本日、実行可能 UDF が ClickHouse Cloud でパブリックベータとして利用可能になった ことを発表できることを嬉しく思います。Python で関数を書き、zip としてクラスタにアップロードすれば、組み込み関数と同じように SQL から呼び出せます。ClickHouse は長期間生存するサンドボックスプロセスのプールを管理し、クエリ速度で行データをそれらに流します。関数は SQL が使えるあらゆる場所で呼び出し可能です。アドホッククエリ、JOIN、さらには INSERT のたびに発火するマテリアライズドビューでも利用できます。
これはまったく新しいアイデアではありません。実行可能 UDF はセルフホスト版の ClickHouse では以前から提供してきました。2023 年の SQL から OpenAI を呼び出す記事 でも同じ仕組みを取り上げています。今回新しいのは、自前のサーバを動かさなくてもこれが使えるようになった点です。モデルコードはデータがある場所に置かれ、マネージドサンドボックス内で実行され、デプロイは Cloud コンソールの 1 つのアップロード画面だけで完結します。
これが何を可能にするかを示すために、デモを構築しました。小さな PyTorch オートエンコーダで約 60 億件の株式取引ティックをインジェスト時にインラインで異常度スコアリングし、Next.js のフロントエンドが埋め込みを消費します。ノートブック、UDF バンドル、SQL、Web アプリの完全なソースはこちらのリポジトリ にあります。
学習済みモデルがあり、ClickHouse にデータのストリームがあるとします。これまで両者を同じ場所で動かすには、おおむね次の 3 つの選択肢しかありませんでした。
別途スコアリングサービスを立ち上げる。 こうするとモデルサーバ、行データをそこにルーティングするインジェストパイプライン、スコアを ClickHouse に書き戻す仕組みを保守する必要があります。モデルはもはやデータの近くにあるとは言えません。
モデルを純粋な SQL に翻訳する。 一部のツリーベースモデルであれば可能です。埋め込みを含むモデルでは苦痛そのものです。再学習のたびに数千行の SQL を手で再生成することになります。
オフラインでバッチスコアリングし、後で結合する。 鮮度が失われます。今しがた発生した取引の「異常」は、今すぐ反応できてこそ意味があります。
実行可能 UDF はこれら 3 つを 1 つに集約します。推論コードを普通の Python ファイルとして書き、ClickHouse にそれを指し示し、SQL から呼び出します。関数は、必要なクエリと一緒にインラインで実行されます。マテリアライズドビューの中でも実行でき、本記事ではまさにそれをやっています。
昨年公開した「Building StockHouse」 では、ClickHouse が株式取引ティックの絶え間ない大量データをリアルタイムでどう処理するかを示しました。あの記事はインジェストとクエリレイヤで止まっていました。当然次に出てくる疑問は、「すべての取引が届いた瞬間に学習済みモデルを適用したくなったらどうするか?」です。
問題の形を分かりやすく示せるので、教師なしの異常検知セットアップを選びました。
小規模なオートエンコーダ(約 27 万パラメータ)を、5,000 万件の過去取引ティックで学習します。入力は、ハッシュ化したティッカー、7 つの数値特徴(価格、サイズ、取引所など)、6 つの周期エンコードされた時間特徴です。
各取引に対して、モデルは 32 次元の埋め込み と再構成誤差 を生成します。誤差が大きいということは、モデルがこのような取引パターンで学習されていないことを意味します。つまり、その銘柄の履歴における通常パターンと比較して形状的に異常 ということです。
このモデルをラップする UDF が embed_trade です。このシステム内で ML 固有のピースはこれだけです。あとはすべて普通の SQL です。スコアの集約、銘柄ごとのベースライン、ビュー、すべて SQL です。
データフローは次のとおりです。
┌───────────────────────────┐
│ default.trades │ ← upstream feed (e.g. Polygon)
└──────────────┬────────────┘
│ INSERT
▼
┌───────────────────────────┐
│ trades_embeddings_mv │ ← fires on every INSERT
│ (calls embed_trade UDF) │
└──────────────┬────────────┘
│
▼
┌───────────────────────────┐
│ default.trades_embeddings│ ← same trade + 32 - dim
│ │ embedding + recon_score
└──────────────┬────────────┘
▲ │
│ │ refresh hourly
│ ▼
│ ┌──────────────────────┐
│ │ trades_baselines │ ← per - symbol score
│ │ trades_dim_baselines │ distribution stats
│ └──────────────────────┘
│
└──── consumed by webapp queries
(anomalies are defined relative
to each symbol's own baselines)
INSERT INTO trades のすべてはマテリアライズドビューを経由し、スコアリングされ、trades_embeddings に格納されます。Web アプリはモデルを再実行することはありません。読み取るのは trades_embeddings と 2 つの軽量なベースラインテーブルだけです。高コストな推論は取引ごとにインジェストとインラインでちょうど 1 回だけ行われ、ダウンストリームのクエリはすべて通常の集約です。
モデル自体は ML 的には小さくて特に目新しくありませんが、UDF がランタイムにロードできるアーティファクトを生成しなければならないため、学習パイプラインには一見の価値があります。完全なウォークスルーは notebook/train_and_deploy_udf.ipynb
学習データを Parquet チャンクとしてストリーミング。 default.trades に対する SELECT で 14 個の入力特徴(価格、サイズ、取引所、コンディションコード数、ハッシュ化ティッカー、時刻と曜日の周期エンコード)をサーバ側で算出します。ノートブックは結果を query_arrow_stream 経由で取得し、500 万行ごとの Parquet チャンクをローカルディスクに書き出します。メモリ上には何も保持しません。
StandardScaler をインクリメンタルにフィット。partial_fit 経由の Welford アルゴリズムは、データセット全体での 1 回の scaler.fit() と同じ平均と分散を、限定的なメモリで得られます。フィットするのは 7 つの数値ベース特徴のみです。ハッシュ化ティッカーは整数キー、周期特徴はすでに妥当なスケールにあります。
オートエンコーダを学習。 TradeAutoencoderV2 は 4 層のエンコーダで 32 次元の潜在空間に圧縮し、対称なデコーダで数値特徴空間に戻します。シンボルの埋め込み参照は入力層で sym_idx = xxHash32(sym) % NUM_HASH_BUCKETS として行われます。損失は再構成された数値特徴の MSE です。学習は IterableDataset 経由で Parquet チャンクから行をストリーミングし、200 バッチの移動平均損失が 5 ウィンドウ連続で改善しなければ停止します。
アーティファクトを 2 つ保存。 scaler_params.pt は mean_ と scale_ を Float32 テンソルとして保持します。trade_autoencoder_v2.pt はモデルの state_dict とコンストラクタの kwargs を含む config dict を保持します。UDF の main.py は起動時にこれらを読み込み、モデルを再構築します。
バンドルをパッケージング。 ノートブックの最後のセルで main.py、requirements.txt、2 つの .pt ファイルを embed_trade.zip に圧縮し、アップロード可能な状態にします。
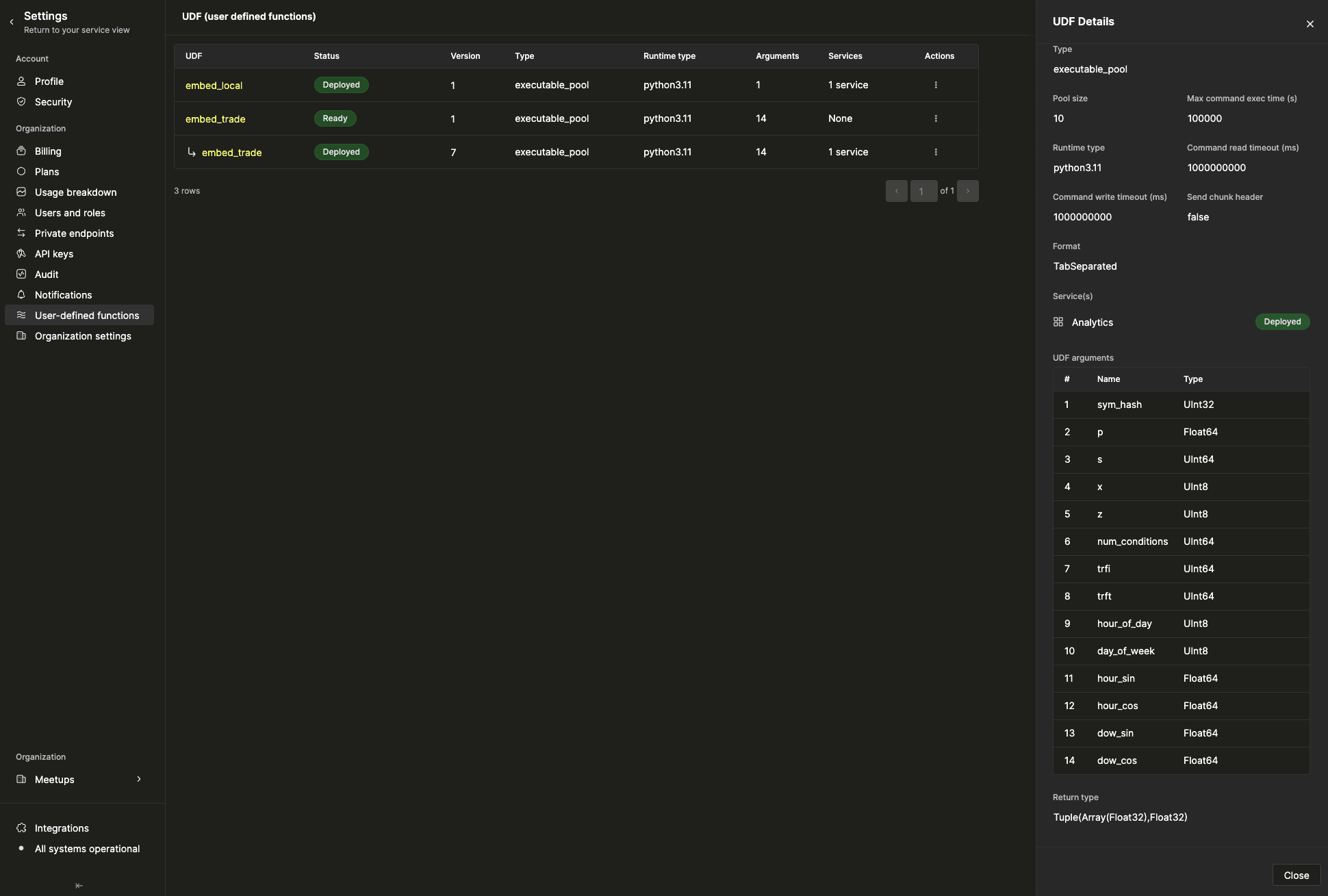
デプロイのインターフェースは Cloud コンソールにある単一のアップロード画面です。名前、コードとモデルファイルが入った zip、いくつかのランタイムパラメータを指定するだけです。
embed_trade では次のように設定します。
タイプ: executable_pool。長期間生存するプロセスで、モデルはメモリ上にホットな状態に保たれます。プールサイズ: レプリカあたり 10。各プロセスは起動時に 2MB のモデルをロードし(約 1.5 秒)、以降の呼び出しでそれを再利用します。ランタイム: python3.11。依存関係(torch==2.4.1、numpy==1.26.4)は zip 内の requirements.txt から取得されます。フォーマット: TabSeparated。UDF は入力 1 行ごとに stdin から 1 行の TSV を読み取り、(embedding, recon_score) を stdout に出力します。14 個の引数 。それぞれ明示的な ClickHouse 型を持ちます。シグネチャはオートエンコーダの学習スキーマと厳密に一致します。完全な対応表は udf/cloud-deployment.md
これにより、関数は組み込み関数と同じように SQL から呼び出せます。
WITH
fromUnixTimestamp64Milli(t, 'America/New_York' ) AS ts,
embed_trade(
xxHash32(sym), p, s, x, z, toUInt64(length(c)), trfi, trft,
toUInt8(toHour(ts)), toUInt8(toDayOfWeek(ts, 1 )),
sin ((toHour(ts) * 2 * pi()) / 24 ),
cos ((toHour(ts) * 2 * pi()) / 24 ),
sin ((toDayOfWeek(ts, 1 ) * 2 * pi()) / 7 ),
cos ((toDayOfWeek(ts, 1 ) * 2 * pi()) / 7 )
) AS result
SELECT
sym, i, x, p, s, c, t, q, z, trfi, trft, inserted_at,
result .2 AS recon_score,
result .1 AS embedding
FROM stockhouse.trades limit 10 ;
興味深いのは、これが「できる」ということではなく、その呼び出しを「どこに置けるか」という点です。
embed_trade をマテリアライズドビューに組み込みます。
CREATE MATERIALIZED VIEW trades_embeddings_mv
TO trades_embeddings
AS
WITH
fromUnixTimestamp64Milli(t, 'America/New_York' ) AS ts,
embed_trade(
xxHash32(sym), p, s, x, z, toUInt64(length(c)), trfi, trft,
toUInt8(toHour(ts)), toUInt8(toDayOfWeek(ts, 1 )),
sin ((toHour(ts) * 2 * pi()) / 24 ),
cos ((toHour(ts) * 2 * pi()) / 24 ),
sin ((toDayOfWeek(ts, 1 ) * 2 * pi()) / 7 ),
cos ((toDayOfWeek(ts, 1 ) * 2 * pi()) / 7 )
) AS result
SELECT
sym, i, x, p, s, c, t, q, z, trfi, trft, inserted_at,
result .2 AS recon_score,
result .1 AS embedding
FROM trades;
INSERT INTO trades のたびに、この MV が発火します。Python プールがそのバッチをスコアリングし、結果を trades_embeddings に書き込みます。他のムーバーも、他のサービスも、別途のスケジューラも存在しません。SQL だけです。
これは、Cloud で実行可能 UDF がサポートされる前には実現できなかった部分です。同等のサービスアーキテクチャを構築するなら、trades から読み出してバッチ化し、モデルサーバーに POST して結果を書き戻す Kafka コンシューマーが必要になります。最終状態は同じでも、動く部品はずっと増えます。ここでは DDL 一文で済むのです。
パフォーマンスの形は予想通りです。1 行あたりのコストはモデルのフォワードパス(ウォーム済みプールで数ミリ秒)に TSV シリアライゼーションを加えたものです。ClickHouse は行をチャンクにまとめて UDF へ渡します。プールは並列でいくつかの推論を同時実行します。3 レプリカのクラスター上で、手動スケーリングなしに ~35K rows/sec を数時間維持しながら、~6B 行の履歴データをバックフィルしました。同じ UDF、同じ MV、同じ SQL です。
オートエンコーダーは、各取引について生の recon_score を返します。これはデータセット全体でおおよそ 0.00002 から 1,000,000+ までの範囲の数値です。「0.062 を超える取引は異常」という単純なフィルター(モデルの学習分布から得たグローバルな 99 パーセンタイルを利用)は一見妥当に思えますが、実際にデータを見るとそうではありません。
BRK.A や LLY のような一部の銘柄は、株価が異常に高いため、すべての取引がこの閾値を超えてしまいます。これらの銘柄の分布全体が、グローバル分布の右側の裾に位置しているからです。そうした銘柄に対して「100% が異常」という統計は、技術的には正しくても実用上は無意味です。
そこで、「異常」を各銘柄自身の履歴に対して相対的に再定義します。銘柄ごとに、その生涯にわたる recon_score の p95 を維持しておきます。ある取引が その銘柄にとって 異常であるとは、その銘柄自身の p95 を超えていることを意味します。構成上、典型的なウィンドウでは約 5% の取引がこれに該当します。この割合が 5% を大きく上回ってスパイクしたとき、その銘柄は本当に異常なウィンドウに突入していると言えます。
銘柄ごとのベースラインは、別の ClickHouse テーブルに保持されます:
CREATE TABLE trades_baselines (
sym LowCardinality(String),
p50 Float32,
p95 Float32,
p99 Float32,
-- ...
computed_at DateTime
)
ENGINE = MergeTree
ORDER BY sym;
更新可能なマテリアライズドビュー は、1時間ごとにデータを再投入します:
CREATE MATERIALIZED VIEW trades_baselines_mv
REFRESH EVERY 1 HOUR
TO trades_baselines
AS
SELECT
sym,
quantiles( 0.5 , 0.95 , 0.99 )(recon_score) AS qs,
qs[ 1 ] AS p50, qs[ 2 ] AS p95, qs[ 3 ] AS p99,
-- ...
FROM trades_embeddings
WHERE NOT has(c, 15 ) AND NOT has(c, 12 ) -- exclude auction prints
GROUP BY sym;
Refreshable MV はリフレッシュのたびに、ターゲットテーブルをアトミックに truncate して置き換えます。プレーンな MergeTree が適切なエンジンです。FINAL も不要、重複排除ロジックも不要、読み取り時のオーバーヘッドもありません。
リーダーボードクエリでは、ライブトレードを baselines テーブルと JOIN し、シンボルごとに自身のベースラインに対する異常値の件数をカウントします:
SELECT
e.sym,
countIf(e.recon_score > b.p95) AS anomaly_count,
round(sumIf(e.s, e.recon_score > b.p95) * 100.0 / sum (e.s), 2 ) AS pct_of_volume
FROM stockhouse.trades_embeddings AS e
INNER JOIN stockhouse.trades_baselines AS b ON e.sym = b.sym
WHERE e.t >= now() - INTERVAL 1 HOUR
GROUP BY e.sym
ORDER BY pct_of_volume DESC
LIMIT 50 ;
このクエリは、~1.7秒(CTE としてインラインでベースラインを再計算する場合)から
~0.27秒(事前計算済みのテーブルと結合する場合)へと短縮されます。同じ結果で、おおよそ6倍
高速です。高コストな部分は、ページを読み込むたびではなく、1時間に1回だけマテリアライズされます。
Webアプリは Next.js + Click UI + Highcharts のデモです。trades_embeddings
とベースラインテーブルを利用します。
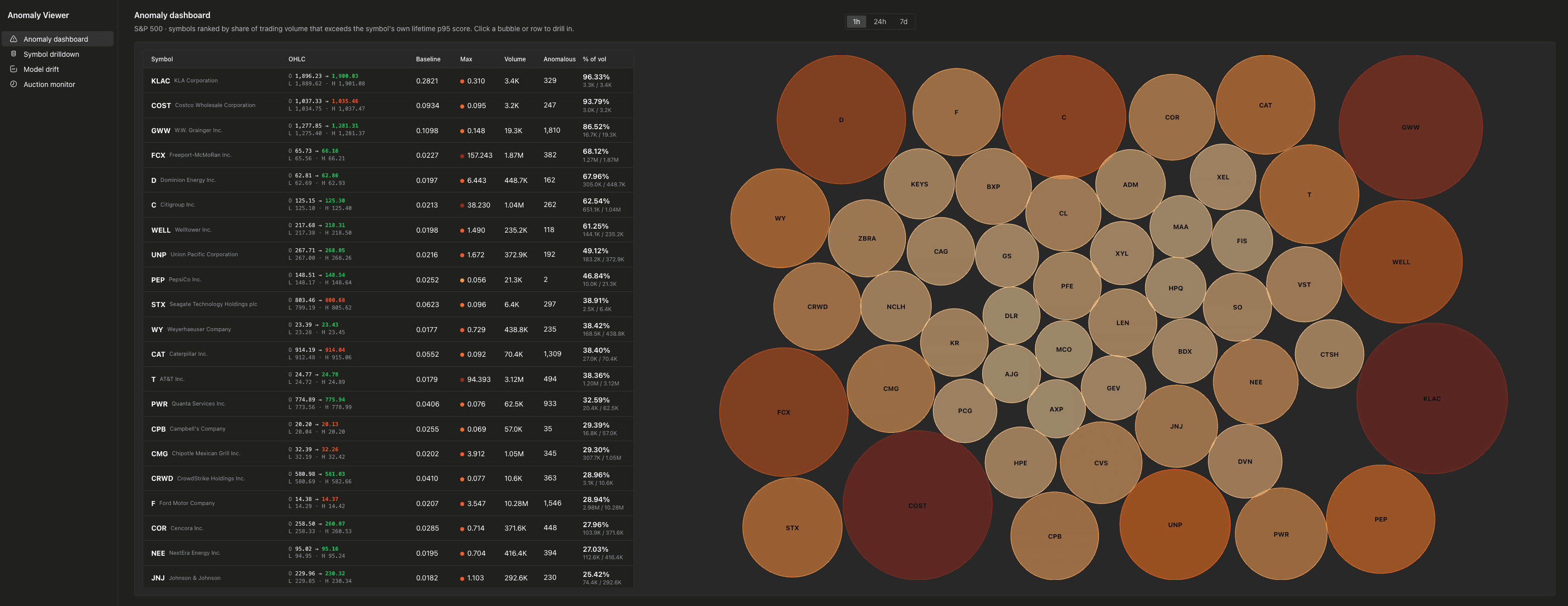
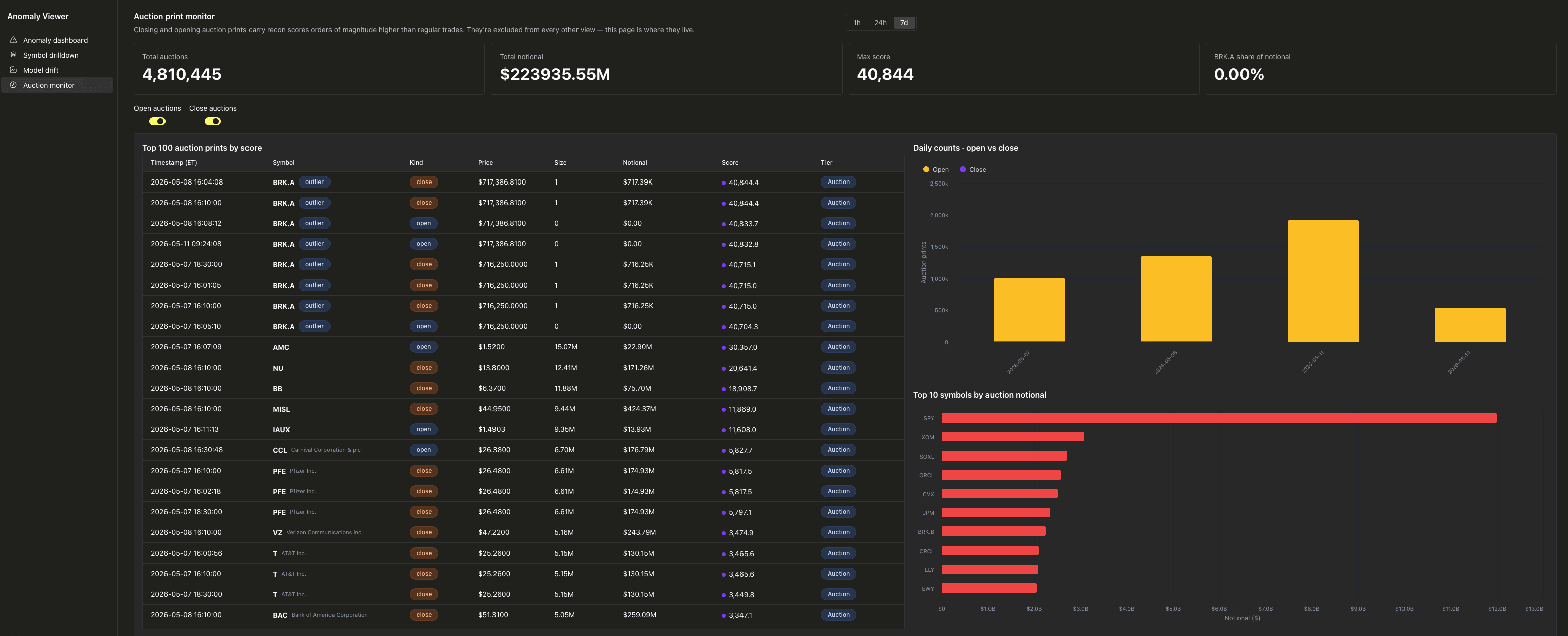
アノマリーダッシュボード は、自身のベースラインを超える取引量の割合で S&P 500 銘柄をランク付けします。
パックドバブルチャートは、各銘柄を pct_of_volume(その銘柄の生涯 p95 を上回る取引が、対象ウィンドウ内の全取引量に占める割合)に基づいてサイズと色で表現します。バブルが赤くて大きい銘柄ほど、その時間帯にアノマリーが集中していたことを意味します。左側のテーブルは同じ並び順で、OHLC、最大スコア、銘柄ごとのベースラインを並べて表示します。
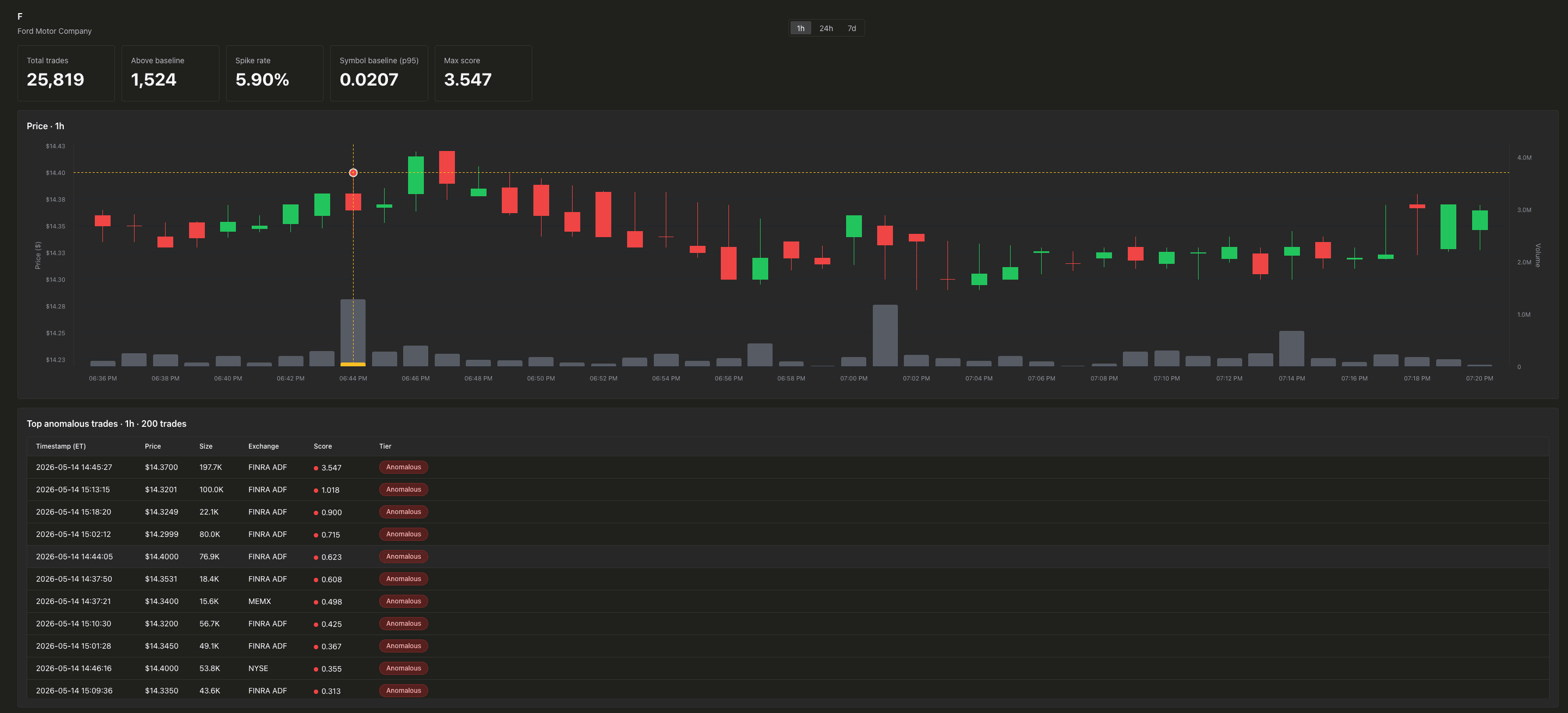
銘柄ドリルダウン は、特定のティッカーにズームインします。
上部にはローソク足と出来高ペインがあります。両方の軸は単一のプロットエリアで重なっており、価格軸は下方向に引き伸ばされ、ローソク足を上部65%に、出来高バーを下部30%に押し込んでいます。異常取引テーブルの任意の行にホバーすると、対応するローソク足の出来高バーが黄色く塗りつぶされ、その取引がバケットの総出来高に占める割合に応じたサイズになります。クロスヘアはローソク足の中央にスナップします。
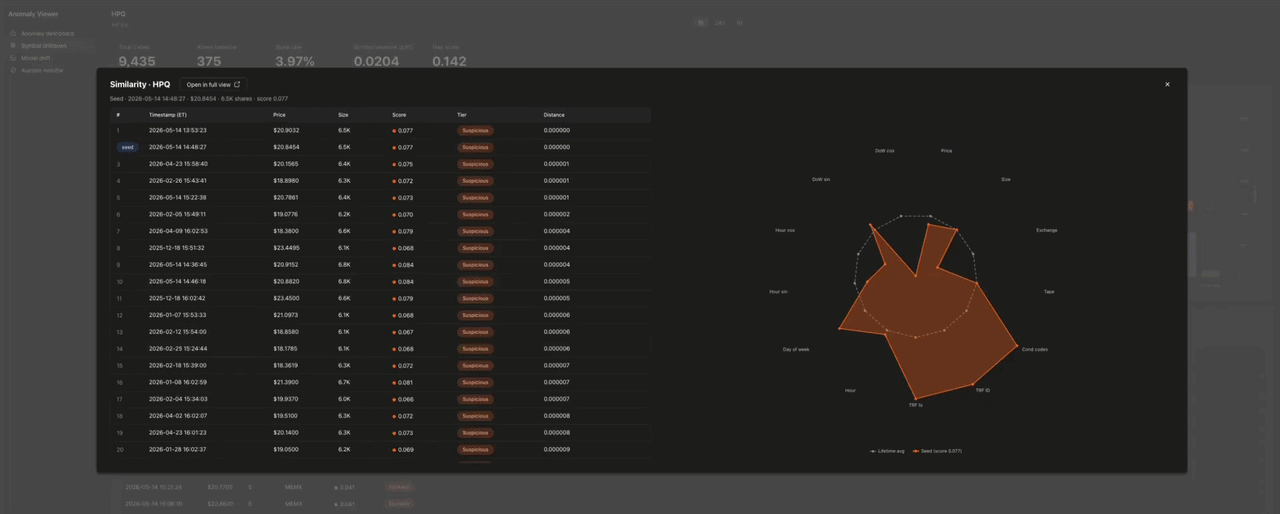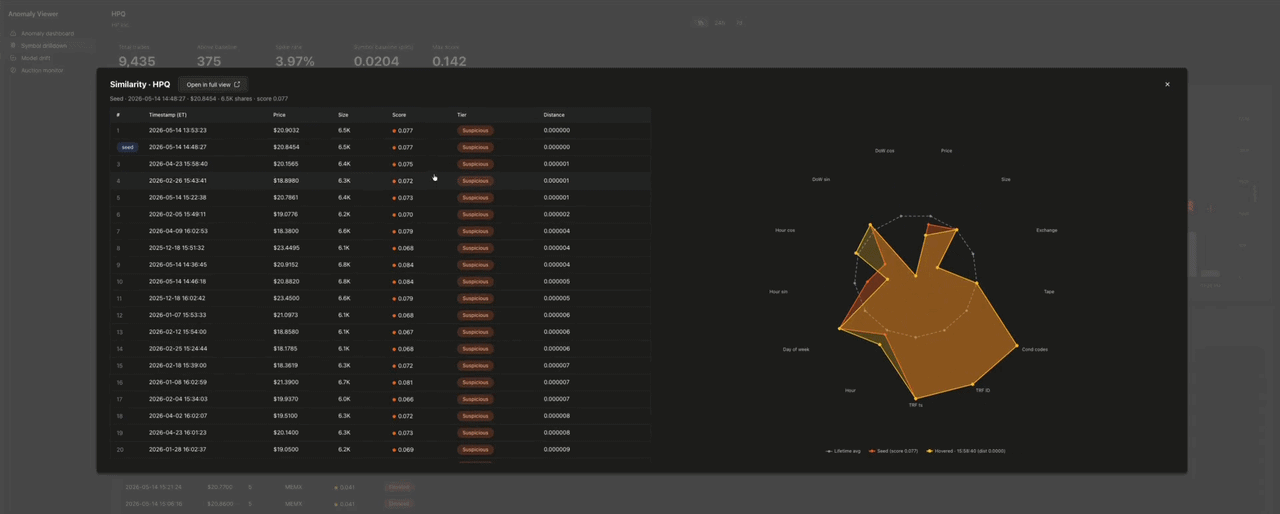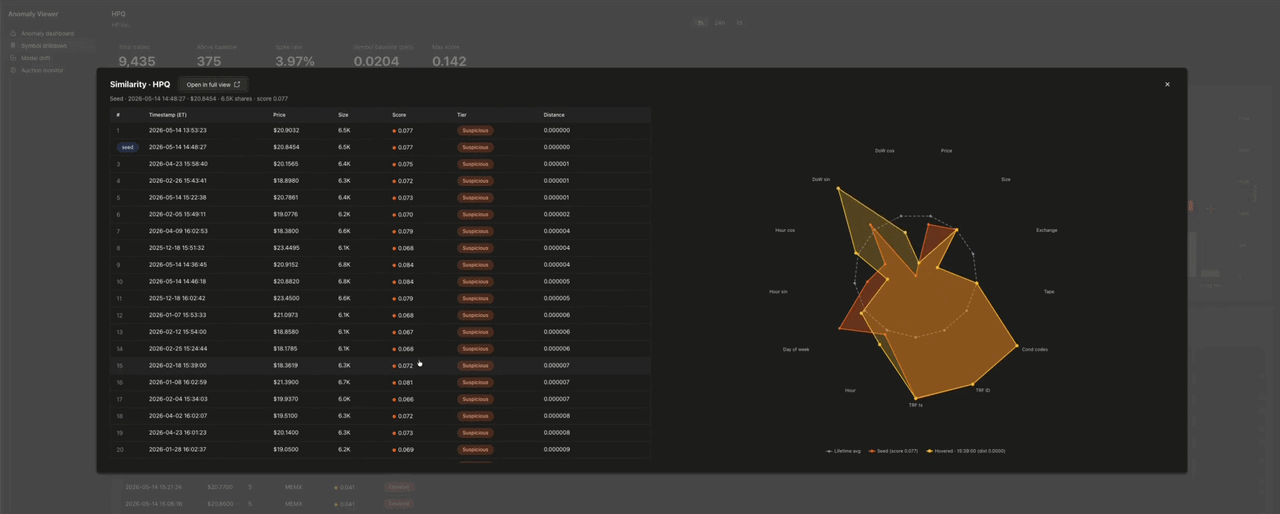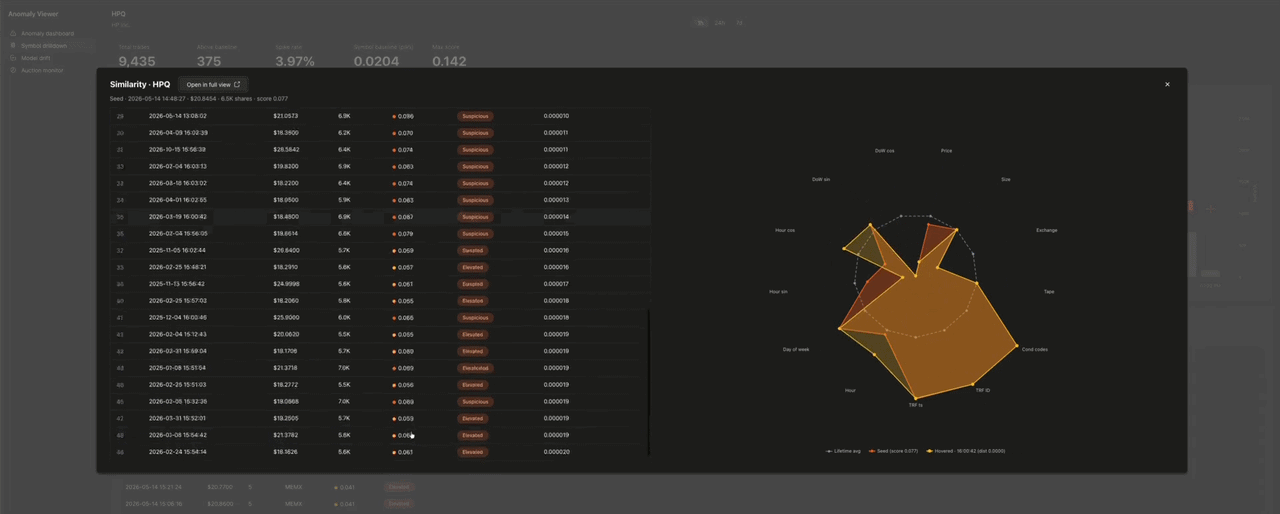
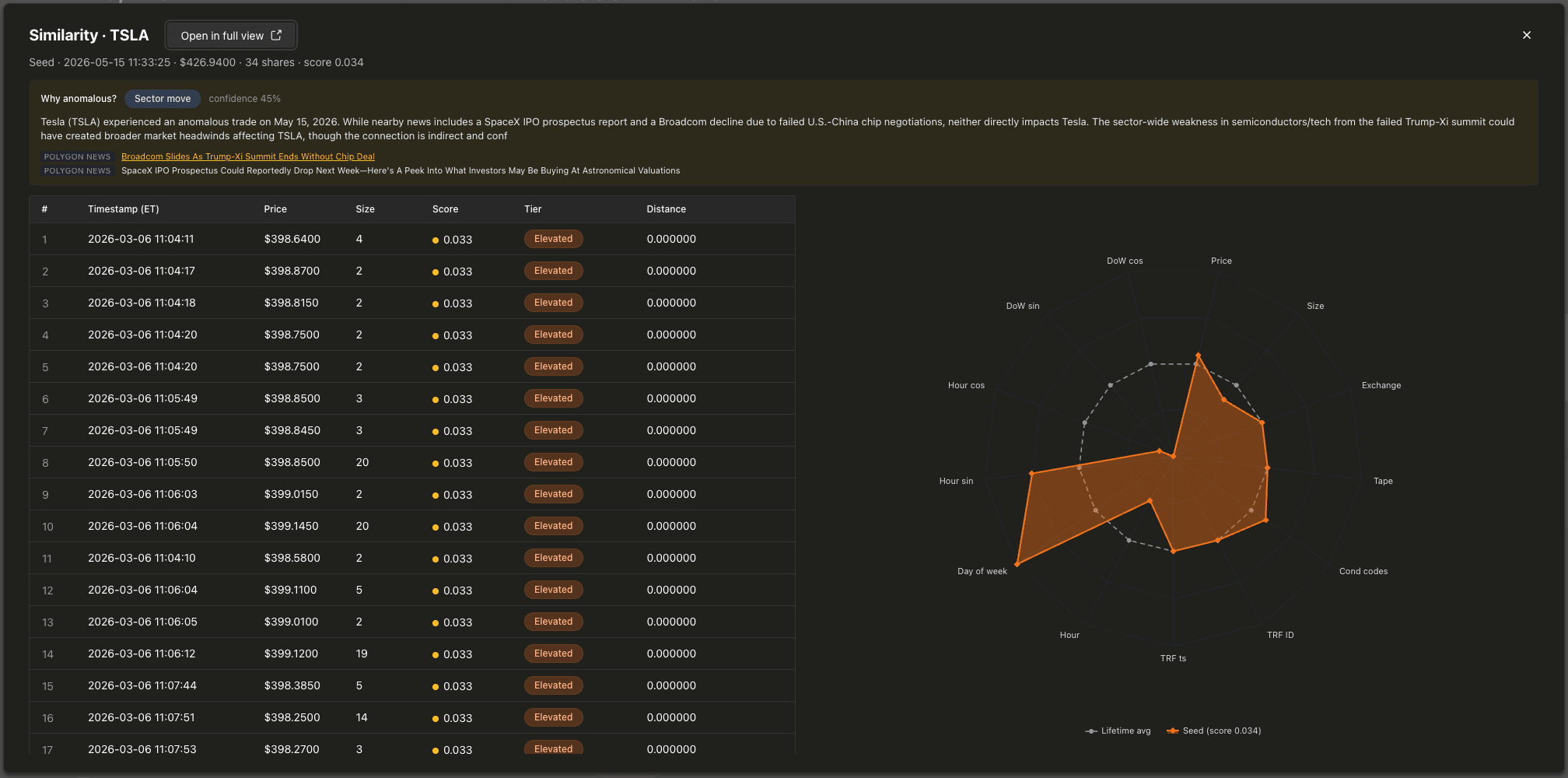
類似検索 は、取引をクリックするとドリルダウン上にモーダルで開きます。
レーダーチャートは、各取引の13個の入力次元を、その銘柄の生涯における各次元の最小値・最大値・平均値で正規化してプロットします。平均値は常に 0.5 にマッピングされるため、ベースライン系列はチャートの中央に正確な13角形として描画されます。偏差が一目で分かります。類似取引の行にホバーすると、それが重ねて表示されます。最も類似した50件の取引は、同一銘柄の embedding 列に対する cosineDistance(embedding, target_embedding) から得られます。
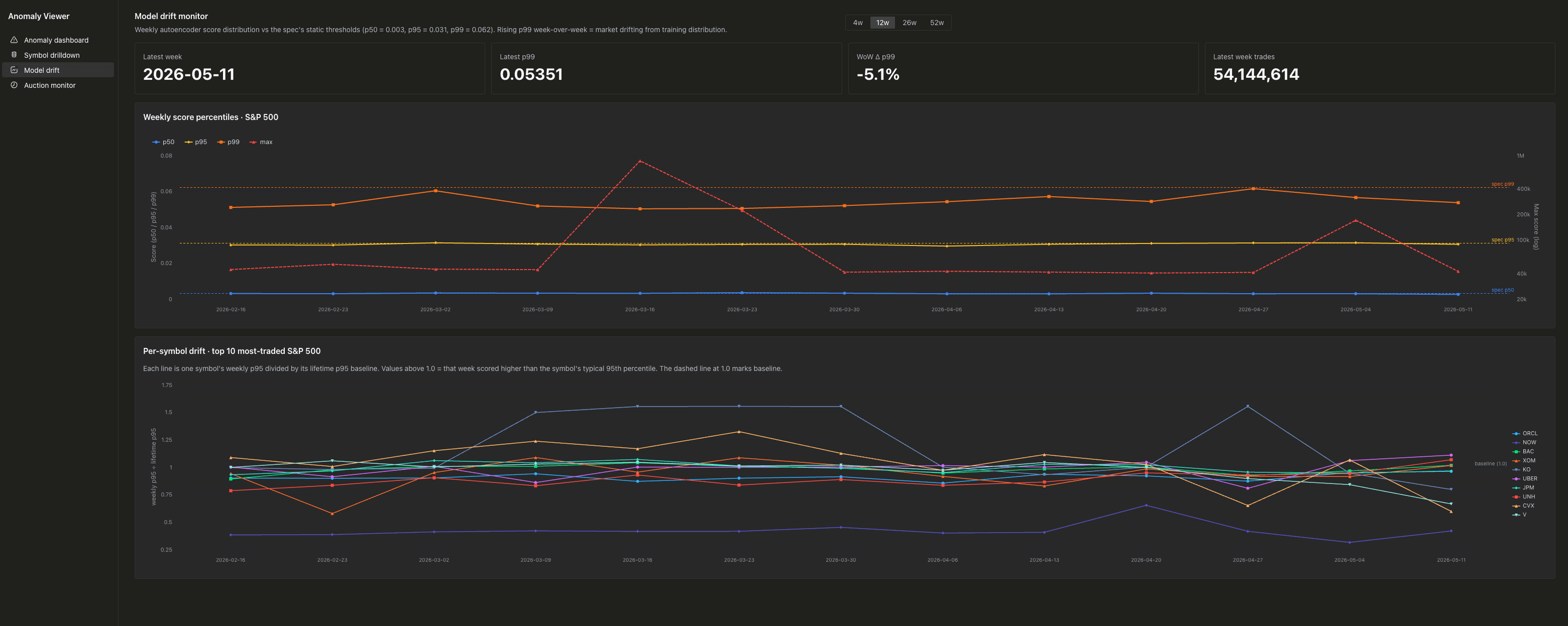
モデルドリフトモニター は、スコア分布を経時的に追跡します。
recon_score の週次 p50、p95、p99、最大値を、モデルが当初キャリブレートされた静的しきい値を示す水平参照線とともに表示します。週を追うごとに p99 が上昇し始めたなら、市場がモデルの学習分布から乖離しており、再学習のタイミングです。
オークションプリントモニター は、極端なテール部分の専用ビューです。寄付き
(c=12)と引け(c=15)のオークションプリントは、その膨大な株数のため、数千から数百万のスコアを記録します。
これらを他の場所でフィルタリングしなければ、あらゆるビューを支配してしまうでしょう。そこで、これらは独自のページを持っています。
ここまで紹介してきたものはすべて、決定論的なパス上で動作します。embed_trade
は取り込み時に行をスコア付けし、ベースラインは1時間ごとにリフレッシュされ、Webアプリは事前計算済みテーブルを読み取ります。読み取りパス上にはどこにも外部呼び出しがありません。これは、負荷を支える部分に求められる形です。安価で、予測可能で、消えてしまう可能性のある上流が存在しません。
しかし、取引がアノマリーとしてフラグ付けされた後、当然次に浮かぶ疑問はなぜ かということです。その答えは ClickHouse の外側にあります — ニュース API、SEC ファイリング、取引停止通知、ソーシャルシグナルなどです。これらを取り込むには、UDF からのネットワークアクセスが必要です。
ネットワークアクセス対応の実行可能 UDF は、ClickHouse Cloud でプライベートベータ提供中です。 有効化すると、UDF ランタイムは許可された任意のホストへのアウトバウンド HTTPS 呼び出しを行えます。このリポジトリでは、これを利用する2つの新しい UDF を追加しました:
(sym, t, window_min) を与えると、2つの外部ソースを呼び出し、その取引時刻付近のイベントを JSON 配列として返します:
Massive News API (Polygon は最近 Massive にブランド変更されましたが、
api.polygon.io エンドポイントは以前と同様に応答します)。SEC EDGAR (無料、公開、API キー不要)。 SELECT
sym,
JSONLength(nearby_events(sym, t, 120 )) AS n_events
FROM stockhouse.trades_embeddings
WHERE recon_score > 1.0
LIMIT 5 ;
これは url() でも ほぼ 実現できます。これを UDF にしている違いは以下の通りです。
インプロセスでの合成。 Polygon の結果と EDGAR のファイリングを、1 回の Python 呼び出しの中で重複排除・ソート・件数制限まで行えます。SQL で 2 つの url() 呼び出しをチェーンすると、同じロジックを UNION ALL と下流の arrayJoin/groupArray 配管に押し込むことになり、動作はするものの見栄えが悪くなります。環境変数による認証。 Polygon API キーはプールプロセスの起動時に POLYGON_API_KEY から読み込まれます。SQL には一切登場しません。プロセスごとの LRU キャッシュ。 各プールワーカーは (sym, minute, window) をキーに直近の結果を保持します。UI 上で同じトレードに 2 回ホバーしても、API 呼び出しは 2 回ではなく 1 回で済みます。コネクションの再利用。 プロセスごとに長寿命の requests.Session() を保持し、HTTP コネクションをそのワーカーが稼働している間(数時間に及ぶ)生かし続けます。
(sym, t) を与えると、nearby_events の内部処理を介してコンテキストを取得し、Anthropic Claude に対して、その異常なトレードの最も可能性の高い原因を分類するよう問い合わせます。戻り値は型付きタプルです:
WITH classify_trade( 'LLY' , 1778777944818 ) AS c
SELECT c .1 AS cause, c .2 AS confidence, c .3 AS summary;
原因は固定された分類体系に制約されます: earnings、m_and_a、halt、rumor、sector_move、block_trade、no_news_found。これは Anthropic の tool-use メカニズムによって強制されます。モデルは、input_schema の cause フィールドに enum を含むツールを呼び出すよう要求されるため、レスポンスは必ずパース可能であり、cause は必ず既知の値のいずれかになることが保証されます。自由形式のテキストを正規表現でパースする必要も、「モデルが 'earnings' に近いが余分な単語を含む何かを返した」というフォローアップロジックも不要です。
Web アプリの類似度モーダルを覚えていますか? classify_trade と nearby_events は、そのモーダルの上部に固定される 「なぜ異常なのか?」 パネルを駆動しています。トレードを開くと、このパネルは両方の UDF を並列で呼び出し、以下を表示します:
分類された原因と信頼度の数値を示すバッジ
モデルが書いた 1〜2 文のサマリー
判断の根拠となったニュースの見出しと提出書類の短いリスト
url() は ClickHouse に長年存在しており、アドホックな取得には適しています。ネットワークアクセス UDF はそれ以外の部分を埋めます: ステートフルなクライアント、認証ライフサイクル、マルチステップのパイプライン、構造化された LLM 出力、プロセスごとのキャッシュなどです。「実行する必要があるコード」と「クエリする必要があるデータ」の境界線がより薄くなります。
3 つの API 呼び出しと LLM プロンプトを含む 200 行の Python 関数を SELECT の中に入れることができます。他の誰もその存在を知る必要はありません。
自身のクラスターで試してみたいですか? ネットワークアクセス UDF はプライベートベータ中です — ClickHouse Cloud サポートに連絡して有効化してもらいましょう!
ほとんどの ML on streaming data アーキテクチャは統合コストを支払っています。モデルはどこかにあり、データは別のどこかにあります。それらをつなぐ接着剤がそれ自体一つのシステムになっています。このリポジトリのセットアップはそれをフラットにします。ClickHouse Cloud クラスター、2MB の Python ファイル、そしてそれらを結びつける 1 つの DDL ステートメントがあるだけです。
Web アプリの UI ロジックはすべて SQL クエリです。システム内で唯一の ML は異常検知ですが、それすら「Web アプリ内の ML」ではなく、テーブルのカラムにすぎません。「この銘柄の直近 1 時間がどれだけ異常か」の計算、「コサイン距離で類似トレードを見つける」クエリ、銘柄ごとの p95 ベースライン、それらすべてを最新に保つマテリアライズドビュー。これらはすべて、標準的な ClickHouse テーブルに対して動作する標準的な SQL 機能です。
Cloud の実行可能 UDF は、ClickHouse の上に新しい抽象化を追加するものではありません。Python を SQL の一部にする手段を提供するものです。
プロジェクト全体は https://github.com/clickhouse/stock-anomaly-udf にあります。
stock-anomaly-udf/
├── notebook/
├── udf/
├── sql/
└── web/
UDF をクラスターに配置する。
SQL ファイルを順番に実行する:
:run sql / 01 _source_schema.sql
:run sql / 02 _embeddings_mv.sql
:run sql / 03 _score_baselines.sql
:run sql / 04 _dim_baselines.sql
過去データのバックフィル (オプション)。MV と同じ SELECT パターンを使い、任意の時間範囲を対象に trades_embeddings へ一括 INSERT を実行します。手順 2 の MV は、それ以降 default.trades へ INSERT されるすべてのデータを自動的に取り込みます。
Web アプリを起動する:
cd web
cp .env.example .env.local
npm install
npm run dev
http://localhost:3000 を開きます。
notebook/ のノートブックでは、独自のオートエンコーダーをエンドツーエンドで学習する手順を説明しています。default.trades から学習データを Parquet チャンクとしてストリーミングし、StandardScaler をインクリメンタルに適合させ、early stopping で学習を行い、成果物をデプロイ可能なバンドルとして zip 化します。
パブリックベータは本日より ClickHouse Cloud で利用可能です。これを使って面白いものを作ったら、ぜひお知らせください!
今すぐ始めましょう ClickHouseが皆さんのデータでどのように動作するか興味はありませんか? わずか数分でClickHouse Cloudを使い始められ、$300の無料クレジットも受け取れます。
Sign up