RubyGems analytics are now available on ClickGems. Learn more in the announcement blog.

Ruby developers, we have exciting news! Following the tremendous success of ClickPy for the Python community, we're thrilled to introduce free Ruby gem analytics via sql.clickhouse.com in partnership with Ruby Central. This allows the Ruby community to do Gem analytics on all downloads since 2017 using just SQL - over 180 billion rows!
If you're interested in how this service came about, read on, otherwise skip straight to the example queries below, or head over to the public service.
It all started with Python #

In early 2024, we launched ClickPy, a simple app that provides analytics on Python package downloads. The dataset behind ClickPy logs every Python package download via the PyPI repository - every time a developer runs pip install, a row is added to ClickHouse.
Within just nine months, the dataset surpassed 1 trillion rows, with the total number of unique downloads now exceeding 1.43 trillion and growing by over 2 billion rows per day.
In addition to the web interface, package maintainers and enthusiasts can query the dataset directly via sql.clickhouse.com using just SQL. This free service has proven incredibly popular, now serving over half a million queries each month! (the above example queries actually use this service).
For those curious, we’ve blogged and documented how ClickPy works, including the ClickHouse features it leverages to deliver millisecond-level performance - even on datasets with over a trillion rows - and how we maintain a stable publicly available service that users can use fairly.
Welcome Ruby Central #
At ClickHouse, we love large datasets. So when Marty Haught from Ruby Central reached out to ask if we could offer a similar service for the Ruby community, we were thrilled:
Hi Dale,
Several members of the RubyGems team were marveling at the ClickPy site and wondered if we could do something similar for RubyGems. Do you know if ClickHouse is receptive to hosting analytics for OSS package repositories?
Thanks, Marty
In addition to the PyPI dataset, sql.clickhouse.com hosts over 35 public datasets, all documented and available to query for free. The opportunity to host another package dataset- especially one that’s valuable to the open source community, technically interesting, and large - was too good to pass up.
A quick call with Marty and Samuel Giddens from the Ruby Central team confirmed that, perhaps unsurprisingly, the structure of the RubyGems data is very similar to the PyPI data.
Ruby datasets #
Ruby Central is a nonprofit organization that supports the Ruby language and its ecosystem. Among other things, they maintain the RubyGems package repository and the gem command-line tool - essential infrastructure for the Ruby community.
If you've ever installed a Ruby package (or "gem"), you've used RubyGems. Much like pip for Python, Ruby developers install packages with a simple command - gem install rails.
Behind the scenes, this triggers a request to RubyGems.org, Ruby Central's central package registry. Every time a developer installs a gem, metadata such as the package name, version, platform, and timestamp gets logged.
This produces a few interesting datasets.
Download logs #
Each row includes the timestamp, package name and version, platform details, and extensive metadata about the client environment, such as the Ruby version, operating system, whether the download was triggered by Bundler or CI, and geolocation data like country and city. It also captures technical details of the request and response, including TLS versions, HTTP status codes, response times, and caching behavior. This makes it ideal for exploring download trends, adoption patterns, and usage contexts across the Ruby ecosystem.
As well as being the largest dataset at over 180 billion rows (as of April 2025), with data available from 2017, the download logs were also the one we aspired to maintain as up-to-date as possible. Given the size of this dataset, Ruby Central offered to provide this via a GCS bucket in gzip compressed NDJSON format, with files delivered every hour.
Daily aggregate downloads #
Ruby Central also publishes a pre-aggregated dataset with daily statistics for each gem. Each row includes the package name, the date, the number of downloads that occurred on that day (daily_downloads), and the cumulative total up to that point (total_downloads). This dataset is periodically updated and can be downloaded from github. While not having the granularity and breadth of metadata as the above dataset, this pre-aggregated version is useful for quick analysis, making it easy to analyze trends over time without scanning raw download logs.
Experienced ClickHouse users may be wondering why we need this dataset if we have the raw data? Although it's true, we can generate aggregate daily downloads using a materialized view natively in ClickHouse (see below) or even just group by day in a query, these aggregate statistics go back to 2013 and are thus useful.
Weekly data dumps #
Ruby Central also publishes weekly exports of gem metadata to GitHub, similar in spirit to the project metadata datasets available for PyPI. These provide a richer view of the Ruby ecosystem beyond just download counts:
- attestations – contains signed metadata for specific gem versions, including SBOMs and security attestations, stored as JSON blobs.
- deletions – tracks removed gem versions, recording the gem name, version, platform, and the user who deleted it.
- dependencies – captures declared gem dependencies along with their version requirements and scopes (e.g. runtime or development).
- gem_downloads – stores the total download count for each gem version, enabling point-in-time snapshots of popularity.
- linksets – includes links associated with each gem, such as homepage, documentation, source code, and issue tracker URLs.
- rubygems – the master list of all gems, with basic metadata including name, creation date, and organization info.
- versions – detailed records of every published gem version, including authors, descriptions, licenses, requirements, checksums, and whether it has been yanked.
These datasets make it easy to analyze package metadata, dependencies, and trends over time - powering everything from dashboards to supply chain insights.
The latter of these two datasets are usually updated weekly in github. While the daily aggregate downloads datasets are updated incrementally with new files added for the last 7 days, the weekly data dump tables are all updated with the current files replaced.
Additionally, we want to make sure all loading was performed using ClickHouse native constructs - minimizing the need for ingestion logic and processing.
Loading the data #
Download logs #
Despite being the largest dataset, the download logs are actually the simplest to load. The schema for this dataset is shown below:
CREATE TABLE rubygems.downloads
(
`timestamp` DateTime,
`request_path` String,
`request_query` String,
`user_agent` Tuple(
agent_name String,
agent_version String,
bundler String,
ci String,
command String,
jruby String,
options String,
platform Tuple(
cpu String,
os String,
version String),
ruby String,
rubygems String,
truffleruby String),
`tls_cipher` String,
`time_elapsed` Int64,
`client_continent` String,
`client_country` String,
`client_region` String,
`client_city` String,
`client_latitude` String,
`client_longitude` String,
`client_timezone` String,
`client_connection` String,
`request` String,
`request_host` String,
`request_bytes` Int64,
`http2` Bool,
`tls` Bool,
`tls_version` String,
`response_status` Int64,
`response_text` String,
`response_bytes` Int64,
`response_cache` String,
`cache_state` String,
`cache_lastuse` Float64,
`cache_hits` Int64,
`server_region` String,
`server_datacenter` String,
`gem` String,
`version` String,
`platform` String
)
ENGINE = MergeTree
ORDER BY (gem, toDate(timestamp))
Ruby Central pushes these logs as compressed JSON to a GCS bucket. ClickHouse has native support for reading both JSON and gzip files from GCS. We could, for example, query these files in place:
SELECT
toStartOfMonth(timestamp) AS month,
count()
FROM gcs('https://storage.googleapis.com/clickhouse-rubygems/backfill/2017//**/*.json.gz', '', '')
GROUP BY month
ORDER BY month DESC
LIMIT 12
┌──────month─┬───count()─┐
│ 2017-12-01 │ 662622048 │
│ 2017-11-01 │ 716549049 │
│ 2017-10-01 │ 693602509 │
│ 2017-09-01 │ 686176096 │
│ 2017-08-01 │ 608606033 │
│ 2017-07-01 │ 556639959 │
│ 2017-06-01 │ 487825551 │
└────────────┴───────────┘
7 rows in set. Elapsed: 252.989 sec. Processed 4.41 billion rows, 236.12 GB (17.44 million rows/s., 933.34 MB/s.)
Peak memory usage: 902.94 MiB.
To load the historical data into ClickHouse, we simply imported using an INSERT INTO SELECT. For example, the following query imports the entirety of 2018 (around 10 billion rows from 120k files totaling 530GB of compressed JSON) in ~ 20 minutes.
INSERT INTO rubygems.downloads_2018
FROM s3Cluster('default', 'https://storage.googleapis.com/clickhouse-rubygems/backfill/2018/**/*.json.gz', '', '')
SETTINGS max_insert_threads = 16, min_insert_block_size_rows = 0, min_insert_block_size_bytes = 2083333333, parallel_distributed_insert_select = 2
0 rows in set. Elapsed: 1317.014 sec. Processed 10.14 billion rows, 562.52 GB (7.70 million rows/s., 427.12 MB/s.)
Peak memory usage: 47.25 GiB.
You may notice we have tuned the settings for this query. These settings assign more resources to the import and parallelize the insert across all nodes (
parallel_distributed_insert_select = 2), with the aim of minimizing the load time. For more information on how to tune similar imports, we recommend the guide "Optimizing for S3 Insert and Read Performance".
While this addresses the historical backfill, to consume new files and insert them into ClickHouse, we use the S3Queue table engine.
This table engine allows the streaming consumption of data from S3 (compatible with GCS). As files are added to a bucket (hourly), ClickHouse will automatically process these files and insert them into a designated table. With this capability, users can set up simple incremental pipelines with no additional code.
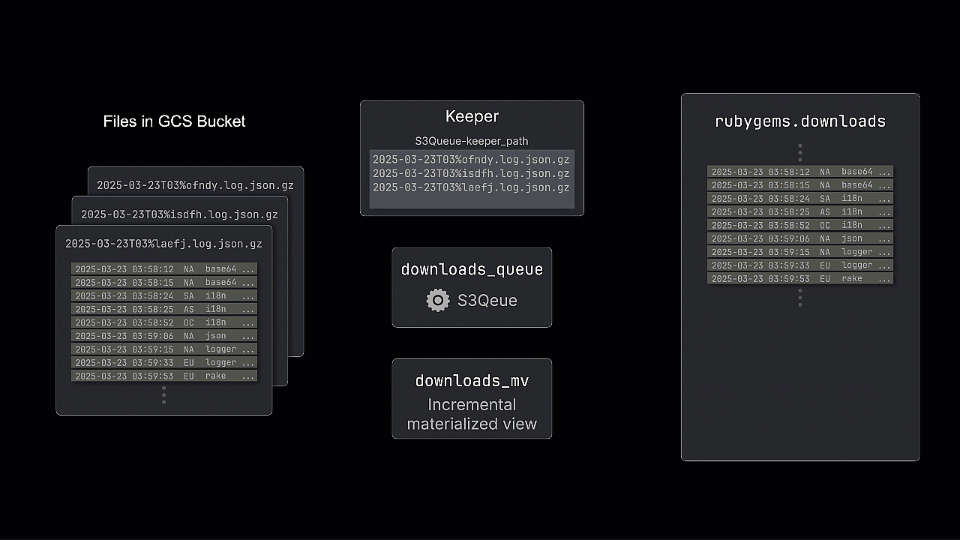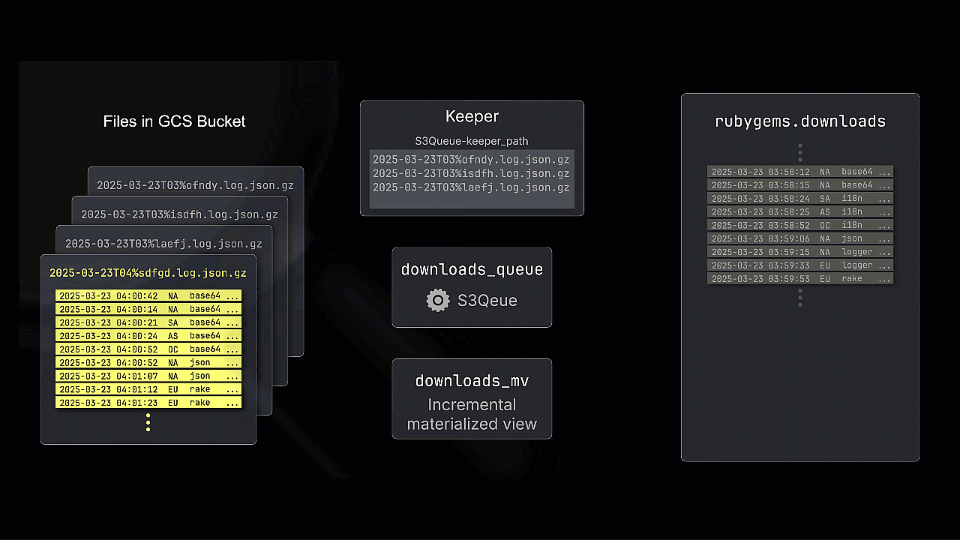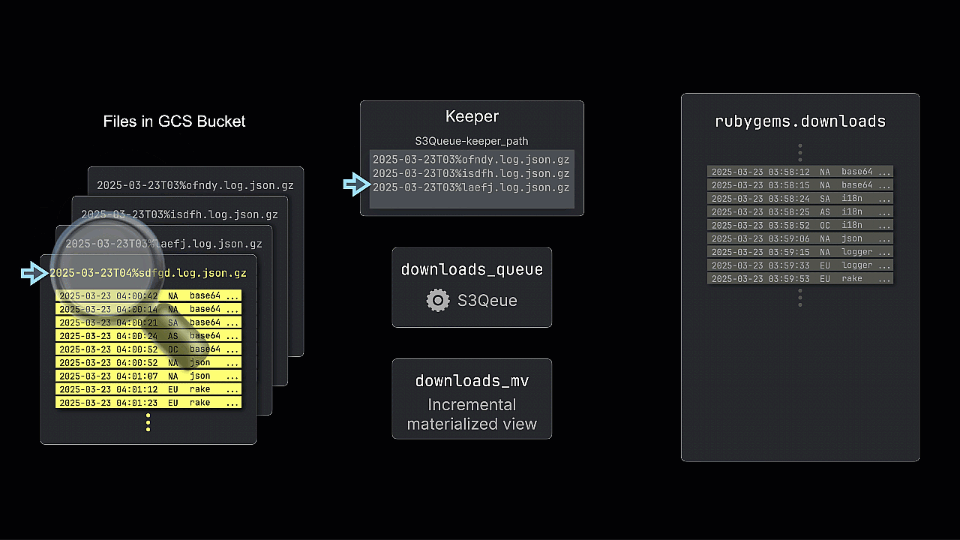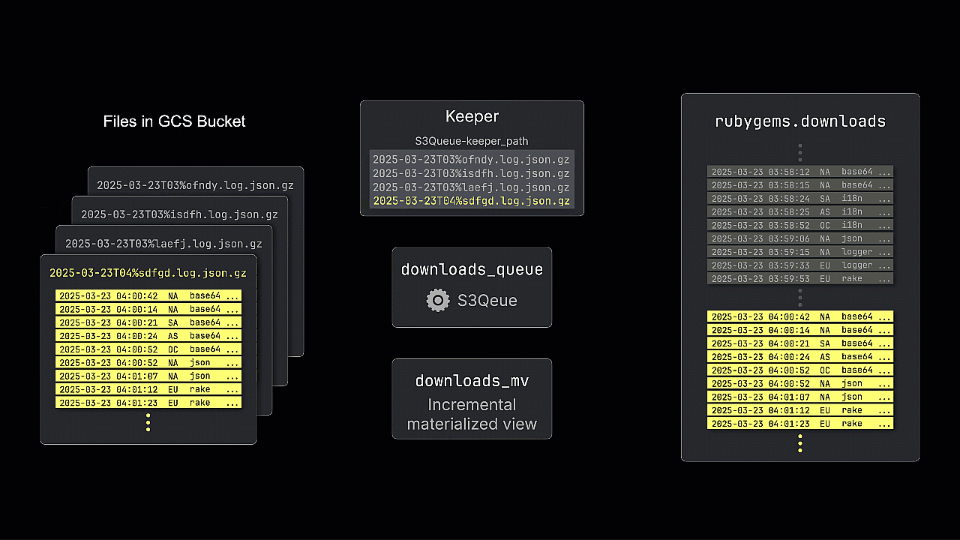
The engine works by periodically polling the bucket and tracking the files present, storing the state in a ClickHouse Keeper node. By default, the list of files retrieved on each poll is compared against the stored list to identify new files. The diagram above shows how a new file is processed (and added to Keeper) and inserted into the queue table. While this doesn’t store the data itself, incremental materialized views can subscribe and transform rows before inserting them into a table for querying.
To create our pipeline we need only two DDL commands - one to create the queue, the second to create the incremental materialized view which subscribes to the changes and pushes the results to our above downloads table.
CREATE TABLE rubygems.downloads_queue_2025_04_01
(
`timestamp` DateTime,
`request_path` String,
`request_query` String,
...
`gem` String,
`version` String,
`platform` String
)
ENGINE = S3Queue('https://storage.googleapis.com/clickhouse-rubygems/incremental/**/*.json.gz', '', '[HIDDEN]', 'JSONEachRow', 'gzip')
SETTINGS mode = 'ordered', s3queue_polling_min_timeout_ms='6000', s3queue_polling_max_timeout_ms='9000', s3queue_buckets = 30, s3queue_processing_threads_num = 10;
CREATE MATERIALIZED VIEW rubygems.downloads_2025_04_01_mv TO rubygems.downloads
AS SELECT *
FROM rubygems.downloads_queue_2025_04_01
A few important notes:
-
The files themselves have no natural order in their naming (within an hour). We, therefore, use the S3queue engine in
unorderedmode. This requires the table engine to track all files (in Keeper) vs exploiting a natural ordering (ordered mode).Use of ordered mode requires a guarantee that the files are delivered in order. This mode works by maintaining a cursor of the highest lexicographical name, using this to identify new files on each iteration. Should files be delivered out of order, it can therefore potentially miss files. The current export logic of the files does not currently provide such guarantees - hence the use of
unorderedmode.While the ordered mode is more efficient for import (tracking only the last-seen file), it places additional constraints on how files are exported. Given the volume (almost 200 billion rows), the Ruby Central team wanted to ensure any export was performed in parallel. This makes ordering impractical: they receive one file per Fastly region per hour, and each arrival triggers a Lambda function that processes the file independently. These Lambda invocations happen concurrently, and there's no reliable or desirable way to serialize their delivery.
Given the possible out-of-order delivery, we thus use unordered mode with S3Queue.
-
We create a new S3Queue and materialized view each day, also dropping the queue and view from the 2 days ago. This ensures each queue doesn't need to track an excessive number of files (less than a 1000). Each day's queue also thus has a 48 hour gratuitous period, in case files are delivered late.
-
We adjust the queue defaults, increasing the minimum and maximum polling time as well as increasing the number of tracked files to 2000.
-
Note the pattern
**/*.json.gzprovides recursive processing of files. -
Our sql.clickhouse.com environment into which we are loading this data has three nodes, each with 60 vCPUs. The setting
s3queue_processing_threads_numassigns the number of threads for file processing per server. In addition, the ordered mode also introduces the settings3queue_buckets. As recommended, we set this to equal a multiplication of the number of replicas (3) by the number of processing threads (10).
With this in place, the data started to flow in. An example query exploring downloads per hour for the bundler gem:
With all data loaded from 2017, this dataset totals around 180 billion rows, compressing from around 9.5 TB of Gzipped JSON (160 TB uncompressed) to less than 5 TB in ClickHouse:
Daily aggregate downloads #
Our second dataset is hosted in github and updated periodically (approximately weekly).
To backfill this data, we simply cloned the repo and ran the following command, using clickhouse-local to parse the files and insert them into our Cloud instance:
clickhouse local --query "SELECT replaceOne( _file, '.csv','')::Date as date, * FROM file('/data/rubygems/gem-daily-downloads/**/*.csv') FORMAT Native" | clickhouse client --host sql-clickhouse.clickhouse.com --secure --password --query "INSERT INTO rubygems.daily_downloads FORMAT Native"
To incrementally update this dataset, we use a simple script.
This bash script incrementally updates the daily aggregate downloads dataset by querying ClickHouse for the latest date already ingested, then downloading any missing CSV files from the RubyGems GitHub repository. It loops through each subsequent day, checks if a file exists, and if so, ingests it using native ClickHouse commands. This ensures the dataset stays up-to-date with minimal logic and no need for external orchestration.
Unlike the download logs, which are streamed via GCS and the S3Queue engine, this dataset is smaller, pre-aggregated, and only updated weekly - making it ideal for a simple pull-and-load pattern. By combining ClickHouse’s ability to query remote files and ingest them in place, the script keeps things lightweight while ensuring continuity in the public dataset hosted at sql.clickhouse.com.
We run this script in Google Cloud Run.
This dataset is around 600m rows as of April 2025.
Weekly data dumps #
The weekly data dumps are also held in Github but are updated in their entirety i.e. all files are replaced for each update. All files belonging to a dataset can be found in a single folder e.g. the full list of Ruby Gems and their metadata.
This makes the files easy to consume. We simply use a refreshable materialized view, which periodically executes an import query - sending the results to a target table. This same approach can be used for both the initial and incremental load.
For example, the following refreshable materialized view executes once a week reading the Ruby Gems package files from a github folder using the url function.
CREATE MATERIALIZED VIEW rubygems.rubygems_mv
REFRESH EVERY 1 WEEK APPEND TO rubygems.rubygems
(
`id` UInt32,
`name` String,
`created_at` DateTime64(6),
`updated_at` DateTime64(6),
`indexed` LowCardinality(String),
`organization_id` LowCardinality(String)
)
AS SELECT *
FROM url('https://raw.githubusercontent.com/segiddins/rubygems-org-db-dumps/refs/heads/main/tables/rubygems/part_{0..100}.csv', 'CSVWithNames')
This view sends the data to the rubygems.rubygems table:
CREATE TABLE rubygems.rubygems
(
`id` UInt32,
`name` String,
`created_at` DateTime64(6),
`updated_at` DateTime64(6),
`indexed` LowCardinality(String),
`organization_id` LowCardinality(String)
)
ENGINE = ReplacingMergeTree
ORDER BY (name, id)
Users wanting to load this data, and any of the other tables in the weekly data dumps, into their own ClickHouse instance could simply create the above table and run
INSERT INTO SELECT * FROM url('https://raw.githubusercontent.com/segiddins/rubygems-org-db-dumps/refs/heads/main/tables/rubygems/part_{0..100}.csv', 'CSVWithNames'). For other table schemas, check out this sql.clickhouse.com query.
There are a few important notes with respect to this view and sorting key.
The view uses the clause APPEND. This means all rows are appended to the target table rubygems.rubygems vs. the default strategy of replacement.
The above policy means the Ruby Gems data will contain duplicates. To address this, we use a ReplacingMergeTree, which de-duplicates data based on unique values of the ordering key (name and id in the above case - these uniquely identify a package). This deduplication process is eventual with duplicates removed through a background merge process.
To address this we can either use the FINAL keyword when querying these tables, which removes any outstanding duplicates at query time, or ensure we aggregate by the ordering keys. The overhead here is expected to be negligible as the volume of data is low ~ millions.
Note that these tables are all relatively small (for ClickHouse), with them predominantly providing metadata. As we demonstrate below, this can be useful for joining the data with other datasets:
Materialized views #
Similar to ClickPy we wanted to create incremental materialized views to accelerate common queries for users.
In its simplest form, an incremental materialized view is simply a query that triggers when an insert is made to a table.
Key to this is the idea that Materialized views don't hold any data themselves. They simply execute a query on the inserted rows and send the results to another "target table" for storage.
Importantly, the query that runs can aggregate the rows into a smaller result set, allowing queries to run faster on the target table. This approach effectively moves work from query time to insert time.
The main motivation here is that the aggregate logs are actually estimates and updated weekly, whereas the results from our materialized view will be precise and updated hourly. This also represents a simple example :)
CREATE MATERIALIZED VIEW rubygems.downloads_per_day_mv TO rubygems.downloads_per_day AS SELECT toDate(timestamp) AS date, gem, count() AS count FROM rubygems.downloads GROUP BY date, gem
This view executes the aggregation below on blocks of data as they are inserted into the downloads table.
SELECT toDate(timestamp) AS date, gem, count() AS count FROM rubygems.downloads GROUP BY date, gem
The result is sent to the "target table" rubygems.downloads_per_day. This, in turn, has a special engine configuration:
CREATE TABLE rubygems.downloads_per_day
(
`date` Date,
`gem` String,
`count` UInt64
)
ENGINE = SummingMergeTree
ORDER BY (gem, date)
The SummingMergeTree replaces all the rows with the same ORDER BY key (gem and date in this case) with one row which contains summarized values for the columns with the numeric data type. Rows with the same project value will be asynchronously merged, and the count will be summed - hence "Summing." This summing behavior means it can be incrementally updated as new data arrives in the downloads table.
To show how this is useful, suppose we wished to look at the downloads per day for the bundler gem. Using the original downloads table:
For most of you, this query probably took around 7-10s to run. Contrast with the equivalent query using the materialized view table dowloads_per_day:
Just a little bit faster I'm sure! Welcome to the power of incremental materialized views - we’ve shifted the computation from query time to insert time.
We maintain a few other materialized views, we use in the queries below but plan to extend these over time and on request.
Example queries #
To get our users started we’ve assembled some example queries. These largely cover the queries used in ClickPy. Feel free to try any of the queries below or head over to sql.clickhouse.com for the full catalog.
Most downloaded gems #
Using our above materialized view:
Emerging gems #
This query uses the materialized view gems_downloads_max_min which mains the min and max date that a gem was downloaded.
WITH (
SELECT max(max_date)
FROM rubygems.gems_downloads_max_min
) AS max_date
SELECT
gem,
sum(count) AS c
FROM rubygems.downloads_per_day
WHERE gem IN (
SELECT name
FROM rubygems.gems_downloads_max_min
GROUP BY name
HAVING min(min_date) >= (max_date - toIntervalMonth(3))
)
GROUP BY gem
ORDER BY c DESC
LIMIT 7
Downloads over time for a gem #
If day granularity is sufficient we can use the downloads_per_day view. For the bundler gem:
For more granular analysis the full fidelity download events can be used (we recommend filtering by date ranges in this case).
Downloads by Ruby version over time #
For the bundler gem:
--Daily gem downloads by version over time. NOTE - We recommended applying a time range (weeks max) to avoid quota limits.
WITH top_versions AS
(
SELECT user_agent.ruby
FROM rubygems.downloads
WHERE (timestamp BETWEEN '2025-01-01' AND '2025-04-03') AND (gem = 'bundler')
GROUP BY user_agent.ruby
ORDER BY count() DESC
LIMIT 10
)
SELECT
user_agent.ruby AS ruby_version,
toStartOfHour(timestamp) AS hour,
count() AS downloads
FROM rubygems.downloads
WHERE (timestamp BETWEEN '2025-01-01' AND '2025-04-03') AND (gem = 'bundler') AND user_agent.ruby IN top_versions
GROUP BY
hour,
ruby_version
ORDER BY
hour DESC,
ruby_version ASC
In the future we’ll provide materialized views to accelerate this query.
Downloads by system over time #
For the bundler gem:
WITH systems AS
(
SELECT user_agent.platform.os
FROM rubygems.downloads
WHERE (timestamp BETWEEN '2025-01-01' AND '2025-04-03')AND (gem = 'bundler') AND (user_agent.platform.os NOT IN ('', 'unknown'))
GROUP BY user_agent.platform.os
ORDER BY count() DESC
LIMIT 5
)
SELECT
user_agent.platform.os AS name,
toStartOfHour(timestamp) AS hour,
count() AS total_downloads
FROM rubygems.downloads
WHERE (timestamp BETWEEN '2025-01-01' AND '2025-04-03') AND (gem = 'bundler') AND (user_agent.platform.os IN (systems))
GROUP BY
name,
hour
ORDER BY
hour ASC,
name DESC
In the future we’ll provide materialized views to accelerate this query.
Downloads for latest Gem version (using dictionaries) #
Some queries require us to use more than 1 table. The weekly metadata tables are particularly useful for more complex queries.
We also provide a number of dictionaries for users to use to accelerate queries. These in-memory structures allow key-value lookups. For example, the following two dictionaries allow the lookup of a gem's id but its name and vice versa:
CREATE DICTIONARY rubygems.name_to_id ( `name` String, `id` UInt64 ) PRIMARY KEY name SOURCE(CLICKHOUSE(QUERY 'SELECT name, id FROM rubygems.rubygems')) LIFETIME(MIN 86400 MAX 90000) LAYOUT(COMPLEX_KEY_HASHED()) CREATE DICTIONARY rubygems.id_to_name ( `id` UInt64, `name` String ) PRIMARY KEY id SOURCE(CLICKHOUSE(QUERY 'SELECT id, name FROM rubygems.rubygems')) LIFETIME(MIN 86400 MAX 90000) LAYOUT(FLAT())
To learn more about dictionaries we recommend the "Dictionary" docs guide
For example, to lookup the bundler gems id:
Conversely, to look up the name from the id 19969:
This is particularly useful in the weekly datasets, where not all tables have a gem name. For example to find the latest version of a gem we can use the versions table, exploiting the above dictionary for the id needed:
We can now combine this with our downloads table to find the weekly downloads for the latest version of the gem.
WITH (
SELECT canonical_number
FROM rubygems.versions
WHERE rubygem_id = dictGet(rubygems.name_to_id, 'id', 'bundler')
ORDER BY arrayMap(x -> toUInt8OrDefault(x, 0), splitByChar('.', canonical_number)) DESC
LIMIT 1
) AS latest_version
SELECT
toStartOfWeek(timestamp) AS week,
count() AS downloads
FROM rubygems.downloads
WHERE (gem = 'bundler') AND (version = latest_version)
GROUP BY week
ORDER BY week ASC
Conclusion & future plans #
We’re just getting started with Ruby Gem analytics and have plenty more planned.
Next up: we’re adding more materialized views and reworking the ClickPy UI to support the Ruby dataset, making it easy for developers to explore gem trends through an interactive web experience. ClickGems, anyone?
Until then, researchers, maintainers, and curious developers can query the data freely at sql.clickhouse.com, with support for both raw download logs and pre-aggregated daily statistics.
A huge thank you to Marty, Samuel, and the wider Ruby Central community for their collaboration, encouragement, and ongoing support in making this possible.



