「リアルタイム」は、データ業界で最も多義的に使われる用語のひとつです。トレーディングデスクにとってはマイクロ秒単位の注文マッチングを意味し、ユーザー向けアプリを構築するチームにとってはサブ秒のページ読み込みを、財務アナリストにとっては「今朝までに最新化されていること」を意味します。ワークロードはそれぞれ異なりますが、いずれも妥当な定義です。
アナリティクスの文脈において「リアルタイム」とは、通常、ユーザー体験そのものがライブであるように感じられることを指します。顧客がダッシュボードを更新したり、リーダーボードを開いたり、問題を調査したりするとき、データには「たった今起きたこと」が反映されていることが期待されます。技術的には、これは単に低レイテンシな分析クエリを提供するだけでなく、大量のデータが継続的に挿入されている最中にそれを実現することを意味します。
リアルタイムアナリティクスとは、単に高速なクエリを提供することではなく、絶えず変化するデータに対して高速なクエリを提供することです。
本ブログでは、なぜ今この形のリアルタイムアナリティクスがこれまで以上に重要なのか、そしてデータ可用性とクエリレイテンシの両面からこの課題をどう分解できるかを解説します。また、データベースが実際にリアルタイムアナリティクスのワークロードをサポートできるかを評価する際に役立つ、実践的な質問リストも持ち帰っていただけるはずです。
なぜ今、リアルタイムアナリティクスが重要なのか #
アナリティクスは長年にわたって劇的に変化してきましたが、現在のパラダイムシフトは、これまでのバッチベースのモデルを打ち破る3つの要因によって推進されています。
第一に、アナリティクスがプロダクトの中に組み込まれつつあります。かつて社内専用だったダッシュボードは、ますます顧客に直接公開されるようになっています。SaaSプロダクトの利用状況エクスプローラー、広告主向けのパフォーマンスビュー、エンドユーザー向けのトレーディング・リスクビューなどです。あらゆるアプリケーションがデータ駆動型となり、結果としてアナリティクスのレイテンシは妥協できないものになりました。リアルタイムアナリティクスはユーザー体験の一部となったのです。
第二に、顧客サマリーを生成したり、調査をスコアリングしたり、サポートチケットをルーティングするエージェントは、見られるデータの質と、それをクエリできる速度によってのみ能力が決まります。レイテンシが本当のボトルネックになり得るのです。しかし鮮度は問題の半分にすぎません。エージェントは人間と同じようにクエリしません。エージェントは人間の100倍以上のクエリを矢継ぎ早に発行でき、それが数百のエージェントが同時に動作することで掛け算となり、それぞれが待ち時間中にトークンを消費します。ほとんどの分析エンジンは、これほどバースト的で予測不可能なワークロードを想定して作られていません。データレイヤーを正しく設計することは、エージェント開発における付随事項ではなく、前提条件です。
第三に、より多くの自動化された判断がライブデータに基づいて行われています。価格設定、パーソナライゼーション、不正防止、オブザーバビリティアラート、広告ターゲティング。これらはもはや人間が後で読むレポートではなく、リクエスト内で行われる判断であり、エンドツーエンドのレイテンシが判断自体の質と有用性に直接影響します。
需要は明確です。この課題を分解する際、「レイテンシ」はしばしばクエリレイテンシのみと誤解されがちですが、実際にはもっと広範なシステム特性であり、データがどれだけ早く到着し、いつクエリ可能になるかも含まれます。
リアルタイムアナリティクスはエンジンの機能ではなく、システム特性である #
顧客がリアルタイムアナリティクスプラットフォームを評価するとき、しばしばクエリレイテンシだけに焦点を当てます。「50ms以内に答えを返せるか?」は妥当な質問であり、静的なデータセットに対して十分なコンピュートを投入すれば、ほとんどの分析エンジンはこれに説得力のある回答を返せます。
しかし、ユーザーが実際に体験するものを決定づける質問はもっと難しいものです。それは、システムが1秒前に到着したデータに対して、取り込みが継続中で、他のユーザーも同時にクエリしている状況で、50msの回答を返せるかどうかです。
データ可用性を考えるには、エンドツーエンドのインサイトまでの時間を考える必要があり、これは3つの要素から構成されます。
- 取り込み時間。 新しく生成されたデータがプラットフォームに到達し、永続的に保存されるまでにどれくらいの時間がかかるか?
- 変換と準備の時間。 クエリが実際に当たるサービング構造(マテリアライズドビュー、ロールアップ、インデックス)をクリーンアップ、エンリッチ、結合、事前集約、または更新するのにどれくらいの時間がかかるか?
- クエリ時間。 データが利用可能になった後、読み取りを計画し実行するのにどれくらいの時間がかかるか?
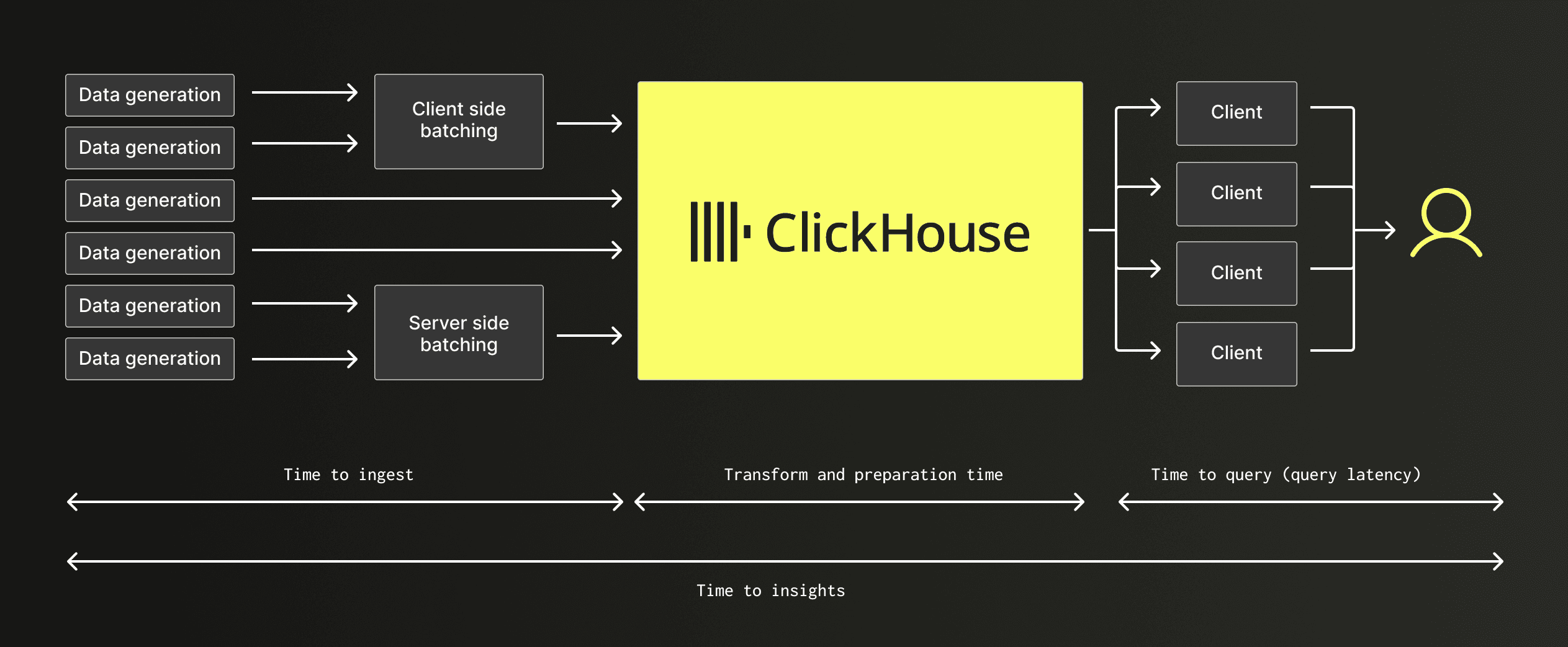
これらのうち1つの次元で高速であっても、別の次元が支配的であれば、ユーザーにとっては遅く感じられることがあります。
これらすべての特性が、高い取り込みスループットと高いクエリ同時実行性の下で、リソース効率を保ちながらスケールして維持される必要があります。
重要なのは、無制限のコンピュートをワークロードに投入することでのみリアルタイムレイテンシを達成するプラットフォームは、現実的に運用できるリアルタイムプラットフォームではないということです。難しいのは、これらの要件すべてを同じエンジンで、同じデータに対して、一方を犠牲にすることなく満たすことです。
なぜデータプラットフォームはこの形のワークロードに苦戦するのか #
今日使われているプラットフォームのほとんどは、より古い世代のアナリティクス、つまりバッチ取り込み、スケジュールされた変換、数時間古いデータに対して社内ユーザーがアドホッククエリを実行する、という用途のために設計されました。それらは構築された目的に対しては優れていますが、根本的にアーキテクチャ上の理由でリアルタイムアナリティクスには苦戦します。
これらのアーキテクチャ上の制約は、大きく以下のカテゴリーにグループ化できます。
- 連続ストリームではなくバッチに最適化された取り込みパス。 多くのウェアハウスアーキテクチャは楽観的並行制御を使用しています。ライターは独立して進行し、コミット時にリトライを通じて競合を解決します。これは書き込みが頻繁ではなく、適切なサイズのバッチであれば機能します。しかし、同時ライターが増えるにつれて、システムは競合解決のためにより多くのリトライにさらされ、テールレイテンシが増加します。継続的な高同時実行性の取り込みこそが、まさにこの問題を顕在化させるワークロードなのです。
- 新しい書き込みがすぐに見えない。 多くの最新のレイクハウスやウェアハウスのアーキテクチャでは、データは書き込まれた直後にクエリ可能になりません。クエリから見えるようになるまでに、カタログ更新、マニフェスト更新、マテリアライズドビューの更新、メタデータの調整ステップを経なければなりません。この遅延は1日の終わりのレポートには問題ありませんが、たった今起きたことを表示することに価値がある機能にとっては致命的です。
- 最適化がライブデータに適用されない。 多くのウェアハウスアーキテクチャはマテリアライズドビューに依存して、スケジュールされた変換を実行し、低レイテンシ提供のために結果を事前計算します。これらの最適化はしばしば1時間ごと、15分ごと、あるいは追加料金を払えば1分ごとに更新されます。その結果、サービングレイヤーが取り得る最も新鮮な状態はその間隔によって制限されます。この制約はアーキテクチャ上のものであり、追加のコンピュートをいくら投入しても解消できません。15分の遅延は請求ダッシュボードでは見えませんが、不正シグナルやライブリーダーボードではイベントを捉えられるかどうかの違いになります。
- ヘッドラインのパフォーマンスは取り込みで生き残らないキャッシュに依存している。 静的データセットでのベンチマークは、キャッシュされ、事前にウォームアップされたクエリのパフォーマンスを示しています。一度、継続的な書き込みがワークロードに加わると、新しいパートごとにパフォーマンスが依存するキャッシュの一部が無効化される可能性があります。その結果、デモで見たパフォーマンスは本番で見るパフォーマンスではなくなります。
- リアルタイム機能がプラットフォームの分離された機能セットになっている。 プラットフォームが最初からリアルタイムを想定して設計されていなかった場合、別のティアを後付けで追加するのが一般的なパターンです。別のテーブルタイプ、別のウェアハウスタイプ、サポートされる操作の異なるセットなどです。SnowflakeのInteractive TablesとInteractive Warehousesは最近の例です。低レイテンシクエリは利用可能ですが、特定のテーブルとウェアハウスタイプに対してのみであり、標準テーブルをクエリすることはできず、ドキュメントがアーキテクチャ上のものと説明する機能制限のリストがあります。切り出された機能ではなく、データセット全体にわたってリアルタイム動作を望むユーザーは、妥協を強いられ、制約に従ってソリューションを設計する必要があります。
- それぞれが独自のシステムを必要とする特殊なクエリタイプ。 最新の分析ワークロードは構造化された行だけではありません。チームはキーワードでログをフィルタリングし、類似性のために埋め込みを比較し、進化するスキーマを持つ半構造化JSONをクエリしたいと考えます。従来の答えは、テキストクエリ用の検索エンジン、埋め込み用のベクトルデータベース、それ以外すべてのための別のウェアハウスを追加することです。追加するシステムごとに、別の取り込みパイプライン、別の整合性境界、別の鮮度の下限、そしてさらなるアーキテクチャ上の複雑さが生じます。エンドツーエンドのレイテンシは、最も遅いコンポーネントによって決まります。
これらは、それらのプラットフォームが構築された目的に対する批判ではありません。バッチ時代のウェアハウスは、スケジュールされた社内向けアナリティクスにおいては依然として優れています。要点は、リアルタイムアナリティクスは形が十分に異なるため、それらのアーキテクチャに後付けで組み込むには、単なるチューニングの問題ではない限界に直面するということです。
リアルタイムアナリティクスプラットフォームが実際に行うべきこと #
リアルタイムアナリティクスを念頭にゼロから構築されたプラットフォームは、いくつかの具体的な設計判断を行う必要があります。このワークロードのためにプラットフォームを評価するときに確認すべき要件は以下のとおりです。
- 取り込みはクエリを劣化させずにスケールするか? 継続的な書き込みがクエリレイテンシを引きずり下ろしてはいけません。実際にはこれは、読み取りパスから隔離されたリソースで実行できる取り込みパスと、ライターが増えてもテールレイテンシを境界内に保てる並行性モデルを意味します。たとえばClickHouseは、楽観的並行制御ではなく、Keeperを通じた合意ベースの調整を使用します。書き込みごとにわずかな調整コストを支払いますが、リアルタイムワークロードで見られる高い挿入並行性下でテールレイテンシを予測可能に保ちます。
- データは書き込まれてから1〜2秒以内にクエリ可能か? 実世界のスケールでは、現実的な目標はミリ秒から数秒の遅延であり、その間にカタログやマニフェストの更新が入りません。
- 変換はスケジュールではなく増分で更新されるか? マテリアライズドビュー、ロールアップ、事前集約(ClickHouseではAggregatingMergeTreeを使用)は、間隔ではなく挿入ごとに更新されるべきです。これにより、すぐに適用され、データ可用性への遅延を強制しません。例えばこれにより、以下が保証されます:
- ライブの請求や使用状況ビューは、ロールアップが更新されるたびに15分ごとにジャンプするのではなく、料金が累積するにつれて正確であり続けます。これは、顧客が自分と同じ数字を見ているときに重要です。
- 不正や異常の集計は、常に1ウィンドウ遅れるのではなく、最新のイベントを反映します。これは、イベントを捉える価値が秒単位で減衰するときに重要です。
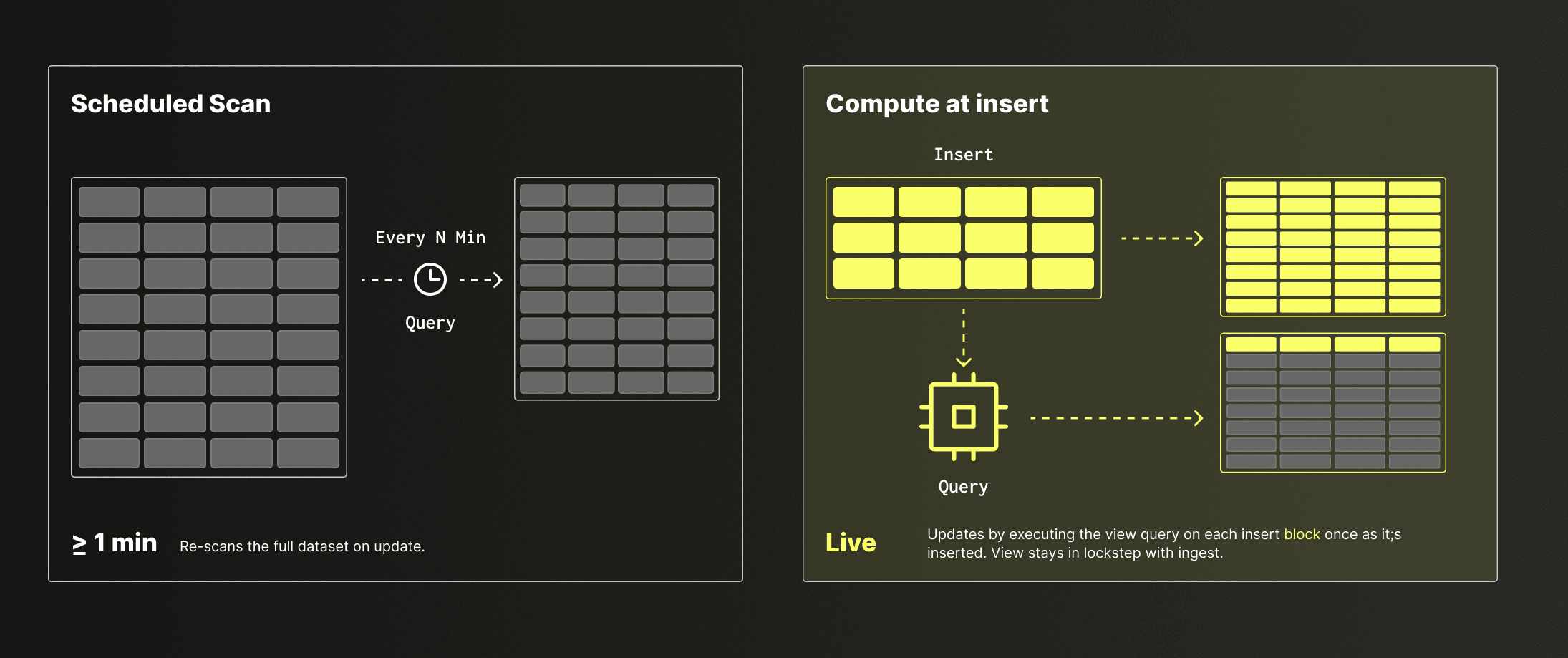
このメンテナンスモデルはコストとスケーラビリティに重要です。更新のたびにフルスキャンに依存するマテリアライズドビューは、鮮度をスケーリングの問題に変え、更新コストがテーブルサイズとともに増大します。増分マテリアライズドビューはこのコストを挿入間で償却し、フルデータセットを繰り返し再計算する代わりに、各行を到着時に一度だけ処理します。
- システムを読み取り時または書き込み時の処理に偏らせることができるか? ワークロードによって望ましいトレードオフは異なります。あるものでは、書き込み時にインデックスや集約を構築し、最新のクエリがすぐに高速化されることを望みます。別のものでは、取り込みスループットを最大化し、バックグラウンド作業に追いつかせたいと考えます。リアルタイムプラットフォームは、その選択を強制せずに公開すべきです。そしてインデックスメンテナンスは決して取り込みをブロックしてはいけません。新しいデータは、インデックスが完全に構築されているかどうかにかかわらず、コミットされ次第クエリ可能でなければなりません。
- 単一のエンジンですべてのワークロードに対応できるか? テキスト検索、ベクトル類似性、JSON、構造化アナリティクス。これらは、それぞれ独自の鮮度の下限を持つ4つの緩く結合されたシステムではなく、同じストレージとクエリエンジン内に存在すべきです。スタックから取り除けるシステムごとに、データが遅れる可能性のある場所が1つ減ります。

-
パフォーマンスはキャッシュされたベンチマークだけでなく、ホットデータで示されているか? どのプラットフォームに対しても問うべき現実的な質問は、昨日のテーブルに対する繰り返しクエリがどれだけ高速かではなく、1秒前に到着したデータに対するクエリがどれだけ高速かです。最初の数字こそ、本番環境で見える数字です。
-
リソース効率はスケールしても維持されるか? リアルタイムシステムは、取り込み量、クエリ同時実行性、保持期間が増大しても効率的であり続ける必要があります。重要な質問は、パフォーマンスがワークロードに対して線形にスケールするのか、それともトラフィックが増えるにつれてレイテンシとコンピュートコストが不釣り合いに悪化し始めるのか、ということです。
これらの要件に共通するのは、リアルタイムアナリティクスがスイッチを入れる機能ではないということです。それは、取り込み、ストレージ、変換、クエリに関する一連の設計判断であり、システム全体にわたって一貫して行われる必要があります。プラットフォームはこのワークロードのために設計されたか、あるいはそれを近似しようと懸命に努力しているかのどちらかです。
Bullet - 実践におけるリアルタイムの姿 #
暗号デリバティブ取引所のBulletは、リアルタイムデータに依存するトレーディングフロントエンドを運用しています。以前のバッチ時代のスタックでは、クエリに5〜30秒、ETLジョブは1時間ごとに20分間実行され、ユーザーは最大1.5時間古いデータを見ることになっていました。ClickHouse Cloudでは、クエリはミリ秒で返り、データレイテンシは99.4%減少して5秒未満となり、チームは同等のコストで1,000倍のデータを扱えるようになりました。共同創業者兼CTOのTristan Frizza氏はこう述べています:
「以前はデータレイク、サービングレイヤー、その他常に壊れる多くのものがありました。ClickHouseがすべてを兼ね備えた万能ソリューションになったのです。」
スケールでのリアルタイムアナリティクスの実世界の例については、当社の顧客がClickHouseでどのように新鮮なデータと低レイテンシのインサイトを提供しているかをご覧ください。



