Lyft is driven by a simple purpose: to serve and connect. Last year, the rideshare giant provided more than 800 million rides to over 40 million people across the U.S. and Canada, helping passengers get where they need to go and helping drivers earn on their own terms.
Beneath each of those rides is a mountain of data. From experimentation and forecasting to campaign targeting and marketplace health, teams across Lyft rely on fast, accurate insights to make smart decisions, improve service, and keep the business moving.
Like transporting millions of people, delivering those insights at scale is a monster task. Lyft processes hundreds of terabytes of data every day, supporting everything from deep historical analysis to real-time decisions where freshness really matters. They needed an analytics system that could handle both, without becoming a nightmare to maintain.
At Open House, engineers Jeana Choi and Ritesh Varyani walked through Lyft’s decision to adopt ClickHouse Cloud, including the evolution of their ingestion pipelines and how ClickHouse has given them the performance and scalability to meet Lyft’s growing needs.
From Druid to ClickHouse Cloud #
For years, Lyft relied on Apache Druid for fast, interactive analytics on time-series data. But as the system grew more complex and costly to maintain, adoption started to stall. Onboarding new teams required a steep learning curve, and day-to-day operations became increasingly difficult to scale.
In 2023, after Lyft’s marketplace team had adopted ClickHouse for a specific use case, the company began evaluating it as a Druid replacement. “One of ClickHouse’s standout factors is its high performance, due to a combination of factors such as column-based data storage and processing, data compression, and indexing,” Jeana and Ritesh wrote at the time.
Along with its high performance, the team’s tests showed that ClickHouse offered several clear advantages: simplified infrastructure, a reduced learning curve, built-in data deduplication, lower operational costs, and support for specialized engines.
“We decided it was a better idea for us to move to ClickHouse,” Jeana says.
The migration began with a self-managed deployment. But as adoption grew and operational needs continued to increase, Lyft moved its analytics to ClickHouse Cloud. Today, ClickHouse’s managed service powers both batch and real-time pipelines, pulling data from S3 (via Trino), Kafka, and Kinesis. It serves queries through client applications, observability tools like Grafana, internal analytical tools, and the ClickHouse Cloud console UI.
The next diagram shows how Lyft ingests, processes, and queries data with ClickHouse Cloud:
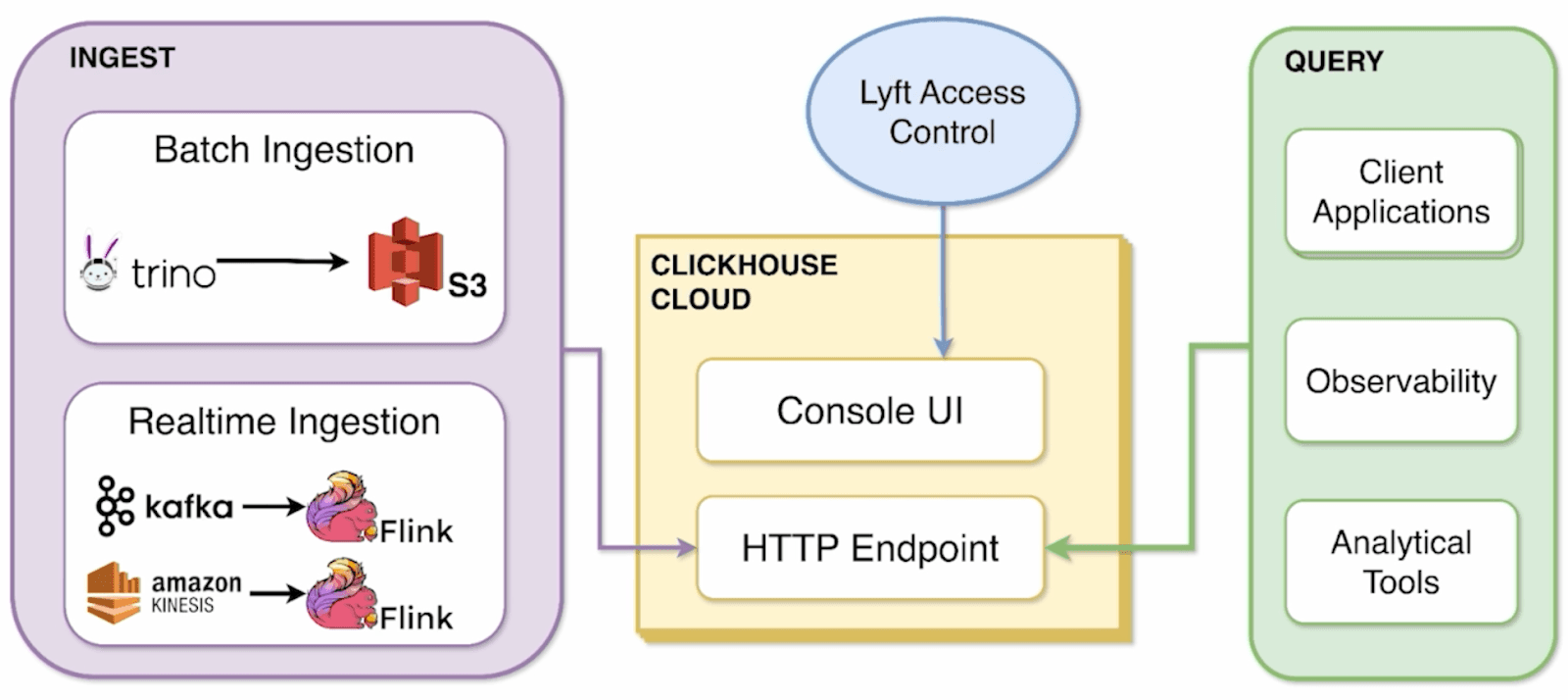
“We use the console UI pretty heavily for anyone who wants to play around quickly,” Jeana says. To support secure and scalable access, the team also implemented automated role-based permissions. New users are onboarded automatically with read-only access, while teams assign elevated permissions through internal workflows. This allows fast, secure access that aligns with Lyft’s access control policies.
Today, Lyft’s analytics system handles hundreds of queries per second on average and is “growing continuously, with peaks in the thousands,” Jeana says. Reading more than 450 terabytes of data per day and writing around 4 terabytes, it delivers a smoother, faster ride for Lyft’s internal teams than their old Druid-based system ever could.
Batch ingestion for business insights #
At Open House, Jeana walked through the batch ingestion side of Lyft’s analytics platform. At its core is a flexible, repeatable ingestion process built to handle schema changes, large-scale aggregations, and efficient long-term storage.
Each batch ingestion job is defined by a TOML file that specifies the source dataset, the aggregation logic (usually a Trino SQL query), and how the target ClickHouse table should be set up—engine type, partitioning, projections, column definitions, and so on. “This is just a nice way for us to organize all of our information,” Jeana says. The jobs run on a schedule and automatically update ClickHouse with fresh data. “If we want to change columns or whatever, this cron figures it out and solves it for us.”
The following diagram shows how Lyft ingests batch data using Trino and ClickHouse’s S3 table function:
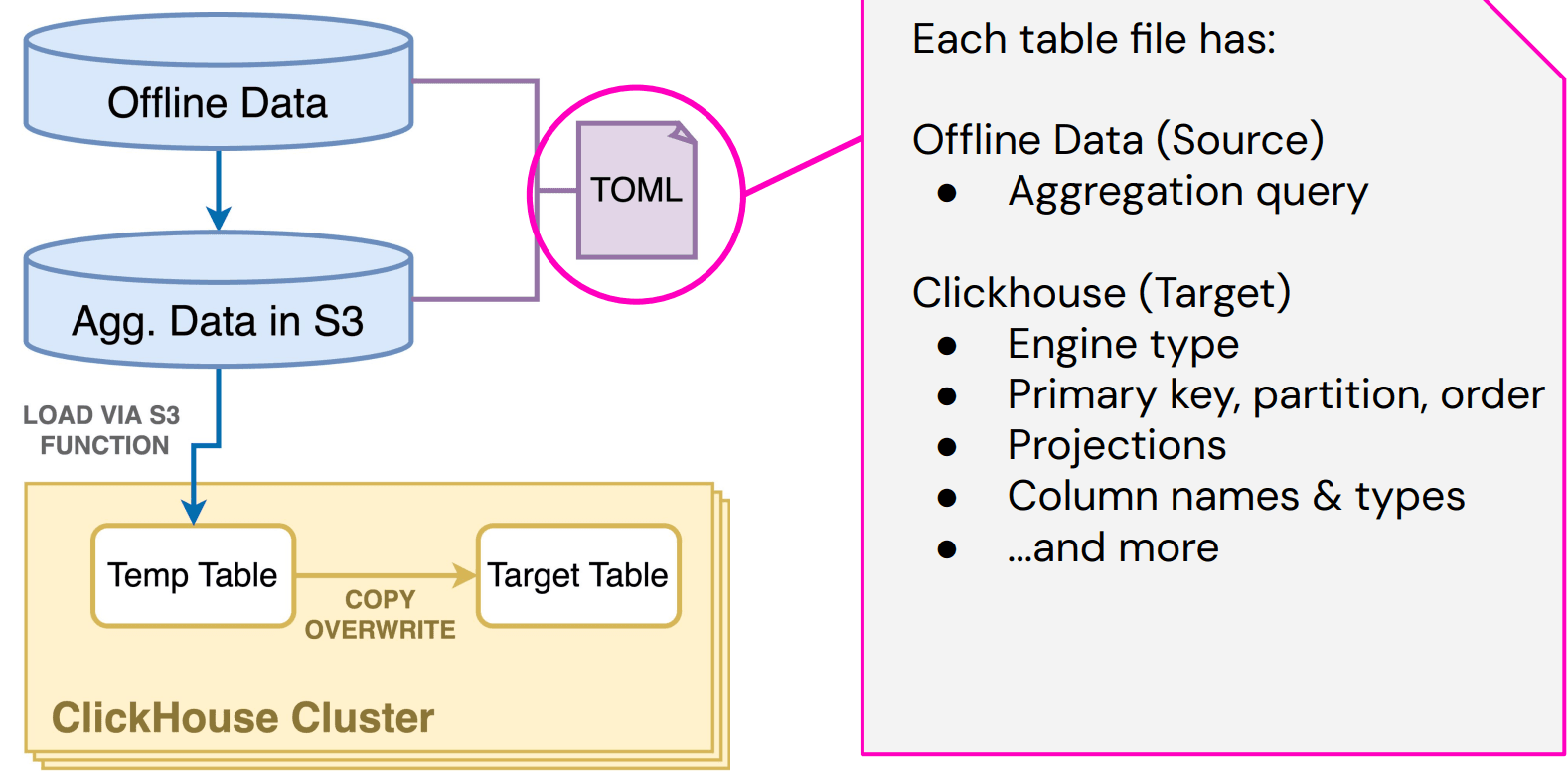
To actually run ingestion, the team reads data from S3 using ClickHouse’s built-in s3 table function, stages it in a temporary table, and then swaps in the updated partitions. “It’s super simple to use and read from whatever S3 bucket you want,” Jeana says.
As Jeans explains, Lyft’s primary use case for batch data is dashboarding. “Our dashboards use terabytes of historical ClickHouse data for business insights. It’s really nice to be able to slice and dice this data over years or months to reveal critical trends pretty quickly.”
Batch ingestion also helps Lyft use resources efficiently. “We can optimize resources for workloads that don’t necessarily need to be in real time,” she adds.
Like any migration, the move to ClickHouse Cloud wasn’t without challenges. The team ran into a few parity issues with their existing in-house systems and had to rework some internal table structures to accommodate differences in cloud feature availability. For example, when the join table engine wasn’t available, they found that dictionaries were actually a better fit for their relatively static lookup data.
Despite the bumps, the result is a more scalable, maintainable system that handles terabytes of batch data with ease.
Real-time ingestion for fast decision-making #
While batch data powers strategic insights, real-time analytics fuel Lyft’s day-to-day operations. At Open House, Ritesh shared how the team built streaming pipelines designed for speed, reliability, and flexibility at scale.
The system supports two main data sources, Kafka and Kinesis, which drive internal use cases like experimentation and forecasting. In both cases, Apache Flink acts as the processing layer. Flink jobs deserialize events, enrich them using Lyft’s centralized protobuf IDL (interface definition language), and send the data to ClickHouse Cloud.
This diagram sketches how Lyft streams real-time data from Kafka and Kinesis into ClickHouse Cloud using Flink:
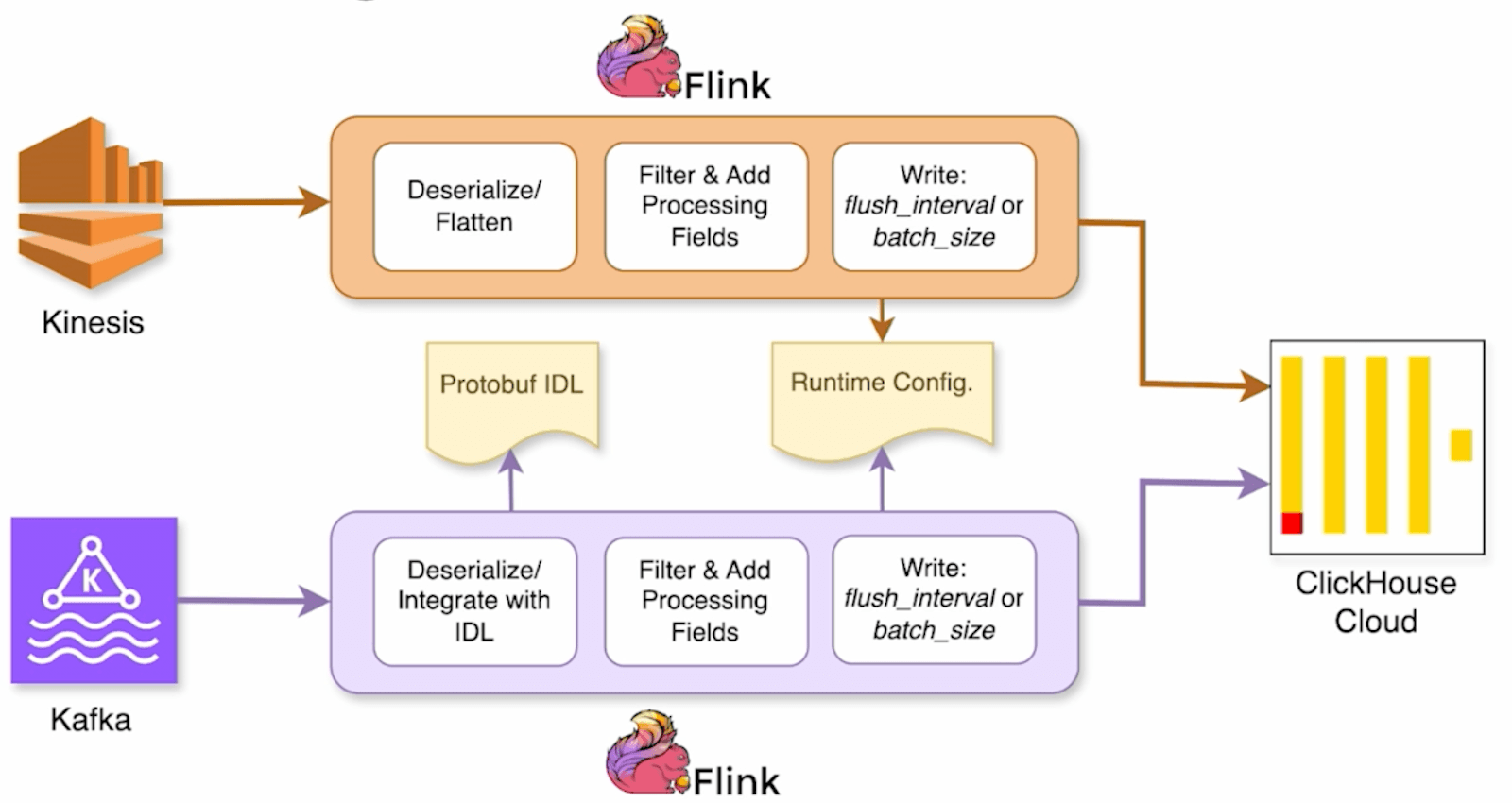
One big evolution Ritesh highlighted was removing the need to manually sync protobuf schema definitions with ClickHouse. “Every event, every message, you have a centralized repository for it,” he explains. In the old setup, engineers had to copy those protobuf definitions into ClickHouse by hand and keep them in sync. “That was a hassle,” especially with nested messages or frequent schema updates.
The new setup uses Java reflection to dynamically deserialize nested messages at runtime based on event-specific configurations. That means no more manual flattening, and ClickHouse stays up to date, even when the protobuf IDL evolves.
This is a sample config mapping Kafka events to ClickHouse tables with deserialization and rollout rules:

This real-time pipeline powers all kinds of everyday decisions. Experimentation teams use it to evaluate treatment effects almost instantly. Marketplace teams rely on it to track supply and demand. Campaign managers tap into real-time signals to adjust targeting on the fly.
Again, the move to ClickHouse Cloud wasn’t without friction. Lyft had to rework systems built around the Kafka table engine, since ClickPipes was still in preview and not quite production-ready. Running an older version of ClickHouse with ZooKeeper also introduced some limitations. And the team had to work through tuning batch sizes, improving data freshness, and navigating a tighter-than-ideal coupling with their IDL pipeline.
The stack is still evolving—“Will it look the same six months from now? Probably not,” Ritesh says—but it’s already become a cornerstone of Lyft’s data-driven culture.
What’s next for Lyft and ClickHouse #
As adoption of ClickHouse grows inside Lyft, Jeana, Ritesh, and their teams are focused on scaling to meet demand. Recent updates, like improved access controls, async inserts, and custom batch sizing, are helping them gear up for higher traffic and heavier workloads.
But the bigger shift is still ahead: deeper integration into Lyft’s broader data platform. “We don’t want to keep ClickHouse Cloud as an isolated product,” Ritesh says. The team is working on end-to-end data completeness checks, new data discovery tools, and direct exports from offline datasets into ClickHouse. Together, these efforts are aimed at making the platform more accessible and impactful across the company.
Reflecting on their progress with ClickHouse so far, Ritesh says there’s lots to celebrate and even more to come. “This journey has been really revolutionary,” he says. “We look forward to continued collaboration.”
To learn more about ClickHouse and see how it can improve the speed and scalability of your team’s data operations, try ClickHouse Cloud free for 30 days.



