Highlights
- Inserting around 100 billion records per day, over 1 million records per second
- Able to aggregate over 1 billion unique users a day
- Moved from MSSQL to Azure Table Storage to ClickHouse
- ClickHouse is deployed on 15 servers with 2 TB total RAM
Admixer is an Ad-Tech company that provides all the components to build infrastructure for advertising products for brands, ad agencies, media houses, publishers, ad networks, and other buy- and sell-side industry players looking for effective ad management. A distinctive feature of Admixer is their technology, which allows:
- Agencies to place advertising campaigns with specified execution conditions (terms, budget, creative display settings)
- Set the rules for distributing advertising campaign budgets among thousands of publishers
- Provide accounts for publishers, where they could not only see income statistics or withdraw money but also create their advertising campaigns, as well as connect other sources of monetization in addition to Network advertising campaigns.
Admixers products include:
- SSP – Supply-side platform where publishers/websites offer advertising space
- DSP – Demand-side platform where advertisers buy advertising space
- ADX – Ad exchange (connects SSPs and DSPs – buyers and sellers of advertisements and advertising space)
- DMP – Data management platform (used by advertisers to configure the audience they want to target)
Admixer provides not only access to these products but allows customers to build an entire ecosystem.
Why We Chose ClickHouse
To implement the previous point, Admixer began developing an Advertising Exchange. Initially, AdExchange was based on the sale of local inventory by external DSPs. Then it began to aggregate the traffic of external SSPs to place local advertisements on it and later redirect this traffic to external DSPs. Thus, ADX was created.
In 2015-2016, the share of external inventory was 3% (100 million requests), then at the end of 2016, it was more than 90% (3 billion requests). With a sharp increase in requests, the load on their processing increased, and most importantly, the load on the storage and provision of online analytics increased. Relational databases could not handle that many inserts for statistics records. Before migrating to Azure, we used a MSSQL server which stored the object structure and statistics.
In 2011, when migrating to Azure, we used Azure Table Storage to store and issue statistics. But with an increase in the number of transactions and the amount of data, it was not optimal to use this solution since Azure Table Storage charges for the number of transactions and the amount of data.
Thus we needed to:
- Display statistics on advertising transactions in the user interface in real-time;
- Accept a significant amount (1 million records per second) of data for insertion;
- Aggregate the received data for different sections (40 operations and the same number of metrics);
- Be able to scale the data warehouse as the number of requests grew;
- Have full control over our costs.
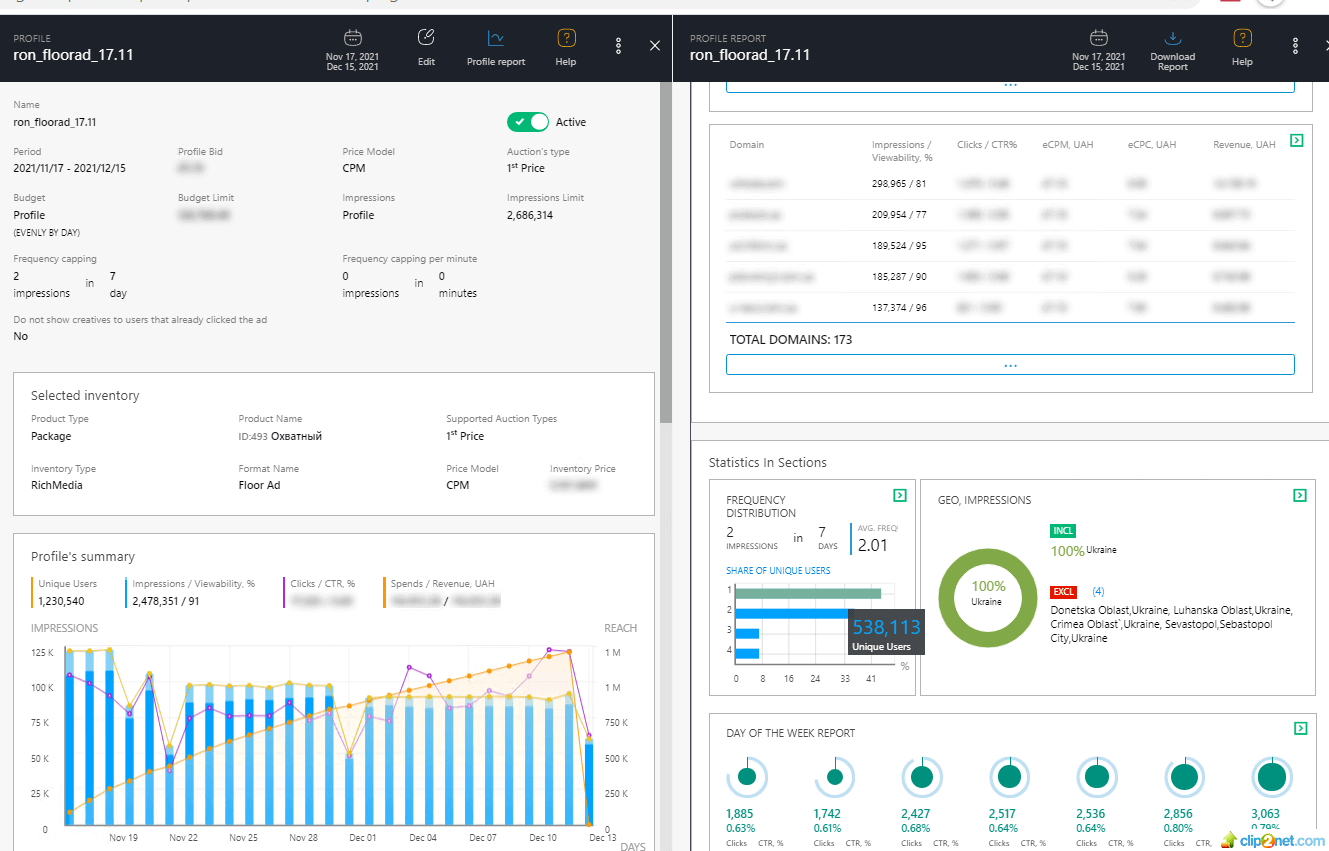
This image shows the Profile Report. Any Ad Campaign in Admixer is split by Line Items (Profiles). It is possible to overview detailed reports by each Profile including Date-Time Statistics, Geo, Domans, SSPs. This report is also updated in real time.
The Advantages of Using ClickHouse
ClickHouse helps to cope with the challenges above and provides the following benefits:
- Not tied to the platform (we decided to migrate from the cloud);
- The cluster we built allows us to receive up to a million inserts per second (and we know how to scale up on demand);
- Has built-in mechanisms for aggregating and distributing data across tables (materialized views);
- Excellent data compression;
- Reading speed makes it possible to display statistics directly in the user interface in real-time;
- Has a SQL dialect that provides the ability to build any reports;
- Has several advanced functions (and allows you to write your own) for processing statistics;
- Built-in HyperLogLog for storing rough data;
- Data sampling;
- Open source / community / good documentation;
- Constant additions of new features, bug fixes, and improvements to the current functionality;
- Convenient operations.
ClickHouse Architecture
Our architecture changed from 2016 to 2020. There are two diagrams below: the state we started and the state we came to.
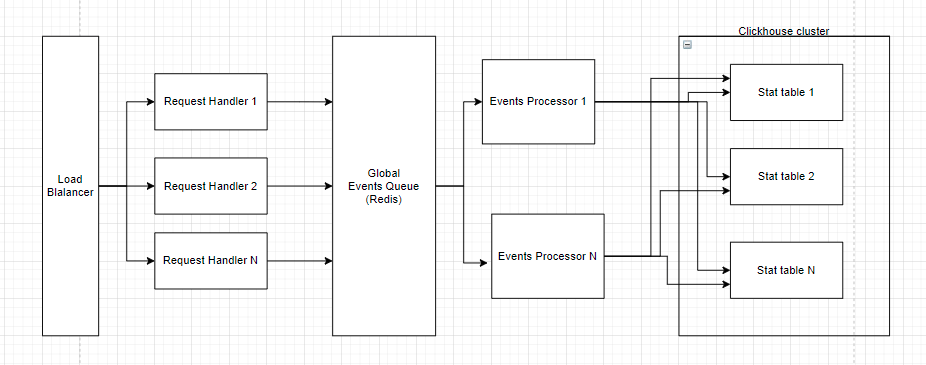
Architecture 2016
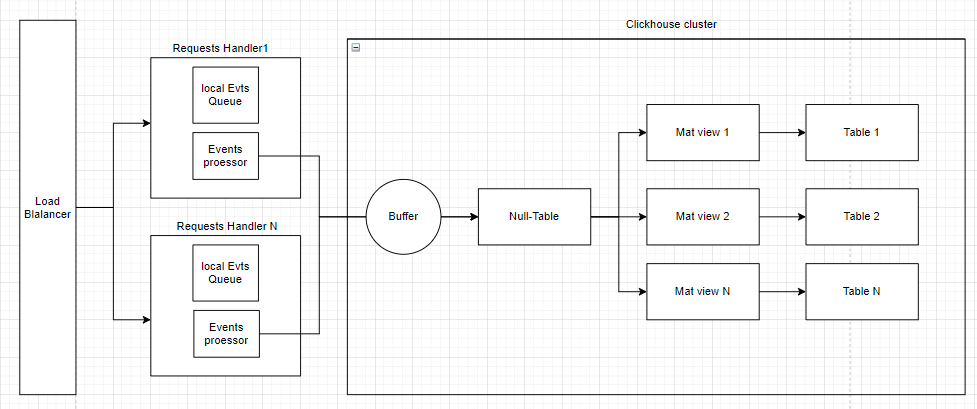
Architecture 2020
Requests Handler is a component that accepts a request for an advertisement and determines which banner to display. After the banner is selected, it records this in the statistics. Since 2020, these components have been receiving over 1 million requests per second. Statistics were recorded through an intermediate element named Global Events Queue. Events were retrieved from GlobalEventsQueue, read by the EventsProcessor components, and additionally validated/enriched, then written to the ClickHouse cluster.
Initially, we wrote from EventsProcessor in ClickHouse into several tables in parallel but then switched through Buffer-> Null-table-> MatViews. We will next investigate if the new asynchronous insert feature in version 21.11 would be an alternative to using a buffer table.
We also reviewed the implementation of the event queue. Initially, we used Redis (but Redis is InMemory storage), thus:
- On server restart, there was a risk of losing events;
- The amount of RAM is relatively small, and if we planned to stop the Events Processor or ClickHouse, there was a risk of overflowing the event queue, so a very high response rate to event processor problems was required.
We tried to replace Redis and use Kafka instead, but the Kafka driver for ClickHouse at the time had issues with arrays (which has since been fixed).
Therefore, we implemented our event queue, which was stored on the disk of each EventHandler component, and the local EventsProcessor was located on the same server. The number of EventsProcessor components has increased, which means that the number of insert requests in ClickHouse has also increased, but this was not a problem.
Since financial optimization was also an essential factor for us, this scheme proved to be excellent in this regard as well. To receive processing and storage of data from ADX, we assembled a cluster with 15 servers (40 threads, 128 RAM, SSD storage), and we also took this with a margin. For the storage cluster for unique users, we used a cluster with 6 of the same servers.
An important point was also the work with receiving data from clusters. If you recklessly send a request to the cluster, this could create a pretty significant load on it, leading to the slowdown of other processes. But ClickHouse has settings for limiting resources and allocating quotas for specific users, which allowed us to solve this case quickly. All configuration files can be perfectly placed in the configuration management system and managed from there.
ClickHouse Handles Over 1 Billion Unique Users Per Day
In addition to statistics aggregation, which summed up metrics by dimension, Admixer provides information on how many unique users have watched ads for an arbitrary time. The number of uniques cannot be summed up. In our system, the user ID is the UUID. When we want to get several unique UUIDs for some arbitrary period, we need to recalculate the unique UUIDs for this period each time. We cannot decompose all possible combinations in advance since the intersection will be too large.
Before using ClickHouse, we could count uniques only for predefined periods: day, week, month, all the time. Also, the number of slices was limited. Also, constant bulk requests for Aerospike slowed down the event processor.
AggregatingMergeTree allowed us with minimal costs to count unique users by a large number of keys in one report. In the beginning, with a cluster from three servers, we could easily count 1 billion uniques per day in ~ 12 slices. There are nuances; large slices cannot be output to the interface since simultaneous scanning of large tables will take a lot of CPU time. The solution to this problem was the report generation service, which has its internal queue and sends the already generated CSV files to the interface. On the other hand, we can output small slices to the interface with a limited date range.
ClickHouse was perfect as Big Data Storage for our ML models.
Advice To Others Who Might Be Considering ClickHouse
The Devil is in the details!
ClickHouse technical tips:
- If you do not need high data accuracy, use HyperLogLog and sampling;
- Run load tests to determine the number of operations that your cluster can withstand given your data structure before assembling the cluster;
- Buffer is a great way to insert data, but watch out for memory;
- Use Native format for insert;
- Avoid large numbers of small parts for continuous flow insertion. Too many tables generate a lot of merges in the background such as the Too many parts (300) error;
- It is necessary to decide on the replication scheme at the beginning. One option is to use ZooKeeper and let tables replicate themselves using ReplicatedMergeTree and other replicating table engines. Because we had many tables and we wanted to choose what parts of the data to replicate to which servers we chose to not use ZooKeeper and have our client spread the writes – each write goes to two servers.
Over the past five years, the Admixer’s Core team has been working with a high-load and aggregation of big data. Any work has its subtleties, do not step on your rake. Use ours.
We offer customers specialized audit, consultation, or create ready-made solutions using ClickHouse to solve high-load tasks. These speciality services are now offered via our new initiative LoadFighters.
About Admixer
Admixer is an independent adtech company that develops an ecosystem of full-stack programmatic solutions. Admixer has its own line of adtech products for brands, ad agencies, media houses, publishers, ad networks, and other buy- and sell-side industry players looking for effective ad management. Our customizable technology, in-depth expertise, and a personal approach help businesses turn programmatic advertising into a scalable revenue channel.
Since their start in 2008, we’ve been on a mission to build an ecosystem with effective and transparent relationships between all of the players in the digital advertising industry.
Today, the company has over 100 supply and demand partners, 3,000+ customers, and 200+ employees worldwide. They run offices in Ukraine, Belarus, Kazakhstan, Moldova, Georgia, and legal entities in the UK and Germany.
For more information please visit:


