We’d like to welcome Christian Petrasch, Product Owner of Data Science and Robin Gontermann, Business Data Analyst at DENIC as guests to our blog. Read on to find out why DENIC chose ClickHouse to power their data science platform allowing them to analyze data from a wide range of sources.
DENIC eG (Deutsches Network Information Center) administers and operates .de, the German namespace on the Internet. With a portfolio of over 17.2 million domains, it is one of the world’s largest registries of top-level domains. DENIC operates on a non-profit basis and provides services that support fast, secure and reliable access to websites and web services under the .de top-level domain. DENIC operates, among other things, a globally distributed name server network and is responsible for registry management with a domain database, registration system and information services for .de domains.
In order to continuously improve the user experience of the internet community, DENIC is increasingly focussed on data analytics. The data science team created a special data analytics cluster, which is able to combine and analyze data from a wide range of information sources.
Background
The data relevant for our analytics is currently distributed among relational databases, server log data and various other sources. These sources are already used for monitoring and system improvements. The analytical features of these tools are limited and cross-evaluations across a wide range of sources is costly or not feasible at all, as they often have to be carried out and evaluated manually.
During the first steps of developing the data science platform, a database based on a relational DBMS was used. The data from different data sources was consolidated by Python agents in containers on Kubernetes and the results were written to target tables in the database, which served as a source for dashboards in Grafana.
This approach resulted in a considerable number of target tables and containers, which on the one hand were difficult to administer and on the other hand also became somewhat overcomplicated.
Relational databases are also only suitable for larger amounts of data to a limited extent, as the processing time of a query can take several minutes to hours. This is clearly too long for dashboards and also puts a strain on the registration database in a way that could lead to restrictions in production.
After Testing Hadoop and Spark, We Chose ClickHouse
Since the data science platform was still in its early stages at DENIC and the team was small with only three people at that time, the administrative effort had to be considered as well as the performance of the solution. Initial tests with file-based databases such as Hadoop and distributed data processing systems such as Spark showed solid performance, but too much administrative effort. A cloud solution provides less administrative effort, but can’t be considered because of data privacy protection.
Therefore, a new platform had to be created that is efficient, generates little administrative effort and at the same time is cost-effective to operate.
Internet research showed that column-oriented databases could be successful. These types of databases are made for fast queries over large amounts of data, which seemed very promising for our purposes. Through several case studies and presentations at conferences, the data science team became aware of ClickHouse.
Initial tests and a PoC showed that ClickHouse met DENIC’ s requirements very well in cluster operation and only requires a small server footprint, which makes it cost-effective.
The setup for Datascience@DENIC is as follows:
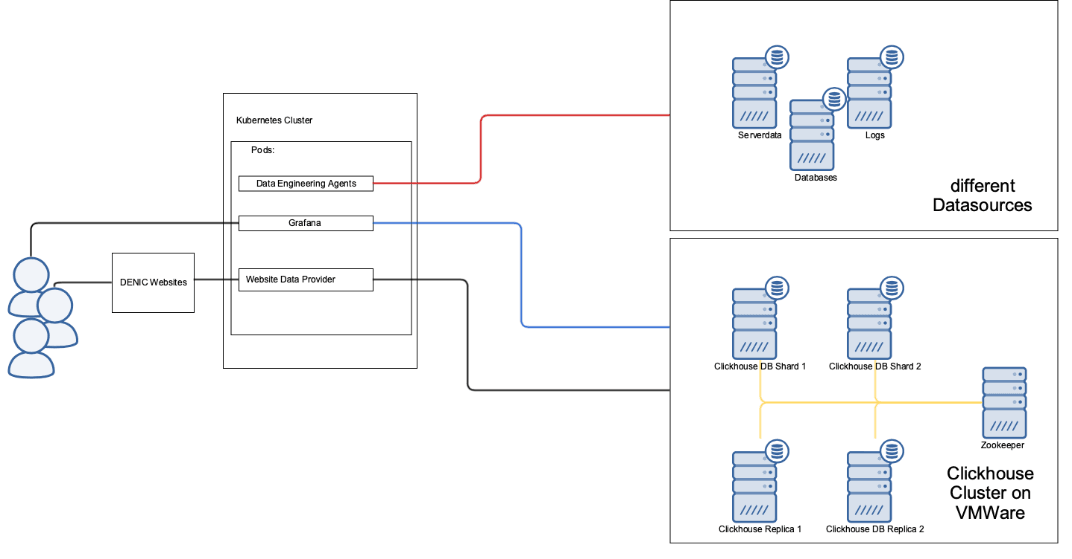
One Of Our Use Cases and Challenges
One of our use cases is the design of a ClickHouse table, that is fed with several entities of DENIC’s registry database. The data (<1,000,000 entries/day) is provided by a REST interface of the registry database as time-series events and fetched, processed and written to the ClickHouse cluster by a Python agent on a daily basis.
Based on the data structure of the registry database, for example, domain and associated holder data are provided separately by the REST interface. However, in order to make better use of the advantages of the ClickHouse cluster, the domain and holder information is written denormalised in a table. Each domain has up to 5 holders and any number of domains belong to one holder. Since domain-related information of an event is to be mapped in a row, the associated holder information must be stored in arrays. A new line entry for the domain is only written if the domain or its holder attributes change.
This means that each domain has its own individual timestamps and thus forms its own time series. In contrast to common time series problems with few different time series but many timestamps, DENIC’s time series modeling is as follows:
A large number of different domains (>20,000,000), each with relatively few timestamps (<1000). Overall, the data structure of the table in the Cickhouse Cluster is as follows:
CREATE TABLE IF NOT EXISTS database.domain_table ON CLUSTER ds_cluster
(
domain String,
reg_acc_id Nullable(Int32),
previous_reg_acc_id Nullable(Int32),
contact_code Array(String),
denic_code Array(String),
holder_country_code Array(String),
holder_city Array(String),
holder_address Array(String),
holder_postal_code Array(String),
holder_name Array(String),
holder_person_type Array(String),
holder_person_type_was_incorrect Array(UInt8),
holder_company_type Array(String),
addresscheck_correction_code Array(String),
addresscheck_address Array(String),
addresscheck_postal_code Array(String),
addresscheck_city Array(String),
domain_ace String,
domain_category Array(String),
is_idn_domain UInt8,
is_locked UInt8,
is_vchecked UInt8,
verified_by Int32,
registration_status LowCardinality(String),
event LowCardinality(String),
business_operation Array(String),
rr_dnskey_algorithm Array(Int16),
rr_dnskey_flags Array(Int16),
rr_dnskey_protocol Array(Int16),
rr_mx_owner Array(String),
rr_mx_dname Array(String),
rr_mx_preference Array(Int16),
rr_a_owner Array(String),
rr_a_address Array(String),
rr_aaaa_owner Array(String),
rr_aaaa_address Array(String),
rr_ns_dname Array(String),
rr_ns_address Array(String),
rr_ns_ip_type Array(Int16),
timestamp DateTime64(6,'Europe/Berlin')
)
ENGINE ReplicatedMergeTree('/ch/database/tables/{layer}-{shard}/event_data', '{replica}')
PARTITION BY substring(domain, 1, 1)
ORDER BY (domain, timestamp);
In order to create this data structure, the Python agent must link the two entities, domains and holders. In the event that holder information changes, the respective valid domain states must be selected from the ClickHouse cluster and be written to the database as new entries with the updated holder information. This query is time-consuming and takes up a large part of the total runtime of the agent.
SELECT *
FROM database.domain_table_distributed
WHERE hasAny(denic_code, ['id1','id2',...]) AND ((domain, timestamp) GLOBAL IN (
SELECT
domain,
max(timestamp)
FROM database.domain_table_distributed
GROUP BY domain
))
The ‘id1’,… in the hasAny filter cover the ids of the holders updated on that day. Up to several thousand holders are updated per day.
In order not to place such a heavy load on the registry database, the initial filling of the ClickHouse cluster had to be carried out as a day-by-day migration.
Learning The Hard Way
After saving several million data records, first noticeable problems occurred. The processing of the data delivered by the REST interface became noticeably slower. The query for selecting the domain states associated with holder updates took about 5 minutes. After investigating that behavior, it became clear that this would take longer and longer as the amount of data increased, making it unsustainable for the future.
The search for countermeasures led us to various options such as materialized views with the use of different ClickHouse engines to support our use case. This learning curve was quite steep and difficult as materialized views have some idiosyncrasies that need to be considered and ultimately led to us discarding this option.
The idea arose to create a materialized view on which the query increases performance.
For the first test, a materialized view was created with the AggregatedMergeTree engine, combined with argMax on the required columns. A first test on a reduced number of columns led to a significant performance increase (2x).
CREATE MATERIALIZED VIEW database.aggregated_mv_test on cluster ds_cluster
ENGINE = ReplicatedAggregatingMergeTree('/ch/database/tables/{layer}-{shard}/aggregated_mv_test', '{replica}')
PARTITION BY substring(domain, 1, 1)
ORDER BY (domain)
POPULATE
AS
SELECT
argMaxState(reg_acc_id, toFloat64(timestamp)) as reg_acc_id,
argMaxState(contact_code,toFloat64(timestamp)) as contact_code,
argMaxState(denic_code,toFloat64(timestamp)) as denic_code,
argMaxState(holder_country_code,toFloat64(timestamp)) as holder_country_code,
domain,
argMaxState(domain_ace,toFloat64(timestamp)) as domain_ace,
maxState(toFloat64(timestamp)) as latest_timestamp
from
database.domain_table
group by domain;
However, a test with all the required columns required too many resources. Even 128 GB RAM was not enough, so the option was discarded.
For the second attempt, the ReplicatedReplacingMergeTree engine was used. This sorts by domain and versions by timestamp. Older, identical versions of the data records, i.e. not current domain entries, are automatically deleted by the engine. This results in a materialized view that for the most part only contains current data. Since the deletion process runs asynchronously in the background, the state determination in the query is still needed. In addition, it was important to ensure that the data was no longer distributed randomly by the Distributed table engine, but that the same domains were stored on the same shard because the replacing process only works on the same shard. The result was a similarly good performance increase (2x) due to the significantly reduced number of entries. In addition, much fewer resources are used overall.
Finally, we came to the conclusion that we use a normal table with the ReplicatedReplacingMergeTree engine, which is maintained with inserts. This is also sorted by domain and versioned by timestamp. Older, time series entries of the same domain are sorted out. If an error occurs when importing the data, the Python agent deletes the incorrectly inserted daily data and restarts the integration process for that day.
This resulted in an improvement of the query runtime from 5 to 3 minutes.
Already a good improvement, but still very long by ClickHouse standards, despite the complicated query. Nevertheless, the increase in query runtimes with continuous filling became much flatter than before.
A Helpful Hand Raised From Somewhere
We got in touch with ClickHouse directly via LinkedIn, as they are interested in various use cases. This is how we got in touch with ClickHouse support, with whom we were able to narrow down the expensive part of the query.
Especially the subquery in combination with the GLOBAL IN was very time-consuming, as they scan the entire table without a filter.
ClickHouse’s idea was then to filter out complete time series instead of individual time series events in the subquery and to select only those that had a holder affected by the update at least once. In addition, instead of using max(timestamp), further query time could be saved by using LIMIT 1 BY domain.
WITH current_domains AS
(
SELECT *
FROM database.current_domain_table_distributed
WHERE domain GLOBAL IN (
SELECT DISTINCT domain
FROM database.current_domain_table_distributed
WHERE hasAny(denic_code, [id1,...])
)
ORDER BY
domain ASC,
timestamp DESC
LIMIT 1 BY domain
)
SELECT *
FROM current_domains
WHERE hasAny(denic_code, [id1,...])
The runtime was significantly improved to about 1 minute.
In further processing, it was identified that the built-in domain filter now has been responsible for the query runtime. The array filter of denic_code, in particular, contributes to this. We were finally able to solve this together with an ARRAY JOIN, so that a more effective IN operation could be used instead of hasAny.
ARRAY JOIN, so that a more effective IN operation could be used instead of hasAny.
WITH current_domains AS
(
SELECT *
FROM database.current_domain_table_distributed
WHERE domain GLOBAL IN (
SELECT DISTINCT domain
FROM database.current_domain_table_distributed
ARRAY JOIN denic_code as id
WHERE id in [id1,... ]
)
ORDER BY
domain ASC,
timestamp DESC
LIMIT 1 BY domain
)
SELECT *
FROM current_domains
WHERE hasAny(denic_code, [id1,...])
In summary, the query runtime was optimized from 5 minutes to about 30 seconds. Even with several hundred million data records imported and many thousands of holder updates per day, this level could be maintained similarly well.
Final Words
ClickHouse and its performance, even in small clusters, provide DENIC with extensive support in the development of a data science platform, which will also be sustainable in the future due to its expandability. We would like to take this opportunity to thank ClickHouse and its support for their excellent assistance.