TL;DR: We’re delighted to announce CryptoHouse, accessible at crypto.clickhouse.com, free blockchain analytics powered by ClickHouse.
Existing public blockchain analytics services require scheduled, asynchronous queries, but ClickHouse offers real-time analytics, democratizing access by enabling instant query responses. Users can use SQL to query this data, which is updated in real-time, thanks to Goldsky, at no cost. Our custom UI allows for saving and sharing queries and basic charting, with examples to get users started. We welcome external contributions to the example queries to help in this effort.
As of today, users of CryptoHouse can query Solana blocks, transactions, token_transfers, block_rewards, accounts, and tokens for free. Similar datasets are available for Ethereum. We plan to expand the data available and expose more blockchains in the coming months!
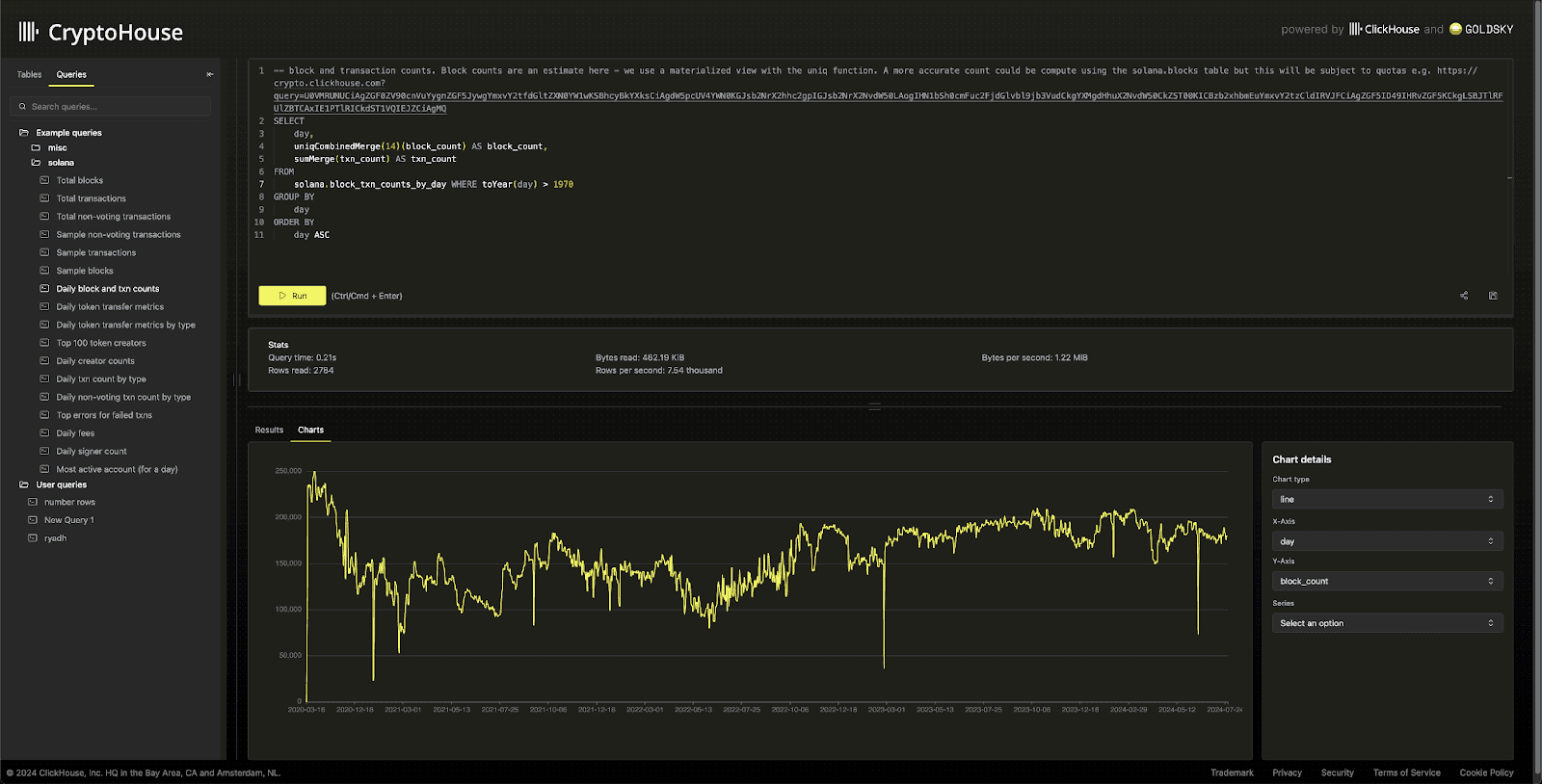
If you’re interested in why and how we built this service, read on…
A need for blockchain analytics
Blockchains are complex entities that can handle thousands of transactions and smart contract executions per second. Understanding their changes and state is crucial for investors making informed decisions and developers building these contracts.
SQL is a natural language for performing these analytics, but this presents two significant challenges: (1) converting blockchain entities into a structured, row-oriented format, and (2) finding a database capable of handling the high throughput and potentially petabytes of data while serving the analytical queries users need.
ClickHouse is the standard for blockchain analytics
As an open-source OLAP database, ClickHouse is ideal for storing blockchain data due to its column-oriented design and highly parallel execution engine. This allows queries to run over terabytes of data, delivering fast analytics across the full dataset. As a result, we have seen ClickHouse increasingly used for blockchain analytics, with companies such as Goldsky and Nansen using ClickHouse at the core of their offerings.
Building a public service
Anyone who follows ClickHouse and is aware of our public demos will know we love to take on big datasets and build services around them. Earlier this year, we released ClickPy, which provides free analytics on Python package downloads. More recently, adsb.exposed wowed the community with some amazing visuals on flight data.
We’ve long known that blockchains offered the potential to satisfy our hunger for large, complex datasets. Of the popular blockchains, we knew the Solana network offers both size and complexity. While existing solutions exist for a public blockchain analytics service, users typically have to schedule queries and wait for them to execute asynchronously - persisting the results for later retrieval. As the maintainers of ClickHouse, we knew we could serve the problem better, delivering real-time analytics on the blockchains at a fraction of the cost and democratizing access to the data by allowing users to write queries and retrieve responses in real time.
While we were comfortable with the ClickHouse side of the effort, we admittedly aren’t crypto experts. Efforts to convert the Solana blockchain into a structured row orientated format looked involved with some prerequisite for domain expertise. The "challenge" therefore remained on pause until some fortuitous meetings earlier this year.
Enter Goldsky
Goldsky is a product which specializes in cryptocurrency data infrastructure, providing developers with tools to build great real-time applications using data from Solana and other blockchain networks. Their platform supports developers in building reliable, data-driven Web3 applications by offering services like live data streaming of blockchain events in a structured format, with delivery straight into databases.
While Goldsky have been users of ClickHouse for some time for their own internal use cases, they are frequently requested to send blockchain data to their customers' own ClickHouse clusters who are looking to perform analytics. While interviewing Jeff Ling, the CTO of Goldsky, for a user story late last year, we shared our idea of building what would become CryptoHouse. To our surprise, Jeff was eager to participate and solve the data engineering component of our problem!
Data engineering challenges
Solana produces 3000-4000 transactions per second, with data that needs to be directly extracted from the nodes. Initially, Goldsky operationalized open-source software to provide Solana support, which equates to scraping the built-in blockchain node APIs. This approach led to an architecture where new blocks would be detected and put into a queue, with multiple workers in charge of fetching all the required transactions before putting these into the Goldsky Mirror data streaming platform with minimal latency.
In practice, each transaction was also extracted into additional datasets, such as token transfers and account changes. The ingestion framework was adjusted to account for all the downstream transformations needed.
With the data now ingesting live into the platform, a mirror pipeline configuration was created for all the tables we wanted to support. Some transformations were needed to match the data with the table, which was optimized for efficient storage and aimed at the most common queries that users would want to run.
# Example pipeline for blocks - this was repeated for all tables
name: clickhouse-partnership-solana
sources:
blocks:
dataset_name: solana.edge_blocks
type: dataset
version: 1.0.0
transforms:
blocks_transform:
sql: >
SELECT hash as block_hash, `timestamp` AS block_timestamp, height, leader, leader_reward, previous_block_hash, slot, transaction_count
FROM blocks
primary_key: block_timestamp, slot, block_hash
sinks:
solana_blocks_sink:
type: clickhouse
table: blocks
secret_name: CLICKHOUSE_PARTNERSHIP_SOLANA
from: blocks_transformFinally, since the final schema required tuples, we had difficulty converting the JSON from our dataset into the right format. To address this we make use of the Null table engine, combined with a Materialized View, to do ClickHouse-specific transformations from a JSON string to a tuple. For example, the following view and Null table are responsible for receiving inserts for the tokens dataset. The results of the Materialized View are sent to the final solana.tokens table:
CREATE TABLE solana.stage_tokens
(
`block_slot` Int64,
`block_hash` String,
`block_timestamp` DateTime64(6),
`tx_signature` String,
`retrieval_timestamp` DateTime64(6),
`is_nft` Bool,
`mint` String,
`update_authority` String,
`name` String,
`symbol` String,
`uri` String,
`seller_fee_basis_points` Decimal(38, 9),
`creators` String,
`primary_sale_happened` Bool,
`is_mutable` Bool
)
ENGINE = Null
CREATE MATERIALIZED VIEW solana.stage_tokens_mv TO solana.tokens
(
`block_slot` Int64,
`block_hash` String,
`block_timestamp` DateTime64(6),
`tx_signature` String,
`retrieval_timestamp` DateTime64(6),
`is_nft` Bool,
`mint` String,
`update_authority` String,
`name` String,
`symbol` String,
`uri` String,
`seller_fee_basis_points` Decimal(38, 9),
`creators` Array(Tuple(String, UInt8, Int64)),
`primary_sale_happened` Bool,
`is_mutable` Bool
)
AS SELECT block_slot, block_hash, block_timestamp, tx_signature, retrieval_timestamp, is_nft, mint, update_authority, name, symbol, uri, seller_fee_basis_points, arrayMap(x -> (x.1, (x.2) = 1, x.3), CAST(creators, 'Array(Tuple(String, Int8, Int64))')) AS creators,primary_sale_happened, is_mutable
FROM solana.stage_tokensThis was incredibly efficient and gave us a lot of flexibility, which allowed us to backfill the data at speeds close to 500k rows/second.
At the edge, we could easily optimize to just having one pipeline with 10 workers to handle all edge data, which equates to around 6000 rows per second written.
For users interested in more details about how incremental Materialized Views work in ClickHouse, we recommend these docs or this video.
When querying, users may notice that some of the Solana blocks and transactions have a
timestampwith a value of1970-01-01and aheightof 0. While Goldsky provides new data, rows prior to June 2024 have been backfilled from BigQuery. This data has Null entries for some timestamp and height values, which in ClickHouse become default values for their respective types - Date and Int64. We intend to rectify these data quality issues in the long term.
ClickHouse challenges
Ensuring fair usage
While the data volume for the Solana blockchain is unremarkable for ClickHouse, with the largest table holding transactions around 500TiB (as shown below), we wanted to provide functionality where anyone could write a SQL query. This presented problems around managing resources fairly across all users and ensuring that a single query cannot consume all available memory or CPU.
SELECT
`table`,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,
round(sum(data_uncompressed_bytes) / sum(data_compressed_bytes), 2) AS ratio
FROM system.parts
WHERE (database = 'solana') AND active
GROUP BY `table`
ORDER BY sum(data_compressed_bytes) DESC
┌─table─────────────────────────┬─compressed_size─┬─uncompressed_size─┬─ratio─┐
│ transactions │ 79.34 TiB │ 468.91 TiB │ 5.91 │
│ transactions_non_voting │ 17.89 TiB │ 162.20 TiB │ 9.07 │
│ token_transfers │ 3.08 TiB │ 18.84 TiB │ 6.11 │
│ block_rewards │ 1.31 TiB │ 10.85 TiB │ 8.28 │
│ accounts │ 47.82 GiB │ 217.88 GiB │ 4.56 │
│ blocks │ 41.17 GiB │ 82.64 GiB │ 2.01 │
│ tokens │ 3.42 GiB │ 10.10 GiB │ 2.96 │
└───────────────────────────────┴─────────────────┴───────────────────┴───────┘
10 rows in set. Elapsed: 0.009 sec. Processed 1.42 thousand rows, 78.31 KB (158.79 thousand rows/s., 8.74 MB/s.)
Peak memory usage: 99.91 KiB.To ensure fair usage (and predictable costs), we impose ClickHouse usage quotas, limiting the number of rows a user query can scan to 10 billion. Queries must also be completed within 60 seconds (most do, thanks to ClickHouse’s performance) with a limit of 60 queries per user per hour. Other limits concerning memory usage aim to ensure service stability and fair usage.
Accelerating queries with Materialized Views
Some queries are invariably more computationally expensive than others. Blockchain queries also often need to scan large amounts of data, providing summary statistics over hundreds of billions of rows. To enable these sorts of queries, we provide ClickHouse Materialized Views, which shift the computation from query time to insert time. This can dramatically accelerate certain queries and allow users to obtain statistics computed across the entire dataset. These views are incrementally updated in real time as data is inserted. As an example, consider the following query, which computes daily fees for every day in the last month:
SELECT
toStartOfDay(block_timestamp) as day,
avg(fee / 1e9) AS avg_fee_sol,
sum(fee / 1e9) as fee_sol
FROM
solana.transactions_non_voting
WHERE block_timestamp > today() - INTERVAL 1 MONTH
GROUP BY
1
ORDER BY 1 DESC
31 rows in set. Elapsed: 1.783 sec. Processed 2.12 billion rows, 50.98 GB (1.19 billion rows/s., 28.58 GB/s.)
Peak memory usage: 454.44 MiB.This query scans around 2b rows and completes in 2s. Users can obtain the same result by using one of the example queries that exploits a Materialized View:
SELECT day,
avgMerge(avg_fee_sol) AS avg,
sumMerge(fee_sol) AS fee_sol
FROM solana.daily_fees_by_day
WHERE day > today() - INTERVAL 1 MONTH
GROUP BY day
ORDER BY day DESC
31 rows in set. Elapsed: 0.007 sec. Processed 1.38 thousand rows, 60.54 KB (184.41 thousand rows/s., 8.11 MB/s.)
Peak memory usage: 4.88 MiB.This completes in 0.007s. Note that the view aggregates by day, so for queries that require more granular statistics, e.g., by the hour for a specific day, we suggest using the source table solana.transactions_non_voting.
The current views were developed in collaboration with the Solana Foundation and optimized during testing. If users find a query which hits quota limits that they believe the community would benefit from, simply raise an issue in the project repository here. We can create the view and backfill the data as required. In future, we hope to automate this process and expose a build system that allows users to simply raise a view proposal or example query as a PR.
Deduplicating data
To deliver events efficiently, Goldsky offers at least one semantics. This means that while we are guaranteed to receive all data that occurs on a chain, we may, under rare circumstances, receive an event more than once. To address this, our tables use a ReplacingMergeTree engine.
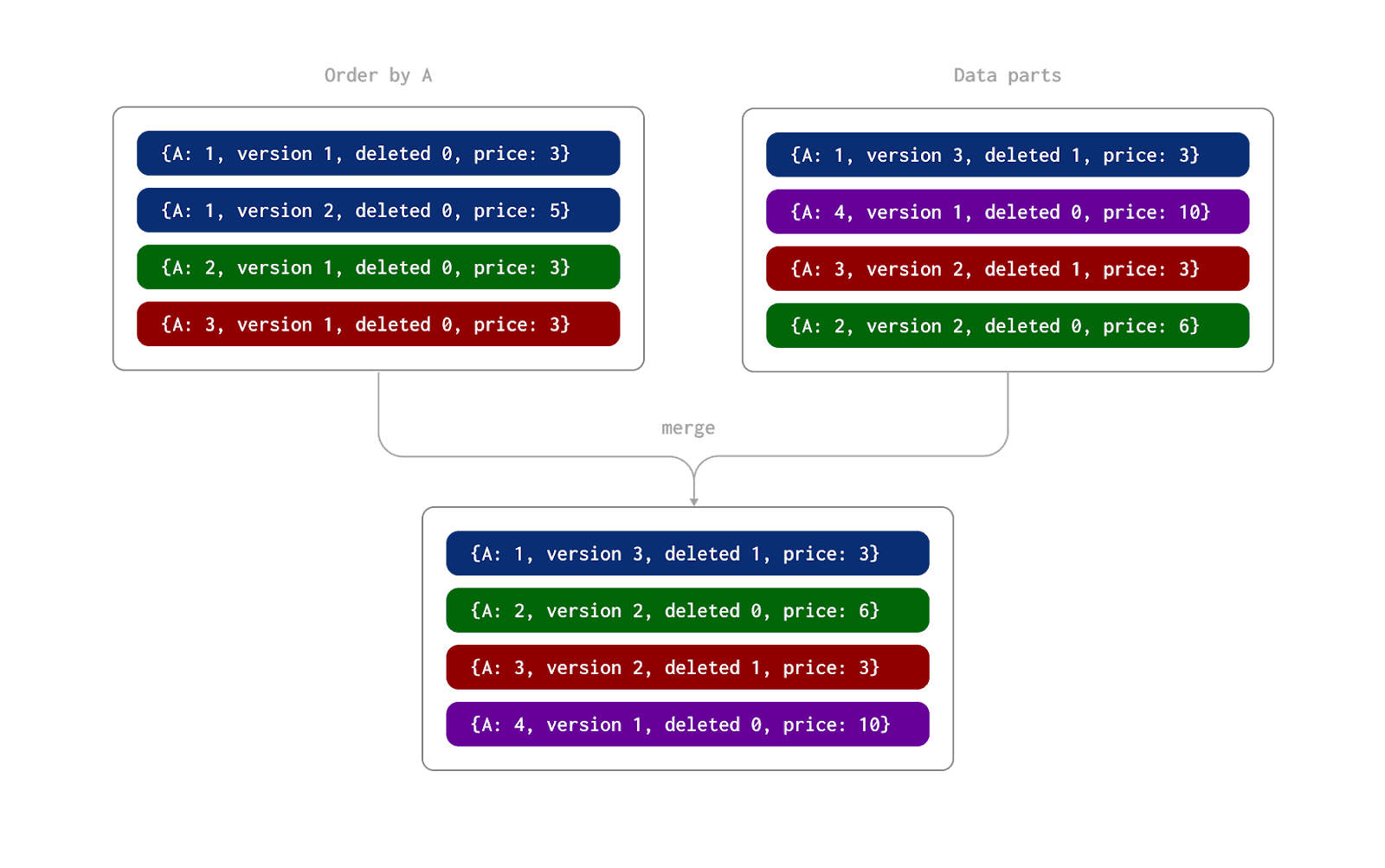
This engine type deduplicates events with the same values for the tables ordering key (in most cases, this is the block_timestamp and slot). This deduplication process occurs asynchronously in the background and is eventually consistent. While results may be slightly inaccurate for a period if duplicate events are inserted, given the large number of rows and the tiny percentage of duplicates, we expect this to be rarely an issue, with most queries not requiring row-level accuracy. For more details on how the ReplacingMergeTree works, see here.
Using ClickHouse Cloud
The instance used to power the service is hosted in ClickHouse Cloud. This provides several benefits, not least the separation of storage and compute. With only one copy of the data stored in object storage, we can scale CPU and memory independently based on user demand. If we see higher user demand for this service, we can simply add more nodes - no resharding or redistribution of the data is required. As well as simplifying operations, using object storage means we can both scale infinitely (effectively) and deliver this service cost-effectively.
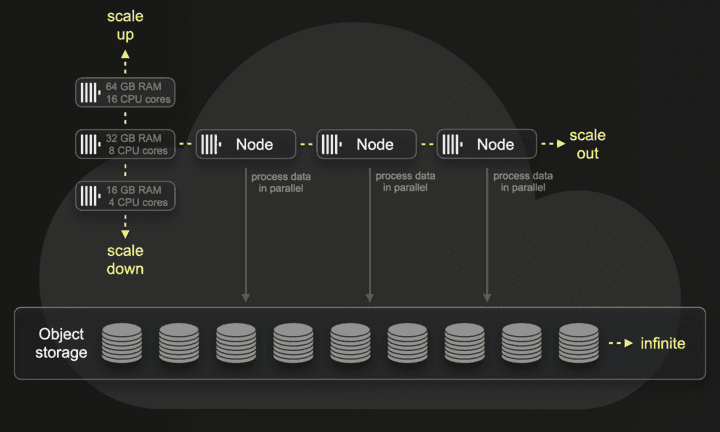
Finally, we exploit the ClickHouse query cache, which was added to open-source earlier this year.
Building a UI
With the data engineering and ClickHouse challenges addressed, we wanted to provide a service users loved using, so we exposed a simple UI that allows users to write and share queries.
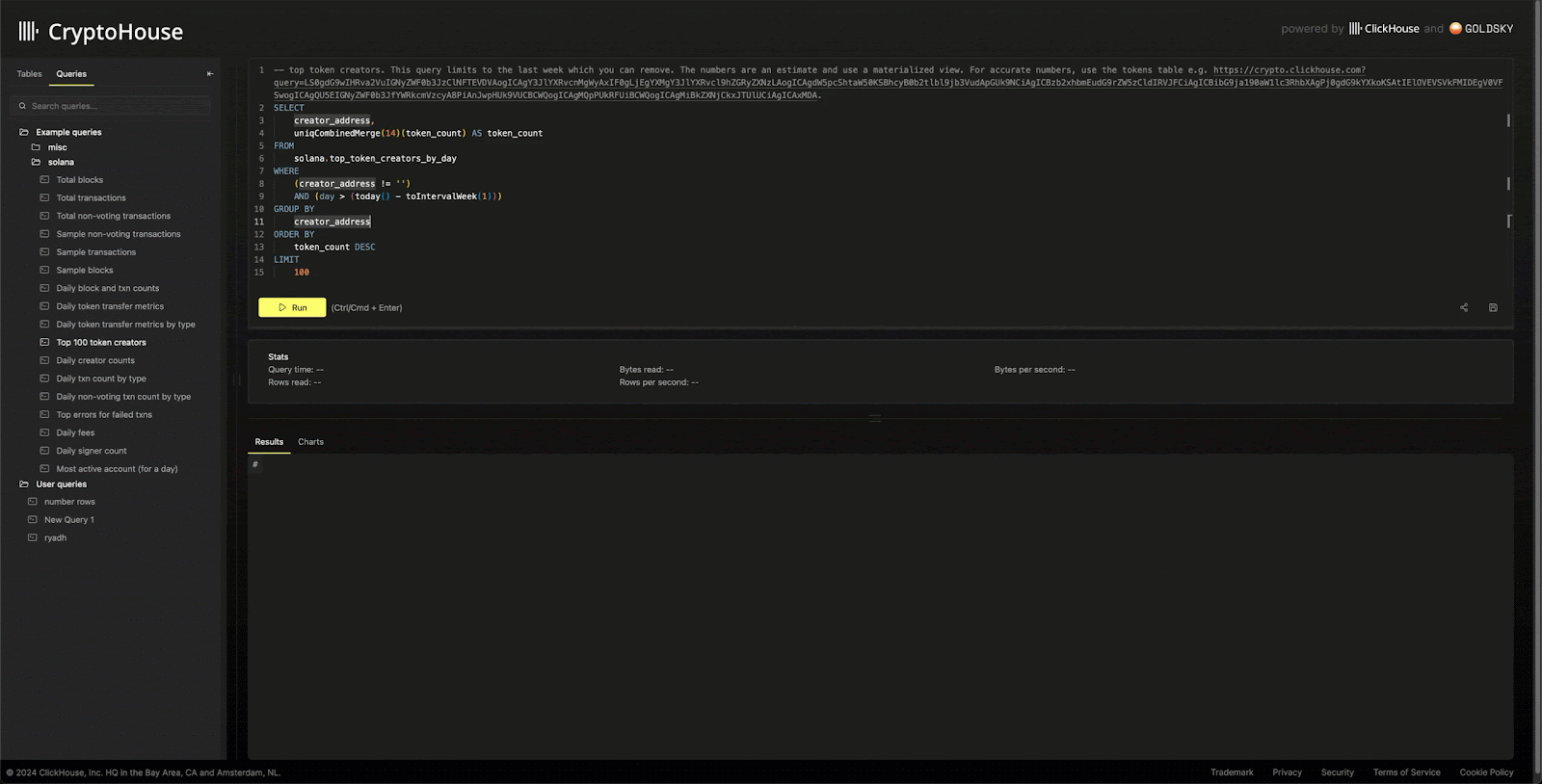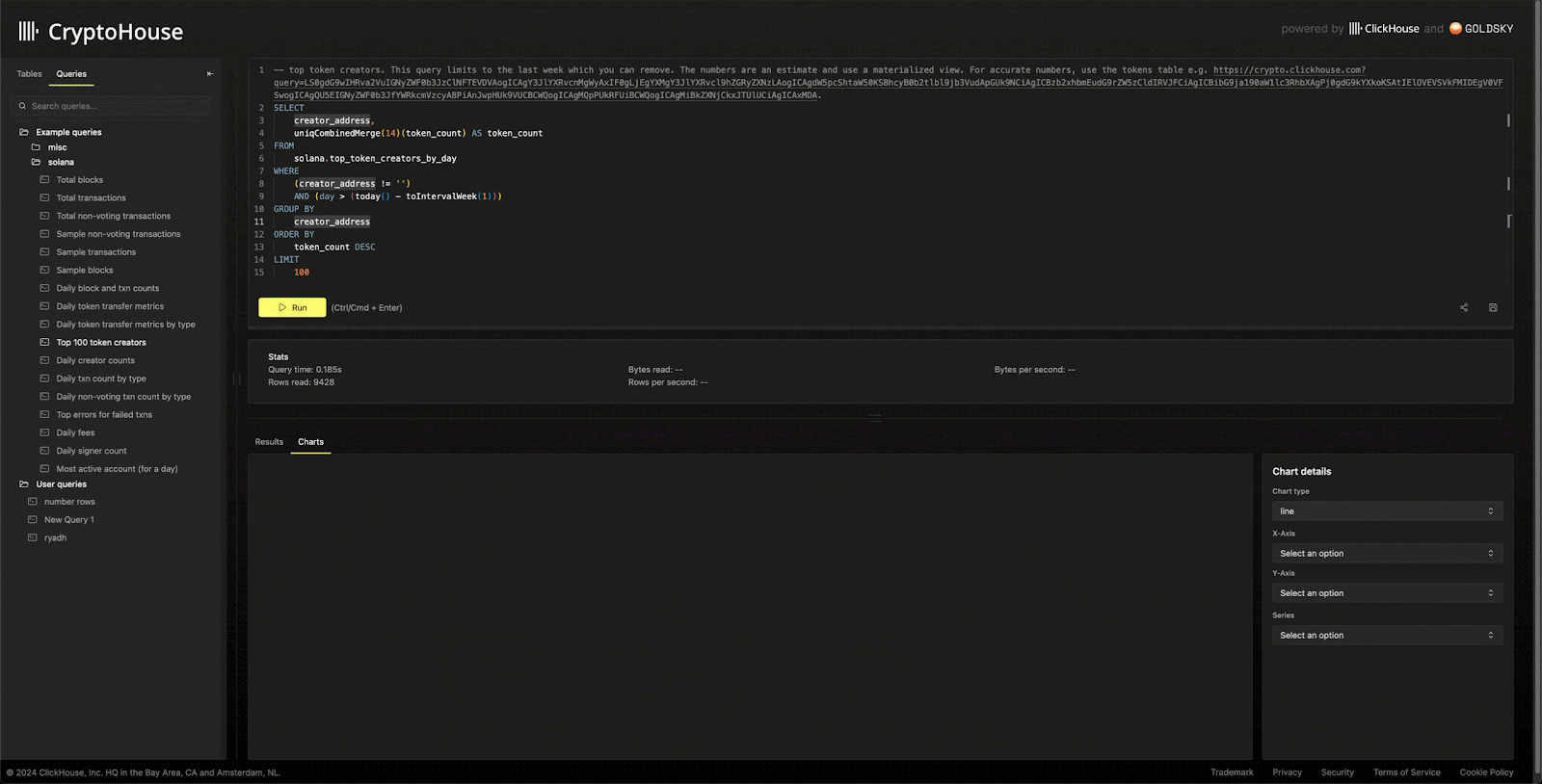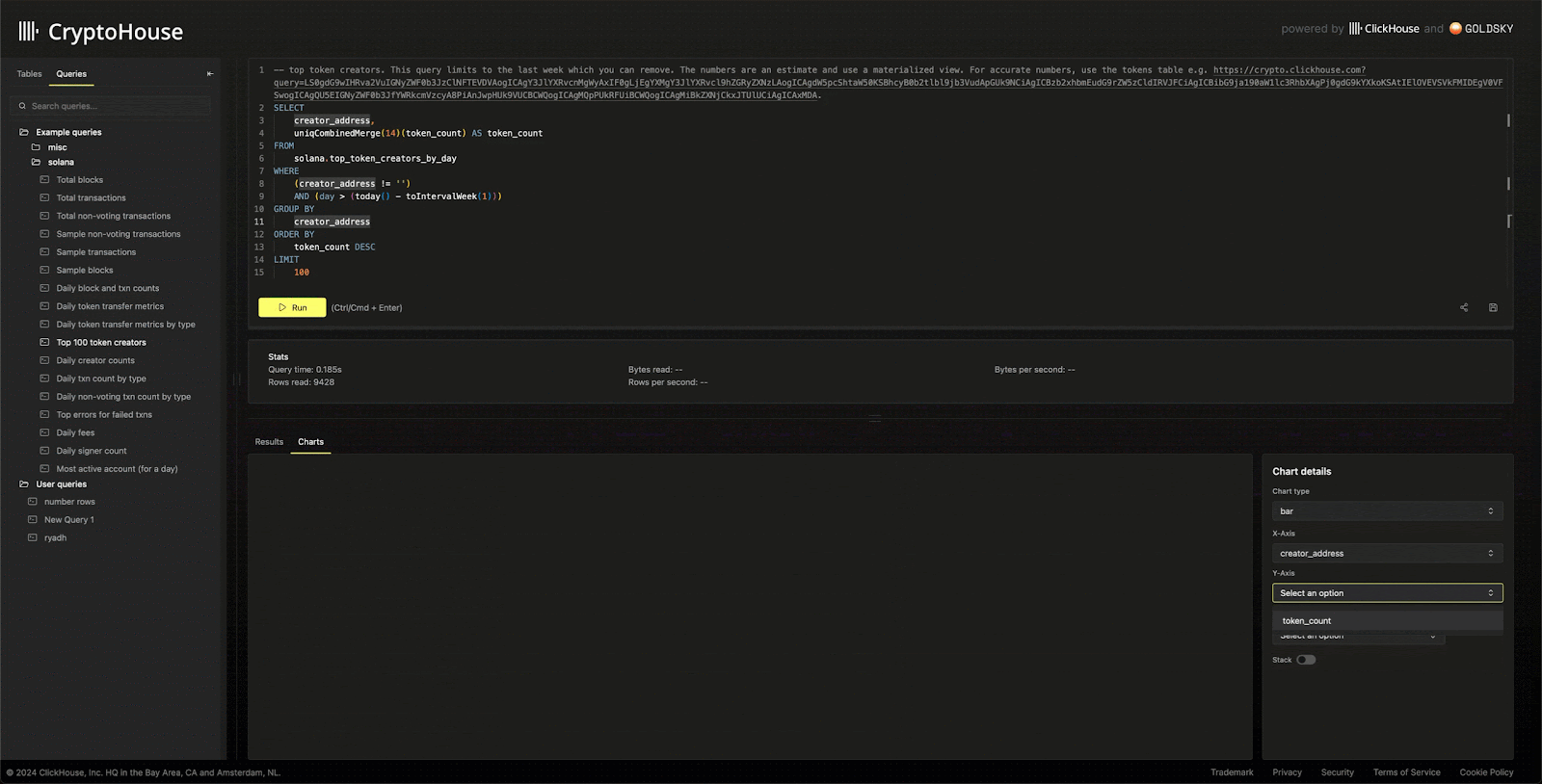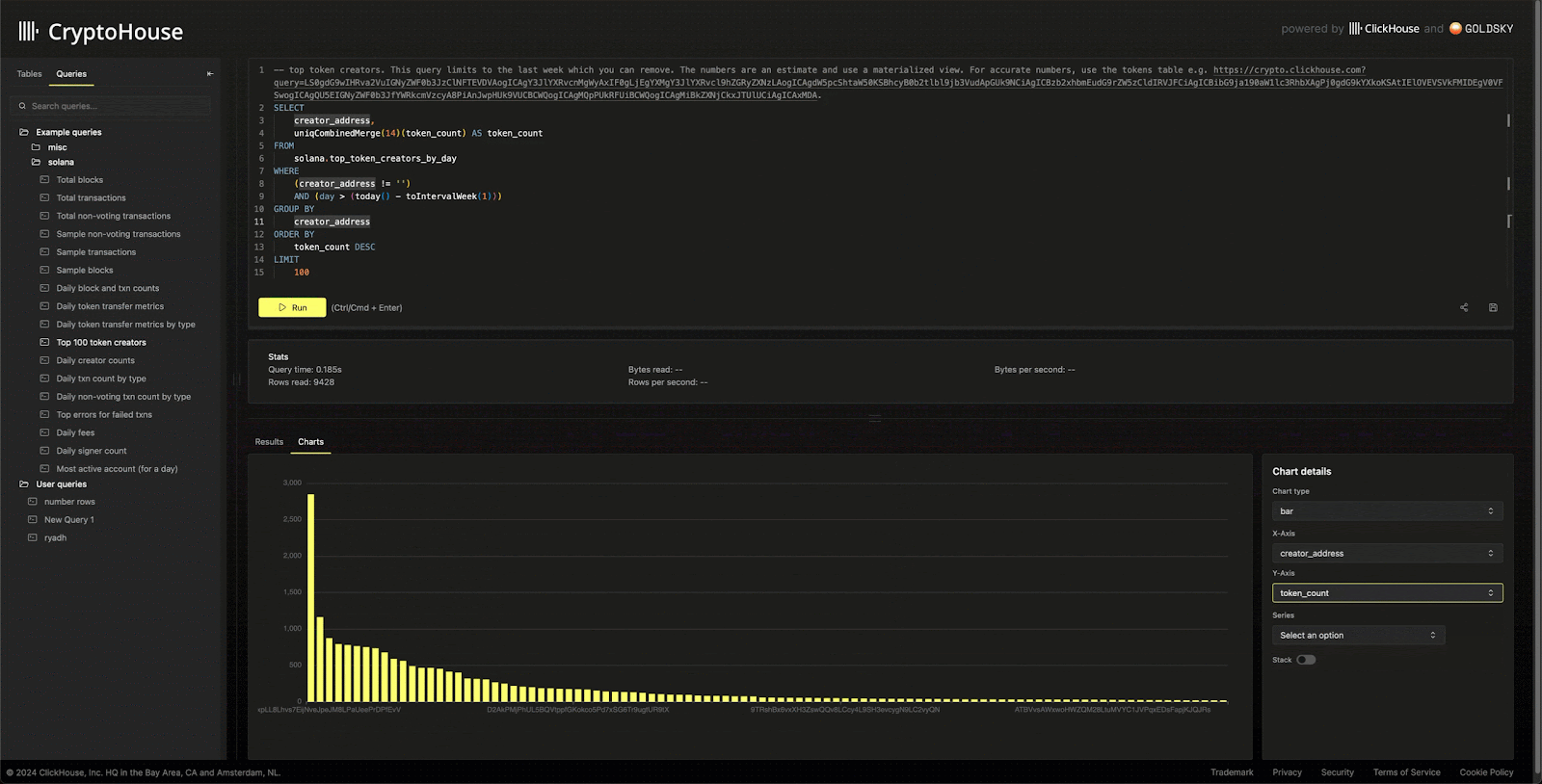
Appreciating that users often need to visualize results, this UI also supports simple multi-dimensional charting, powered by e-charts.
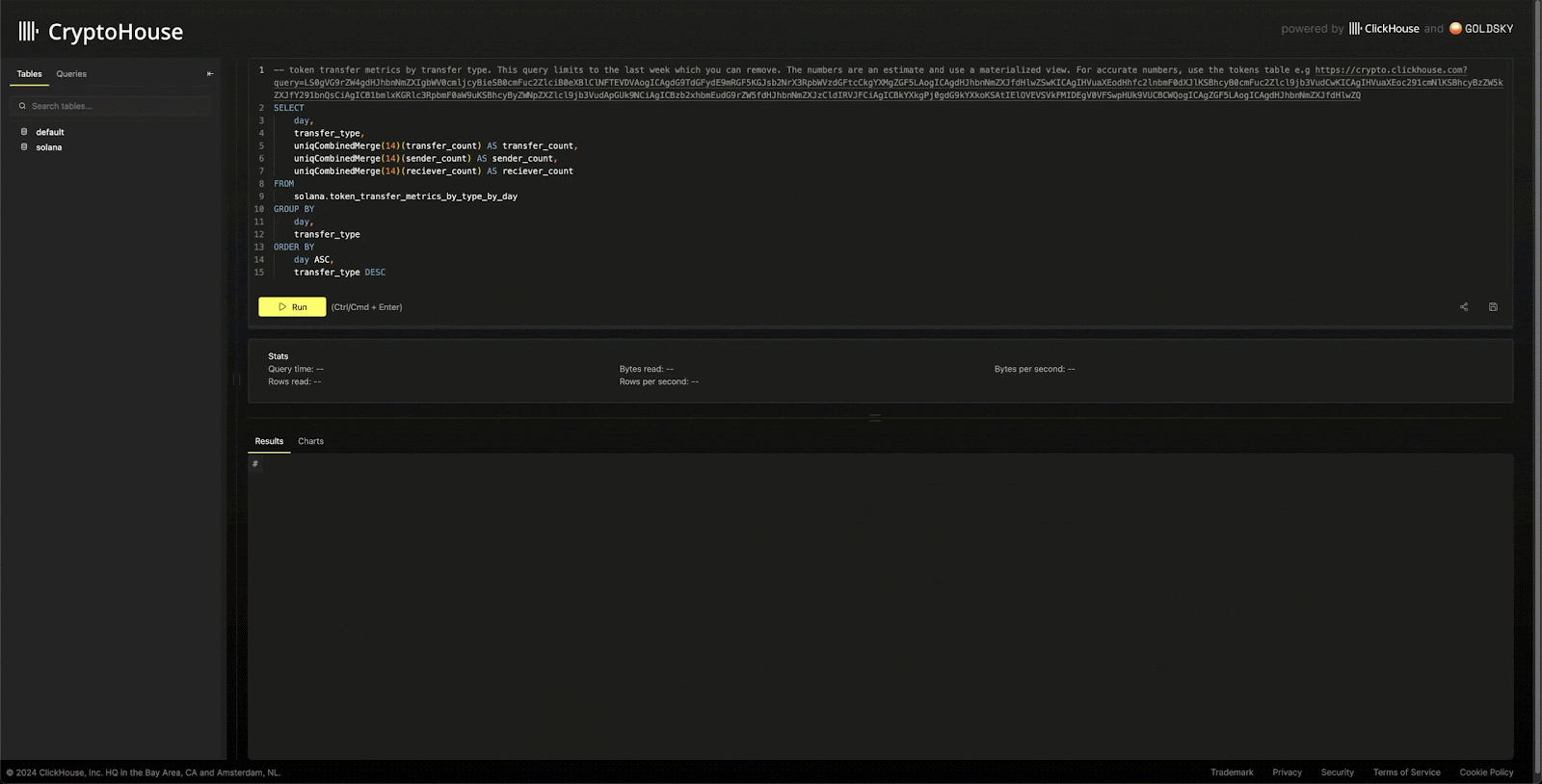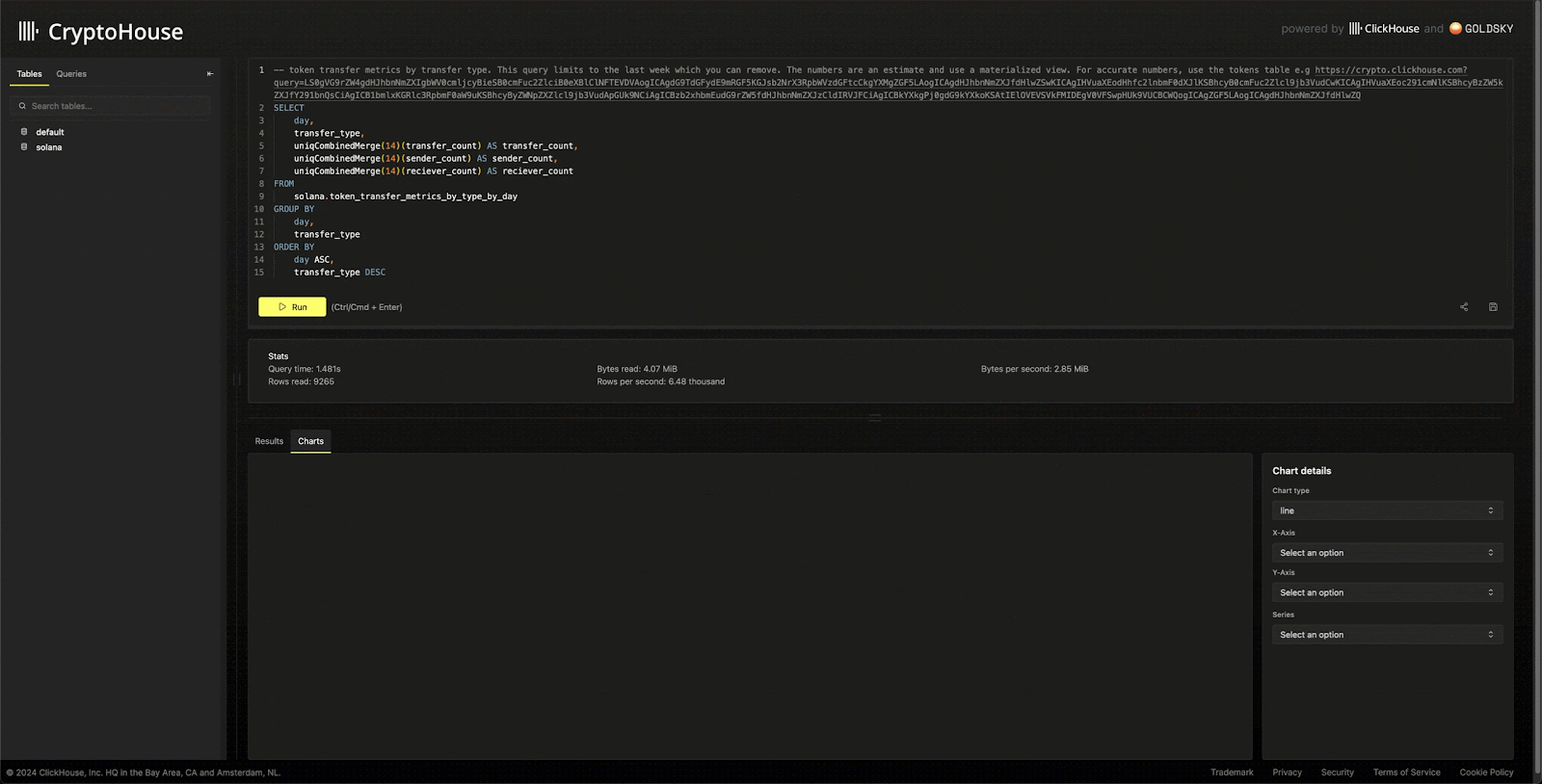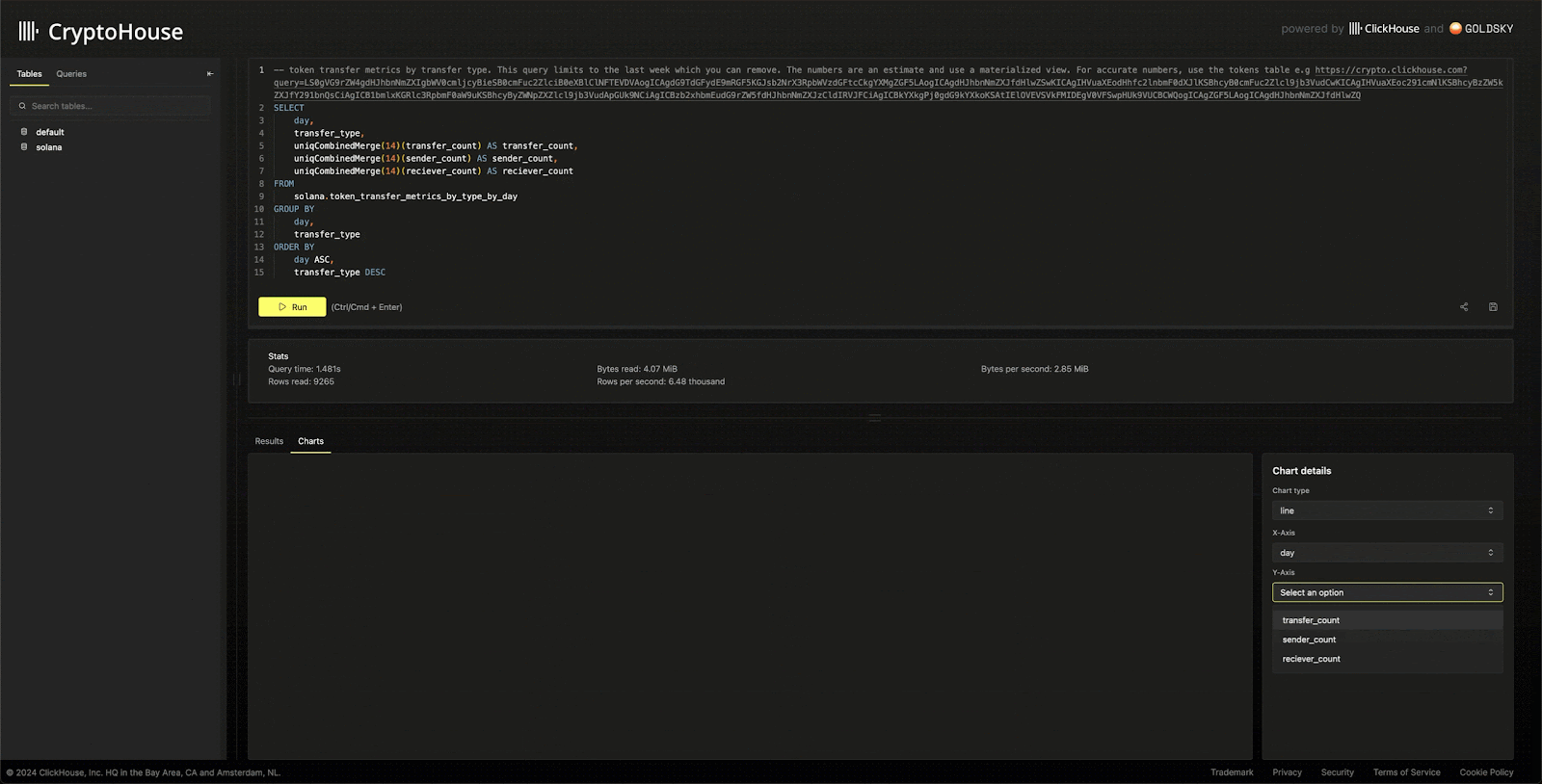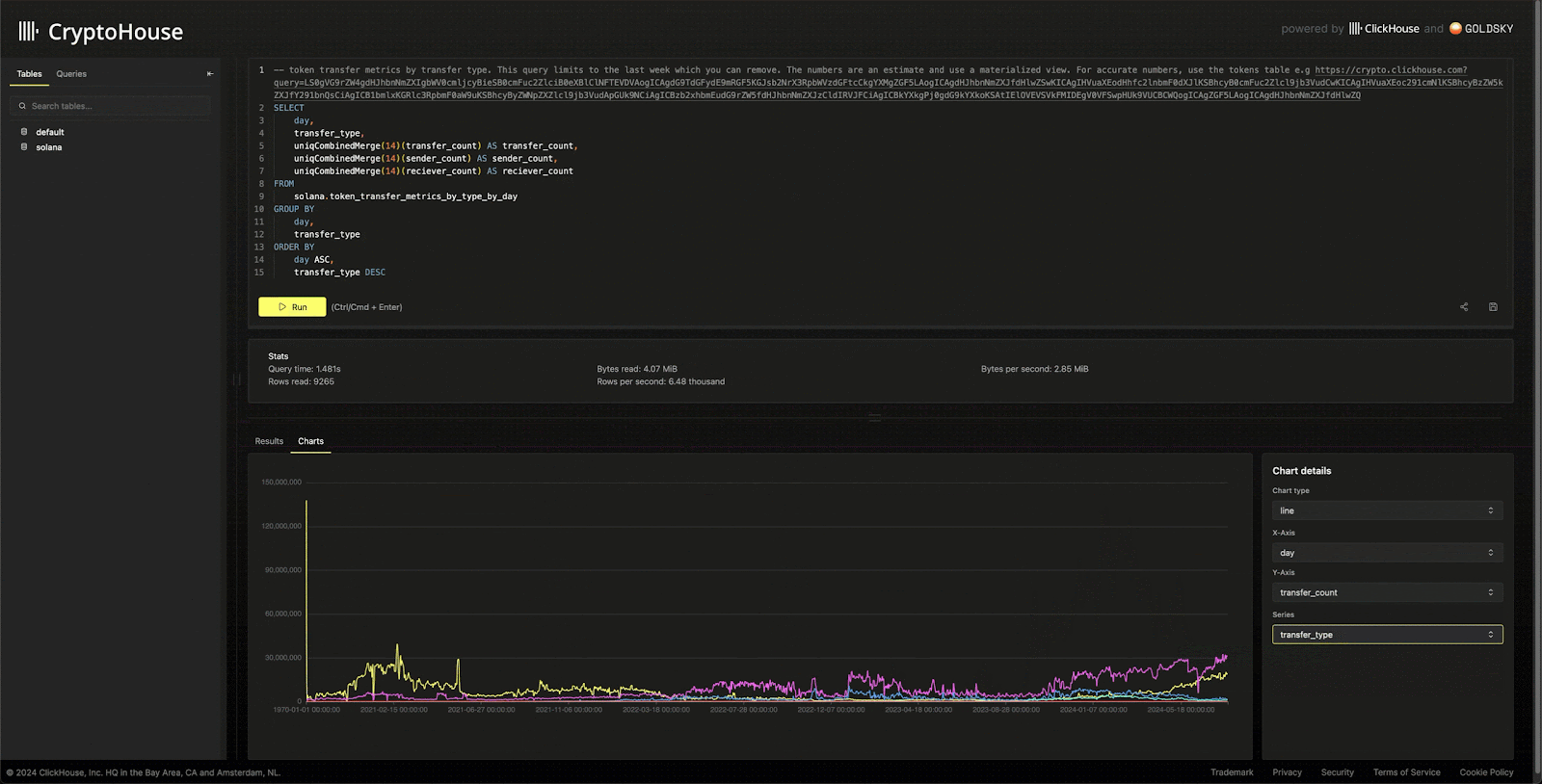
Note that users can save their queries alongside the examples provided. However, these are not persisted in the service and only exist in the browser store.
Tips on querying
To avoid hitting quota limits, we recommend users:
- Use Materialized Views. These deliberately shift computation to insert time, minimizing the number of rows user queries need to read. Many of these use AggregateFunction types, which store the intermediate result from an aggregation. This requires the use of a -Merge function when querying e.g. here.
- Use date filters on main tables - The Materialized Views aggregate by day. For more granular analysis, refer to the base tables e.g., transactions. These tables contain every event and are, as a result, hundreds of billions of rows. When querying these rows, always apply a date filter to avoid exceeding a month's timespan.
If users want more…
While we have attempted to be as generous as possible with quotas, we expect some users will want to run queries requiring more computational power than CryptoHouse offers. CryptoHouse is intended for community usage and not for organizations looking to build a service or commercial offering, so higher volumes of queries are not supported.
If you need higher quotas or need to issue more queries for these purposes, we recommend contacting Goldsky, who can provide the data in a dedicated ClickHouse instance. This can also be tuned to your access patterns and requirements, delivering superior performance and lower latency queries.
Conclusion
We’re delighted to announce that CryptoHouse is now available for our users and the crypto community. This blog post covers some of the technical details.
For readers interested in more details, we’ll deliver a developer-focused session with Goldsky at Solana breakpoint in September, covering the service's internals and the challenges encountered.
We welcome users to raise issues and discussions in the public repository.



