In early 2020, Kami was growing steadily. The New Zealand-based edtech company provided schools with a suite of digital annotation and collaboration tools. Their Postgres-based event tracking system worked “well enough,” says co-founder and CTO Jordan Thoms, giving them insights into feature engagement and user behavior in classrooms around the world.
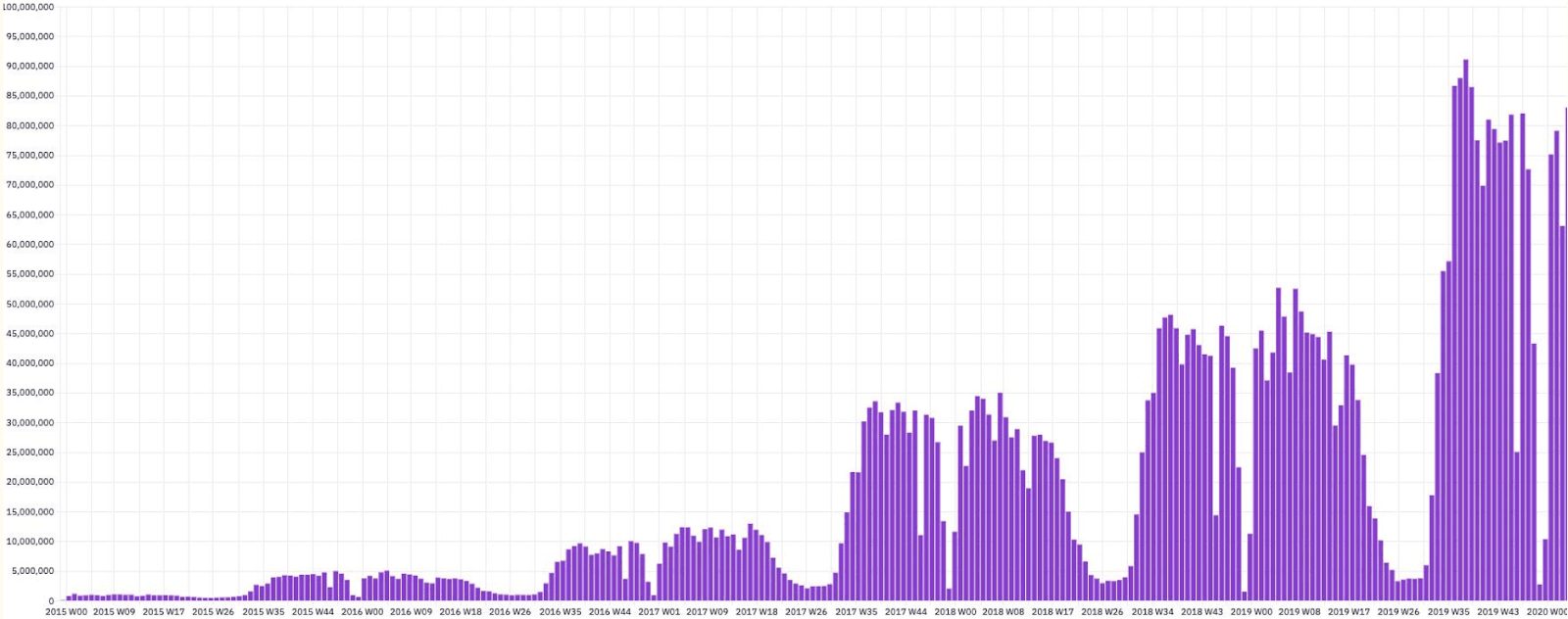
Kami’s weekly event volume grew steadily from 2015 to 2019
Then, in March 2020, everything changed. The COVID-19 pandemic forced schools online overnight, turning Kami into an essential tool for remote learning. Weekly event volume skyrocketed from around 80 million to nearly 2 billion—a 23x increase. Postgres, already struggling (but at least functional), became a major bottleneck. Queries took so long to run that data became practically unusable. “Absolutely everything broke,” Jordan says.
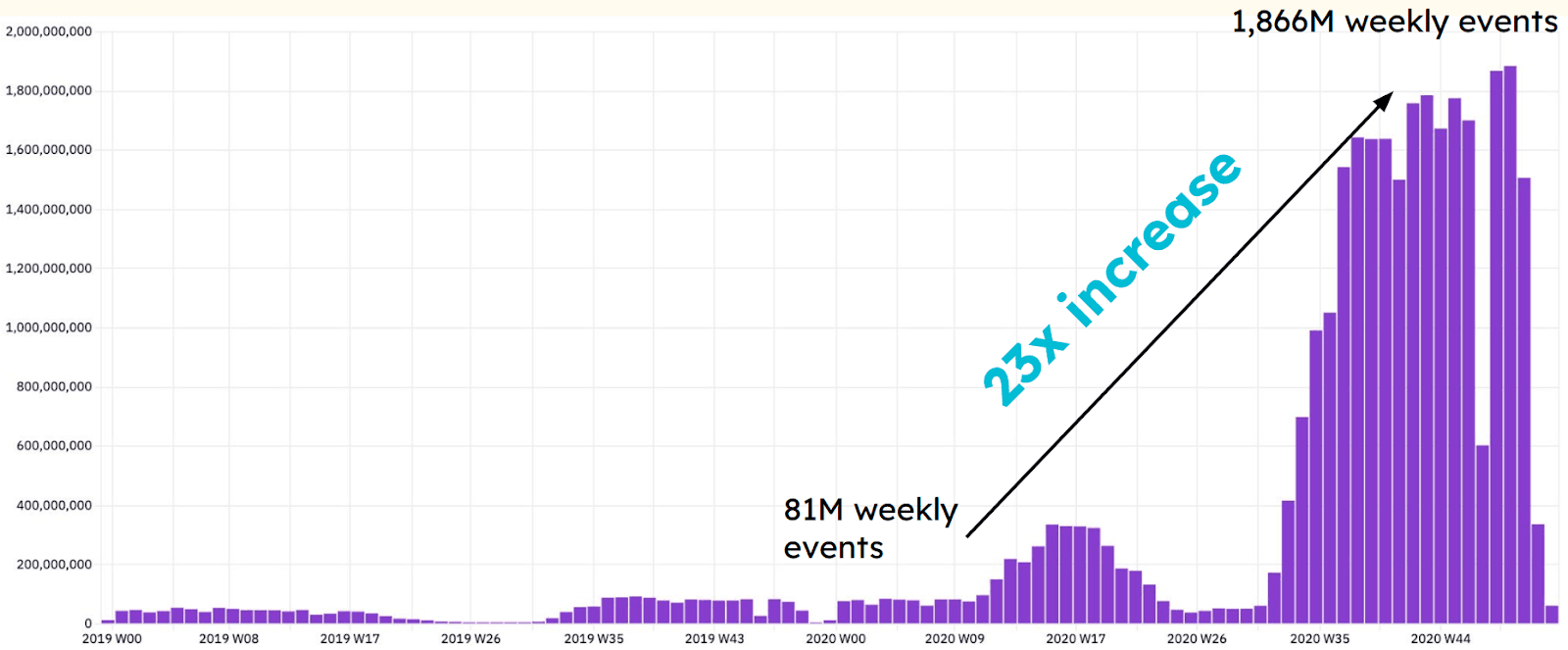
Kami’s weekly event volume surged by 23x from 2019 to 2020
At a February 2025 ClickHouse meetup in Auckland, Jordan and Head of Data Chuan-Zheng Lee shared the story of Kami’s data journey—from Postgres’s breaking point to their ClickHouse migration and the scalability and performance gains that followed.
Postgres hits its limits #
In 2014, Kami decided to bring event tracking in-house, replacing third-party solutions like Google Analytics and Mixpanel. “We wanted more ownership and control over our data,” Jordan says. “For us, that meant the freedom and flexibility to run the queries we needed. It also meant more control over costs, which became a bigger factor as we scaled.”
Kami’s original Postgres-based data architecture
At the time, the company was small—Jordan was one of just two engineers—so the initial system was designed to be as simple as possible. Events were sent from the frontend to their Rails backend, where they were written directly into Postgres. The schema was straightforward: an event table with a JSONB column for storing arbitrary event metadata. To analyze their data, they used Redash to write SQL queries against Postgres.
This lightweight architecture worked well at first, but as event volumes grew, queries became slower, and Postgres began struggling under the load. To combat this, the team made a series of incremental improvements, adding read replicas to separate analytics queries from production workloads, introducing a message queue to buffer incoming events, and experimenting with SSD and NVMe storage to improve query performance.

Kami’s Postgres-based data architecture with optimizations
While these optimizations bought them time, Jordan and the team recognized that they were pushing Postgres beyond the limits of its transactional design. “We managed to hack it and keep it working for a while, but it was clear we were pushing Postgres outside the wheelhouse of what it’s really good at,” Jordan says.
Kami’s data architecture finally hit its breaking point in 2020 during the COVID-19 pandemic. As the shift to remote learning drove usage 5, 10, 20 times higher than anything Kami had seen before, Postgres could no longer keep up. While ingestion continued, queries became painfully slow, rendering analytics dashboards nearly useless.
“Our events database was good enough to collect the events, but analyzing that data was almost impossible because any query would take far too long to run with the kind of volumes of data we were collecting,” Jordan says. “Clearly we needed a different solution.”
Solving for scale #
In late 2020, Jordan and the team set out to find a data architecture that could handle massive data volumes and support Kami’s continued growth. They explored several options for scaling their existing Postgres-based system, including Citus, a Postgres extension designed for distributed workloads. But after testing, Jordan says, “None of them could deliver the performance we needed to handle the enormous data volumes we were getting.”
Specifically, they needed a system that could ingest millions of events per second while still delivering fast, complex queries across billions of rows. After years of wrestling with Postgres under read-heavy workloads, they knew they needed something built for high-speed aggregations and analytical queries, not just transactional processing.
Open-source flexibility was also important—they wanted a system they could run locally for development and testing, rather than relying on a proprietary cloud-only solution. As Jordan explains, “We want developers who are running the code locally to have the full system, including the data warehouse, so they can verify that data flows correctly and integrates properly with the parts of the system that are querying it.”
ClickHouse checked all the boxes. Its columnar storage model enabled efficient compression and lightning-fast queries, even on massive datasets. Its high ingestion speed meant Kami could process real-time event data without overwhelming their infrastructure. Just as important, it was open-source, giving the team the freedom to experiment, iterate, and fine-tune performance without vendor lock-in.
“After testing multiple options, we decided ClickHouse was the best solution for our needs and really the only one that could handle our scale,” Jordan says.
Migrating to ClickHouse #
With their decision made, the next challenge was migration. Kami’s existing event data was stored in Postgres as JSONB, allowing for flexible, freeform event tracking. But ClickHouse’s columnar model required a structured schema, meaning they couldn’t simply move data as-is. To bridge this gap, Jordan and the team built a custom Java-based Kafka consumer that extracted raw event data, transformed JSON into structured columns, resolved inconsistencies, and wrote the results into ClickHouse. The migration also gave them a chance to clean up years’ worth of “bad, weird data” that had accumulated in the system, Jordan says.
Migrating historical data presented its own set of challenges. “We could have used PeerDB, but it didn’t exist yet,” Jordan says with a laugh. Instead, they experimented with Debezium and other change data capture (CDC) tools, but “none of them could even remotely handle the volume of data we were talking about.” Ultimately, they built a manual extraction and backfill process, pulling years of event logs from Postgres and streaming them into ClickHouse. Keeping historical data in Kafka also gave them the flexibility to reprocess events efficiently whenever schema changes were needed.
Kami’s first ClickHouse-based data architecture
With their new Kafka-to-ClickHouse pipeline, Kami finally had the analytical power they had envisioned since first bringing event tracking in-house back in 2014. But the true impact of the switch would only become clear once they put the new system to work.
A new events architecture #
ClickHouse’s impact was immediate. Even at massive volumes, it delivered the performance Kami needed without extensive pre-aggregations. “We didn’t think that hard about doing pre-aggregations at first—we just rested on ClickHouse’s speed for a while,” Chuan-Zheng explains. Queries that once required pre-aggregated rollup tables in Postgres could now be executed directly on 140 billion+ rows, returning results in a few minutes instead of hours.
With query speed no longer a bottleneck, Kami has since focused on bringing in more contextual data for deeper insights. “Having users’ data is great,” Chuan-Zheng says, “but to get the insights we really need in order to understand our business, we had to join this to other things.” They’ve integrated data from their CRM, production databases, and school district records, giving them visibility into not just how users interact with the product, but also how engagement varies across schools, states, countries, user plans, and user segments.
As their data architecture expands, the Kami team has continued optimizing ingestion and syncing processes. While they currently use ClickHouse’s MaterializedPostgreSQL engine to sync data from Postgres, they plan to migrate to PeerDB for better scalability and reliability. For CRM data stored in CockroachDB, they use ClickHouse’s Kafka integration, allowing them to ingest change data in real time without added complexity.
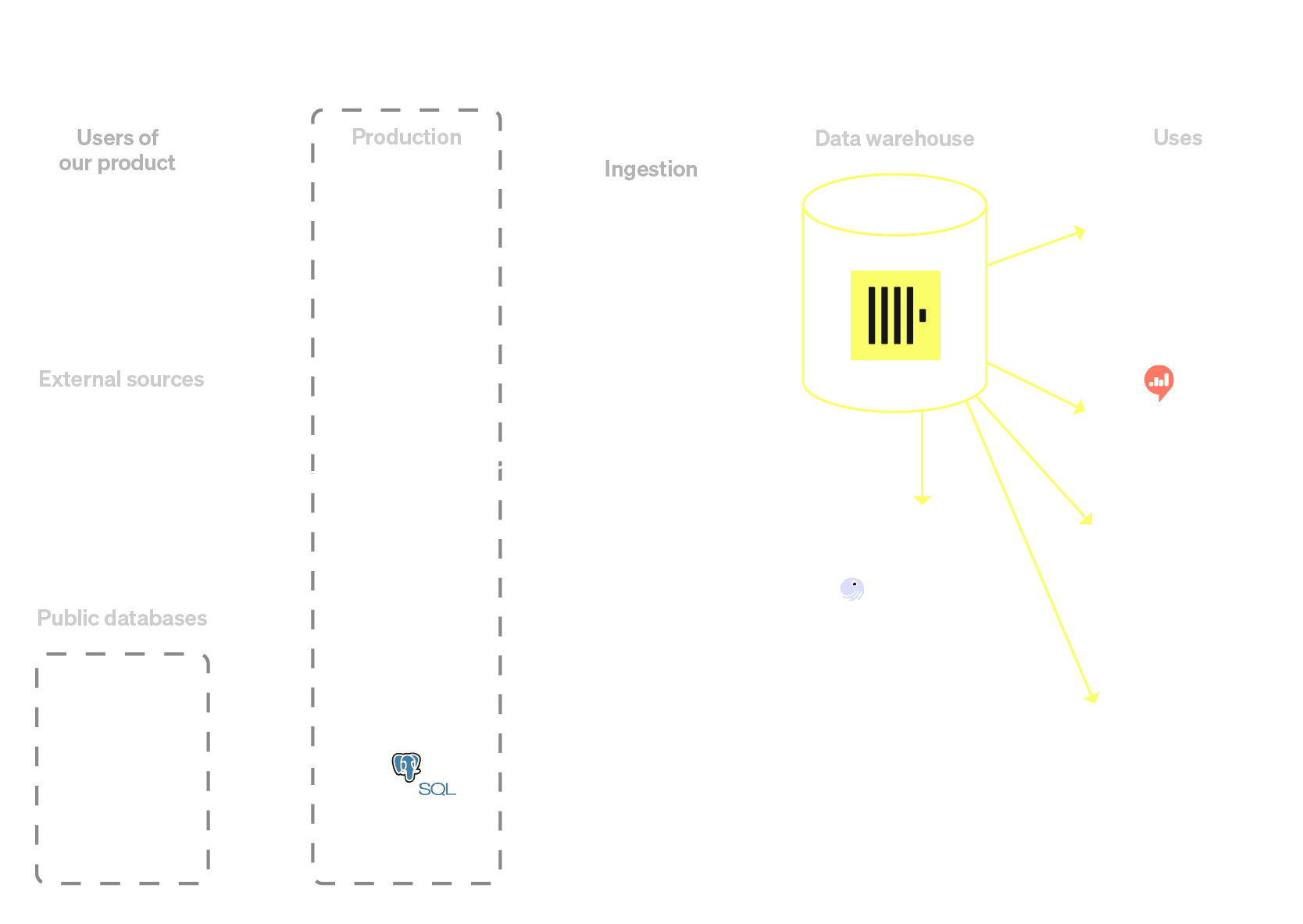
Kami’s current ClickHouse-based data architecture
To further improve performance, Kami recently introduced dbt-powered aggregations, storing one row per user per day instead of querying raw event data. This has “massively accelerated” Daily and Weekly Active User (DAU, WAU) queries, cutting DAU query execution time from 3-4 minutes on 140 billion rows to just 1 second on 1.3 billion rows.
Of course, scaling any platform comes with challenges. As Kami’s team grows, so does the need for data governance and clear metric definitions. Even seemingly simple classifications, such as distinguishing between students and teachers, have proven more complex than expected. “It turns out students don’t always tell the truth,” Chuan-Zheng jokes. Ensuring data literacy across the company is becoming a bigger priority. But Chuan-Zheng sees this as a positive shift. “This is the sign of a growing company,” he says. “So it’s a nice problem to have.”
Scaling for the future #
With the migration to ClickHouse, what started as a COVID-driven emergency has become a foundation for long-term growth. Kami’s new system, built to handle billions of events and run complex queries in seconds, has shifted their focus from keeping up with demand to unlocking deeper insights. And thanks to ClickHouse’s flexibility, they can keep refining ingestion, aggregation, and query performance as their data needs evolve.
Looking ahead, the team is set on scaling even further. Moving to PeerDB will improve reliability, and ongoing optimizations to their transformation pipeline will make things even more efficient. As Kami expands its product offerings and user base, their ClickHouse-powered data stack ensures they can support that growth. Most importantly, Kami is equipped to continue serving classrooms worldwide, helping deliver a seamless, data-driven learning experience to the millions of teachers and students who rely on their platform every day.
To see what ClickHouse can do for the performance and scalability of your team’s data operations, try ClickHouse Cloud free for 30 days.



