Earlier this year, the team at ClickHouse decided to start officially supporting and contributing to the OpenTelemetry exporter for ClickHouse, which has recently graduated to beta for both the logging and tracing (the highest level in the OTel exporter ecosystem at the moment). In this post, we wanted to use this milestone as an opportunity to highlight the OpenTelemetry and ClickHouse integration, a key consideration when evaluating the top OpenTelemetry-compatible platforms.
What is OpenTelemetry?
OpenTelemetry (OTel for short) is an open-source framework from the Cloud Native Computing Foundation (CNCF) that enables the standardized collection, processing, and export of telemetry data. Structured around the main observability pillars (traces, metrics, and logs), OTel provides a standard for instrumentation, but how this data is stored and queried is what separates the best open-source observability solutions from traditional, siloed stacks.
OTel also provides instrumentation libraries for multiple languages, which automate data gathering with minimal code changes. An OTel Collector manages this data flow, acting as a gateway to export telemetry data to various backend platforms. By offering a consistent observability standard, OTel helps teams collect telemetry data efficiently and gain insights into complex systems.
Why does OpenTelemetry matter?
In the fragmented and vendor-dominated space of observability, OTel brings a standardized, flexible, and open approach. As software applications become more complex, spanning microservices and cloud-based architectures, it's challenging to track what is happening within and between systems. OTel addresses this by enabling consistent collection and analysis of key telemetry data.
The vendor-neutral approach is especially valuable, allowing teams to avoid the vendor lock-in common with proprietary platforms such as New Relic. By using OTel, organizations can easily switch between or combine different observability backends to fit their needs, reducing costs and boosting flexibility. The standardized format for telemetry data simplifies integration across systems, even in multi-cloud and hybrid environments.
OpenTelemetry + ClickHouse
In a previous blog, we explained how tools like ClickHouse allow us to handle large volumes of observability data, making it a viable open-source alternative to proprietary systems. SQL-based observability works well for teams familiar with SQL, providing control over costs and extensibility. As open-source tooling like OTel continues to evolve, this approach is becoming increasingly practical for organizations with significant data needs.
A key component of the SQL-based Observability stack is the OpenTelemetry Collector. The OTel collector gathers telemetry data from SDKs or other sources and forwards it to a supported backend. It acts as a centralized hub to receive, process, and export telemetry data. The OTel Collector can function as either a local collector for a single application (agent) or as a centralized collector for multiple applications (gateway).
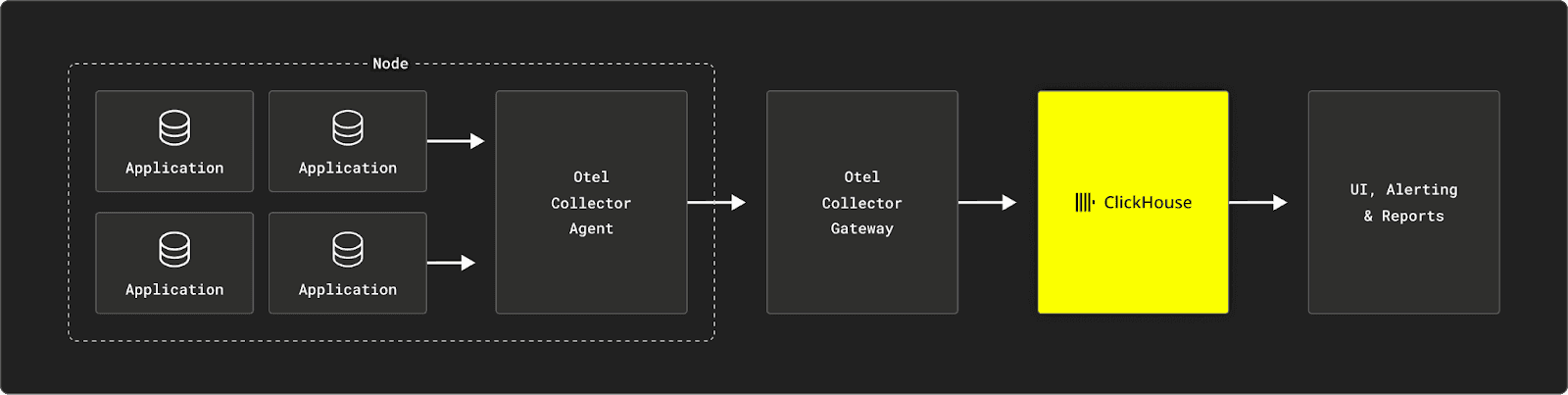
The Collector includes a range of exporters that support various data formats. Exporters send the data to the chosen backend or observability platform, like ClickHouse. Developers can configure multiple exporters to route telemetry data to different destinations as needed.
Since we use OpenTelemetry for our own needs at ClickHouse and we see many successful users adopting it, we decided to officially support the OTel Exporter for ClickHouse and contribute to the development of this component. The OTel exporter for ClickHouse is already in great shape thanks to the great work of its maintainers (@hanjm, @dmitryax, @Frapschen) and the community contributions, so for us, it’s really about making sure we can support key use cases at scale.
One Schema to Rule Them All
The schema question was the first one we decided to tackle. There is no "one size fits all". This is a hard reality to accept when designing an exporter for ClickHouse. As with any large-scale database, you need to have a good idea of what you're inserting and how you plan on getting it back out. ClickHouse performs best when you optimize your schema for your use case.
In the case of OpenTelemetry data, this is even more relevant. Even the designers of OpenTelemetry faced this issue when writing the SDKs. How do we fit such a large ecosystem of languages and tools into a single telemetry pipeline? Every team has its own pattern for searching logs and traces, and this needs to be considered when modeling a table schema. How long is data kept? Does your architecture prefer filtering by service name, or do you have another identifier you must partition by? Do you need columns for filtering by Kubernetes pod names? It's impossible to include everyone, and we can't sacrifice performance and usability by aiming to do so.
"One size fits most" is the best we can hope for and is the case for the ClickHouse exporter. A default schema is provided for logs, traces, and metrics. The default schema will perform well for most common telemetry use cases, but if you're trying to build a logging solution at scale, then we recommend you take time to understand how your data is being stored and accessed within ClickHouse and pick a relevant primary key as we did for our internal logging solution which stores more than 43 Petabyte of OTel data (as of October 2024).

Stats from LogHouse, ClickHouse Cloud OTel-based logging platform
The exporter will create the required tables for you by default, but this isn't recommended for production workloads. If you want to replace a table schema without modifying the exporter's code, you can do so by simply creating the tables yourself. The configuration file simply defines the table names to which data will be sent. This requires that the column names match what is inserted by the exporter, and the types are compatible with the underlying data.
{
"Timestamp": "2024-06-15 21:48:06.207795400",
"TraceId": "10c0fcd202c978d6400aaa24f3810514",
"SpanId": "60e8560ae018fc6e",
"TraceFlags": 1,
"SeverityText": "Information",
"SeverityNumber": 9,
"ServiceName": "cartservice",
"Body": "GetCartAsync called with userId={userId}",
"ResourceAttributes": {
"container.id": "4ef56d8f15da5f46f3828283af8507ee8dc782e0bd971ae38892a2133a3f3318",
"docker.cli.cobra.command_path": "docker%20compose",
"host.arch": "",
"host.name": "4ef56d8f15da",
"telemetry.sdk.language": "dotnet",
"telemetry.sdk.name": "opentelemetry",
"telemetry.sdk.version": "1.8.0"
},
"ScopeName": "cartservice.cartstore.RedisCartStore",
"ScopeAttributes": {},
"LogAttributes": {
"userId": "71155994-7b72-428a-9d51-43962a82ae43"
}
}An example of an OpenTelemetry Produced Log Event
If you need a significantly different schema than what is provided by default, you may use a ClickHouse materialized view. The default table schemas provide a usable starting point, but they can also be seen as a guide on what data the exporter can expose. If you’re modeling your own table, you can choose to include or exclude certain columns or even change their type. For our internal logging, we used this as an opportunity to extract columns related to Kubernetes, such as pod names. We then put this into the table’s primary key to optimize the performance for our specific query patterns.
It is best to disable table creation by default for production deployments. If you have multiple exporter processes running, they will race to create the tables (possibly with different versions!). In this user guide, we list the best practices for using ClickHouse as an observability store.
Below, we display the custom schema we use for LogHouse, our ClickHouse Cloud Logging Solution:
CREATE TABLE otel.server_text_log_0
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`EventDate` Date,
`EventTime` DateTime,
`TraceId` String CODEC(ZSTD(1)),
`SpanId` String CODEC(ZSTD(1)),
`TraceFlags` UInt32 CODEC(ZSTD(1)),
`SeverityText` LowCardinality(String) CODEC(ZSTD(1)),
`SeverityNumber` Int32 CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`Body` String CODEC(ZSTD(1)),
`Namespace` LowCardinality(String),
`Cell` LowCardinality(String),
`CloudProvider` LowCardinality(String),
`Region` LowCardinality(String),
`ContainerName` LowCardinality(String),
`PodName` LowCardinality(String),
`query_id` String CODEC(ZSTD(1)),
`logger_name` LowCardinality(String),
`source_file` LowCardinality(String),
`source_line` LowCardinality(String),
`level` LowCardinality(String),
`thread_name` LowCardinality(String),
`thread_id` LowCardinality(String),
`ResourceSchemaUrl` String CODEC(ZSTD(1)),
`ScopeSchemaUrl` String CODEC(ZSTD(1)),
`ScopeName` String CODEC(ZSTD(1)),
`ScopeVersion` String CODEC(ZSTD(1)),
`ScopeAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`LogAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
INDEX idx_trace_id TraceId TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_thread_id thread_id TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_thread_name thread_name TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_Namespace Namespace TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_source_file source_file TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_scope_attr_key mapKeys(ScopeAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_scope_attr_value mapValues(ScopeAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_res_attr_key mapKeys(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_res_attr_value mapValues(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_log_attr_key mapKeys(LogAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_log_attr_value mapValues(LogAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_body Body TYPE tokenbf_v1(32768, 3, 0) GRANULARITY 1
)
ENGINE = SharedMergeTree
PARTITION BY EventDate
ORDER BY (PodName, Timestamp)
TTL EventTime + toIntervalDay(180)
SETTINGS index_granularity = 8192, ttl_only_drop_parts = 1;The OTel Schema for LogHouse, ClickHouse Cloud Logging Solution
A few observations about the LogHouse schema:
- We use the ordering key
(PodName, Timestamp). This is optimized for our query access patterns where users usually filter by these columns. Users will want to modify this based on their expected workflows. - We use the
LowCardinality(String)type for all String columns with the exception of those with very high cardinality. This dictionary encodes our string values and has proven to improve compression, and thus read performance. Our current rule of thumb is to apply this encoding for any string columns with a cardinality lower than 10,000 unique values. - Our default compression codec for all columns is ZSTD at level 1. This is specific to the fact our data is stored on S3. While ZSTD can be slower at compression when compared to alternatives, such as LZ4, this is offset by better compression ratios and consistently fast decompression (around 20% variance). These are preferable properties when using S3 for storage.
- Inherited from the OTel schema, we use
bloom_filtersfor the keys for any maps and values. This provides a secondary index on the keys and values of the maps based on a Bloom filter data structure. A Bloom filter is a data structure that allows space-efficient testing of set membership at the cost of a slight chance of false positives. In theory, this allows us to evaluate quickly whether granules on disk contain a specific map key or value. This filter might make sense logically as some map keys and values should be correlated with the ordering keys of pod name and timestamp i.e. the specific pods will have specific attributes. However, others will exist for every pod - we don’t expect these queries to be accelerated when querying on these values as the chances of the filtering condition being met by at least one of the rows in a granule is very high (in this configuration a block is a granule as GRANULARITY=1). For further details on why a correlation is needed between the ordering key and column/expression, see here. This general rule has been considered for other columns such as Namespace. Generally, these Bloom filters have been applied liberally and need to be optimized - a pending task. The false-positive rate of 0.01 has also not been tuned.
Next Steps
There is room for improvement for the ClickHouse exporter. Our goal is to keep the exporter up to date with the latest developments from the ClickHouse server. As new optimizations are found, and new performance benchmarks are tested, we can find ways to improve the default schema for logs, traces, and metrics.
One of the key features that will impact many observability use cases is ClickHouse's recent support for a new JSON data type, which will simplify how attributes are stored and searched for logs and traces. In addition to new features, OTel+ClickHouse users frequently submit feedback in the repository, which has led to many feature improvements and bug fixes over the past year.
Appendix: Contributing to OpenTelemetry
The magic of open source lies in the collaborative power of the community: by contributing to OpenTelemetry, you can directly impact and shape the future of observability. Whether you're refining code, enhancing documentation, or providing feedback, every contribution amplifies the project's reach and benefits developers around the world. In this section, we share some tips.

Contributing to OpenTelemetry is similar to most other open-source projects; you don't need to be a member to contribute. Whether it's sharing your thoughts on an issue, or opening a pull request, all contributions are welcome on the project.
As a component maintainer, the most valuable thing for someone to contribute is actually the easiest: feedback. Knowing what bugs users are facing, or learning about a feature gap that would improve the experience for multiple users is incredibly valuable. While we do use the ClickHouse exporter internally, our usage isn't the same as someone else's, and we have a lot to learn from the community.
Of course, we also have users who are familiar with both OpenTelemetry and ClickHouse and are able to make clever contributions to the exporter. An example of this we would like to highlight is a recent effort to sort map attributes before inserting them into ClickHouse. In the previous versions, log and trace attributes were simply inserted as they were received. This does not always lead to the best compression, as attributes may reflect the same data but be in a different order. By sorting map attributes by key, we are able to benefit from ClickHouse's excellent compression. This is an idea that was noted in external issues, but wasn't yet added. A user from the community found this and submitted a pull request with their implementation.
If you find yourself frequently interacting with an OpenTelemetry project, it may be a good idea to become a member of their organization. There's a full guide of the process on the community repository, but the overall idea is to show that you're already a member in practice. Membership applications are submitted by creating an issue on GitHub along with a list of your contributions (issues, pull requests, etc.). If existing members agree, your membership will be approved, and you can begin taking on larger roles within the organization. This isn't required to make a contribution, but it shows the other members and visitors that you're actively participating in the OTel ecosystem.



