Welcome to the July ClickHouse newsletter, which will round up what’s happened in real-time data warehouses over the last month.
This month, we have optimal table sorting in the 24.6 release, tracking vessels with ClickHouse & Grafana, and tactics for optimizing CPU usage when running ClickHouse.
Inside this issue
- Featured community member
- Upcoming events
- 24.6 release
- How to track vessels with Python, ClickHouse, and Grafana
- ClickHouse MergeTree Engine
- Optimizing ClickHouse: The Tactics that worked for highlight.io
- ClickHouse Cloud updates: July 2024
- Video corner: Import patterns
- Post of the month
Featured community member
This month's featured community member is taiyang-li (李扬)

taiyang-li is a frequent contributor to the ClickHouse database, regularly contributing pull requests that improve ClickHouse’s performance and string processing capabilities. In just the last few months, he’s committed code that let the -UTF8 functions handle strings containing only ASCII characters, fixed concat to accept empty arguments, and improved the compatibility of the upper/lowerUTF8 functions. And if you’ve noticed that the splitByRegexp, coalesce, or ifNotNull functions are quicker, you can also thank taiyang-li for that!
Upcoming events
- ClickHouse Fundamentals - July 24th & 25th
- ClickHouse Community Call - July 30th
- Migrating from Postgres to ClickHouse Workshop - July 31st
- BigQuery to ClickHouse Workshop - August 7th
- ClickHouse Fundamentals - August 13th & 14th
- ClickHouse Admin Workshop - August 21st
24.6 release

The latest release of ClickHouse saw the introduction of optimal table sorting. We can use this setting on table creation, and when ingesting data, after sorting by ORDER BY key, ClickHouse will automatically sort data to achieve the best compression. We also had a beta release of chDB that lets you query Pandas DataFrames directly, and functions for Hilbert Curves were added.
How to track vessels with Python, ClickHouse, and Grafana

Ignacio Van Droogenbroeck has written a cool blog post on tracking vessels in San Francisco and Buenos Aires. He shows how to get the data from AisStream’s WebSockets API into ClickHouse and then creates a series of visualizations using Grafana.
ClickHouse MergeTree Engine
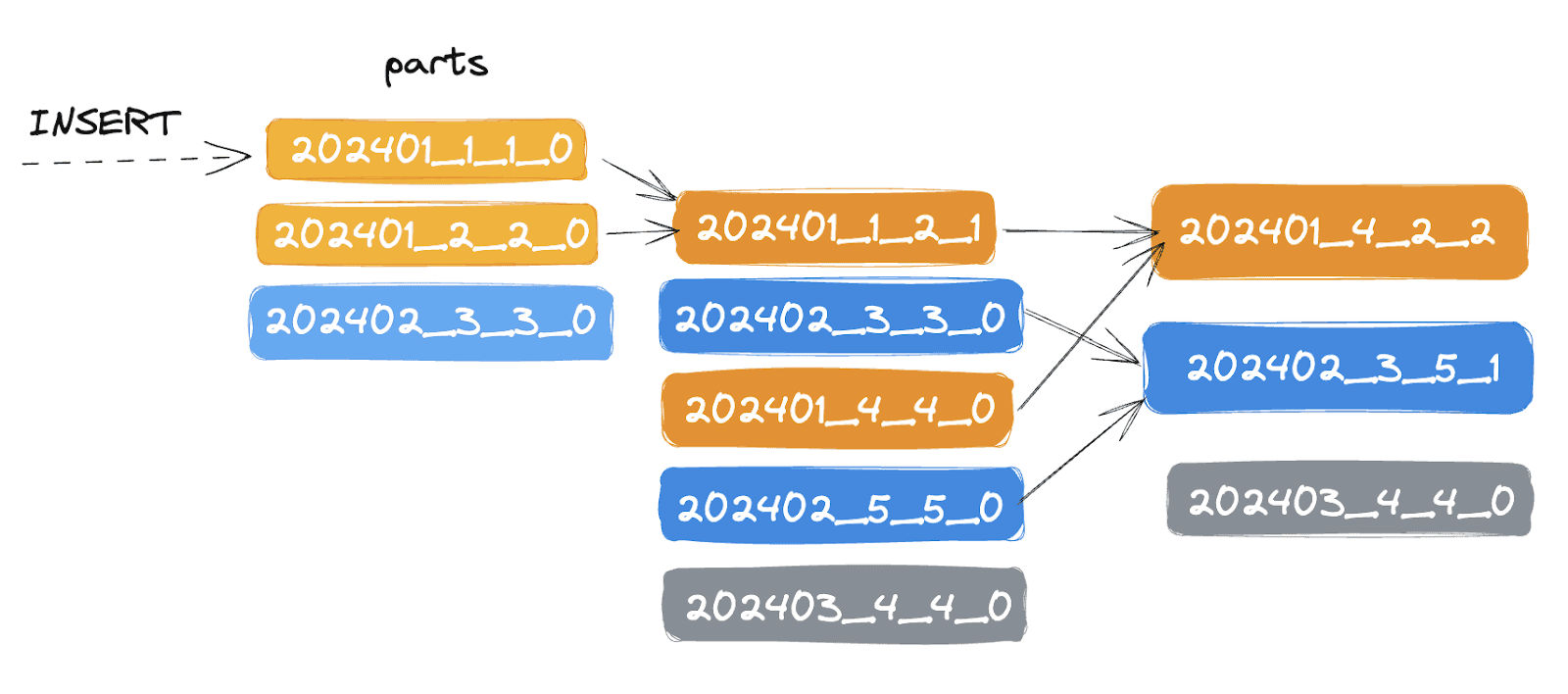
Tôi là Duyệt has started writing blog posts about using ClickHouse in Kubernetes. A recent post explores the default MergeTree table engine. Tôi explains what happens when data is ingested into a table using this engine. He then goes through how to use it, including inserting data, supported data types, and column modifiers.
Optimizing ClickHouse: Tactics that worked for highlight.io
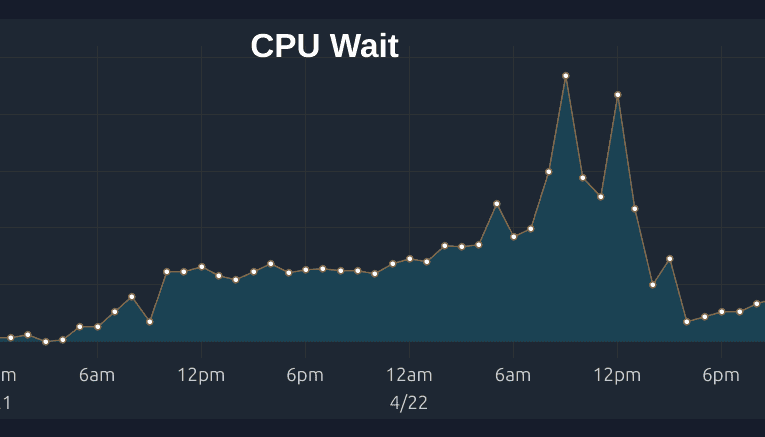
highlight.io is an open-source, full-stack Monitoring Platform. It ingests 100 TB of observability per month, much of which goes into ClickHouse. CTO Vadim Korolik has written a blog post sharing their lessons on optimizing ClickHouse to reduce CPU load.
ClickHouse Cloud updates: July 2024

Did you know that we publish a ClickHouse Cloud Changelog every fortnight? In the latest version, we announced the availability of ClickHouse Cloud on Microsoft Azure and a new Query Logs Insights UI to make it easier to debug your queries. The Prometheus endpoints for metrics is also in Private Preview.
Video corner: Import patterns
Mark Needham has recorded several videos demonstrating import patterns with ClickHouse:
- Deriving columns from other columns shows how to use the DEFAULT, ALIAS, and MATERIALIZED column modifiers
- Next, we learn about the EPHEMERAL column modifier, which is used when we don’t want to store a column but rather have that column referenced by the other column modifiers.
- Finally, we use the Null Table Engine to route incoming data to different destination tables based on filtering criteria.
Post of the month
Our favorite post this month was by anhtho, who’s using ClickHouse to analyze billing data.