- Netflixは毎日5ペタバイト、毎秒1,060万イベントのログをClickHouseで処理
- 最適化①(取り込み): 生成型レキサーによるフィンガープリンティングで8〜10倍高速化(216μs → 23μs)
- 最適化②(シリアライゼーション): ネイティブプロトコル+LZ4圧縮でCPU・メモリ効率を大幅改善
- 最適化③(クエリ): タグマップを31シャードに分割し、クエリ時間を3秒 → 700ms以下に短縮
- ログは生成から20秒以内に検索可能、エンジニアがリアルタイムでデバッグできる環境を実現
まとめ
「Netflixでは、すべてをスケールが牽引しています」とエンジニアのDaniel Muino氏は語ります。これは冗談ではありません。
Netflixの最大の名前空間において、ロギングシステムは毎日5ペタバイトという驚異的なデータを取り込んでいます。平均で毎秒1,060万イベントを処理し、ピーク時には1,250万に達します(「何かおかしなことが起こっていない限りはですが――その場合はさらに高くなることもあります」とDaniel氏は言います)。各イベントの平均サイズは約5 KBです。Netflixに40,000以上存在する各マイクロサービスのニーズに応じて、ログは2週間から2年まで保持されます。
そしてシステムは圧倒的に書き込みが多いにもかかわらず、毎秒500〜1,000という見事なクエリ数を処理しています。これらのクエリは、エンジニアが問題をデバッグし、マイクロサービスを監視し、190カ国の3億人以上の加入者に向けてプラットフォームを稼働し続けるために使用しているものです。
このスケールが大半のロギングプラットフォームを圧倒するものであることは間違いありません。このようなインタラクティブ性を実現する――数秒で検索可能なログ、瞬時に感じられるクエリ――には、適切なデータベース(ClickHouse!)だけでなく、慎重に設計された一連の最適化が必要でした。
2025年7月にロスガトスで開催されたClickHouseミートアップで、Daniel氏は、Netflixのペタバイト規模のロギングを高速かつコスト効率の高いものにした3つのブレークスルーを含め、チームがどのようにそれを実現したかを共有してくれました。
Netflixのロギングアーキテクチャの内側 #
Netflixのロギング構成は「かなりシンプルで、特に変わったところはありません」とDaniel氏は言います。「ただ、それを機能させるためには、多くの選択をしなければなりませんでした。」
ログは数千のマイクロサービスから軽量なサイドカーを通じて流れ、イベントを取り込みクラスターに転送します。短いバッファを経た後、データはAmazon S3に書き込まれ、Amazon Kinesisにメッセージが配置されて下流処理がトリガーされます。そこから中央のハブアプリケーションがデータを消費し、別々の名前空間にルーティングして、適切なストレージ階層に書き込みます。
ClickHouseはシステムの中心にホット階層として位置しています。速度が重要となる最近のログを保存し、高速なクエリとインタラクティブなデバッグを実現します。「ClickHouseのおかげで、このデータを非常に新鮮な状態で提供できます」とDaniel氏は言います。「途中で行うすべてのバッファリングは、私たちにあまり影響を与えません。」
履歴データについては、Netflixは Apache Iceberg を使用しており、より大きな時間スケールでコスト効率の高い長期保存とクエリ機能を提供します。両方の階層の上には、クエリAPIがどの名前空間を検索するかを自動的に決定するため、エンジニアは内部で何が起きているかを意識することなく、統合されたビューを得られます。
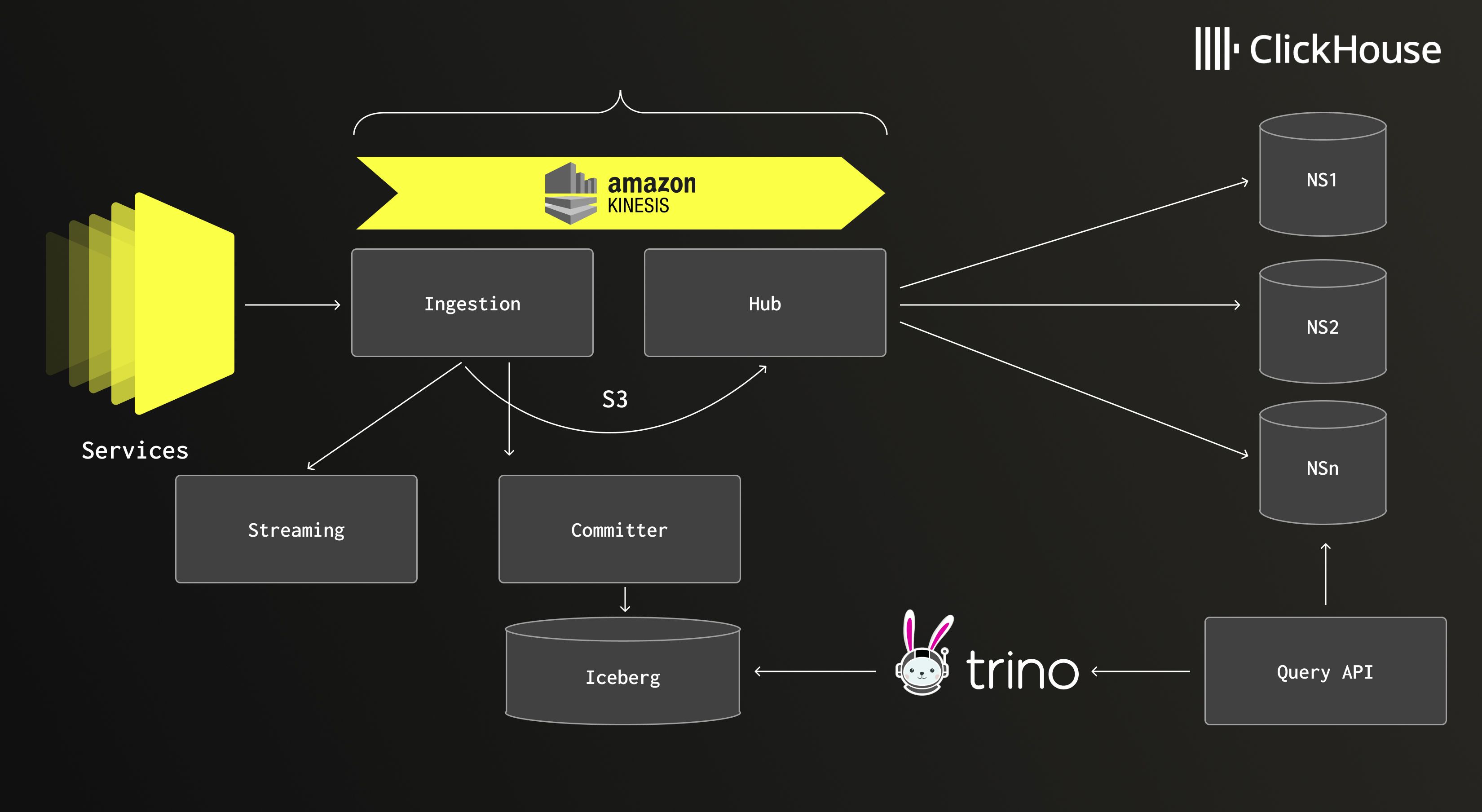
Netflixのロギングアーキテクチャ。ホットデータ用のClickHouseと長期保存用のIcebergを組み合わせている。
その結果、システムはほぼ瞬時に動作するように感じられます。ログは通常、生成から20秒以内に検索可能となり、Netflixの5分のSLAをはるかに上回ります。場合によっては、エンジニアは2秒のレイテンシでライブログをストリーミングすることもできます。イベントをクリックして開いたり、JSONペイロードを展開したり、フィンガープリントハッシュで数百万のメッセージをグループ化したり、周辺のログをドリルダウンしたり――これらすべてをクエリの完了を待つことなく行えます。
しかしDaniel氏が説明するように、このレベルのインタラクティブ性は一夜にして実現したわけではありません。取り込み、シリアライゼーション、クエリの3つの大きな最適化が、システムを今日の姿へと変えたのです。
最適化 #1: 取り込み - フィンガープリンティング #
ログを有用にするためには、Netflixはまず類似メッセージをグループ化する必要があります。フィンガープリンティングと呼ばれるこのプロセスは、エンジニアがほぼ同一の何百万ものエントリーを1つのパターンに集約することで、ノイズを切り抜けるのを助けます。これがなければ、Netflixの規模でログを検索することは、控えめに言っても圧倒的なものになるでしょう。
初期段階では、チームはログメッセージをグループに分類するために機械学習モデルを試しました。理論的には機能しましたが、実際にはリソースを使いすぎました。「非常に高価で、非常に遅く、製品全体が機能しなくなりました」とDaniel氏は振り返ります。
次にチームは正規表現に移り、ログテキスト内のパターンをマッチングし、値を汎用トークンに置き換えました。これは助けになりましたが、正規表現では毎秒1,000万イベントには追いつけませんでした。「生のテキストからエンティティを認識することは、コンパイラが長らく行ってきたことです」とDaniel氏は説明します。「基本的には同じ問題に同じ解決策があります――レキサーが必要なのです。」
そこでチームは、JFlex(最適化されたトークナイザーを生成するJavaツール)を使用して、フィンガープリンティングを生成型レキサーとして再構築しました。実行時に複雑な正規表現を評価する代わりに、新しいシステムはパターンを効率的なコードにコンパイルします。その成果は絶大で、スループットは8〜10倍に増加し、平均フィンガープリンティング時間は216マイクロ秒から23マイクロ秒に低下しました。99パーセンタイルでさえ、レイテンシは大幅に低くなりました。
「大きな勝利でした」とDaniel氏は語ります。「そして、基本的にはただ書き直しただけでした。」その書き直しはシステムの最大の取り込みボトルネックの1つを解消し、Netflixがスケーリングを続けるための余地を与えました。
最適化 #2: ハブ - シリアライゼーション #
ログがフィンガープリント化されると、それでも毎秒数百万のレートでClickHouseに書き込む必要があります。ここでNetflixは別のボトルネックに直面しました――シリアライゼーションです。
チームの最初の実装はJDBCバッチ挿入に依存していました。シンプルで馴染みやすかったものの、非効率でもありました。すべてのプリペアドステートメントが、クライアントにデータベースとスキーマやシリアライゼーションの詳細を交渉させ、スケールが悪いオーバーヘッドを追加していました。「もっと改善できると思いました」とDaniel氏は言います。
そこでチームは抽象化スタックの一段下に降り、ClickHouseの低レベルJavaクライアントが公開するRowBinaryフォーマットを使用しました。これは、データを列ごとに手動でシリアライズすることを意味しました――マップ長を書き込み、DateTime64をエポックからのナノ秒としてエンコードし、その他の癖を処理しました。これによって「大きなパフォーマンスの向上」が得られたとDaniel氏は言いますが、それでもまだ十分ではありませんでした。
「CPUとアロケーションのプロファイルを見たとき、本当に気になりました」と彼は言います。「なぜ私が望んでいる以上の作業をしているのか? なぜ私が望んでいる以上のメモリを使っているのか?」
ブレークスルーは、Daniel氏が入力フォーマットをベンチマークするClickHouseのブログ記事を読んだときに訪れました。ネイティブプロトコルは一貫してRowBinaryを上回るパフォーマンスを示しましたが、Javaクライアントはそれをサポートしていませんでした。サポートしていたのはGoクライアントだけでした。「だから私はGoクライアントをリバースエンジニアリングしました」とDaniel氏は言います。
Netflixは、ネイティブプロトコルを使用してLZ4で圧縮されたブロックを生成し、ClickHouseに直接送信する独自のエンコーダーを構築しました。その結果、CPU使用率の低下、メモリ効率の向上、そしてRowBinaryと同等(場合によってはそれ以上)のスループットが得られました。
「完璧ではありません。完成したばかりなので」とDaniel氏は言います。「でも、以前と同等のレベルに達していて、最適化の余地はまだまだあります。」
最適化 #3: クエリ - カスタムタグ #
取り込みとシリアライゼーションが主に書き込み中心の課題だったのに対し、3つ目のボトルネックは読み込み側にありました。Netflixのエンジニアはタグに大きく依存しています――各ログイベントに付加される動的なキーと値のペアで、マイクロサービス、リクエストID、その他のカスタム属性でフィルタリングできるようにするものです。便利である一方、タグはシステムの最大の頭痛の種の1つにもなりました。
「カスタムタグは私たちにとって大きな問題です」とDaniel氏は語ります。「ユーザーが一般的に使用する中で、最もコストの高いクエリです、ダントツで。」
当初、タグはシンプルなMap(String, String)として保存されていました。内部的には、ClickHouseはマップをキーと値の2つの並列配列として表現します。各ルックアップはそれらの配列を線形スキャンする必要がありました。1時間あたり最大25,000のユニークなタグキーと数千万のユニークな値があるNetflixのスケールでは、クエリのパフォーマンスは急速に低下しました。
Daniel氏はClickHouseの作成者Alexei Milovidov氏と話し合い、彼はLowCardinality型の使用を提案しました。それはキーには有効でしたが、値はあまりにも多すぎたため、問題の半分しか解決できませんでした。「LowCardinality値はオプションになりませんでした」とDaniel氏は指摘します。
解決策は驚くほどシンプルでした――マップをシャード化することです。タグキーを31個の小さなマップにハッシュ化することで、クエリはすべてのキーをスキャンする代わりに、適切なシャードに直接ジャンプできるようになりました。
違いは絶大でした。かつて3秒かかっていたフィルタリングクエリは1.3秒に低下しました。フィルター+プロジェクションのクエリは、ほぼ3秒から700ミリ秒未満に低下しました。どちらの場合も、スキャンされるデータ量は5倍から8倍小さくなりました。
「以前は多くの問題を引き起こしていたクエリが、今ではそこそこ大丈夫になりました」とDaniel氏は言います。そしてNetflixのスケールでは、と彼は付け加えます、「それは大きな、大きな勝利です。」
シンプルさの美しさ #
これら3つの最適化――フィンガープリンティングの再考、シリアライゼーションの書き直し、そしてクエリの再形成――を組み合わせることで、ボトルネックが解消され、NetflixのロギングシステムはどこにあるClickHouse展開の中でも最大かつ最速のものの1つとして確固たる地位を築きました。
エンジニアを遅らせるどころか、Netflixの超人的なスケールにおいてさえ、システムは軽量でインタラクティブに感じられるようになりました。そのような応答性は、障害対応に追われるか、世界中の何億人もの視聴者のためにサービスをスムーズに稼働し続けるかの違いを生み出すことができます。
最終的にDaniel氏は、チームの成功を巧妙なトリックよりも、規律ある エンジニアリングのおかげだと評価しています。「鍵は、最小限の作業で済むようにいかに物事をシンプルにするか、ということに尽きます」と彼は言います。
チームのデータオペレーションを変革しませんか? ClickHouse Cloudを30日間無料でお試しください。



