TLDR
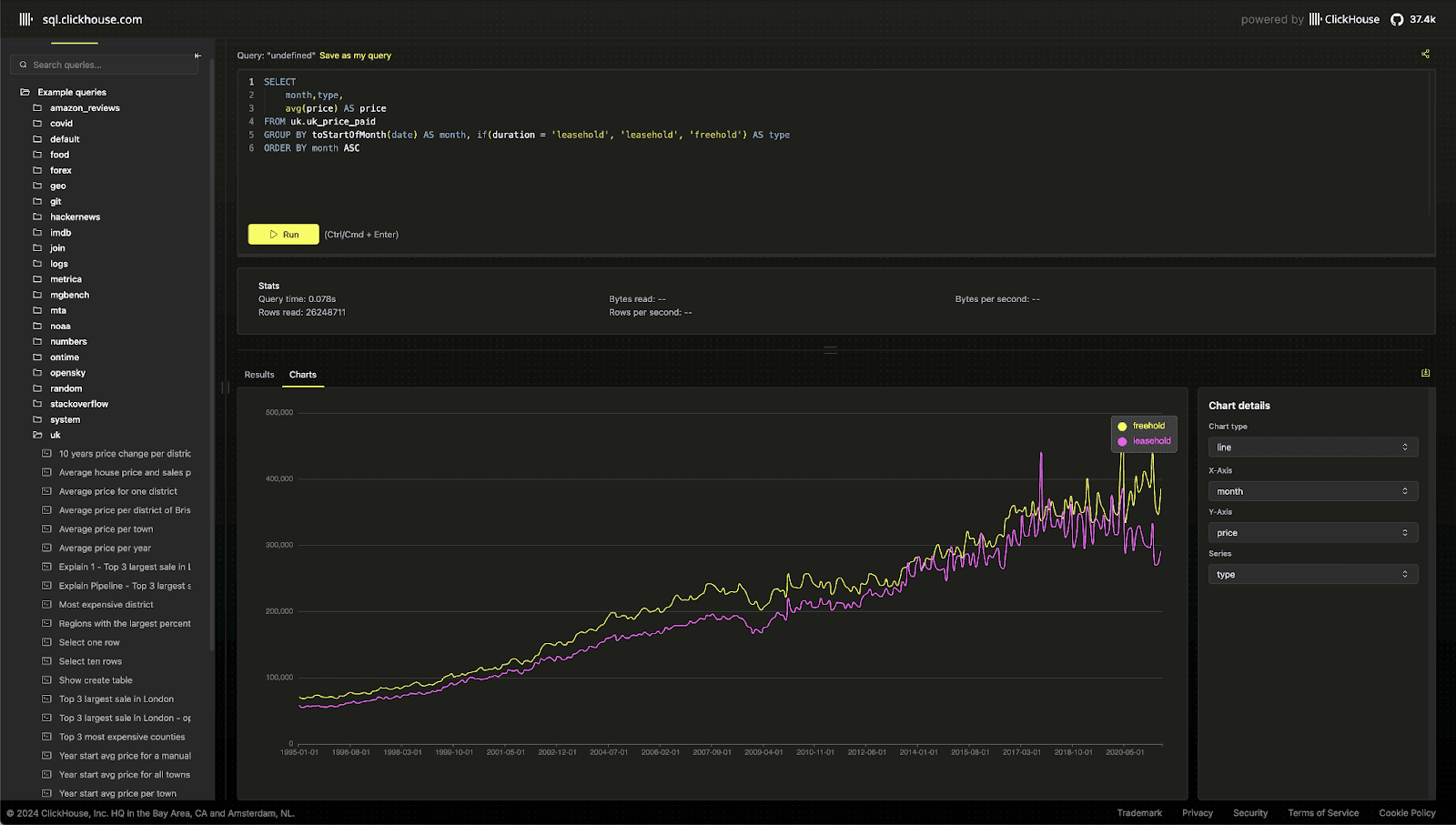
As part of our efforts to make querying large datasets easier than ever, we’re pleased to announce the availability of sql.clickhouse.com! This new SQL playground has over 35 datasets and 220 example queries to get started. We’ve included some simple charting capabilities, which we plan to improve, and the ability to save and share queries! Take it for a spin and share your favorite queries either on social or via the GitHub repo, where we’ll add them for others to enjoy!
Background
As ClickHouse users, we are passionate about datasets. We even have an internal slack channel, aptly named "data lovers" for sharing interesting datasets for experimentation and testing of features! Historically, we've documented these datasets and tried to provide example queries to get users started. While we also made many of these datasets available in a public ClickHouse instance, also referenced from our documentation, this used the classic Play interface packaged with ClickHouse.
This Play interface is deliberately simple and ideal for getting started: it has no dependencies and is a single HTML file.
However, this didn’t provide the rich user experience we wanted for our playground. Ideally, we wanted something where users could navigate and save example queries while supporting syntax highlighting, autocomplete, query parameters, results export, basic charting, and rich sharing features. These features would allow users to explore datasets and hopefully help users get started with ClickHouse and share their problems.
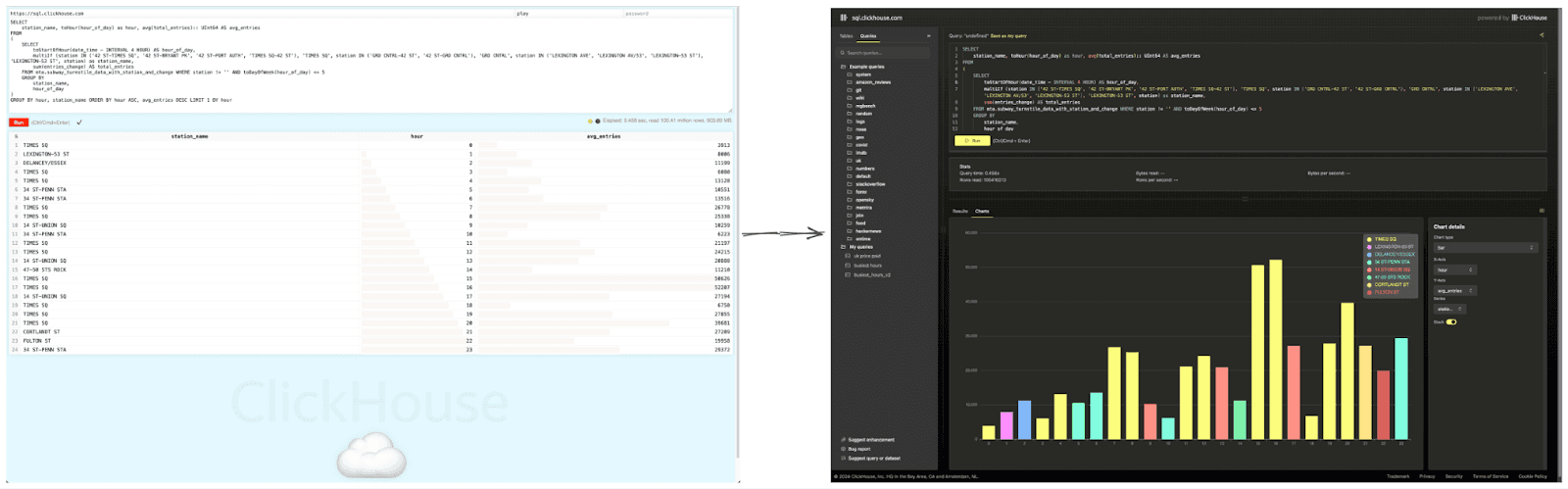
Fortunately, we recently built a UI for our CryptoHouse demo, where users can query over 100TB of blockchain data for free - including Solana, Ethereum, and Polymarket. This UI was also built to be reusable, benefiting from reusing some of the experiences and code from our own ClickHouse Cloud SQL console. With a few enhancements, we were able to quickly re-purpose this demo, and we also used the opportunity to re-organize and catalog our existing demo datasets. With over 35 datasets totaling 60 TB (and growing!), we’ve also loaded all of the 220 example queries from our docs and blogs to help users get started.
Our documentation and blogs will increasingly reference this environment moving forward, with the recent MTA blog already benefiting from this new playground.
Users who prefer to use the clickhouse-client, or wish to integrate the service into their own applications, can connect directly to the ClickHouse instance at sql-clickhouse.clickhouse.com e.g.
clickhouse client --host sql-clickhouse.clickhouse.com --secure --user demo --password ''
Building a UI with ClickHouse made simple
The demo-ui remains a single-page application built using NextJS and React, where the client makes all requests. As we described in detail in our blog post about building single-page applications, this is made possible by some key ClickHouse features:
- HTTP interface & REST API- makes it trivial to query ClickHouse with SQL from Javascript. By default, ClickHouse listens on port 8123 or 8443 (if SSL), with the latter exposed in ClickHouse Cloud. This interface includes support for HTTP compression and sessions.
- Output formats - support for over 70 output data formats, including 20 sub formats for JSON allowing easy parsing with Javascript.
- Query parameters - allowing queries to be templated and remain robust to SQL injections.
- Role-Based Access Control - allowing administrators to limit access to specific tables and rows.
- Restrictions on query complexity—We restrict users to read-only and limit the query complexity and resources available. In Playground, we limit users to reading 10 billion rows per query and returning 1000 in a result set.
- Quotas - to limit the number of queries from any specific client (keyed off IP Address), thus preventing rogue or malicious clients from overwhelming the database. Users are limited to 60 queries per hour in Playground.
The latter three are particularly important here as they allow us to expose the ClickHouse Cloud instance behind the demo to the public internet and safely expose the read-only credentials. For further details on the exact configuration of ClickHouse used, see here.
The UI also heavily uses our component library, click-ui. This library provides a set of React components that align with our own brand and provide an opinionated set of behaviors. This library is the backbone of our Cloud UI and rapidly accelerates development, avoiding spending hours “pixel pushing” to achieve just the right appearance. This is particularly useful when you want to move fast for a demo!
Finally, we’d like to mention Apache Echarts. This charting library is easy to integrate and extremely well documented, allowing us to provide charting capabilities with minimal effort.
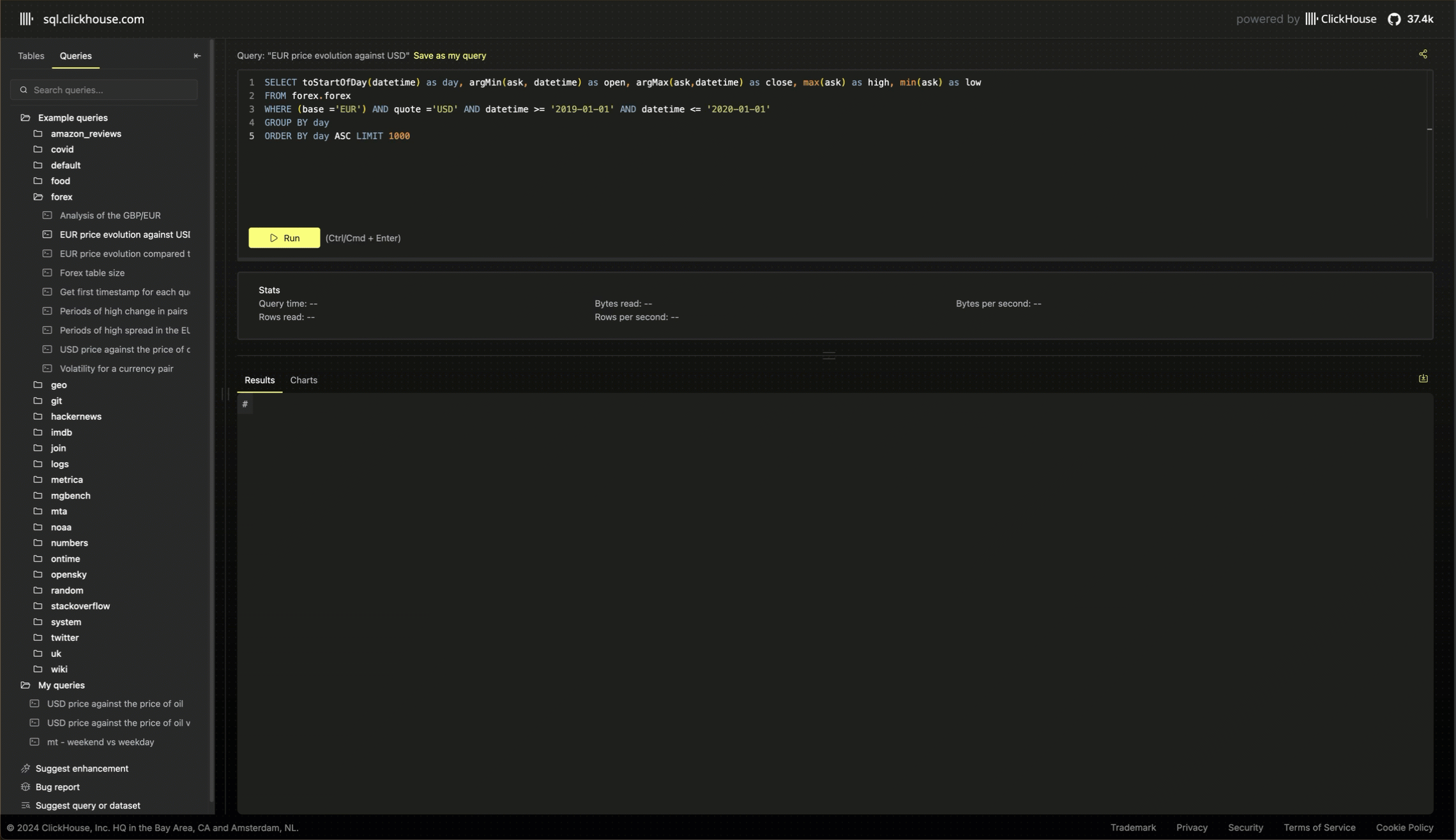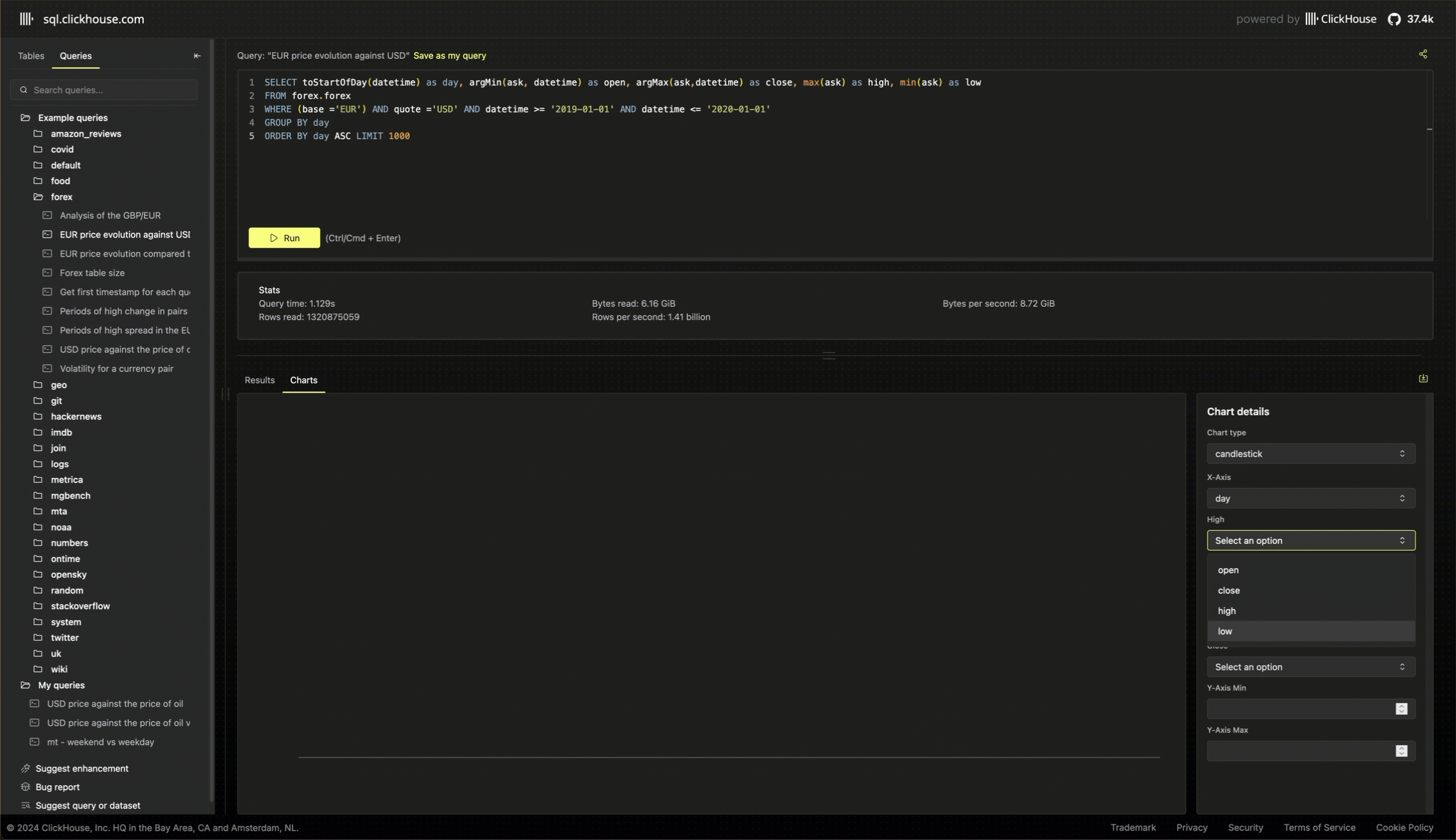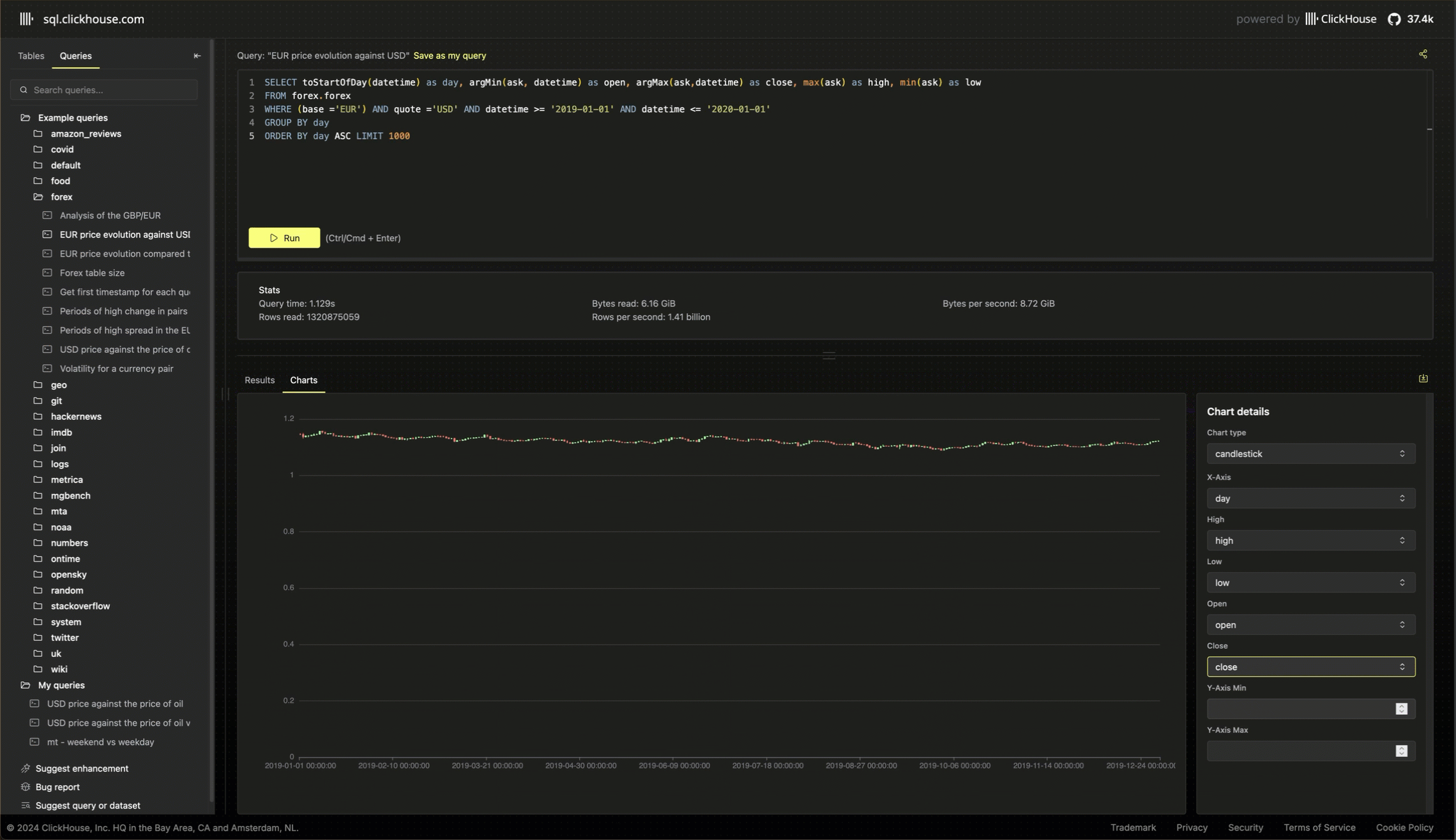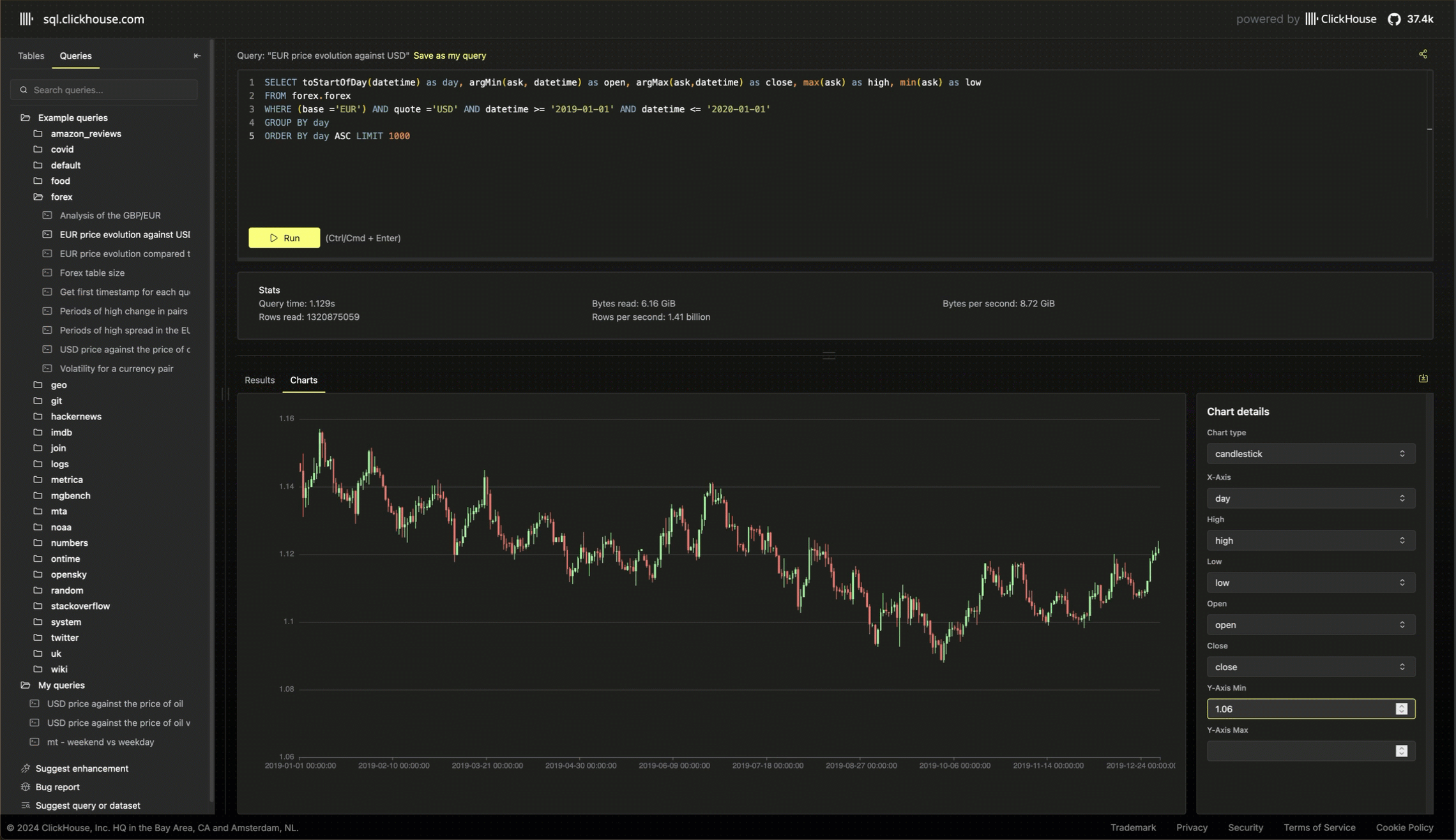
Running cost-efficient demo playgrounds
While a demo playground is essential to any OSS database, we must also provide the service cost-efficiently. Quotas are a component of this, ensuring fair usage and preventing one user from consuming all the resources. The service also benefits from ClickHouse Cloud’s separation of storage and compute, with the data backed on object storage. This minimizes the data storage cost and allows us to scale infinitely as we add more demo datasets.
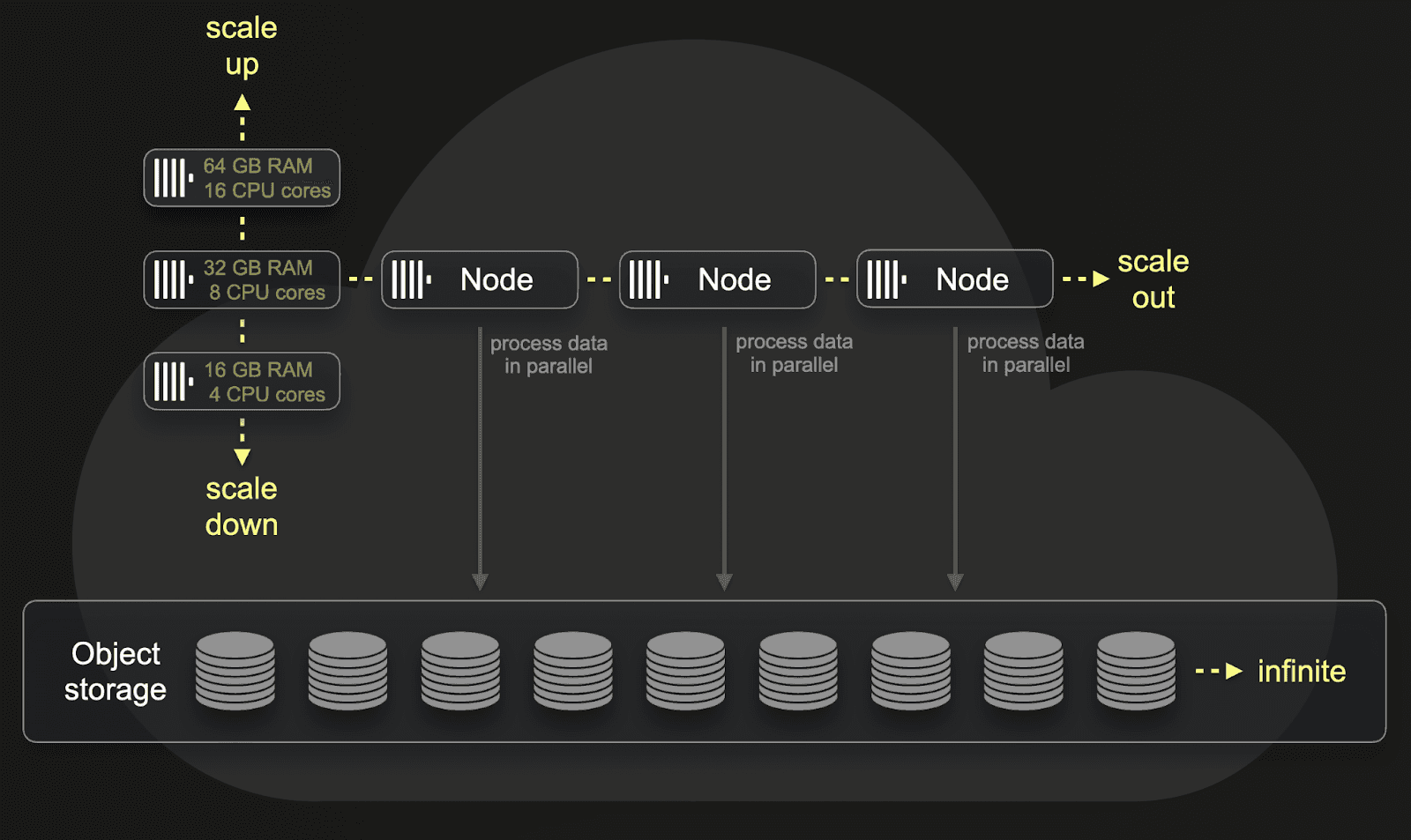
While ClickHouse Cloud does support auto-scaling, the cluster is currently fixed at 3 nodes of 30vCPUs each—predominantly because we expect a fairly constant query load if our users adopt the demo. We monitor and alert on resource consumption and will review these resources based on demand, either scaling vertically or horizontally as required.
Finally, while our current datasets are static, our next efforts will focus on ensuring as many of them are kept up-to-date as possible. This is likely to exploit two key ClickHouse Cloud features:
- ClickPipes - a managed integration platform that makes ingesting data into ClickHouse simple. While this will require us to ensure dataset changes are periodically made available on either Kafka or object storage, it should greatly simplify data loading.
- Compute-compute separation - currently in preview, this provides the flexibility to create multiple compute node groups, each with its own endpoint, while sharing the same object storage. This architecture enables isolation between various types of workloads, allowing for fine-tuned resource allocation. For the playground, this means we can allocate dedicated compute for writes, isolating this workload from user queries (and thus not impacting their performance) and allowing it to be scaled independently achieving better cost efficiency.
A few technical highlights
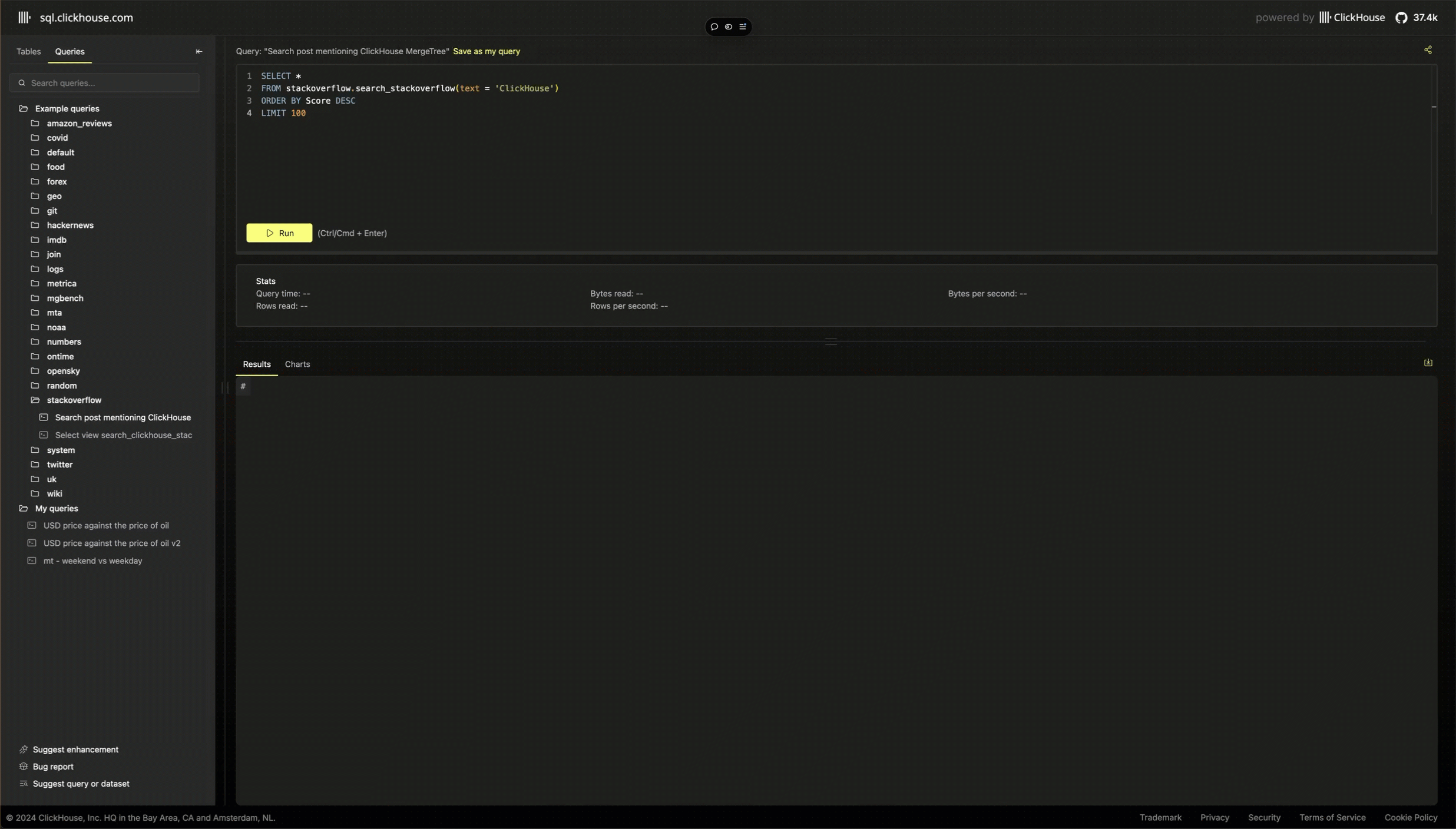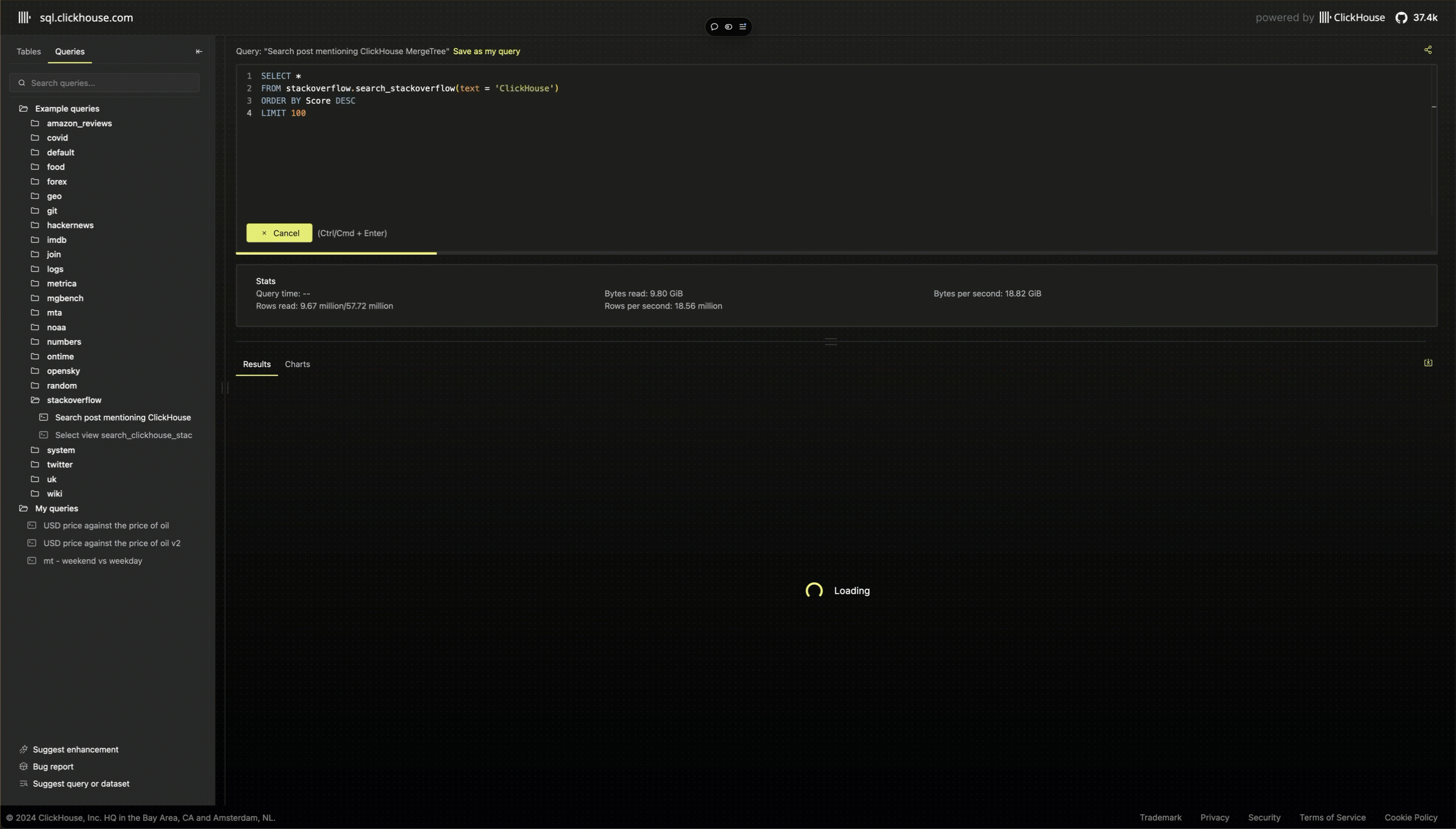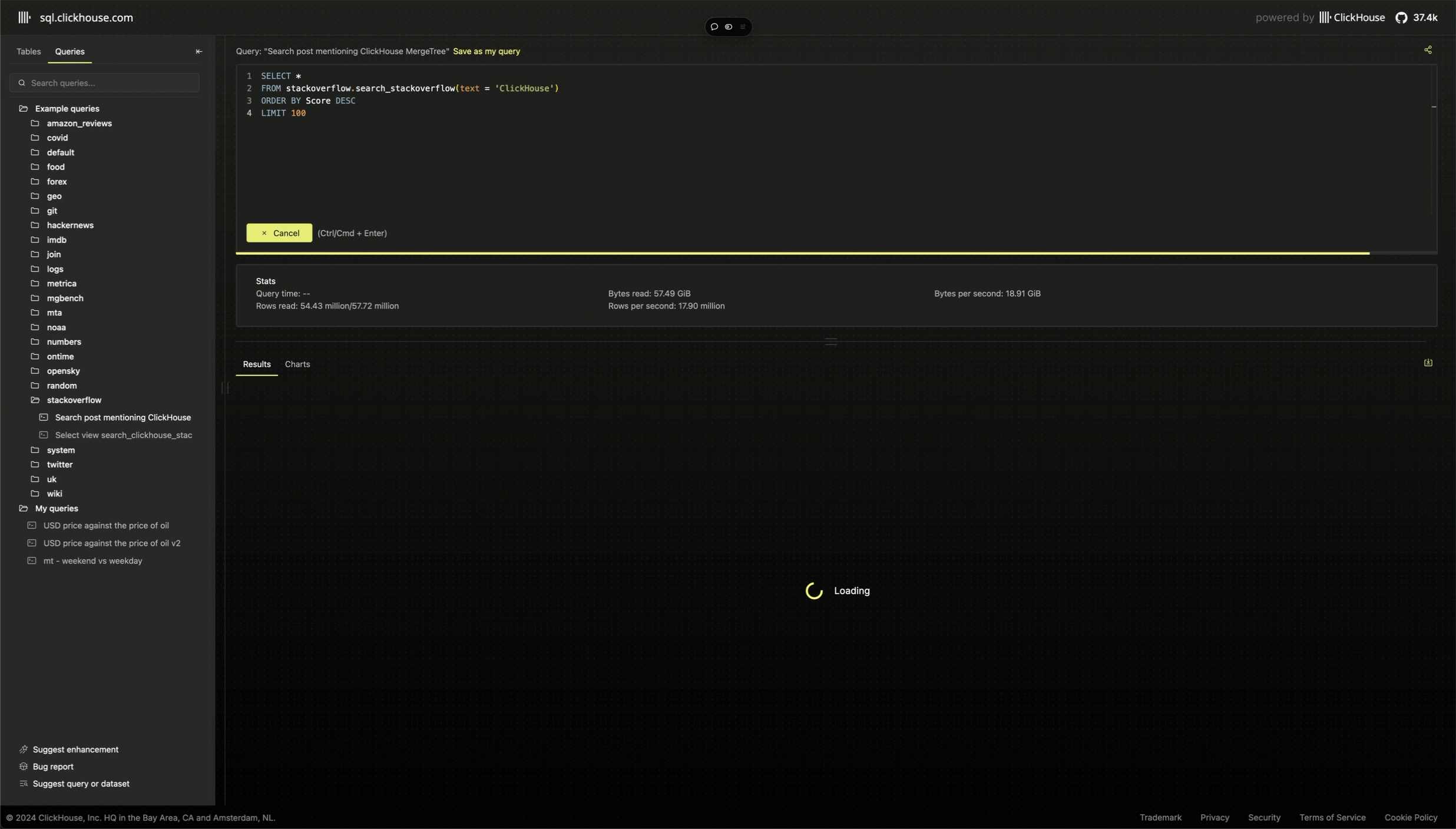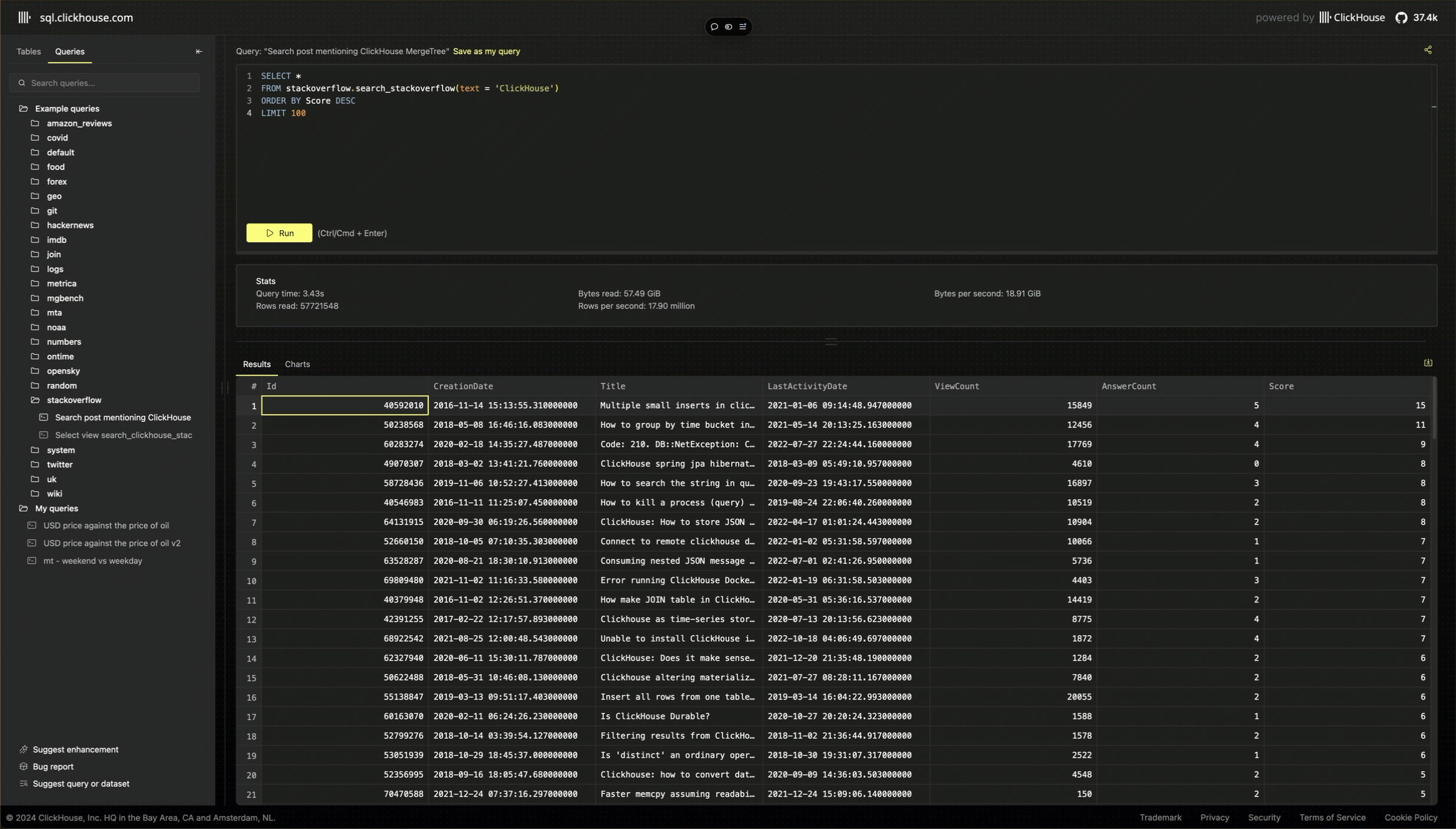
Although the demo UI is simple, there is one feature that’s worth sharing the implementation details. New users to ClickHouse often comment on how the active query feedback provided in the clickhouse-client is one of the highlights when first running a query.

This feedback becomes increasingly essential as users write more complex queries - not only to estimate how long the query will take but also for its performance and resource consumption. We were keen to ensure a similar experience was available to users in the playground, as well as support for canceling if it was apparent a query was likely to exhaust complexity limits (e.g., 10 billion rows scanned) and never complete.
While the HTTP interface of ClicKHouse will send response headers as a query executes, these are not supported in browsers' fetch API and are tricky to read. Although alternatives exist, e.g., using the formats that return progress in the response stream, such as JSONEachRowWithProgress, these are also not ideal and incur an overhead. Instead, we explicitly assign a query ID to each query and use a separate query run on a fixed interval (every 100ms), which checks the system.processes table:
SELECT
sum(read_rows) AS read_rows,
sum(total_rows_approx) AS total_rows,
sum(read_bytes) AS read_bytes,
read_rows / max(elapsed) AS rps,
read_bytes / max(elapsed) AS bps,
formatReadableQuantity(read_rows) AS formatted_rows,
formatReadableQuantity(total_rows) AS formatted_total_rows,
formatReadableSize(read_bytes) AS formatted_bytes,
formatReadableQuantity(rps) AS formatted_rps,
formatReadableSize(bps) AS formatted_bps
FROM clusterAllReplicas(default, system.processes)
WHERE (initial_user = 'demo') AND startsWith(query_id, {uuid:String})This query runs under a monitor user, which has lower complexity limits concerning the number of rows it can read but a higher quota for the number of queries allowed per hour. This allows us to provide rich details on the progress of a query as it runs:
Contributing queries and datasets
The playground allows users to save queries (and their configured chart) locally. This persists only in browser storage, although you can share the query and its chart via a link. If you feel a query is worth documenting and sharing with the broader community as an official example, please raise an issue or PR on the source example query file. We will also ensure that example queries and new datasets contributed to the documentation are available in the playground.
As we highlight below, we’re looking to improve this experience by simplifying the submission of example queries.
Looking forward
Our efforts to improve the SQL playground moving forward will focus on three areas:
- Live datasets - Ensure the datasets are updated as new data becomes available. Although some of the datasets are not subject to change, others, such as GitHub events, can be updated in real-time. We expect this to be a gradual effort.
- Sharing widget - Although we’ve actively linked all example queries in our docs and blogs to the new playground, users would ideally be able to run these in place. This requires a query widget that we can embed across pages, with results and charts rendered in place. This same widget could then be used in a forum or discussion-based format to improve collaboration amongst our community.
- Simplifying sharing - As we noted above, the process for sharing new datasets and example queries is currently a bit cumbersome. We’re exploring ways to make this process smoother and easier.
Stay tuned for developments!
Conclusion
The new ClickHouse SQL Playground is a resource for our community and data enthusiasts to explore, experiment, and share insights using real-world datasets while also learning ClickHouse. We hope our users find the playground valuable and encourage you to share your feedback (and favorite queries)!
Get started with ClickHouse Cloud today and receive $300 in credits. At the end of your 30-day trial, continue with a pay-as-you-go plan, or contact us to learn more about our volume-based discounts. Visit our pricing page for details.



