- LyftはApache DruidからClickHouse Cloudに移行し、日々450TB超のデータ処理と毎秒数百件のクエリをシンプルな運用で実現しています
- S3バッチ取り込みとKafka/Kinesisリアルタイムストリーミングの両方をClickHouse Cloudで統合し、ダッシュボードから実験・予測まで幅広いユースケースを支えています
- セルフマネージドからマネージドサービスへの移行により運用負荷を大幅に削減し、アクセス制御の自動化やスキーマ同期の廃止など継続的な改善を進めています
まとめ
Lyftはシンプルな目的に突き動かされています。それは「人々に貢献し、人々をつなぐこと」。昨年、このライドシェア大手は米国とカナダで4,000万人を超える人々に対して、8億回以上のライドを提供し、乗客が目的地にたどり着くのを助け、ドライバーが自分のペースで稼げるよう支援しました。
それぞれのライドの裏には、膨大なデータが存在します。実験や予測、キャンペーンのターゲティング、マーケットプレイスの健全性の把握まで、Lyftの各チームは賢明な意思決定を行い、サービスを改善し、ビジネスを動かし続けるために、迅速で正確なインサイトに頼っています。
数百万の人を運ぶのと同じく、これらのインサイトを大規模に提供することは途方もない仕事です。Lyftは毎日数百テラバイトのデータを処理しており、深い履歴分析から、データの鮮度が真に重要となるリアルタイムの意思決定まで、あらゆる用途を支えています。彼らは、保守が悪夢にならずに両方を扱える分析システムを必要としていました。
Open Houseでは、エンジニアのJeana ChoiとRitesh Varyaniが、LyftがClickHouse Cloudを採用するに至った経緯について語りました。これには、取り込みパイプラインの進化や、ClickHouseがLyftの拡大するニーズに応えるためのパフォーマンスとスケーラビリティをどのようにもたらしたかが含まれます。
DruidからClickHouse Cloudへ #
長年にわたり、Lyftは時系列データに対する高速でインタラクティブな分析にApache Druidを利用してきました。しかし、システムが複雑化し、保守コストが膨らむにつれて、その採用は伸び悩み始めました。新しいチームのオンボーディングには急な学習曲線が必要で、日々の運用もスケールさせるのがますます困難になっていきました。
2023年、Lyftのマーケットプレイスチームが特定のユースケースでClickHouseを採用したのを受け、同社はDruidの置き換え候補としてClickHouseの評価を開始しました。「ClickHouseの際立った特徴のひとつは、カラム指向のデータ格納と処理、データ圧縮、インデックスといった要素の組み合わせによる高いパフォーマンスです」と、JeanaとRiteshは当時書いています。
高いパフォーマンスに加え、チームのテストでは、ClickHouseが次のような明確な利点を備えていることが明らかになりました。シンプル化されたインフラ、軽減された学習コスト、組み込みのデータ重複排除、低い運用コスト、そして特化型エンジンのサポートです。
「ClickHouseに移行する方が良いと判断しました」とJeanaは言います。
移行はセルフマネージドのデプロイから始まりました。しかし、採用が広がり、運用面での要求が増え続けたため、Lyftは分析基盤をClickHouse Cloudに移行しました。現在、ClickHouseのマネージドサービスはバッチおよびリアルタイムのパイプラインを支えており、S3(Trino経由)、Kafka、Kinesisからデータを取り込んでいます。クライアントアプリケーション、Grafanaのようなオブザーバビリティツール、社内分析ツール、そしてClickHouse CloudのコンソールUIを通じてクエリを提供しています。
次の図は、LyftがどのようにClickHouse Cloudでデータを取り込み、処理し、クエリしているかを示しています。
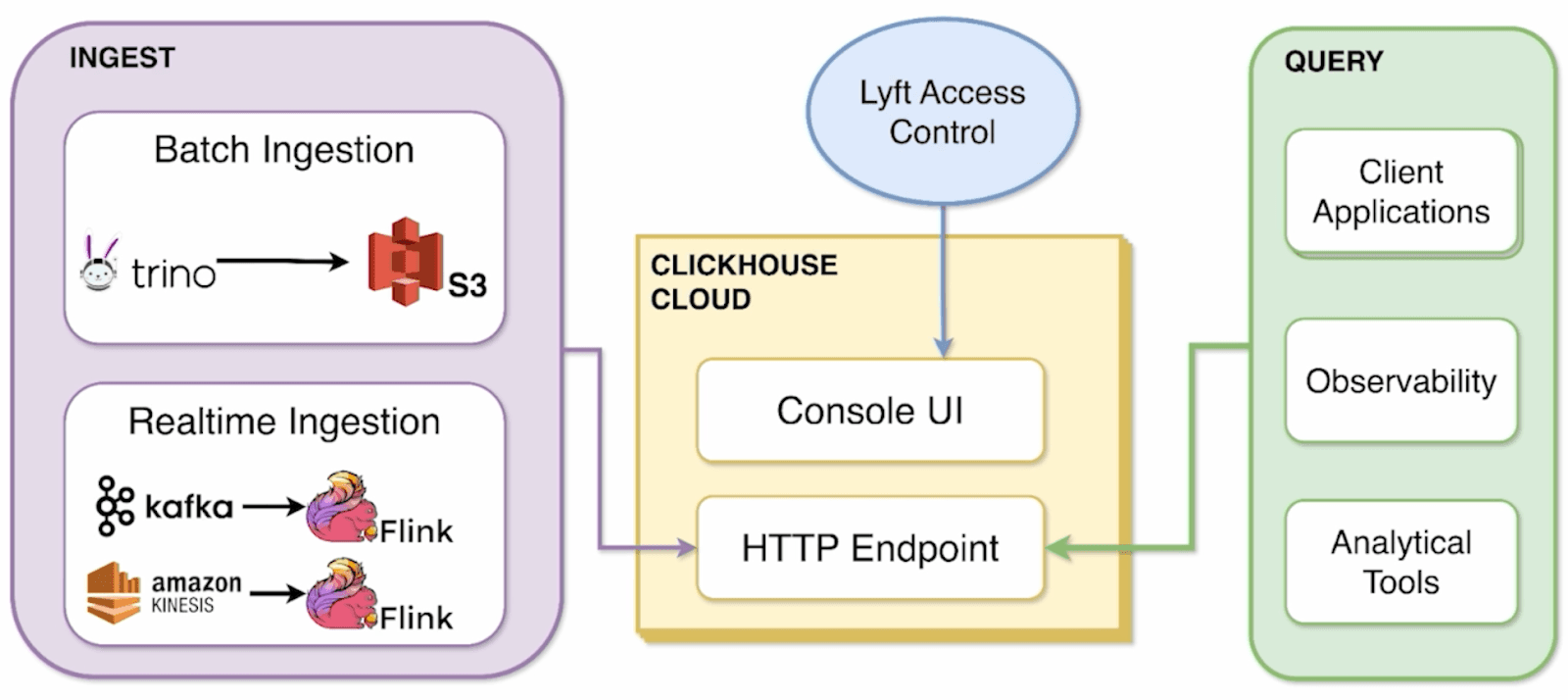
「サクッと触ってみたい人のために、コンソールUIをかなり頻繁に使っています」とJeanaは言います。安全かつスケーラブルなアクセスを実現するために、チームはロールベース権限の自動化も導入しました。新規ユーザーは自動的にread-onlyアクセスでオンボーディングされ、社内ワークフローを通じてチームが昇格権限を割り当てます。これにより、Lyftのアクセス制御ポリシーに沿った迅速かつ安全なアクセスが可能になります。
現在、Lyftの分析システムは平均して1秒あたり数百のクエリを処理しており、「ピーク時には数千に達するなど、継続的に成長しています」とJeanaは話します。1日あたり450テラバイトを超えるデータの読み取りと、約4テラバイトの書き込みを行っており、以前のDruidベースのシステムでは決して実現できなかった、よりスムーズで高速な体験を社内チームに提供しています。
ビジネスインサイトのためのバッチ取り込み #
Open Houseで、JeanaはLyftの分析プラットフォームのバッチ取り込み部分について解説しました。その中核には、スキーマ変更、大規模な集計、効率的な長期保管に対応するための、柔軟で再利用可能な取り込みプロセスがあります。
各バッチ取り込みジョブはTOMLファイルで定義され、ソースデータセット、集計ロジック(通常はTrinoのSQLクエリ)、そしてターゲットのClickHouseテーブルをどのように設定するか(エンジンの種類、パーティショニング、プロジェクション、カラム定義など)を指定します。「これは情報をきれいに整理する良い方法なんです」とJeanaは言います。ジョブはスケジュール実行され、新しいデータでClickHouseを自動的に更新します。「カラムを変えたい時など、このcronが自動で判断して処理してくれます」
次の図は、LyftがTrinoとClickHouseのS3テーブル関数を使ってバッチデータを取り込む方法を示しています。
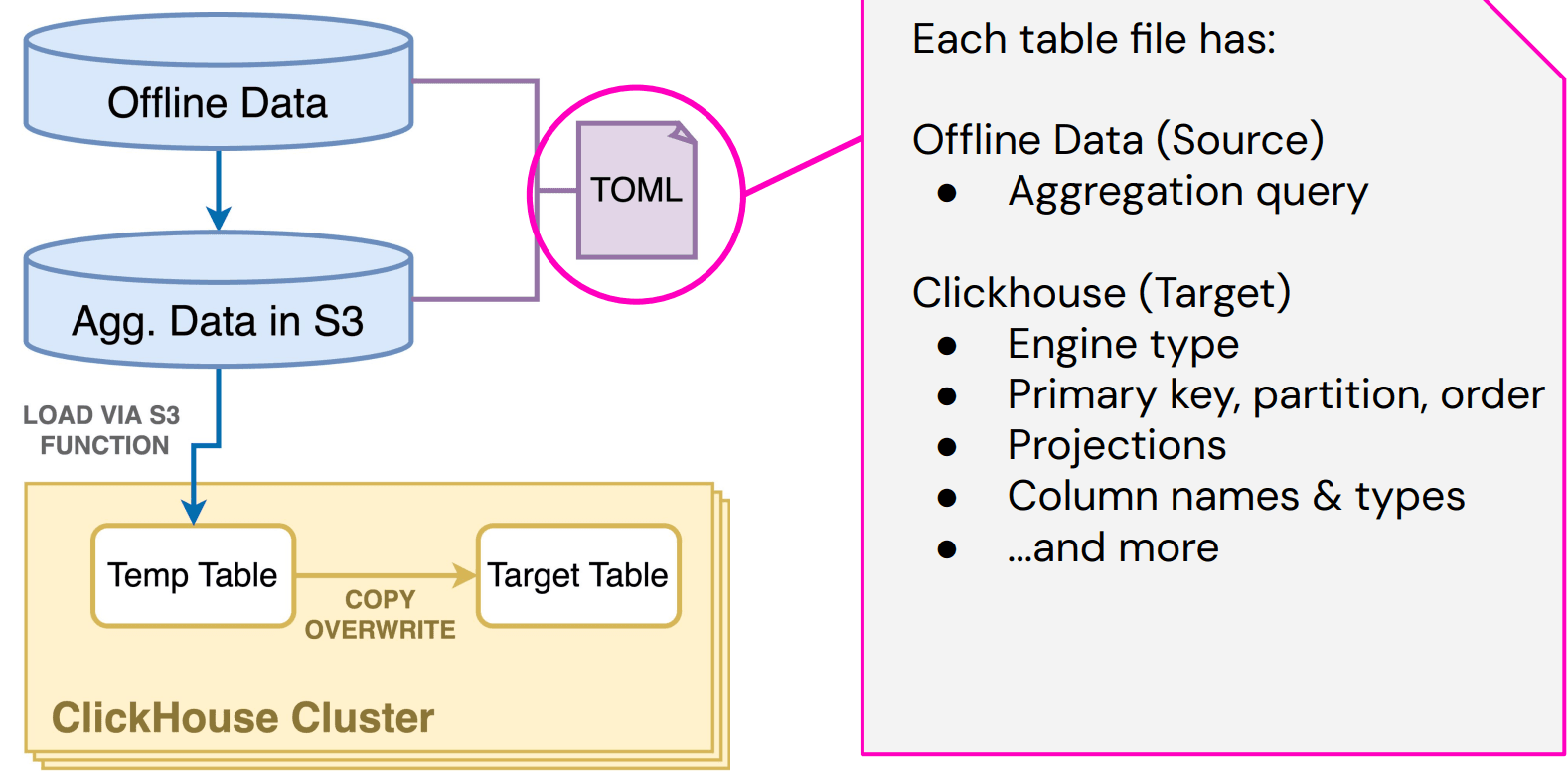
実際の取り込みでは、チームはClickHouseの組み込みs3テーブル関数を使ってS3からデータを読み込み、テンポラリテーブルにステージングした後、更新されたパーティションを差し替えます。「使うのも、好きなS3バケットから読むのも、めちゃくちゃシンプルです」とJeanaは言います。
Jeanaが説明するように、Lyftのバッチデータの主なユースケースはダッシュボード作成です。「ダッシュボードはビジネスインサイトのために、テラバイト規模の履歴ClickHouseデータを使っています。年単位、月単位でデータをスライス&ダイスして、重要なトレンドを素早く可視化できるのは本当に便利です」
バッチ取り込みは、Lyftがリソースを効率的に使うのにも役立っています。「必ずしもリアルタイムである必要のないワークロードに対して、リソースを最適化できます」と彼女は付け加えます。
どんな移行もそうですが、ClickHouse Cloudへの移行も課題と無縁ではありませんでした。チームは既存の社内システムとの整合性の問題にいくつか遭遇し、クラウドで利用可能な機能の違いに対応するため、一部の内部テーブル構造を作り直す必要がありました。例えば、joinテーブルエンジンが利用できなかった際には、比較的静的なルックアップデータに対してはディクショナリの方が実は適していることがわかりました。
困難はあったものの、結果として、テラバイト規模のバッチデータを難なく処理できる、よりスケーラブルで保守しやすいシステムが実現しました。
迅速な意思決定のためのリアルタイム取り込み #
バッチデータが戦略的なインサイトを支える一方で、リアルタイム分析はLyftの日々の業務を駆動しています。Open Houseでは、Riteshが、大規模に速度・信頼性・柔軟性を実現するためにチームがどのようにストリーミングパイプラインを構築したかを共有しました。
このシステムは、KafkaとKinesisという2つの主要なデータソースをサポートしており、実験や予測といった社内ユースケースを駆動しています。どちらの場合も、Apache Flinkが処理レイヤとして機能します。Flinkジョブはイベントをデシリアライズし、Lyftの中央集約型のprotobuf IDL (interface definition language) を使ってエンリッチした上で、データをClickHouse Cloudへ送信します。
この図は、LyftがFlinkを使ってKafkaとKinesisからClickHouse Cloudへリアルタイムデータをストリーミングする様子を示しています。
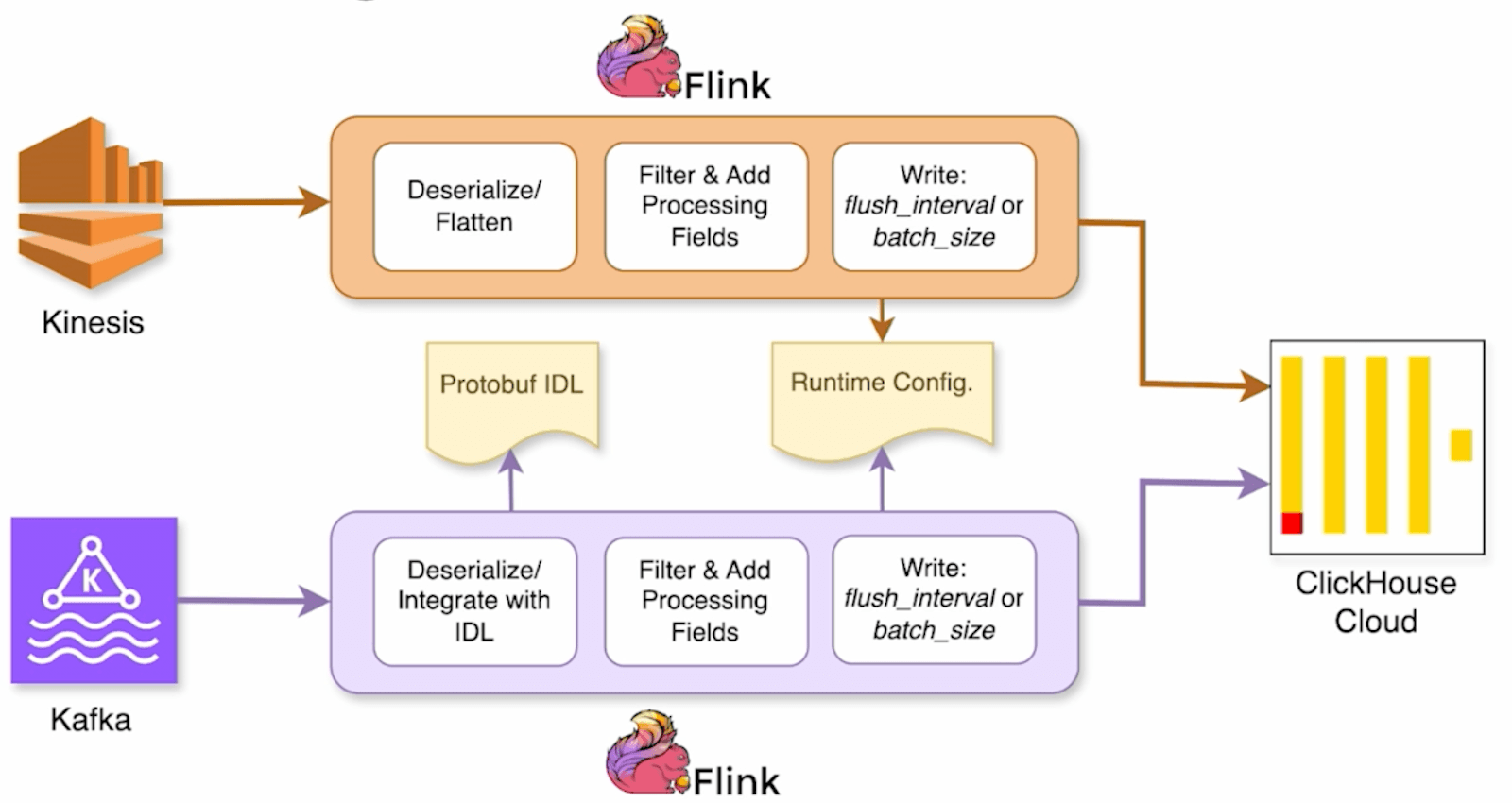
Riteshが強調した大きな進化のひとつは、protobufのスキーマ定義をClickHouseと手動で同期する必要をなくしたことです。「すべてのイベント、すべてのメッセージについて、中央集約型のリポジトリがあります」と彼は説明します。以前のセットアップでは、エンジニアがprotobufの定義を手作業でClickHouseにコピーし、同期し続ける必要がありました。「これは特にネストしたメッセージや、頻繁なスキーマ更新がある場合には大変な手間でした」
新しいセットアップでは、イベント固有の設定に基づき、Javaリフレクションを使ってネストしたメッセージを実行時に動的にデシリアライズします。これにより、手動でのフラット化が不要になり、protobuf IDLが進化してもClickHouseは常に最新の状態に保たれます。
これは、Kafkaイベントを、デシリアライズおよびロールアウトのルールとともにClickHouseテーブルにマッピングするサンプル設定です。

このリアルタイムパイプラインは、あらゆる日々の意思決定を支えています。実験チームはこれを使って、ほぼ瞬時に処置効果を評価します。マーケットプレイスチームは需給の追跡に頼り、キャンペーンマネージャーはリアルタイムシグナルを活用してターゲティングを即座に調整します。
繰り返しになりますが、ClickHouse Cloudへの移行も摩擦と無縁ではありませんでした。LyftはKafkaテーブルエンジンを中心に構築したシステムを作り直す必要がありました。当時ClickPipesはまだプレビュー段階で、本番運用に耐えるほど成熟していなかったためです。古いバージョンのClickHouseをZooKeeperと共に運用していたことも、いくつかの制約をもたらしました。さらにチームは、バッチサイズのチューニング、データの鮮度の向上、そして理想よりもやや密結合だったIDLパイプラインとの関係性の調整に取り組む必要がありました。
スタックは現在も進化中ですが——「6か月後も同じ姿でしょうか? おそらく違うでしょう」とRiteshは語ります——既にLyftのデータドリブン文化の基盤となっています。
LyftとClickHouseの次のステップ #
Lyft社内でのClickHouse採用が広がるにつれて、Jeana、Ritesh、そして彼らのチームは需要に応えるためのスケーリングに注力しています。アクセス制御の改善、非同期インサート、カスタムバッチサイズなど、最近のアップデートは、より高いトラフィックと重いワークロードに備える上で役立っています。
しかし、より大きな変化はこれからです。Lyftの広範なデータプラットフォームへのより深い統合です。「ClickHouse Cloudを独立した製品のままにはしておきたくありません」とRiteshは言います。チームはエンドツーエンドのデータ完全性チェック、新たなデータディスカバリーツール、そしてオフラインデータセットからClickHouseへの直接エクスポートに取り組んでいます。これらの取り組みは、プラットフォームを社内全体でよりアクセスしやすく、影響力のあるものにすることを目指しています。
これまでのClickHouseとの歩みを振り返り、Riteshは祝うべきことがたくさんあり、これからもっと多くのことがあると言います。「この道のりは本当に革命的でした」と彼は語ります。「今後もコラボレーションを続けていけることを楽しみにしています」
ClickHouseについてさらに詳しく知り、チームのデータ運用の速度とスケーラビリティをどのように改善できるかを確かめるには、ClickHouse Cloudを30日間無料でお試しください。



