `commit.record.reply.root.record`, SKIP `commit.record.value.value`),
`kind` LowCardinality(String),
`scrape_ts` DateTime64(6),
`bluesky_ts` DateTime64(6),
`dedup_hash` String
)
ENGINE = ReplacingMergeTree
PARTITION BY toStartOfInterval(bluesky_ts, toIntervalMinute(20))
ORDER BY dedup_hash
TTL toStartOfMinute(bluesky_ts) + toIntervalMinute(1440) SETTINGS ttl_only_drop_parts=1Although we use a ReplacingMergeTree we will own deduplicate events within each partition i.e. merging will only occur within a partition. Note we use a TTL to expire data after it is older than 1440 seconds (24 hours). The setting ttl_only_drop_parts=1 ensures parts are only dropped if all rows in that part have expired.
A higher number of partitions can cause issues with large part counts, causing query performance issues and "Too many parts" errors. We mitigate this by only keeping a day's worth of partitions (72 in total) in the silver table, using TTL rules to expire older data.
Incremental materialized views for filtering
When applying filtering and de-duplication rules to Bronze data, users often preserve negative matches by sending these to a Dead-Letter table for further analysis. Given we plan to periodically send recent partitions in our silver tier to our gold tier, we don't want events arriving too late. For this reason, and to demonstrate a dead letter queue principle, we'll send any events from the bronze layer where the difference between the scrape_ts and bluesky_ts is greater than 20 minutes to a dead letter queue. Events with a "delay" less than this will be inserted into their partition in the silver table shown above.
To achieve this, we use two incremental materialized views. Each view runs a SELECT query on rows inserted into the bluesky_raw Bronze table, sending results to either the dead letter queue or bluesky_dedup silver table. The difference between these views, other than their target table, is their filter criteria.
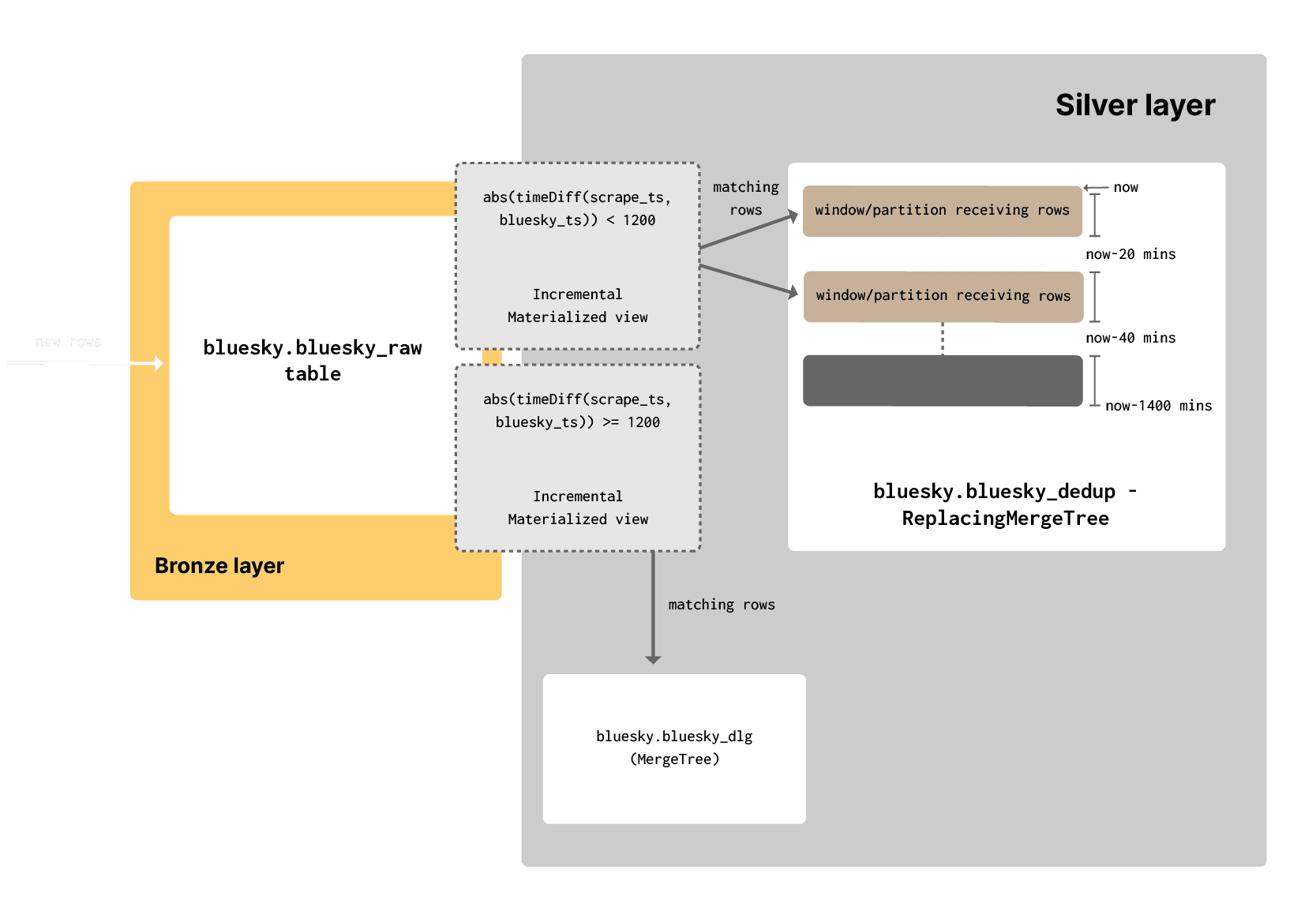
Our view for sending rows to the silver table:
CREATE MATERIALIZED VIEW bluesky.bluesky_dedup_mv TO bluesky.bluesky_dedup
(
`data` JSON,
`kind` LowCardinality(String),
`scrape_ts` DateTime64(6),
`bluesky_ts` DateTime64(6),
`dedup_hash` String
)
AS SELECT
data,
kind,
scrape_ts,
bluesky_ts,
dedup_hash
FROM bluesky.bluesky_raw
WHERE abs(timeDiff(scrape_ts, bluesky_ts)) < 1200Our dead-letter queue table schema and its associated materialized view:
CREATE TABLE bluesky.bluesky_dlq
(
`data` JSON(SKIP `commit.record.reply.root.record`, SKIP `commit.record.value.value`),
`kind` LowCardinality(String),
`scrape_ts` DateTime64(6),
`bluesky_ts` DateTime64(6),
`dedup_hash` String
)
ENGINE = MergeTree
ORDER BY (kind, scrape_ts)
CREATE MATERIALIZED VIEW bluesky.bluesky_dlq_mv TO bluesky.bluesky_dlq
(
`data` JSON,
`kind` LowCardinality(String),
`scrape_ts` DateTime64(6),
`bluesky_ts` DateTime64(6),
`dedup_hash` String
)
AS SELECT
data,
kind,
scrape_ts,
bluesky_ts,
dedup_hash
FROM bluesky.bluesky_raw
WHERE abs(timeDiff(scrape_ts, bluesky_ts)) >= 1200Note we use a standard MergeTree for our dead letter queue.
Sending data to gold layer
The above process leaves partitions populated in our silver tier. Periodically, we want to transfer data from these, guaranteeing events have been fully deduplicated, to our gold tier. We want this to occur reasonably promptly so as to ensure recent data is available in our gold tier for analytics.
We achieve this periodic flushing using a Refreshable Materialized View. These views execute periodically against silver layer tables and enable advanced transformations, such as complex joins, that denormalize the data before it is written to Gold layer tables.
In our case, we want to simply periodically insert data from the latest partition, which shouldn’t receive any more data, to the gold table. This query should be executed with the FINAL clause to ensure all events are deduplicated. While this is typically computationally more expensive than a normal query, we can exploit two properties here:
- The query is only executed periodically - in our case every 20 minutes, shifting the cost to the ingest layer away from the users query.
- We are targeting a single partition with each execution. We can limit query time deduplication to the target partition with the setting
do_not_merge_across_partitions_select_final=1, further optimizing this query and reducing the work required.
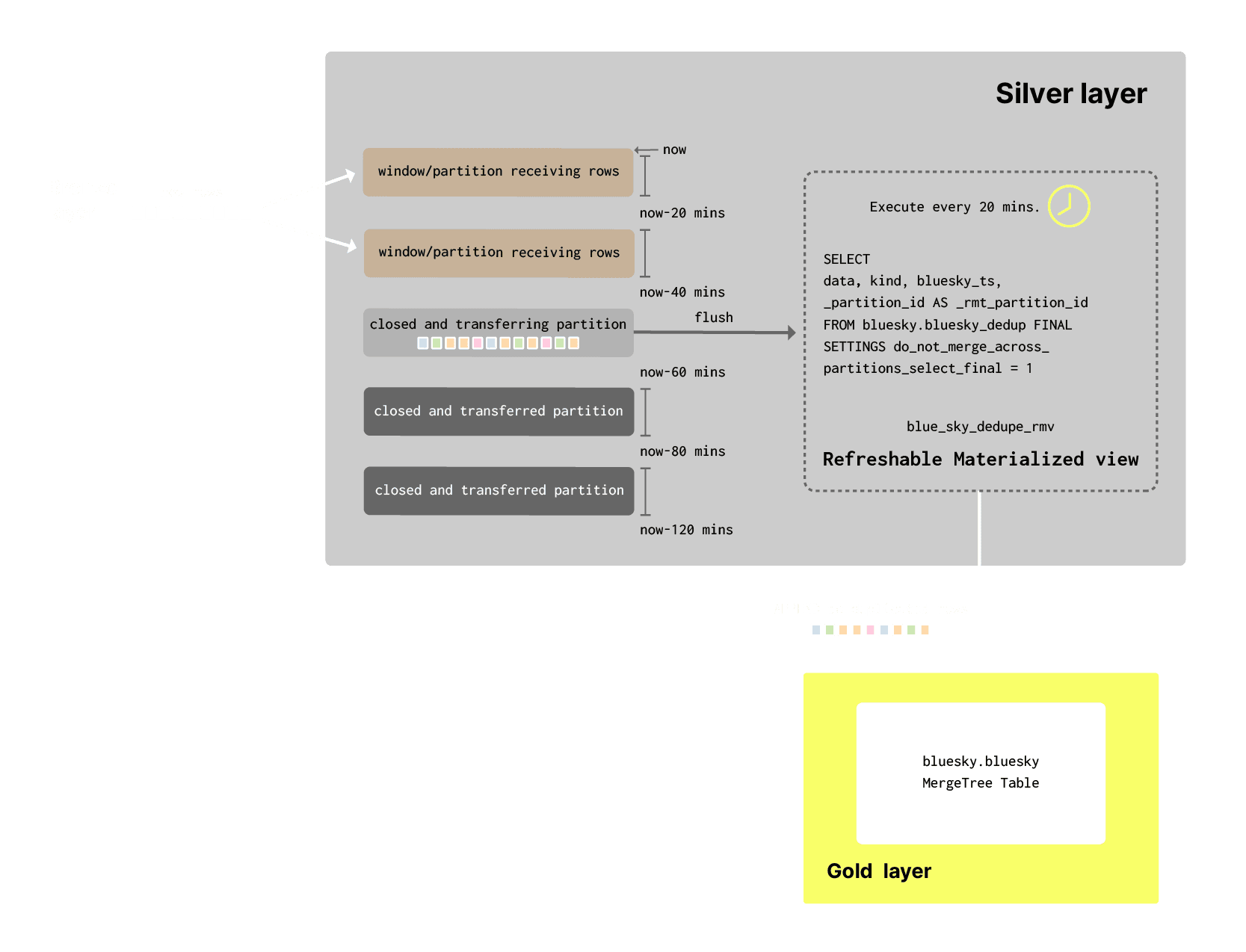
This only requires us to identify the partition to flush to the gold tier each time. Our logic here is captured by the diagram above, but in summary:
- We identify the latest partition in the silver table
bluesky_dedupusing the _partition_id metadata field. We subtract 40 mins from this partition_id (which is a timestamp) giving us the partition 2 time windows ago i.e. X - 2. We refer to this as thecurrent_partition. - Our target gold layer table
blueskyincludes a_rmt_partition_idcolumn populated by the refreshable materialized view, which records from which silver partition each event originated. We use this to identify the most recent partition which was successfully transferred. We add 20mins to this to identify the next partition to process, referring to this asnext_to_process. - If
next_to_processis equal to 1200 we knowblueskywas empty (0 + 1200 seconds = 1200) and no events have been inserted to the gold tier yet i.e. first execution of the view. In this case, we simply use the value ofcurrent_partitionand insert all events where the_partition_id = current_partition. - If
next_to_processis greater than 1200, we know we have already transferred partitions. In this case, if thecurrent_partitionis >=next_to_process, then we know we are least 40 mins behind (2 partitions) the latest partition and use the value ofnext_to_process- inserting all events where the_partition_id = next_to_process. Ifcurrent_partition<next_to_process, then return anoop(0) and don’t move data.
The above logic is designed to be robust to cases where execution is not perfect every 20 minutes e.g. repeated executions or cases where execution is delayed or fails. Our resulting Refreshable Materialized View encapsulating the above logic in its SELECT statement is shown below:
CREATE MATERIALIZED VIEW bluesky.blue_sky_dedupe_rmv
REFRESH EVERY 20 MINUTE APPEND TO bluesky.bluesky
(
`data` JSON(SKIP `commit.record.reply.root.record`, SKIP `commit.record.value.value`),
`kind` LowCardinality(String),
`bluesky_ts` DateTime64(6),
`_rmt_partition_id` LowCardinality(String)
)
AS WITH
(
--step 1
SELECT toUnixTimestamp(subtractMinutes(CAST(_partition_id, 'DateTime'), 40))
FROM bluesky.bluesky_dedup
GROUP BY _partition_id
ORDER BY _partition_id DESC
LIMIT 1
) AS current_partition,
(
--step 2
SELECT toUnixTimestamp(addMinutes(CAST(max(partition_id), 'DateTime'), 20))
FROM bluesky.latest_partition
) AS next_to_process
SELECT
data,
kind,
bluesky_ts,
_partition_id AS _rmt_partition_id
FROM bluesky.bluesky_dedup
FINAL
--step 3 & 4
WHERE _partition_id = CAST(if(next_to_process = 1200, current_partition, if(current_partition >= next_to_process, next_to_process, 0)), 'String')
SETTINGS do_not_merge_across_partitions_select_final = 1This view executes every 20 minutes, delivering clean, deduplicated data to our Gold layer. Note that the data incurs a delay of 40 minutes until it is available here, although users can query the silver layer for more recent data if required.
An astute reader may notice that our query in step 2, and in the earlier diagram, uses the table latest_partition rather than querying _rmt_partition_id in the bluesky gold table. This table is produced by an incremental materialized view and an optimization, which makes identifying the next partition more efficient. This view, shown below, tracks the latest partition from inserts to the gold table.
CREATE MATERIALIZED VIEW bluesky.latest_partition_mv TO bluesky.latest_partition
(
`partition_id` UInt32
)
AS SELECT max(CAST(_rmt_partition_id, 'UInt32')) AS partition_id
FROM bluesky.bluesky
CREATE TABLE bluesky.latest_partition
(
`partition_id` SimpleAggregateFunction(max, UInt32)
)
ENGINE = AggregatingMergeTree
ORDER BY tuple()Gold layer for data analysis
The above refreshable materialized view periodically sends data to our gold tier table bluesky. The schema of this table is shown below:
CREATE TABLE bluesky.bluesky
(
`data` JSON(SKIP `commit.record.reply.root.record`, SKIP `commit.record.value.value`),
`kind` LowCardinality(String),
`bluesky_ts` DateTime64(6),
`_rmt_partition_id` LowCardinality(String)
)
ENGINE = MergeTree
PARTITION BY toStartOfInterval(bluesky_ts, toIntervalMonth(1))
ORDER BY (kind, bluesky_ts)With data fully de-duplicated prior to its insertion, we can use a standard MergeTree. Our ordering key here is chosen exclusively on the access patterns of our consumers and to optimize for compression. Our table here is partitioned by month, principally for data management, and since we expect most queries to read the most recent data.
Note that while we still exploit the JSON type a this tier, we could perform more transformations on the data in the earlier refreshable materialized view e.g. extracting commonly queried columns to the root, or using ALIAS columns, to simplify query syntax.
Materialized views for common queries
This gold layer should be entirely optimized for querying by downstream applications and consumers. While our ordering key aims to facilitate this, not all access patterns will be the same. Until now the most common application for incremental materialized views has been to perform filtering and data insertion between layers. However, our earlier use of a view to compute the next partition, hinted out how else we might optimize other queries.
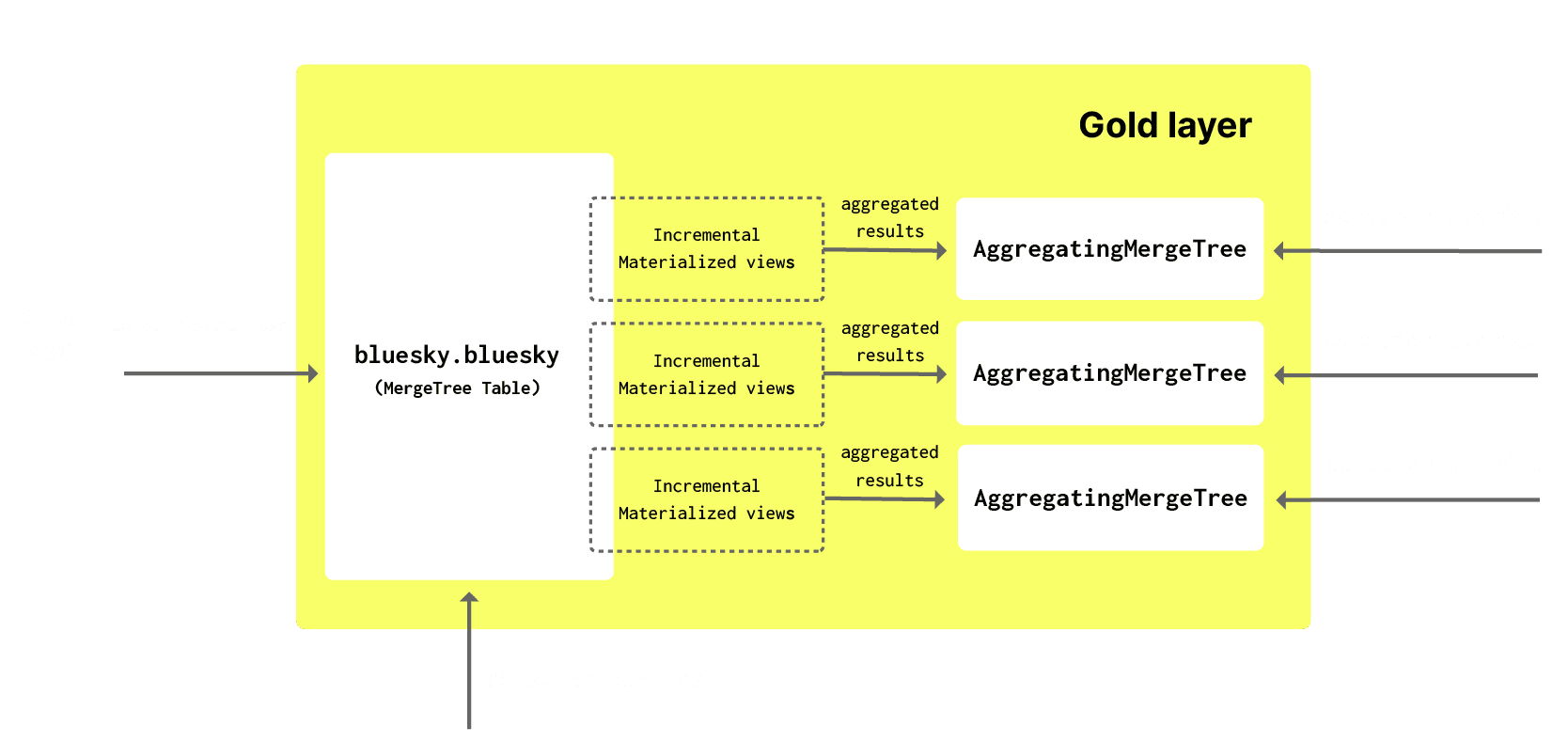
As well as allowing filtering and sending subsets of data to a target table with different ordering keys (optimized for other access patterns), materialized views can be used to precompute aggregates at insert time when rows are added to the gold table. These aggregations results will be a smaller representation of the original data (a partial sketch in the case of aggregations). As well as ensuring the resulting query for reading the results from the target table is simple, it ensures query times are faster than if the same computation was performed on the original data, shifting computation (and thus query latency) from query time to insert time. A full guide on materialized views can be found here.
As an example, consider our earlier query, which computes the most common types of commit events:
SELECT data.commit.collection AS collection, count() AS c, uniq(data.did) AS users
FROM bluesky
WHERE kind = 'commit'
GROUP BY ALL
ORDER BY c DESC
LIMIT 10
┌─collection───────────────┬─────────c─┬───users─┐
│ app.bsky.feed.like │ 269979403 │ 5270604 │
│ app.bsky.graph.follow │ 150891706 │ 5631987 │
│ app.bsky.feed.post │ 46886207 │ 3083647 │
│ app.bsky.feed.repost │ 33249341 │ 1956986 │
│ app.bsky.graph.block │ 9789707 │ 993578 │
│ app.bsky.graph.listitem │ 3231676 │ 102020 │
│ app.bsky.actor.profile │ 1731669 │ 1280895 │
│ app.bsky.graph.listblock │ 263667 │ 105310 │
│ app.bsky.feed.threadgate │ 215715 │ 49871 │
│ app.bsky.feed.postgate │ 99625 │ 19960 │
└──────────────────────────┴───────────┴─────────┘
10 rows in set. Elapsed: 6.445 sec. Processed 516.53 million rows, 45.50 GB (80.15 million rows/s., 7.06 GB/s.)
Peak memory usage: 986.51 MiB.For 500 million events, this query takes around 6 seconds. To convert this to an incremental materialized view, we need to prepare a table to receive the incremental aggregation results:
CREATE TABLE bluesky.top_post_types
(
`collection` LowCardinality(String),
`posts` SimpleAggregateFunction(sum, UInt64),
`users` AggregateFunction(uniq, String)
)
ENGINE = AggregatingMergeTree
ORDER BY collectionNote how we need to use an AggregatingMergeTree and specify the ordering key to be our grouping key - aggregation results with the same value for this column will be merged. The incremental results need to be stored under a special column types SimpleAggregateFunction and AggregateFunction - for this we need to specify the function and associated type.
Our corresponding materialized view, which populates this table as rows are inserted into the gold table, is shown below. Notice how we use the -State suffix to explicitly generate an aggregation state:
CREATE MATERIALIZED VIEW top_post_types_mv TO top_posts_types
AS
SELECT data.commit.collection AS collection, count() AS posts,
uniqState(CAST(data.did, 'String')) AS users
FROM bluesky
WHERE kind = 'commit'
GROUP BY ALLWhen querying this table, we use the -Merge suffix to merge aggregation states.
SELECT collection,
sum(posts) AS posts,
uniqMerge(users) AS users
FROM top_post_types
GROUP BY collection
ORDER BY posts DESC
LIMIT 10
10 rows in set. Elapsed: 0.042 sec.Our query performance has improved by over 150x!
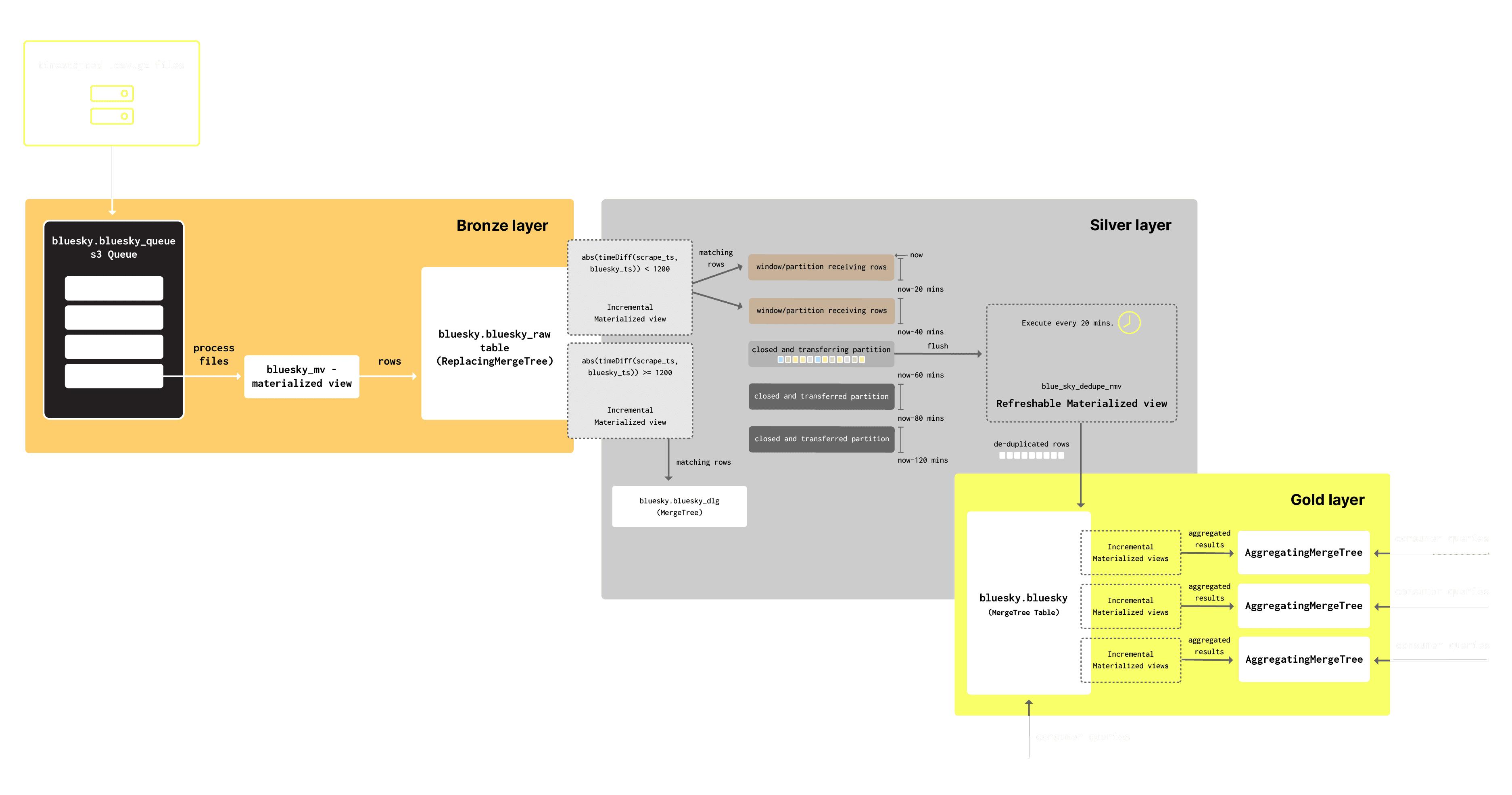
Our final architecture diagram showing all of our layers:
Example queries & visuals @ sql.clickhouse.com
The above represents a very simple example. This data is available in sql.clickhouse.com where the above Medallion workflow is continuously executed. We have provided further materialized views as examples for efficient querying.
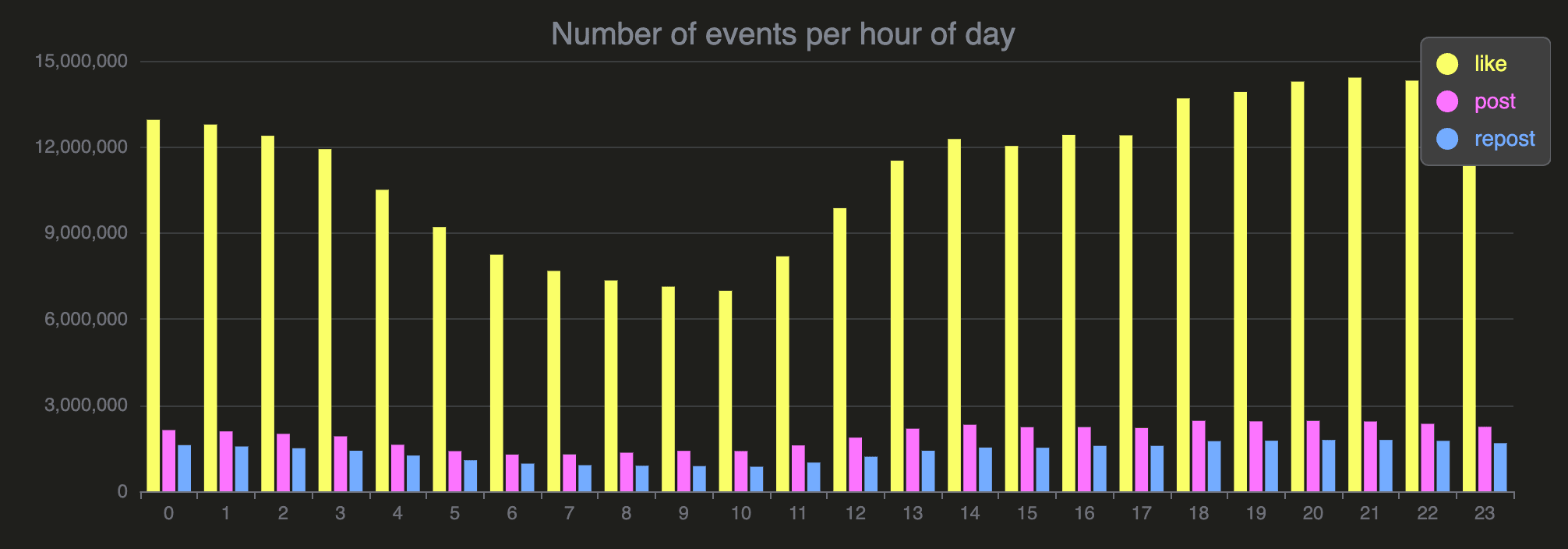
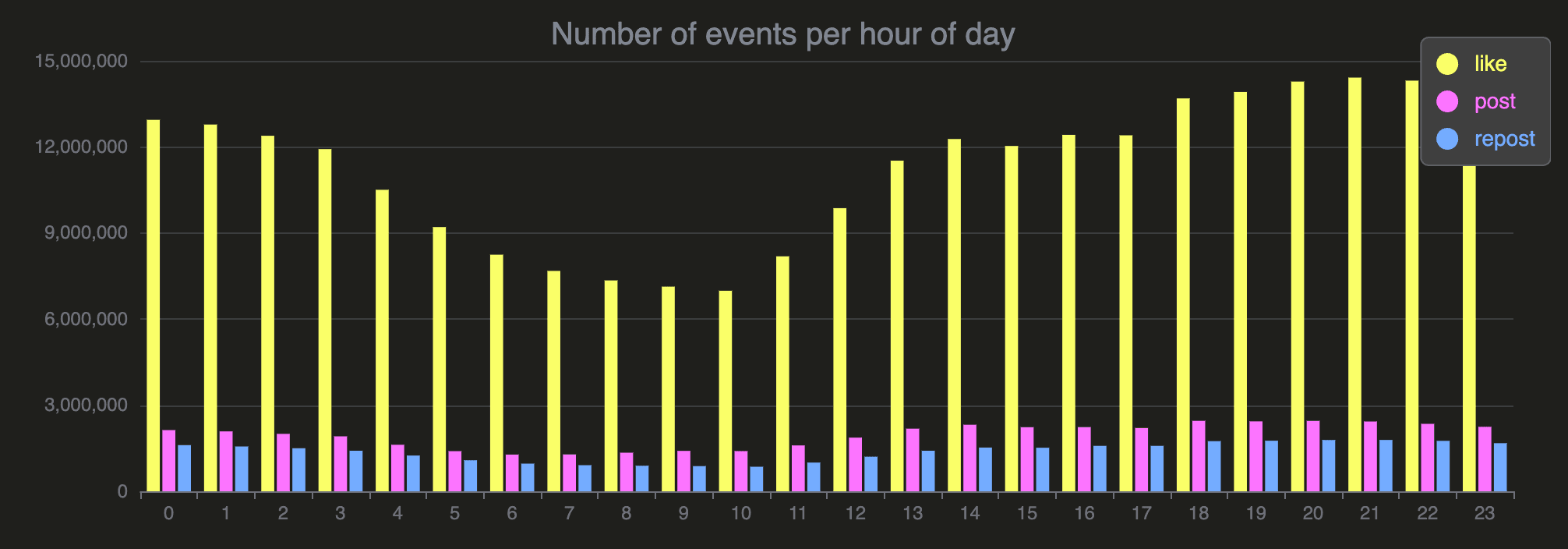
For example, to query for the most popular time for people to like, post, and re-post on Bluesky, users can run the following query:
SELECT event, hour_of_day, sum(count) as count
FROM bluesky.events_per_hour_of_day
WHERE event in ['post', 'repost', 'like']
GROUP BY event, hour_of_day
ORDER BY hour_of_day;
72 rows in set. Elapsed: 0.007 sec.The query runs in 7 milliseconds.
You can run this query in our playground to render the result as a chart:
Below is the corresponding materialized view and its target table, which is populated as rows are inserted into the gold table:
CREATE TABLE bluesky.events_per_hour_of_day
(
event LowCardinality(String),
hour_of_day UInt8,
count SimpleAggregateFunction(sum, UInt64)
)
ENGINE = AggregatingMergeTree
ORDER BY (event, hour_of_day);
CREATE MATERIALIZED VIEW bluesky.events_per_hour_of_day_mv TO bluesky.events_per_hour_of_day
AS SELECT
extract(data.commit.collection, '\\.([^.]+)$') AS event,
toHour(bluesky_ts) as hour_of_day,
count() AS count
FROM bluesky.bluesky
WHERE (kind = 'commit')
GROUP BY event, hour_of_day;For a full list of queries and their associated views, see here. Alternatively, feel free to query either gold or silver tables directly! Some examples to get you started:
- Total events
- When do people use BlueSky
- Top event types
- Top event types by count
- Top event types by unique users
- Most liked posts
- Most liked posts about ClickHouse
- Most reposted posts
- Most used languages
- Most liked users
- Most reposted users
Closing thoughts
In this blog, we showcased a fully realized Medallion architecture built exclusively with ClickHouse, demonstrating how its powerful features can transform raw, semi-structured data into high-quality, query-ready datasets. Through the Bronze, Silver, and Gold tiers, we tackled common challenges such as malformed data, inconsistencies in structure, and a significant amount of duplication. By leveraging ClickHouse’s JSON data type, we efficiently processed inherently semi-structured and highly dynamic data, all while maintaining exceptional performance.
While this architecture provides a robust and flexible workflow, it does introduce inherent delays as data moves through the layers. In our implementation, deduplication windows helped minimize these delays, but a trade-off remains between delivering real-time data and ensuring high data quality. This makes the Medallion architecture particularly suited for datasets with high duplication rates and less critical requirements for real-time availability.
We encourage users to explore it further on our public demo environment at sql.clickhouse.com. Here, you can query the data for free and experiment with the workflow firsthand.
Get started with ClickHouse Cloud today and receive $300 in credits. At the end of your 30-day trial, continue with a pay-as-you-go plan, or contact us to learn more about our volume-based discounts. Visit our pricing page for details.



