In a previous post I introduced how you can build a table in ClickHouse containing all of the data from your GitHub Actions using GitHub Webhooks. We do this for the ClickHouse organization, to provide essential metrics on the internal queue of workflow jobs.
Just having this and doing nothing with it would be a huge waste of gemstone data, so a couple of months ago the data was used to implement a lambda to quickly inflate and deflate our workers on demand. This has improved the responsiveness of our job launching, reacting to an increase in scheduled tests, as well as saving us compute when the workload is lower. Let's discuss how we achieved this!
The Idea
We have all events in our database for when a workflow job was created, started or finished. Consider this query from the previous post, which returns the current ClickHouse queue size for self-managed GitHub Runners:
SELECT last_status, count() AS queue, labels FROM ( SELECT argMax(status, updated_at) AS last_status, labels, id, html_url FROM default.workflow_jobs WHERE has(labels, 'self-hosted') AND (started_at > (now() - toIntervalHour(3))) GROUP BY ALL HAVING last_status != 'completed' ) GROUP BY ALL ORDER BY labels ASC, last_status ASC

Knowing this allows us proactively to scale-up the runners to cover the demand, or scale-down to free unnecessary resources.
The new desired capacity is calculated based on the current number of runners and jobs in progress and queue. If there is a deficit, we increase the capacity proportional to it (usually, deficit / 5). And for the unnecessary reserve, we quickly deflate the group (reserve / 2).
An old system
The officially recommended approach in AWS to trigger scaling up/down is assigning CloudWatch alarms to Auto-Scaling Groups (ASG.) So, whenever an alarm is in an alarm state, the ASG adds or removes some instances.
We used to monitor how many instances of each ASG were in a busy state using the GitHub runners API. If there were more than 97% busy runners for 5 minutes, another one runner was added. For scaling out the rule was less than 70%.
The system used to be very reactive and inert. To warm up groups with 50+ runners it required a few hours.
Improvements and statistics
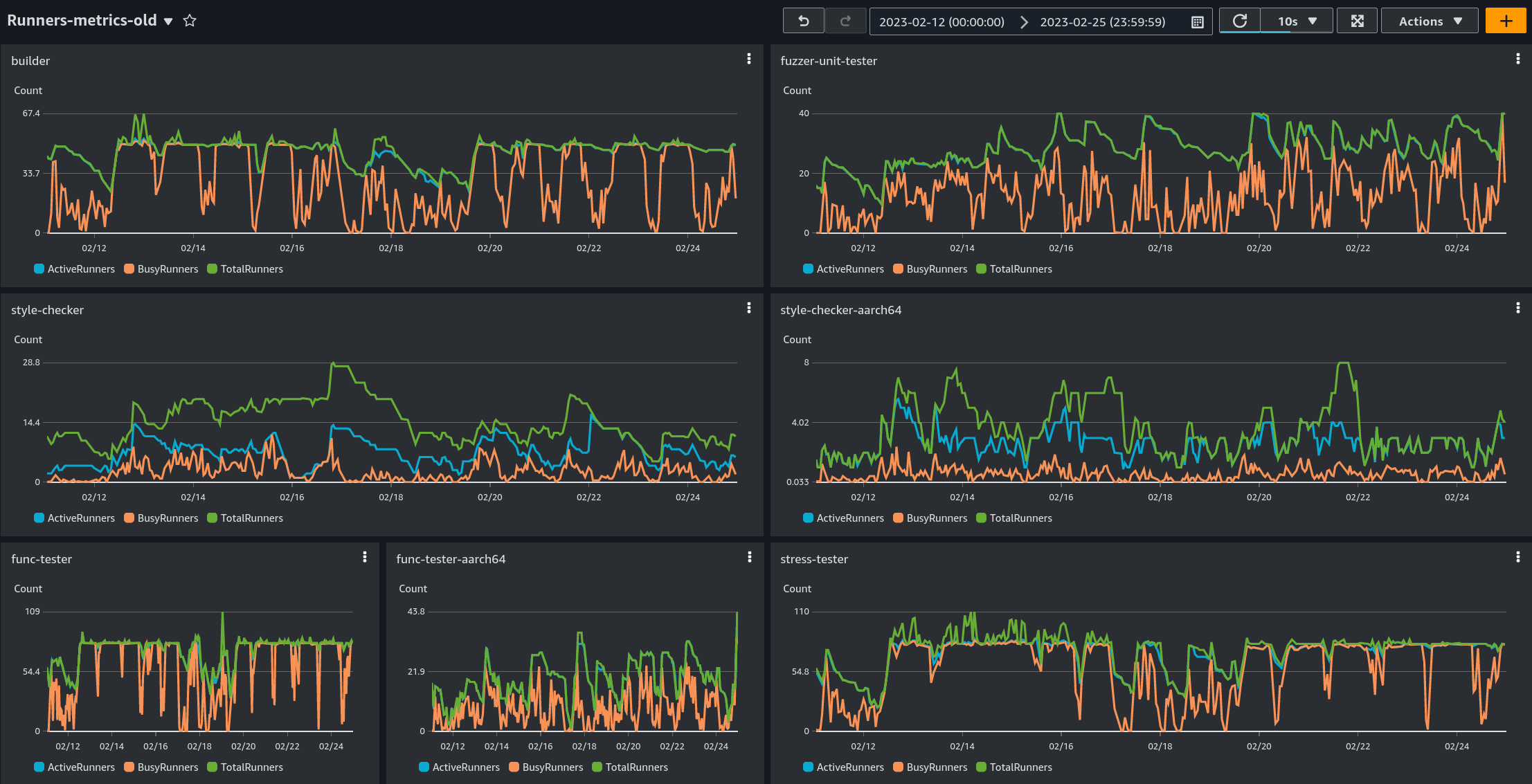
After switching to our new system, we both achieved faster jobs launching and a saving of compute time after the job was done. You can see how it affected the runners on the graphs:
The old system:
The new system:
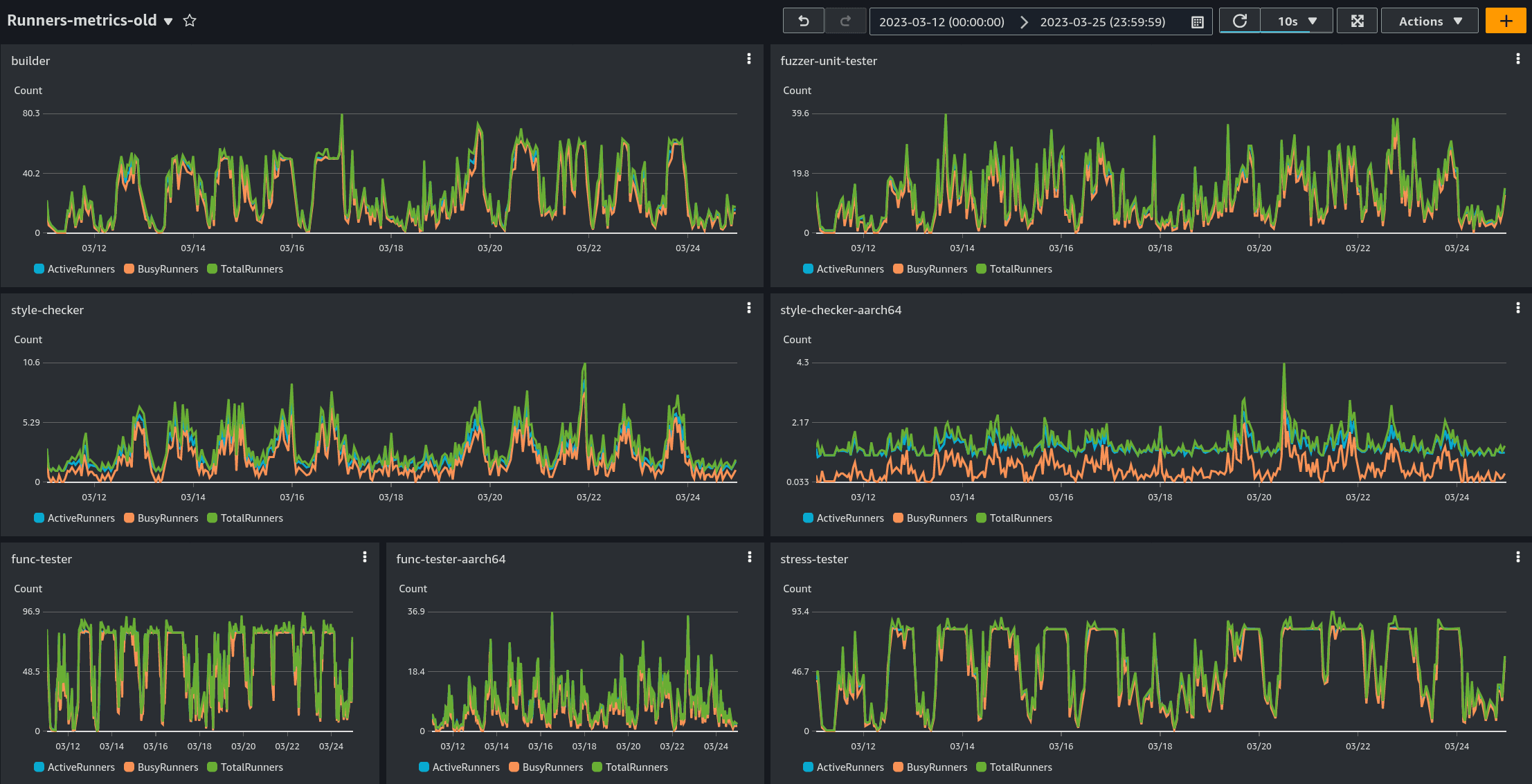
We can see how the Busy and Active Runners are more tightly correlated in the new system, indicating that provisioned workers are more heavily utilized. The code used here is all available in our repository. Hopefully others can make similar improvements and savings!


