はじめに #
私たちはちょうど1年前に、Gunnar Morling氏のOne Billion Row Challengeに挑み、10億行のテキストファイルをどれだけ速く集計できるかをテストしたことがあります(詳しくはこちら)。
今回、新たなチャレンジとして「One Billion Documents JSON Challenge」を提案します。これは、セミ構造化されたJSONドキュメントの大規模データセットを、各データベースがどれだけ効率的に格納・集計できるかを測定するものです。
このチャレンジに取り組むにあたり、効率的なJSON実装が必要でした。私たちは最近、ClickHouse向けに新たに開発した強力なJSONデータ型について詳しく解説し、この機能が列指向型ストレージに最適なJSON実装である理由を紹介しました。
この記事では、ClickHouseのJSON実装を、他のJSONをサポートするデータストアと比較します。その結果は、きっと驚くべきものだと思います。
これを実現するために、私たちはJSONBenchというベンチマークを開発しました。これは完全に再現可能で、同一のJSONデータセットを次の5つのJSONサポートデータストアにロードします。
- ClickHouse
- MongoDB
- Elasticsearch
- DuckDB
- PostgreSQL
JSONBenchは、ロードしたJSONデータセットのストレージサイズと、5種類の典型的な分析クエリのクエリ性能を評価します。
ここでは、10億件のJSONドキュメントを格納・クエリしたベンチマーク結果の概要をご覧いただけます。
MongoDBと比較すると、ClickHouseはストレージ効率が40%優れており、集計は2500倍も高速です。
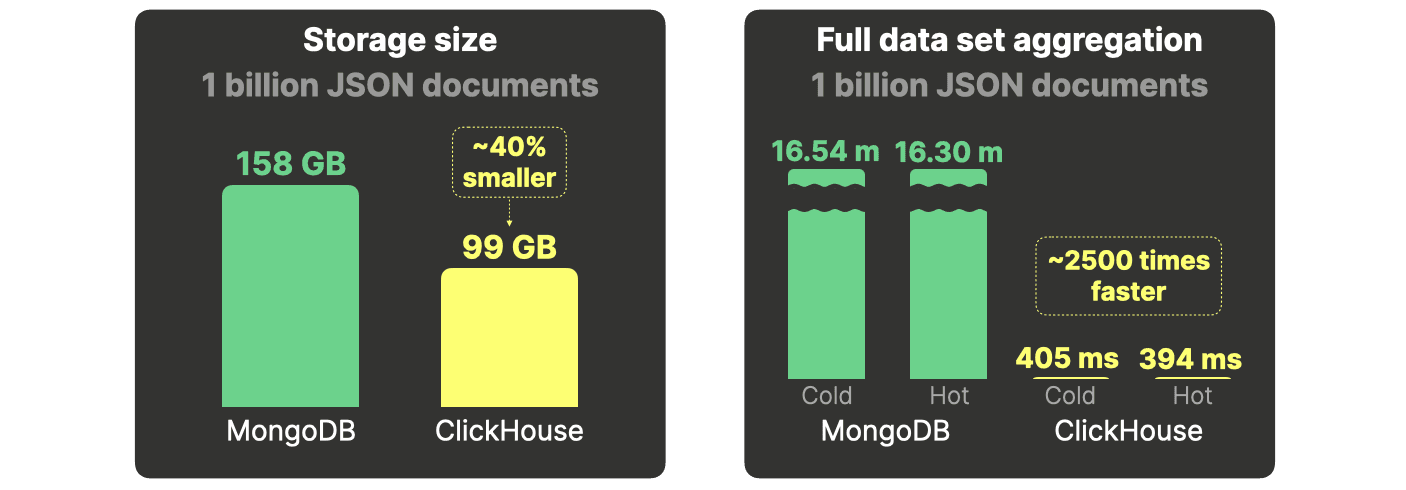
Elasticsearchと比較すると、ClickHouseの必要なストレージ領域は約2分の1で、集計は10倍も高速です。
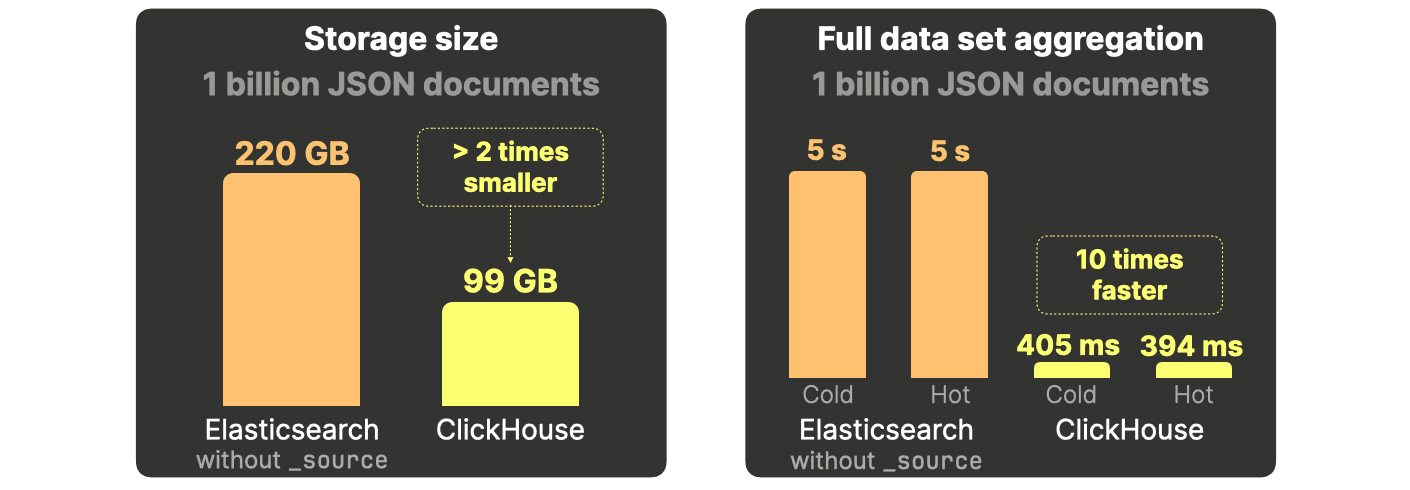
DuckDBと比較すると、ClickHouseはディスク領域を5分の1に抑えられ、分析クエリでのパフォーマンスは9000倍高速です。

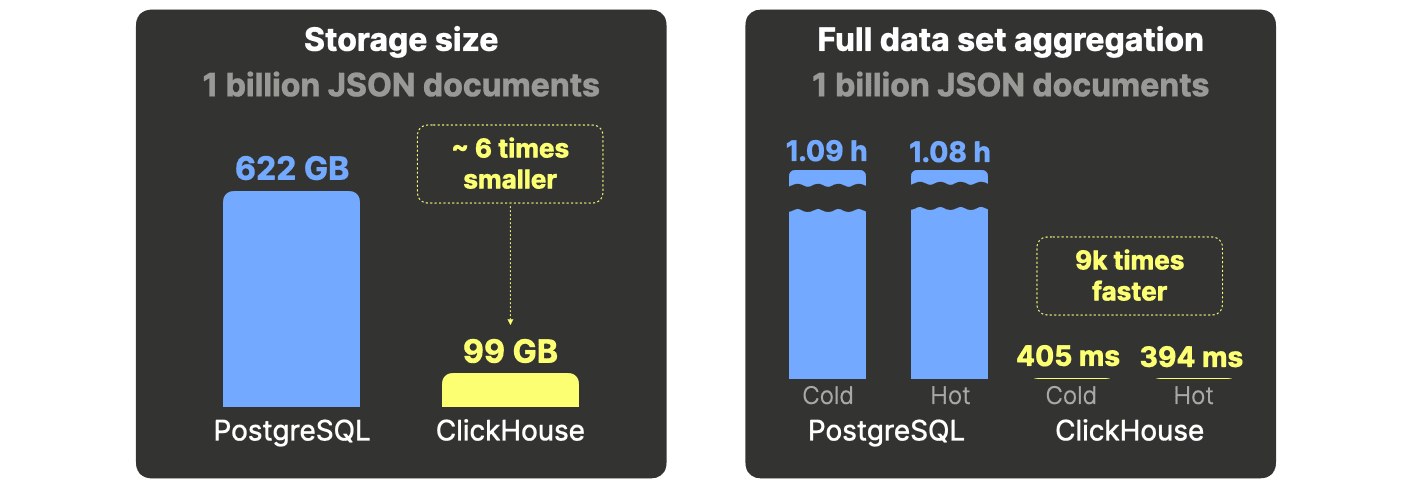
PostgreSQLと比較すると、ClickHouseはディスク使用量が6分の1で、分析クエリは9000倍高速です。
さらに、同じ 圧縮アルゴリズムを使ってファイル として保存する場合と比較しても、ClickHouseはJSONドキュメントを 20%小さく 格納できます。

この記事の残りの部分では、まずテストに使用したJSONデータセットを紹介し、その後に各ベンチマーク対象システムのJSON機能について簡単に概説します(技術的な詳細に興味がない方はこちらからスキップ可能)。次に、ベンチマークの設定、クエリ、手法について説明し、最後にベンチマーク結果を示しながら分析します。
JSONデータセット - 10億件のBlueskyイベント #
今回のテスト用JSONデータセットは、ソーシャルメディアプラットフォームBlueskyのイベントストリームをスクレイピングしたものです。別の記事で、このデータをどのように取得したか詳しく紹介しています。データは自然にJSONドキュメントとして整形されており、各ドキュメントが特定のBlueskyイベント(例:post、like、repostなど)を表現しています。
ベンチマークでは、以下の8つのBlueskyイベントデータセット(下図の①〜⑧)を各システムにロードします。
評価対象システム #
このセクションでは、ベンチマーク対象のシステムが備えるJSON機能、データ圧縮技術、およびインデックスやキャッシュのようなクエリ高速化手段を概説します。これらの技術的詳細を理解することで、今回のベンチマークを公正かつ正確に行うためにどのような設定を行ったかがより明確になります。
技術的な詳細に興味のない方は、こちらからスキップしていただけます。
ClickHouse #
ClickHouseは列型の分析用データベースです。本記事では、JSONデータの取り扱いにおける高い能力を示すため、他のシステムとの比較を行っています。
JSONサポート #
私たちは最近、ClickHouse向けに新しい強力なJSONデータ型を構築しました。これは、本格的なカラム指向ストレージ、動的に変化するデータ構造への対応(タイプ統一が不要)、そして個々のJSONパスへの高速アクセスを可能にするものです。
JSONストレージ #
ClickHouseは、こちらで詳しく解説しているように、各ユニークなJSONパスの値をネイティブカラムとして保存します。これにより高いデータ圧縮率を実現でき、さらに古典的なデータ型と同等の高いクエリ性能を保てます。
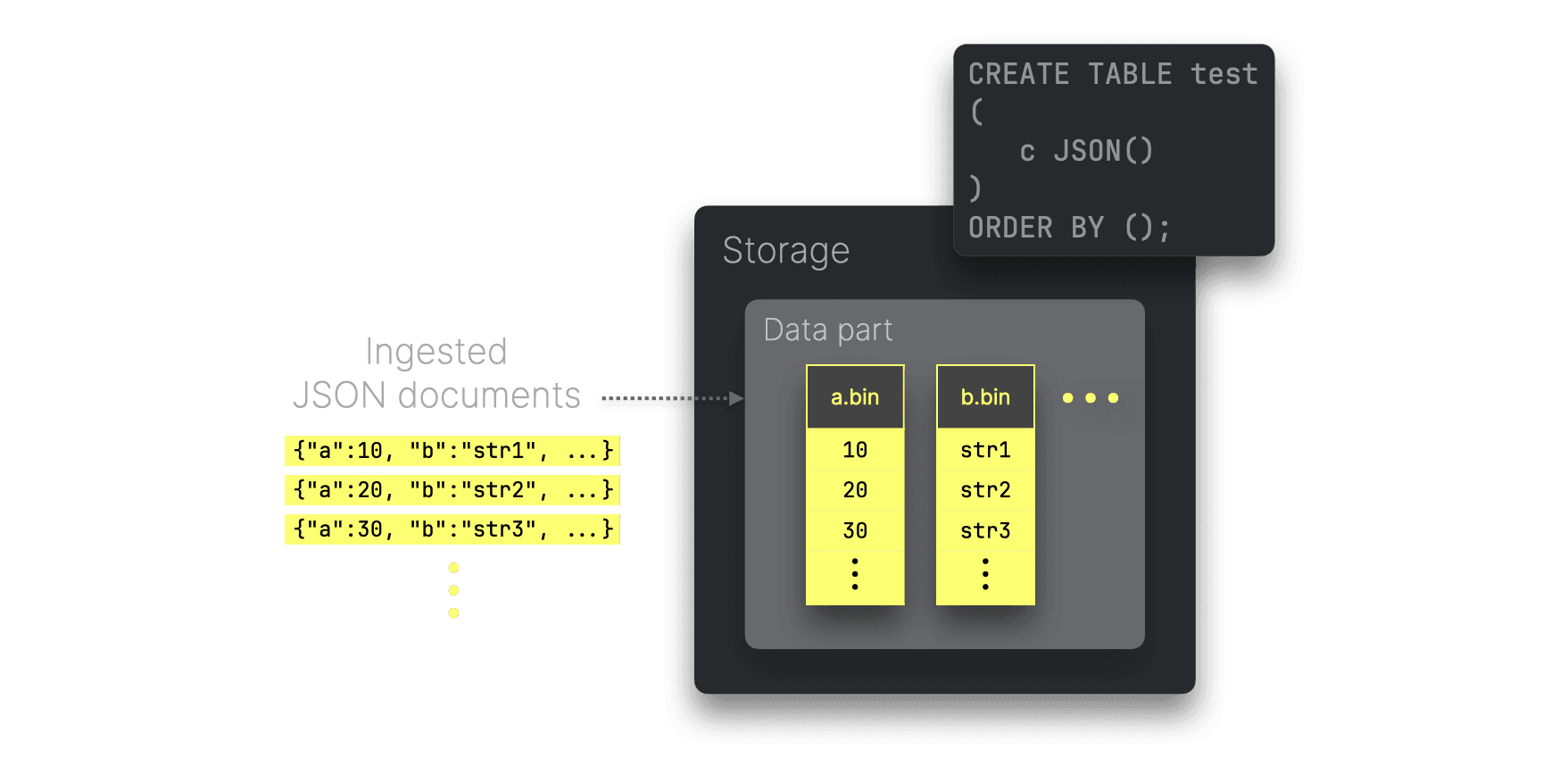
上の図は、各ユニークなJSONパスから取り出された値がどのようにディスク上で別々の(高圧縮された)カラムファイルとして格納されるかの概要を示しています(data part内のファイル)。これらのカラムは独立して参照でき、数個のJSONパスのみを参照するクエリでは不要なI/Oを最小限に抑えられます。
データソートと圧縮 #
ClickHouseのJSON型では、JSONパスをprimary keyに利用できます。これにより、ロードされたJSONドキュメントは各テーブルパーツ内で、これらのパスの値で並べ替えられた形でディスクに保存されます。さらに、ClickHouseは疎なプライマリインデックスを生成し、プライマリキーに対するフィルタクエリを自動的に高速化します。
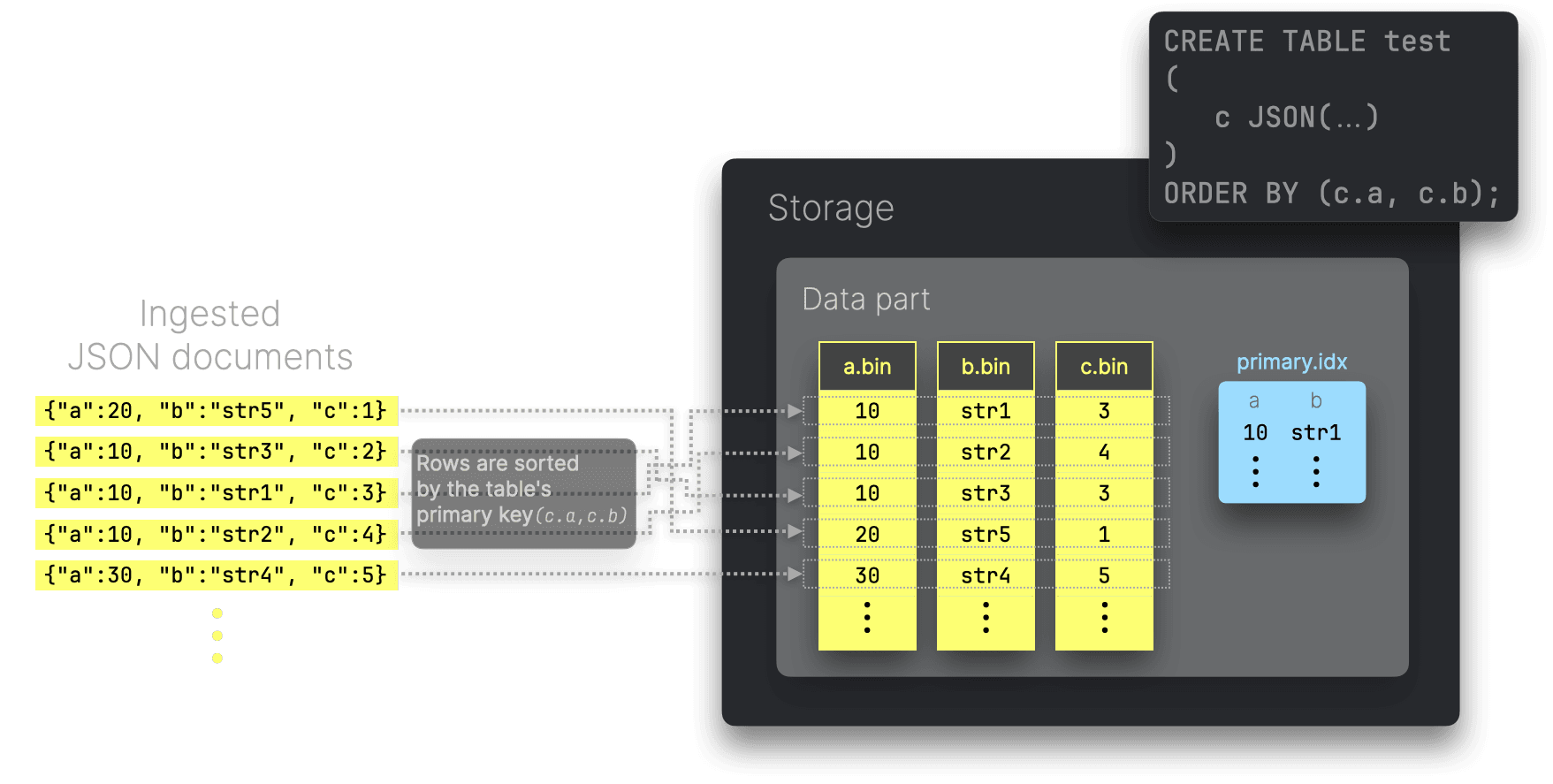
JSONサブカラムをプライマリキーに使うことで、同様のデータが各カラムファイル内でより密に固まるので、適切な順序(カーディナリティの低い順に)並べることで、カラムファイルの圧縮率が高まる可能性があります。さらにオンディスクのデータがソート済みなので、クエリの検索ソート順と物理データのソート順が一致する場合には再ソートが不要になり、早期終了などの最適化も可能です。
柔軟な圧縮オプション #
ClickHouseは、デフォルトではセルフマネージド版でlz4、ClickHouse Cloudではzstdを、各データカラムファイルに対してブロック単位で適用します。
また、個々のカラムごとに使用する圧縮コーデックをCREATE TABLEクエリで指定することもできます。ClickHouseは、汎用コーデック、特殊コーデック、暗号化コーデックなどを連結して利用することも可能です。
JSON型に対しては、現在のClickHouseでは、JSONフィールド全体に対してコーデックを指定できます(例:こちらではデフォルトのlz4からzstdに変更)。将来的には、JSONパス単位でコーデック指定を行う機能も計画されています。
多様なJSONフォーマット対応 #
ClickHouseは、データ読み込みやクエリ結果出力用に20種類以上のJSONフォーマットをサポートしています。
クエリ処理 #
今回のベンチマーク結果で示すように、ClickHouseのクエリ処理は非常に優れています。どのようにJSONデータに対してクエリを実行するのかを簡単に解説します。
前述のとおり、ClickHouseは各ユニークなJSONパスの値を、従来のデータ型(例:整数)と同様に格納しているため、JSONデータであっても高パフォーマンスの集計を可能にします。
インターネット規模のアナリティクス向けに構築されたClickHouseは、90種類以上の組込み集計関数をフルに並列化し、利用可能なすべてのリソースを使って効率的にデータをフィルタ・集計します。たとえば、avg集計関数の場合は以下のイメージです。
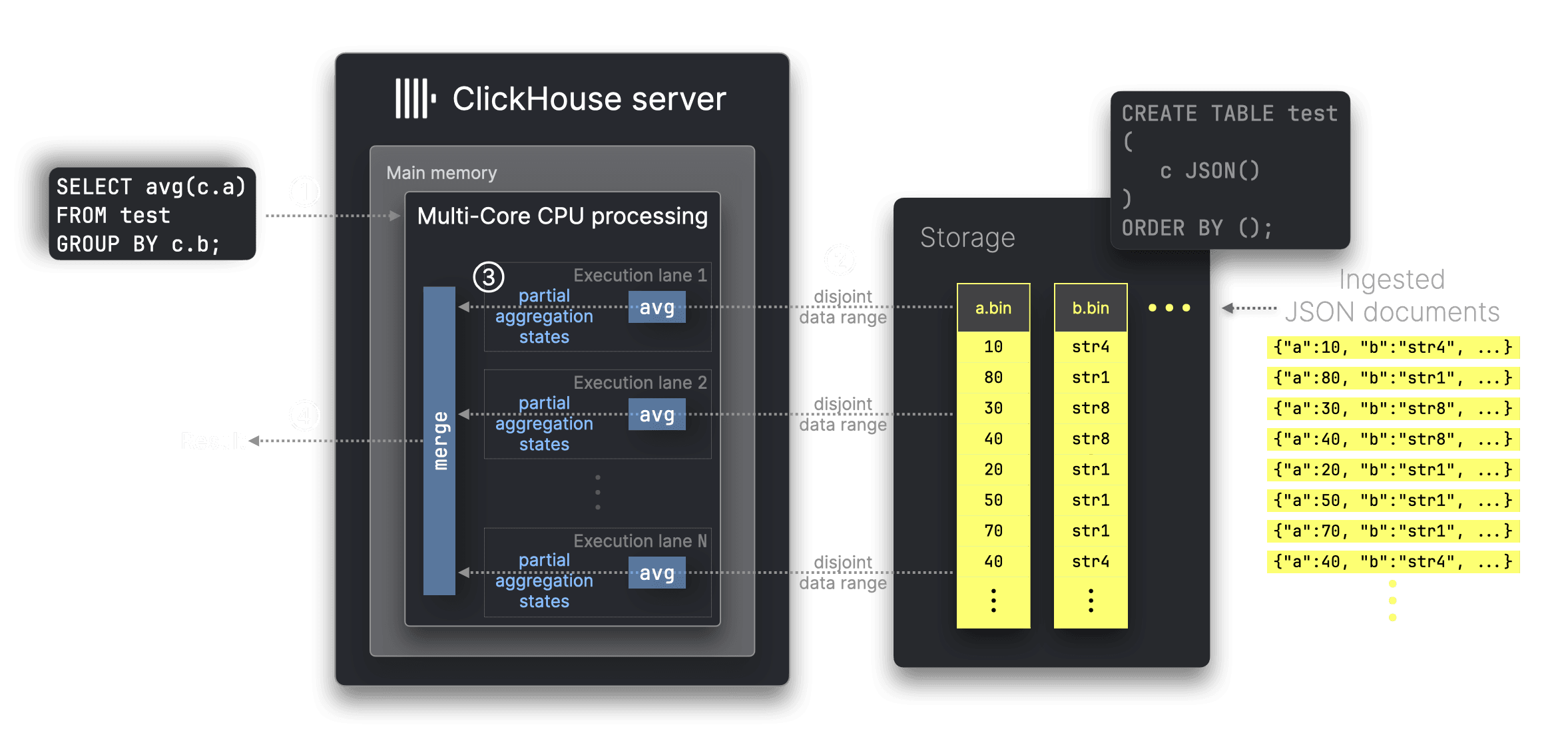
上の図では、① c.aとc.bという2つのJSONパスに対するavg集計クエリを処理しています。ClickHouseは対応するカラムファイルa.binとb.binのみを読み込み、単一サーバ内の32CPUコアなどでN個のデータ範囲を並列に処理します(クエリ対象の行をN分割して並列計算)。集計キーとは無関係にデータ範囲を動的に分割できるため、負荷分散が最適化されます。この並列化は部分集計ステートを用いることで可能になります。
本ベンチマークのClickHouseでは、物理実行プランも取得しています。たとえば、こちらでは、benchmark query ①の10億行フルスキャン集計を、CPUコア32個をフル活用して並列実行している様子が分かります。
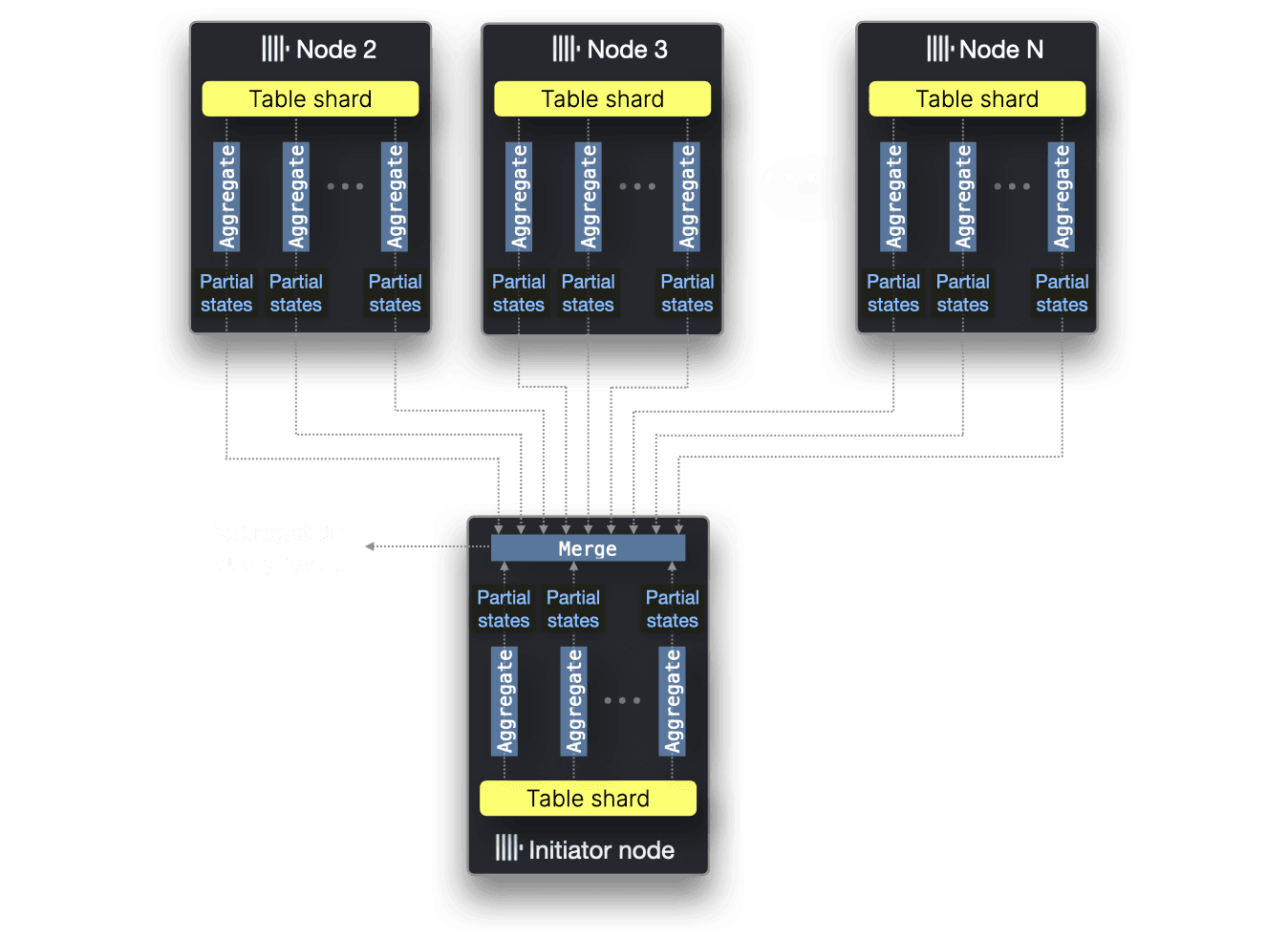
マルチノードでの並列化 #
今回のベンチマークはシングルノード性能のみを比較していますが、もしテーブルがシャード分割されて複数ノードにデータが分散している場合、ClickHouseはすべてのノードのCPUコアを使って集計関数を並列化し、全体を処理できます。
キャッシュ #
ClickHouseはクエリ処理中に組込みのキャッシュやOSページキャッシュを使います。たとえばデフォルトでは無効になっていますが、クエリ結果キャッシュも備えています。
MongoDB #
MongoDBは最も有名なJSONデータベースの一つです。
JSONサポート #
MongoDBは、あらゆるデータをBSONドキュメントとしてネイティブに格納します。BSONはJSONをバイナリ表現した形式です。
JSONストレージ #
MongoDBのデフォルトストレージエンジンWiredTigerは、ディスク上のデータをページ単位のB-Tree構造で管理します。ルートノードおよび中間ノードにはキーと他ノードへの参照が格納され、リーフノードにはBSONドキュメントを保持するデータブロックがあります。
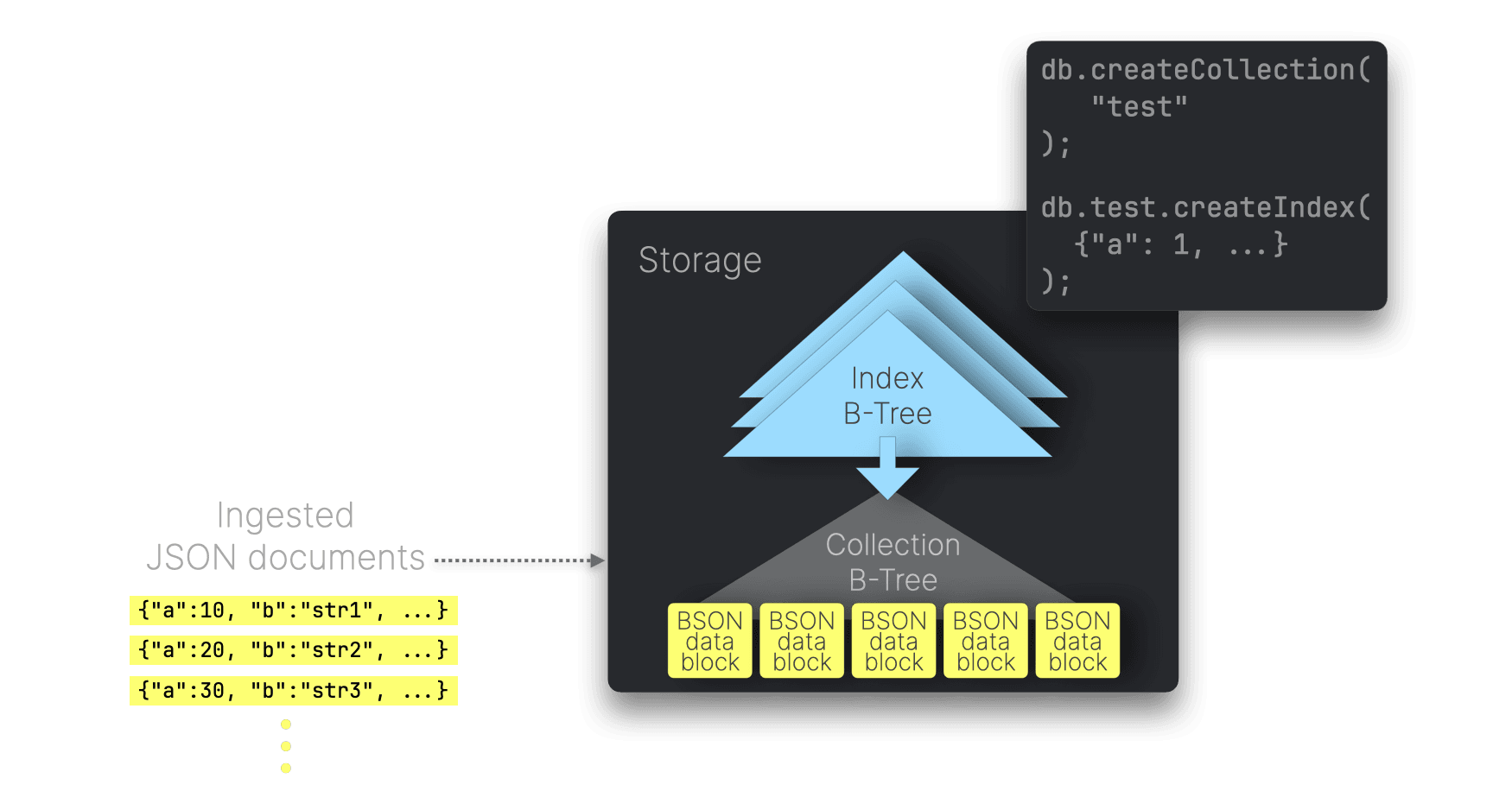
MongoDBでは、JSONパス上にセカンダリインデックスを作成できます。これらのインデックスはB-Treeで構成され、挿入された各JSONドキュメントに対して該当のJSONパスの値がノードに格納されます。これらのインデックスはメモリに読み込まれ、クエリプランナーが高速にツリーを探索して該当ドキュメントを特定し、その後ディスクから読み込んで処理します。
Covered index scans #
クエリがインデックス化されたJSONパスのみを参照する場合、MongoDBはディスク上のドキュメントを読み込まずにインデックスのみでクエリを完了できます。これをcovered queryと呼び、covered index scanによって実現されます。
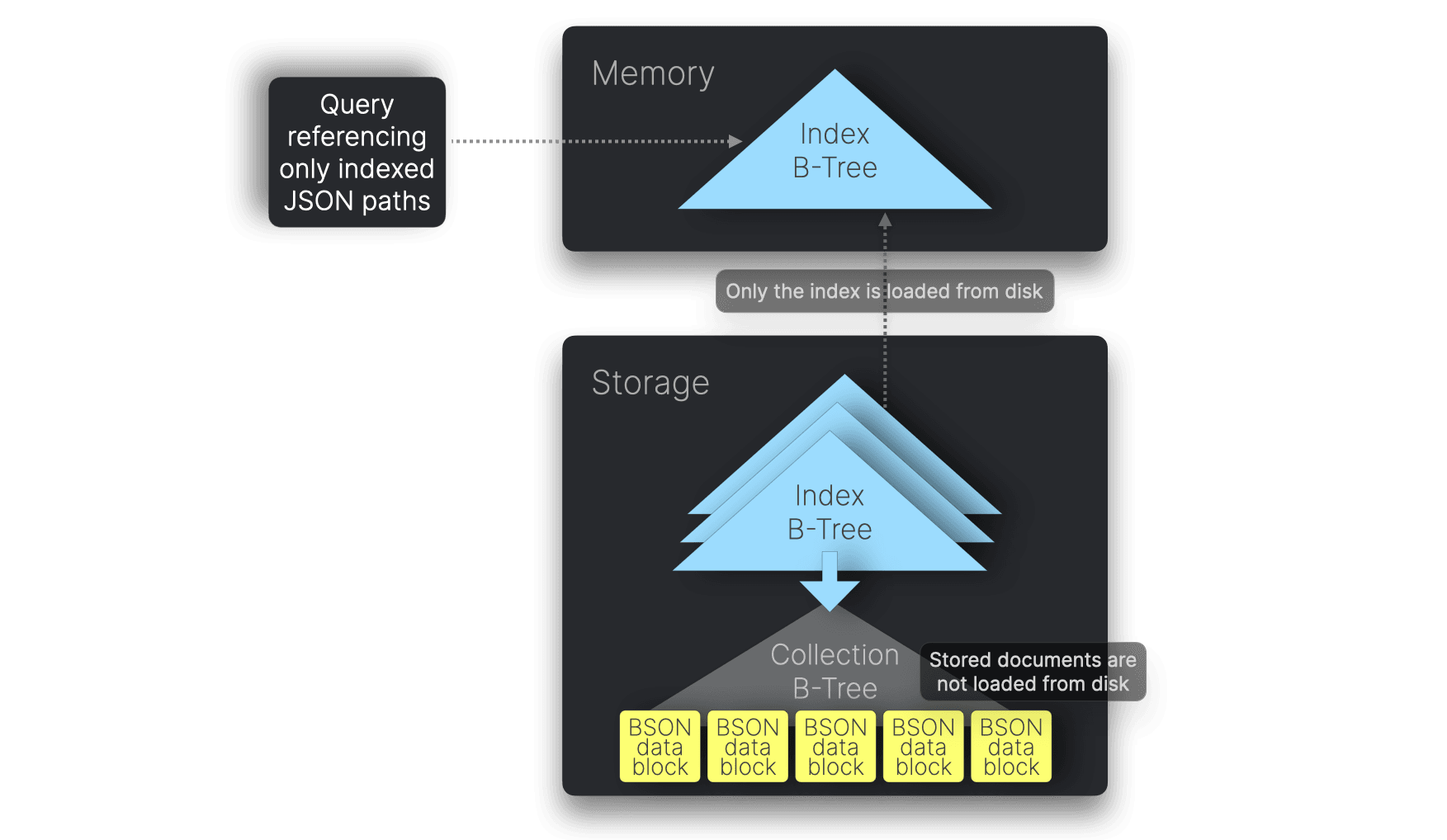
私たちのベンチマークでのMongoDBクエリ5種はすべてcovered queryです。これは、デフォルトの複合インデックスがクエリに必要なすべてのフィールドを含んでいるためです。ベストプラクティスに従い、明示的にcovered index scansを有効化しています。
こちらのクエリ実行プランを見れば確認できます。例えば10億ドキュメントを格納したコレクションに対するクエリでは、IXSCANステージのみが表示され、COLLSCANやFETCHステージがありません。一方、covered index scanを有効にする前の古いプラン(参考)では、COLLSCANやFETCHが含まれ、ドキュメントをディスクから読み込んでいたことが分かります。
このメソッドはインデックスがメモリに載ることが条件となります。今回のテストマシン(128 GB RAM)では、10億件データセットでの27 GBインデックスを十分格納できますが、シャーディングされたセットアップなどでは、インデックスのメモリ搭載性に注意が必要です(インデックスがシャードキーを含む必要など)。
データ圧縮 #
WiredTigerは、コレクションにsnappyを使ったブロック圧縮、インデックスにprefix compressionをデフォルトで適用します。代わりにzstd圧縮を有効にして圧縮率を高めることも可能です。
データソート #
MongoDBは、clustered collectionsを介してドキュメントを特定のclustered indexの順に格納し、類似データをまとめることで圧縮率を向上させる機能を備えます。しかし、clustered indexキーはユニークであり、8 MBという最大サイズ制限があるため、今回のテストデータには適用できませんでした。
キャッシュ #
MongoDBはWiredTiger内部キャッシュやOSページキャッシュを利用し、専用のクエリ結果キャッシュは持ちません。WiredTigerキャッシュには最近アクセスされたデータとインデックスが格納され、デフォルトでは利用可能RAMの50% - 1GBが割り当てられます。このキャッシュはMongoDBサーバを再起動しない限りクリアされません。
制限事項 #
ベンチマークに含まれるJSONのtime_usフィールドはマイクロ秒精度の日付です。しかしMongoDBはミリ秒精度しかサポートしていません。一方でClickHouseはナノ秒精度まで扱えます。
また、MongoDBの集計フレームワークはビルトインのCOUNT DISTINCT演算子を備えていません。代替として、ベンチマークのクエリ②では、より非効率な$addToSetを使っています。
Elasticsearch #
ElasticsearchはJSONベースの検索・分析エンジンです。
JSONサポート #
ElasticsearchはJSONドキュメントをネイティブに受け取って格納します。
JSONストレージとデータ圧縮 #
Elasticsearchで取り込まれたJSONデータは、特定のアクセスパターンに最適化された複数のデータ構造としてインデックス化・保存されます。これらの構造はLuceneが管理するセグメント内に格納されます。LuceneはElasticsearchの検索と分析の中核となるJavaライブラリです。
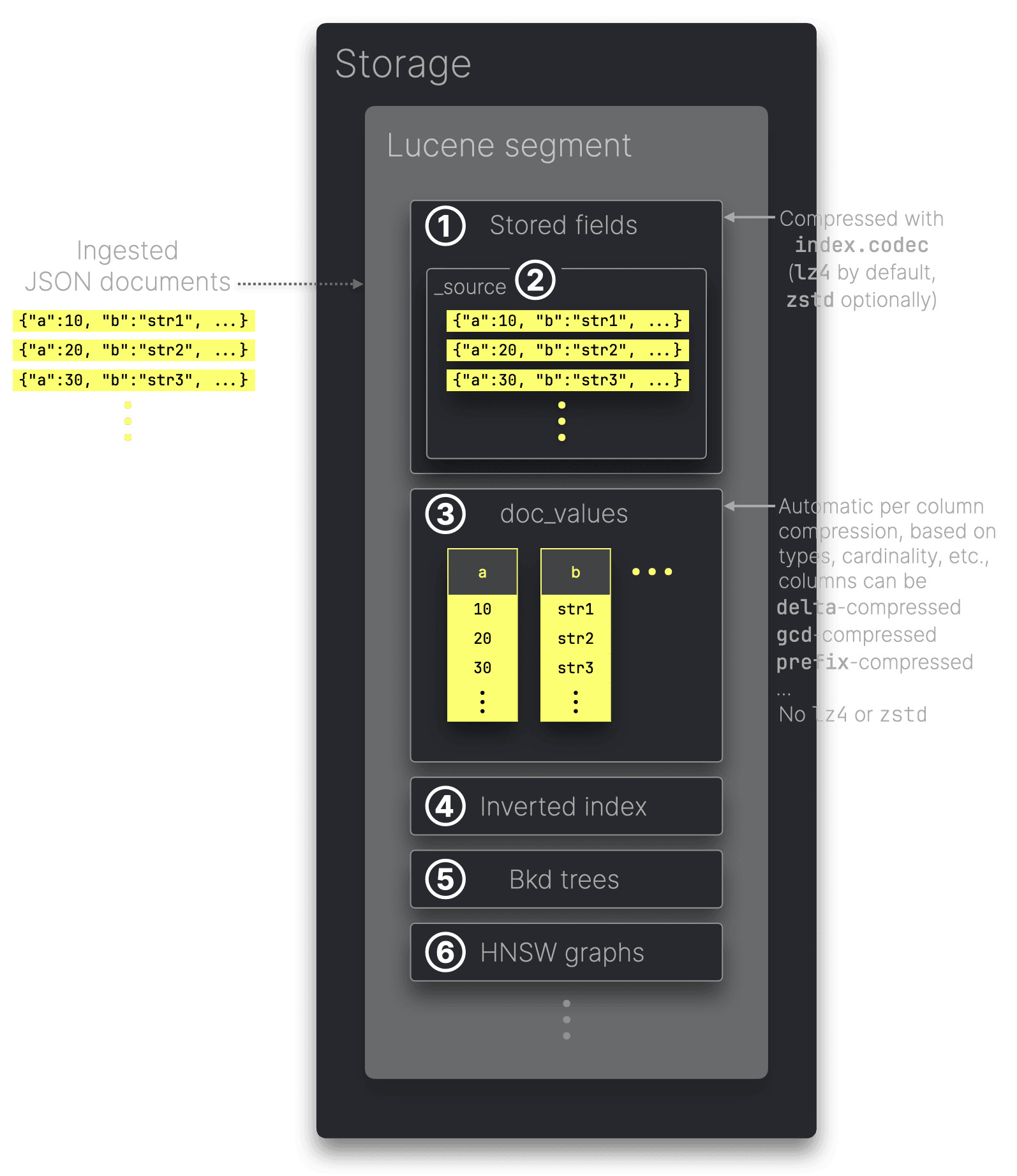
① Stored fieldsはフィールドのオリジナル値を返却するためのドキュメントストアとして機能します。デフォルトでは② _sourceもここに含まれ、取り込まれたJSONドキュメントの原文を保持します。_sourceやその他stored fieldsは、index.codec設定(デフォルトはlz4、より圧縮率の高いzstdも可)で指定されるアルゴリズムで圧縮されます。
③ Doc_valuesには、JSONドキュメントのフィールド値がカラム指向のオンディスク構造で格納されます。分析クエリでの集計・ソートのパフォーマンス向上を目的としています。ただし、doc_valuesにはlz4やzstdは使われません。各カラムはLuceneのエンコーディングによって特殊に圧縮され、データ型やカーディナリティなどに応じて最適なエンコーディング方式が選択されます。
こちらで、④ inverted index、⑤ Bkd-tree、⑥ HNSQ graphsなどの他のLuceneセグメント構造についても詳しく解説しています。
_sourceの役割 #
オープンソース版Elasticsearchにおいて、_sourceフィールドはreindexingや新バージョンへのアップグレードなどで必要不可欠であり、またオリジナルドキュメントを返すクエリでも使われます。一方、これを無効化するとストレージサイズは大きく削減されるものの、これらの機能が失われます。
Elasticsearchのエンタープライズ版では、synthetic _sourceを利用して、_sourceを他のLuceneデータ構造から再構築することが可能です。
今回のベンチマーククエリはdoc_valuesを利用して集計結果を返すため、オリジナルドキュメントを返す必要はありません。したがって、OSS版Elasticsearchで_sourceをオフにすることでEnterprise版のsynethic _source機能による省ストレージ効果をシミュレートしています。比較のため、_sourceを有効にした場合も計測しています。
公平なストレージ比較のためのElasticsearch設定 #
前述のように、Elasticsearchは様々なデータ構造(inverted index、doc_values など)にデータを格納し、用途ごとに最適化しています。今回のベンチマークは分析処理を中心とするため、以下のように設定しました:
- Inverted indexのサイズを最小化: 文字列をすべてkeywordとして扱い、フルテキスト検索を無効化(これにより
doc_valuesに値が格納され、分析クエリに最適化)。 - 日付フィールドマッピング: 取り込んだドキュメントの日時フィールドをdate型としてマッピングし、LuceneのBkdツリーを利用。
- ストレージオーバーヘッドの削減: meta-fieldsを無効化し、JSONデータからのフィールドのみを保持。_sourceをオフにして、synthetic _sourceに近い状態をシミュレート。
- Index sortingの有効化: ClickHouseのソートキーと同じフィールドでソートし、データの圧縮とクエリ性能を向上。
- シングルノード最適化: レプリカを無効化。
- ロールオーバーとマージの最適化: ベストプラクティスに従い、ロールオーバーとマージを設定。
以下の図は、本ベンチマークにおけるElasticsearchのデータ構造構成を要約したものです。
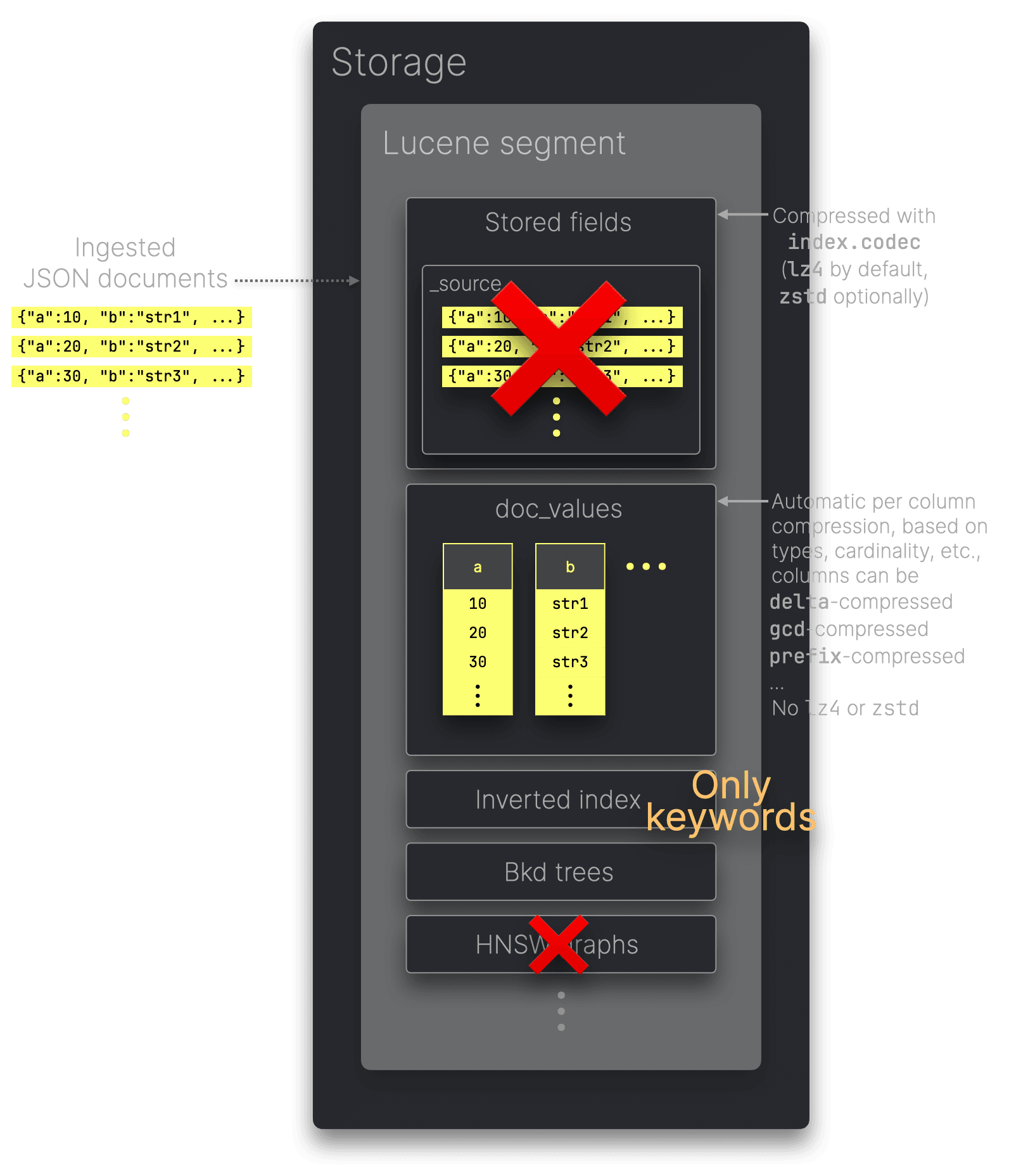
なお、_sourceをオフにすると、index.codecで指定した圧縮アルゴリズムはほぼ意味をなしません。stored fieldsとして扱うデータが無くなるためです。同様の設定でlz4とzstdを比較してもディスク使用量がほとんど変わらないのはこのためです。
データソート #
Elasticsearchはデータのソートを有効化することで、stored fieldsやdoc_valuesが連続した似通ったデータとして圧縮される形を促進し、クエリの早期終了(early termination)を可能にします。これはClickHouseの仕組みにも似ています。
キャッシュ #
ElasticsearchはOSページキャッシュに加え、シャードレベルのrequest cacheやセグメントレベルのquery cacheなど複数のキャッシュを使用します。
さらに、ElasticsearchはJavaのJVM上でクエリを実行するため、起動時に物理RAMの半分程度をヒープとして割り当てます(最大32 GBまで)。残りのRAM領域はOSページキャッシュ経由でディスクI/Oを高速化します。
制限事項 #
大規模分析やオブザーバビリティのようなユースケースでは、数十億行にわたるテーブルに対してcount(*)やcount_distinct(...)を行うクエリが非常に一般的です。
この観点から、私たちのベンチマーククエリもcount(*)を多用し、query ②ではcount_distinct(...)も実行します。
Elasticsearchでcount(*)を実行すると、複数シャードにまたがる場合は近似値しか得られません。ES|QLのCOUNT_DISTINCT集計関数も同様で、HyperLogLog++アルゴリズムを用いた近似値となります。
一方、ClickHouseはcount(*)を完全に正確に計算し、count_distinct(...)についても近似と厳密の両方をサポートしています。query ②では厳密なバージョンを使用しています。
また、今回のBlueskyテストデータに含まれるtime_usはマイクロ秒精度のタイムスタンプです。Elasticsearchでもdate_nanos型でナノ秒精度の日付を保存できますが、ES|QLの日付/時刻関数はdate型(ミリ秒精度)しか対応していません。そのため、本ベンチマークではtime_usをミリ秒精度のdate型として格納しています。
ClickHouseでは日付/時刻関数がナノ秒精度まで扱えます。
DuckDB #
DuckDBはシングルノード環境向けに設計された列指向型分析データベースです。
JSONサポート #
DuckDBは2022年にJSON論理型を導入しました。
JSONストレージ #
DuckDBは列指向型データベースですが、現状ClickHouseほどJSONを分解して格納しません。DuckDBテーブル内のJSONカラムでは、取り込まれたJSONドキュメントが文字列として保存されます(解析済みの構造として保存されない)。
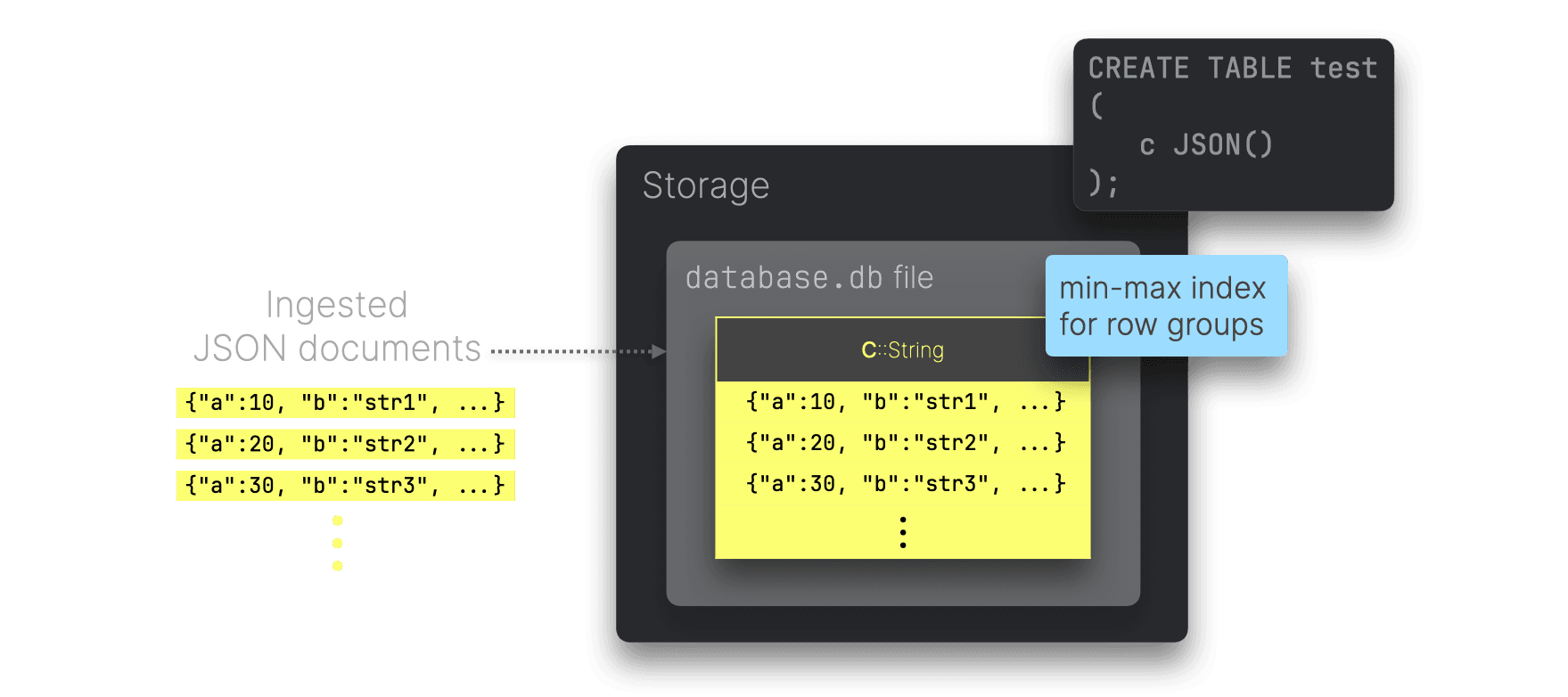
DuckDBはデフォルトで最小最大インデックスを自動生成します。これにより、高速なフィルタリングや集計をサポートしますが、これは行グループごとに保存された最小値と最大値を利用するしくみです。
また、Adaptive Radix Tree(ART)インデックスを指定して作成できますが、制限があり、非常に選択度の高いポイントクエリや約0.1%以下の行を対象とするフィルタクエリでしか効果を発揮しません。
データ圧縮 #
DuckDBは自動的に軽量圧縮アルゴリズムを選択し、カラムごとに圧縮を適用します。
データソート #
DuckDBのドキュメントでは、事前にソートした状態でデータを挿入し、類似値をまとめることで圧縮効率や最小最大インデックスの効果を高めることが推奨されています。ただしDuckDB自体が自動でデータをソートするわけではありません。
キャッシュ #
DuckDBはOSページキャッシュと内部のバッファマネージャを使用し、ストレージから読み込んだページをキャッシュします。
PostgreSQL #
PostgreSQLは古くからある行指向のリレーショナルデータベースで、JSONを一級サポートしています。私たちは、行指向データベースとしてDuckDBやClickHouseのような最新列指向型データベースと比較するために取り上げました。ただし、PostgreSQLは大規模分析向けではないため、JSONBenchのようなテストではスペック的に不利で、他のシステムと直接競合するわけではありません。
JSONサポート #
PostgreSQLはJSONとJSONBの2種類のJSONデータ型をネイティブサポートしています。
- JSON型:2012年リリースのPostgreSQL 9.2で導入。文字列として保存し、使用時に再度パース。
- JSONB型:2014年リリースのPostgreSQL 9.4で導入。BSONに類似するバイナリ形式で保存され、高速な検索や機能が利用可能。
最新の推奨は性能面でも機能面でも優れるJSONBとなります。
JSONストレージ #
PostgreSQLは行指向データベースなので、JSONBタプルをディスク上で行単位に順次格納します。
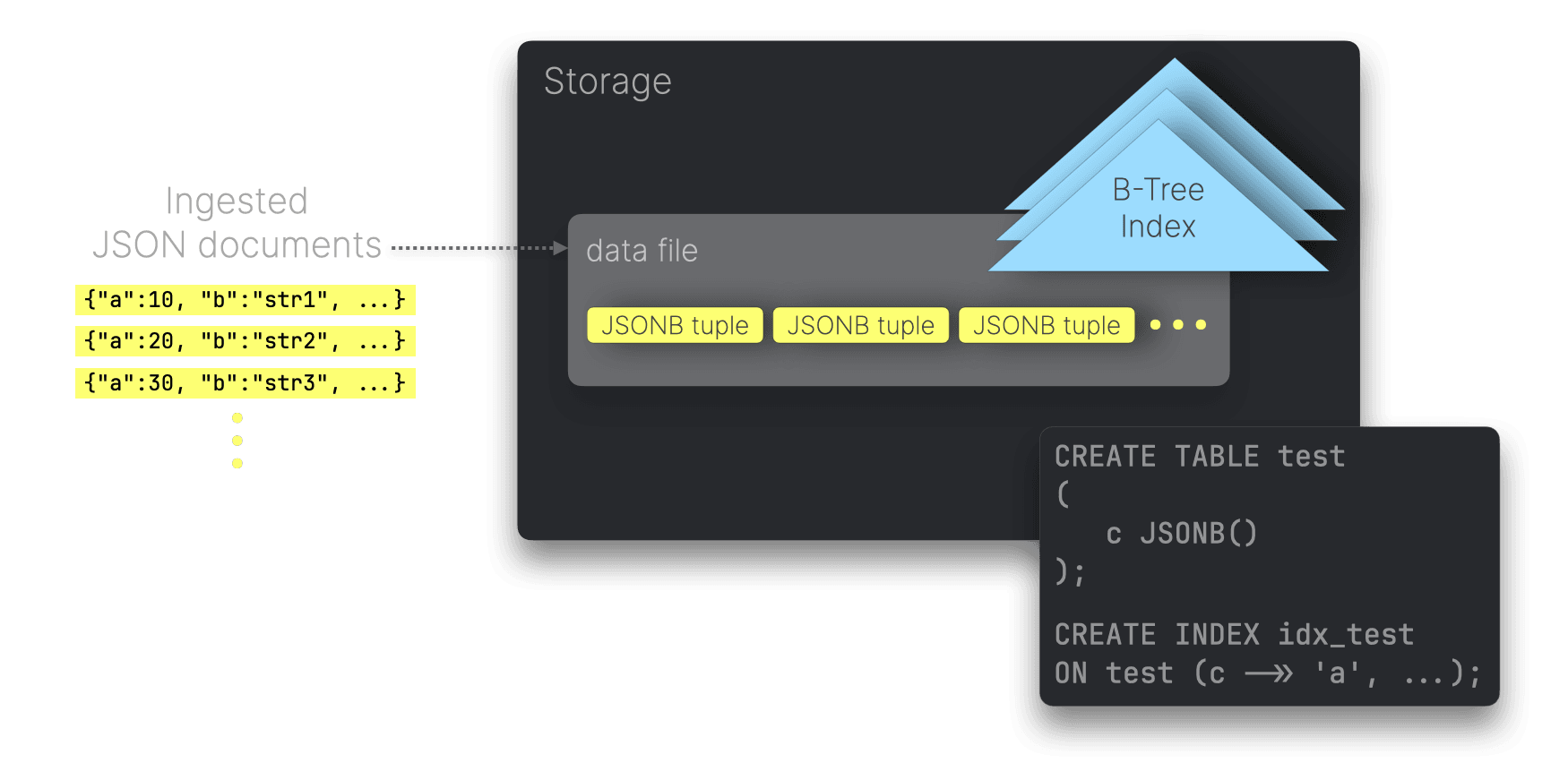
ユーザーはCREATE INDEXによって特定のJSONパスにセカンダリインデックスを作成できます。デフォルトではB-Treeインデックスで、各行に対してインデックスのエントリが1つ、インデックスにはJSONパスの値が格納されます。
Index-only scan #
PostgreSQLはB-Treeインデックスでindex-only scanをサポートしており、covered index scansに類似した最適化が可能です。ただし、自動ではなく可視性マップによりテーブルの行が「可視」としてマークされている必要があります。これによりテーブルを読まずにインデックスだけでクエリを完結できます。
私たちのベンチマークでは、PostgreSQLのクエリ実行プランを取得して、index-only scanが行われているか検証しています。
データ圧縮 #
PostgreSQLは行ごとに8 KBのページをディスク上に配置し、各ページにできるだけ多くのタプルを詰め込みます。理想的にはタプルは2 KB以内が望ましいです。2 KBを超えるタプルはTOAST機構によって圧縮・分割されます。TOASTはpglzやlz4などをサポートし、2 KB以下のタプルは圧縮されません。
データソート #
PostgreSQLはCLUSTERコマンドで物理的にテーブルをソートする「clustered tables」をサポートします。しかし、ClickHouseやElasticsearchのようにデータのソート順で圧縮率が向上するわけではなく、PostgreSQLは行指向なので行内のデータがまとめて格納されるためです。実際には2 KB以上のタプルのみTOASTで圧縮され、データソートによる恩恵は限定的です。
キャッシュ #
PostgreSQLはクエリ実行プランやテーブル/インデックスブロックをキャッシュし、OSページキャッシュも利用します。ただし、専用のクエリ結果キャッシュはありません。
ベンチマーク設定 #
ClickBenchを参考に、私たちはJSONBenchという完全再現可能なベンチマークを作成しました。詳細な利用手順はこちらからご覧いただけます。
ハードウェアとOS #
ベンチマークはすべて、専用のAWS EC2 m6i.8xlargeインスタンス(32 CPUコア、128 GB RAM、10 TB gp3ボリューム)上で行いました。OSはUbuntu Linux 24.04 LTSです。
評価システムのバージョン #
以下のOSSバージョンを使用してベンチマークを行いました(すべてJSONを一級サポート):
- ClickHouse 25.1.1
- MongoDB 8.0.3
- Elasticsearch 8.17.0
- DuckDB 1.1.3
- PostgreSQL 16.6
測定項目 #
ベンチマークでは、ストレージサイズとクエリ性能を評価し、それぞれデフォルトの圧縮設定と最高の圧縮設定でテストしました。
システムの introspection 機能に応じて、以下の項目も計測しています:
-
インデックスのストレージサイズ
- ClickHouse 例
- MongoDB 例
- PostgreSQL 例
-
データのみのストレージサイズ(インデックスを除く)
- ClickHouse 例
- MongoDB 例
- PostgreSQL 例
-
トータルストレージサイズ(データ + インデックス)
- ClickHouse 例
- MongoDB 例
- Elasticsearch 例
- DuckDB 例
- PostgreSQL 例
-
各クエリの実行プラン(インデックス利用などの検証用)
- ClickHouseの論理プランと物理プランの例
- MongoDBの例
- DuckDBの例
- PostgreSQLの例
-
クエリごとの最大メモリ使用量
ベンチマーククエリ #
各システムについて、コールド/ホットのパフォーマンスを含め、5種類の分析クエリを8つのデータセットに対して順番に実行しました。
ClickHouse、DuckDB、PostgreSQL向けにはSQL、MongoDBにはaggregation pipeline、ElasticsearchにはES|QLを使用しました。それらが同等の処理であることを示すため、1百万件データセットに対する実行結果をリンク先に載せています(1百万件なら完全にロードできるので結果を完全比較可能)。
Query ① - Blueskyのイベント種類トップ #
- ClickHouse版 + 結果
- MongoDB版 + 結果
- Elasticsearch版 + 結果
- DuckDB版 + 結果
- PostgreSQL版 + 結果
Query ② - Blueskyのイベント種類トップとユーザー数 #
- ClickHouse版 + 結果
- MongoDB版 + 結果
- Elasticsearch版 + 結果
- DuckDB版 + 結果
- PostgreSQL版 + 結果
Query ③ - Blueskyはいつ使われるか #
- ClickHouse版 + 結果
- MongoDB版 + 結果
- Elasticsearch版 + 結果
- DuckDB版 + 結果
- PostgreSQL版 + 結果
Query ④ - もっとも古参の投稿者トップ3 #
- ClickHouse版 + 結果
- MongoDB版 + 結果
- Elasticsearch版 + 結果
- DuckDB版 + 結果
- PostgreSQL版 + 結果
Query ⑤ - もっとも活動期間が長いユーザートップ3 #
- ClickHouse版 + 結果
- MongoDB版 + 結果
- Elasticsearch版 + 結果
- DuckDB版 + 結果
- PostgreSQL版 + 結果
ベンチマーク手法 #
この記事では、最大10億件のBluesky JSONドキュメントを取り込み時のストレージサイズと、5種類の典型的分析クエリ(連続実行)の性能を比較しました。
評価は、5つのオープンソースJSON対応データストアを単一ノードで動かし、定義済みの手法に従って行いました。以下に手法を説明します。
チューニングなし #
ClickBenchと同様に、すべてのシステムは標準設定のまま、特別なチューニングは行っていません。
例外として、MongoDBのクエリ②で以下のエラーが発生しました。
MongoServerError[ExceededMemoryLimit]: PlanExecutor error during aggregation :: caused by :: Used too much memory for a single array. Memory limit: 104857600. Current set has 2279516 elements and is 104857601 bytes.
これはCOUNT DISTINCTがないために使っている$addToSet演算子がデフォルトで100MBの制限を超えてしまったことが原因です。対応として、internalQueryMaxAddToSetBytesを引き上げました。
また、ベストプラクティスに従い、MongoDBのカバードインデックススキャンを有効化するため、internalQueryPlannerGenerateCoveredWholeIndexScansをオンにしました。結果として、ベンチマーククエリのMongoDBはすべてcoveredクエリとなり、これが有効でない場合の実行時間よりも大幅に速くなります。
クエリ結果キャッシュなし #
ElasticsearchやClickHouseのように、クエリ結果キャッシュを有効化すると、その後の実行はキャッシュから即座に結果を返せます。しかしこれではベンチマークとして有意義な比較にならないため、全システムでクエリ結果キャッシュを無効化・クリアしています。
トップレベルのフィールド抽出はなし #
今回の目的は、「各システムのJSONデータ型」の性能比較に集中することです。そこで、テスト対象の各システム・データ構成では、単一のJSON型フィールドのみを持つテーブル*に制限しました。
ClickHouseのDDL例:
1CREATE TABLE bluesky ( 2 data JSON 3) ORDER BY();
DuckDBのDDL例:
1CREATE TABLE bluesky ( 2 data JSON 3);
PostgreSQLのDDL例:
1CREATE TABLE bluesky ( 2 data JSONB 3);
MongoDBやElasticsearchはリレーショナルDBではないため、DDLはやや異なりますが、同様に「単一フィールド(ドキュメント単位)でJSONを扱う」概念で比較しています。
ClickHouseのDDLではプライマリキーを指定するためにJSONパスと型ヒントをJSON型の定義内部で指定しています。一方、DuckDBやPostgreSQLはセカンダリインデックスをCREATE TABLE後に作成し、同じ目的を達成しています。詳細は次のセクションを参照してください。
一部のJSONパスだけインデックス&データソート可 #
今回のベンチマーククエリを高速化するため、各システムで以下のJSONパスに対するインデックス(または相当する機能)を作成できるようにしました:
- kind: 大部分のBlueskyイベント構造を分岐させるパス(
commit,identity,accountなどがある) - commit.operation:
commitイベントがcreate,delete,updateのどれかを表す - commit.collection:
commitイベントの種類(例:post,repost,likeなど) - did: イベントを引き起こしたBlueskyユーザーのID
- time_us: Blueskyタイムスタンプの不一致問題を簡単化するため、すべてのイベントがこのタイムスタンプ(実際にはAPI取得時刻)を持つとみなす
DuckDBとElasticsearchを除く全システムでは、これらのパスを1つの複合インデックスにまとめました(カーディナリティの低い順で並べる)。
1(kind, commit.operation, commit.collection, did, time_us)
ClickHouseでは、プライマリキー/ソートキーを同等に設定しました:
1ORDER BY ( 2 data.kind, 3 data.commit.operation, 4 data.commit.collection, 5 data.did, 6 fromUnixTimestamp64Micro(data.time_us));
MongoDBでは、セカンダリインデックスを作成:
1db.bluesky.createIndex({ 2 "kind": 1, 3 "commit.operation": 1, 4 "commit.collection": 1, 5 "did": 1, 6 "time_us": 1});
PostgreSQLでは、セカンダリインデックスを作成:
1CREATE INDEX idx_bluesky
2ON bluesky (
3 (data ->> 'kind'),
4 (data -> 'commit' ->> 'operation'),
5 (data -> 'commit' ->> 'collection'),
6 (data ->> 'did'),
7 (TO_TIMESTAMP((data ->> 'time_us')::BIGINT / 1000000.0))
8);
DuckDBでは、利用可能なインデックスを使っても今回のベンチマーククエリに利点がないと判断し、データソートも自動化されません。
Elasticsearchはセカンダリインデックスの概念はありませんが、doc_valuesを自動的に作成し、index sortingによって最適化を行います。ClickHouseのソートキーと同じJSONパスでインデックスソートを行っています。
MongoDBとPostgreSQLでインデックスオンリースキャンを許容 #
多くのベンチマーククエリでkind, commit.operation, commit.collectionによるフィルタ(3つ同時)が行われますが、これらも複合インデックスを利用しています。
didやtime_usはクエリでフィルタされませんが、MongoDBやPostgreSQLでindex-only scanを有効化するには、クエリが参照する列をすべてインデックスに含める必要があります。ClickHouseの場合は、didやtime_usもプライマリキーに含めることでディスクサイズ比較をより正確にできるようにしています。
クエリ実行プランからインデックス利用を検証 #
前述したように、私たちは各システムのクエリ実行プランを解析して、ベンチマーククエリが意図したインデックスを正しく利用しているかを検証しました。
データセット件数に多少の差異は許容 #
大規模なJSONデータセットでは、一部のシステムが特定ドキュメントをパースできず読み込めないケースがしばしば起こります。実装の違いやフォーマットの例外などが原因です。
今回のベンチマークでは、100%完璧にロードできなくても構わないという前提としました。ロードできたドキュメント数が元データセットサイズに近似していれば、性能やストレージ比較には十分だと考えています。
結果として、ベンチマークではdataset_size(予定行数)と、実際にロードできた行数(num_loaded_documents)を記録しています。
例えば10億ドキュメントの場合、各システムでロードできた行数は以下のとおりでした:
- ClickHouse: 999,999,258件
- MongoDB: 893,632,990件
- Elasticsearch: 999,998,998件
- DuckDB: 974,400,000件
- PostgreSQL: 804,000,000件
JSONBenchオンラインダッシュボードのData Qualityメトリクスで、システムごとのロード完了率も確認できます。1百万、1千万、1億、10億件など各サイズでのロード率を比較可能です。
私たちは、ロード方法の改良や不具合修正によって、より多くのドキュメントをロードできるようにする貢献を歓迎します。
コールドとホットクエリ時間 #
ClickBenchと同様に、各ベンチマーククエリをそれぞれ3回実行し、1回目の実行をコールドランタイム、2回目と3回目のうち最短をホットランタイムとします。1回目の実行前には、OSレベルのページキャッシュをクリア(例:ClickHouseのケース)します。
以下はご要望に沿って、元の英文ブログ記事を日本語に翻訳したものです。リンクや参照先は原文のまま残してあります。
ベンチマーク結果 #
いよいよベンチマーク結果の紹介です。前述した手法に従い、10億件の JSON ドキュメントを扱うデータセットに対する結果を示します。実運用で考えられるデータ量に注目するため、このような大きな規模のデータセットを対象にしています。
また、比較をシンプルかつ実際的にするために、各システムで利用可能な最適な圧縮オプションを使った場合の結果のみを掲載しています。多くのシステムが同じ zstd アルゴリズムを採用していること、そしてペタバイト級の現実的なシナリオではストレージコスト削減のために圧縮が極めて重要となることを考慮して、この方針としました。
小規模データセットの結果は重複を避けるため、そして実際のユースケースではあまり意味がないため、ここでは割愛しています。たとえば Bluesky のようなプラットフォームでは 1 秒間に数百万件のイベントが生まれる可能性があるので、あまりに小さいデータセットは現実的ではありません。
もっと詳しく知りたい方のために、デフォルト圧縮オプションや小規模データセットを含むすべての結果を JSONBench のオンラインダッシュボード で公開しています。すべてのシステムについて結果を簡単に分析・比較できるようになっています:
- 1 million JSON ドキュメント(100万件): storage sizes, cold runtimes, hot runtimes
- 10 million JSON ドキュメント(1000万件): storage sizes, cold runtimes, hot runtimes
- 100 million JSON ドキュメント(1億件): storage sizes, cold runtimes, hot runtimes
- 1 billion JSON ドキュメント(10億件): storage sizes, cold runtimes, hot runtimes)
これから、best available compression(最適な圧縮オプション)で 10億件の JSON ドキュメントを取り込んだ際の、総ストレージサイズおよび分析系クエリのパフォーマンスを示します。
最適な圧縮を適用した場合のストレージサイズ #

上の図は 7 つの棒グラフで示されるストレージサイズを、左から右へ順に解説していきます。
まず、Bluesky の JSONファイル は、圧縮しない状態で 482 GB のディスク容量を占めます。これを zstd で圧縮すると 124 GB まで削減されます。
ClickHouse に zstd 圧縮を設定した状態でこれらのファイルを取り込むと、合計のディスクサイズは 99 GB となります。
注目すべきは、ClickHouse がソースファイルを
zstdで直接圧縮したものよりさらに小さくデータを保持している点です。これは上記で説明したように、ClickHouse が各 JSON パスの値をネイティブなカラムに分割して格納し、それぞれを個別に圧縮していることが大きく寄与します。また、プライマリキーが使用されている場合は、カラムごとに類似するデータをまとめ、ソートした上で圧縮できるため、圧縮率がさらに高まります。
MongoDB では zstd 圧縮を有効化した状態で JSON データを保持すると、ディスクサイズは 158 GB となり、ClickHouse より 40% 大きいサイズとなります。
Elasticsearch はできる限り公平に構成を整えました。_source を無効にした状態で、設定 された zstd 圧縮を用いると 220 GB が必要で、ClickHouse より 2 倍以上多い容量が必要です。
すでに説明済みのとおり、設定した圧縮アルゴリズムは _source のような “stored fields” のデータにしか適用されません。_source を無効にすると、そのメリットがほとんど失われるということは、同じ構成で lz4 圧縮を使ったサイズを比較すれば明らかです。
もし _source が必要(たとえばエンタープライズ版の「synthetic _source」が使えない OSS 版など)であれば、同じ構成で _source を有効にするとディスクサイズは 360 GB になり、ClickHouse の 3 倍以上となります。さらにデフォルトの lz4 圧縮を使うと 455 GB に膨れ上がります。
DuckDB には専用の圧縮アルゴリズムを選択する機能はなく、内部で軽量な圧縮アルゴリズムを自動的に適用しています。取り込んだ JSON ドキュメントのディスク使用量は 472 GB で、ClickHouse のほぼ 5 倍になります。
PostgreSQL は“巨大な”タプルにだけ圧縮を適用し、しかもタプル単位でのみ行います。今回のようにほとんどのタプルが閾値を下回るケースでは、ほぼ圧縮が効きません。最適な lz4 を使ってもディスク容量は 622 GB となり、デフォルトの pglz でもほとんど同じ サイズ です。ClickHouse より 6 倍以上大きなサイズになります。
続いて、この取り込んだ JSON データに対して各システムでベンチマーククエリを実行した際のランタイムを見ていきます。
クエリ①の集計パフォーマンス #
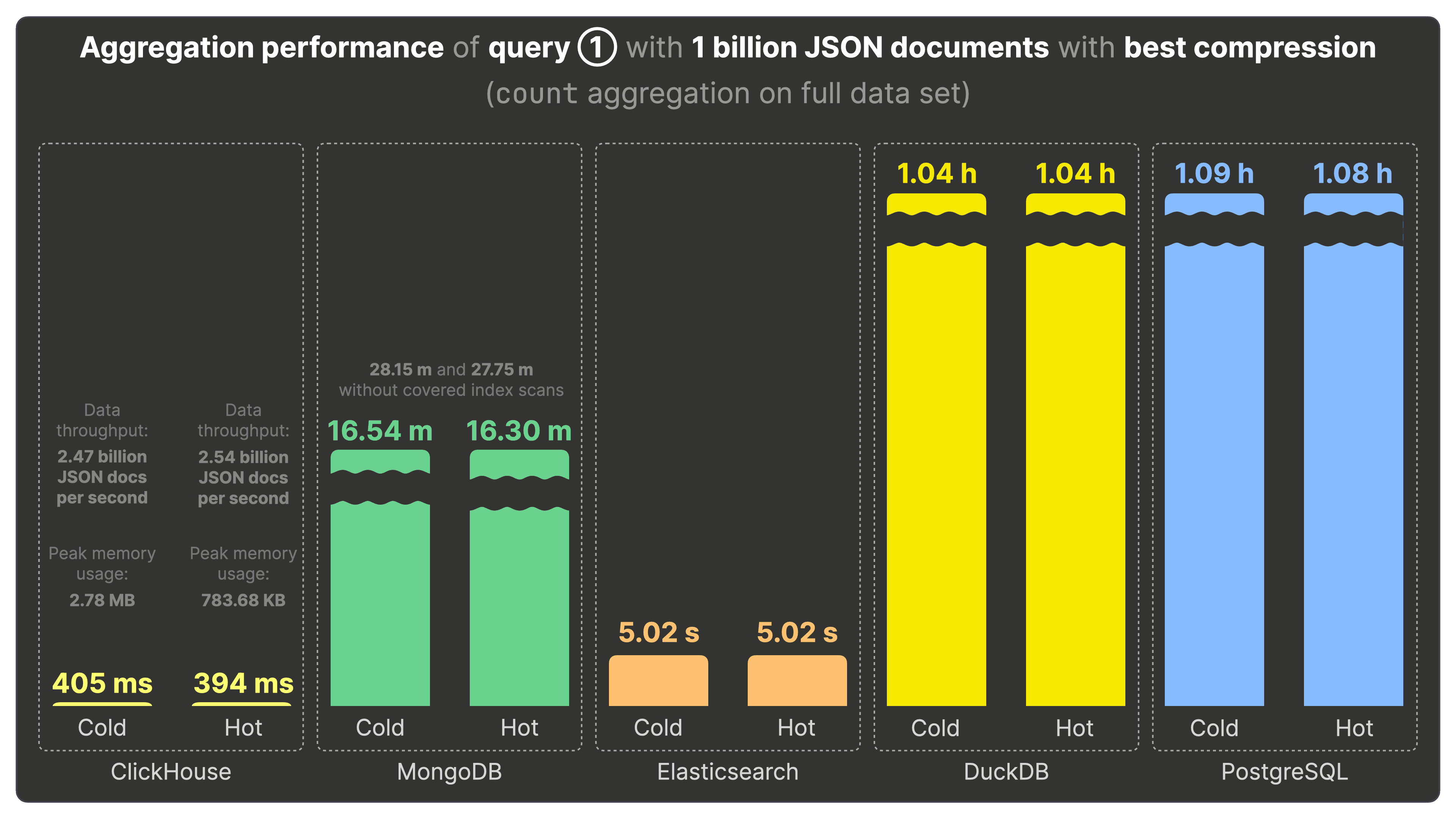
下の図は、10億件の JSON ドキュメントを最適な圧縮オプションで各システムに格納した状態で、ベンチマークのクエリ①をコールド実行およびホット実行したときのランタイムを示しています。クエリ①はデータセット全体に対して count 集計を行い、Bluesky イベントタイプの人気度を求めるものです。
左から右に 5 つのセクションを順に見ていきましょう。
-
ClickHouse はコールド実行で 405ミリ秒、ホット実行で 394ミリ秒 でクエリ①を完了します。これは秒間 24.7 億~25.4 億レコードを処理している計算になります。ClickHouse ではクエリ実行ごとのメモリ使用量も測定しており、コールド・ホットともに 3 MB 未満 で済んでいる点も注目です。
-
MongoDB では、すべてのベンチマーククエリに対しカバードインデックススキャンを有効にしています。その結果、クエリ①のコールド・ホット実行ともに 約16分 かかり、ClickHouse より 2500 倍遅いという結果でした。カバードインデックススキャンにより、クエリに必要なデータがすべてインデックス上のメモリに存在しているため、ディスクアクセスの必要がなく、コールドとホットで大きな差はありません。
参考までに、カバードインデックススキャンなしの場合はコールド・ホットともに 約28分 かかり、ClickHouse より 4200 倍遅くなります。
-
Elasticsearch は ES|QL 版のクエリ①をコールド・ホットともに 約5秒 で実行し、ClickHouse より 12 倍遅いという結果です。
-
DuckDB はクエリ①のコールド・ホット実行ともに 約1時間 かかり、ClickHouse より 9000 倍遅くなりました。
-
PostgreSQL も同様にコールド・ホットともに 約1時間 を要し、ClickHouse より 9000 倍遅いという結果です。
DuckDB と PostgreSQL は 10億件規模の JSON を扱う際に非常に時間がかかり、すべてのベンチマーククエリで極めて遅い実行時間を示しました(同一ハードウェア、デフォルト構成での比較です)。詳しいボトルネック分析はまだ行えていませんが、専門的な知見やプルリクエストをお待ちしています。
クエリ②の集計パフォーマンス #
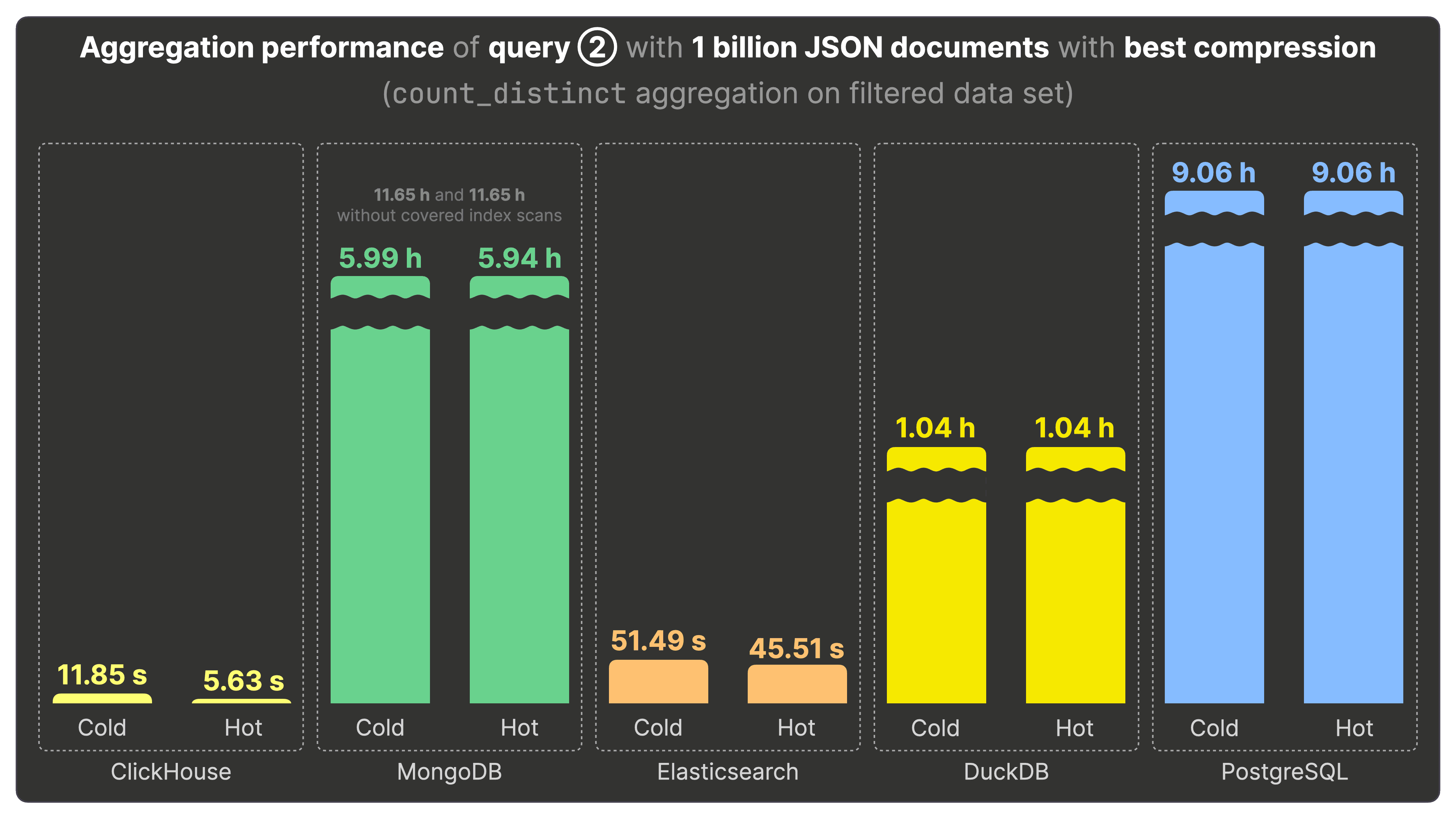
クエリ② は、クエリ①にフィルタ条件と count_distinct 集計を加え、人気のある Bluesky イベントごとにユニークユーザー数を算出するものです。
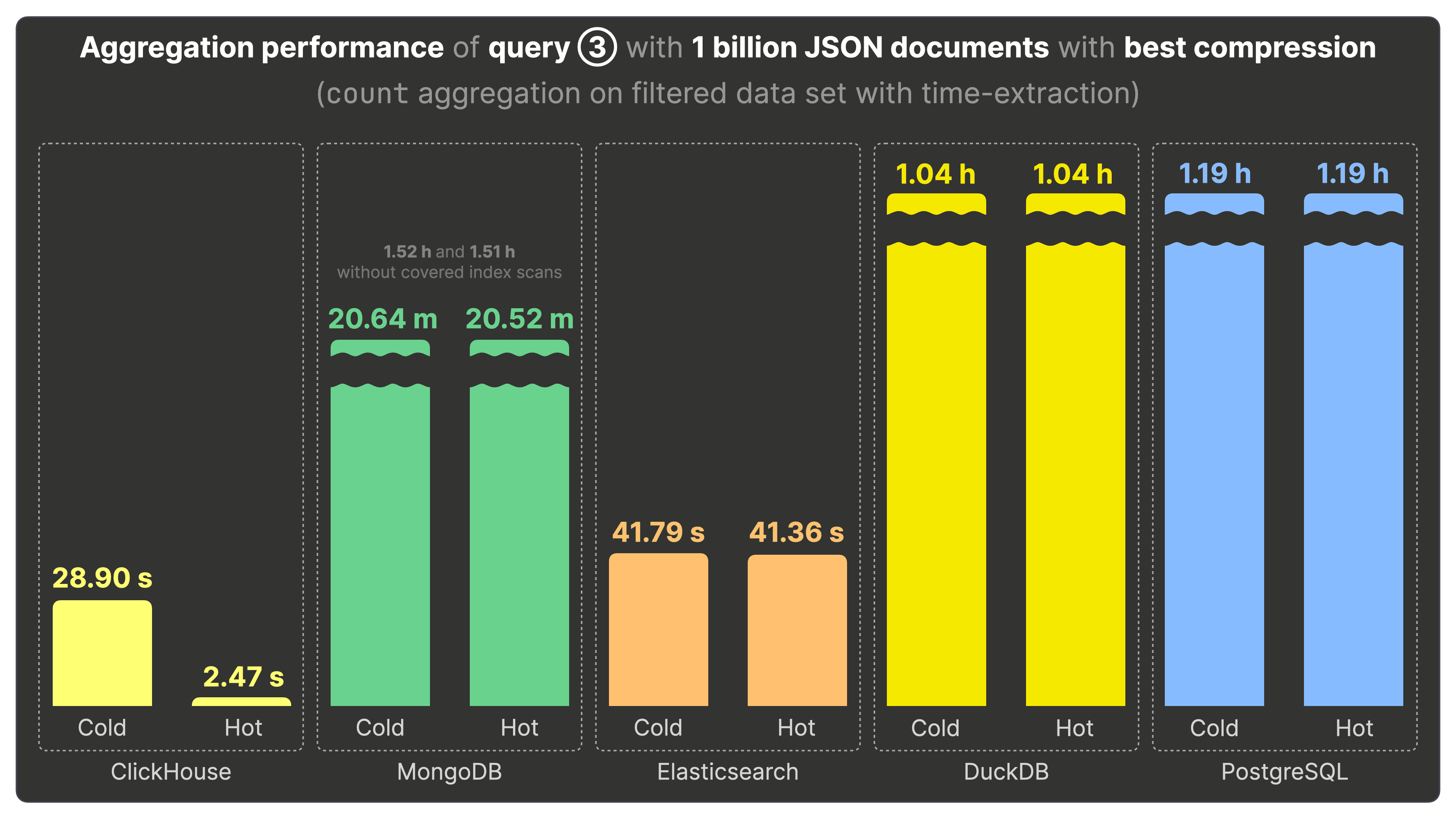
クエリ③の集計パフォーマンス #
クエリ③ は、イベントのタイムスタンプから時刻(時)の部分を取り出し、それぞれの Bluesky イベントが一日のどの時間帯にもっとも利用されているかを調べるため、hour-of-the-day でグルーピングして集計を行います。
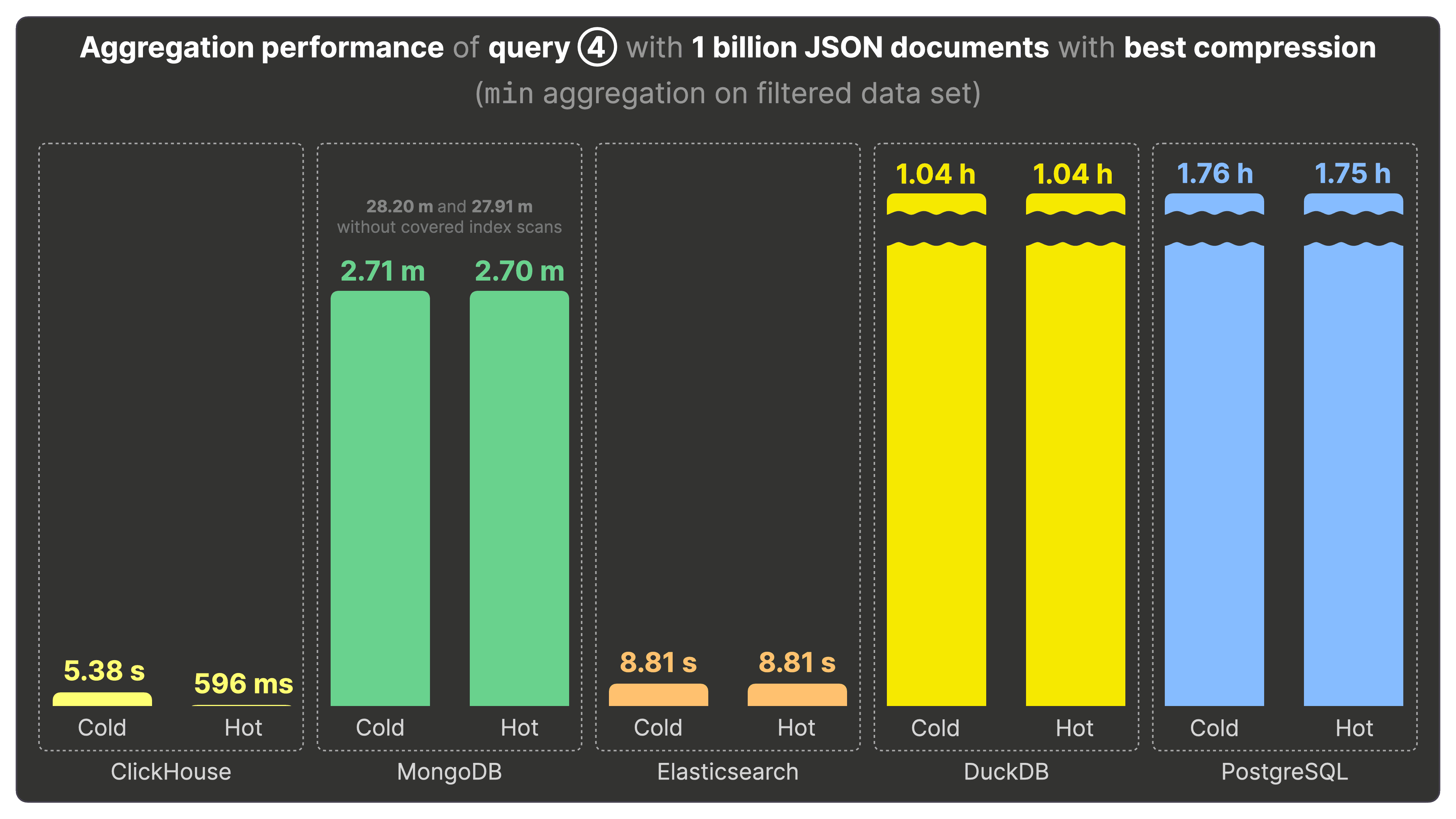
クエリ④の集計パフォーマンス #
クエリ④ は、最も古い投稿を行ったユーザー、つまり「ポストベテラン」上位3名を探すため、データセットに対して min 集計を行います。
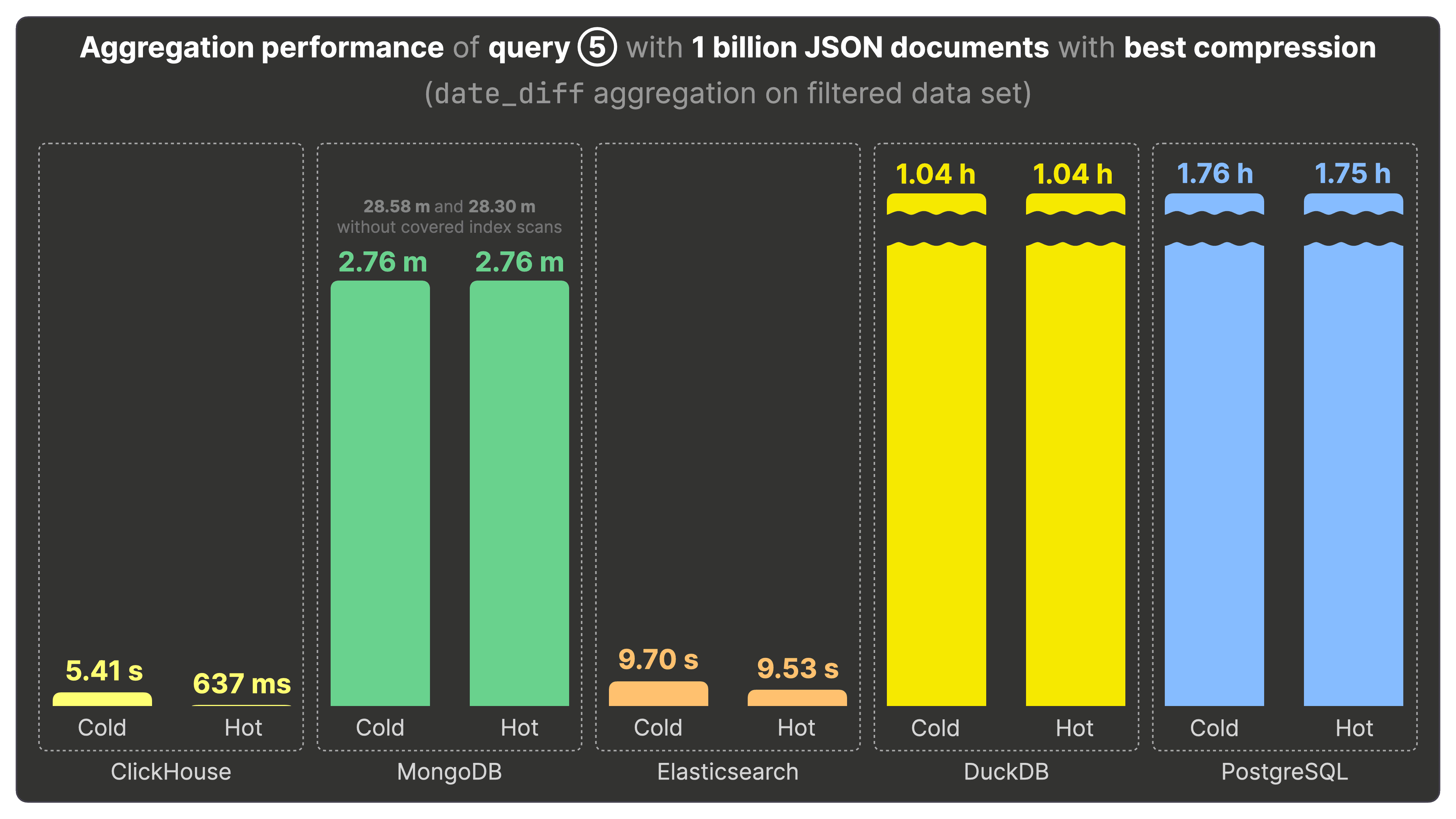
クエリ⑤の集計パフォーマンス #
クエリ⑤ は、date_diff 集計を使って Bluesky 上で最も長い活動期間を持つユーザー上位3名を抽出します。
まとめ #
このベンチマーク結果から、ClickHouse はストレージ効率・クエリパフォーマンスの両面で、JSON をサポートする他のデータストアを大きく上回ることがわかりました。
分析系クエリにおいては、MongoDB などの主要な JSON データストアに比べて数千倍もの高速性を示し、DuckDB や PostgreSQL に対しても数千倍、Elasticsearch と比較しても桁違いに高速でした。さらに、ディスク上の JSON ドキュメントの圧縮効率も高く、同じ zstd で圧縮したファイルよりも小さくなるため、大規模分析用途での TCO(総所有コスト)削減にも寄与します。
ClickHouse の ネイティブ JSON データ型 を使えば、スキーマ設計や調整を事前に厳密に行わなくても、ディスク上で最適に圧縮され、かつ高速な分析クエリを実行できます。これは特にイベントの多くが JSON 形式でやり取りされるユースケースや、SQL ベースのオブザーバビリティ など、コスト効率と分析クエリ性能が重要となる場面で非常に有効です。ClickHouse は、汎用的な JSON データストアとして比類ない存在だと言えます。
今回の記事では、主要なデータストアが持つ JSON サポートの特徴や性能を実際のベンチマークを通じて比較・考察しました。より詳細に学んでみたい方、またベンチマークに貢献してみたい方は、ぜひ JSONBench(オープンソースの JSON ベンチマーク)にご参加ください。すでにあるベンチマークの改善や新たなシステムの追加など、The Billion Docs JSON Challenge に挑戦してみてください!🥊



