
旅行の荷造りを終えたのに、空港で旅行に行かないことが判明したら、荷造りをスキップできたと想像してみてください。これが、ClickHouseが現在データに対して行っていることです。
ClickHouseは利用可能な分析データベースの中で最速のものの1つであり、その速度の多くは不要な作業を回避することから生まれています。スキャンして処理するデータが少ないほど、クエリの実行は高速になります。今回、この考え方をさらに推し進め、新しい最適化である遅延マテリアライゼーションを導入しました。これにより、実際に必要になるまで列データの読み取りを遅らせます。
この一見「遅延的」な動作は、特に大規模なデータセットをソートしてLIMIT句を適用するトップNクエリ(可観測性や一般的な分析でよく見られるパターン)など、実際のワークロードで非常に効果的であることが判明しています。これらのシナリオでは、遅延マテリアライゼーションによってパフォーマンスが劇的に向上し、多くの場合、桁違いに高速化されます。
ネタバレ注意: SQLを一行も変更せずに、ClickHouseのクエリが219秒からわずか139ミリ秒に短縮された事例(1,576倍の高速化)をご紹介します。同じクエリ、同じテーブル、同じマシンです。唯一変わったのは、ClickHouseがデータを読み取るタイミングだけです。
この記事では、遅延マテリアライゼーションがどのように機能し、ClickHouseの広範なI/O最適化スタックにどのように適合するのかを説明します。全体像を把握していただくために、ClickHouseにおけるI/O効率の他の主要な構成要素についても簡単に説明し、遅延マテリアライゼーションが何を行うかだけでなく、既存の技術とどのように異なり、補完し合うのかを強調します。
まず、ClickHouseがすでに使用している主要なI/O削減技術について説明し、次に実際のクエリをそれらの技術を通してレイヤーごとに実行し、最終的に遅延マテリアライゼーションが介入してすべてを変えるところまでを見ていきます。
ClickHouseにおけるI/O効率の構成要素 #
長年にわたり、ClickHouseはI/Oを積極的に削減するために、階層化された一連の最適化を導入してきました。これらの技術は、その速度と効率の基盤を形成しています。
- カラムナストレージ により、クエリに不要な列全体をスキップでき、また、類似した値をまとめてグループ化することで高い圧縮率を実現し、データロード中のI/Oを最小限に抑えます。
- スパースプライマリインデックス、セカンダリデータスキッピングインデックス、および**プロジェクション** は、インデックス付き列のフィルタに一致する可能性のあるグラニュール(行ブロック)を特定することにより、無関係なデータを削減します。これらの技術はグラニュールレベルで動作し、個別または組み合わせて使用できます。
- PREWHERE は、インデックス付けされていない列のフィルタについても一致を確認し、そうでなければロードされて破棄されるデータを早期にスキップします。インデックスによって選択されたグラニュールを独立して処理したり、絞り込んだりすることができ、すべての列フィルタに一致しない行をスキップすることでグラニュールの削減を補完します。
- クエリ条件キャッシュ(詳細解説) は、前回どのグラニュールがすべてのフィルタに一致したかを記憶することで、繰り返し実行されるクエリを高速化します。これにより、ClickHouseは、クエリの形状が変化した場合でも、一致しなかったグラニュールの読み取りとフィルタリングをスキップできます。これは単にインデックスとPREWHEREフィルタリングの結果をキャッシュするため、ここではこれ以上説明しません。以下のすべてのテストでは、結果の偏りを避けるために無効にしています。
これらの技術(以下で紹介する遅延マテリアライゼーションを含む)は、クエリ処理中のI/Oを削減するものであり、この記事の焦点です。インクリメンタルまたはリフレッシュ可能なマテリアライズドビューを使用して結果を事前に計算することで、テーブルサイズ(およびクエリの作業量)を事前に削減するという直交するアプローチもありますが、ここでは説明しません。
遅延マテリアライゼーションによるスタックの完成 #
前述のI/O最適化は読み取るデータを大幅に削減できますが、それでもWHERE句を通過する行のすべての列は、ソート、集計、またはLIMITのような操作を実行する前にロードする必要があると想定しています。しかし、一部の列が後になるまで必要ない場合や、WHERE句を通過したにもかかわらず一部のデータがまったく必要ない場合はどうなるでしょうか?
そこで登場するのが遅延マテリアライゼーションです。これはI/O最適化スタックを完成させる直交的な機能強化です。
- インデックス作成は、PREWHEREとともに、
WHERE句の列フィルタに一致する行のみが処理されるようにします。 - 遅延マテリアライゼーションは、クエリ実行計画で実際に必要とされるまで列の読み取りを延期することで、これを基盤としています。フィルタリング後であっても、ソートなどの次の操作に必要な列のみがすぐにロードされます。他の列は延期され、
LIMITのために、最終結果を生成するのに十分な量だけ、部分的に読み取られることがよくあります。これにより、遅延マテリアライゼーションは、最終結果が特定の、多くの場合大きな列から少数の行しか必要としないトップNクエリに対して特に強力になります。
このようなきめ細かい列処理は、ClickHouseが各列を独立して保存しているためにのみ可能です。行指向データベースでは、すべての列が一緒に読み取られるため、このレベルの遅延I/Oは単純に実現不可能です。
その影響を示すために、実際の例を通して、各最適化レイヤーがどのように役割を果たすかを見ていきます。
テスト設定:データセットとマシン #
1995年から2015年までの約1億5000万件の製品レビューが含まれるAmazon顧客レビューデータセットを使用します。
We’re running ClickHouse 25.4 on an AWS m6i.8xlarge EC2 instance with:
• 32 vCPUs
• 128 GiB RAM
• 1 TiB gp3 SSD (with default settings: 3000 IOPS, 125 MiB/s max throughput 🐌)
• Ubuntu Linux 24.04
そのマシンで、まずAmazonレビューテーブルを作成しました:
CREATE TABLE amazon.amazon_reviews
(
`review_date` Date CODEC(ZSTD(1)),
`marketplace` LowCardinality(String) CODEC(ZSTD(1)),
`customer_id` UInt64 CODEC(ZSTD(1)),
`review_id` String CODEC(ZSTD(1)),
`product_id` String CODEC(ZSTD(1)),
`product_parent` UInt64 CODEC(ZSTD(1)),
`product_title` String CODEC(ZSTD(1)),
`product_category` LowCardinality(String) CODEC(ZSTD(1)),
`star_rating` UInt8 CODEC(ZSTD(1)),
`helpful_votes` UInt32 CODEC(ZSTD(1)),
`total_votes` UInt32 CODEC(ZSTD(1)),
`vine` Bool CODEC(ZSTD(1)),
`verified_purchase` Bool CODEC(ZSTD(1)),
`review_headline` String CODEC(ZSTD(1)),
`review_body` String CODEC(ZSTD(1))
)
ENGINE = MergeTree
ORDER BY (review_date, product_category);
そして、公開されているサンプルデータセットのS3バケットでホストされているParquetファイルからデータセットをロードしました:
INSERT INTO amazon.amazon_reviews
SELECT * FROM s3Cluster('default', 'https://datasets-documentation.s3.eu-west-3.amazonaws.com/amazon_reviews/amazon_reviews_*.snappy.parquet');
ロード後のテーブルサイズを確認します:
SELECT
formatReadableQuantity(sum(rows)) AS rows,
formatReadableSize(sum(data_uncompressed_bytes)) AS data_size,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size
FROM system.parts
WHERE active AND database = 'amazon' AND table = 'amazon_reviews';
┌─rows───────────┬─data_size─┬─compressed_size─┐ │ 150.96 million │ 70.47 GiB │ 30.05 GiB │ └────────────────┴───────────┴─────────────────┘
ロード後、テーブルには約1億5000万行が含まれ、以下のようになります:
- 非圧縮データ 70 GiB
- ZSTD(1)を使用してディスク上で約30 GiBに圧縮
ClickHouseは高速だが、ディスクがそうではないかもしれない #
1億5000万行はClickHouseにとってほとんど課題ではありません。例えば、このクエリはhelpful_votes列(テーブルのソートキーの一部ではない)の1億5000万個すべての値をソートし、上位3件を返します。これは、OSファイルシステムキャッシュを事前にクリアしたコールドな状態でわずか70ミリ秒で実行され、処理スループットは21.5億行/秒です。
SELECT helpful_votes FROM amazon.amazon_reviews ORDER BY helpful_votes DESC LIMIT 3;
┌─helpful_votes─┐ │ 47524 │ │ 41393 │ │ 41278 │ └───────────────┘ 3 rows in set. Elapsed: 0.070 sec. Processed 150.96 million rows, 603.83 MB (2.15 billion rows/s., 8.61 GB/s.) Peak memory usage: 3.59 MiB.
このクエリにはフィルタがないため、インデックス作成、PREWHERE、その他のI/O削減技術の恩恵は受けないことに注意してください。しかし、カラムナストレージのおかげで、ClickHouseはhelpful_votes列のみを読み取り、残りはスキップします。
もう1つの例として、単一のreview_body列からすべてのデータを(コールドファイルシステムキャッシュで)選択するクエリを示します。
SELECT review_body FROM amazon.amazon_reviews FORMAT Null;
Query id: b9566386-047d-427c-a5ec-e90bee027b02 0 rows in set. Elapsed: 176.640 sec. Processed 150.96 million rows, 56.02 GB (854.61 thousand rows/s., 317.13 MB/s.) Peak memory usage: 733.14 MiB.
😱 ほぼ3分です!単一の列を読み取っただけなのに。
しかし、ボトルネックはClickHouseではなく、ディスクのスループットでした。このクエリは、前の例の600 MBに対して56 GBというはるかに大きな列をスキャンしました。比較的遅いディスクと32個のCPUコアを持つテストマシンでは、ClickHouseは32個の並列ストリームを使用してデータを読み取りました。クエリログは、3分間の実行時間の大部分がreadシステムコールの待機に費やされたことを確認しています。
SELECT
round(ProfileEvents['DiskReadElapsedMicroseconds'] / 1e6) AS disk_read_seconds,
ProfileEvents['ConcurrencyControlSlotsAcquired'] AS parallel_streams,
formatReadableTimeDelta(round(disk_read_seconds / parallel_streams), 'seconds') AS time_per_stream
FROM system.query_log
WHERE query_id = 'b9566386-047d-427c-a5ec-e90bee027b02'
AND type = 'QueryFinish';
┌─disk_read_seconds─┬─parallel_streams─┬─time_per_stream─┐ │ 5512 │ 32 │ 172 seconds │ └───────────────────┴──────────────────┴─────────────────┘
明らかに、特にコールドキャッシュの場合、ブルートフォーススキャンは理想的ではありません。ClickHouseに何か処理させるものを与えましょう。
より現実的なクエリ — 最適化が重要な場面 #
空港での騒動にもかかわらず、私はまだビーチでの休暇を決意しており、そのためには最高の電子書籍リーダーをロードする必要があります。そこで、ClickHouseに、2010年以降のデジタル電子書籍購入に関する、最も役立つ5つ星の検証済みレビューを見つける手助けを依頼し、役立つ投票数、書籍のタイトル、レビューの見出し、レビュー自体を表示します。
SELECT
helpful_votes,
product_title,
review_headline,
review_body
FROM amazon.amazon_reviews
WHERE review_date >= '2010-01-01'
AND product_category = 'Digital_Ebook_Purchase'
AND verified_purchase
AND star_rating > 4
ORDER BY helpful_votes DESC
LIMIT 3
FORMAT Vertical;
Row 1: ────── helpful_votes: 6376 product_title: Wheat Belly: Lose the Wheat, Lose the Weight, and Find Your Path Back to Health review_headline: Overweight? Diabetic? Got High Blood Pressure, Arthritis? Get this Book! review_body: I've been following Dr. Davis' heart scan blog for the past ... Row 2: ────── helpful_votes: 4149 product_title: The Life-Changing Magic of Tidying Up: The Japanese Art of Decluttering and Organizing review_headline: Truly life changing review_body: I rarely write reviews, but this book truly sparked somethin... Row 3: ────── helpful_votes: 2623 product_title: The Fast Metabolism Diet: Eat More Food and Lose More Weight review_headline: Fantastic Results **UPDATED 1/23/2015** review_body: I have been on this program for 7 days so far. I know it ma...
上記のクエリは、テーブル内で最大の3つの列(product_title、review_headline、review_body)を含む4つの列を選択します。
SELECT
name as column,
formatReadableSize(sum(data_uncompressed_bytes)) AS data_size,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size
FROM system.columns
WHERE database = 'amazon' AND table = 'amazon_reviews'
GROUP BY name
ORDER BY sum(data_uncompressed_bytes) DESC;
┌─column────────────┬─data_size──┬─compressed_size─┐ │ review_body │ 51.13 GiB │ 21.60 GiB │ │ product_title │ 8.12 GiB │ 3.53 GiB │ │ review_headline │ 3.38 GiB │ 1.58 GiB │ │ review_id │ 2.07 GiB │ 1.35 GiB │ │ product_id │ 1.55 GiB │ 720.97 MiB │ │ customer_id │ 1.12 GiB │ 524.35 MiB │ │ product_parent │ 1.12 GiB │ 571.63 MiB │ │ helpful_votes │ 575.86 MiB │ 72.11 MiB │ │ total_votes │ 575.86 MiB │ 83.50 MiB │ │ review_date │ 287.93 MiB │ 239.43 KiB │ │ marketplace │ 144.51 MiB │ 414.92 KiB │ │ product_category │ 144.25 MiB │ 838.96 KiB │ │ star_rating │ 143.96 MiB │ 41.99 MiB │ │ verified_purchase │ 143.96 MiB │ 20.50 MiB │ │ vine │ 1.75 MiB │ 844.89 KiB │ └───────────────────┴────────────┴─────────────────┘
このサンプルクエリは、60GB以上の(非圧縮)データにアクセスします。以前に示したように、32の並列ストリームを使用しても、(比較的遅い)ディスクからコールドキャッシュでそれを読み取るだけで3分以上かかります。
しかし、このクエリには複数の列(review_date、product_category、verified_purchase、star_rating)に対するフィルタと、helpful_votesによるソート後に適用されるLIMITが含まれています。これは、ClickHouseの階層化されたI/O最適化に最適な設定です。
- インデックス作成 は、プライマリ/ソートキー(
review_date、product_category)のフィルタに一致しない行を削減します。 - PREWHERE はフィルタリングをより深くプッシュし、すべての列フィルタに一致しない行を削減します。
- 遅延マテリアライゼーション は、大きな
SELECT列(product_title、review_headline、review_body)の読み込みを、ソートとLIMITの適用後、実際に必要になるまで遅延させます。理想的には、その大きな列データのほとんどはまったく読み取られません。
各レイヤーがI/Oをさらに削減します。これらが連携することで、データ読み取り量、メモリ使用量、クエリ時間が短縮されます。それがどれほどの違いを生むか、レイヤーごとに見ていきましょう。
OSレベルのファイルシステムキャッシュがコールドな状態で #
以下のセクションでは、各クエリ実行前にOSレベルのファイルシステム(ページ)キャッシュをクリアします。
echo 3 | sudo tee /proc/sys/vm/drop_caches >/dev/null
をLinuxコマンドラインで実行します。これにより、最悪のシナリオをシミュレートし、結果がキャッシュされたデータではなく実際のディスク読み取りを反映するようにします。
ショートカットなし:ベースラインとなるフルスキャン #
最適化を導入する前に、ClickHouseがショートカットなしでクエリを実行した場合に何が起こるかを見てみましょう。インデックス作成も、PREWHEREも、遅延マテリアライゼーションもありません。
これを行うために、ソート/プライマリキーのないテーブルのバージョンでサンプルクエリを実行します。つまり、インデックスベースの最適化の恩恵は受けません。次のコマンドは、そのベースラインテーブルを作成します。
CREATE TABLE amazon.amazon_reviews_no_pk
Engine = MergeTree
ORDER BY ()
AS SELECT * FROM amazon.amazon_reviews;
次に、PREWHEREと遅延マテリアライゼーションの両方を無効にして、ベースラインテーブルでサンプルクエリを実行します。
SELECT
helpful_votes,
product_title,
review_headline,
review_body
FROM amazon.amazon_reviews_no_pk
WHERE review_date >= '2010-01-01'
AND product_category = 'Digital_Ebook_Purchase'
AND verified_purchase
AND star_rating > 4
ORDER BY helpful_votes DESC
LIMIT 3
FORMAT Null
SETTINGS
optimize_move_to_prewhere = false,
query_plan_optimize_lazy_materialization = false;
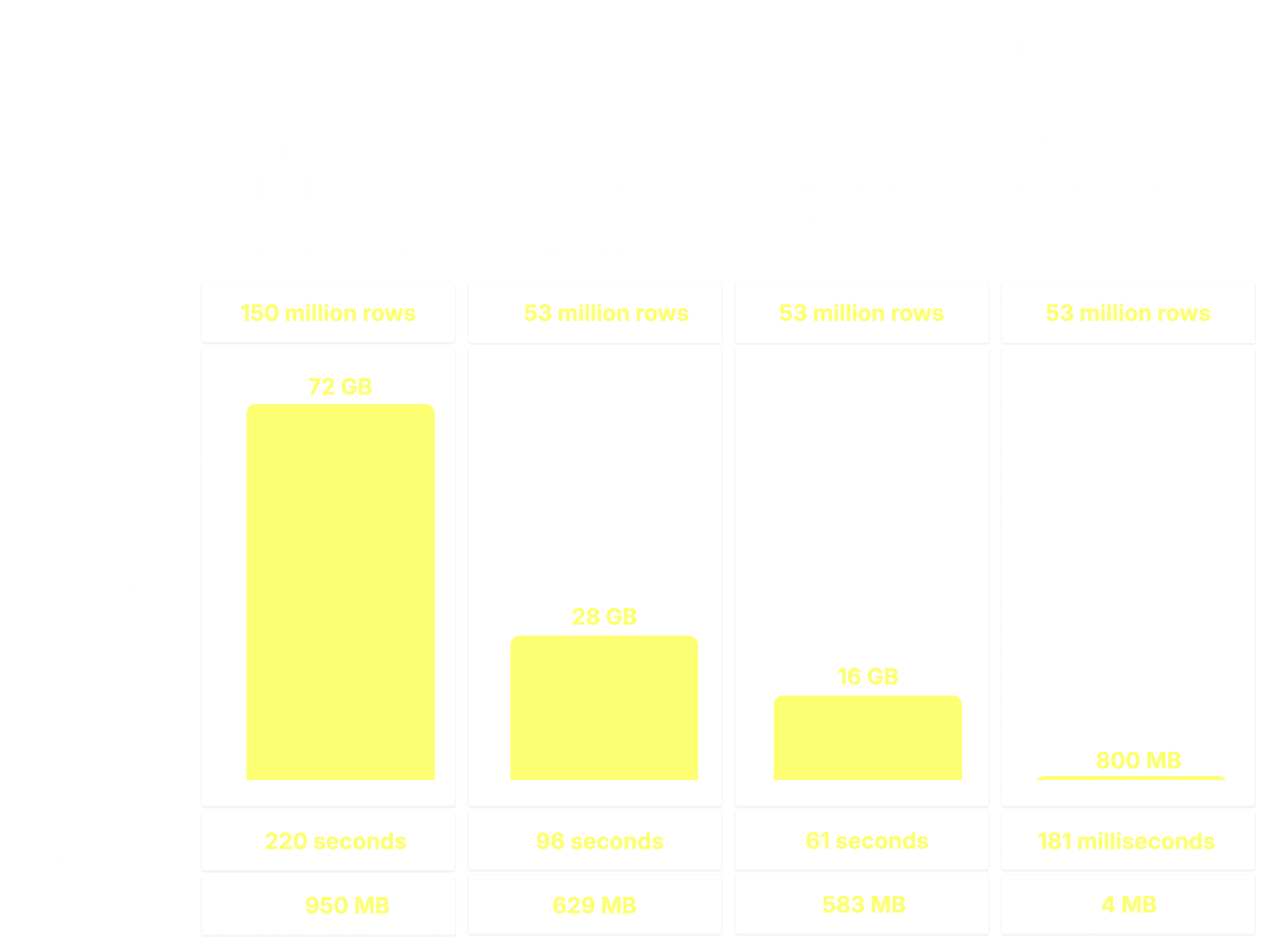
3 rows in set. Elapsed: 219.508 sec. Processed 150.96 million rows, 72.13 GB (687.71 thousand rows/s., 328.60 MB/s.) Peak memory usage: 953.25 MiB.
① クエリは、グラニュール(ClickHouseの最小処理単位で、デフォルトでは各8,192行をカバー)に編成された1億5000万行すべてを、② 必要な8列のディスクから③ メモリにストリーミングし、220秒で72 GBのデータを処理し、ピークメモリ使用量は953 MiBでした。

ClickHouseはテーブルデータをストリーミング方式で処理し、すべてのデータを一度にメモリにロードするのではなく、グラニュールのブロックを段階的に読み取って操作します。そのため、上記の72 GBのデータを処理したクエリでも、ピークメモリ使用量は1 GiB未満に抑えられました。
ベースラインが設定されたので、最初の最適化レイヤーがどのように改善されるかを見てみましょう。
① プライマリインデックスの活用 #
明らかに、データセット全体をスキャンするのは最適とは程遠いです。ClickHouseの最適化を適用し始めましょう。まずはプライマリインデックスからです。元のテーブル(複合ソート(プライマリ)キーとして(review_date, product_category)を使用)で、PREWHEREと遅延マテリアライゼーションの両方を無効にしたままサンプルクエリを実行します。
SELECT
helpful_votes,
product_title,
review_headline,
review_body
FROM amazon.amazon_reviews
WHERE review_date >= '2010-01-01'
AND product_category = 'Digital_Ebook_Purchase'
AND verified_purchase
AND star_rating > 4
ORDER BY helpful_votes DESC
LIMIT 3
FORMAT Null
SETTINGS
optimize_move_to_prewhere = false,
query_plan_optimize_lazy_materialization = false;
0 rows in set. Elapsed: 95.865 sec. Processed 53.01 million rows, 27.67 GB (552.98 thousand rows/s., 288.68 MB/s.) Peak memory usage: 629.00 MiB.
クエリには①テーブルの複合ソート(プライマリ)キーに対するフィルタが含まれているため、ClickHouseは②スパースプライマリインデックスをロードして評価し、③一致する行を含む可能性のあるプライマリキー列内のグラニュールのみを選択します。これらの関連する可能性のあるグラニュールは、その後④クエリに必要な他の列からの位置合わせされたグラニュールとともにメモリにストリーミングされます。残りのフィルタはこのステップの後に適用されます。
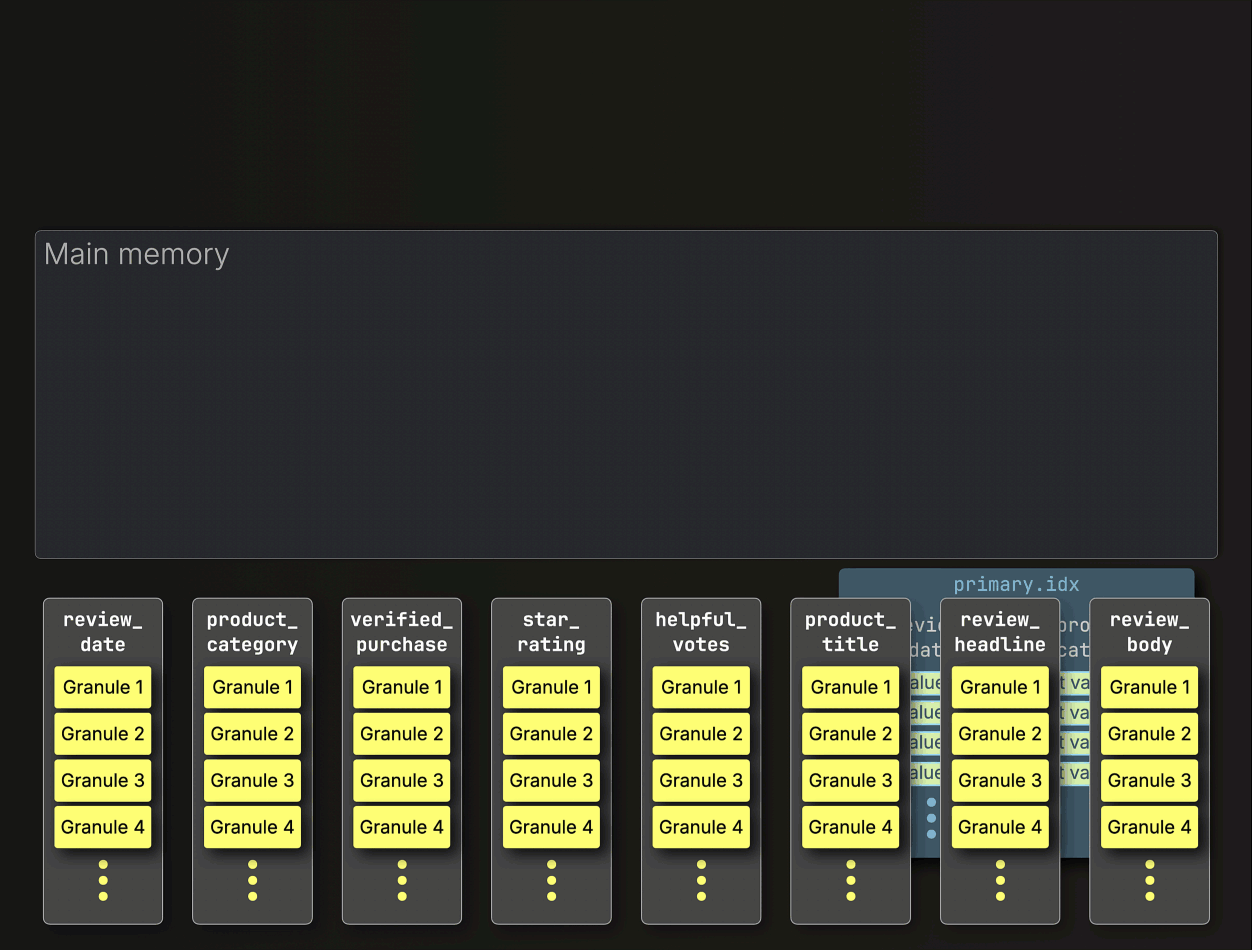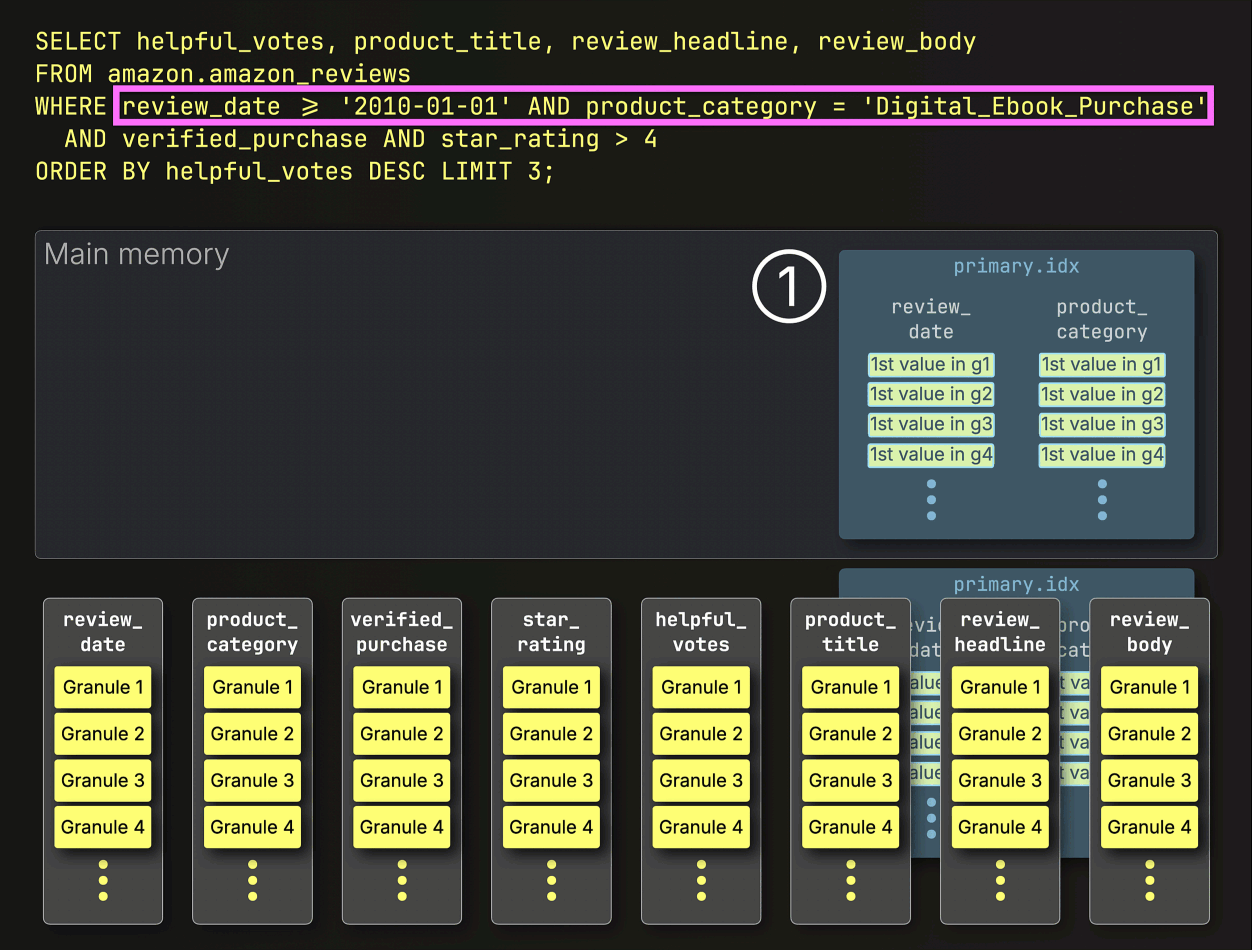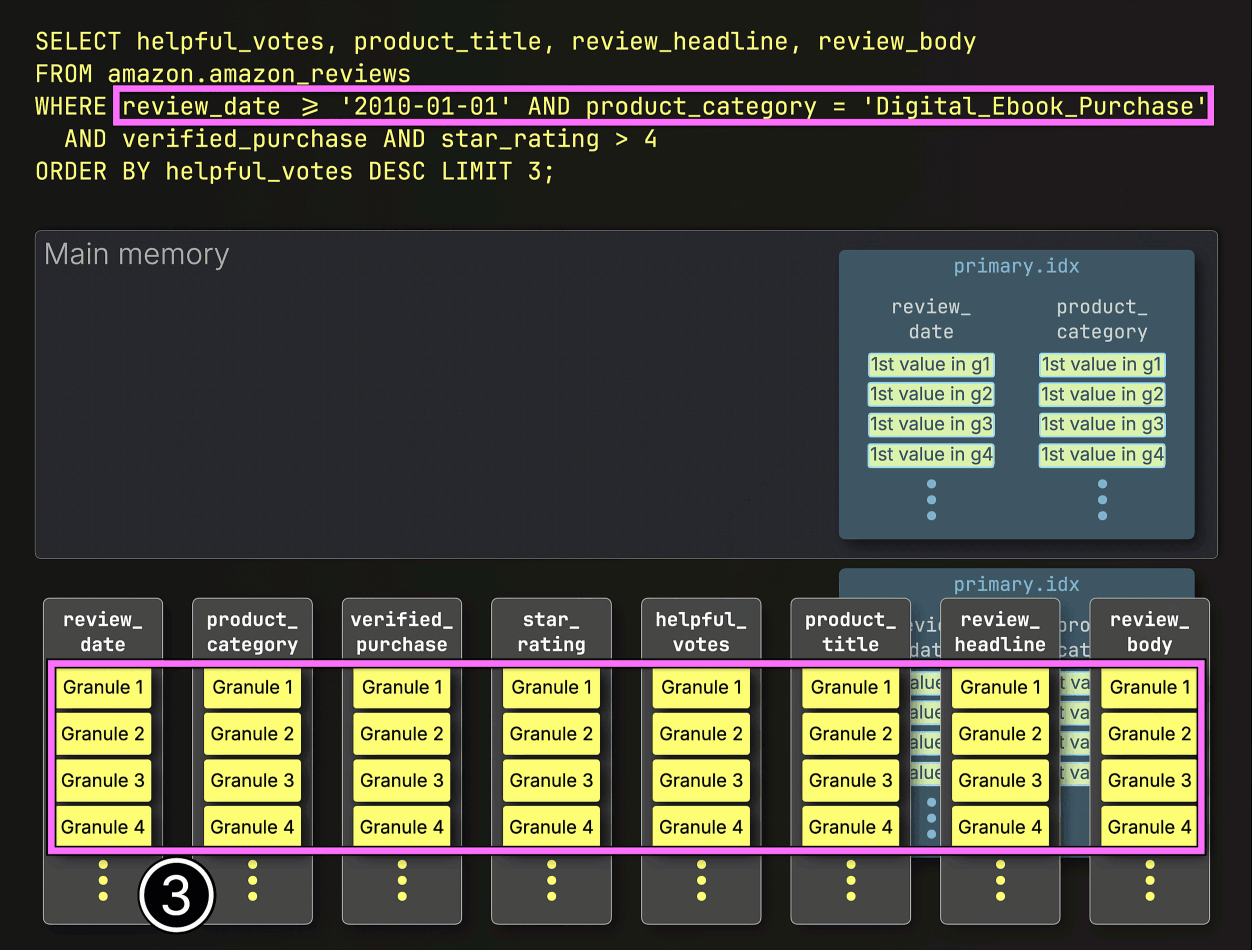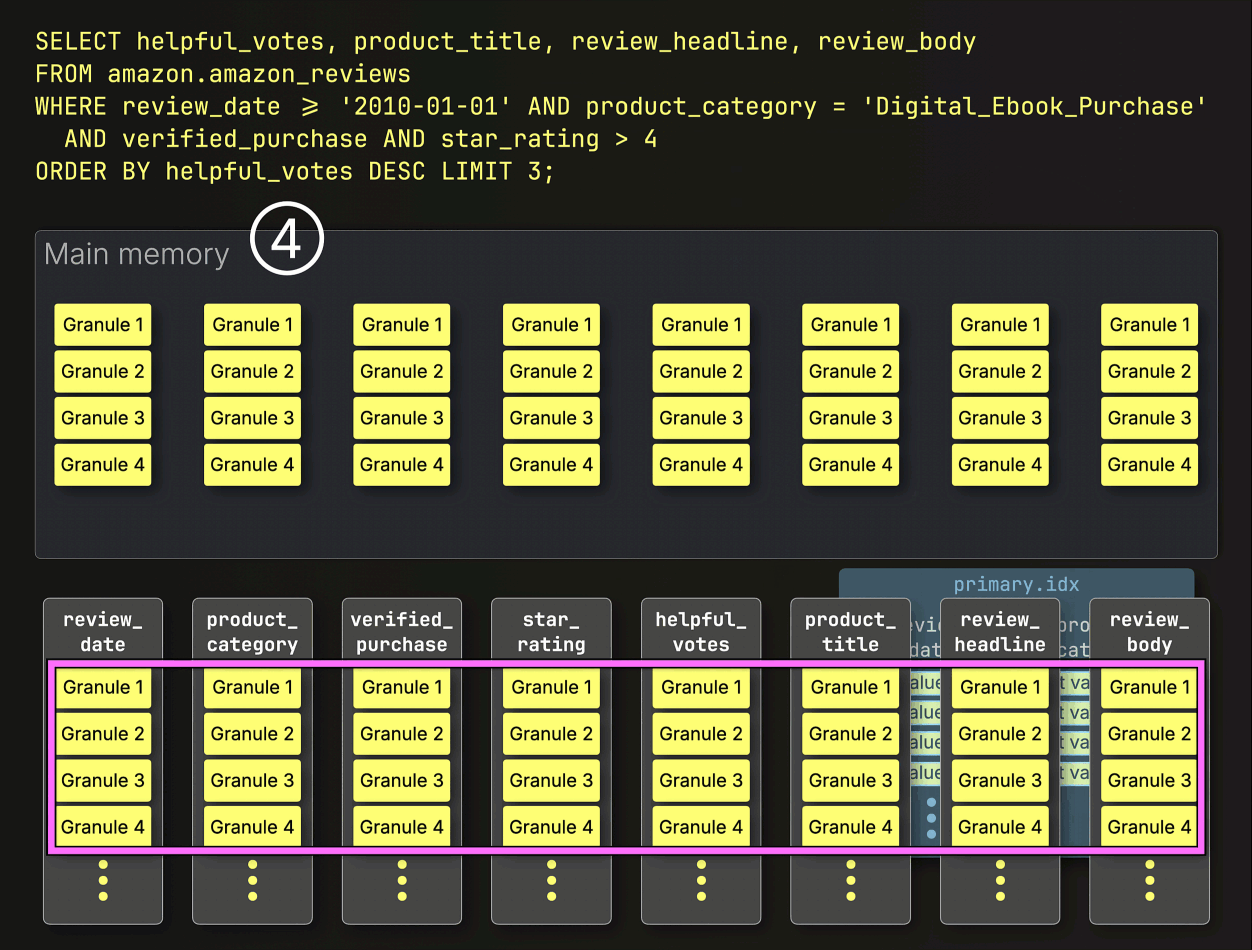
その結果、必要な8列からわずか5300万行のみがディスクからメモリにストリーミングされ、72 GBではなく28 GBのデータが処理され、実行時間は半分以上短縮されました(220秒に対して96秒)。
プライマリインデックスは、プライマリキー列のフィルタに基づいてグラニュールを削減します。
しかし、ClickHouseは、キー列のグラニュールと位置的に一致する他のすべての列グラニュールを依然としてロードします。これは、キー以外の列のフィルタによって後で除外される場合でも同様です。つまり、不要なデータが依然として読み取られ、処理されているのです。
これを修正するために、次にPREWHEREを有効にします。
② PREWHEREの追加 #
同じクエリを再度実行します。今回はPREWHEREを有効にします(ただし、遅延マテリアライゼーションはまだ無効です)。PREWHEREは、ディスクから非フィルタ列を読み取る前に関連性のないデータをフィルタリングする効率の追加レイヤーを追加します。
SELECT
helpful_votes,
product_title,
review_headline,
review_body
FROM amazon.amazon_reviews
WHERE review_date >= '2010-01-01'
AND product_category = 'Digital_Ebook_Purchase'
AND verified_purchase
AND star_rating > 4
ORDER BY helpful_votes DESC
LIMIT 3
FORMAT Null
SETTINGS
optimize_move_to_prewhere = true,
query_plan_optimize_lazy_materialization = false;
0 rows in set. Elapsed: 61.148 sec. Processed 53.01 million rows, 16.28 GB (866.94 thousand rows/s., 266.24 MB/s.) Peak memory usage: 583.30 MiB.
PREWHEREを有効にすると、クエリは同じ5300万行を処理しましたが、読み取る列データは大幅に少なくなり(27.67GBに対して16.28GB)、完了時間は36%速くなりました(96秒に対して61秒)。また、ピークメモリ使用量もわずかに削減されました。
この改善を理解するために、PREWHEREがClickHouseのクエリ処理方法をどのように変更するかを簡単に見ていきましょう。
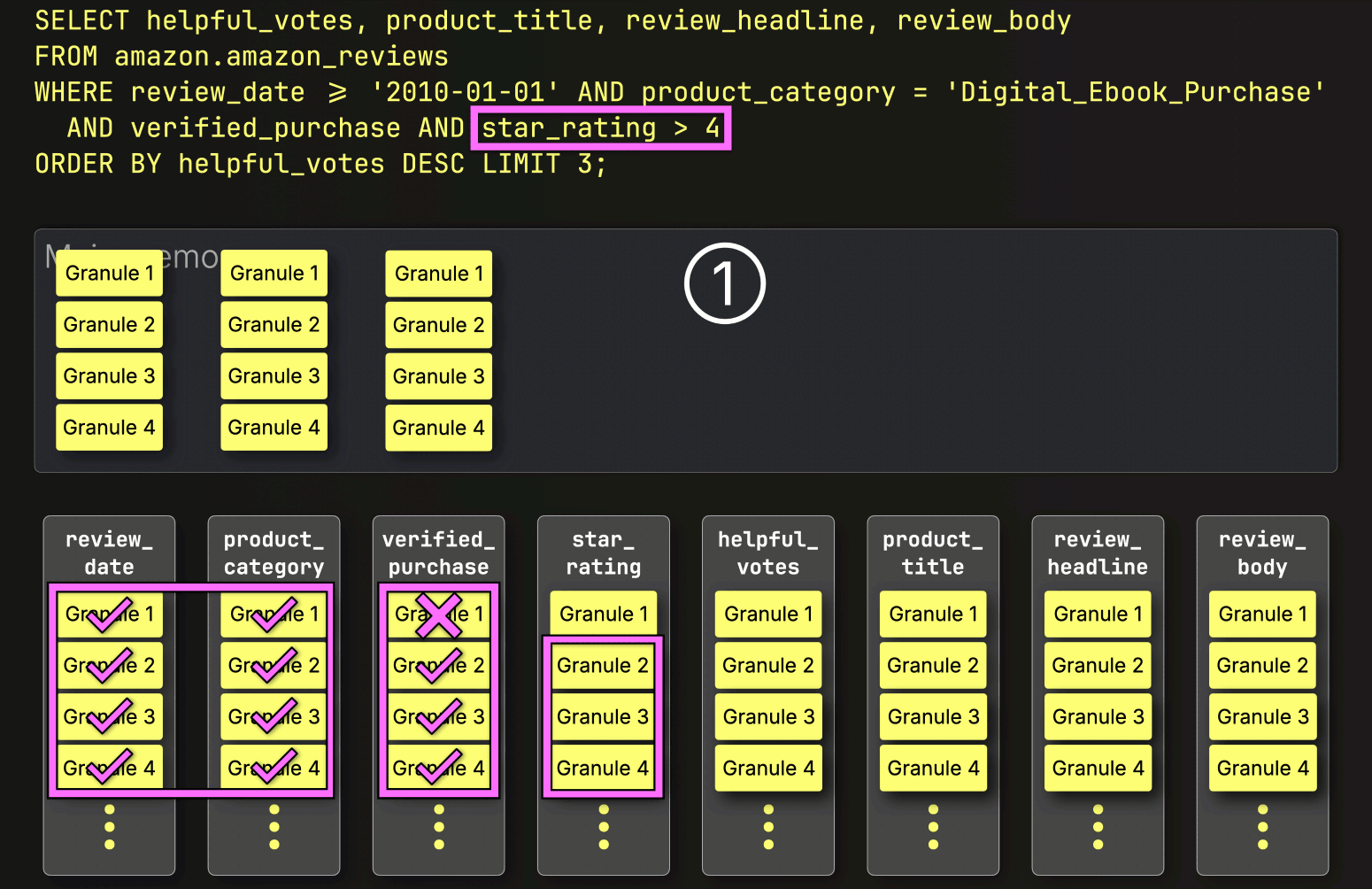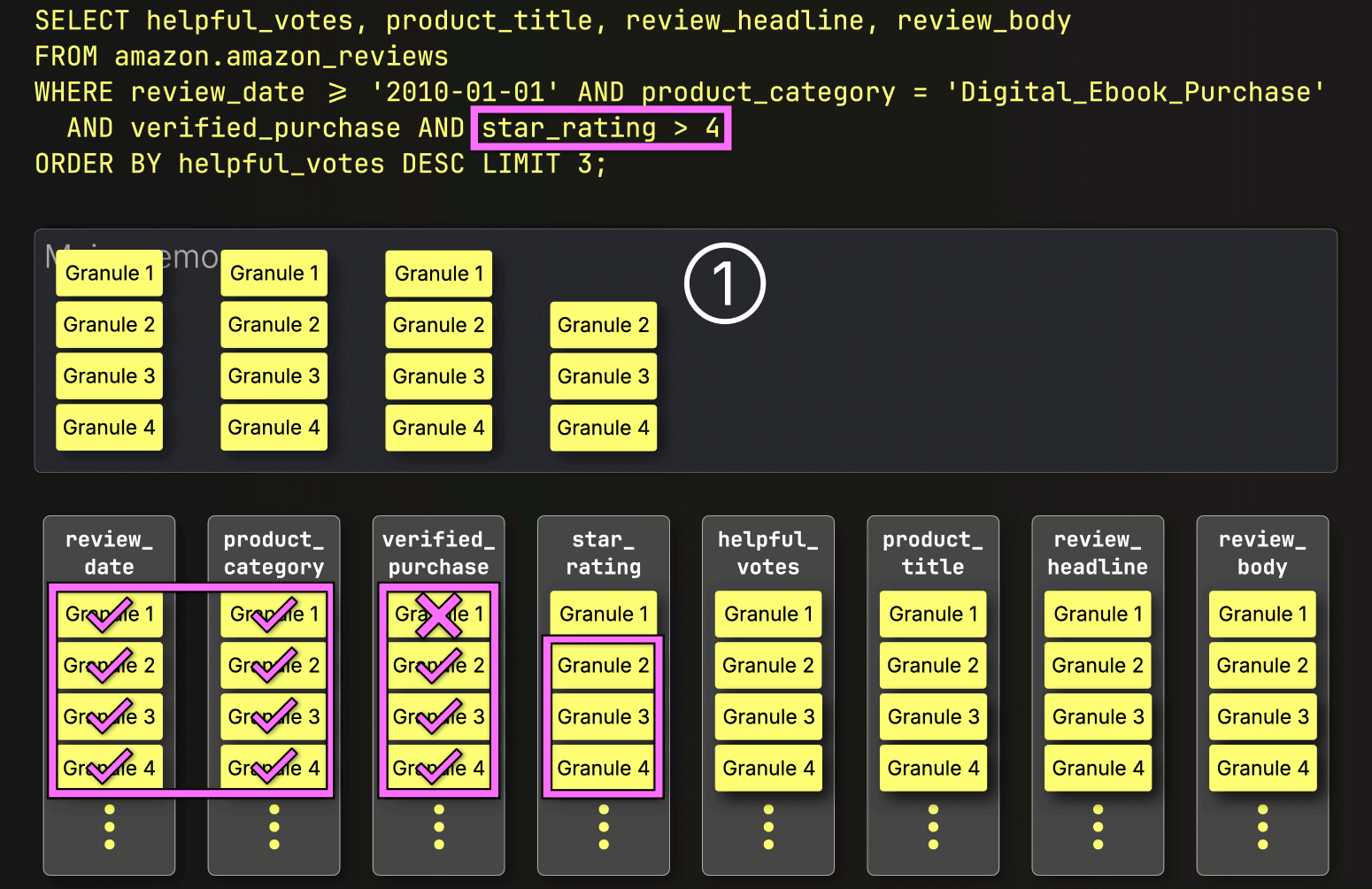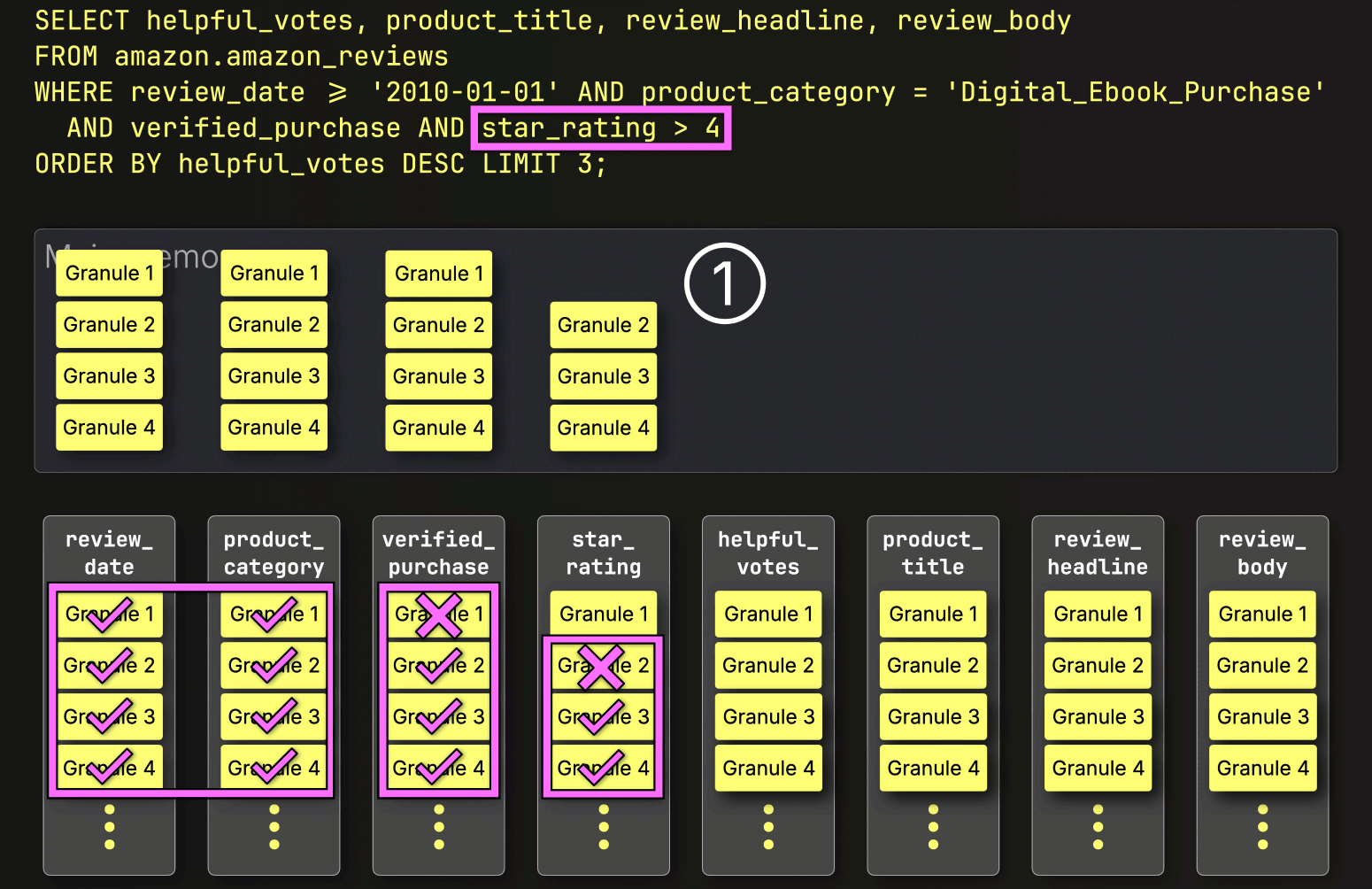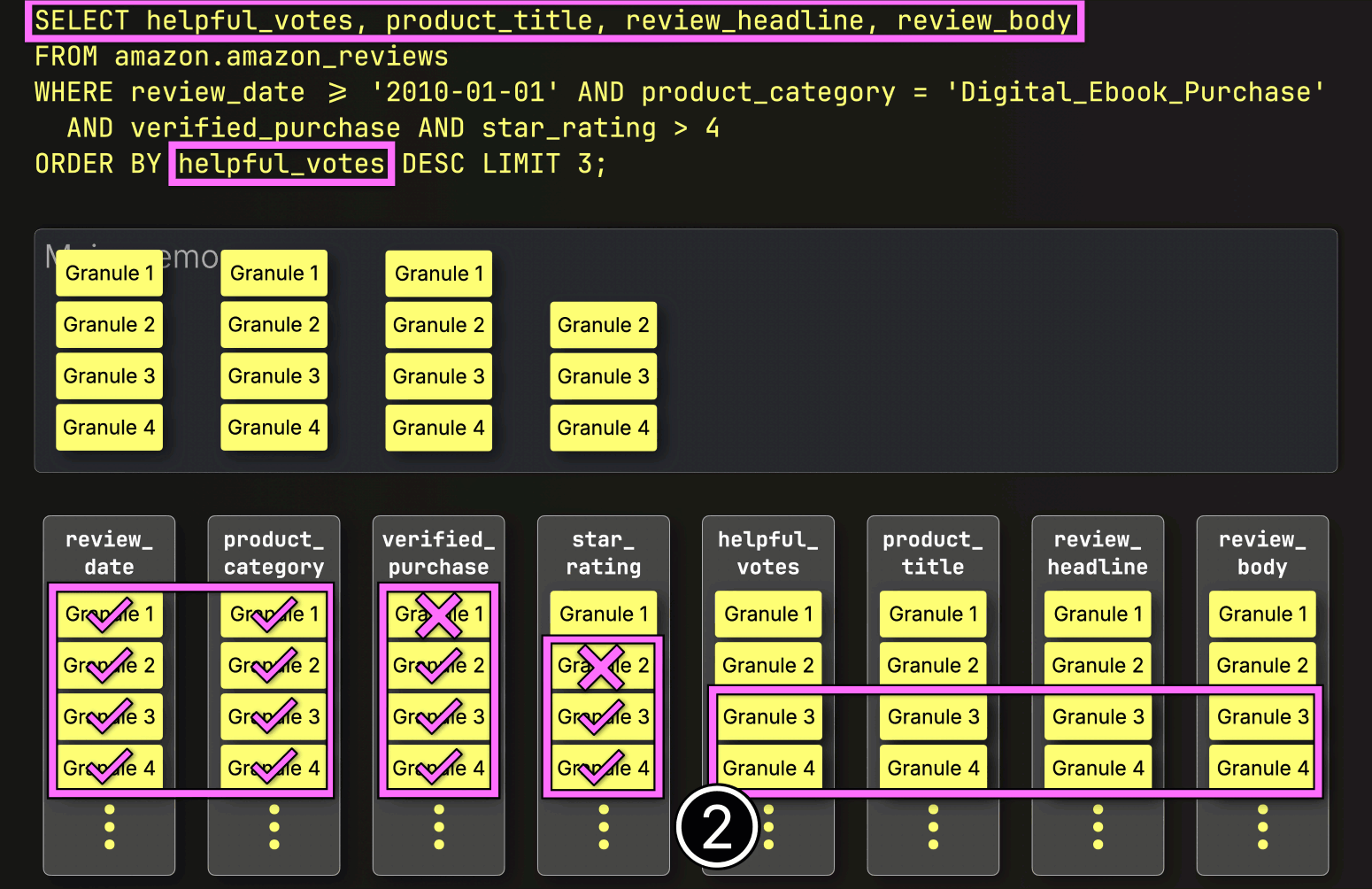
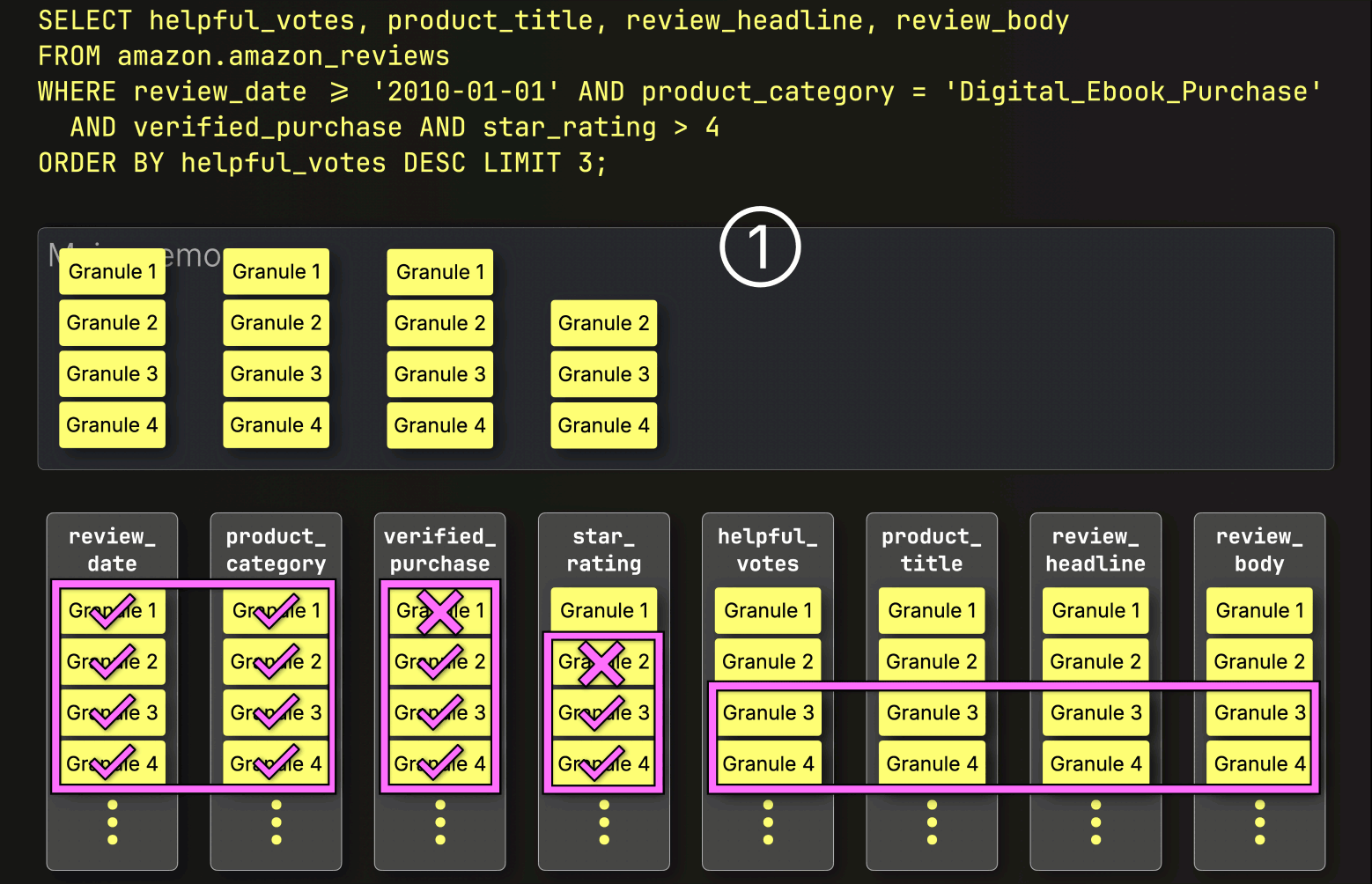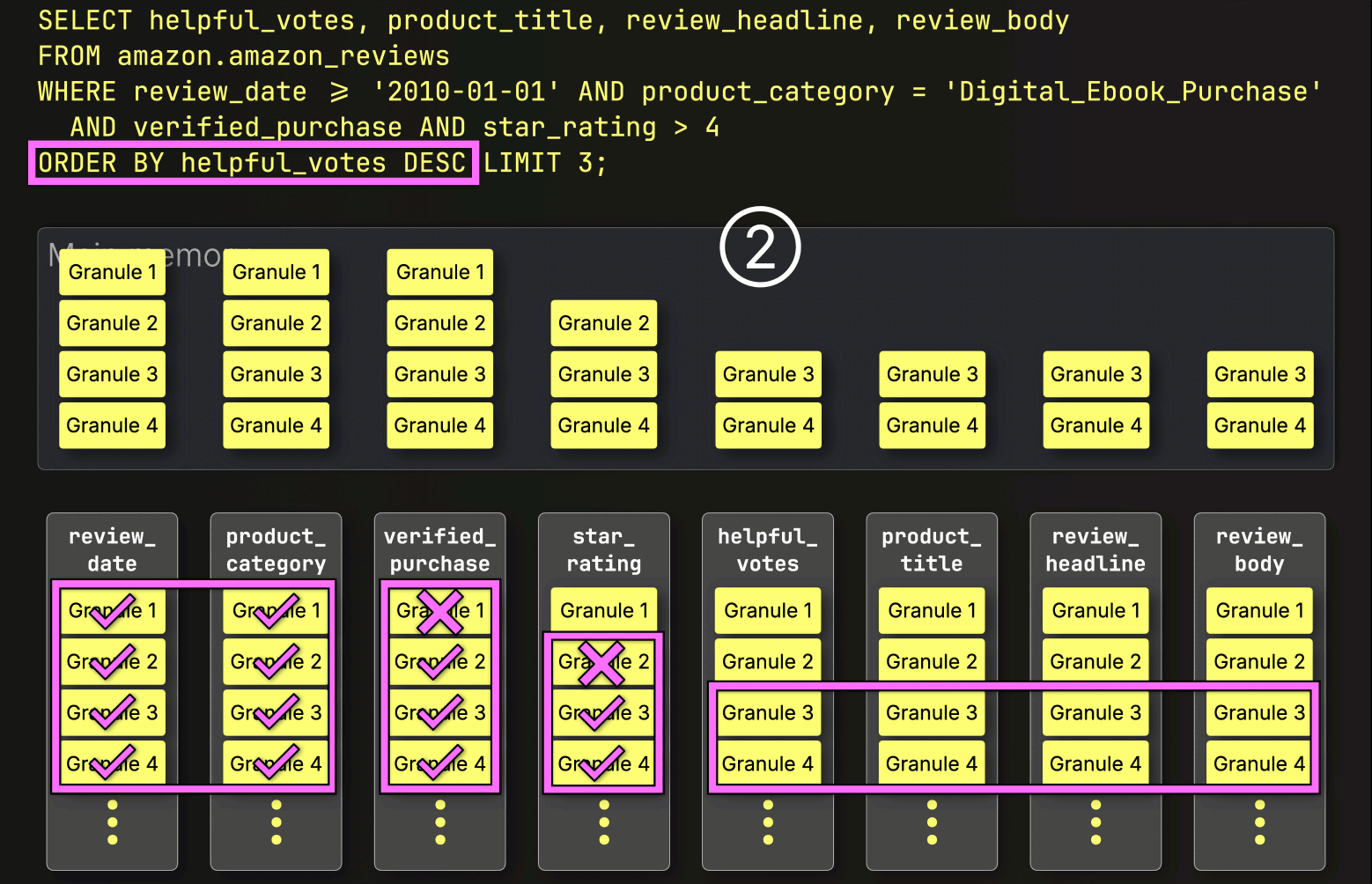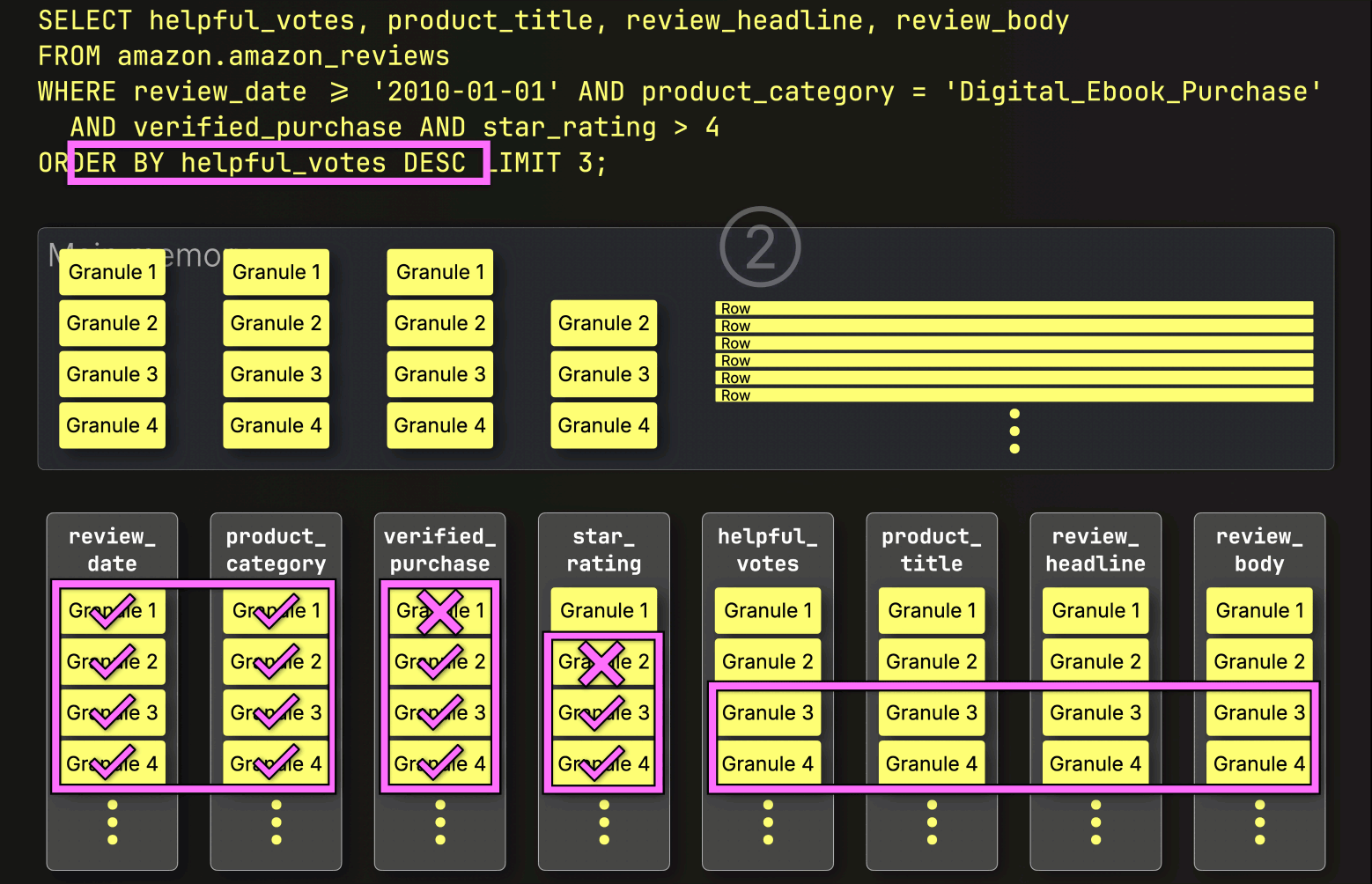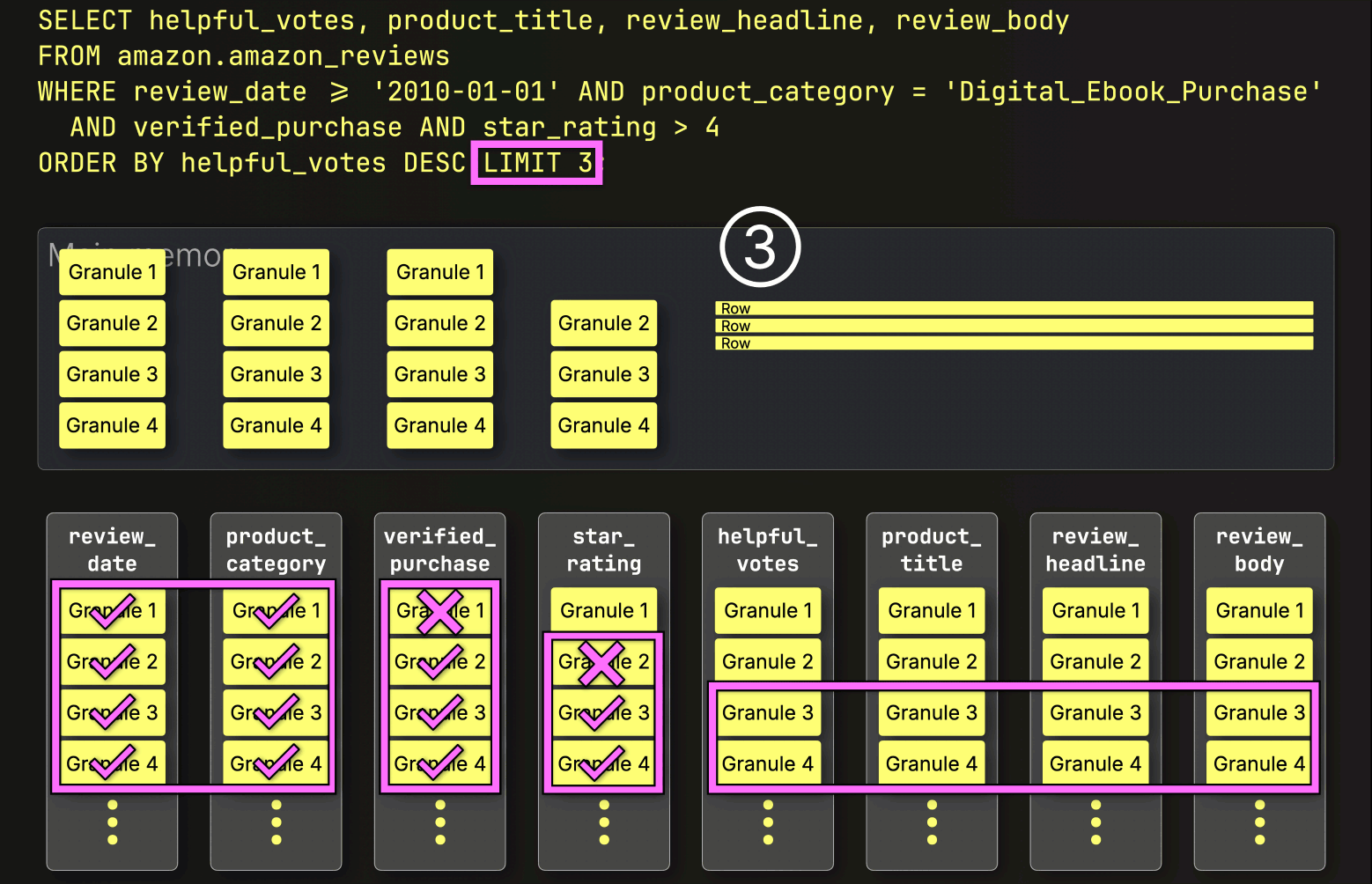
選択されたすべての列グラニュールを事前にストリーミングする代わりに、ClickHouseはPREWHERE処理を開始し、①インデックス分析によって特定されたプライマリキー列グラニュールのみをロードして、実際に一致が含まれているかを確認します。この場合、選択されたすべてのグラニュールが一致するため、②次のフィルタ列であるverified_purchaseの位置合わせされたグラニュールが、さらなるフィルタリングのためにロードされるように選択されます。
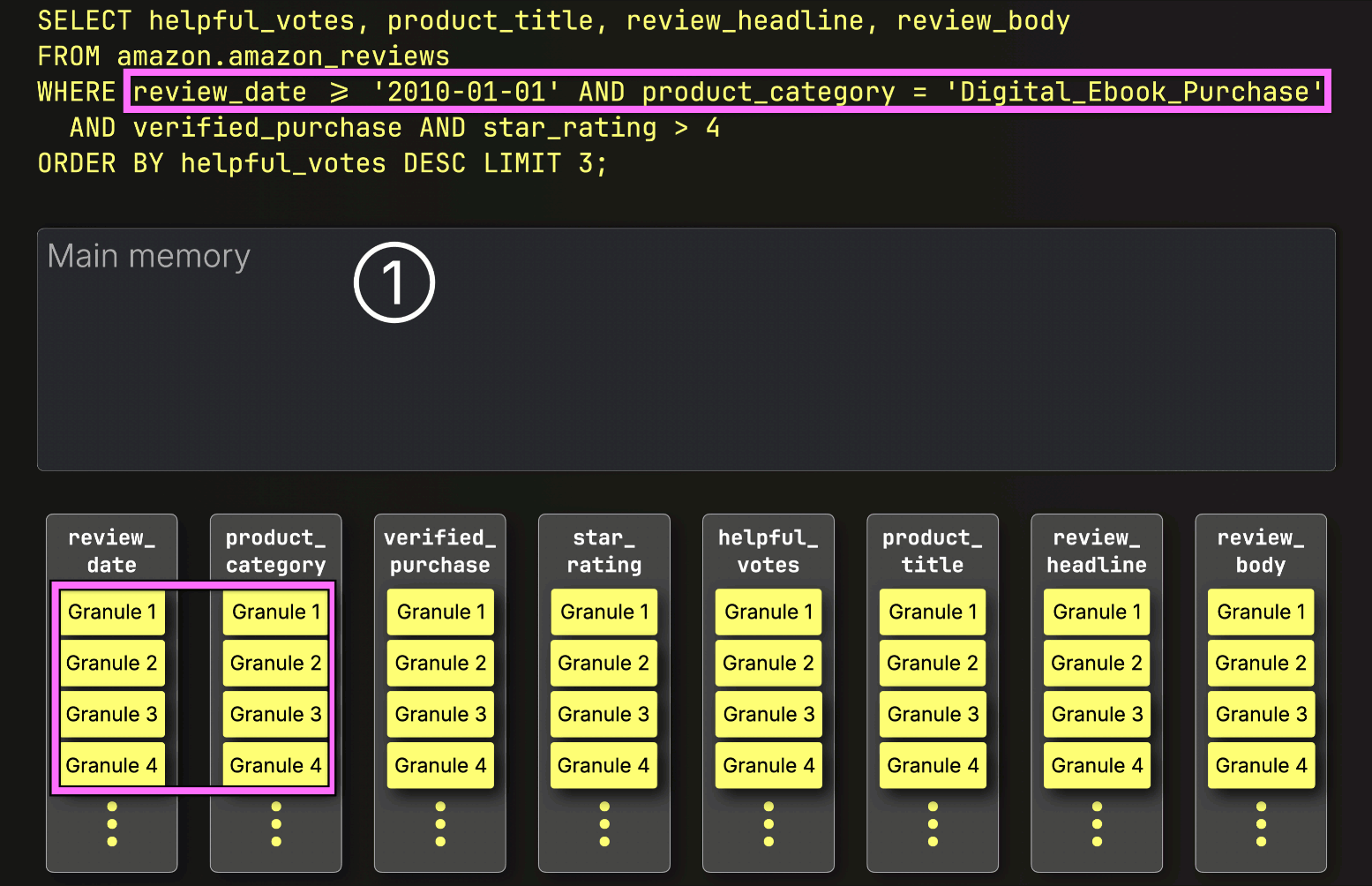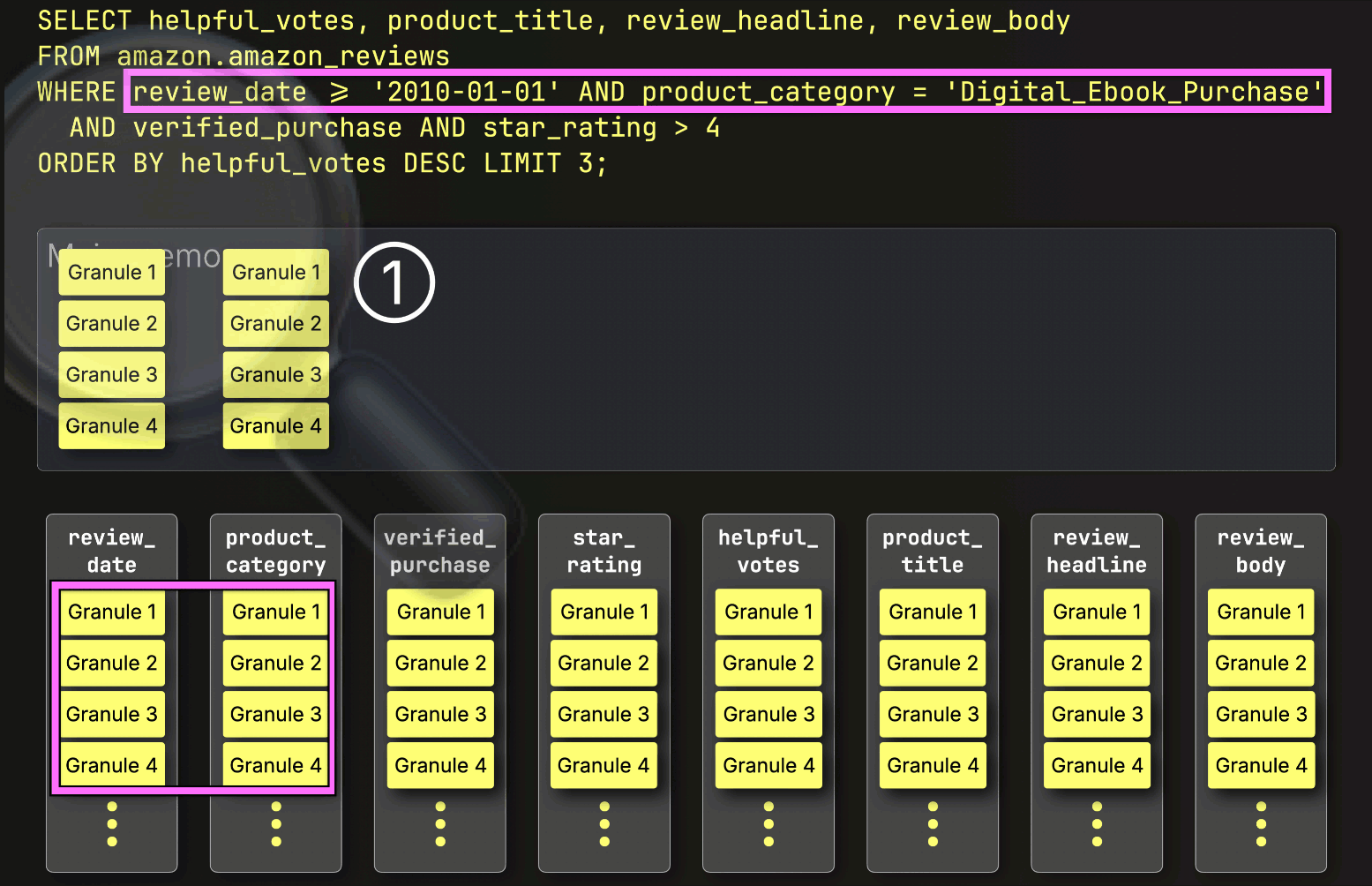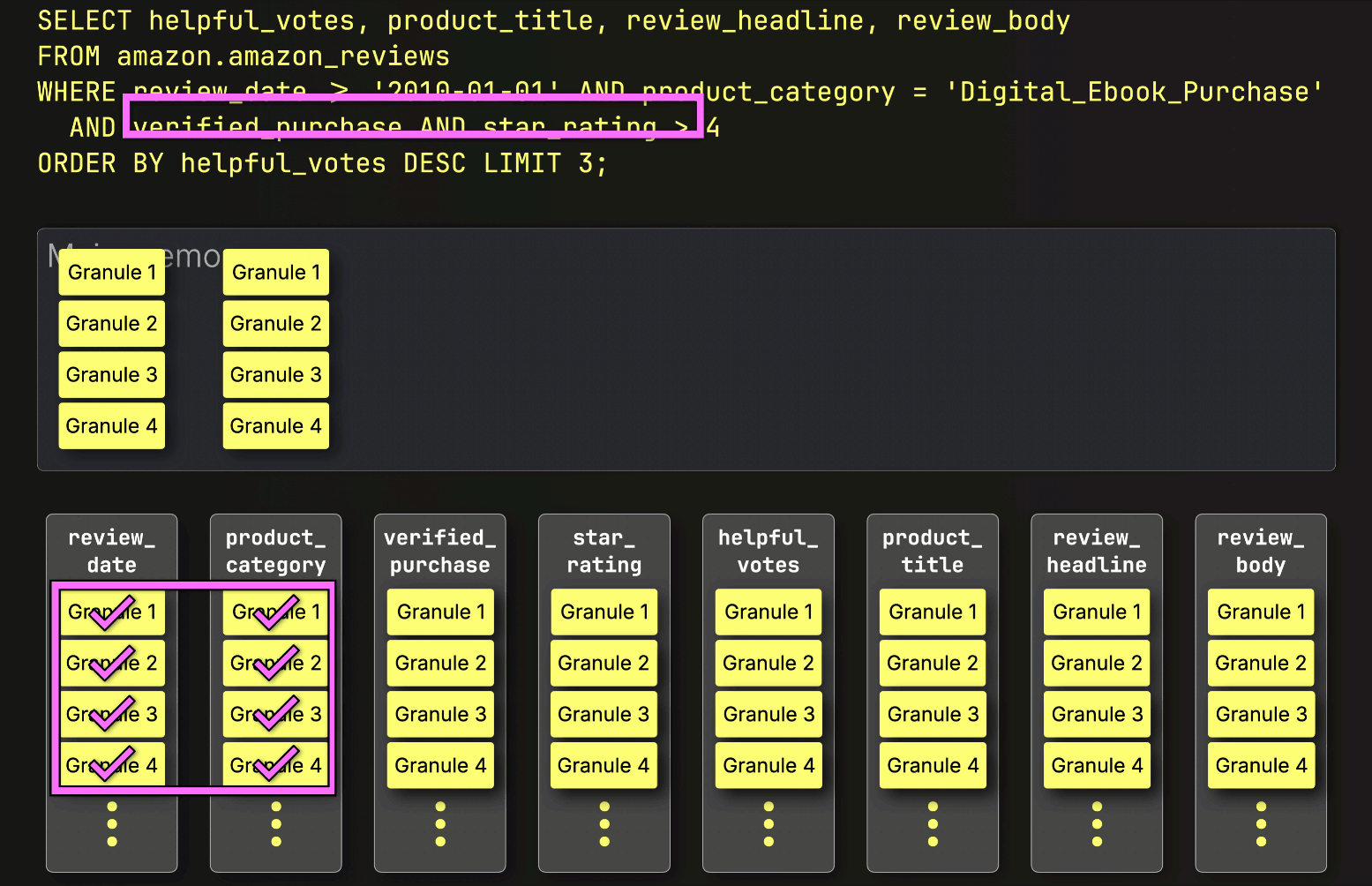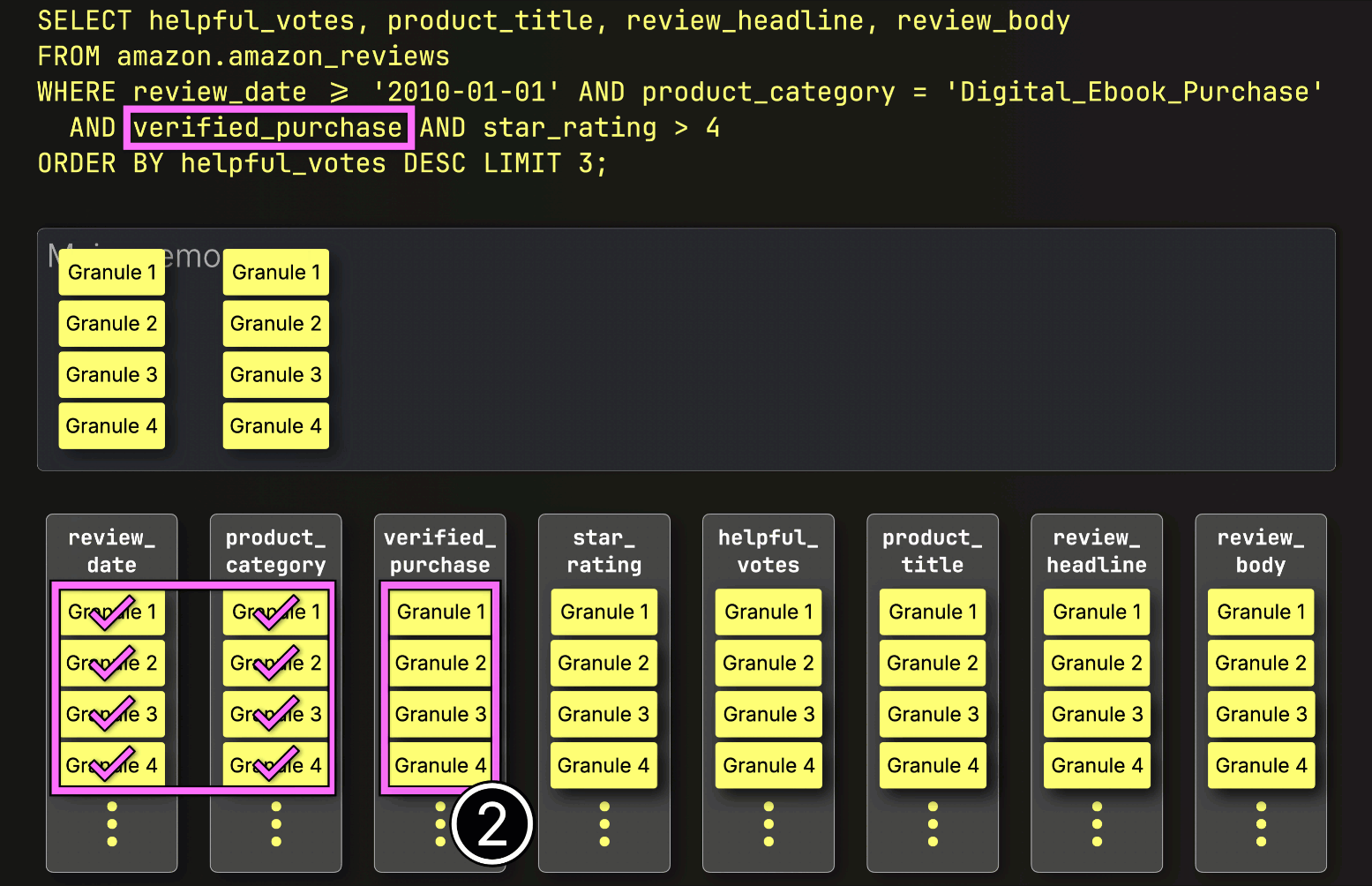
次に、ClickHouseは①選択されたverified_purchase列のグラニュールを読み取り、フィルタverified_purchase(verified_purchase == Trueのショートカット)を評価します。
この場合、4つのグラニュールのうち3つが一致する行を含んでいるため、②次のフィルタ列であるstar_ratingから、それらの位置的に整列したグラニュールのみがさらなる処理のために選択されます。
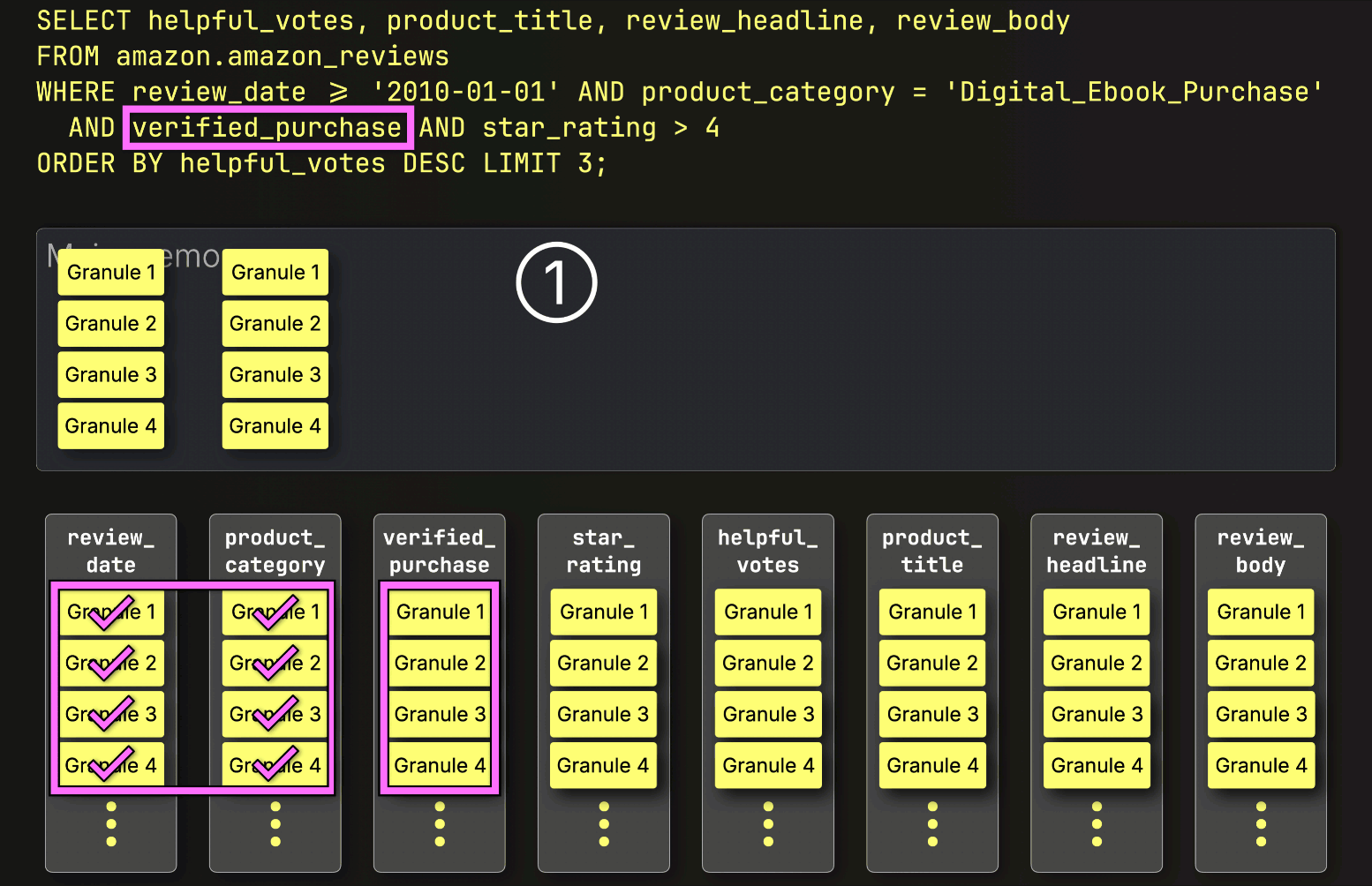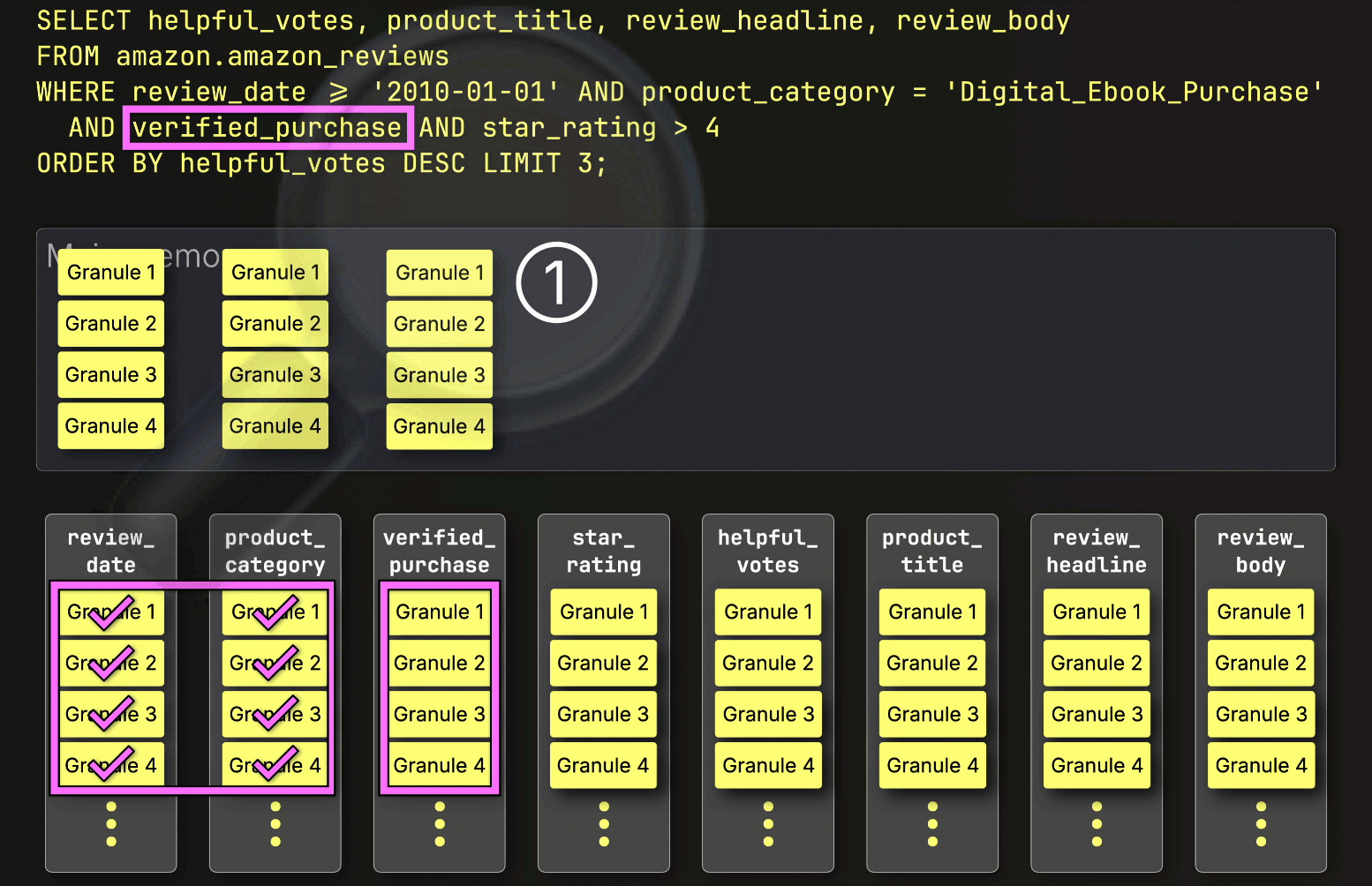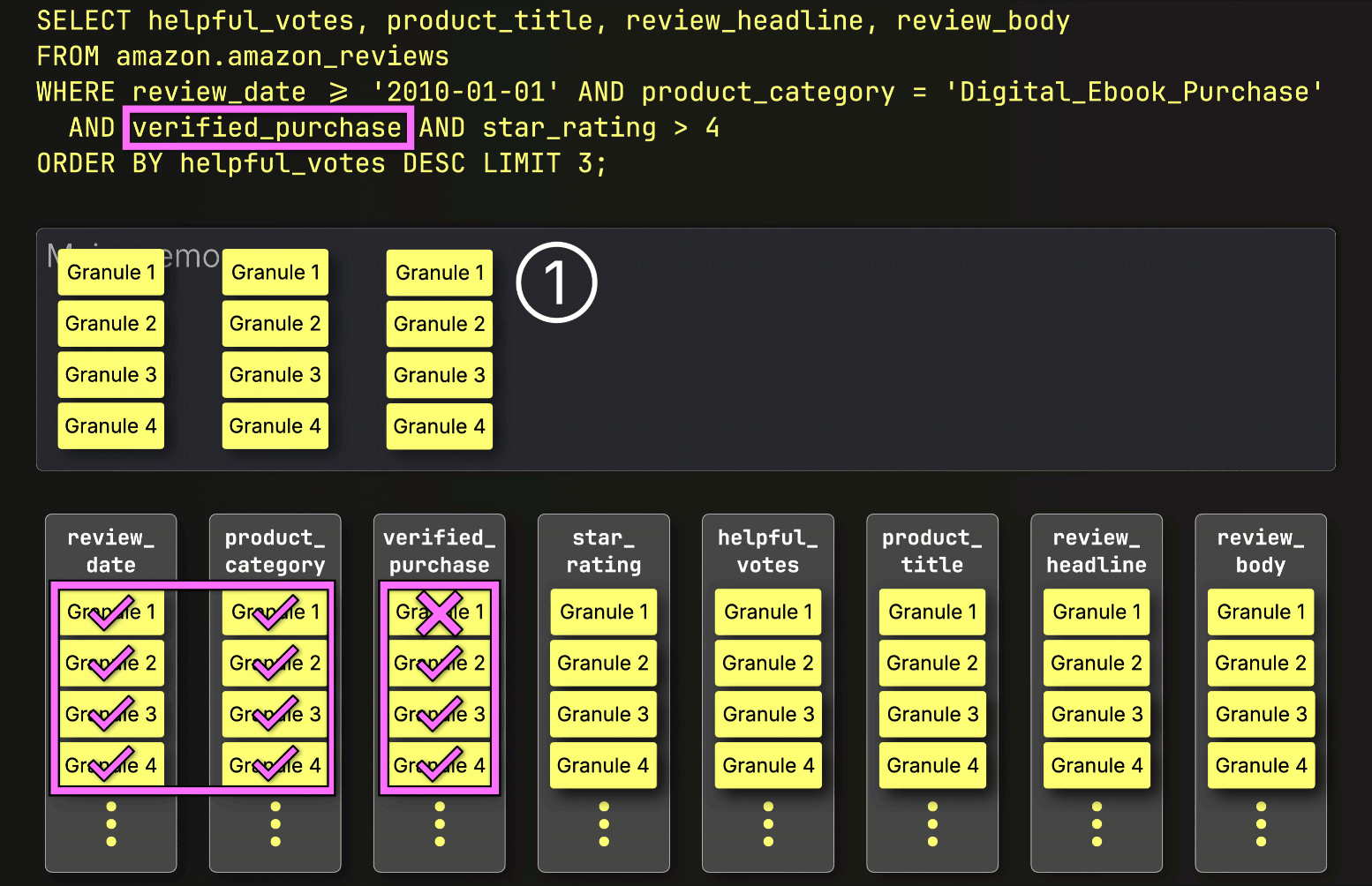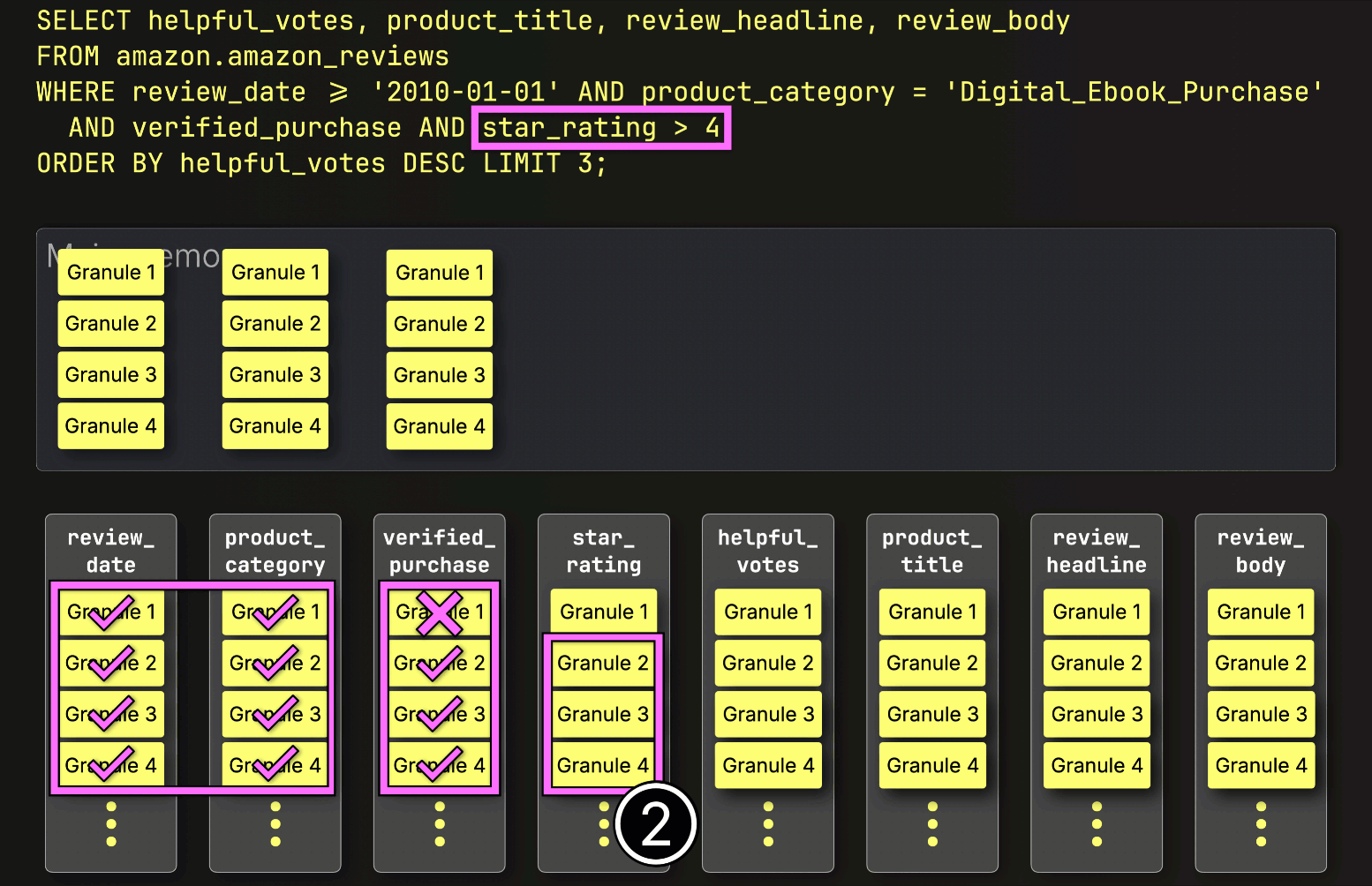
最後に、ClickHouseはstar_rating列から選択された3つのグラニュールを読み取り、最後のフィルタstar_rating > 4を評価します。
3つのグラニュールのうち2つが一致する行を含んでいるため、残りの列(helpful_votes、product_title、review_headline、review_body)から位置的に整列したグラニュールのみが、さらなる処理のためにロードされるように選択されます。
これで、PREWHERE処理は完了です。
プライマリインデックスによって選択されたすべての列グラニュールを事前にロードしてから残りのフィルタを適用する代わりに、PREWHEREは選択されたデータを早期に事前フィルタリングします(そのため、この名前が付けられています)。ClickHouseは、コストベースのアプローチ(通常は読み取りコストが最も低い列から開始)を使用してフィルタを1列ずつ評価し、各ステップを通過する行のデータのみをロードします。これにより、データセットが段階的に絞り込まれ、クエリがソート、集計、
LIMIT、SELECTなどの主要な操作を実行する前にI/Oが削減されます。
PREWHEREはインデックス作成とは独立して機能することにも注意してください。クエリにインデックス付けされていない列のフィルタしかない場合でも、一致しない行を早期にスキップすることでI/Oを削減するのに役立ちます。
PREWHEREフィルタリング後のステップ #
PREWHEREフィルタリングの後、ClickHouseは①選択されたデータをロードし、②ソートし、③LIMIT句を適用します。
これまでに追加してきた各レイヤーは、クエリ時間を少しずつ短縮し、不要なデータをスキップし、I/Oを削減し、作業を効率化してきました。
220秒かかったフルスキャンから、すでに61秒まで短縮されました。しかし、まだ終わりではありません。最後のレイヤーが、これまでで最大の削減をもたらします。
③ 遅延マテリアライゼーションの有効化 #
遅延マテリアライゼーションがスタックに加わるとどうなるか見てみましょう。遅延マテリアライゼーションを含むすべてのI/O最適化を有効にして、クエリを最後に一度実行します。
SELECT
helpful_votes,
product_title,
review_headline,
review_body
FROM amazon.amazon_reviews
WHERE review_date >= '2010-01-01'
AND product_category = 'Digital_Ebook_Purchase'
AND verified_purchase
AND star_rating > 4
ORDER BY helpful_votes DESC
LIMIT 3
FORMAT Null
SETTINGS
optimize_move_to_prewhere = true,
query_plan_optimize_lazy_materialization = true;
0 rows in set. Elapsed: 0.181 sec. Processed 53.01 million rows, 807.55 MB (292.95 million rows/s., 4.46 GB/s.) Peak memory usage: 3.88 MiB.
😮 61 秒から 181 ミリ秒へ、338 倍の高速化。
ClickHouseは同じ5300万行を処理しましたが、読み取る列データは20倍少なく、使用メモリは150倍少なく、瞬く間に終了しました。
その仕組みを詳しく見ていきましょう。
説明は簡単です。
PREWHEREフィルタリングの後、ClickHouseは残りのすべての列をすぐにロードしません。
代わりに、次に必要なものだけをロードします。次のステップはhelpful_votesによるソートとLIMITの適用なので、ClickHouseは①選択された(そしてPREWHEREでフィルタリングされた)helpful_votesグラニュールのみをロードし、②それらの行をソートし、③LIMITを適用し、そしてその後にのみ④対応する行を大きなproduct_title、review_headline、review_body列からロードします。
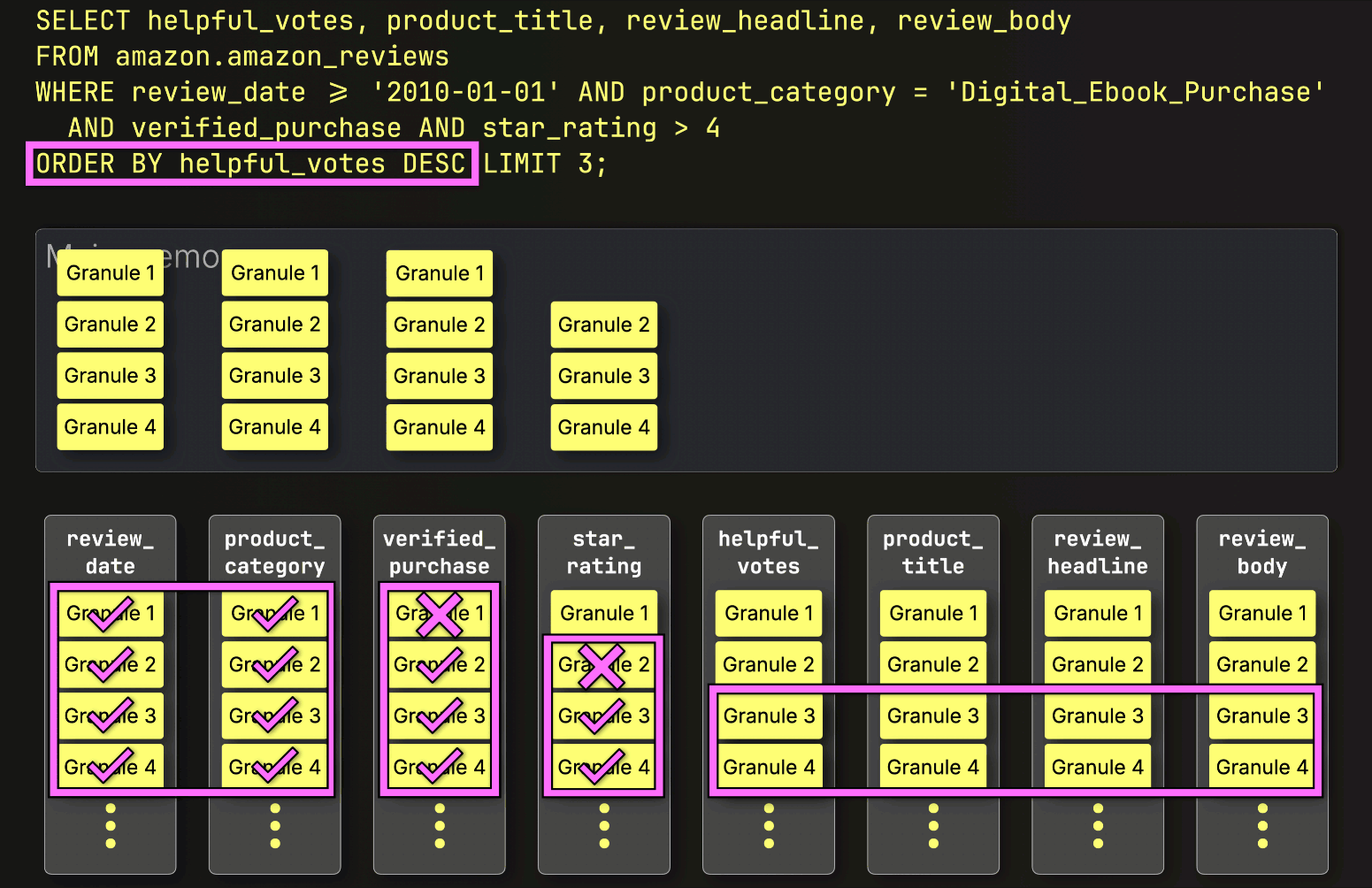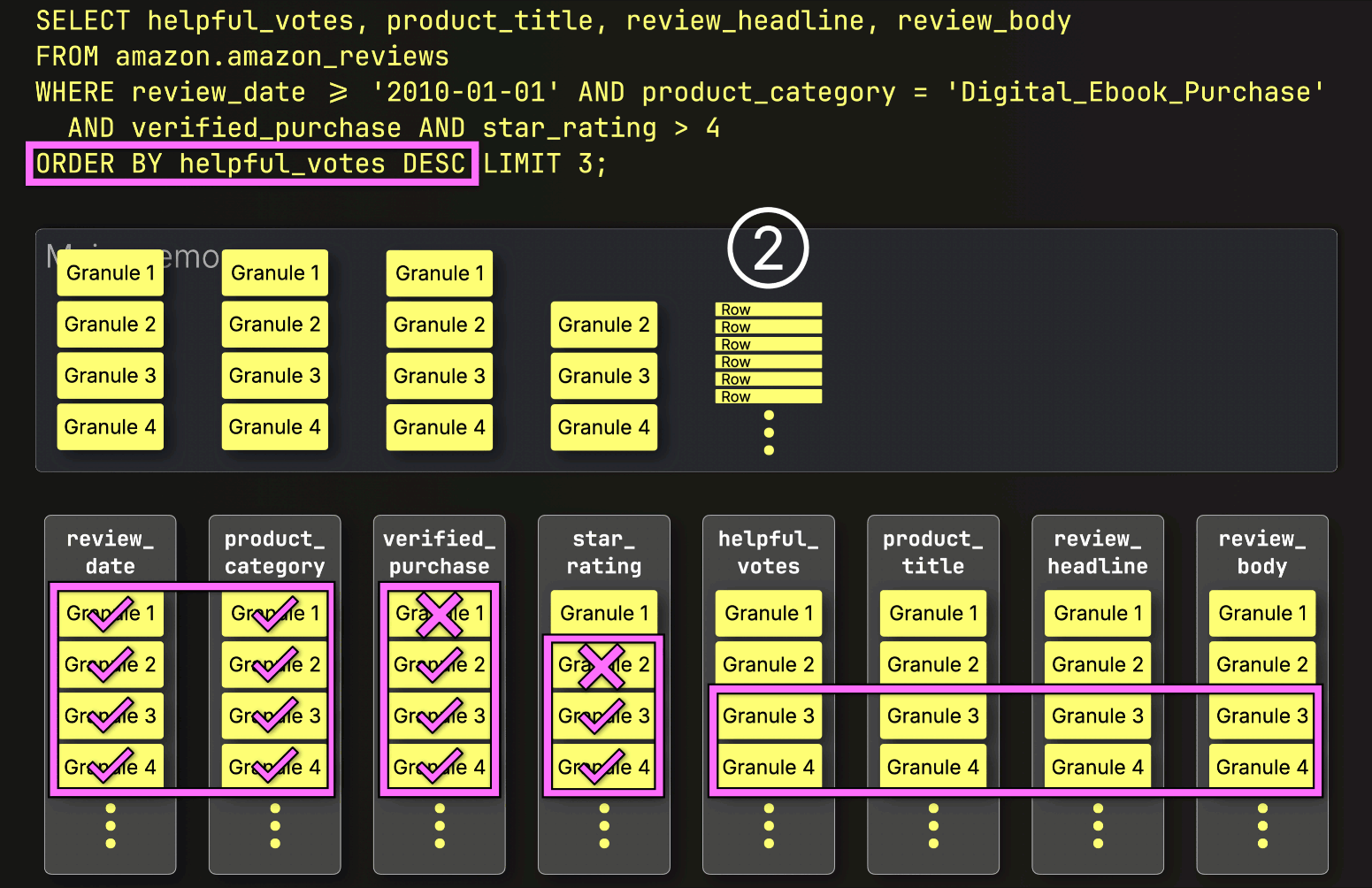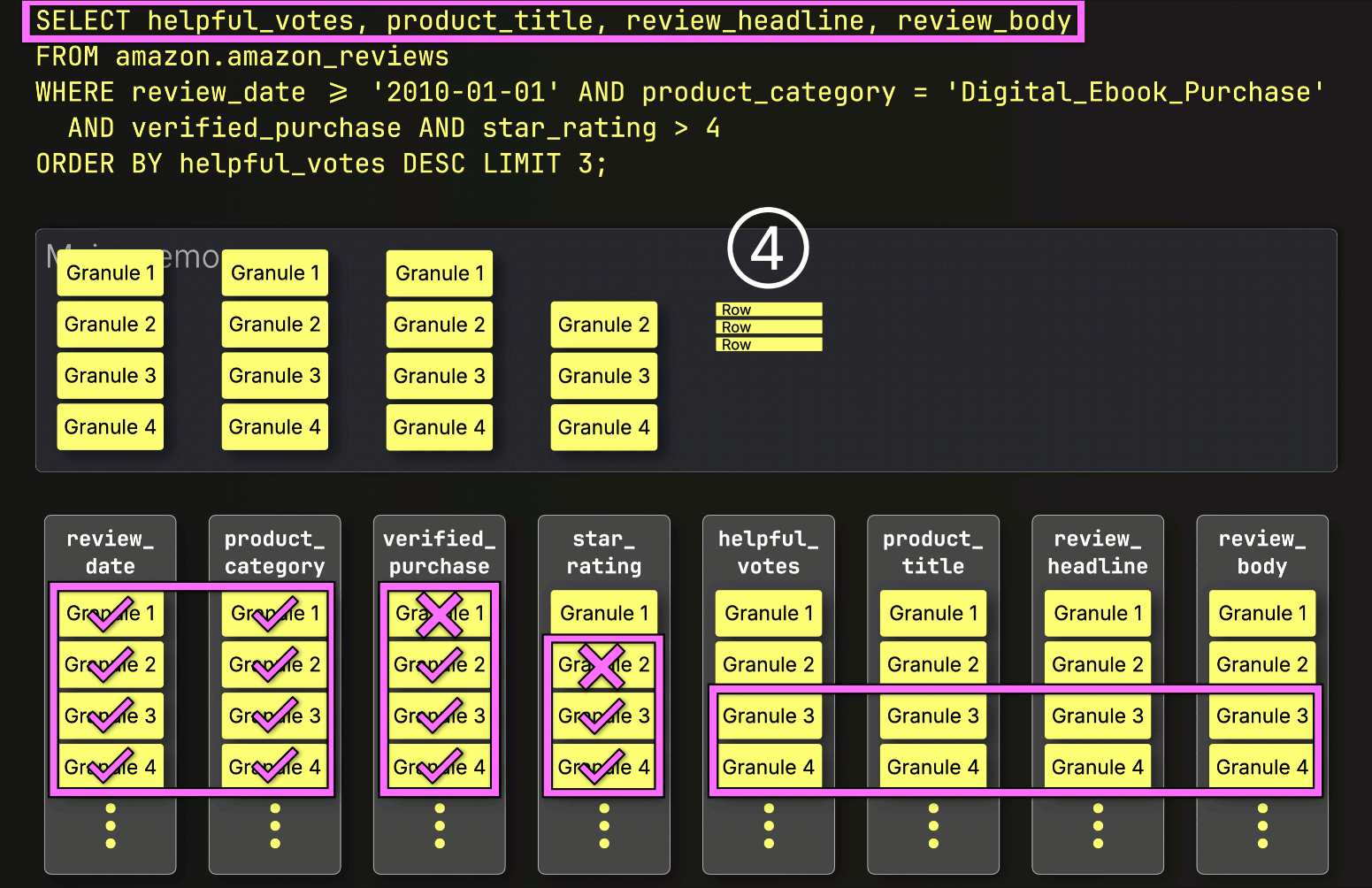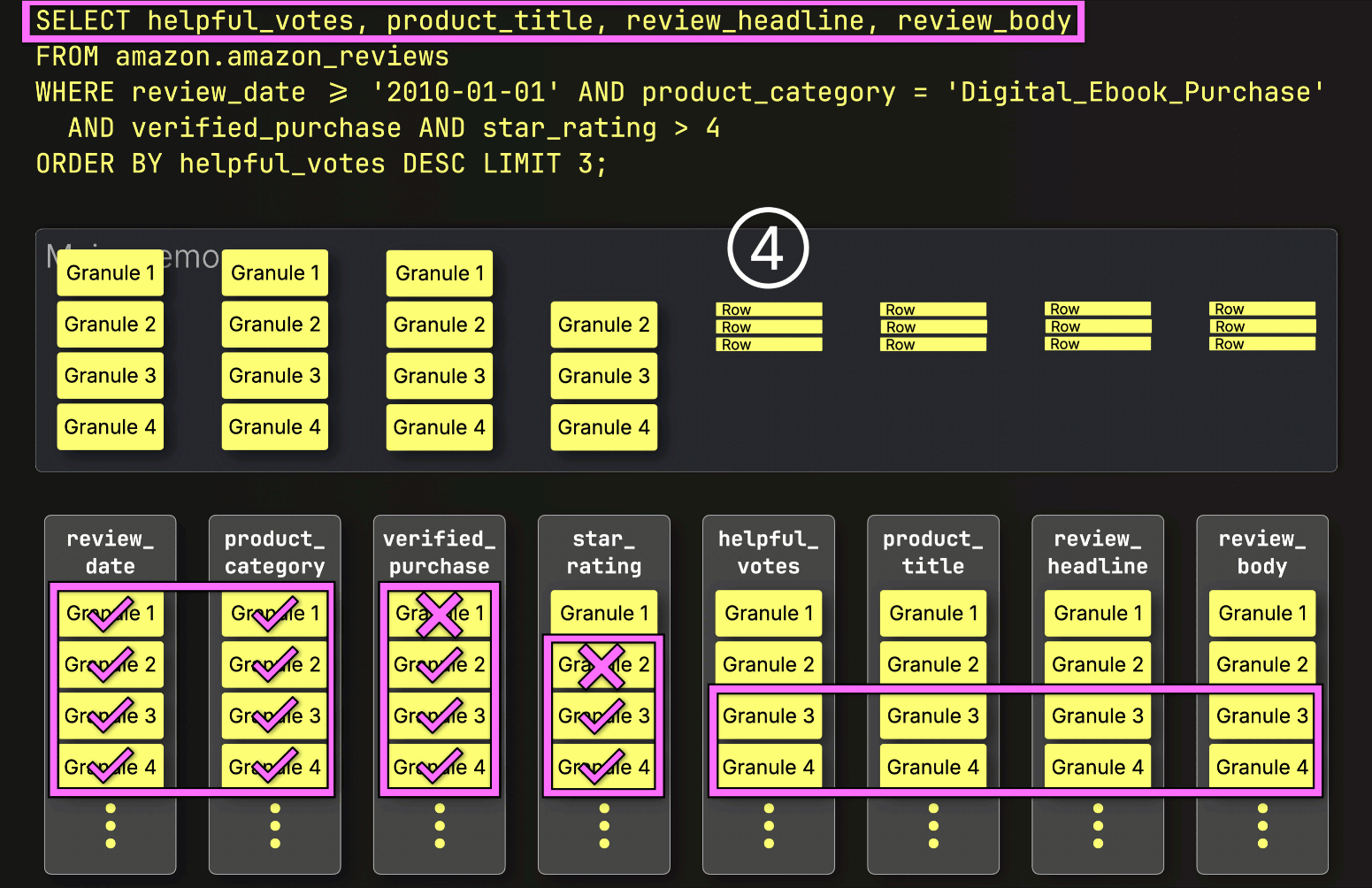
そして、このようにして最後のレイヤーが所定の位置に収まり、実行時間は220秒からわずか181ミリ秒に短縮されました。同じクエリ、同じテーブル、同じマシン、同じ遅いディスク…ただ1,215倍高速になっただけです。変更したのは、データの読み取り方法とタイミングだけです。
この例では、クエリが大きなテキスト列を選択し、遅延マテリアライゼーションのおかげで最終的にそれらから3行しか必要とされないため、遅延マテリアライゼーションが最大の効果をもたらします。しかし、データセットとクエリの形状によっては、インデックス作成やPREWHEREのような初期の最適化の方が大きな節約をもたらす場合があります。これらの技術は連携して機能し、それぞれが異なる方法でI/O削減に貢献します。
注意: 遅延マテリアライゼーションは LIMIT N クエリに対して自動的に適用されますが、N のしきい値までです。これは query_plan_max_limit_for_lazy_materialization 設定(デフォルト: 10)によって制御されます。0 に設定すると、遅延マテリアライゼーションは上限なしですべての LIMIT 値に適用されます。
フィルタなしでの高速化:遅延マテリアライゼーション単独の効果 #
インデックス作成とPREWHEREの恩恵を受けるには、クエリにフィルタが必要です。インデックス作成の場合はプライマリキー列に、PREWHEREの場合は任意の列にフィルタが必要です。上記で示したように、遅延マテリアライゼーションはこれらにきれいに重ねられますが、他とは異なり、列フィルタがまったくないクエリも高速化できます。
これを実証するために、サンプルクエリからすべてのフィルタを削除し、日付、製品、評価、または検証ステータスに関係なく、役立つ投票数が最も多いレビューを見つけ、上位3件をタイトル、見出し、全文とともに返します。
まず、遅延マテリアライゼーションを無効にして、そのクエリを(コールドファイルシステムキャッシュで)実行します。
SELECT
helpful_votes,
product_title,
review_headline,
review_body
FROM amazon.amazon_reviews
ORDER BY helpful_votes DESC
LIMIT 3
FORMAT Vertical
SETTINGS
query_plan_optimize_lazy_materialization = false;
Row 1: ────── helpful_votes: 47524 product_title: Kindle: Amazon's Original Wireless Reading Device (1st generation) review_headline: Why and how the Kindle changes everything review_body: This is less a "pros and cons" review than a hopefully use... Row 2: ────── helpful_votes: 41393 product_title: BIC Cristal For Her Ball Pen, 1.0mm, Black, 16ct (MSLP16-Blk) review_headline: FINALLY! review_body: Someone has answered my gentle prayers and FINALLY designed ... Row 3: ────── helpful_votes: 41278 product_title: The Mountain Kids 100% Cotton Three Wolf Moon T-Shirt review_headline: Dual Function Design review_body: This item has wolves on it which makes it intrinsically swee... 0 rows in set. Elapsed: 219.071 sec. Processed 150.96 million rows, 71.38 GB (689.08 thousand rows/s., 325.81 MB/s.) Peak memory usage: 1.11 GiB.
次に、再度クエリを実行します(再びコールドファイルシステムキャッシュを使用)。ただし、今回は遅延マテリアライゼーションを有効にします。
SELECT
helpful_votes,
product_title,
review_headline,
review_body
FROM amazon.amazon_reviews
ORDER BY helpful_votes DESC
LIMIT 3
FORMAT Vertical
SETTINGS
query_plan_optimize_lazy_materialization = true;
Row 1: ────── helpful_votes: 47524 product_title: Kindle: Amazon's Original Wireless Reading Device (1st generation) review_headline: Why and how the Kindle changes everything review_body: This is less a "pros and cons" review than a hopefully use... Row 2: ────── helpful_votes: 41393 product_title: BIC Cristal For Her Ball Pen, 1.0mm, Black, 16ct (MSLP16-Blk) review_headline: FINALLY! review_body: Someone has answered my gentle prayers and FINALLY designed ... Row 3: ────── helpful_votes: 41278 product_title: The Mountain Kids 100% Cotton Three Wolf Moon T-Shirt review_headline: Dual Function Design review_body: This item has wolves on it which makes it intrinsically swee... 0 rows in set. Elapsed: 0.139 sec. Processed 150.96 million rows, 1.81 GB (1.09 billion rows/s., 13.06 GB/s.) Peak memory usage: 3.80 MiB.
驚きました:1,576倍の高速化 — 219秒からわずか139ミリ秒へ — データ読み取り量は40倍少なく、メモリ使用量は300倍低くなりました。
この例は、ClickHouseのI/O最適化の中で遅延マテリアライゼーションをユニークなものにしている点を浮き彫りにしています。
遅延マテリアライゼーションは、高速化を実現するために列フィルタを必要としません。インデックス作成とPREWHEREはデータをスキップするためにクエリ述語に依存しますが、遅延マテリアライゼーションは、必要なときに必要なものだけをロードすることで、純粋に作業を遅延させることによってパフォーマンスを向上させます。
クエリ実行計画における遅延マテリアライゼーションの確認 #
前のクエリの遅延マテリアライゼーションは、EXPLAIN句を使用してクエリの論理実行計画を調べることで確認できます。
EXPLAIN actions = 1
SELECT
helpful_votes,
product_title,
review_headline,
review_body
FROM amazon.amazon_reviews
ORDER BY helpful_votes DESC
LIMIT 3
SETTINGS
query_plan_optimize_lazy_materialization = true;
... Lazily read columns: review_headline, review_body, product_title Limit Sorting ReadFromMergeTree
演算子プランを下から上に読むと、ClickHouseが3つの大きなString列の読み取りをソートと制限の後まで遅延させていることがわかります。
レイヤーごとにより速く — そして今、はるかに遅延的に #
この旅は、フルテーブルスキャンから始まりました:220秒、72GBの読み取り、1GiBのメモリ使用。ClickHouseの階層化されたI/O最適化を通じて、一度に1つの技術で実行時間を削り取ってきました。
- ① プライマリインデックスは、インデックス付き列(
review_date、product_category)のフィルタに一致しないグラニュールを削減しました。 - ② PREWHEREは、インデックスを通過したがインデックス付けされていない列(
verified_purchase、star_rating)のフィルタに失敗したグラニュールを早期にフィルタリングし、不要な読み取りを削減しました。 - ③ 遅延マテリアライゼーションは、大きな
SELECT列(product_title、review_headline、review_body)の読み取りを、helpful_votesによるソートとLIMITの適用後まで遅延させました。
各レイヤーが役立ちましたが、私たちのデータセットとクエリの形状にとって、遅延マテリアライゼーションはゲームを変えました。
結果は?
- フィルタリングされたクエリで220秒 → 0.18秒 = 1,200倍以上の高速化
- フルテーブルのトップNクエリで219秒 → 0.139秒 = 1,500倍以上の高速化
**同じテーブル、同じマシン、同じSQLコード。**変更したのは、ClickHouseがデータを読み取る方法とタイミングだけです。
遅延マテリアライゼーションはClickHouseを高速化するだけでなく、I/O最適化スタックを完成させます。 そして最も遅延的な部分は?それ(とPREWHERE)はデフォルトでオンになっています。指一本動かさずに速度を得られます



