このブログ記事では、MLOpsの世界と、ClickHouse内のデータをどのようにモデル化・変換すれば、機械学習モデルのトレーニング用の効率的な特徴量ストアとして機能させられるかを解説します。ここで紹介するアプローチは、実際に運用中のClickHouseユーザーが共有してくれたテクニックや、既存の特徴量ストアで利用している方法にも基づいています。
本記事では、ClickHouseをデータソース、オフラインストア、変換エンジンとして使う方法にフォーカスします。これらは特徴量ストアの重要な構成要素であり、モデル学習用のデータを効率的かつ正確に提供するうえで欠かせません。多くの既存特徴量ストアが抽象化を行う部分を、この記事ではもう少し踏み込んで「どうやって効率的にデータをモデル化して特徴量を作り、提供できるか」というところに焦点を当てます。独自の特徴量ストアを構築してみたい方や、既存の特徴量ストアでどんなテクニックが使われているのか知りたい方は、ぜひ読み進めてみてください。
なぜ ClickHouse なのか? #
以前のブログ記事でも「特徴量ストアとは何か」を解説していますので、本記事に入る前に基本的な概念を押さえておくことをおすすめします。シンプルにいうと、特徴量ストアは機械学習モデルのトレーニングに用いるデータを一元的に管理するリポジトリで、共同作業や再利用性を向上させ、モデルのイテレーション速度を上げるために活用されます。
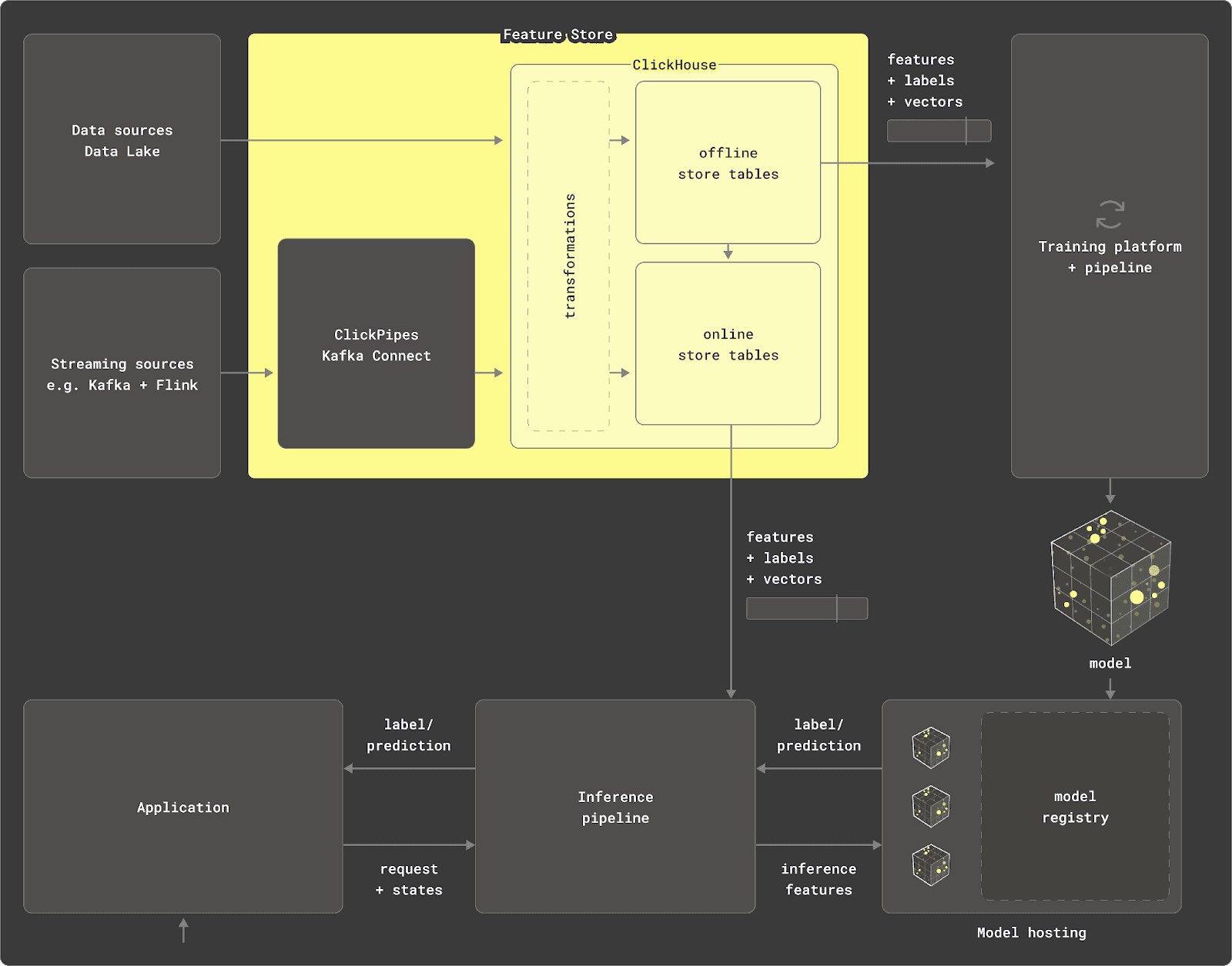
リアルタイムデータウェアハウスであるClickHouseは、単なるデータソースにとどまらず、特徴量ストアのうち以下2つの主なコンポーネントを担えます。
-
変換エンジン: ClickHouseはSQLによるデータ変換を行い、分析・統計系の関数が最適化されています。ParquetやPostgres、MySQLなどさまざまなソースからデータをクエリでき、ペタバイト級のデータに対して集計が可能です。マテリアライズドビューを使って挿入時にデータ変換することもできます。また、PythonからchDB経由で大規模なデータフレームを変換する使い方もできます。
-
オフラインストア: ClickHouseは
INSERT INTO SELECT構文によってクエリ結果を永続化でき、テーブルスキーマを自動生成できます。大規模なデータのイテレーションやスケールにも対応し、特徴量をテーブルにタイムスタンプ付きで格納し、ポイントインタイムでクエリする形がよく取られます。ClickHouse特有のスパースインデックスやASOF LEFT JOIN構文により、高速なフィルタリングや特徴量の結合が実現され、学習パイプラインのデータ準備を効率化します。これらの処理はクラスタ全体で並列化されるため、ペタバイト規模にスケールしつつも特徴量ストア自体は軽量に保てます。
今回は、こうした役割をClickHouseでどのように実現するのか、データのモデル化と運用方法について詳しく見ていきます。
全体的なステップ #
ClickHouseをオフライン特徴量ストアとして使い、モデルをトレーニングする際は、以下のステップで考えるとわかりやすいです。
-
探索
ClickHouse上のソースデータをSQLでクエリしながら理解を深める。 -
データサブセットと特徴量の特定
使えそうな特徴量や、それらが紐づくエンティティ、必要となるデータのサブセットを特定する。このステップで抽出したデータを「特徴量サブセット」と呼ぶ。 -
特徴量の作成
特徴量を生成するためのSQLクエリを作成する。 -
モデル用データの生成
共通のキーとタイムスタンプを基準にASOF JOINなどで特徴量を結合し、最終的に特徴量ベクトルを作る。 -
テストセットとトレーニングセットの生成
「特徴量サブセット」をテスト、トレーニング、(必要に応じて)バリデーションに分割する。 -
モデルの学習
トレーニングデータを使ってさまざまなアルゴリズムでモデルを学習する。 -
モデル選択とチューニング
バリデーションセットでモデルを評価し、最適なモデル選択とハイパーパラメータのチューニングを行う。 -
モデル評価
テストセットで最終モデルを評価し、性能が十分であれば終了。そうでなければ2に戻る。
ここでは、ClickHouseに特有のステップである(1)~(5)について解説していきます。上記フローで重要なのは、非常に反復的であるという点です。特に(3)と(4)は「特徴量エンジニアリング」と呼ばれ、モデルを選ぶ段階以上に時間を要することが多いです。ここを最適化してClickHouseをうまく使えば、時間とコストの大幅な削減につながります。
以下では、各ステップを順に見ていき、ClickHouseの機能を最大限に活用する柔軟なアプローチを提案します。
データセット & 例 #
例として、以下のウェブ解析データセットを使用します(データセットの解説はこちら)。これは1億行のデータで、あるURLへのリクエストを1イベントとして扱います。ClickHouse上でWeb解析データを使って機械学習モデルを学習するケースは、ユーザーの利用例としてもよく見られます[1][2]。
データサイズが大きいため、以下のテーブルは使用カラムに絞っており、完全なスキーマはこちらで確認できます。
CREATE TABLE default.web_events
(
`EventTime` DateTime,
`UserID` UInt64,
`URL` String,
`UserAgent` UInt8,
`RefererCategoryID` UInt16,
`URLCategoryID` UInt16,
`FetchTiming` UInt32,
`ClientIP` UInt32,
`IsNotBounce` UInt8,
-- 多数のカラムが続く...
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
今回の例では、このデータセットを使って「ユーザーがリクエストを送ったときにバウンス(直帰)するかどうか」を予測するモデルを作ることを想定します。上記ソースデータでは、IsNotBounceカラムがバウンスかどうかを示す指標で、これを分類ラベル(ターゲット)とみなします。
ここでは実際にモデル構築やPythonコードは示さず、データモデリングの流れにフォーカスします。そのため、使う特徴量は説明用のサンプルにすぎません。
ステップ 1 – 探索 #
まずはソースデータを探索・理解し、ClickHouseでのSQLクエリに慣れていきます。ClickHouseには分析関数が豊富に用意されていますので、ここを把握しておくと便利です。データの概要をつかんだら、どんな特徴量をモデルに使うか、またそのために必要なデータのサブセットは何かを決めていきます。
ステップ 2 – 特徴量とサブセット #
バウンス予測モデルを作る場合、学習用データには各データポイントに対応する特徴量ベクトルを用意する必要があります。多くの場合、これらの特徴量は「元データの一部から抽出・変換したもの」です。
ほかのブログ記事でも解説しているように、特徴量や特徴量ベクトルは、ざっくり言うと結果セットのカラムと行に対応します。大事なのは、学習時と推論時の両方で利用可能であることです。
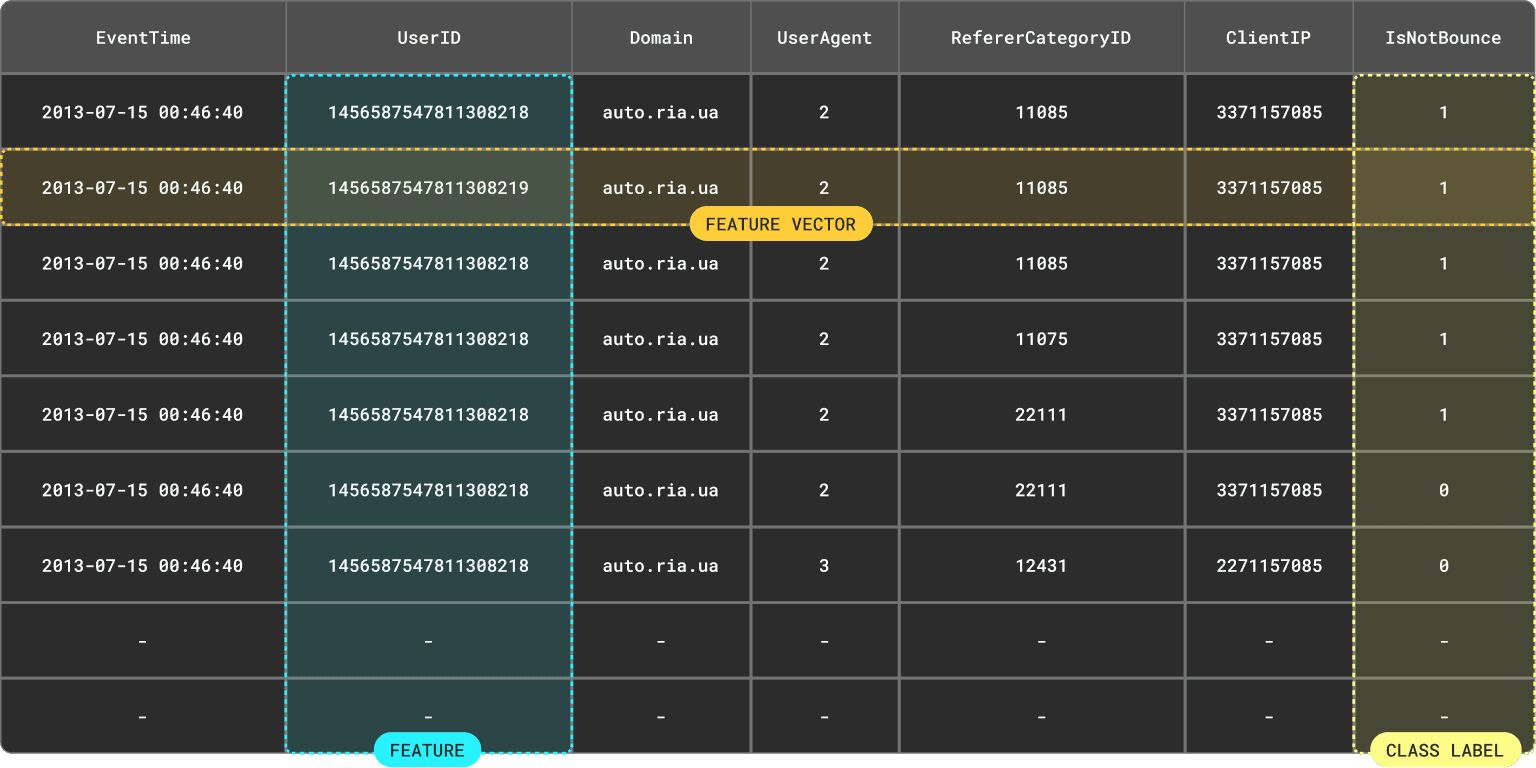
ここで「結果セット」という言い方を強調しているのは、単にテーブルのある行・一部カラムを取り出すだけでなく、集計や変換を経て特徴量を計算するケースがほとんどだからです。
特徴量の特定 #
特徴量を検討する際に、モデリング手法に影響を与える2つの重要な観点を押さえておきましょう。
-
エンティティとの関連付け
特徴量は、どの「エンティティ」に紐づくか(あるいはキーベースで管理されるか)が重要です。今回のケースだと、ユーザーに紐づく特徴量(例: ユーザー年齢、Client IP、ユーザーエージェントなど)や、ドメインに紐づく特徴量(例: ドメインの年間アクセス数)などが考えられます。エンティティに紐づけるには、一意に識別するキーが必要です。今回であれば、
UserIDでユーザーを、URLから抽出できるドメインをdomain(URL)で取得し、ドメインをエンティティとします。 -
動的で複雑な特徴量
一部の特徴量はユーザー年齢のようにほとんど変化しない場合もありますが、Client IPなどは時期によって変わる場合もあります。こうした特徴量は、ある時点の値が必要になります。つまり「ポイントインタイム」が重要です。また、単純な列の値だけでなく集計が必要なケースも多く、そうした集計ベースの特徴量こそClickHouseが得意とする部分です。
特徴量の例 #
例えば、以下のような特徴量を使ってバウンス予測に役立てると仮定してみます。すべて時刻に紐づく動的なものです。
- アクセス時のユーザーエージェント
ユーザーエンティティに紐づき、カラムUserAgentから取得。 - リファラのカテゴリ
ユーザーエンティティに紐づき、RefererCategoryIDカラムから取得(例: 検索エンジン、SNS、直打ちなど)。 - ユーザーが1時間に訪問したドメイン数
ユーザーエンティティに紐づく集計値。GROUP BYで計算が必要。 - 1時間にそのドメインを訪れたユニークIP数
ドメインエンティティに紐づく集計値。GROUP BYが必要。 - ページのカテゴリ
ユーザーエンティティとして扱うが、URLCategoryIDカラムから取得(単純な列ベースの特徴量)。 - ドメインごとの1時間あたりの平均リクエスト時間
FetchTimingカラムから集計して計算し、ドメインエンティティに紐づける。
実際にはもっと適切な特徴量があるかもしれませんが、ここでは例示のため単純化してあります。また、一部の特徴量は実際には「セッション」など他のエンティティに紐づけるべきかもしれません。
特徴量サブセット #
使う特徴量をざっくり決めたら、それらを作るのに必要なデータだけを抜き出す「サブセット」を抽出することもよく行われます。データがそれほど大きくない場合は不要ですが、巨大な場合や細かい前処理が必要な場合によく使われます。
このステップでよく見られるのが、学習用データを格納するテーブルを作っておく方法です。ここでは「特徴量サブセット」と呼ぶことにします。具体的には以下を含むようなイメージです:
- 各特徴量ベクトルに対応するエンティティの値
- イベント時刻
- クラスラベル(ターゲット)
- 特徴量生成に使うカラム
(将来的に使う可能性があるカラムもあらかじめ入れておく場合も)
このようにすると以下のメリットがあります:
-
元のデータを読み出すときとは異なる読み方で最適化・ソートが行え、後続のクエリが高速になる。
-
変形やフィルタリングが重いクエリになる場合、最初に一度だけ実行してサブセットテーブルに挿入すれば、以降の処理が効率化される。
さらに、元データには重複がなくても、サブセットとして取り出す列の組み合わせによって重複が発生するケースがあります。この段階で重複排除(データクレンジング)を行うことも可能です。
例えば、predict_bounce_subsetという中間テーブルを作るとしましょう。必要なカラムはEventTime、ラベルのIsNotBounce、エンティティキーとしてDomainとUserID、そして簡単な特徴量候補のUserAgent, RefererCategoryID, URLCategoryID、集計に必要なFetchTimingとClientIPです。
CREATE TABLE predict_bounce_subset
(
EventTime DateTime64,
UserID UInt64,
Domain String,
UserAgent UInt8,
RefererCategoryID UInt16,
URLCategoryID UInt16,
FetchTiming UInt32,
ClientIP UInt32,
IsNotBounce UInt8
)
ENGINE = ReplacingMergeTree
ORDER BY (EventTime, Domain, UserID, UserAgent, RefererCategoryID, URLCategoryID, FetchTiming, ClientIP, IsNotBounce)
PRIMARY KEY (EventTime, Domain, UserID)
ここではReplacingMergeTreeを使います。このエンジンは、ORDER BYのキーが同じ行をバックグラウンド処理で重複排除してくれます。クエリ時に重複を排除したい場合は、FINAL修飾子を使います。上記例では、全カラムが同じなら重複扱いになるように設定しています。EventTime, UserID, Domainが同じでもFetchTimingが異なれば別行として残るイメージです。
ReplacingMergeTreeについては、詳細をこちらで確認できます。
ORDER BYに指定したカラム全てがPRIMARY KEYに載るわけではありません。今回の例では、
PRIMARY KEYにはEventTime, Domain, UserIDだけを載せ、他のカラムは並べ替えキーとしてのみ利用しています。これによってメモリ使用量を節約できます。
ここで、Robotness=0(ボットでないアクセス)かつDomainとUserIDが存在するイベントのみを取り出すとします。このフィルタで行数は4200万件になったとします。
INSERT INTO predict_bounce_subset SELECT
EventTime,
UserID,
domain(URL) AS Domain,
UserAgent,
RefererCategoryID,
URLCategoryID,
FetchTiming,
ClientIP,
IsNotBounce
FROM web_events
WHERE Robotness = 0 AND Domain != '' AND UserID != 0
0 rows in set. Elapsed: 7.886 sec. Processed 99.98 million rows, 12.62 GB (12.68 million rows/s., 1.60 GB/s.)
SELECT formatReadableQuantity(count()) AS count
FROM predict_bounce_subset FINAL
┌─count─────────┐
│ 42.89 million │
└───────────────┘
1 row in set. Elapsed: 0.003 sec.
上記で
FINAL修飾子を使うことで、クエリ時に重複排除後の行数を数えています。
特徴量サブセットの更新 #
サブセットを一度作ると、元データに新しいイベントが来るたびに更新したい場合があります。スケジュールクエリで再作成する方法もありますが、ClickHouseなら(インクリメンタルな)マテリアライズドビューで更新処理を自動化できます。
マテリアライズドビューは、あるテーブルへのデータ挿入ブロックが発生したタイミングで指定クエリを実行し、その結果を別のテーブルに入れるトリガーのような仕組みです。今回の例だと、web_eventsへの挿入ブロックに合わせてビューのクエリが実行され、その結果がpredict_bounce_subsetに挿入されます。これにより、新規データ分だけ追加入力されていくのと等価になります。

例えば、predict_bounce_subsetを保つマテリアライズドビューは以下のようになります。
CREATE MATERIALIZED VIEW predict_bounce_subset_mv TO predict_bounce_subset AS
SELECT
EventTime,
UserID,
domain(URL) AS Domain,
UserAgent,
RefererCategoryID,
URLCategoryID,
FetchTiming,
ClientIP,
IsNotBounce
FROM web_events
WHERE Robotness = 0 AND Domain != '' AND UserID != 0
これはシンプルな例ですが、マテリアライズドビューの強力な機能についてはこちらをご覧ください。以降のステップでは、predict_bounce_subsetを使用するものとします。
ステップ 3 – 特徴量の作成 #
実際にモデルを学習させるには、用意した特徴量を組み合わせて、IsNotBounceというラベルを含む「特徴量ベクトル」を作る必要があります。

ここで示すように、複数のエンティティに紐づいた特徴量を1つの行にまとめ上げる必要があります。多くの場合、別エンティティの「直近時刻の値」を取得する形になるため、時間で整合を取ることが大切です。
ClickHouseに慣れたエンジニアであれば、一つの長大なSQLクエリでこの特徴量ベクトルを一気に生成することも可能です。しかしデータ量が膨大な場合、計算量の大きいクエリになり、管理や再利用も難しくなります。
また、特徴量ベクトルは繰り返し実験を回す中で内容が変わるため、最適化も含めてクエリ定義を共有・再利用したいケースが多いです。そこで、特徴量のクエリ結果を一度テーブルに落とし込む(INSERT INTO SELECTで永続化する)設計がよく取られます。これにより、計算を1回で済ませ、他のデータサイエンティストと結果を共有し、クエリ内容も最適化・バージョン管理しやすくなります。
ここでは「SQLクエリ定義をどのように宣言・バージョン管理・共有するか」は割愛しますが、SQLもコードである以上、さまざまなソリューションが考えられます。
特徴量テーブル #
特徴量テーブルは、エンティティと必要ならタイムスタンプをセットで保持しておき、そこに実際の特徴量の値を格納する仕組みです。多くのユーザー事例を見ると、次の2つのパターンがあります。
- 特徴量ごとにテーブルを作る
- エンティティごとにテーブルを作る
両者には一長一短がありますが、どちらも共通して「特徴量を再利用可能にする」「データの圧縮率が高くなる」というメリットがあります。
なお、単純な列から取れる特徴量については、必ずしも別テーブルにせず、サブセットテーブルからそのまま取得する形でも問題ありません。
特徴量テーブル(特徴量ごと) #
「1特徴量=1テーブル」とする場合、テーブル名がその特徴量名を表します。この方式の利点は、後段での結合がシンプルになりやすく、マテリアライズドビューを使って更新するときも管理しやすい点です。
一方で、特徴量が何千もあるような場合はテーブルも同じだけ必要になり、すべてをマテリアライズドビューで保守するのはスケーラビリティ上困難になる場合があります。
以下は、ドメインごとの「1時間あたりのユニークIP数」を保持するテーブルの例です。
CREATE TABLE number_unique_ips_per_hour
(
Domain String,
EventTime DateTime64,
Value Int64
)
ENGINE = MergeTree
ORDER BY (Domain, EventTime)
ORDER BYは圧縮と読み込みパターンを考慮して設定します。INSERT INTO SELECTで集計結果を挿入し、特徴量テーブルを作る例を示します。
INSERT INTO number_unique_ips_per_hour SELECT
Domain,
toStartOfHour(EventTime) AS EventTime,
uniqExact(ClientIP) AS Value
FROM predict_bounce_subset FINAL
GROUP BY
Domain,
EventTime
0 rows in set. Elapsed: 0.777 sec. Processed 43.80 million rows, 1.49 GB (56.39 million rows/s., 1.92 GB/s.)
SELECT count()
FROM number_unique_ips_per_hour
┌─count()─┐
│ 613382 │
└─────────┘
ここではDomainとValueをカラム名に使いましたが、一般化したい場合は下記のようにEntityとValueという汎用名を持つテーブルにし、Variant型でデータ型をある程度柔軟に扱う方法もあります。
CREATE TABLE
(
Entity Variant(UInt64, Int64, String),
EventTime DateTime64,
Value Variant(UInt64, Int64, Float64)
)
ENGINE = MergeTree
ORDER BY (Entity, EventTime)
Variant型は実験的な機能で、1つのカラムに複数の型(String, Float64, Int64など)のいずれかを保持できるようにしたものです。
特徴量テーブル(各エンティティ) #
もう1つのアプローチは、同じエンティティに紐づく複数の特徴量を1つのテーブルにまとめる形です。テーブル内にFeatureIdという列を用意して、各行がどの特徴量なのかを区別します。
この方式のメリットは、特徴量が増えてもテーブルの数はエンティティ単位で済むので、大規模ケースでも比較的管理しやすいことです。一方、マテリアライズドビューとの組み合わせがやや難しくなり、エンジニアリング面で工夫が必要になることがあります。
さらにドメインをエンティティとする場合、ドメインに紐づく特徴量はVariant型が必要になる可能性があります。下記の例ではUInt64, Int64, Float64をサポートするテーブルとしています。
-- domain Features
SET allow_experimental_variant_type=1
CREATE TABLE domain_features
(
Domain String,
FeatureId String,
EventTime DateTime,
Value Variant(UInt64, Int64, Float64)
)
ENGINE = MergeTree
ORDER BY (FeatureId, Domain, EventTime)
ORDER BY (FeatureId, Domain, EventTime)は、後でFeatureIdやDomainでフィルタするパターンに最適化しています。先ほどの「1時間あたりのユニークIP数」をこのテーブルに入れる場合は、次のようになります。
INSERT INTO domain_features SELECT
Domain,
'number_unique_ips_per_hour' AS FeatureId,
toStartOfHour(EventTime) AS EventTime,
uniqExact(ClientIP) AS Value
FROM predict_bounce_subset FINAL
GROUP BY
Domain,
EventTime
0 rows in set. Elapsed: 0.573 sec. Processed 43.80 million rows, 1.49 GB (76.40 million rows/s., 2.60 GB/s.)
SELECT count()
FROM domain_features
┌─count()─┐
│ 613382 │
└─────────┘
「特徴量ごとテーブルのほうが読み取り速度が速いのでは?」と思うかもしれませんが、
ORDER BYキーとスパースインデックスをしっかり設定すれば、パフォーマンス差はほとんどありません。
特徴量テーブルの更新 #
一部の特徴量は固定的ですが、多くの場合、元データの到着に合わせて特徴量を更新する必要があります。「サブセット更新」の章で紹介したやり方と同様、マテリアライズドビューで自動更新できます。
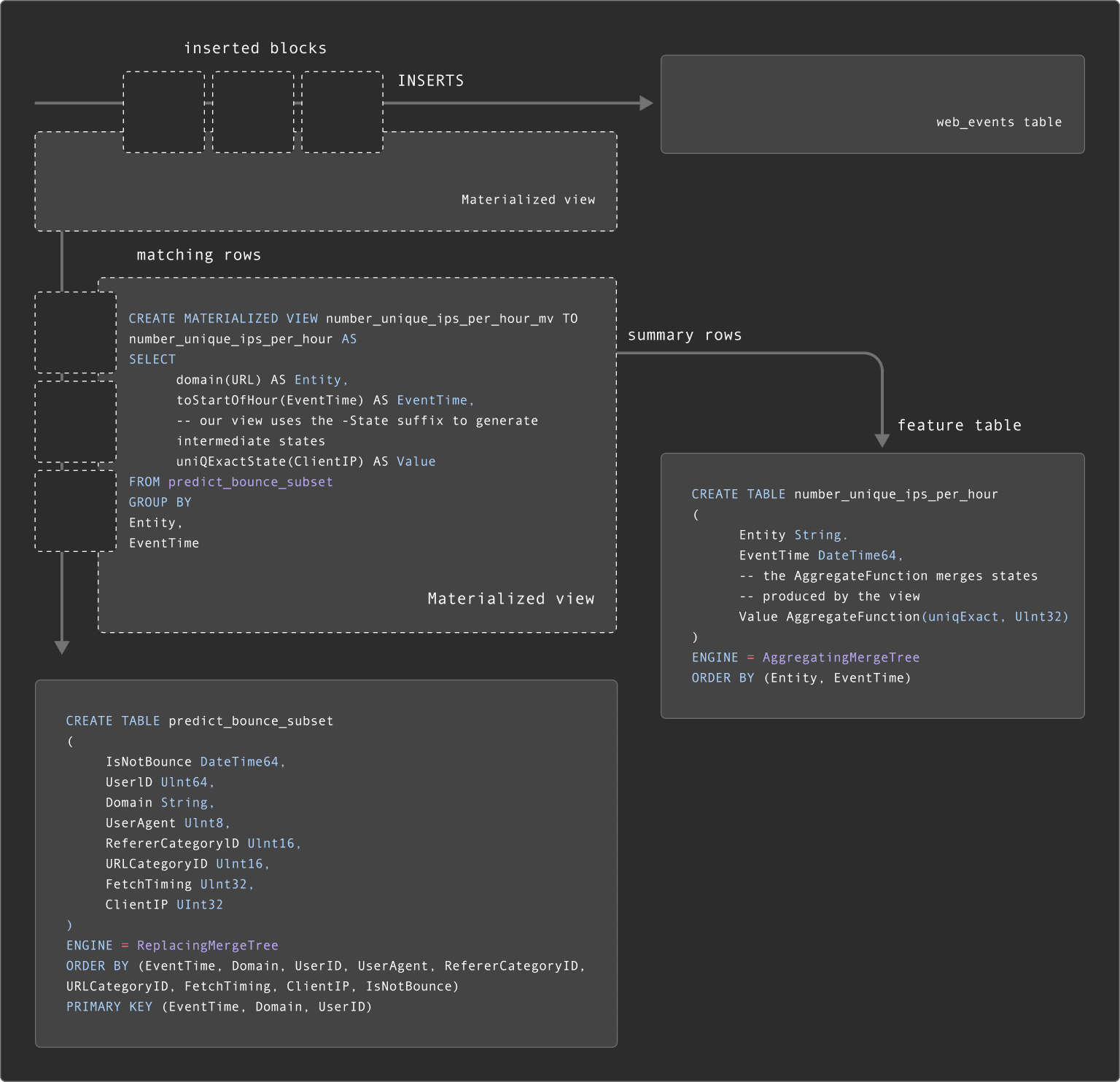
ただし、特徴量が集計結果の場合はクエリが複雑になり、結果を保持するテーブルではAggregatingMergeTreeとAggregateFunction型を使い、マテリアライズドビュー側では部分的な集計状態(*-State)を扱う必要があります。下記は「特徴量ごとテーブル(per feature)」でやる場合の例です。
CREATE TABLE number_unique_ips_per_hour
(
Entity String,
EventTime DateTime64,
Value AggregateFunction(uniqExact, UInt32)
)
ENGINE = AggregatingMergeTree
ORDER BY (Entity, EventTime)
CREATE MATERIALIZED VIEW number_unique_ips_per_hour_mv TO number_unique_ips_per_hour AS
SELECT
domain(URL) AS Entity,
toStartOfHour(EventTime) AS EventTime,
-- ビューでは-Stateを付けて部分集計状態を生成
uniqExactState(ClientIP) AS Value
FROM predict_bounce_subset
GROUP BY
Entity,
EventTime
こうすると、predict_bounce_subsetにデータが入るたびにこのテーブルが更新されます。ただし、問い合わせるときはFINAL句またはGROUP BY+uniqExactMerge(Value)を使って集計状態をマージする必要があります。例えば、以下のようにuniqExactMergeを使って実際の値を取得します。
-- 単一ドメインの値を取得するクエリ例
SELECT
EventTime,
Entity,
uniqExactMerge(Value) AS Value
FROM number_unique_ips_per_hour
WHERE Entity = 'smeshariki.ru'
GROUP BY
Entity,
EventTime
ORDER BY EventTime DESC LIMIT 5
┌───────────────EventTime─┬─Entity────────┬─Value─┐
│ 2013-07-31 23:00:00.000 │ smeshariki.ru │ 3810 │
│ 2013-07-31 22:00:00.000 │ smeshariki.ru │ 3895 │
│ 2013-07-31 21:00:00.000 │ smeshariki.ru │ 4053 │
│ 2013-07-31 20:00:00.000 │ smeshariki.ru │ 3893 │
│ 2013-07-31 19:00:00.000 │ smeshariki.ru │ 3926 │
└─────────────────────────┴───────────────┴───────┘
5 rows in set. Elapsed: 0.491 sec. Processed 8.19 thousand rows, 1.28 MB (16.67 thousand rows/s., 2.61 MB/s.)
Peak memory usage: 235.93 MiB.
このように部分集計状態を持っておくことで、後から「1日単位で見たい」といった別の集計も簡単に計算できます(クエリ側でさらにGROUP BYすればOK)。また、下図のように、predict_bounce_subsetを更新するマテリアライズドビューと、それをさらに参照するマテリアライズドビューを「連鎖」させるケースもあります。詳しくはこちらをご覧ください。
エンティティごとの特徴量テーブルを更新 #
「特徴量ごとテーブル」の場合、特徴量テーブルの数だけマテリアライズドビューが必要になるので、特徴量が10個を超えると挿入時の処理コストも上がってきます(1テーブルにつき1マテリアライズドビュー)。大量の特徴量を扱う場合にはスケーリング面で不向きです。
一方、「エンティティごとテーブル」方式だとテーブル数が減らせますが、VariantとAggregateFunctionを組み合わせた方法は現在サポートされていません。そこで選択肢となるのが「Refreshable Materialized Views (実験的機能)」です。これは従来のインクリメンタルなマテリアライズドビューとは異なり、定期的にビュークエリを全件実行し、ターゲットテーブルの内容をアトミックに置き換える仕組みです。

例えば、10分ごとに「ドメインごとのユニークIP数」を再計算するには、以下のように書きます。
-- 実験的機能を有効化
SET allow_experimental_refreshable_materialized_view = 1
CREATE MATERIALIZED VIEW domain_features_mv REFRESH EVERY 10 MINUTES TO domain_features AS
SELECT
Domain,
'number_unique_ips_per_hour' AS FeatureId,
toStartOfHour(EventTime) AS EventTime,
uniqExact(ClientIP) AS Value
FROM predict_bounce_subset
GROUP BY
Domain,
EventTime
Refreshable Materialized Viewの詳細はこちらで確認できます。
ステップ 4 – モデル用データの生成 #
特徴量の準備ができたら、これらを組み合わせてモデル用データを作ります。これがトレーニング・バリデーション・テストを作る基礎となるわけです。
このテーブルの各行が特徴量ベクトルに対応します。特徴量サブセットpredict_bounce_subsetに対して、作成した特徴量テーブルをJOINしていきます。
predict_bounce_subsetにはラベルやタイムスタンプ、エンティティキーがすでに入っています。これを左側のテーブルとして使い、必要な特徴量を結合するのが自然です。(また大抵の場合これが最大のテーブルなので、JOINの最適化の観点でも有利です)。
結合条件は以下の2つです:
- 同じエンティティキー(例:
UserIDやDomain) - なるべく近いタイムスタンプ(
EventTime)
この「同じキー + 時間で最も近い値」を実現するにはASOF JOINが必要です。最終的にはこの結果を「モデルテーブル」に格納し、そこから学習や検証用のデータを抽出する形をとります。まずはpredict_bounceというモデルテーブルを宣言してみましょう。
CREATE TABLE predict_bounce_model (
Row UInt64,
EventTime DateTime64,
UserID UInt64,
Domain String,
UserAgent UInt8,
RefererCategoryID UInt16,
URLCategoryID UInt16,
DomainsVisitedPerHour UInt32 COMMENT 'Number of domains visited in last hour by the user',
UniqueIPsPerHour UInt32 COMMENT 'Number of unique ips visiting the domain per hour',
AverageRequestTime Float32 COMMENT 'Average request time for the domain per hour',
IsNotBounce UInt8,
) ENGINE = MergeTree
ORDER BY (Row, EventTime)
ここでRow列を用意し、各行にユニークな値を持たせます。ORDER BYにはRowとEventTimeを組み込み、後述するトレーニング/テストセット分割時に使います。
特徴量の結合とアラインメント #
ASOF JOINでエンティティキーとタイムスタンプを突き合わせることで、必要な特徴量を紐づけます。「特徴量ごとテーブル」を使っているとして、以下の3つがあるとします。
number_unique_ips_per_hour
ドメインごとの1時間あたりのユニークIP数domains_visited_per_hour
ユーザーごとの1時間あたりの訪問ドメイン数average_request_time
ドメインごとの1時間あたりの平均リクエスト時間
単純化すれば、以下のように書けます。
INSERT INTO predict_bounce_model SELECT
rand() AS Row,
mt.EventTime AS EventTime,
mt.UserID AS UserID,
mt.Domain AS Domain,
mt.UserAgent,
mt.RefererCategoryID,
mt.URLCategoryID,
dv.Value AS DomainsVisitedPerHour,
uips.Value AS UniqueIPsPerHour,
art.Value AS AverageRequestTime,
mt.IsNotBounce
FROM predict_bounce_subset AS mt FINAL
ASOF JOIN domains_visited_per_hour AS dv ON (mt.UserID = dv.UserID) AND (mt.EventTime >= dv.EventTime)
ASOF JOIN number_unique_ips_per_hour AS uips ON (mt.Domain = uips.Domain) AND (mt.EventTime >= uips.EventTime)
ASOF JOIN average_request_time AS art ON (mt.Domain = art.Domain) AND (mt.EventTime >= art.EventTime)
0 rows in set. Elapsed: 13.440 sec. Processed 89.38 million rows, 3.10 GB (6.65 million rows/s., 230.36 MB/s.)
Peak memory usage: 2.94 GiB.
SELECT * FROM predict_bounce_model LIMIT 1 FORMAT Vertical
Row 1:
──────
Row: 57
EventTime: 2013-07-10 06:11:39.000
UserID: 1993141920794806602
Domain: smeshariki.ru
UserAgent: 7
RefererCategoryID: 16000
URLCategoryID: 9911
DomainsVisitedPerHour: 1
UniqueIPsPerHour: 16479
AverageRequestTime: 182.69382
IsNotBounce: 0
「エンティティごとテーブル」を使う場合は、FeatureIdでフィルタしてそれぞれサブクエリにして結合するので、もう少し複雑になります。下記は実行例です(多少時間はかかる可能性があります)。
INSERT INTO predict_bounce_model SELECT
rand() AS Row,
mt.EventTime AS EventTime,
mt.UserID AS UserID,
mt.Domain AS Domain,
mt.UserAgent,
mt.RefererCategoryID,
mt.URLCategoryID,
DomainsVisitedPerHour,
UniqueIPsPerHour,
AverageRequestTime,
mt.IsNotBounce
FROM predict_bounce_subset AS mt FINAL
ASOF LEFT JOIN (
SELECT Domain, EventTime, Value.UInt64 AS UniqueIPsPerHour
FROM domain_features
WHERE FeatureId = 'number_unique_ips_per_hour'
) AS df ON (mt.Domain = df.Domain) AND (mt.EventTime >= df.EventTime)
ASOF LEFT JOIN (
SELECT Domain, EventTime, Value.Float64 AS AverageRequestTime
FROM domain_features
WHERE FeatureId = 'average_request_time'
) AS art ON (mt.Domain = art.Domain) AND (mt.EventTime >= art.EventTime)
ASOF LEFT JOIN (
SELECT UserID, EventTime, Value.UInt64 AS DomainsVisitedPerHour
FROM user_features
WHERE FeatureId = 'domains_visited_per_hour'
) AS dv ON (mt.UserID = dv.UserID) AND (mt.EventTime >= dv.EventTime)
0 rows in set. Elapsed: 12.528 sec. Processed 58.65 million rows, 3.08 GB (4.68 million rows/s., 245.66 MB/s.)
Peak memory usage: 3.16 GiB.
なお、上記ASOF JOINはハッシュジョインを利用していますが、v24.7で
full_sorting_mergeアルゴリズムが追加され、ソートされたテーブルをマージする形でJOINを行う最適化が可能になりました。これにより事前ソートや大量のデータ処理が削減され、高速化とリソース削減が期待できます。
ステップ 5 – テストおよびトレーニング用データセットの生成 #
最終的に完成したモデルデータテーブルから、学習・バリデーション・テスト用にデータを分割します。例えば80%をトレーニング、10%をバリデーション、10%をテストとするなどです。ここで大事なのは、クエリを何度実行しても常に同じデータを取り出せるようにすること、そして行の順番や選択がぶれないことです。
この安定性と再現性を簡単に担保するために、先ほどのRow列やEventTime列が使えます。例えば80%をトレーニングデータにし、EventTime昇順で返したい場合、次のようなクエリが使えます。
SELECT * EXCEPT Row
FROM predict_bounce_model
WHERE (Row % 100) < 80
ORDER BY EventTime, Row ASC
これが常に同じ結果を返すことは、例えば以下のようにハッシュを取れば確認できます。
SELECT
groupBitXor(sub) AS hash,
count() AS count
FROM
(
SELECT sipHash64(concat(*)) AS sub
FROM predict_bounce_model
WHERE (Row % 100) < 80
ORDER BY
EventTime ASC,
Row ASC
)
┌─────────────────hash─┬────count─┐
│ 14452214628073740040 │ 34315802 │
└──────────────────────┴──────────┘
1 row in set. Elapsed: 8.346 sec. Processed 42.89 million rows, 2.74 GB (5.14 million rows/s., 328.29 MB/s.)
Peak memory usage: 10.29 GiB.
-- 同じクエリを再度実行 (省略)
┌─────────────────hash─┬────count─┐
│ 14452214628073740040 │ 34315802 │
└──────────────────────┴──────────┘
同様に、バリデーションやテストには以下のようなクエリが使えます。
-- validation
SELECT * EXCEPT Row
FROM predict_bounce_model
WHERE (Row % 100) BETWEEN 80 AND 89
ORDER BY EventTime, Row ASC
-- test
SELECT * EXCEPT Row
FROM predict_bounce_model
WHERE (Row % 100) BETWEEN 90 AND 100
ORDER BY EventTime, Row ASC
実際には時系列で分割してリークを防ぎたい場合もあるので、EventTimeをキーにするなど、運用に合わせて最適化してください。詳しくはこちらのOrdering Key選択に関するガイドも参考になります。
構築するか、導入するか #
ここまでのフローでは、マルチステップのクエリや複雑な処理が必要になっていることがわかります。ClickHouseを使ってオフライン特徴量ストアを構築する場合は、だいたい以下の3パターンに分かれます。
-
フルスクラッチで構築
データ構造や最適化を自社の要件に合わせて徹底的にチューニングしたい場合。広告テックのように特徴量ストアがビジネスの肝で超大規模データを扱う企業では、こうしたアプローチが選ばれます。 -
dbt + Airflow
dbtで複雑なクエリやデータモデリングを管理し、Airflowでワークフローをスケジューリングする構成。特徴量ストアをフルスクラッチで作るほどではないが、ある程度のカスタム要件に対応したい場合に最適です。
既存のフレームワークを使いながら大規模データと複雑なクエリをさばける点がバランスが良く、多くのエンジニアが利用しています。 -
既存の特徴量ストアを導入し、ClickHouseを連携
例としてFeatureformなどがClickHouseをバックエンドに利用し、特徴量の管理やバージョン管理、ガバナンス機能を提供しています。これらを利用すれば、データサイエンティスト側の負担が減り、ワークフローも標準化できるメリットがあります。
自社の要件とのマッチ度合いが導入判断のポイントになります。
 画像: Featureform Feature Store
画像: Featureform Feature Store
推論時における ClickHouse #
本記事ではClickHouseをオフラインストアとして使う話が中心でしたが、実際の運用フェーズでは学習済みモデルをデプロイして推論を行う際に、リアルタイムでユーザーIDやドメインなどの情報を参照する必要があります。「直近1時間の集計結果」などを推論のたびに計算するのは重すぎるので、何らかの形で事前に特徴量を用意しておき、それを即座に参照できるようにする「オンラインストア」的な使い方が必要です。
ClickHouseはリアルタイム分析DBとして高い同時実行性能と低レイテンシ、書き込み処理の多さにも対応できるので、こうしたオンライン特徴量ストアにも利用可能です。オフラインで計算した特徴量をそのまま同じクラスタか別のインスタンスに移して利用するといったフローも十分実現可能です。詳細は別記事で解説予定です。
結論 #
本記事では、ClickHouseを使ったオフライン特徴量ストア&変換エンジンの代表的なデータモデリング手法を紹介しました。実際にはここで挙げた以外にもさまざまな方法がありますが、本記事の内容はFeatureformなどClickHouseと連携する特徴量ストアで一般的に採用されているやり方に近いものです。もし「自分はこうやって運用している」「こういう改善案がある」という方がいれば、ぜひ教えてください。
ClickHouseで機械学習用データをモデリングし、パイプラインを高速化しながら、数十億行レベルのデータに対してもすばやく特徴量を作り上げる方法をぜひ試してみてください。



