- Cogent SecurityはClickHouseを活用して、数十億件のセキュリティ検出結果をサブ秒で提供し、AIネイティブな脆弱性管理プラットフォームを支えています。
- PostgresからClickHouseへの移行により、1億行規模においてキャッシュなしでP90クエリレイテンシを5秒から1秒未満へと短縮しました。
- さらにCogentのChart Agentは、エージェント型ループアーキテクチャとClickHouseのプロジェクションを組み合わせることで、精度を40%から94%へと向上させています。
まとめ
AIによってソフトウェア脆弱性の悪用がより速く、より容易になる一方で、エンタープライズのセキュリティチームは、しばしばデプロイが難しく使い勝手の悪いポイントソリューションに足かせをはめられ、後れを取りつつあります。
「私たちの目標は、AIによって脅威の状況が急速に変化する中でも、企業が遅れずについていけるようにすることです」とCogent Securityの創業エンジニアであるKaran Gugle氏は語ります。
プラットフォームのローンチからわずか6か月、Karan氏は2つのことがすでに明らかになっていると言います。1つは、企業は人手不足で、数百万件、時には数億件もの検出結果に対処しなければならないこと。もう1つは、これらの検出結果を実際に修正するには、膨大な組織的コンテキストと、それらが検出されたシステムへの深い理解が必要であることです。
「ユーザーは検出結果をフィルタリングし、自分たちのデータについて質問を投げかけ、リスク修正に着手する必要があります。Cogentのプラットフォームで真に際立つには、これらすべての動作が即時的で、正確で、まるで魔法のように感じられる必要があります」とKaran氏は語ります。「これは、エージェントにとってはなおさら当てはまります。ユーザーが環境内の最新の脅威を追跡したり、コンプライアンスレポートを生成したり、最重要資産の脆弱性を修正したりする際、エージェントは膨大なデータを処理することになるからです。」
2026年3月にサンフランシスコで開催されたClickHouseミートアップで、Karan氏と機械学習エンジニアのSagar Maheshwari氏は、CogentがどのようにClickHouseを基盤としたデータプラットフォームを構築したのか、そしてそれがエージェント型の脆弱性管理にどのような可能性を開くのかについて共有しました。
拡大する脅威ギャップ #
脆弱性管理の課題は、目に見えて悪化しています。National Vulnerability Database(NVD)は現在32万件以上のCVEを追跡しており、この数字はわずか過去10年で5倍に膨れ上がっています。さらに、LLMを活用したツールキットの台頭により、脅威は新たな形で加速しています。
「悪用を試みるために必要な知識のハードルは、経験豊富なシステムエンジニアレベルから、意図とコーディングエージェントへのアクセスさえあれば誰でも、というレベルにまで下がりました」とKaran氏は語ります。
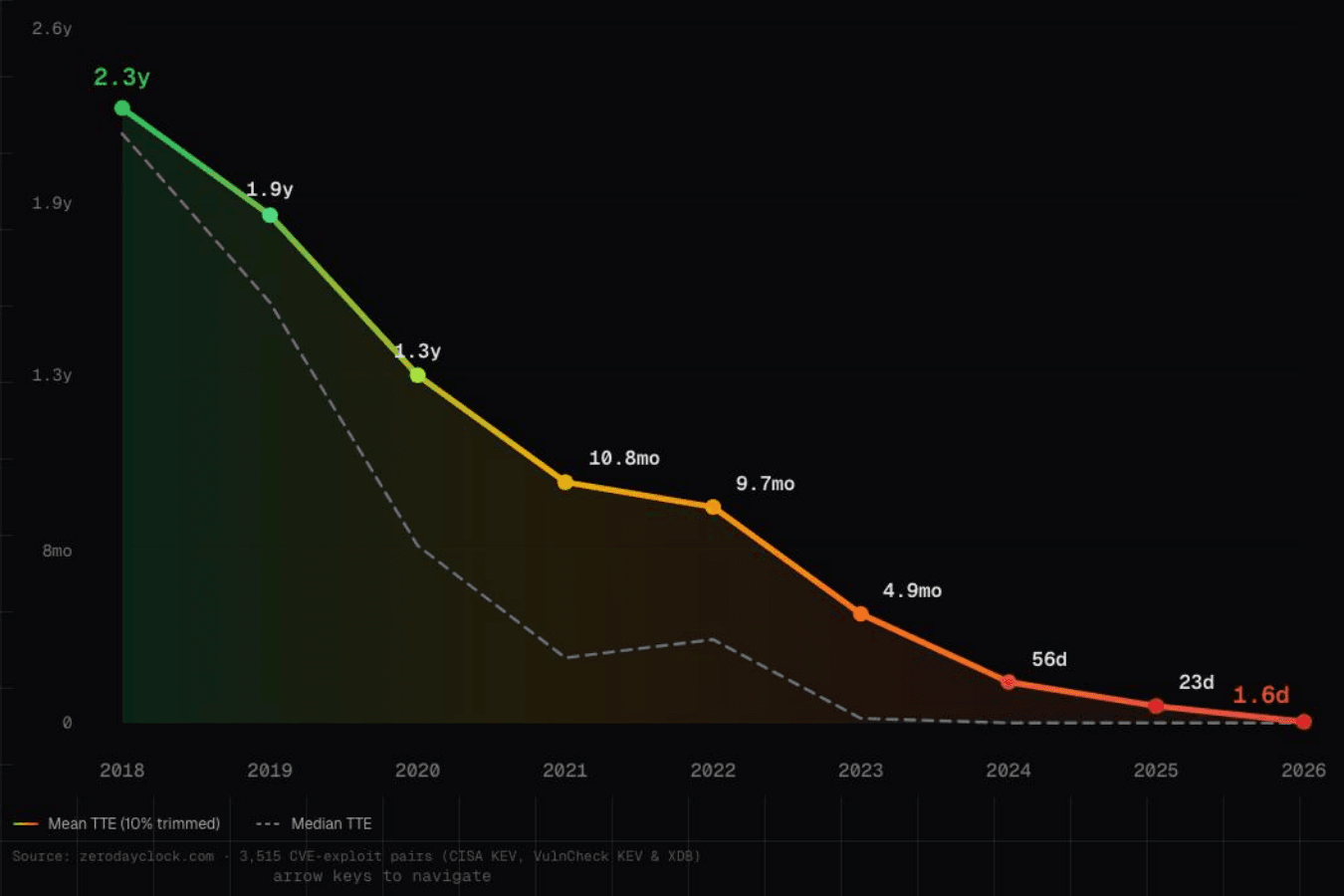
数字がそれを裏付けています。2018年、平均的なtime-to-exploit(TTE) ―― 脆弱性が公開されてから実際に悪用されるまでの期間 ―― は約2.3年でした。2026年、その数字はわずか1.6日にまで縮まっています。
2018年以降、平均time-to-exploit(TTE)は2.3年から1.6日にまで短縮された。
防御側を見ると、セキュリティチームは慢性的な人手不足に陥っており、「スキャン → コンテキスト化 → 優先順位付け → 修正」のループは遅く、手動で、摩擦だらけです。ほとんどのチームは自分たち自身の内部SLAを満たすことすらできておらず、最も重大な脆弱性の50%は2か月経っても未解決のままです。「これはかなり恐ろしい現実です」とKaran氏は語ります。
脆弱性が発見されたら、修正フェーズ ―― なぜそれが重要かをエンジニアリングに伝え、実際に修正する適切な担当者を見つけること ―― は、Karan氏の表現を借りれば「綱渡りのよう」であり、技術的課題であると同時に組織的・プロセス的な課題でもあります。
「このループのすべてを、AIを活用した攻撃者に対抗するためにマシン速度で実行する必要があります」と彼は言います。「私たちが解決しようとしているのは、まさにそこです。」
スケールするセキュリティデータ #
Fortune 500の顧客では、わずか90日で100億を超えるデータポイントが生成され、1日あたり最大1億件のチェンジログイベントが発生することもあります。このデータをチャート、フィルター、エージェントクエリ、バックエンドAPIで信頼性高く提供するため、Cogentは各顧客に専用のClickHouseデータベースを提供しており、製品の異なる表示面に合わせて最適化された100以上のテーブルを備えています。
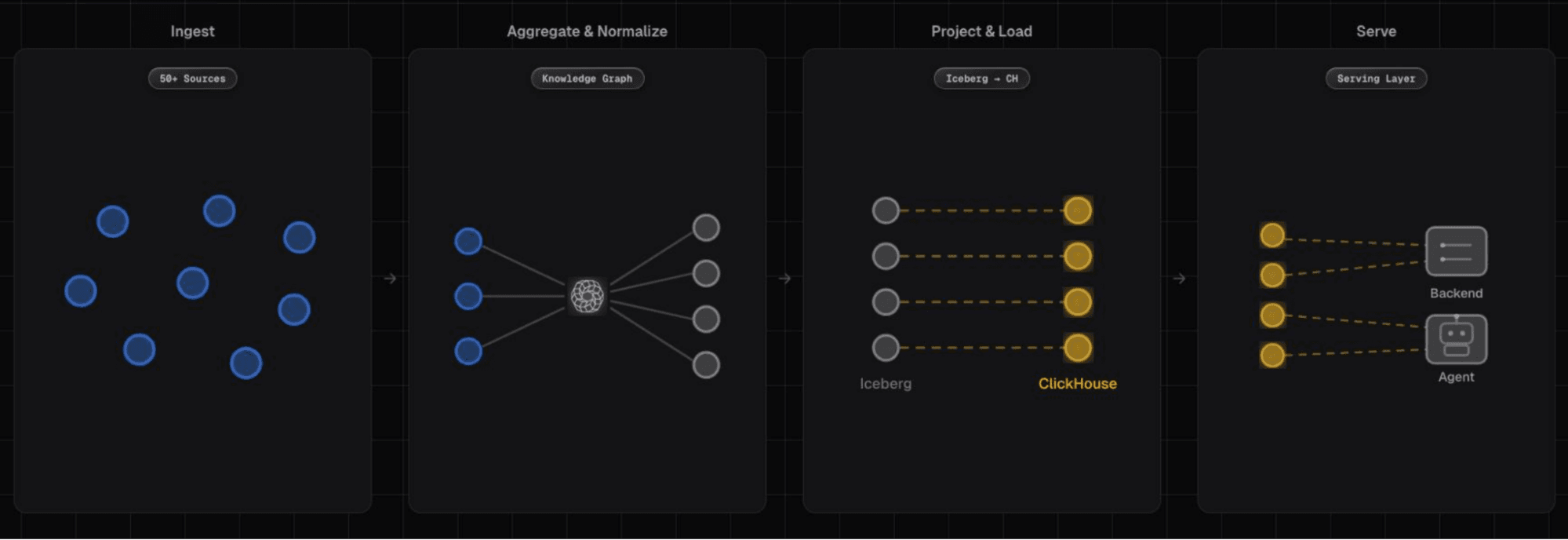
データは、クラウドプロバイダー、脆弱性スキャナー、Slack、Confluence、Jiraなどのビジネスツールを含む50以上のソースから到着します。これらのソースは互いに切り離されているため、Cogentのプラットフォームではまずエンティティ解決を行い、顧客のデータソース間の適切な結合キーを見つけて環境の統一されたビューを生成します。その結果として、データ全体をグラフ的にトラバースできるナレッジグラフが出来上がります。
そこからdbtが非正規化テーブルをIcebergに投影します ―― ナレッジグラフの事前結合・事前集計済みのビューです。これらの投影は次に、ClickHouse Spark Connectorを介してClickHouseにロードされます。これにより、ロードパスに対して安価で調整可能、かつ高度にスケーラブルなコンピュートが提供されます。テーブルスキーマとレイアウトの決定はすべて、ClickHouse dbtライブラリを使って定義されます。
Cogentのデータパイプライン:取り込みからClickHouse駆動のサービングレイヤーまで。
「これが素晴らしいのは、Iceberg dbtの変換パイプラインを、必要なClickHouseの最適化と同じ場所に配置できる点です」とKaran氏は説明します。「たとえば、適切なインデックス、ClickHouseのプロジェクション、圧縮タイプなどを設定できます。」結果として、S3上のIcebergをsource of truthとし、ClickHouseをサービングエンジンとする、クリーンなホット/コールド型データレイクハウスアーキテクチャが実現します。
スピード重視の設計 #
結果を提示する前に、Karan氏は大規模での読み取り高速化を支えるCogentのアプローチの基盤となる5つの設計原則を共有しました。
1つ目はクエリ駆動設計です。「これは、伝統的なリレーショナルの世界から来た人にとって、おそらく最大のマインドセットの変化でしょう」と彼は言います。「エンティティモデルから始めるのではありません。製品が実行する必要のあるクエリから始めて、そこから逆算してテーブルを設計するのです。」
2つ目の原則はすべてを非正規化することです。Cogentのdbtプロジェクションは、データがClickHouseに到達する前に事前結合・事前集計を行い、クエリ時の高価なJOIN操作を排除します。
3つ目はプロジェクションとインデックスの活用です。「これはClickHouseのスーパーパワーの1つです」とKaran氏は言います。「実質的に、わずかなインサート増幅と追加のストレージと引き換えに、フィルタ性能を劇的に向上させているのです。」各プロジェクションは同じデータに対する追加の物理ソート順となり、まったく異なるクエリパターンを単一のテーブルから提供できるようにします。
4つ目は、各カラム型に適した圧縮コーデックを選ぶこと ―― タイムスタンプにはDelta、文字列にはLZ4、コールドデータにはZSTD ―― により、読み取りI/Oとストレージフットプリントを削減することです。
最後に、すべてをベンチマークすること。「system.query_logはあなたの味方です」とKaran氏は語ります。
サブセカンドのパフォーマンス #
Cogentの以前のPostgresベースの構成と現状の差は、スピードが大きな差別化要因となる製品において、適切なインフラがどれだけのことを実現できるかを物語っています。
「これがどれほど重要かを強調したいのです ―― 単なるベンチマーク演習としてではなく、私たちの製品と顧客にとってです」とKaran氏は言います。「セキュリティツールはこの種の負荷の下で頻繁に崩壊します。組織全体の何百万もの検出結果をトリアージしようとしているセキュリティエンジニアにとって、25秒のページロードは何より避けたいものです。」
| P50 | P90 | P99 | |
|---|---|---|---|
| Postgres | 2秒 | 5秒 | 25秒 |
| ClickHouse (1億行) | 0.3秒 | 0.9秒 | 2.5秒 |
| ClickHouse (5億行) | 0.6秒 | 1.8秒 | 4.2秒 |
| 目標 | 0.5秒 | 1秒 | 3秒 |
現在、クエリの98.7%が1億行で3秒未満に完了し、5億行でも86.3%が3秒未満に完了します。Karan氏が補足するように、「これは、バックエンドやデータベースレベルでのキャッシングを一切行わずに、です。」
レポーティングを会話型に #
インフラの話を終えると、Sagar氏がマイクを取り、その上に構築されたものを順に紹介しました。
「私たちが取引するほぼすべての顧客は、現在および過去のリスク姿勢をモニタリングするためのチャートやダッシュボードを必要としています」と彼は言います。「GRC、取締役会向けプレゼン、SLA追跡、日常的な可観測性など、用途を問わずです。」従来、こうしたニーズに応えるには、データサイロからCSVをエクスポートし、BIツールを手動で設定し、会議前に慌ててデータをかき集める必要がありました。本来であればすぐに答えが出るはずのことに、アナリストが何日もかける状態です。
Cogentのアプローチは、レポーティングを会話型にすることです。同社のChart Agentは、自然言語のリクエストを受け取り、チャートをレンダリングするのに必要なClickHouse SQLを生成し、Change Data Captureログをリアルタイムでクエリします。「欲しいものを言葉で言えれば、私たちはそのチャートを作成できます」とSagar氏は言います。「総じて、私たちはレポーティングを ―― 正確さを犠牲にすることなく ―― 数日ではなく数秒で可能にしたいのです。」
最初のバージョンはシングルショットのアプローチを採用していました ―― すべてのコンテキストをシステムプロンプトに詰め込み、ユーザーリクエストを送信し、Sagar氏の表現を借りれば「正しいSQLが返ってくることを祈る」というものです。約100件のtext-to-SQLサンプルからなるゴールデンデータセットでは、これは40%の精度を達成しました。失敗のパターンは明白でした。クエリを実行して仮定を検証する能力がないため、LLMは「自信満々で誤ったSQLを書く」上に、無関係なコンテキストに気を取られてしまうのです。
解決策は、3つの主要コンポーネントを備えたエージェント型ループでした。1つ目はagentic RAGで、データモデルを検索し、必要に応じて関連コンテキストを取り出します。2つ目はライブSQL実行ツールで、ClickHouseに対して直接クエリを実行し、実際のデータを見ます。3つ目はインターリーブされた思考で、すべてを事前に計画するのではなく、ツール呼び出しの間で推論を行い、中間結果が別のアプローチを示唆した際に頑なに当初案にこだわらないようにします。結果:シングルショットで40%だった同じデータセットで、94%の精度を達成しました。
精度に向けた反復 #
Chart AgentのSQLは非決定論的なため、評価は厄介ですが不可能ではありません。Cogentは2つの補完的な評価アプローチを使用しています。トレース評価では、LLM-as-a-judgeを使用して、エージェントが正しく振る舞ったか ―― 関連するスキーマを引き出し、中間クエリを実行し、SQLを検証したか ―― を評価します。
SQL出力検証はより難易度の高い評価です。同じデータセットを与えたとき、エージェントが生成したSQLが期待されるSQLと同じデータ出力を生成するかどうかをチェックします。Cogentでは、SQL文字列の等価性ではなくデータ出力の等価性を評価しており、小型言語モデルを使って期待されるカラムを生成されたカラムにマッピングします。さらに、各テストケースは3回実行され、多数決によって判定されます。「一度正しいだけでは十分ではありません」とSagar氏は言います。「一貫している必要があります。」
反復に取り掛かったとき、データモデルを動的に探索しクエリを実行するためのツールを追加すること ―― 最初のエージェント版 ―― によって、精度は58%に押し上げられました。ゴールデンSQLパターンのキュレートされたクエリバンクによって75%に達し、エージェントはクエリロジックをゼロから考案するのではなく、実証済みのパターンに基盤を置けるようになりました。テナントメモリーバンク ―― エージェントが過去の実行から学んだ教訓を参照できるもの ―― によって82%になりました。
最も顕著なジャンプは、エージェント側の変更ではなく、データ側の変更から生まれました。「エージェントに毎回これらをゼロから構築させるのではなく、ClickHouseに事前計算済みの集計を作成しました。私たちはこれをプロジェクションと呼んでいます」とSagar氏は説明します。「エージェントが書く必要のあるクエリを単純化するだけで、精度が94%にジャンプするのを見たのです。」
唯一のsource of truth #
これらすべてを支えているのが、Cogentが社内で構築したインフラの一部であるOntology Serviceです。
「データモデルが変わると、エージェントは『なんだこれは』という瞬間に直面します。コンテキストと実際のデータの間の不一致で混乱するからです」とSagar氏は言います。Ontology Serviceは、データモデルとそのセマンティクス ―― 説明、列挙、関係性 ―― を物理スキーマと同じ場所に配置することで、この問題を解決します。Sagar氏の言葉を借りれば、「唯一のsource of truth、ドリフトなし」です。
エンタープライズセキュリティはさらに複雑さの層を加えます。「顧客は常にユニークな環境を持っています」とSagar氏は説明します。「Ontology Serviceがないと、エージェントはカスタムフィールドとそのセマンティクスを理解しようとして本当に苦労します。」Ontology Service内のテナント単位のオーバーレイにより、エージェントは各顧客の完全な実効スキーマを自動的に参照できるようになります。
「データモデルをエージェントフレンドリーにすることは新しいパラダイムです」とSagar氏は言います。「これは今後、業界がデータモデリングについて考える方法を変えていくと私は考えています。」
好循環 #
「ClickHouseがAIにもたらす鍵となるものはスピードです」とKaran氏は語ります。
Cogentにおいて、そのスピードはあらゆるレベルでメリットを波及させます。サブセカンドのクエリは、データベースがついていけないと単純に機能しない反復的なエージェントループを可能にします。クエリあたりの低レイテンシは、エージェントの実行全体にわたって積み重なります。そして、高速な評価ループによって、チームは改善をより早く顧客に届けられます。100件のデータ出力比較を、それぞれ3回実行の多数決で行うには、反復を苦行に変えないデータベースが必要です。
Cogentが見出した好循環はシンプルです。高速なデータベースはより多くのツール呼び出しを可能にし、より多くのツール呼び出しはより良い精度を生み、より良い精度はより洗練されたエージェントパターンへの扉を開きます。AI加速型の攻撃者に企業がついていけるよう支援することを急ぐ会社にとって、この循環こそが、他のすべてが構築される土台なのです。



