title
ClickHouse vs Snowflakeによるリアルタイム分析 - 比較と移行

要約 #
この「ClickHouse vs. Snowflake」ブログシリーズは2つのパートで構成されており、それぞれ独立して読むことができます。各パートは以下のとおりです。
-
比較と移行 - 本記事では、ClickHouseとSnowflakeのアーキテクチャ上の類似点と相違点を概説し、ClickHouse Cloudがリアルタイム分析に特に適した機能をレビューします。SnowflakeからClickHouseへのワークロード移行に興味がある方のために、データセットの違いやデータ移行方法についても解説します。
-
ベンチマークとコスト分析 - シリーズのもう一つの記事では、提案するアプリケーションを支える一連のリアルタイム分析用クエリを両システムでベンチマークし、さまざまな最適化を試した上でコストを直接比較しています。私たちの結果によると、ClickHouse Cloudはパフォーマンスとコストの両面でSnowflakeを上回りました。
- 本番運用では、ClickHouse CloudはSnowflakeより3〜5倍コスト効率が高い
- クエリ速度はSnowflakeと比較して2倍以上高速
- データ圧縮率はSnowflakeより38%優れている
目次 #
はじめに #
Snowflakeはオンプレミスのレガシーなデータウェアハウスのワークロードをクラウドに移行することを主目的としたクラウドデータウェアハウスです。大規模な長時間レポート処理に最適化されています。データをクラウドへ移行するにつれ、データオーナーはこのデータをどのように活用してさらに価値を引き出せるかを検討するようになります。たとえば、社内外で使うリアルタイムアプリケーションに活用するといったケースです。そこで、リアルタイム分析に最適化されたデータベースであるClickHouseの必要性に気づきます。
私たちはこの比較を公正に行うよう努めており、Snowflakeがデータウェアハウス用途で素晴らしい機能をいくつも備えていることも認めています。私たちはClickHouseの専門家ではありますが、Snowflakeに関しては必ずしも専門家ではありません。Snowflakeに詳しいユーザーからのフィードバックや改善の提案を歓迎しています。Snowflakeが他のユースケースにも利用可能であることは承知していますが、本記事の範囲はリアルタイム分析に絞られています。
ClickHouse vs Snowflake #
類似点 #
Snowflakeはクラウドベースのデータウェアハウスプラットフォームで、大量データの格納・処理・分析をスケーラブルかつ効率的に行うためのソリューションを提供します。ClickHouse同様、Snowflakeは既存技術の上に構築されたものではなく、独自のSQLクエリエンジンとカスタムアーキテクチャを採用しています。
Snowflakeのアーキテクチャは、共有ディスク(私たちは「共有ストレージ」という用語を好みます)と共有ナッシングアーキテクチャをハイブリッドに組み合わせたものと説明されます。つまり、オブジェクトストア(S3など)を使ってすべての計算ノードからアクセスできる(共有ディスク)一方、クエリに応じて各計算ノードがデータの一部をローカルに保持する(共有ナッシング)仕組みです。これは理論上、両方の利点を兼ね備えているとされます。共有ディスクアーキテクチャのシンプルさと、共有ナッシングアーキテクチャのスケーラビリティを兼ね備えているわけです。
この設計は、オブジェクトストレージを主要なストレージとして利用することを前提としており、ほぼ無限の同時アクセス性と高い耐久性、スケーラブルなスループットを実現しています。
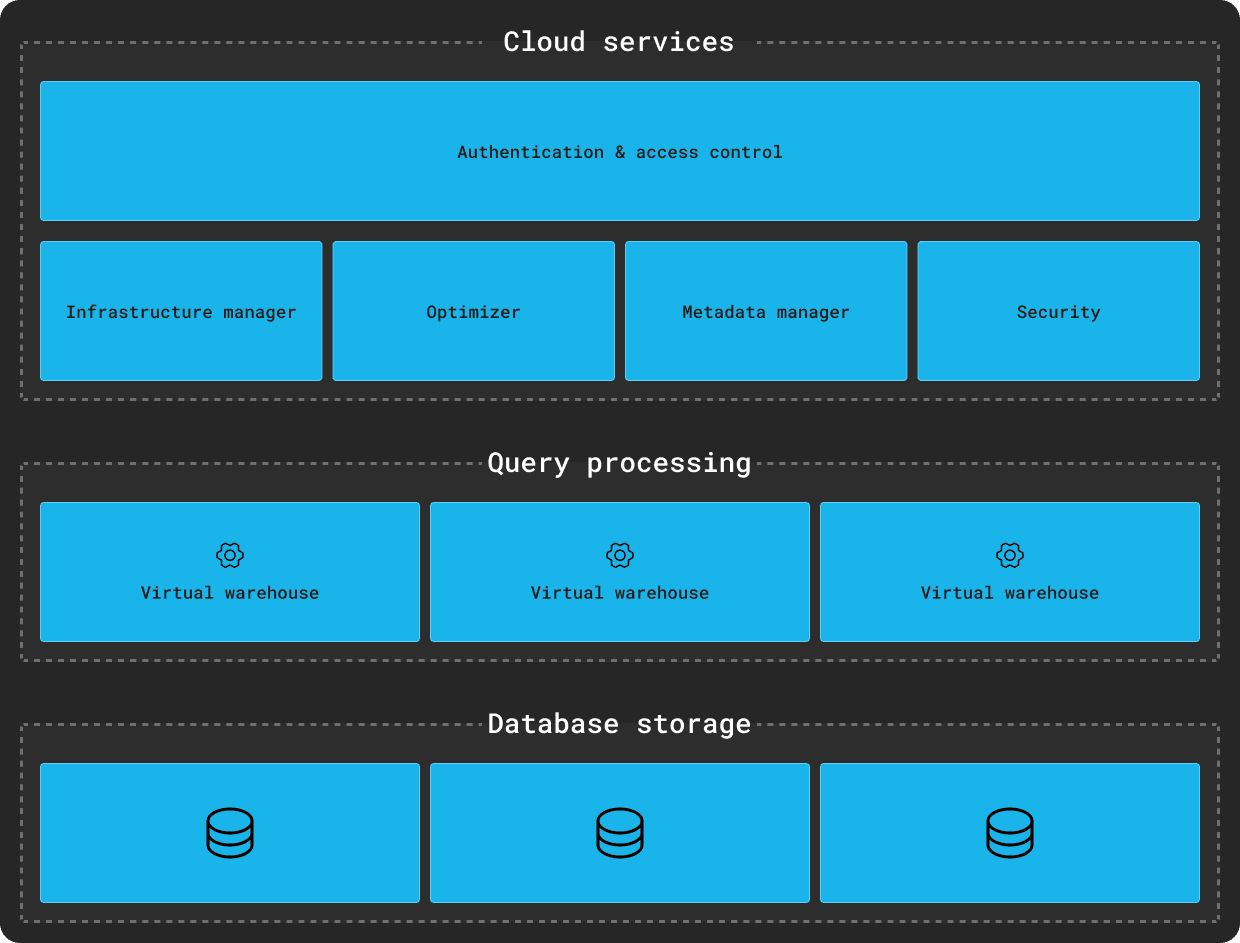 クレジット: https://docs.snowflake.com/en/user-guide/intro-key-concepts
クレジット: https://docs.snowflake.com/en/user-guide/intro-key-concepts
一方、ClickHouseはオープンソースかつクラウドホスティングされた製品で、共有ディスクと共有ナッシングのどちらの構成にもデプロイすることができます。後者はセルフマネージド環境で一般的です。CPUやメモリのスケールアップは容易ですが、共有ナッシング構成ではクラスタ構成変更の際にデータのレプリケーションや管理にまつわる古典的な課題やオーバーヘッドが発生します。
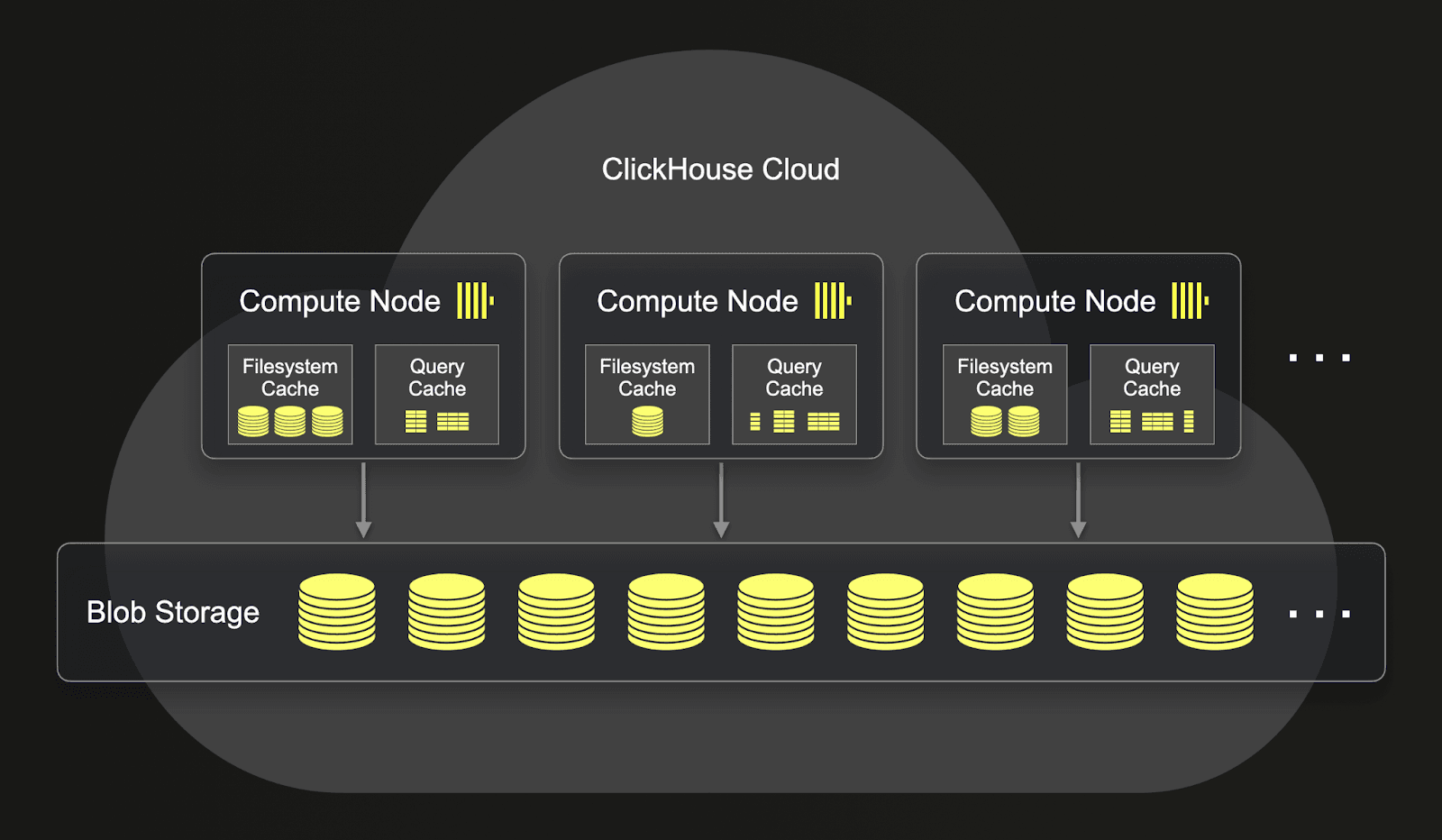
このため、ClickHouse CloudではSnowflakeと同様のコンセプトを持つ共有ストレージアーキテクチャを採用しています。S3やGCSなどのオブジェクトストアに単一コピーのデータを格納し、ほぼ無制限のストレージ容量と強力な冗長性が得られます。すべてのノードはこの単一コピーのデータと各ノード固有のローカルSSDキャッシュにアクセスできます。ノード数やスペックを調整することでCPUやメモリをスケールさせます。Snowflakeと同様、S3のスケーラビリティ特性によって、ノードを追加してもディスクI/Oやネットワークがボトルネックになりにくく、並行アクセスが増えても性能が落ちにくいのが特長です。
相違点 #
基盤となるストレージ形式やクエリエンジン以外にも、これらのアーキテクチャにはいくつか細かな違いがあります。
- Snowflakeの計算リソースは、ウェアハウスという概念を通じて提供されます。これは一定サイズのノード数で構成されます。Snowflakeはウェアハウスの具体的な構成を公開していませんが、一般的には各ノードに8vCPU、16GiB、200GBのローカルストレージ(キャッシュ用)があると理解されています。ノード数はTシャツサイズ方式で決まり、たとえばX-Smallは1ノード、Smallは2ノード、Mediumは4ノード、Largeは8ノードといった具合です。これらのウェアハウスはオブジェクトストア上にあるデータをどれでもクエリすることが可能です。クエリ負荷がかかっていないアイドル時はウェアハウスが停止し、クエリが来ると再開します。ストレージコストは常に請求されますが、ウェアハウスの料金はアクティブな時間だけ発生します。
- ClickHouse Cloudも同様に、ノードとそのローカルキャッシュストレージを使った仕組みを利用します。ただしTシャツサイズではなく、ユーザーは合計CPUとメモリを指定してサービスをデプロイし、それに応じて(あらかじめ定義した上限内で)クエリ負荷に合わせて自動的に垂直・水平方向にスケールします。ClickHouse Cloudのノードは現在、Snowflakeの1:2とは異なり1。現時点では、Snowflakeのウェアハウスほど厳密にデータと疎結合ではありませんが、将来的には疎結合の構成も可能です。ノードはアイドルになると自動的に停止し、クエリが来ると再開します。必要に応じて手動でリサイズもできます。
- ClickHouse Cloudのクエリキャッシュは各ノード固有であり、Snowflakeのようにサービスレイヤーで共有していません。それでも、ベンチマークではSnowflakeより高いパフォーマンスを示しました。
- SnowflakeとClickHouse Cloudはクエリ同時実行数を増やすために異なるアプローチを取っています。Snowflakeはマルチクラスタウェアハウスという機能で並列化を図り、クエリ同時実行数を増やします(クエリレイテンシ自体は改善しません)。一方ClickHouseでは、垂直または水平スケールによってメモリやCPUを増やすことでこれを実現します。本記事では同時実行数よりもレイテンシに主眼を置いているため詳細は扱いませんが、Snowflakeがウェアハウスごとの同時実行数をデフォルトで8に制限しているのに対し、ClickHouse Cloudは1ノードあたり1000クエリまで実行可能である点は注目に値します。
- Snowflakeはデータセットに対してコンピュートサイズを変更でき、ウェアハウスの再開も速い点があるため、アドホッククエリの体験は良好です。データウェアハウスやデータレイク用途では、これが他システムに対する優位性につながる場合があります。
追加の機能やデータ型における類似点・相違点については後述します。
リアルタイム分析 #
ベンチマークの結果から、ClickHouseは以下の観点でリアルタイム分析アプリケーションにおいてSnowflakeを上回っています。
- クエリレイテンシ: Snowflakeのクエリは、テーブルにクラスタリングを適用して最適化してもなお高めのレイテンシが生じます。テーブルをSnowflake側でクラスタリングキーに含め、ClickHouse側でPRIMARY KEYに含めた列でフィルタをかけた場合でも、Snowflakeでは同等のパフォーマンスを達成するのにClickHouseの2倍以上の計算リソースが必要でした。Snowflakeの永続的なクエリキャッシュは一部のレイテンシ問題を緩和しますが、フィルタ条件が多様化すると効果が薄れます。また、キャッシュはデータが変更されると無効化されるため、新しいデータが取り込まれるようなユースケースではキャッシュの恩恵を受けにくい可能性があります。今回のベンチマークではそのケースを想定していませんが、実際の運用ではもっと新しいデータが継続的に追加されるでしょう。
ClickHouseのクエリキャッシュはノード固有であり、トランザクションレベルの一貫性を保証しませんが、リアルタイム分析には向いている設計です。ユーザーはクエリごとにクエリキャッシュの使用を制御でき、サイズやクエリのキャッシュ対象となる実行回数・時間などの制限も設定できます。 - コスト削減: Snowflakeではクエリが一定時間走らないとウェアハウスが自動で休止し、課金がストップする仕組みがあります。ただし、このアイドルチェックは60秒までしか下げられません。そして、クエリが届くと数秒以内にウェアハウスが再開します。リソースを使った分だけ課金されるので、アドホッククエリ主体のワークロードにはメリットがあります。
しかし、多くのリアルタイム分析ワークロードでは継続的なデータ取り込みと頻繁なクエリ実行が必要となり、アイドルになるタイミングがほぼありません(例: 外部に公開されているダッシュボードなど)。結果としてウェアハウスは常にアクティブになり、Snowflakeのアイドル停止機能によるコストメリットが活かせません。一方、ClickHouse Cloudは1秒あたりのコスト単価がSnowflakeより低いため、常時稼働が求められるリアルタイム分析ワークロードでは最終的な料金が大幅に下がります。 - 機能に関する予測可能な価格設定: マテリアライズドビューやクラスタリング(ClickHouseのORDER BYに相当)などは、リアルタイム分析で高いパフォーマンスを得るうえで不可欠な機能です。Snowflakeではこれらの機能が追加課金や高い料金プランを必要とし、さらにバックグラウンドでどれだけ処理が走るかは予測しづらいです。一方、ClickHouse Cloudではこれらの機能を使っても基本コストに追加料金はかかりません(挿入時のCPU・メモリ使用量が増える程度)。私たちのベンチマークでは、これらの違いやクエリの高速化、圧縮率の高さが合わさって、トータルコストをSnowflakeより大きく下げられることが分かりました。
さらにClickHouseには、リアルタイム分析機能を幅広くサポートする次のような特長があるという声もユーザーから寄せられています。
- アグリゲートコンビネータや配列関数などの特殊な分析関数が豊富で、複雑なクエリも短い構文で書け、パフォーマンスや可読性を向上できる
- Snowflakeほど厳しくないエイリアス制約など、分析向けに設計されたクエリ構文
- ENUMや精密指定可能な数値型など、より豊富なデータ型サポート。特にSnowflakeでは数値の精度指定があってもディスク消費には影響せず、ClickHouseでは型を厳密にすることで非圧縮時メモリを削減できる
- ファイルやデータ形式の幅広いサポート(Snowflakeの制限された形式よりも多い)により、分析データのインポート・エクスポートが簡単
- S3やMySQL、PostgreSQL、MongoDB、Delta Lakeなど、さまざまなデータレイクやデータストアに対してアドホックでフェデレーテッドクエリを実行可能
- 列ごとにカスタムスキーマやコーデックを指定することで高い圧縮率を実現可能。ベンチマークでもこの機能を活用して圧縮率を高めました
- セカンダリインデックスとプロジェクション機能をサポート。セカンダリインデックスにはインバーテッドインデックスも含まれ、テキスト検索にも対応。プロジェクションはクエリごとに最適化を行うための仕組みです。プロジェクションはSnowflakeのマテリアライズドビューと似ていますが、制限が少なく、すべてのアグリゲート関数をサポートしています。プロジェクション自体でコストが増加することはなく(Snowflakeでは機能使用によって1.5倍課金される場合がある)、ストレージ使用量増加分のみが影響します。ベンチマーク分析でこれらの機能が有効であることを示します。
- マテリアライズドビューもサポート。Snowflakeのマテリアライズドビュー(ClickHouseのプロジェクションに近い)とは異なり、ClickHouseのマテリアライズドビューはデータの挿入時にのみトリガーが実行されます。
- 結果は別のテーブルに格納可能で、もとのデータを保持する必要はありません。要約したデータだけでいいなら、ストレージ削減と高いパフォーマンスを両立できます。
- JOINやWHEREフィルタをサポートし、またマテリアライズドビューをチェーンさせることもできます。
クラスタリング vs ORDER BY #
ClickHouseもSnowflakeもカラム指向データベースです。行指向に比べてCPUキャッシュやSIMD命令を効率的に活用でき、特定のカラムをソートしておくと圧縮率が上がります。どちらも最適な読み取りパフォーマンスにはソートやインデックスが重要で、実装の違いはあるものの、概念としては類似しています。
ClickHouseでは、スパースインデックスとソートされたデータを中心とした構造を採用しています。テーブル作成時にORDER BYでカラムのタプルを指定し、ディスク上のソート順を決定します。一般的には頻繁に使われるクエリのフィルタ列を、カーディナリティが低い順に並べるとよいとされています。また、ORDER BYを省略するとデフォルトでPRIMARY KEYが使われますが、PRIMARY KEYとORDER BYを両方指定することも可能です(PRIMARY KEYはORDER BYの先頭と一致している必要があります)。スパースインデックスはディスク上がソートされていることを前提として動くため、効率的にデータをスキップできます。
Snowflakeはマイクロパーティションと呼ばれる独自構造を使いつつ、クラスタリングという機能で似たコンセプトを提供しています。クラスタリングキーに指定されたカラムをもとにマイクロパーティションが割り振られ、同じ値を持つデータが近接配置されるようになります。これはClickHouseのORDER BYと同様、ディスク上のデータが並ぶ順序を制御し、クエリや圧縮において同様の利点を得ることができます。
ただし、実装上はいくつかの違いがあります。
- ClickHouseは、データ挿入時に
ORDER BYに従って自動的にソートとインデックス構築を行います。これによる追加コストはほぼなく、高速に更新が必要なテーブルでも適切に最適化されます。 - Snowflakeはバックグラウンドでの自動クラスタリングによってデータを再配置し、クレジットが消費されます。これにかかる料金を事前に予測するのは難しく、多数の行があるテーブルでこそ威力を発揮する一方で頻繁に更新されるテーブルには推奨していないです。カラムのカーディナリティによってコストが大きく左右され、Snowflakeでは
to_dateなどの式を使ってカーディナリティを下げることを推奨しています。さらに、クラスタリングによる恩恵が得られるまでには時間がかかり、すぐに最適化されるわけではありません。 - Snowflakeはマイクロパーティション方式なので、高コストではあるものの再クラスタリングが可能です。一方ClickHouseでは、テーブルを完全に再書き込みしなければ再ソートできません。
両システムとも、分析処理では一般的にGROUP BYやソート、フィルタリングで特定のカラムをよく使用するため、こうしたソート/クラスタリングの設定は重要になります。クラスタリング/ORDER BYに指定するカラムはできるだけ多くのクエリで恩恵を受けられるよう選択し、カラムの並び順にも気を配る必要があります。
カラム選択の推奨事項は両システムでほぼ共通しています。
- 選択的なフィルタで頻繁に使うカラムを採用する。
GROUP BYに使われるカラムもメモリ効率で役立つ - カーディナリティが十分に高いカラムを使う(コイントスのように50%の行しか絞れないものは避ける)
- 複数カラムが必要な場合は、カーディナリティが低いカラムから高いカラムの順に並べる。特にClickHouseではこの点が非常に重要ですが、Snowflakeも考え方は同じと思われます。
注: 上記の推奨事項は似ていますが、Snowflakeは高カーディナリティカラムをクラスタリングキーに指定するのを推奨していません。これはClickHouseには当てはまりません。タイムスタンプなどカーディナリティが高い列はClickHouseでもORDER BYの候補になります。
このガイドラインを踏まえた上で、私たちのベンチマークを行いました。
データ移行 #
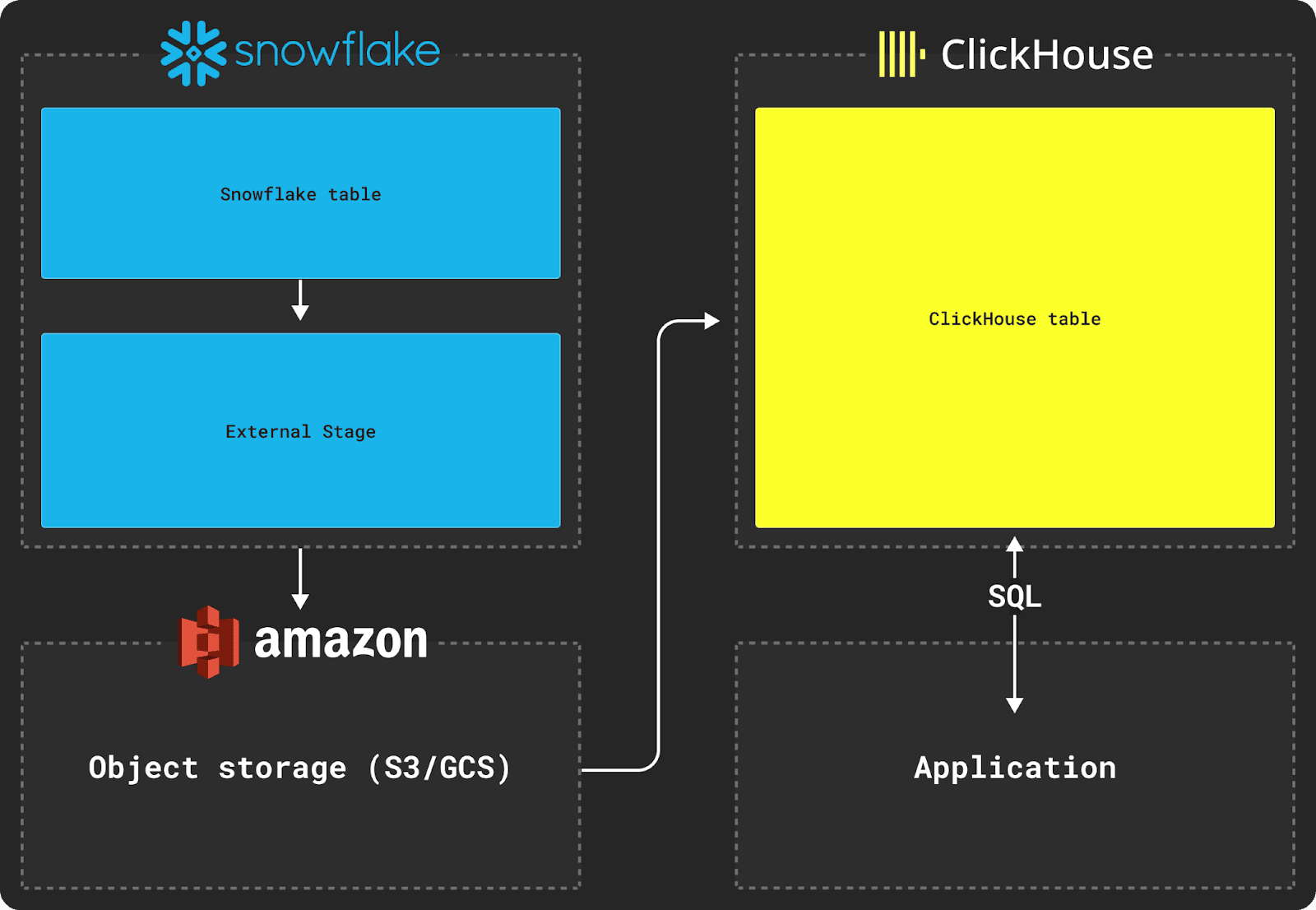
SnowflakeからClickHouseにデータを移行する場合、S3などのオブジェクトストアを中継ストレージとして利用することができます。SnowflakeとClickHouseのCOPY INTOやINSERT INTO SELECTコマンドを組み合わせ、次のような流れで転送します。
Snowflakeからのアンロード #
Snowflakeからのエクスポートには、図のようにExternal Stageを使います。これはClickHouseのS3テーブルエンジンと似ており、外部にホストされたファイルのまとまりをSQLで参照できるようにします。
SnowflakeとClickHouse間のデータ移行には、型情報を維持し、圧縮効率も良く、ネスト構造を扱えるParquet形式を推奨します。JSONのndjson形式を使う方法もありますが、こちらは可読性を除けばデータ量が増加する傾向があります。
以下の例では65億行のPyPiデータセットをエクスポートしています。このスキーマとデータセットは、publicなBigQueryテーブルから取得したもので、こちらのとおりPiPなどのツールを使ったPythonパッケージのダウンロード履歴を記録しています。詳細はベンチマーク記事で紹介していますが、550億行以上の大きなデータセットであり、リアルタイム分析における一般的なデータ構造に近いものとして選びました。
下記の例では、SnowflakeでParquetの名前付きファイル形式を作成し、次にエクスポート先のS3を表すExternal Stageを宣言してから、COPY INTOコマンドでエクスポートします。このステージはS3バケットへの抽象化レイヤーで、権限付与も行いやすくなります。
SnowflakeではS3への書き込み権限を付与する方法が複数あります。サンプルを簡単にするため今回はキーとシークレットを直接使っていますが、本番環境ではSnowflake Storage Integrationを使うことを推奨します。
CREATE FILE FORMAT my_parquet_format TYPE = parquet;
CREATE OR REPLACE STAGE my_ext_unload_stage
URL='s3://datasets-documentation/pypi/sample/'
CREDENTIALS=(AWS_KEY_ID='<key>' AWS_SECRET_KEY='<secret>')
FILE_FORMAT = my_parquet_format;
-- 全ファイルに「pypi」プレフィックスを適用し、最大ファイルサイズを150MBに指定
COPY INTO @my_ext_unload_stage/pypi from pypi max_file_size=157286400 header=true;
Snowflake側のスキーマは以下です。
CREATE TABLE PYPI (
timestamp TIMESTAMP,
country_code varchar,
url varchar,
project varchar,
file OBJECT,
installer OBJECT,
python varchar,
implementation OBJECT,
distro VARIANT,
system OBJECT,
cpu varchar,
openssl_version varchar,
setuptools_version varchar,
rustc_version varchar,
tls_protocol varchar,
tls_cipher varchar
) DATA_RETENTION_TIME_IN_DAYS = 0;
Parquetにエクスポートするとサイズは約5.5TiB、1ファイル150MB上限で分割されます。AWS us-east-1にある2X-LARGEサイズのウェアハウスで処理時間は30分程度です。header=trueを指定しているのはカラム名を出力するためです。VARIANTやOBJECTカラムはデフォルトでJSON文字列として出力されるので、ClickHouseにインサートする際にキャストが必要になります。
ClickHouseへのインポート #
一度オブジェクトストアに書き出してしまえば、ClickHouseのs3テーブル関数などを使ってテーブルへ取り込めます。以下の例のように実行します。
以下のようなターゲットスキーマを想定します。
CREATE TABLE default.pypi
(
`timestamp` DateTime64(6),
`date` Date MATERIALIZED timestamp,
`country_code` LowCardinality(String),
`url` String,
`project` String,
`file` Tuple(filename String, project String, version String, type Enum8('bdist_wheel' = 0, 'sdist' = 1, 'bdist_egg' = 2, 'bdist_wininst' = 3, 'bdist_dumb' = 4, 'bdist_msi' = 5, 'bdist_rpm' = 6, 'bdist_dmg' = 7)),
`installer` Tuple(name LowCardinality(String), version LowCardinality(String)),
`python` LowCardinality(String),
`implementation` Tuple(name LowCardinality(String), version LowCardinality(String)),
`distro` Tuple(name LowCardinality(String), version LowCardinality(String), id LowCardinality(String), libc Tuple(lib Enum8('' = 0, 'glibc' = 1, 'libc' = 2), version LowCardinality(String))),
`system` Tuple(name LowCardinality(String), release String),
`cpu` LowCardinality(String),
`openssl_version` LowCardinality(String),
`setuptools_version` LowCardinality(String),
`rustc_version` LowCardinality(String),
`tls_protocol` Enum8('TLSv1.2' = 0, 'TLSv1.3' = 1),
`tls_cipher` Enum8('ECDHE-RSA-AES128-GCM-SHA256' = 0, 'ECDHE-RSA-CHACHA20-POLY1305' = 1, 'ECDHE-RSA-AES128-SHA256' = 2, 'TLS_AES_256_GCM_SHA384' = 3, 'AES128-GCM-SHA256' = 4, 'TLS_AES_128_GCM_SHA256' = 5, 'ECDHE-RSA-AES256-GCM-SHA384' = 6, 'AES128-SHA' = 7, 'ECDHE-RSA-AES128-SHA' = 8)
)
ENGINE = MergeTree
ORDER BY (date, timestamp)
Snowflake側でOBJECTやVARIANTだった構造化データはJSON文字列として出力されるため、JSONExtract関数を使ってインサート時にタプルへ変換します。
INSERT INTO pypi
SELECT
TIMESTAMP,
COUNTRY_CODE,
URL,
PROJECT,
JSONExtract(ifNull(FILE, '{}'), 'Tuple(filename String, project String, version String, type Enum8(\'bdist_wheel\' = 0, \'sdist\' = 1, \'bdist_egg\' = 2, \'bdist_wininst\' = 3, \'bdist_dumb\' = 4, \'bdist_msi\' = 5, \'bdist_rpm\' = 6, \'bdist_dmg\' = 7))') AS file,
JSONExtract(ifNull(INSTALLER, '{}'), 'Tuple(name LowCardinality(String), version LowCardinality(String))') AS installer,
PYTHON,
JSONExtract(ifNull(IMPLEMENTATION, '{}'), 'Tuple(name LowCardinality(String), version LowCardinality(String))') AS implementation,
JSONExtract(ifNull(DISTRO, '{}'), 'Tuple(name LowCardinality(String), version LowCardinality(String), id LowCardinality(String), libc Tuple(lib Enum8(\'\' = 0, \'glibc\' = 1, \'libc\' = 2), version LowCardinality(String)))') AS distro,
JSONExtract(ifNull(SYSTEM, '{}'), 'Tuple(name LowCardinality(String), release String)') AS system,
CPU,
OPENSSL_VERSION,
SETUPTOOLS_VERSION,
RUSTC_VERSION,
TLS_PROTOCOL,
TLS_CIPHER
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/pypi/2023/pypi*.parquet')
SETTINGS input_format_null_as_default = 1, input_format_parquet_case_insensitive_column_matching = 1
ここでは、input_format_null_as_default=1とinput_format_parquet_case_insensitive_column_matching=1を有効にし、null値をデフォルトに変換し、列名の大小文字を区別しないようにしています。
AzureやGoogle Cloudを使う場合も同様に処理できます。ClickHouseにはそれぞれの専用テーブル関数などが用意されています。
結論 #
本記事では、リアルタイム分析をユースケースとした場合にSnowflakeとClickHouseがどのように比較されるかを、両システムの類似点や相違点とともに見てきました。リアルタイム分析で有用なClickHouseの機能を挙げ、Snowflakeからワークロードを移行する際の考慮点も解説しました。次の記事では、サンプルのリアルタイム分析アプリケーションを構築し、圧縮や挿入パフォーマンスの違い、代表的なクエリのベンチマークを行います。その結果をコスト分析とともに紹介し、ClickHouse Cloud導入時のコスト削減可能性を示します。
付録 #
SnowflakeからClickHouseへリアルタイム分析ワークロードを移行する際に知っておくべき主要な概念を、以下にまとめます。データ型の違いやクラスタリングとORDER BYの相違を補足的に解説します。
データ型 #
数値型 #
SnowflakeとClickHouseを比較すると、SnowflakeよりClickHouseのほうが数値型の精度指定が細かいことに気づくでしょう。Snowflakeは数値型にNumberを使っており、精度(桁数)とスケール(小数点以下の桁数)を指定します(最大38桁)。整数はNumberの精度とスケールを0にしたものと同じです。Snowflakeではマイクロパーティションレベルで最小限のバイトで格納するため、ユーザーが指定する精度やスケールは実際のディスク使用量に大きく影響しません。圧縮で相殺される部分もあります。一方、Float64型を使用すると、精度を一部失う代わりにさらに広い範囲の値を扱えます。
ClickHouseは、符号付き・符号なしの複数のビット幅を持つ整数型と浮動小数点型を提供し、明示的に精度を指定してメモリ消費を抑えることができます。Decimal型はSnowflakeのNumberと同等ですが、最大76桁までサポートするためSnowflakeの倍の精度があります。浮動小数点はFloat32とFloat64の2種類があり、精度が必要ない場合はFloat32で圧縮とメモリを節約できます。
文字列 #
ClickHouseとSnowflakeでは文字列型の扱い方に違いがあります。SnowflakeのVARCHARはUTF-8でエンコードされたUnicode文字列を保持し、最大長を指定しても実際の使用バイト数だけが格納されます。その他のTEXTやNCharなどの型はVARCHARのエイリアスです。
ClickHouseは生バイト列として文字列を保持し、エンコーディングはユーザー側が管理します。クエリ時にエンコーディングを扱うための関数が用意されています(こちらの考え方も参照)。実装的には、ClickHouseのString型はSnowflakeのBinary型に近いと言えます。
また、照合順序(コレーション)はSnowflakeとClickHouseの双方がサポートしています。
セミ構造化 #
SnowflakeとClickHouseはどちらもセミ構造化データのために豊富な型サポートを提供しています。SnowflakeはVARIANTを中心にARRAYやOBJECTを定義し、ClickHouseはJSON型やTuple、Nested型で実現します。SnowflakeのARRAYやOBJECTもVARIANTの制約付きにすぎず、内部型を厳密に指定できないのが特徴です。
一方、ClickHouseはNamed TupleやNested型によって、階層化された構造を明示的に定義できます。サブカラムごとに型を厳密に指定し、そこに圧縮やコーデックを適用できます。Snowflakeでは内部まで型を細かく指定できないため、最適な圧縮を得るために構造をフラット化することを推奨しています。また、Snowflakeにはセミ構造化データにサイズ制限があります。
以下の表は、SnowflakeとClickHouseの型対応をまとめたものです。
| Snowflake | ClickHouse | 備考 |
|---|---|---|
| NUMBER | Decimal | ClickHouseではSnowflakeの倍となる76桁までの精度とスケールをサポート |
| FLOAT, FLOAT4, FLOAT8 | Float32, Float64 | Snowflakeでは浮動小数点は常に64ビット |
| VARCHAR | String | |
| BINARY | String | |
| BOOLEAN | Bool | |
| DATE | Date, Date32 | SnowflakeのDATEはClickHouseのDateより広い範囲をカバー。ClickHouseのDateは2バイトでコンパクト |
| TIME(N) | 直接の対応はないが、DateTimeやDateTime64(N)で表現可能 | DateTime64は同様に小数点以下の精度を扱える |
| TIMESTAMP - TIMESTAMP_LTZ, TIMESTAMP_NTZ, TIMESTAMP_TZ | DateTime と DateTime64 | DateTimeおよびDateTime64では列ごとにTZパラメータを設定可能。設定がない場合はサーバーのタイムゾーンが使われる。クライアント側で--use_client_time_zoneを使うこともできる |
| VARIANT | JSON, Tuple, Nested | ClickHouseのJSON型はまだ実験的機能。挿入時に型を推論する。Tuple, Nested, Arrayを使って明示的に型を定義する方法もある |
| OBJECT | Tuple, Map, JSON | OBJECTとMapはどちらもキーがStringの構造。Snowflakeでは値もVARIANTで、キーごとに型が異なる可能性がある。ClickHouseでは値の型を厳密にする必要があるため、混在型を扱うにはJSON型やTupleで明示的に定義する |
| ARRAY | Array, Nested | SnowflakeのARRAYはVARIANTのサブタイプ。一方ClickHouseのArrayは要素が強く型付けされる |
| GEOGRAPHY | Point, Ring, Polygon, MultiPolygon | Snowflakeは座標系(WGS 84)を固定的に適用。ClickHouseはクエリ時に指定する |
| GEOMETRY | Point, Ring, Polygon, MultiPolygon |
このほかClickHouseには以下のような型もあります。
- ipv4とipv6などのIP専用型(Snowflakeより効率的に格納できる場合がある)
- FixedString - ハッシュなど固定長のバイト列を扱うのに便利
- LowCardinality - どんな型でも辞書エンコードをかけられる。カーディナリティが10万未満のときに有効
- Enum - 小さな整数値で名前付き定数を格納できる
- UUID - UUIDを効率的に格納
- ベクトルは
Array(Float32)などで表現可能で、距離関数にも対応
さらに、ClickHouseではアグリゲート関数の中間状態を格納できるというユニークな機能があります。これは実装依存の形式ですが、マテリアライズドビューなどと組み合わせることで、挿入時の集計結果の状態を保持し、後からマージ関数を適用して素早く集計結果を取得できます(詳しくはこちら)。
お問い合わせいただければ、ClickHouse Cloudを用いたリアルタイム分析の詳細をご案内します。あるいはこちらからClickHouse Cloudを始めると、300ドル分のクレジットが付与されます。



