"Originally, we did not anticipate that ClickHouse itself would be so powerful, and ClickHouse Keeper's performance is equally impressive!"
"Migrating from ZooKeeper to ClickHouse Keeper achieved more than 75% reduction in CPU and memory usage."
"After switching to ClickHouse Keeper, performance improved nearly 8 times."
Background
Bonree ONE is an integrated intelligent observability platform offered by Bonree Data Technology.
After migrating all Bonree ONE observability data to ClickHouse clusters, the performance and stability requirements for ZooKeeper increased with growing data volumes.
ZooKeeper is the shared information repository and consensus system for coordinating and synchronizing distributed operations in ClickHouse. We encountered some pain points in using ZooKeeper that would affect business operations if not addressed promptly.
Ultimately, we decided to replace ZooKeeper with ClickHouse Keeper to solve issues related to write performance, maintenance costs, and cluster management. ClickHouse Keeper is a fast, more resource-efficient, and feature-rich drop-in replacement for ZooKeeper, implemented in C++.
For a smooth migration, we had to find approaches for:
- Automated migration
- Authentication
- Data migration
- Data verification
This post describes these approaches in detail.
ZooKeeper became a bottleneck
As the data volumes and types of data continuously expanded, the pressure on ZooKeeper from the ClickHouse cluster increased. For instance, in scenarios requiring high real-time performance for alarm data storage and queries, the following issues were encountered with ZooKeeper:
-
Limited capacity: In our cloud deployment, with Keeper configured with 4C8G (4 CPU cores and 8 GB RAM per node) resources, a single ZooKeeper cluster (3 nodes) could support up to 5 shards (16 CPU cores and 32 GB RAM per shard node, 2 replicas per shard), with approximately 20,000 parts per shard, totaling around 100,000 parts. As data volumes and the number of tables increased, the cluster size rapidly expanded. Therefore, every time the cluster was expanded by 5 shards, we had to add another ZooKeeper cluster, leading to significant maintenance costs.
-
Performance bottleneck: Initially, with ClickHouse storing 1TB of data and a total of fewer than 12,000 parts, data could be inserted successfully within milliseconds. However, as the data volume increased and the number of parts reached 20,000, the response time for data insertion became significantly slower, taking tens of seconds to insert successfully. This resulted in issues where data could not be queried timely, affecting user experience.
-
High resource usage: ZooKeeper consumed a lot of memory and I/O resources, and costs increased with data volume growth.
In a comparative test within the same observability data environment, ZooKeeper's memory consumption was 4.5 times higher, and I/O usage was 8 times higher than ClickHouse Keeper's.
- Stability issues: Developed in Java, ZooKeeper could experience frequent full GC cycles, leading to service interruptions and performance fluctuations in ClickHouse. Additionally, issues like
zxid overflowoccurred. When ClickHouse executed parts synchronization among replicas in the background, it had to register with ZooKeeper first. Poor ZooKeeper performance could lead to increased background threads, resulting in data synchronization delays among replicas. In our cloud platform, using ZooKeeper for metadata storage resulted in a delay queue of over 10,000 parts, seriously affecting the accuracy of business queries.
Based on the above pain points and the characteristics of write-intensive data analysis scenarios, we chose ClickHouse Keeper, which performed better as a ZooKeeper replacement. Key considerations included:
-
Compatibility: ClickHouse Keeper is compatible with ZooKeeper client protocols. Any standard ZooKeeper client can interact with ClickHouse Keeper, supporting the use of ClickHouse client commands. This means no server-side modifications are needed to connect to ClickHouse Keeper.
-
Historical data migration: We could use the clickHouse-keeper-converter tool to convert historical data from ZooKeeper and import the converted snapshot files into the ClickHouse Keeper cluster. The conversion efficiency was controlled by choosing five-minute blocks for millions of paths, reducing the overall cluster stop-write time and minimizing the impact on online products.
-
Service stability: Written in C++, ClickHouse-Keeper enhances overall service stability by fundamentally solving the Full GC issue caused by ZooKeeper and improving service performance through server parameter adjustments.
-
Resource and performance: Compressed storage of metadata reduces resource usage. It also uses CPU, memory, and disk I/O more efficiently. By using resources more efficiently, ClickHouse Keeper's performance is superior.
Solution evolution
Original solution based on ZooKeeper
As our observability platform business expanded, the platform’s data was divided into critical and general categories. Prioritized performance and query requirements for critical data required physical resource isolation. Logical resource isolation for a large cluster was cumbersome because onboarding new category data required reallocation and resource adjustment. Physically isolating different resources was more efficient, allowing operations to focus only on resource support for one specific area.
Initially, we used multiple ClickHouse Clusters coordinated through ZooKeeper to handle the complexity and different SLAs of diverse data categories. However, as ClickHouse expanded, the pressure on ZooKeeper also increased, leading to delays and task accumulation. To resolve this, we used the official ClickHouse multi-ZooKeeper architecture: parts metadata for each group of 5 shards is stored in a dedicated ZooKeeper cluster (consisting of 3 nodes each) per group; table metadata is stored centrally in another ZooKeeper cluster (consisting of 3 nodes) for all groups:
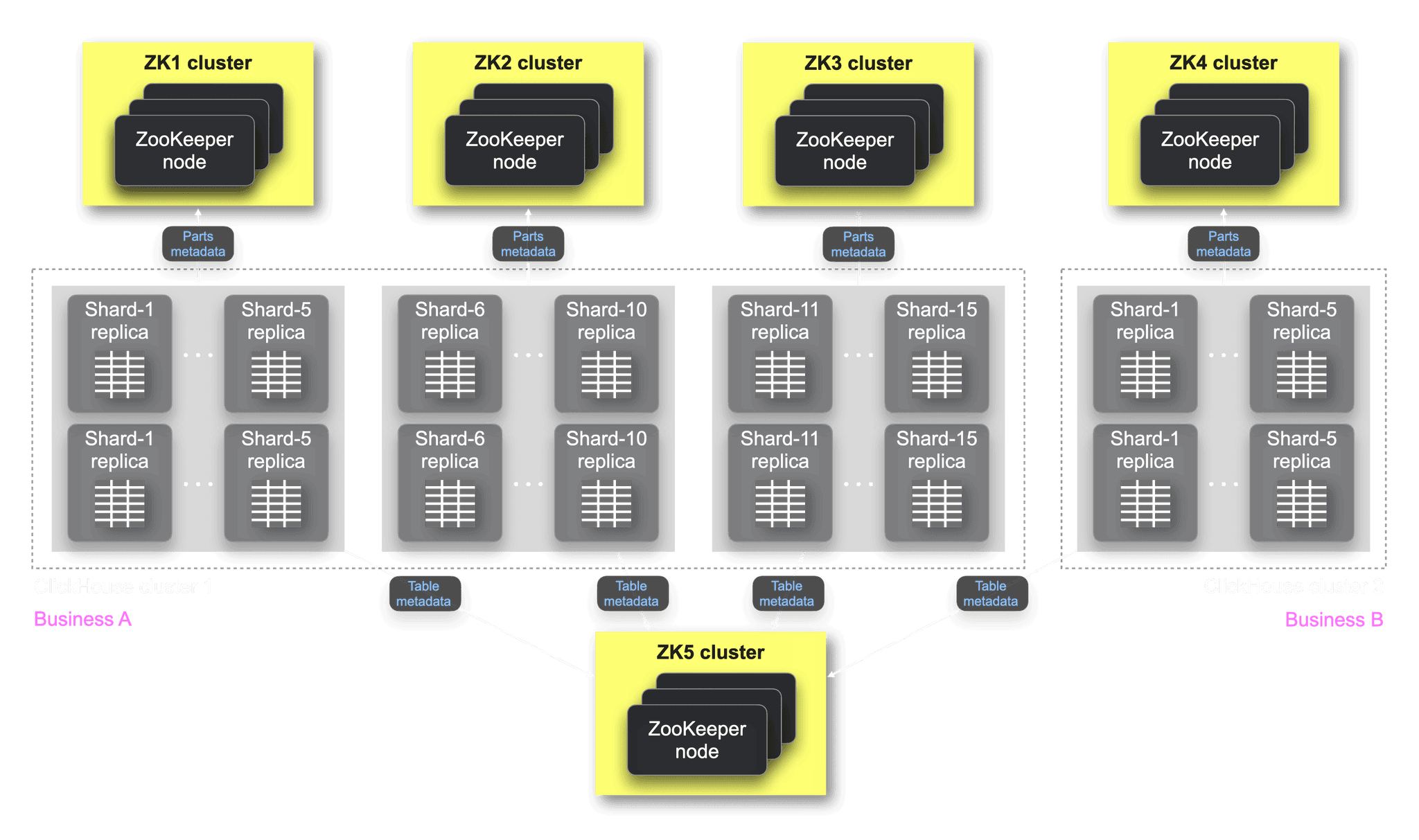
The figure above illustrates that business A and business B require physical isolation, with ClickHouse cluster 1 (15 shards, 2 replicas per shard) for A and ClickHouse cluster 2 (5 shards, 2 replicas per shard) for B. Queries map to ClickHouse instances on different physical resources based on cluster names, ensuring resource isolation. The part metadata of each group of 5 shards in ClickHouse cluster 1 is managed by a dedicated ZooKeeper cluster (ZK1, ZK2, ZK3), while ZK4 manages ClickHouse cluster 2's 5 shards part metadata. All table metadata for ClickHouse cluster 1 and ClickHouse cluster 2 is stored in a shared ZooKeeper (ZK5) cluster for stability. Maintaining five ZooKeeper clusters (5 times 3 nodes = 15 nodes) was cumbersome, and performance and stability degraded over time.
New solution based on ClickHouse Keeper
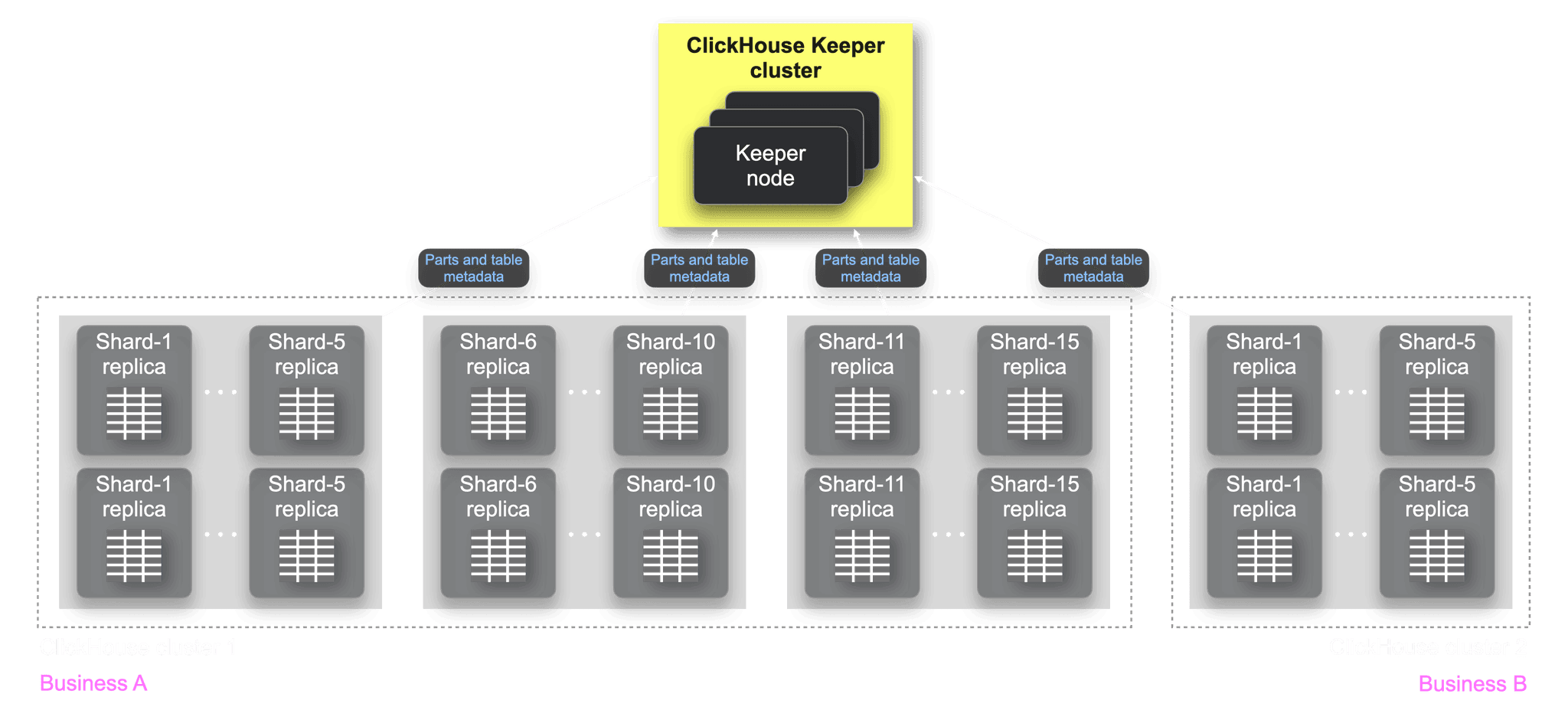
Testing verified that using ClickHouse Keeper improved data insertion speed, ClickHouse cluster stability, and replica synchronization speed. Due to ClickHouse Keeper's excellent performance, we no longer needed multiple ZooKeeper node sets, opting to maintain just one ClickHouse Keeper node set for supporting over 15 shards, simplifying the original solution significantly:
Migration process
Pre-migration preparations
ClickHouse continuously updates data in ZooKeeper. Even without data ingestion, background tasks (e.g., background part merges) still alter data in ZooKeeper, making it hard to ensure data consistency before and after the migration. We thoroughly studied ClickHouse's background tasks causing data modifications in ZooKeeper and stopped these tasks using commands (e.g. SYSTEM STOP MERGES). This ensured data consistency between ZooKeeper and ClickHouse Keeper before and after the migration, facilitating data comparison and validation. An automated migration process ensured the change was completed within 30 minutes without severely impacting the business.
Automated migration
The migration process involved running multiple commands across machines and evaluating results, with human error risks and increased migration time. To address this, we developed an automated migration tool based on Ansible, an IT automation tool used for configuration management, software deployment, and advanced task orchestration like seamless rolling updates. The migration steps were:
- Stop data ingestion.
- Stop ClickHouse's merge and other background tasks.
- Record comparison metrics.
- Restart each ZooKeeper cluster to obtain the latest snapshot files.
- Copy and convert snapshot files from ZooKeeper to ClickHouse Keeper.
- Load snapshot files into ClickHouse Keeper and sample compare ZooKeeper and ClickHouse-Keeper node contents.
- Switch ClickHouse metadata storage from ZooKeeper to ClickHouse Keeper.
- Compare metrics with step 3.
- Start ClickHouse's merge and background tasks and data ingestion.
Automating the migration avoided operational errors, significantly reducing the migration time from 2-3 hours manually to a few minutes, minimizing the impact on business queries during the migration. The core automated process included:
// Stop ClickHouse schema creation and table operations
stopClickHouseManagers()// Stop ClickHouse data write operations
stopClickHouseConsumers()// Stop ClickHouse merge and other background tasks
ClickHouseStopMerges()// Obtain the latest snapshot information from ZooKeeper clusters
getNewZookeeperSnap()// Convert ZooKeeper snapshots to ClickHouse-Keeper snapshots
createAndExecConvertShell(housekeeperClusterName)// Start ClickHouse clusters
startClickHouses()// Compare data before and after the migration
checkClickHouseSelectData()Challenges
The migration process described above is quite basic. Still, the environment was more complex, involving multiple clusters, various ZooKeeper node sets, and issues such as multi-ZooKeeper to single ClickHouse-Keeper transitions (the community version only supports one-to-one), encryption and authentication problems, and data verification efficiency challenges.
Migrating multiple ZooKeeper clusters to a single ClickHouse Keeper cluster
ClickHouse Keeper significantly outperformed ZooKeeper in performance tests, and required much fewer resources. Therefore, multiple ZooKeeper clusters had to be reduced to a single cluster to avoid resource waste. The official clickHouse-keeper-converter tool supports only a one-to-one ZooKeeper to ClickHouse Keeper conversion. We solved this by:
- Sampling some ZooKeeper nodes before migration, saving this information for comparison after migration, ensuring data consistency before and after the migration.
- Modifying the
clickHouse-keeper-convertersource code to support merging snapshots from multiple ZooKeeper node sets into one ClickHouse Keeper node set. For example:
// Deserialize all snapshot files in a loop
for (const auto &item : existing_snapshots) {
deserializeKeeperStorageFromSnapshot(storage item.second log);
}// Modify numChildren property acquisition method to avoid using incremental IDs
storage.container.updateValue(parent_path [path = itr.key] (KeeperStorage::Node &value) {
value.addChild(getBaseName(path));
value.stat.numChildren = static_cast<int32_t>(value.getChildren().size());
});// File output stream when creating the conversion snapshot file, for quick reading by the subsequent diff tool
int flags = (O_APPEND | O_CREAT | O_WRONLY);
std::unique_ptr<WriteBufferFromFile> out = std::make_unique<WriteBufferFromFile>("pathLog", DBMS_DEFAULT_BUFFER_SIZE, flags);Encrypted authentication
Bonree has many private B2B (business-to-business) customers, some of whom historically required encrypted authentication for ZooKeeper content while others did not, resulting in varying situations. All scenarios had to be considered to ensure a smooth migration. ZooKeeper can perform ACL (Access Control List) encryption. Here’s how to handle the conversion of already encrypted ZooKeeper clusters, partially encrypted ZooKeeper clusters, and non-encrypted ZooKeeper clusters based on different strategies:
-
Fully encrypted or fully unencrypted: If everything is encrypted and the encryption information is consistent, meaning that each node in the ZooKeeper cluster uses the same ACL strategy and the content of the strategy is the same, and ClickHouse Keeper's ACL is compatible with ZooKeeper's ACL, we can retain the original encryption information and directly perform the conversion. The ClickHouse configuration file does not need modification. If there is no encryption at all, i.e., ClickHouse has not configured ACL information when using ZooKeeper, this scenario can also be directly converted, and the ClickHouse configuration file does not need modification either.
-
Partially encrypted or inconsistent encryption information: In this case, we need to remove the original encryption information and modify the ClickHouse configuration file to ensure the encryption method is consistent. The steps to remove ZooKeeper encryption are as follows:
-
Add a super administrator account. When starting the ZooKeeper cluster, add the following in the JAVA startup command:
Dzookeeper.DigestAuthenticationProvider.superDigest=zookeeper:{XXXXXX} -
Restart the ZooKeeper cluster.
-
Use the ZooKeeper client to enter the cluster:
zkCli.sh -server ${zookeeper_cluster_address, format as ip1:port,ip2:port} -
Log in with the super administrator account:
addauth digest zookeeper:#{XXXXXX} -
Execute the command to remove node authentication (the more nodes under the target path, the longer it will take):
setAcl -R ${zookeeper_znode_path} world:anyone:cdrwa -
Remove the super administrator account added in step (1) and restart the ZooKeeper cluster.
-
After the migration, decide whether you need to enable encryption again in ClickHouse-Keeper.
-
Verification process
We faced three significant challenges for the verification process that had to be addressed to ensure a successful migration:
- Limitations in data retrieval: It is currently impossible to retrieve all existing paths stored in ZooKeeper with a single command.
- Cluster consolidation: We merged multiple ZooKeeper clusters into a single ClickHouse Keeper cluster.
- Data comparison accuracy and speed: During the automated migration process, it is critical to perform data comparison both quickly and accurately. Failure to do so could exponentially increase the migration duration, heightening the risk of misjudgment and potential migration failure.
To quickly retrieve and compare paths, we implemented the following strategies:
-
When converting ZooKeeper snapshots to ClickHouse Keeper snapshots, we print all converted paths to a pathlog target file. During comparison, we sample the content of this file, converting ZooKeeper queries into file reads. Originally, reading 9 million ZooKeeper paths took about 9 hours, but with optimization, it now takes only a few seconds (e.g. by loading pathlog into memory for reading).
-
We compare znode paths sequentially based on the migration relationship. We ensure that tasks like merges are shut down before comparison, further ensuring no temporary directories appear, thereby guaranteeing the validity of the comparison. The comparison is divided into two scenarios:
- Differentiated paths: These paths exist only under the
/clickhouse/tablespath and are present in only one ZooKeeper cluster. If they pass comparison verification, the validation is successful. Conversely, if they do not exist in multiple ZooKeeper clusters or exist in two or more clusters, the validation fails. This ensures the correctness of differentiated path data. - Common paths: The contents of the paths are the same in all ZooKeeper clusters, passing comparison verification. This ensures the correctness of common path data.
- Differentiated paths: These paths exist only under the
Tuning
We applied the following parameter tuning for ClickHouse Keeper:
-
max_requests_batch_size: This indicates the maximum size of requests batched before sending to raft. The larger the cluster, the more this value should be adjusted upward to facilitate batching and performance improvement. In our scenario, we set the value to 10,000.
-
force_sync: Indicates whether requests are synchronously written to the log. Optimized setting is false.
-
compress_logs: Indicates whether logs are compressed. Log file size affects startup speed and disk usage. Optimized setting is true.
-
compress_snapshots_with_zstd_format: Indicates whether snapshots are compressed. Log file size affects startup speed and disk usage. Optimized setting is true.
Results
After replacing ZooKeeper with ClickHouse Keeper, the resource savings and write latency improvements were significant, resolving the performance bottlenecks of storing metadata in ZooKeeper, while also lowering the maintenance barrier.
Previously, the IO bottleneck in ZooKeeper would directly impact the overall write latency of ClickHouse storage. In our cloud platform with trillions of ingested events, migrating from ZooKeeper to ClickHouse Keeper resulted in over 75% savings in CPU and memory usage.
After switching to ClickHouse Keeper, IO overhead decreased by 8 times, and performance improved nearly 8 times.
Originally, we did not anticipate that ClickHouse itself would be so powerful, and ClickHouse-Keeper's performance is equally impressive!
| Language | Resources | CPU util. | RAM util. | I/O util. | Ingest duration | Failure rate | |
|---|---|---|---|---|---|---|---|
| ZooKeeper | Java | 12 nodes | 36 cores | 81.6 GB | 4% | P99=15s | high |
| ClickHouse Keeper | C++ | 3 nodes | 9 cores | 18 GB | <0.5% | P99=2s | almost zero |
| Savings | 75% | 75% | 78% | 87% | 86% | >90% |



