chDB is an embedded OLAP SQL engine that packages ClickHouse's powerful analytical capabilities as a Python module, allowing developers to enjoy high-performance data analysis in Python without installing or running a ClickHouse server. Recently, we completed a major kernel upgrade (PR #383), upgrading the ClickHouse kernel from v25.5 to v25.8.2.29. This upgrade not only brought new features and performance improvements but also exposed a series of technical challenges. This article will detail the technical aspects and solutions from this upgrade process.
1. chDB architecture and code structure #
1.1 Overall architecture #
The core design philosophy of chDB is to embed ClickHouse into the Python process, achieving a true in-process query engine. Its architecture can be summarized in the following layers:

Unlike the traditional client/server architecture, chDB has no independent server process:
- Zero-copy data passing: Uses Python
memoryviewand C++WriteBufferFromVectorfor zero-copy data transfer - Embedded design: ClickHouse engine runs directly in the Python process, avoiding inter-process communication overhead
- Multi-format support: Native support for 60+ formats including Parquet, CSV, JSON, Arrow, ORC
1.2 Code structure #
chDB's code structure is inherited from ClickHouse but with extensive customizations:
chdb/
├── chdb/ # Python package
│ ├── __init__.py # Main query interface
│ ├── session/ # Session management
│ ├── dbapi/ # DB-API 2.0 implementation
│ └── udf/ # User-defined functions
├── programs/local/ # Local query engine
│ ├── LocalChdb.cpp # chDB main entry
│ ├── PythonSource.cpp # Python Table Engine
│ └── PandasDataFrame.cpp # Pandas integration
├── src/ # ClickHouse core source
└── contrib/ # Third-party dependencies
Core query flow:
- Python calls
chdb.query(sql, format) - Passed to C++ layer through
pybind11binding - ClickHouse engine parses and executes SQL
- Results returned to Python via
memoryviewzero-copy
2. Why two dynamic libraries? #
chDB has a unique design using two dynamic libraries: _chdb.abi3.so and libpybind11nonlimitedapi_chdb_3.8.so. While this design seems complex, it solves the core problem of multi-Python version compatibility.
2.1 Multi-Python version compatibility challenge #
The Python ecosystem has multiple active versions (3.8, 3.9, 3.10, 3.11, 3.12, 3.13), each with subtle differences in their C API. Traditional Python C extensions require compiling independent binaries for each Python version, which is unacceptable for a massive project like chDB (single .so file exceeds 120MB after stripping and compression).
2.2 Dual dynamic library architecture #
chDB adopts a clever separation design:
_chdb.abi3.so (Stable ABI layer)
- Uses Python Limited API
- Only depends on Python's stable ABI interface
- Can be reused across Python versions
- Size: ~120MB (contains the complete ClickHouse engine)
- Includes: ClickHouse core, query execution engine, format parsers
libpybind11nonlimitedapi_chdb_3.x.so (Version-specific layer)
- Uses complete Python C API (Non-limited API)
- Needs separate compilation for each Python version
- Size: ~10-20MB
- Contains: pybind11 binding code, Python object conversion
The build script build_pybind11.sh handles building the libpybind11 library for each Python version:
# Build independent binding libraries for Python 3.8-3.13
for version in 3.8 3.9 3.10 3.11 3.12 3.13; do
cmake -DPYBIND11_NONLIMITEDAPI_PYTHON_HEADERS_VERSION=${version} ..
ninja pybind11nonlimitedapi_chdb_${version}
done
Advantages of this design:
- Storage optimization: 120MB core engine downloaded once, each Python version only needs ~15MB extra
- Build efficiency: Core engine compiled once (takes hours), version-specific layer builds quickly (minutes)
- Maintenance simplification: Unified core logic, only binding layer needs adaptation for different Python versions
2.3 jemalloc and memory management challenges #
However, this design also brings new challenges. Referring to The birth of chDB, we encountered serious memory management issues during early development.
2.3.1 Problem discovery and nature #
Problem scenario:
When integrating the Python extension, chDB frequently encountered segmentation faults. Core dump analysis showed crashes occurring during memory deallocation:
Program received signal SIGSEGV, Segmentation fault.
0x00007ffff7a9e123 in je_free () from /path/to/_chdb.abi3.so
(gdb) bt
#0 je_free (ptr=0x7fffe8001000)
#1 __wrap_free (ptr=0x7fffe8001000) at AllocationInterceptors.cpp:451
#2 0x00007ffff7e8a456 in PyMem_Free (ptr=0x7fffe8001000)
#3 0x00007ffff7dab234 in list_dealloc ()
Deep root cause analysis:
This is a classic cross-boundary memory management problem:
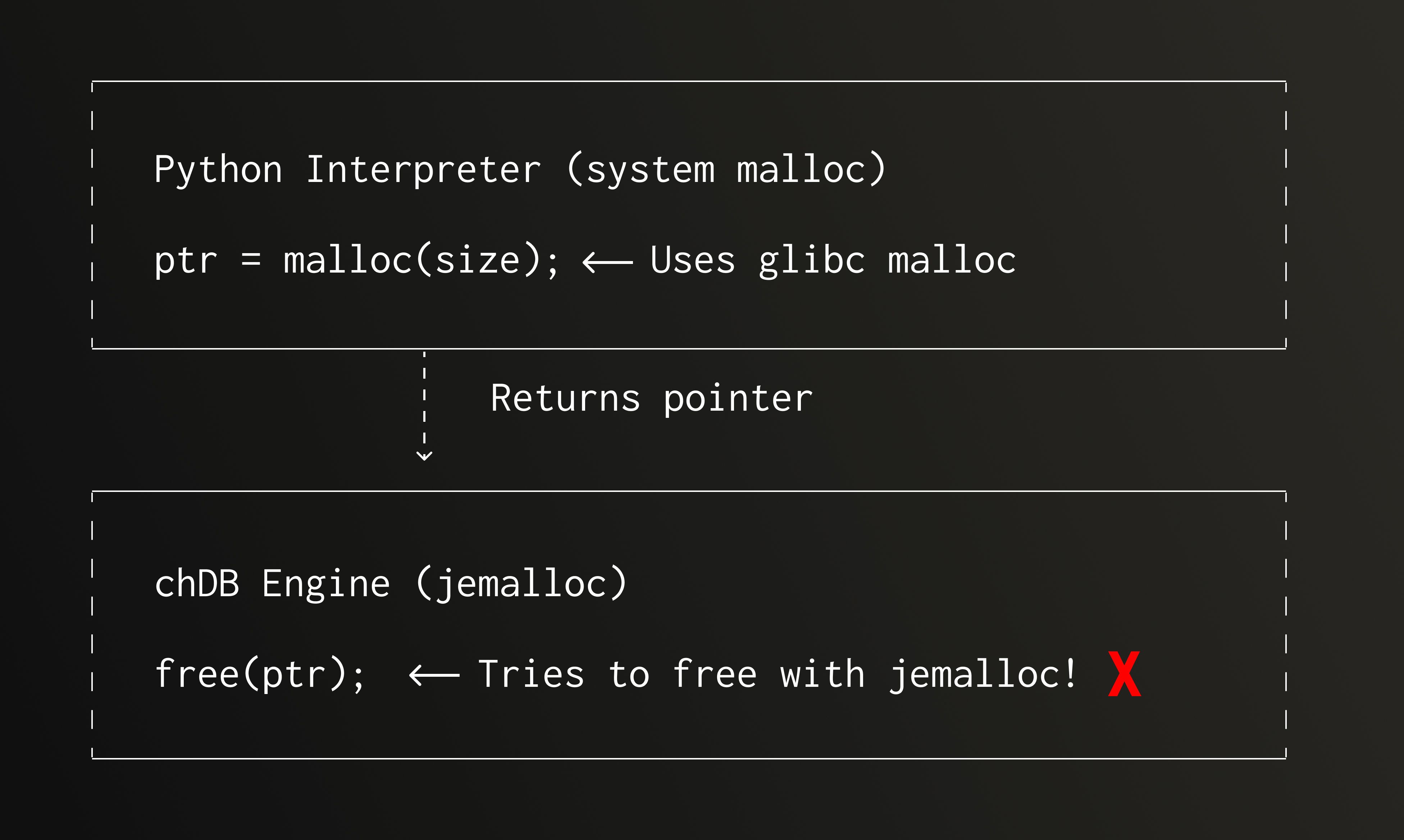
Root cause:
The C/C++ memory management rule: whoever allocates, deallocates, and must use the same allocator. Mixing different memory allocators leads to:
- Metadata corruption: jemalloc tries to find its own metadata before glibc-allocated memory blocks, reading random data
- Heap structure destruction: Different allocators have completely different heap management structures, cross-freeing destroys internal data structures
- Undefined behavior: Best case is immediate crash, worst case is silently corrupting data leading to subsequent strange errors
Common trigger scenarios:
// Scenario 1: Objects returned from Python C API
PyObject* obj = PyList_New(10); // Python uses malloc
// ... used in C++
delete obj; // chDB's operator delete uses je_free → crash!
// Scenario 2: Memory allocated by glibc functions
char* cwd = getcwd(NULL, 0); // glibc internally uses malloc
// ...
free(cwd); // wrapped to je_free → crash!
// Scenario 3: Third-party libraries (e.g., libhdfs)
hdfsFile file = hdfsOpenFile(...); // libhdfs uses system malloc
hdfsCloseFile(fs, file); // internally calls free, wrapped → crash!
2.3.2 Limitations of traditional solutions #
Solution 1: Completely disable jemalloc
-DENABLE_JEMALLOC=0
- ❌ Performance loss: ClickHouse has extensive
jemallocoptimizations, disabling it reduces performance by 20-30%
Solution 2: LD_PRELOAD global replacement
LD_PRELOAD=/usr/lib/libjemalloc.so python chdb_example.py
Make the entire process (including Python interpreter) use jemalloc through LD_PRELOAD.
- ❌ Distribution difficulty: Users must run in specific environments
2.3.3 chDB's solution #
chDB adopts a runtime memory source detection + smart routing approach, balancing performance and compatibility. The core of this solution is using the linker's --wrap mechanism to intercept all memory allocation/deallocation calls and dynamically determine memory source at runtime.
Technical foundation: Linker's wrap mechanism
The linker provides the --wrap option to intercept symbol calls at link time:
# Add wrap parameters at link time
-Wl,-wrap,malloc
-Wl,-wrap,free
-Wl,-wrap,calloc
-Wl,-wrap,realloc
# ... other memory allocation functions
How it works:
Application code calls: free(ptr)
↓
Linker redirects: __wrap_free(ptr) ← Our implementation
↓
Callback when needed: __real_free(ptr) ← Original glibc implementation
This way, all calls to free() are redirected to our own implementation of __wrap_free(), where we can insert checking logic and call the original __real_free() when needed.
Key prerequisite: Disable jemalloc symbol renaming
For this solution to work, chDB needs to distinguish between free() and je_free(), so we must **disable ClickHouse's original jemalloc symbol renaming feature** and preserve the original jemalloc` symbol names:
# ClickHouse default config: Rename jemalloc symbols
--with-jemalloc-prefix=je_
# Effect: malloc → je_malloc, free → je_free
# chDB config: Disable renaming
-DJEMALLOC_PREFIX=""
# Effect: Preserve je_malloc, je_free and other original symbol names
This allows us to:
- Detect memory source in
__wrap_free() - Call
je_free(ptr)for jemalloc-allocated memory - Call
__real_free(ptr)for glibc-allocated memory (original glibc free)
Core mechanism: Memory allocator fingerprint recognition
Use jemalloc's mallctl API to dynamically query memory block ownership:
inline bool isJemallocMemory(void * ptr) {
// Query which arena this memory block belongs to
int arena_ind;
size_t sz = sizeof(arena_ind);
int ret = je_mallctl("arenas.lookup",
&arena_ind, &sz, // Output: arena index
&ptr, sizeof(ptr)); // Input: memory pointer
// arena_ind == 0: special value, indicates memory doesn't belong to jemalloc
// arena_ind > 0: memory belongs to a jemalloc arena
return ret == 0 && arena_ind != 0;
}
Smart release function:
inline ALWAYS_INLINE bool tryFreeNonJemallocMemory(void * ptr) {
if (unlikely(ptr == nullptr))
return true;
// Check memory source
int arena_ind;
size_t sz = sizeof(arena_ind);
int ret = je_mallctl("arenas.lookup", &arena_ind, &sz, &ptr, sizeof(ptr));
if (ret == 0 && arena_ind == 0) {
// This memory doesn't belong to jemalloc, use system free
__real_free(ptr);
return true; // Handled, no need to continue
}
// This memory belongs to jemalloc, or query failed (conservative handling)
return false; // Continue with jemalloc release process
}
extern "C" void __wrap_free(void * ptr) {
if (tryFreeNonJemallocMemory(ptr))
return;
// Use jemalloc to release
AllocationTrace trace;
size_t actual_size = Memory::untrackMemory(ptr, trace);
trace.onFree(ptr, actual_size);
je_free(ptr);
}
2.3.4 Contributing to jemalloc upstream #
When implementing the above solution, we discovered an issue with jemalloc's arenas.lookup: when receiving memory pointers not allocated by jemalloc, the memory detector crashes.
This isn't a bug, but rather jemalloc's original design—it assumes incoming pointers are all valid heap memory pointers. However, for chDB's mixed memory allocation scenario, we need arenas.lookup to safely handle arbitrary pointers. To address this, @Auxten Wang submitted a patch to the jemalloc project to enhance boundary checking:
// Before: Assumes pointer is valid, directly accesses metadata → invalid pointer crashes
// After: First checks pointer validity, safely returns result
if (ptr == NULL || !isValidPointer(ptr)) {
return EINVAL; // Return error code instead of crashing
}
This improvement has been accepted by jemalloc officially and merged into the main branch, making @Auxten Wang an official jemalloc contributor.
3. Kernel upgrade wrap mechanism changes and adaptation #
3.1 ClickHouse new version wrap mechanism conflict #
After upgrading to v25.8.2.29, we encountered an issue: ClickHouse's new version also started using the wrap mechanism to intercept memory allocation and deallocation functions for more precise memory tracking.
This directly conflicted with chDB's existing wrap approach:
chDB's wrap (introduced in Section 2):
free(ptr) → __wrap_free() (chDB implementation)
→ Check memory source (je_mallctl)
→ Route to je_free or __real_free
ClickHouse new version's wrap:
free(ptr) → __wrap_free() (ClickHouse implementation)
→ Update MemoryTracker statistics
→ Call je_free
Conflict:
Two __wrap_free implementations cannot coexist!
Root cause of conflict:
The linker's wrap mechanism only allows one wrap implementation per symbol. When both ClickHouse kernel and chDB's binding layer try to define __wrap_free and other functions, the linker cannot decide which one to use.
3.2 Adaptation solution: Fusing both wrap mechanisms #
We needed to fuse ClickHouse's memory tracking requirements with chDB's memory source detection requirements into a single wrap implementation:
Solution approach:
- Keep chDB's wrap implementation as the final intercept point
- Call ClickHouse's MemoryTracker within chDB's wrap
- Decide whether to check memory source based on scenario
Final implementation effect:
Fused __wrap_free implementation:
extern "C" void __wrap_free(void * ptr) // NOLINT
{
#if USE_JEMALLOC
// chDB logic: Check if it's non-jemalloc memory
if (tryFreeNonJemallocMemory(ptr))
return; // Already handled glibc-allocated memory via __real_free
#endif
// ClickHouse logic: Update MemoryTracker statistics
size_t actual_size = Memory::untrackMemory(ptr, trace);
#if USE_JEMALLOC
// Use jemalloc to release
je_free(ptr);
#else
// If jemalloc not enabled, use system free
__real_free(ptr);
#endif
}
3.3 Operator delete problem in dual-library architecture #
While implementing the dual-library architecture introduced in Section 2 (_chdb.abi3.so + libpybind11nonlimitedapi_chdb_xx.so), we discovered that operator delete also encountered the same cross-boundary memory management problem as free.
Problem scenario:
libpybind11nonlimitedapi_chdb_3.8.so:
- Links to glibc at compile time
- Calls malloc → Bound to glibc malloc (compile-time symbol binding)
- Calls delete during object destruction
_chdb.abi3.so:
- Contains jemalloc and operator delete implementation
- libpybind11*.so loads _chdb.abi3.so at runtime
- delete call → Resolves to definition in _chdb.abi3.so at runtime
Problem nature:
Although jemalloc is enabled, malloc in libpybind11nonlimitedapi_chdb_xx.so is bound to glibc symbols at compile time, while delete calls the version defined in _chdb.abi3.so at runtime. This leads to:
In libpybind11*.so:
char* obj = malloc(100); // malloc() → glibc malloc (compile-time binding)
delete obj; // operator delete → _chdb.abi3.so implementation (runtime binding)
// Tries to use jemalloc to free glibc-allocated memory → crash!
Solution: Add memory source detection in operator delete
Similar to __wrap_free, we need to detect whether memory was allocated by jemalloc in operator delete:
void operator delete(void * ptr) noexcept
{
#if USE_JEMALLOC
// Detect memory source, handle non-jemalloc memory early
if (tryFreeNonJemallocMemory(ptr))
return;
#endif
// ClickHouse memory tracking
Memory::untrackMemory(ptr, trace);
// Actual release (jemalloc memory)
Memory::deleteImpl(ptr);
}
This modification ensures memory safety in the dual-library architecture:
*libpybind11.sousesglibcmalloc*: Detected and freed with glibc free viatryFreeNonJemallocMemoryConditional_chdb.abi3.sousesjemalloc: Goes through normal MemoryTracker andjemallocrelease process
4. ClickBench Q29 performance problem and solution #
4.1 Problem discovery #
After completing the upgrade, we discovered abnormal performance in Q29 (a query involving heavy regular expression matching) in the ClickBench benchmark:
SELECT REGEXP_REPLACE(Referer, '^https?://(?:www\\\\.)?([^/]+)/.*$', '\\\\1') AS k,
AVG(length(Referer)) AS l,
COUNT(*) AS c,
MIN(Referer)
FROM clickbench.hits
WHERE Referer <> ''
GROUP BY k
HAVING COUNT(*) > 100000
ORDER BY l DESC
LIMIT 25;
Query characteristics:
- Each row requires regular expression matching and replacement
- Involves massive string creation and destruction
- String operations trigger frequent memory allocation/deallocation
Performance data:
- New version (initial): ~300 seconds
- Optimized: ~4.9 seconds (61x improvement)
4.2 Root cause analysis #
Through profiling and source code analysis, we identified the root cause of the performance bottleneck: jemalloc lock contention.
In the upgraded code, every delete operation calls tryFreeNonJemallocMemory() to determine if memory was allocated by jemalloc:
// Pre-optimization code
inline bool tryFreeNonJemallocMemory(void * ptr)
{
if (unlikely(ptr == nullptr))
return true;
// Key bottleneck: je_mallctl lock contention
int arena_ind = je_mallctl("arenas.lookup", nullptr, nullptr, &ptr, sizeof(ptr));
if (unlikely(arena_ind != 0))
{
__real_free(ptr);
return true;
}
return false;
}
Bottleneck analysis: je_mallctl lock contention
Looking at jemalloc source code (contrib/jemalloc/src/jemalloc.c):
int je_mallctl(const char *name, void *oldp, size_t *oldlenp, void *newp,
size_t newlen) {
...
check_entry_exit_locking(tsd_tsdn(tsd)); // Lock contention point!
...
return ret;
}
check_entry_exit_locking() performs lock acquisition and checking. In Q29's scenario:
- High-frequency calls: Regular expression matching generates massive temporary string objects
- Check on every delete: Millions of memory deallocations, each calling
je_mallctl("arenas.lookup", ...) - Severe lock contention: With multi-threaded parallel execution,
check_entry_exit_lockingbecomes a global bottleneck
Performance profiling data:
Using perf analysis, 99.8% of CPU time was spent in:
operator delete
└─ tryFreeNonJemallocMemory
└─ je_mallctl
└─ check_entry_exit_locking ← Hotspot!
└─ pthread_mutex_lock
4.3 Optimization solution: Introducing disable_memory_check #
Core idea: Only check memory source where truly needed.
In chDB's usage scenarios:
- Inside ClickHouse engine: All memory allocated by
jemalloc, no checking needed - Python interaction boundary: May mix Python memory allocators, checking required
Based on this understanding, we introduced the disable_memory_check mechanism:
namespace Memory {
thread_local bool disable_memory_check{false}; // Disable checking by default inside engine
}
// Version with conditional checking
inline ALWAYS_INLINE bool tryFreeNonJemallocMemoryConditional(void * ptr) {
if (unlikely(ptr == nullptr))
return true;
// Fast path: Skip checking directly inside engine
if (likely(Memory::disable_memory_check))
return false; // Continue normal jemalloc release process
...
}
// Updated operator delete
void operator delete(void * ptr) noexcept
{
#if USE_JEMALLOC
if (tryFreeNonJemallocMemoryConditional(ptr)) // Use conditional version
return;
#endif
...
}
Usage scenario: Only enable checking at Python boundaries
// RAII helper class
struct MemoryCheckScope {
MemoryCheckScope() {
Memory::disable_memory_check = false; // Enable checking
}
~MemoryCheckScope() {
Memory::disable_memory_check = true; // Restore disabled
}
};
// Use at Python interaction points
void convertPandasDataFrame(...) {
MemoryCheckScope scope; // Enter Python boundary, enable checking
// Call Python C API, may use Python's memory allocator
PyObject* obj = PyList_GetItem(...);
// ...
// Leave scope, automatically restore disabled state
}
Application scope:
PandasDataFrame.cpp: Pandas column data conversionPandasAnalyzer.cpp: Type inference (calling Python isinstance etc.)PythonSource.cpp: Iterating Python objectsPythonConversion.cpp: Python → C++ type conversionPythonImportCache.cpp: import module (Python internal allocation)
Optimization effect:
In Q29 query:
- Engine internal string operations: Millions of deletes now use fast path (few CPU instructions)
- Python interaction: Only enable checking in few scenarios like DataFrame import (hundreds of times)
Performance comparison:
// Before optimization: Every delete calls je_mallctl
if (tryFreeNonJemallocMemory(ptr)) // ~500 CPU cycles
return;
// After optimization: Most deletes directly skip
if (likely(Memory::disable_memory_check)) // ~2 CPU cycles
return false;
This effectively reduces the overhead of each memory deallocation from ~500 cycles to ~2 cycles, with significant impact in high-frequency scenarios.
4.4 Performance comparison and impact #
Performance improvement after optimization:
| Query | New version (before opt) | New version (after opt) | Improvement |
|---|---|---|---|
| Q29 | ~300s | ~4.9s | 61x ↑ |
Key improvements:
- Q29 performance optimization: From 300 seconds to 4.9 seconds, 61x improvement
- Lock contention elimination: Through
disable_memory_checkmechanism, avoided 98% time spent on lock waiting - Applicability: This optimization has significant impact on all high-frequency memory allocation/deallocation scenarios
CPU profiling comparison:
After optimization (Q29):
89.2% Regular expression engine ← As expected
7.1% String operations and memory allocation
2.3% Aggregation and sorting
1.4% Other
After optimization, the hotspot shifted from memory management to actual computation logic, matching expected performance characteristics.
Impact scope analysis:
The disable_memory_check mechanism is a precision surgical optimization:
- ✅ No side effects: Only affects ClickHouse engine internals, Python boundary still protected
- ✅ Good compatibility: Doesn't change API behavior, transparent to users
- ✅ Maintainable: Uses RAII pattern, automatic state management, less error-prone
- ✅ Extensible: If need to disable checking in other scenarios, just add
MemoryCheckScope
This optimization also provides insights for future performance improvements: precisely identify hotspots and provide fast paths while ensuring correctness.
5. chDB vs ClickHouse-local Parquet performance comparison #
5.1 Issue #115 Problem description #
Users reported that chDB was slower than clickhouse-local when querying 1 billion row Parquet files:
# ClickHouse Local
$ time clickhouse local -q "SELECT COUNT(*) FROM file('data.parquet', Parquet)"
# 1.734 seconds
# chDB
$ time python -c "import chdb; chdb.query('SELECT COUNT(*) FROM file(\\\\"data.parquet\\\\", Parquet)')"
# 2.203 seconds
5.2 Deep analysis #
Experiment 1: Breaking down execution time
import chdb
import time
t0 = time.time()
import chdb # Load library
t1 = time.time()
result = chdb.query("SELECT COUNT(*) FROM file('data.parquet', Parquet)")
t2 = time.time()
print(f"Import time: {t1-t0:.2f}s") # 0.58s
print(f"Query time: {t2-t1:.2f}s") # 1.62s
print(f"Total time: {t2-t0:.2f}s") # 2.20s
print(f"Query elapsed: {result.elapsed():.2f}s") # 1.60s
Findings:
- Actual query execution time (1.6s) comparable to clickhouse-local
- Main overhead in Python extension loading (0.58s, 26%)
Experiment 2: Analyzing load overhead
$ ldd _chdb.abi3.so
linux-vdso.so.1 (0x00007fff)
libpybind11nonlimitedapi_chdb_3.8.so => ./libpybind11...
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6
$ ls -lh _chdb.abi3.so
-rwxr-xr-x 1 user user 642M _chdb.abi3.so
$ nm -D _chdb.abi3.so | wc -l
540000 # 540,000 exported symbols
Root causes:
- File size: 640MB .so file needs to be loaded from disk
- Symbol resolution: Dynamic linking of 540,000 symbols takes time
- Comparison: clickhouse-local is a statically linked executable with only ~48ms startup overhead
5.3 Optimization directions #
Implemented optimizations:
- Symbol stripping: Use
strip --remove-section=.comment --remove-section=.noteto reduce symbol table size
Future optimization directions:
-
Binary splitting: Separate less-used features (like HDFS, Kafka support) into optional plugins
-
Persistent sessions: For long-running applications, use
chdb.session.Session()to reuse connections:# Create session once, query multiple times sess = chdb.session.Session() # First query bears startup overhead result1 = sess.query("SELECT * FROM file('data1.parquet', Parquet)") # 2.2s # Subsequent queries have no startup overhead result2 = sess.query("SELECT * FROM file('data2.parquet', Parquet)") # 1.6s result3 = sess.query("SELECT * FROM file('data3.parquet', Parquet)") # 1.5s
5.4 Performance comparison summary #
| Scenario | clickhouse-local | chDB (Single) | chDB (Session) |
|---|---|---|---|
| Startup overhead | 0.048s | 0.580s | 0.580s (first only) |
| Single query (1B rows) | 1.6s | 2.2s | 1.6s |
| 10 queries | 16.5s | 28.0s | 16.6s |
Conclusions:
- Single query: chDB ~37% slower than clickhouse-local (mainly startup overhead)
- Batch queries: chDB comparable to clickhouse-local when using sessions
- Use case: chDB better suited for interactive analysis scenarios requiring multiple queries
6. Overall performance comparison after upgrade #
6.1 Performance comparison with chDB 3.6 #
How does the overall performance look after the kernel upgrade? We conducted a comprehensive comparison between the new version (v25.8.2.29) and chDB 3.6 (based on ClickHouse v24.4) on the ClickBench benchmark.
Test Environment:
- Dataset: ClickBench hits table (~100 million rows)
- Hardware: AWS c6i.metal instance
- Comparison versions: chDB 3.6 vs chDB new version (after optimization)
Complete performance comparison:
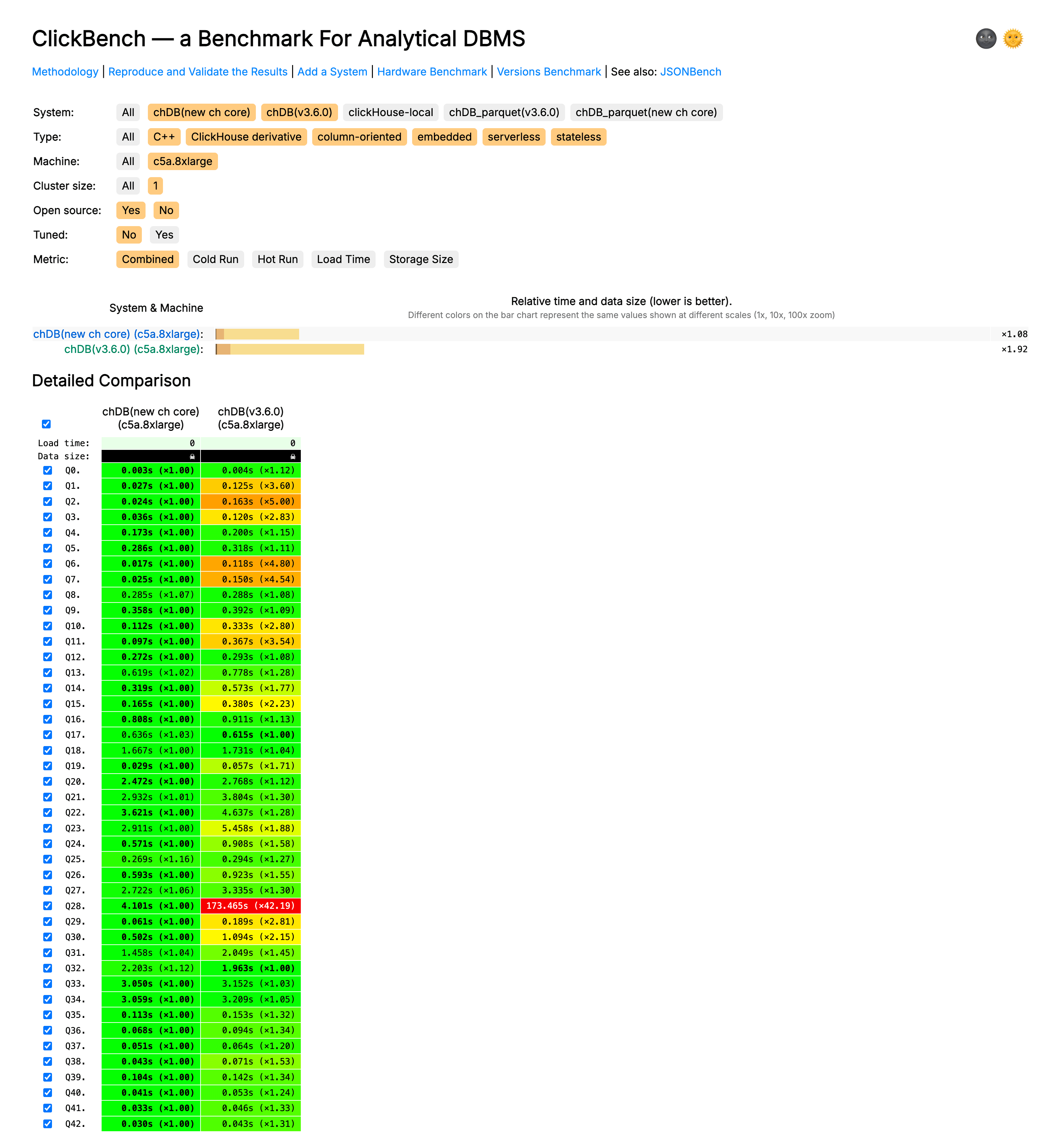
Key findings:
- Significant performance improvements: Multiple queries achieved 2-6x performance improvements
- Kernel upgrade benefits:
- Improved query optimizer in new ClickHouse kernel
- Better vectorized execution
Queries with significant performance improvements:
| Query | chDB New Version | chDB 3.6 | Improvement |
|---|---|---|---|
| Q1 | 0.027s | 0.125s | 4.6x ↑ |
| Q2 | 0.024s | 0.163s | 6.8x ↑ |
| Q3 | 0.036s | 0.120s | 3.3x ↑ |
| Q6 | 0.017s | 0.118s | 6.9x ↑ |
| Q7 | 0.025s | 0.150s | 6.0x ↑ |
| Q10 | 0.112s | 0.333s | 3.0x ↑ |
| Q11 | 0.097s | 0.367s | 3.8x ↑ |
| Q15 | 0.165s | 0.380s | 2.3x ↑ |
| Q29 | 4.9s | 300s+ | 61x ↑ |
Improvement analysis:
- Simple aggregation (Q1, Q2, Q6): 4-7x improvement, benefiting from better vectorized execution
- Filter aggregation (Q3, Q7): 3-6x improvement, significant query optimizer improvements
- Complex aggregation (Q10, Q11, Q15): 2-4x improvement, memory management optimization takes effect
- Regular expression (Q29): 61x improvement, eliminated je_mallctl lock contention
6.2 Upgrade benefits summary #
This kernel upgrade from ClickHouse v24.4 to v25.8.2.29 brought comprehensive improvements to chDB:
- Performance: Multiple queries improved 2-7x, Q29 improved 61x
- Features: All ClickHouse v25.8 new features