
The release train keeps on rolling. We are super excited to share the updates in 23.2.
And, we already have a date for the 23.3 release, please register now to join the community call on March 30 at 9:00 AM (PST) / 6:00 PM (CEST).
Release Summary
-
18 new features.
-
30 performance optimisations.
-
43 bug fixes.
Multiple SQL language features and extended integrations support. But, as always, there are a few headline items worth checking out:
Multi-stage PREWHERE (Alexander Gololobov)
The PREWHERE clause has been a feature in ClickHouse since the first OSS release. This optimization is designed to reduce the number of rows a query is required to read, and prior to 22.2 used, a 2-step execution process. When a query runs, the granules required for reading are first identified using the table's primary key. This identifies a set of granules, each containing a number of rows (8192 by default). However, not all of the rows inside these granules will match the filter clause on the primary keys - since a granule can contain a range of values or because the WHERE condition does not use the primary key. In order to identify the correct rows and before the SELECT columns can be read, additional filtering is therefore desirable. This is performed in a 2nd stage of reading using PREWHERE, which allows both the primary and non-primary key columns in the WHERE clause to be further filtered. This required the granules to be read and filtered with a linear scan.
ClickHouse would move columns to the PREWHERE stage based on internal heuristics. Users could alternatively manually specify columns to be used where the automatic choices were not effective, using the explicit PREWHERE clause. Each of these columns would be filtered independently in this 2nd stage of reading, and only those rows which satisfied all of the conditions read in the latter stages of the pipeline.
We visualize this below:

In 23.2, this pre-where optimization has been split into multiple steps. Columns are filtered in the order of smallest to largest (uncompressed size). The rows identified from applying a filter on a column can be used to further reduce the granules scanned in the subsequent step. As each step becomes more efficient, the combined cost for all steps is reduced. We illustrate this below:

This behavior currently needs to be enabled via the setting enable_multiple_prewhere_read_steps=1. When set, it makes sense in most cases to set move_all_conditions_to_prewhere. While not yet on by default, we recommended users try this on their queries and report their findings in either our slack community or as a github issue. We expect to see appreciable performance improvements, especially when filtering by large columns.
Iceberg, Right Ahead - Support for Apache Iceberg (ucasFL)
23.2 brings read support for the Apache Iceberg format.
What is Apache Iceberg?
Originally developed by Netflix, Apache Iceberg is a high-performance table format that is independent of any specific SQL engine - allowing it to be queried by any SQL engine, including now ClickHouse!
This table format is increasingly popular and has rapidly become an industry standard for managing data in data lakes. While Parquet has established itself as the data file format of choice for data lakes, tables would typically be represented as a set of files located in a bucket or folder. This is typically sufficient for ad-hoc querying but makes managing large datasets cumbersome and means table abstractions by tools such as ClickHouse were loosely established at best, with no support for schema evolution or write consistency. Most importantly for ClickHouse, this approach would rely on file listing operations - potentially expensive on object stores such as s3. Filtering of data requires all data to be opened and read, other than limited abilities to restrict files by using glob patterns on a naming schema.
Iceberg aims to address these challenges by bringing SQL table-like functionality to files in a data lake in an open and accessible manner. Specifically, Iceberg provides:
- Support for schema evolution to track changes to a table over time
- Ability to create snapshots of data that define a specific version. These versions can be queried, allowing users to "time travel" between generations.
- Support for rolling back to prior versions of data quickly
- Automatic partitioning of files to assist with filtering - historically, users would need to do this error-prone task by hand and maintain it across updates.
- Metadata that query engines can use to provide advanced planning and filtering.
These table capabilities are provided by manifest files. These manifests maintain a history of the underlying data files with a complete description of their schema, partitioning, and file information. This abstraction allows for the support of immutable snapshots, organized efficiently in a hierarchical structure that tracks all changes in a table over time.
Importantly, the underlying file formats do not change, with Apache Iceberg supporting Parquet, ORC, and Avro.
ClickHouse Support
ClickHouse currently supports reading v1 (v2 support is coming soon!) of the Iceberg format via the iceberg table function and Iceberg table engine. Below we provide examples of these for the house price dataset, by computing the most expensive towns in England on average over the last 20 years and their most expensive street. These queries should be reproducible on your own ClickHouse instance, with this dataset public.
With the table function:
SELECT
town,
round(avg(price)) AS avg_price,
argMax(street, price) AS street
FROM iceberg('https://datasets-documentation.s3.eu-west-3.amazonaws.com/house_prices_iceberg/')
GROUP BY town
HAVING street != ''
ORDER BY avg(price) DESC
LIMIT 10
┌─town──────────────┬─avg_price─┬─street─────────┐
│ GATWICK │ 28232812 │ NORTH TERMINAL │
│ VIRGINIA WATER │ 903457 │ WEST DRIVE │
│ CHALFONT ST GILES │ 830274 │ PHEASANT HILL │
│ COBHAM │ 720600 │ REDHILL ROAD │
│ BEACONSFIELD │ 690689 │ AYLESBURY END │
│ ESHER │ 638641 │ COPSEM LANE │
│ KESTON │ 606303 │ WESTERHAM ROAD │
│ GERRARDS CROSS │ 601461 │ NARCOT LANE │
│ ASCOT │ 559106 │ BAGSHOT ROAD │
│ WEYBRIDGE │ 552827 │ THE HEIGHTS │
└───────────────────┴───────────┴────────────────┘
10 rows in set. Elapsed: 18.151 sec. Processed 27.07 million rows, 1.37 GB (1.49 million rows/s., 75.50 MB/s.)Equivalent query with the table engine:
CREATE TABLE house_iceberg
ENGINE = Iceberg('https://datasets-documentation.s3.eu-west-3.amazonaws.com/house_prices_iceberg/')
SELECT
town,
round(avg(price)) AS avg_price,
argMax(street, price) AS street
FROM house_iceberg
GROUP BY town
HAVING street != ''
ORDER BY avg(price) DESC
LIMIT 10Aside from v2 support, we also plan to support querying specific snapshots in future versions - right now ClickHouse queries only the latest snapshot. Additionally, the metadata files provided by Iceberg contain column statistics for the data file themselves, e.g., the upper bounds of columns which we plan to exploit to avoid data read operations.
Support for Correlation Matrices (FFFFFFFHHHHHHH from Tencent)
In 23.2, we add support for computing correlation matrices. As a reminder, a correlation matrix is a table that contains the correlation coefficient between all possible values in a table. This represents an easy way to summarise a large dataset and identify columns that are either strongly or negatively correlated. Used by a number of statistical analysis techniques, this calculation historically would require either a very complex or multiple queries in ClickHouse. With the new corrMatrix function, this query is now trivial.
For the example below, we compute the correlation matrix for a number of github metrics often closely watched by developers - most notably the number of stars. We limit this to repositories with at least 100 stars. For this, we utilize the Github Events dataset, which is documented as part of our test datasets and available in our demo environment sql.clickhouse.com for users to query.
SELECT arrayMap(x -> round(x, 3), arrayJoin(corrMatrix(stars, issue_raised, follows, prs, forks, commit_comment_event, issues_commented))) AS correlation_matrix
FROM
(
SELECT
countIf(event_type = 'WatchEvent') AS stars,
countIf(event_type = 'IssuesEvent') AS issue_raised,
countIf(event_type = 'FollowEvent') AS follows,
countIf(event_type = 'PullRequestEvent') AS prs,
countIf(event_type = 'ForkEvent') AS forks,
countIf(event_type = 'CommitCommentEvent') AS commit_comment_event,
countIf(event_type = 'IssueCommentEvent') AS issues_commented
FROM github_events
GROUP BY repo_name
HAVING stars > 100
)
┌─correlation_matrix──────────────────────┐
│ [1,0.298,0.003,0.22,0.552,0.063,0.291] │
│ [0.298,1,0.035,0.376,0.223,0.104,0.557] │
│ [0.003,0.035,1,0.004,0.004,0.015,0.003] │
│ [0.22,0.376,0.004,1,0.277,0.151,0.685] │
│ [0.552,0.223,0.004,0.277,1,0.057,0.262] │
│ [0.063,0.104,0.015,0.151,0.057,1,0.175] │
│ [0.291,0.557,0.003,0.685,0.262,0.175,1] │
└─────────────────────────────────────────┘
7 rows in set. Elapsed: 44.847 sec. Processed 5.72 billion rows, 51.60 GB (127.65 million rows/s., 1.15 GB/s.)Recall that the value of each entry in the matrix represents the Pearson correlation coefficient, where 1 represents a strong linear relationship, -1 is a negative relationship, and 0 is no correlation at all.
The above matrix is best visualized using a heatmap. Below we use Superset.
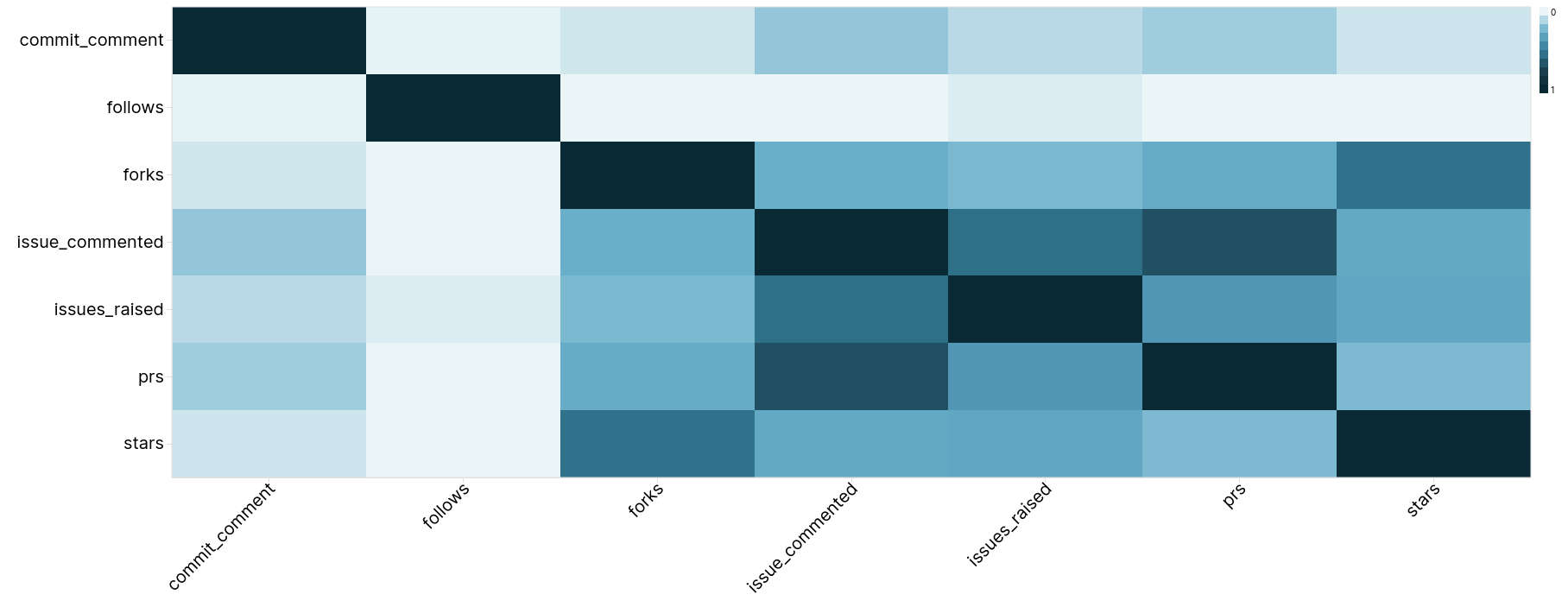
We leave drawing conclusions to the reader but stars in particular seem to be poorly correlated with other repo activity, with the exception of possibly the number of forks.
Support for Amazon MSK (Mark Zitnik)
Last month, we announced the beta release of our open-source Kafka Connect Sink for ClickHouse. In response to demand from our community, we can now announce this connector is fully compatible with AWS' hosted offering MSK.
Metabase Plugin GA Release (Serge Klochkov)
At ClickHouse, we passionately believe supporting our open-source ecosystem is fundamental to adoption and ensuring our users are successful. In this spirit, this month we announced the GA release of our ClickHouse plugin for the OSS visualization tool Metabase. Working with the Metabase team, this plugin is also now available in Metabase Cloud. For users needing a visualization tool for ClickHouse, we recommend users watch our recent webinar with our friends at Metabase.



