Introduction
After a long time in the making, ClickHouse v23.1 shipped a highly anticipated feature - experimental support for inverted indexes. In this blog post, we will not only explore why the community is so excited about inverted indexes but also discuss in detail how inverted indexes work in ClickHouse. A big "thank you!" to IBM, who developed and contributed the code for inverted indexes over the course of the last six months.
Inverted Indices
Inverted indexes were invented decades ago, but it's only because of search engines like Google that most people interact with inverted indexes multiple times a day - usually without knowing it. An inverted index is the central data structure that enables fast and powerful searching in vast collections of text documents. The idea underlying inverted indexes is to compile a database of terms with pointers to the documents which contain these terms.
Let's look at a small example with four documents to better understand how inverted indexes work.
CREATE TABLE docs
(
`key` UInt64,
`doc` String
)
ENGINE = MergeTree()
ORDER BY key;
INSERT INTO docs VALUES
(0, 'Sail against the wind'),
(1, 'Wait and see'),
(2, 'Sail the seven seas'),
(3, 'See how the wind blows');To find all documents which contain the term "wind" we could write the following SQL query:
SELECT *
FROM docs
WHERE doc LIKE '%wind%';
┌─key─┬─doc────────────────────┐
│ 0 │ Sail against the wind │
│ 3 │ See how the wind blows │
└─────┴────────────────────────┘
2 rows in set. Elapsed: 0.006 sec.As expected, this query returns the first and the last document. However, it quickly becomes expensive: we need to check whether each row of column "doc" matches the search term. This means that the runtime of the search grows proportionally with the table size. To avoid that, we create an inverted index on column doc. Since the inverted index is still in an experimental state, we first need to enable it. This step will become obsolete once inverted indexes become GA.
SET allow_experimental_inverted_index = true;
ALTER TABLE docs ADD INDEX inv_idx(doc) TYPE inverted;
ALTER TABLE docs MATERIALIZE INDEX inv_idx;When creating the index, ClickHouse splits each document in the "docs" column into a list of terms. By default, splitting is done along whitespaces, but it is also possible to tokenize the text into n-grams. The resulting index will conceptually look like this:
| Dictionary (Terms) | Posting Lists |
|---|---|
| and | 1 |
| against | 0 |
| blows | 3 |
| how | 3 |
| Sail | 0, 2 |
| See | 3 |
| see | 1 |
| seas | 1 |
| seven | 2 |
| the | 0, 2, 3 |
| Wait | 1 |
| wind | 0, 3 |
As we can see, the inverted index associates each term with "postings", i.e., the row positions of the documents which contain the corresponding term.
The dictionary in inverted indexes is usually organized in a way that terms can be found quickly. The simplest method to achieve that is to store the terms in alphabetical sort order and to use binary search for lookups. In contrast to that, ClickHouse stores dictionaries as finite state transducers (FSTs). We will discuss FSTs in more detail below. Their main advantage is that redundancies, e.g., shared prefixes between adjacent terms, can be easily removed. This reduces the memory footprint of the dictionary and improves the overall throughput.
Further interesting extensions of dictionaries that are currently not supported but might be added in the future include the following:
- a removal of stop words that carry no semantic weight like "a", "and", "the" etc., and
- lemmatization and stemming as language-specific techniques to reduce words to their linguistic word root, e.g., "walking" becomes "walk", "went" becomes "go", "driving" becomes "drive" etc.
ClickHouse also stores the posting lists in a compressed format (more specifically as "roaring bitmap") with the goal of reducing their memory consumption. We will dig a bit deeper into posting list compression below. In the initial inverted index version, posting lists refer to the row positions of the documents which contain the corresponding term. This might be extended in the future with additional metadata, for example:
- A document frequency count stored with each posting indicating how often the term occurs in the document. Such information will allow us to calculate the term frequency / inverse document frequency (TF-IDF), which is useful for ranking search results.
- Word-level postings, i.e., the exact positions of terms inside documents. Such data allows to answer phrase queries where the user does not search for a single term but for multiple consecutive terms (a "phrase").
If we rerun our query, it will automatically use the index:
SELECT * from docs WHERE doc LIKE '%wind%';
┌─key─┬─doc────────────────────┐
│ 0 │ Sail against the wind │
│ 3 │ See how the wind blows │
└─────┴────────────────────────┘
2 rows in set. Elapsed: 0.007 sec.We can use EXPLAIN indexes = 1 to verify that the index was used:
EXPLAIN indexes = 1
SELECT * from docs WHERE doc LIKE '%wind%';
┌─explain─────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ ReadFromMergeTree (default.docs) │
│ Indexes: │
│ PrimaryKey │
│ Condition: true │
│ Parts: 1/1 │
│ Granules: 1/1 │
│ Skip │
│ Name: inv_idx │
│ Description: inverted GRANULARITY 1 │
│ Parts: 1/1 │
│ Granules: 1/1 │
└─────────────────────────────────────────────┘
12 rows in set. Elapsed: 0.006 sec.Posting Lists
Let's first discuss how posting lists are stored. As you can see in the example above, the postings within a posting list are monotonically increasing. Furthermore, the terms in real-world data are typically distributed in a highly skewed manner. This means that most terms normally occur in only a few documents, whereas a few terms occur in many documents. Traditional implementations of inverted indexes exploit both properties by compressing their posting lists with a combination of delta encoding and Golomb (or Golomb-Rice) encoding. Such compression accomplishes a very high compression rate, but compression and decompression become rather slow.
Modern posting list compression formats are able to strike a better balance between compression/decompression performance and compression rate. Inverted indexes in ClickHouse utilize the state-of-the-art roaring bitmaps format to compress the posting lists. The main idea of this format is to represent the postings as a bitmap (e.g. [3, 4, 7] becomes [00011001]), which are then divided into chunks and stored in specialized containers.
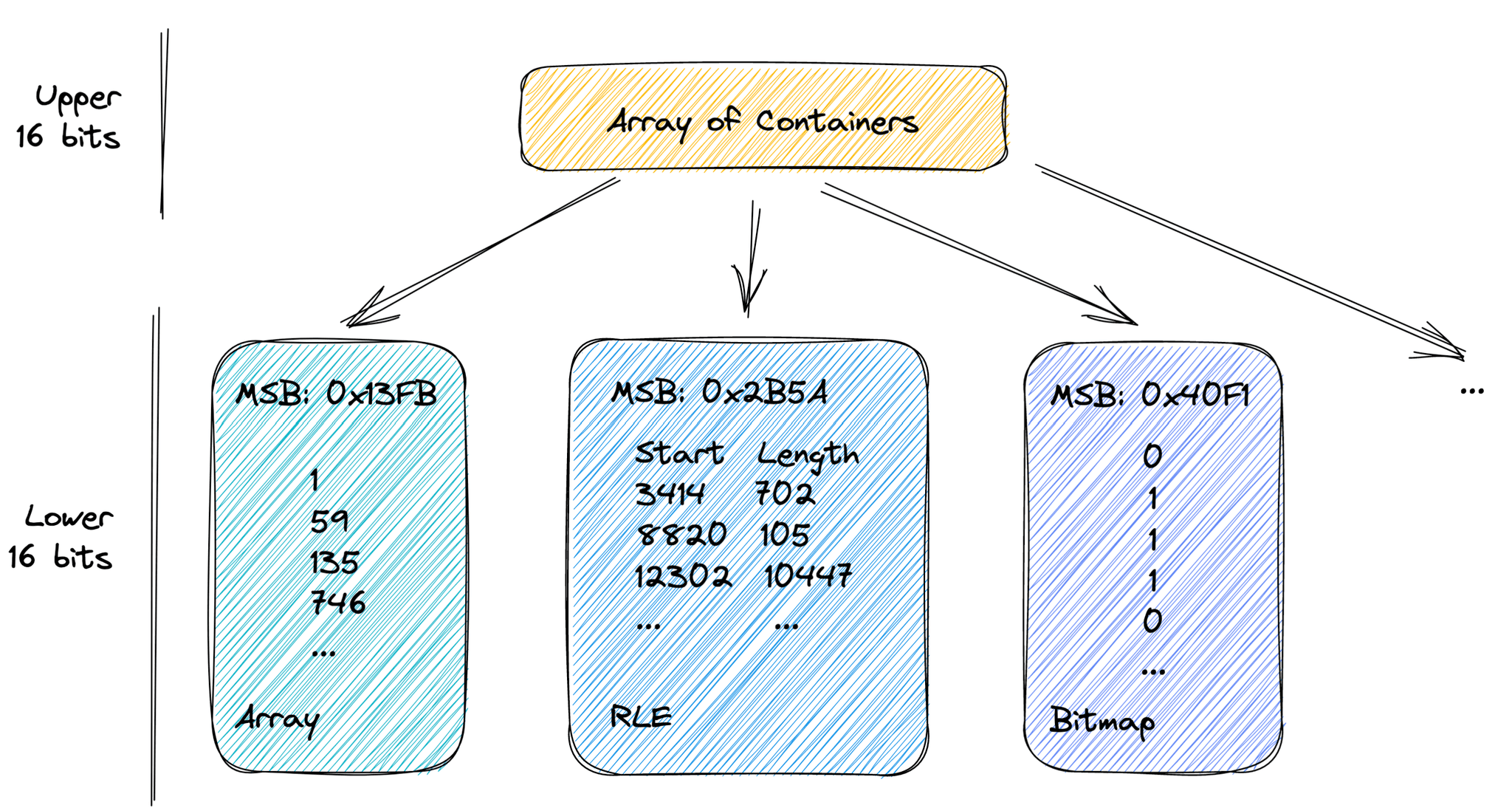
Roaring bitmaps store sorted lists of 32-bit integers, i.e., the maximum value is ca. 4.2 billion. The range of all possible integers is then split into equally large ranges of 2^16 integers. All integers in one chunk share their 16 most significant bits, whereas the 16 least significant bits are kept in a specialized container, depending on the distribution of the values in the range. The available container types include an array (for sparsely distributed values), bitmap (for densely distributed values), and run-length encoded (RLE, for data with long consecutive runs of values). An "array of containers" sorted on the upper 16 bits serves as an entry point into the list of containers. This structure is usually small enough to fit into the CPU cache.
In the context of inverted indexes, it is also important to be able to merge and intersect two posting lists quickly. This becomes necessary when users search for a disjunction (OR) or conjunction (AND) of multiple terms, e.g., SELECT * from docs WHERE doc IN ('wind', 'blows', 'sail'). Roaring bitmaps are especially good at this as they come with optimized algorithms to union and intersect every combination of two container types. For more details on roaring bitmaps, we refer to this publication.
Dictionary Compression
Now that we have taken a closer look at the posting lists let's turn our attention to the compression of dictionaries. The inverted indexes in ClickHouse use Finite State Transducers (FSTs) to represent dictionaries. Most people are probably unfamiliar with FSTs, but many people know Finite State Machines. This type of automata has a set of states and a set of transitions between the states, and depending on whether one ends up in an accepting or a non-accepting state, they accept or reject an input. FSTs work similarly, except that state transitions not only consume input, they also produce output. For this reason, FSTs are a popular tool in computer linguistics to translate between two languages.
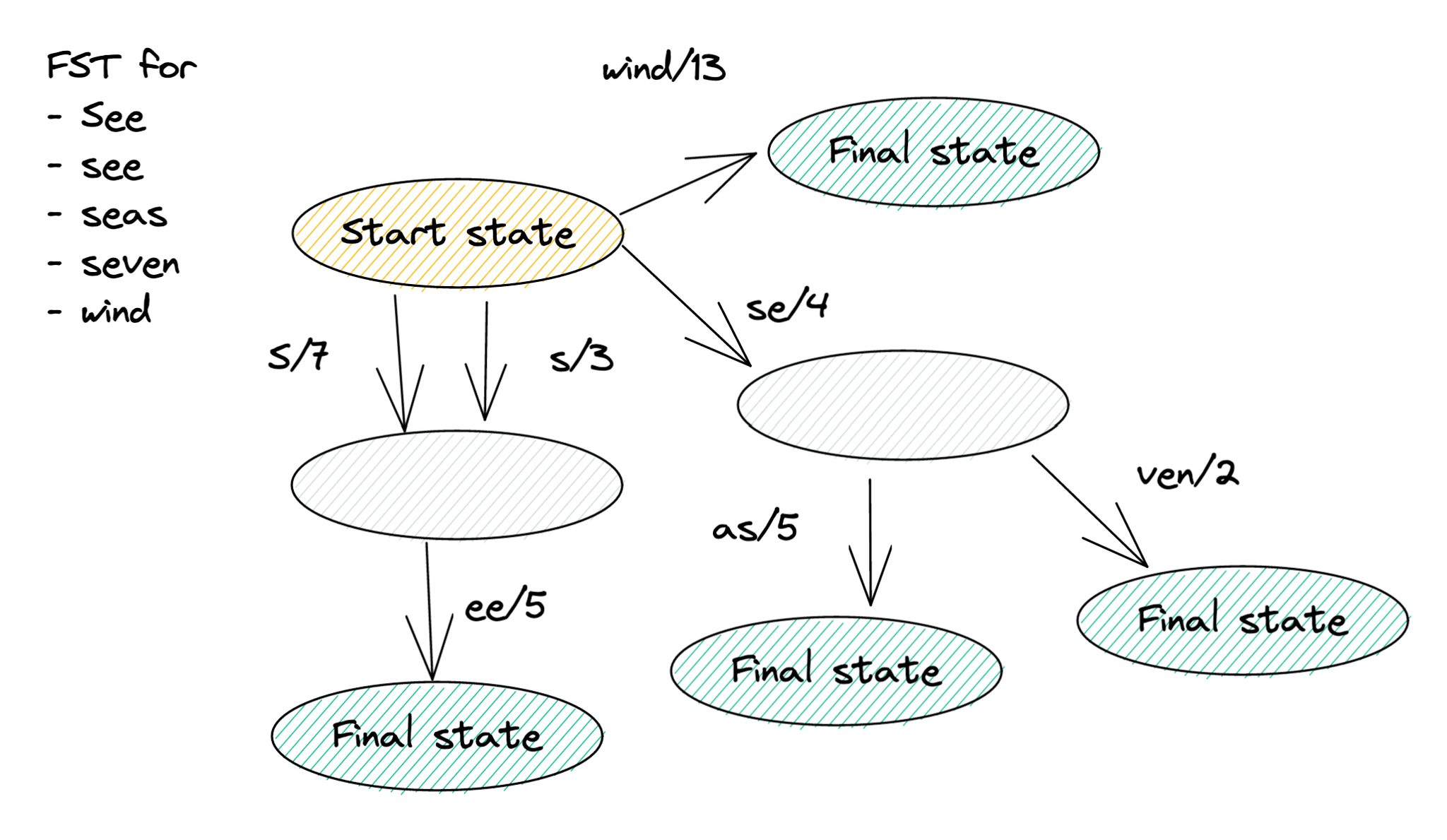
In ClickHouse's inverted indexes, FSTs "translate" terms to posting list offsets. The FST in the above example accepts the terms "See, "see", "seas", "seven" and "wind". The posting list offset is computed by accumulating the outputs of each transition. For example, the term "seas" produces offset 4 + 5 = 9. The figure shows a compressed FST in which common substrings are removed using the techniques explained here.
Disk Layout
Before demonstrating inverted indexes on a realistic dataset, we will quickly discuss their construction and on-disk layout.
Inverted index construction, also known as "inversion", is a CPU and time-intensive operation. Inverted indexes in ClickHouse are implemented as secondary indices, and as such, they exist at the granularity of a part. With the current implementation, a merge of two parts re-creates the inverted index on the new part from scratch. This might be optimized in the future with more lightweight incremental index maintenance that is able to merge two existing indexes directly. For now, care was taken to limit the cost of index creation. Out of different possible index construction methods, ClickHouse uses a strategy ("single-pass in-memory inversion") which
- iterates the underlying column data in a single pass (as opposed to requiring two passes),
- processes a configurable chunk of data (as opposed to allocating memory proportional to the size of the underlying column), and
- constructs the index directly (instead of writing intermediate files to disk, which are subsequently merged in a postprocessing step).
The resulting inverted index is segmented, i.e., consists of multiple smaller sub-indexes. Each segment corresponds to a consecutive row range of the original column. Row ranges can be of different sizes but their approximate size can be controlled by the parameter max_digestion_size_per_segment.
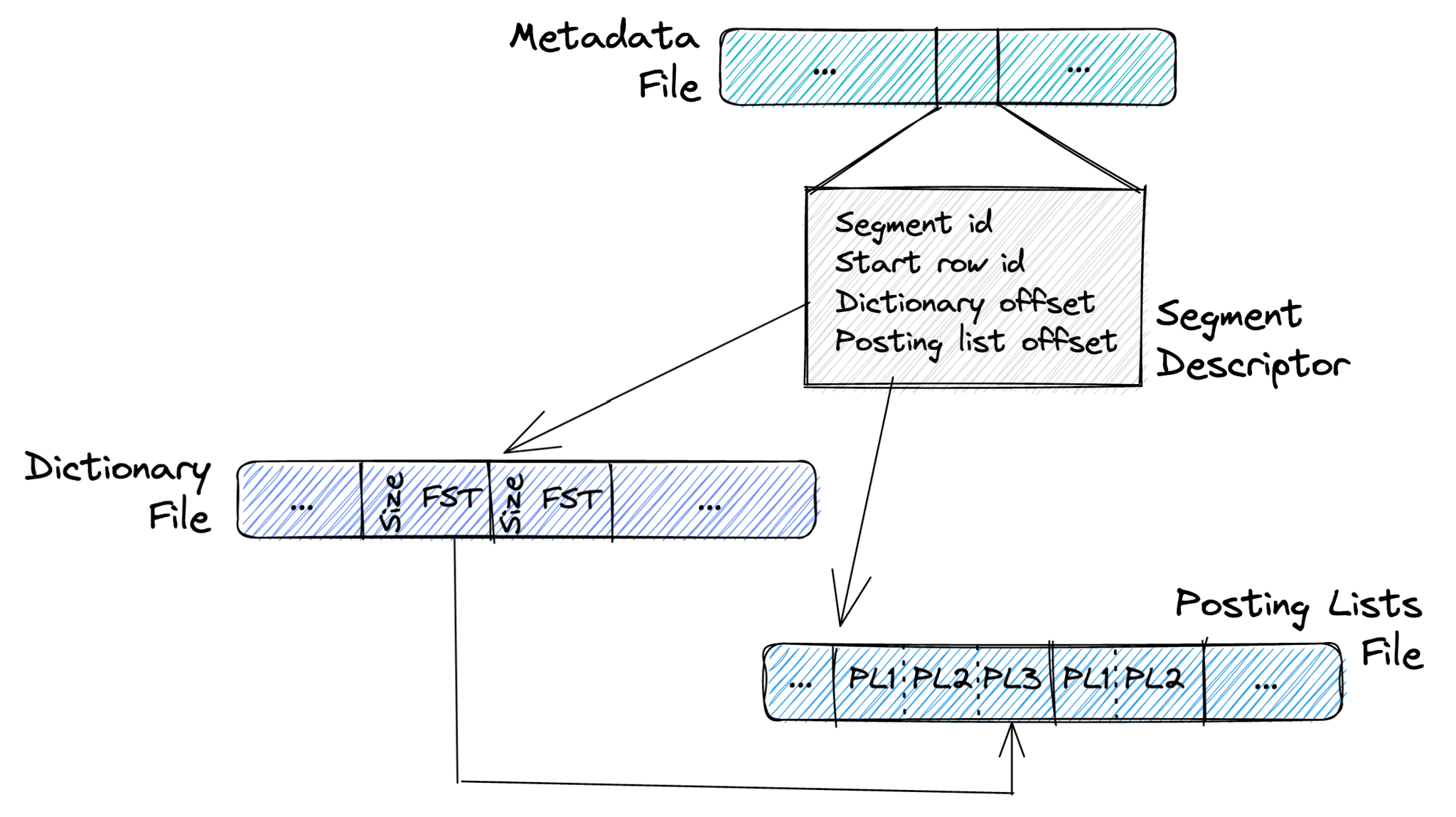
The index of a part is stored as three files.
The metadata file is an array of segment descriptors, each containing a unique segment id, a start row id, a dictionary offset, and a posting list offset. The start row id represents the starting row of the segment, whereas the dictionary and posting list offsets point to the beginning of the current segment's sections in the posting list and the dictionary files.
The posting list file contains the posting lists of all segments. A segment can have multiple posting lists because it can have multiple terms. Starting from the metadata file, we can use the posting list offset to jump to the first posting list of a segment. But since there can be multiple terms within the segment, we also need to find the correct posting list within the segment.
That is what the dictionary file is for. It contains each segment's dictionary (+ the dictionary size) in the form of a minimized FST. During an index lookup, ClickHouse will use the dictionary and the posting list offset in the metadata file to jump to the right FST and the beginning of the segment's posting lists. It will then use the FST in the dictionary file to calculate the offset from the start of the segment's posting lists to the actual posting list and eventually decompress it. Because of this architecture, the inverted index is never fully read into memory; only pieces of the metadata file, the dictionary file, and the posting list file are read at a time.
A Real-world Example
Finally, it is time to demonstrate the inverted index. We use the Hacker News dataset, which contains 28.7 million comments posted on Hacker News. Let's first import the data:
CREATE TABLE hackernews
(
`id` UInt64,
`deleted` UInt8,
`type` String,
`author` String,
`timestamp` DateTime,
`comment` String,
`dead` UInt8,
`parent` UInt64,
`poll` UInt64,
`children` Array(UInt32),
`url` String,
`score` UInt32,
`title` String,
`parts` Array(UInt32),
`descendants` UInt32
)
ENGINE = MergeTree
ORDER BY (type, author);
INSERT INTO hackernews
SELECT * FROM s3(
'https://datasets-documentation.s3.eu-west-3.amazonaws.com/hackernews/hacknernews.parquet',
'Parquet',
'id UInt64,
deleted UInt8,
type String,
by String,
time DateTime,
text String,
dead UInt8,
parent UInt64,
poll UInt64,
kids Array(UInt32),
url String,
score UInt32,
title String,
parts Array(UInt32),
descendants UInt32');To find out how many comments mention "ClickHouse", we can run:
SELECT count(*)
FROM hackernews
WHERE hasToken(lower(comment), 'ClickHouse');
┌─count()─┐
│ 516 │
└─────────┘
1 row in set. Elapsed: 0.843 sec. Processed 28.74 million rows, 9.75 GB (34.08 million rows/s., 11.57 GB/s.)On my machine, the query took 0.843 seconds to complete. Let's now create an inverted index on the "comment" column. Note that we index lowercase comments to find terms unrelated to their case.
ALTER TABLE hackernews ADD INDEX comment_idx(lower(comment)) TYPE inverted;
ALTER TABLE hackernews MATERIALIZE INDEX comment_idx;Materialization of the index takes a while (to check if the index was created, use the system table system.data_skipping_indices). Let's run the query again:
SELECT count(*)
FROM hackernews
WHERE hasToken(lower(comment), 'clickhouse');
┌─count()─┐
│ 1145 │
└─────────┘
1 row in set. Elapsed: 0.248 sec. Processed 4.54 million rows, 1.79 GB (18.34 million rows/s., 7.24 GB/s.)
EXPLAIN indexes = 1
SELECT count(*)
FROM hackernews
WHERE hasToken(lower(comment), 'clickhouse')
┌─explain─────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Filter (WHERE) │
│ ReadFromMergeTree (default.hackernews) │
│ Indexes: │
│ PrimaryKey │
│ Condition: true │
│ Parts: 4/4 │
│ Granules: 3528/3528 │
│ Skip │
│ Name: comment_idx │
│ Description: inverted GRANULARITY 1 │
│ Parts: 4/4 │
│ Granules: 554/3528 │
└─────────────────────────────────────────────────┘This is about 3.4x faster than without an index! We can also search for one or all of multiple terms, i.e., disjunctions or conjunctions:
SELECT count(*)
FROM hackernews
WHERE multiSearchAny(lower(comment), ['oltp', 'olap']);
┌─count()─┐
│ 2177 │
└─────────┘
1 row in set. Elapsed: 0.482 sec. Processed 8.84 million rows, 3.47 GB (18.34 million rows/s., 7.19 GB/s.)
SELECT count(*)
FROM hackernews
WHERE hasToken(lower(comment), 'avx') AND hasToken(lower(comment), 'sve');
┌─count()─┐
│ 22 │
└─────────┘
1 row in set. Elapsed: 0.240 sec. Processed 663.55 thousand rows, 272.44 MB (2.77 million rows/s., 1.14 GB/s.)In the future, there will hopefully be a dedicated function similar to multiSearchAny() to search for multiple AND'ed terms at once.
With that, we wrap our blog post on inverted indexes in ClickHouse. We would be happy to hear back from you, for example, with your own experiences using inverted indexes or ideas for future extensions.



