trip.com では、ホテルや航空券の予約、観光地、ツアーパッケージ、ビジネストラベル管理、旅行コンテンツなど、幅広いデジタルサービスを提供しています。おそらくお察しの通り、拡張性があり、堅牢で高速なログプラットフォームが必要であり、それが運用の健全性を保つ鍵となっています。
始める前に、少し興味を引くために、ClickHouseの上に構築したプラットフォームを示すいくつかの数字をご覧いただきます:
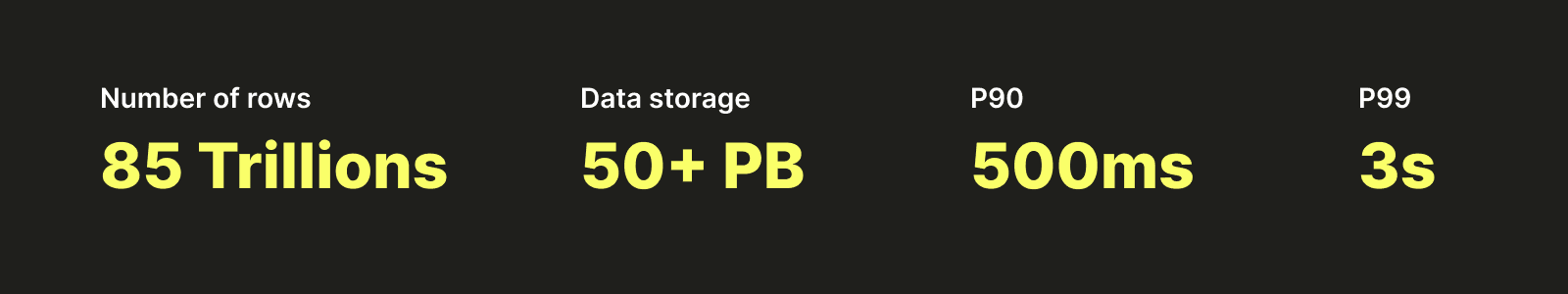
このブログ記事では、ログプラットフォームのストーリー、初めて構築した理由、使用した技術、そしてSharedMergeTreeといった機能を活用するClickHouseの上での今後の計画についてご紹介します。
以下は、私たちが旅を通して触れるさまざまなトピックです:
- 中央集約型ログプラットフォームをどのように構築したか
- ログプラットフォームをどのように拡張し、ElasticsearchからClickHouseに移行したか
- 運用体験をどのように改善したか
- AlicloudでどのようにClickHouse Cloudをテストしたか
簡単にするために、タイムラインにまとめてみましょう:

中央集約型ログプラットフォームの構築 #
すべての偉大なストーリーは偉大な問題から始まりますが、私たちのプロジェクトも2012年以前には trip.com に統一された中央集約型のログプラットフォームがなかったために始まりました。各チームや事業ユニット(BU)が自分たちのログを収集し管理している状態で、以下のような多くの課題が存在しました:
- これらの環境を開発、維持、運用するために多くの人手が必要で、そのために多くの重複した努力が必要でした。
- データガバナンスとコントロールが複雑化しました。
- 会社内での統一された標準がありませんでした。
このことから、中央集約型で統一されたログプラットフォームを構築する必要があることがわかりました。
2012年、私たちは最初のプラットフォームを立ち上げました。それはElasticsearchの上に構築され、ETL、ストレージ、ログアクセス、およびクエリの標準を定義し始めました。
現在はもうElasticsearchはログプラットフォームには使用していませんが、どのように私たちのソリューションを実装したか調べる価値があります。このことが、後にClickHouseに移行する際に考慮しなければならなかった多くのその後の作業につながりました。
ストレージ #
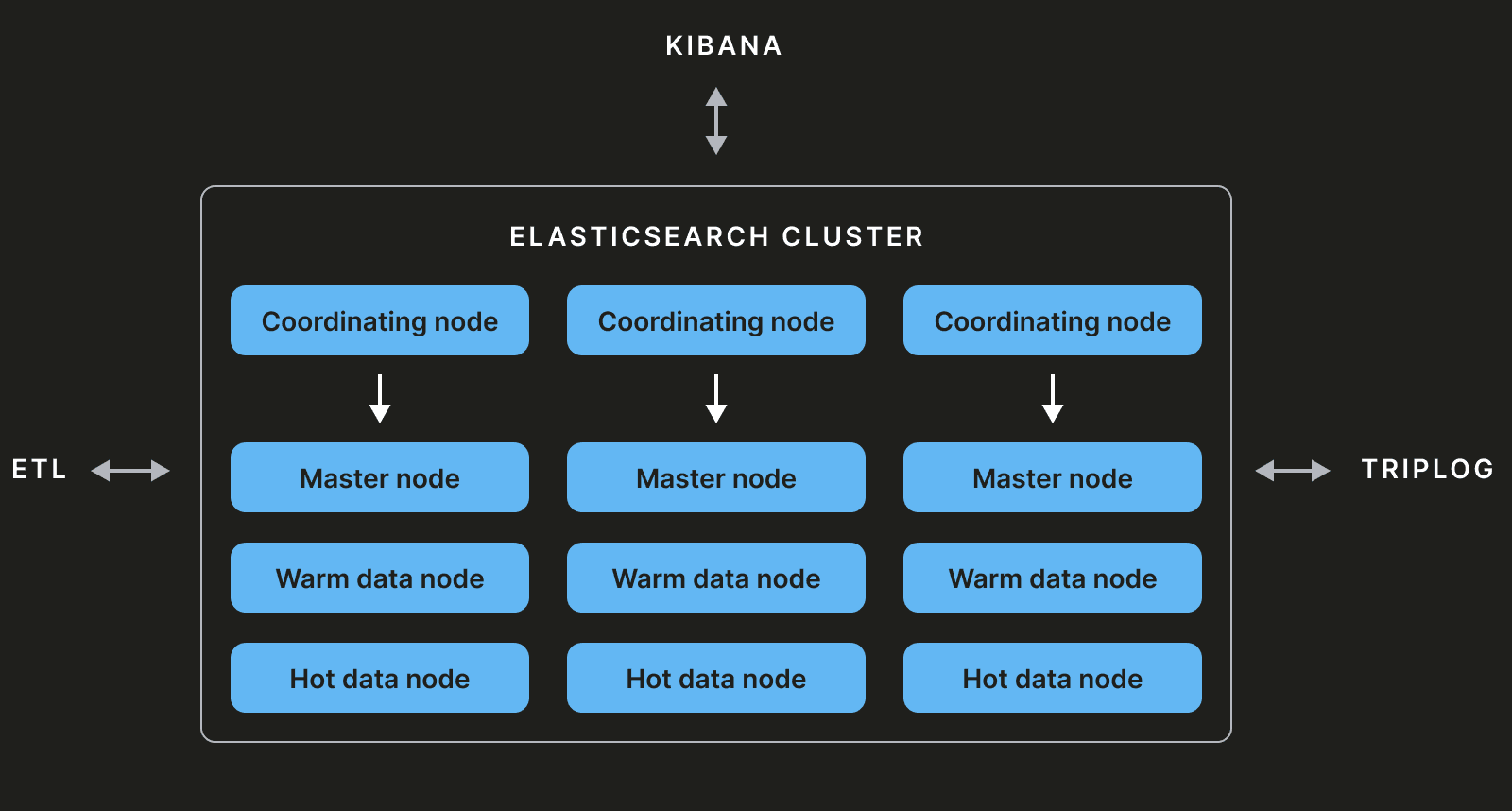
私たちのElasticsearchクラスターは主にマスターノード、コーディネーターノード、およびデータノードで構成されています。
マスターノード #
すべてのElasticsearchクラスターは少なくとも3つのマスター候補ノードで構成されます。これらのうち1つがマスターに選出され、クラスター状態を維持する責任を持ちます。クラスター状態は、様々なインデックス、シャード、レプリカなどの情報を含むメタデータです。クラスター状態を変更する操作は、マスターノードによって実行されます。
データノード #
データノードはデータを保存し、CRUD操作を実行するために使用されます。これらは複数のレイヤーに分割することができます:ホット、ウォームなど。
コーディネーターノード #
このタイプのノードは、(マスター、データ、インジェスト、トランスフォームなどの)他の機能を持たず、クラスター状態を考慮したスマートな負荷分散装置として機能します。コーディネーターがCRUD操作を伴うクエリを受け取ると、それはデータノードに送信されます。または、インデックスを追加または削除するクエリを受け取ると、それはマスターノードに送信されます。
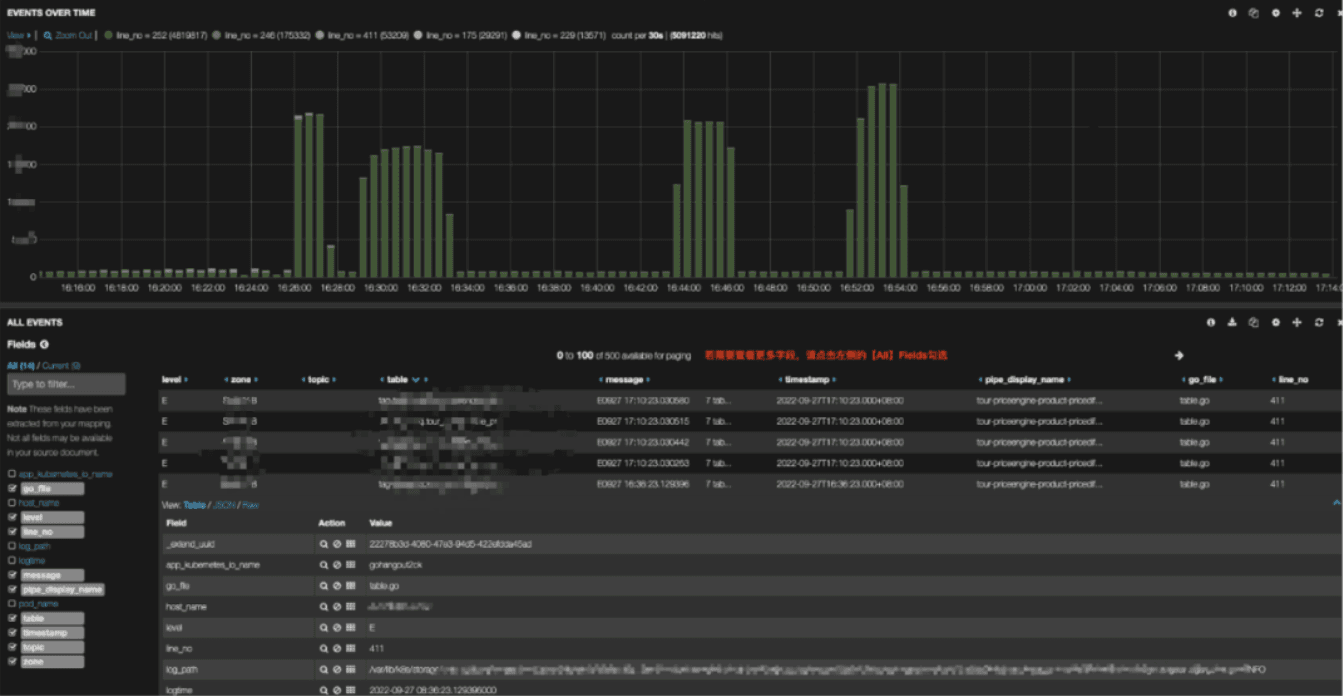
可視化 #
Elasticsearchの上に、可視化層としてKibanaを使用しました。下記に可視化の例を示します:
データ挿入 #
私たちのユーザーには、ログをプラットフォームに送信するための2つのオプションがあります:Kafka経由とエージェント経由です。
Kafka経由 #
最初の方法は、会社のフレームワークTripLogを使ってデータをKafkaメッセージブローカーにインジェストすることです(Hermesを使用)。
private static final Logger log = LoggerFactory.getLogger(Demo.class);
public void demo (){
TagMarker marker = TagMarkerBuilder.newBuilder().scenario("demo").addTag("tagA", "valueA").addTag("tagA", "valueA").build();
log.info(marker, "Hello World!");
}
これにより、ユーザーはログを容易にプラットフォームに送信するためのフレームワークを得られます。
エージェント経由 #
もう一つのアプローチは、Filebeat、Logstash、Logagent、またはカスタムクライアントなどのエージェントを使用して直接Kafkaに書き込むことです。以下はFilebeatの設定例です:
filebeat.config.inputs:
enabled: true
path: "/path/to/your/filebeat/config"
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/history.log
- /var/log/auth.log
- /var/log/secure
- /var/log/messages
harvester_buffer_size: 102400
max_bytes: 100000
tail_files: true
fields:
type: os
ignore_older: 30m
close_inactive: 2m
close_timeout: 40m
close_removed: true
clean_removed: true
output.kafka:
hosts: ["kafka_broker1", "kafka_broker2"]
topic: "logs-%{[fields.type]}"
required_acks: 0
compression: none
max_message_bytes: 1000000
processors:
- rename:
when:
equals:
source: "message"
target: "log_message"
ETL #
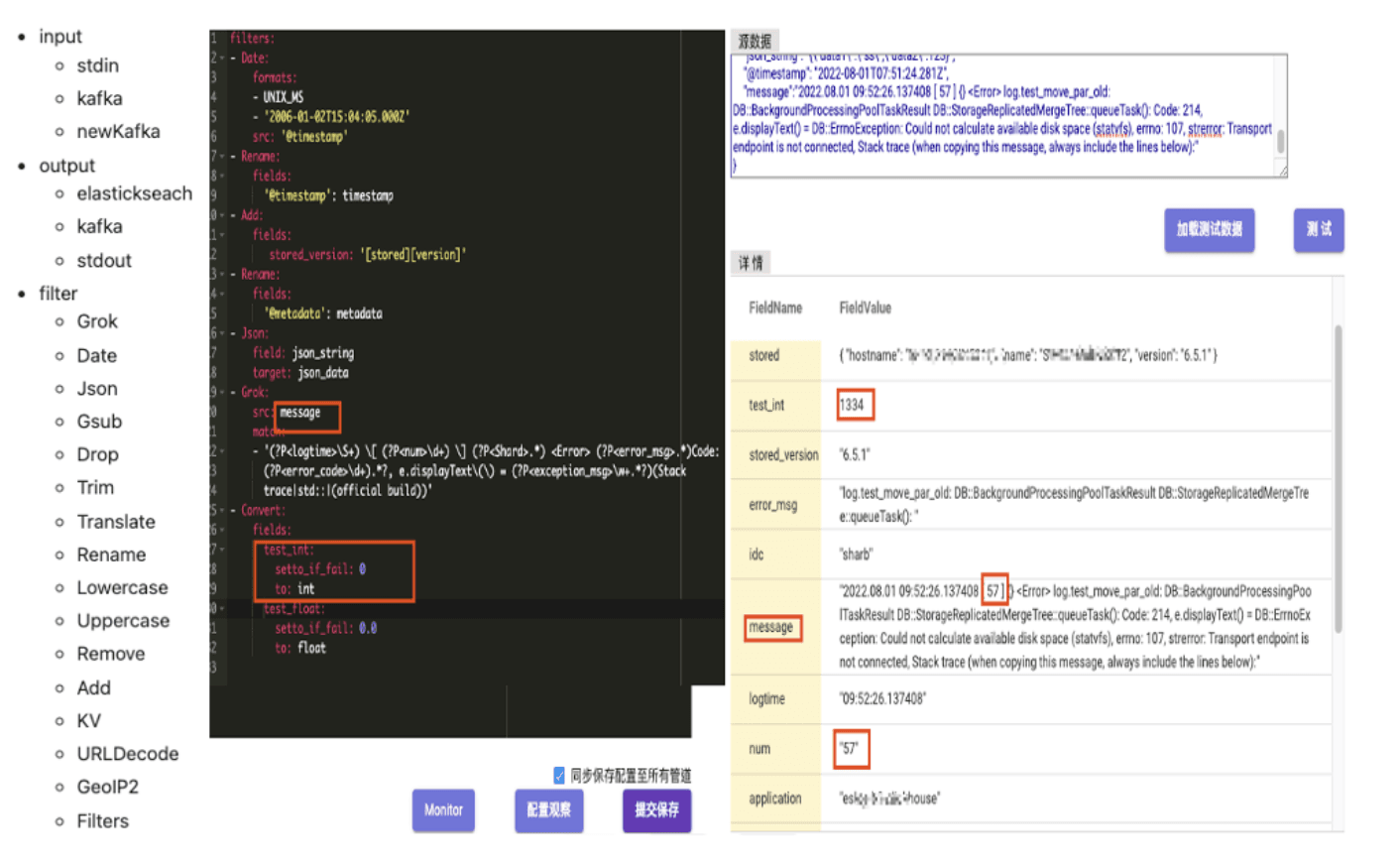
ユーザーが選択したアプローチにかかわらず、データはKafkaに入った後、gohangoutを用いてElasticsearchにパイプライン化されます。
Gohangoutは、Logstashの代替として trip.com によって開発され、維持されているオープンソースのアプリケーションです。Kafkaからデータを消費し、ETL操作を行い、最終的にからのデータを様々なストレージ媒体(ClickHouseやElasticsearchなど)に出力することを設計しています。フィルターモジュールでのデータ処理には、データクリーニング用の共通機能が含まれており、JSON処理、Grokパターンマッチング、時間変換(以下に示されています)が行われます。以下の例で、GoHangoutはMessageフィールドからnumデータを正規表現マッチングを使用して抽出し、別のフィールドとして保存します。
ガラスの天井に到達する #
多くの人々はオブザーバビリティのためにElasticsearchを使用しており、そのデータ量が小さい場合には力を発揮します。使いやすいソフトウェア、スキーマレスな体験、幅広い機能、Kibanaによる人気のUIを提供します。しかし、我々の規模でデプロイすると、よく知られている課題に直面します。
Elasticsearchに4PBのデータを保存しているときに、以下のようなクラスターの安定性に関する複数の問題に直面し始めました:
- クラスターへの高負荷が多くのリクエスト拒否、書き込み遅延、遅いクエリを引き起こしました
- ホットノードからコールドノードへの1日200TBのデータ移行が大きなパフォーマンス低下をもたらしました
- シャードの割り当てが困難で、一部のノードが圧倒されました
- 大規模クエリはメモリ不足(OOM)例外を引き起こしました。
クラスターのパフォーマンスについても:
- クエリ速度は全体的なクラスター状態に影響を受けました
- インジェスト時の高いCPU使用量のせいで挿入スループットを増やすことが難しかったです
そして最後に、コストに関して:
- データのボリューム、データ構造、および圧縮の欠如が高いストレージ要求を引き起こしました
- 圧縮率が低いため、業務上の影響があり、保有期間を小さくせざるを得ませんでした
- Elasticsearchが原因で発生するJVMとメモリの限界がTCO(総所有コスト)を上昇させました
これらの問題を認識した後、私たちは代替案を探し始め、そしてClickHouseが登場しました!
ClickHouse vs Elasticsearch #
ElasticsearchとClickHouseにはいくつかの基本的な違いがあり、それらを見ていきましょう。
Query DSL vs SQL #
ElasticsearchはQuery DSL(Domain Specific Language)と呼ばれる特定のクエリ言語に依存しています。今ではより多くのオプションがありますが、これがメインの構文です。一方のClickHouseはSQLに依存しており、極めて主流で、非常にユーザーフレンドリーで、さまざまな統合やBIツールに対応しています。
内部構造 #
ElasticsearchとClickHouseは内部挙動にいくつかの類似点がありますが、Elasticsearchはセグメントを生成し、ClickHouseはパーツを書き込みます。どちらも時間とともに非同期で統合され、より大きなパーツとセグメントを作成しますが、ClickHouseは列指向モデルであり、そのデータはORDER BYキーによりソートされます。これにより、素早いフィルタリングと高圧縮率による効率的なストレージ使用が可能なスパースインデックスを構築できます。このインデックスメカニズムについてはこのガイドをご覧ください。
インデックス vs テーブル #
Elasticsearchではデータはインデックスに保存され、シャードに分割されます。これらは比較的小さなサイズ範囲(私たちの時点では推奨はシャードごとに約50GBでした)に保たれる必要があります。対照的に、ClickHouseのデータはテーブルに保存され、TB単位またはそれ以上の大きさにすることができます。さらに、ClickHouseはパーティションキーを作成することができ、物理的にデータを異なるフォルダに分けます。必要に応じてこれらのパーティションを効率的に操作することができます。
全体として、ClickHouseの機能と特性に感銘を受けました。それには、列指向ストレージ、ベクトル化クエリ実行、高圧縮率、高挿入スループットがあります。これらは、私たちのログソリューションが求めるパフォーマンス、安定性、費用対効果を満たすものでした。そのため、私たちはClickHouseを使ってストレージとクエリ層を置き換えることを決定しました。
次の課題は、サービスを中断せずにどのようにして1つのストレージから他のストレージにシームレスに移行するかでした。
Logs 2.0: ClickHouseへの移行 #
ClickHouseへの移行を決定した際に、いくつかの異なるタスクを特定しました:
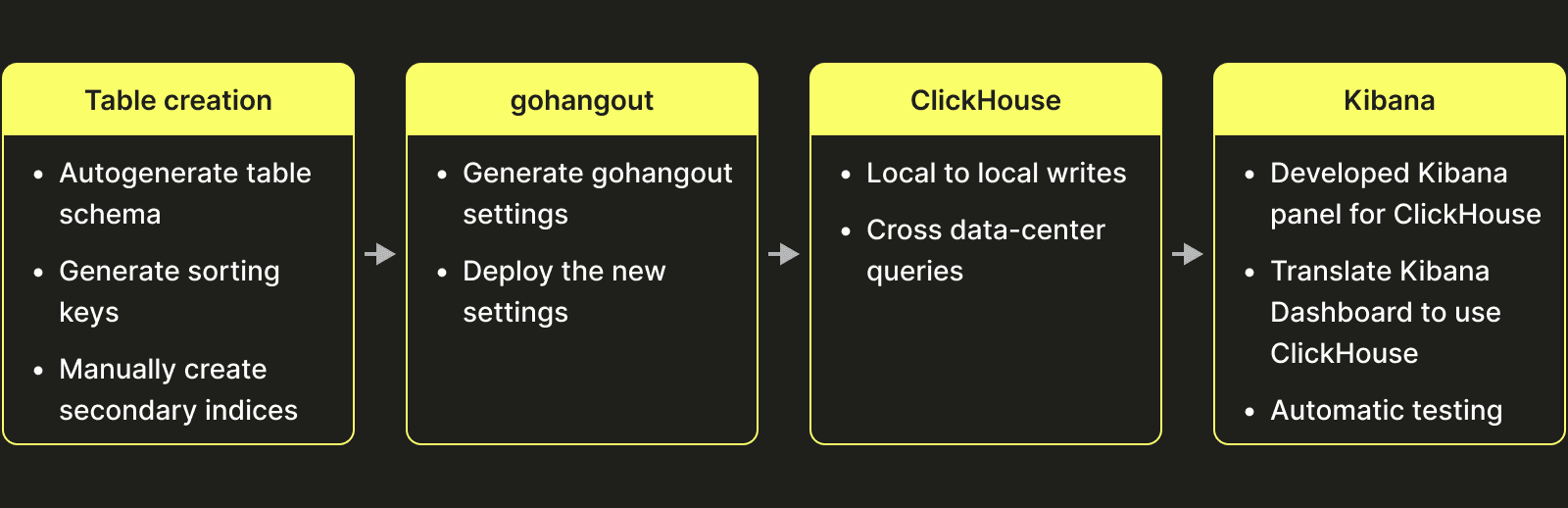
テーブル設計 #
これは、最終的に設計した初期のテーブル設計です(数年前のものであり、現在のClickHouseには存在するデータ型がすべて揃っていません。例えばマップなど):
CREATE TABLE log.example
(
`timestamp` DateTime64(9) CODEC(ZSTD(1)),
`_log_increment_id` Int64 CODEC(ZSTD(1)),
`host_ip` LowCardinality(String) CODEC(ZSTD(1)),
`host_name` LowCardinality(String) CODEC(ZSTD(1)),
`log_level` LowCardinality(String) CODEC(ZSTD(1)),
`message` String CODEC(ZSTD(1)),
`message_prefix` String MATERIALIZED substring(message, 1, 128) CODEC(ZSTD(1)),
`_tag_keys` Array(LowCardinality(String)) CODEC(ZSTD(1)),
`_tag_vals` Array(String) CODEC(ZSTD(1)),
`log_type` LowCardinality(String) CODEC(ZSTD(1)),
...
INDEX idx_message_prefix message_prefix TYPE tokenbf_v1(8192, 2, 0) GRANULARITY 16,
...
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/example', '{replica}')
PARTITION BY toYYYYMMDD(timestamp)
ORDER BY (log_level, timestamp, host_ip, host_name)
TTL toDateTime(timestamp) + toIntervalHour(168)
- 動的に変化するタグを保存するためにデュアルリストアプローチを採用しています(将来的にはマップを使用する予定です)。つまり、2つの配列にキーと値を分けて保存しています。
- データの操作を容易にするために、日別のパーティション分けを行っています。私たちのデータ量では、日別のパーティション分けが理にかなっていますが、多くの場合には月次または週次のパーティショニングの方が適しています。
- クエリで使用するフィルターに応じて、上記のテーブル以上の
ORDER BYキーを持つことをお勧めします。上記のキーは、log_levelとtimeを使用するクエリに最適化されています。たとえば、クエリがlog_levelを利用していない場合、キーにはtimeカラムのみを含めることが理にかなっています。 - Tokenbf_v1 Bloomフィルターを利用して、用語クエリやファジークエリを最適化します。
- _log_increment_idカラムは、効率的なスクロールページネーションと正確なデータ位置決めを可能にするグローバルに一意のインクリメンタルIDを含んでいます。
- ZSTDデータ圧縮方式により、40%以上のストレージコストを削減しています。
クラスターセットアップ #
Elasticsearchでの歴史的なセットアップと経験を踏まえ、同様のアーキテクチャを複製することに決めました。我々のClickHouse-KeeperインスタンスはElasticsearchにおけるマスターノードと同様に機能します。データを保持せず、分散テーブルがClickHouseサーバーを指すクエリノードを複数展開しました。これらのサーバーはデータノードをホストしデータを保存し書き込みます。以下の図が我々のアーキテクチャの最終的な形です:
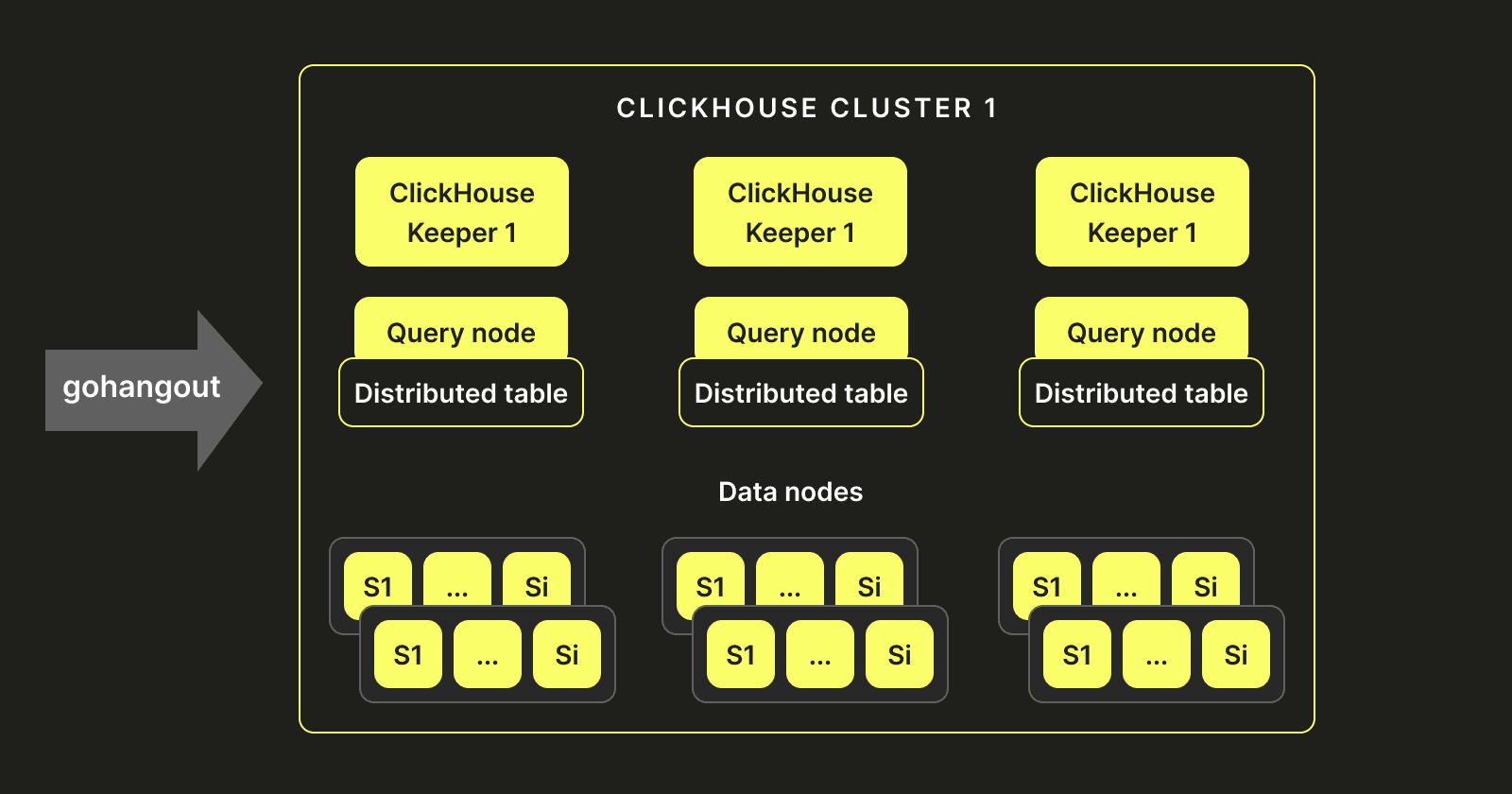
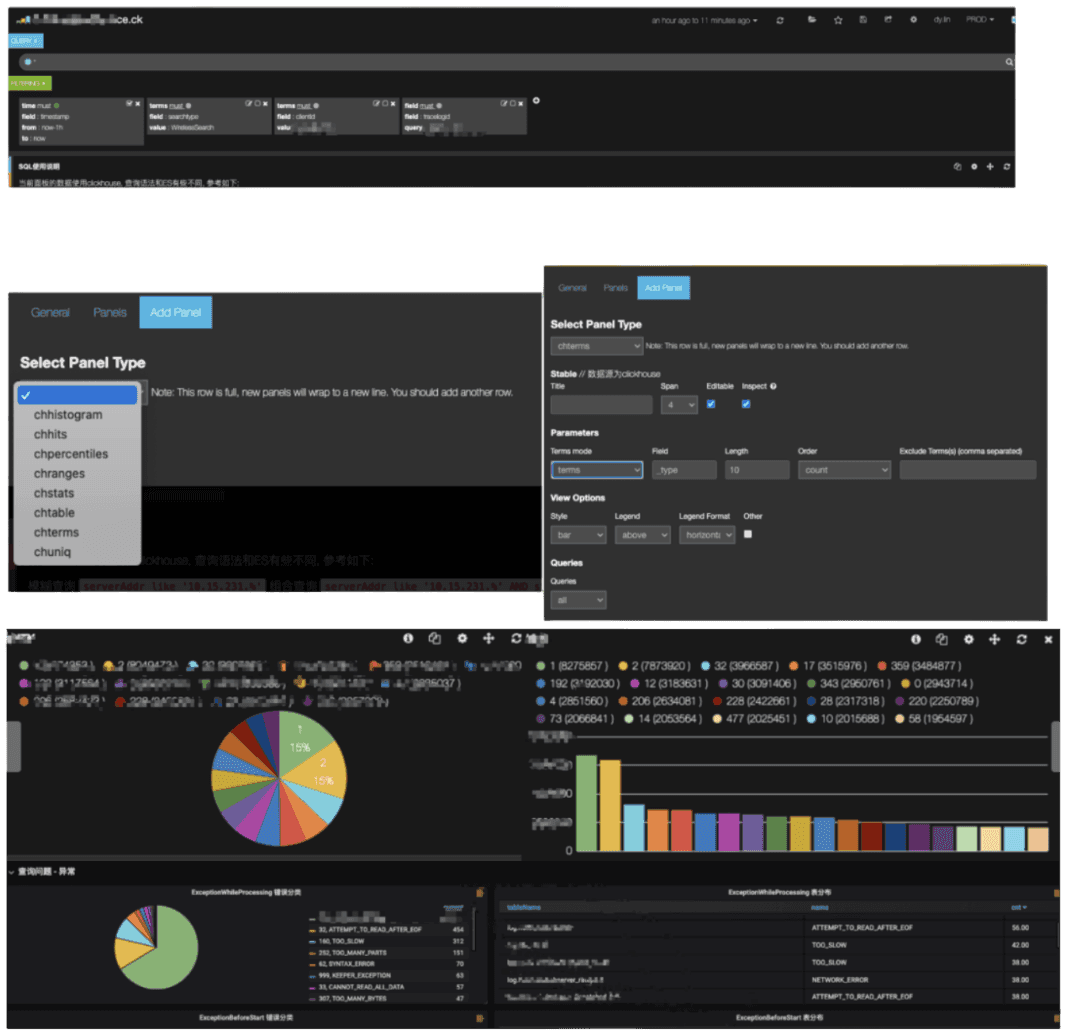
データ可視化 #
ClickHouseに移行した後も、ユーザーにシームレスな体験を提供したかったため、ユーザーのすべての可視化とダッシュボードがClickHouseを利用できるようにする必要がありました。これは課題であり、KibanaはもともとElasticsearch上で開発されたツールで、追加のストレージエンジンをサポートしていません。そのため、ClickHouseとインターフェースできるようにKibanaをカスタマイズする必要がありました。これには、ClickHouseで使用できる新しいデータパネルをKibanaに作成する必要がありました:chhistogram, chhits, chpercentiles, chranges, chstats, chtable, chterms, そして chuniq。
私たちは、既存のKibanaダッシュボードの95%をClickHouseで使用できるようにするスクリプトを作成し、最終的にKibanaを強化してユーザーがSQLクエリを書くことができるようにしました。
Triplog #
我々のログパイプラインはセルフサービスで、ユーザーはログを送信できます。これらのユーザーは、インデックスを作成し、所有権、権限、TTLポリシーを定義できる必要があります。そのため、ユーザーがテーブル、ユーザー、役割を管理し、データフローを監視し、アラートを作成できるインターフェースを提供するプラットフォームTriplogを作成しました。
振り返り #
すべての移行が完了した今、新しいプラットフォームのパフォーマンスを確認する時です。 95%の移行を自動化しシームレスな移行を達成しましたが、成功指標に戻り、新しいプラットフォームがどのように機能しているかを確認することが重要です。最も重要なのはクエリパフォーマンスと総所有コスト(TCO)でした。
総所有コスト(TCO) #
元々のコストの大部分はストレージでした。ElasticsearchとClickHouseで同じデータサンプルを用いたストレージを比較してみましょう:
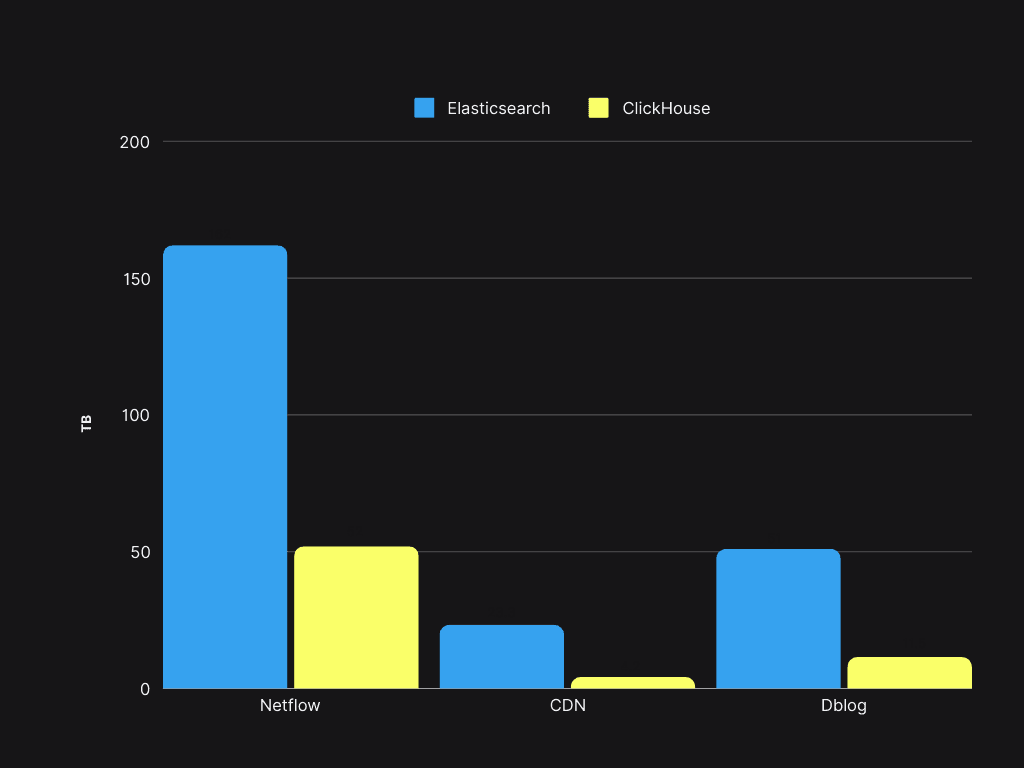
ストレージスペースの節約は50%以上に達し、既存のElasticsearchサーバーでClickHouseを用いてデータ量を4倍に増やせるようになりました。
クエリパフォーマンス #
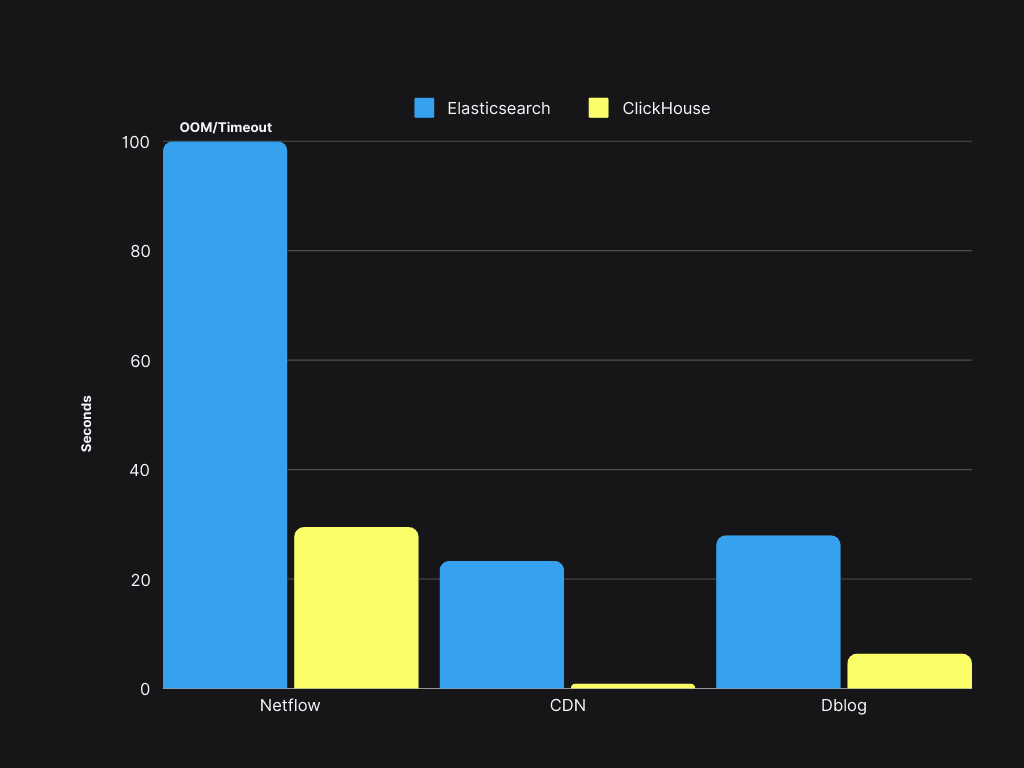
クエリの速度はElasticSearchよりも4倍から30倍速く、P90は300ms未満、P99は1.5秒未満です。
ログ3.0: ClickHouseベースのプラットフォームの改善 #
2022年にElasticsearchからの移行を完了して以来、より多くのログ用途をプラットフォームに追加し、4PBから20PBに成長しました。そして30PBに向けてさらに成長し拡大するにつれて、新たな課題に直面しました。
パフォーマンスと機能上の課題 #
- この規模の単一のClickHouseクラスタは管理が難しいです。デプロイメント時にClickHouse-KeeperやSharedMergeTreeがなく、Zookeeper周りでパフォーマンスの課題に直面し、DDLタイムアウトの例外が発生しました。
- ユーザーによる不適切なインデックスの選択が、サブオプティマルなクエリパフォーマンスを引き起こし、スキーマを改善してデータを再挿入する必要がありました。
- 不適切で最適化されていないクエリがパフォーマンスの問題を引き起こしました。
運用上の課題 #
- クラスタの構築はAnsibleに依存しているため、デプロイメントサイクルが長くなります(数時間)。
- 現在のClickHouseインスタンスはコミュニティバージョンから数バージョン遅れており、現在のクラスタデプロイメントモードは更新を行うのに不便です。
上述したパフォーマンスの課題に対処するため、まず単一クラスタのアプローチを避けました。我々の規模では、SharedMergeTreeやClickHouse Keeperなしでメタデータの管理が困難となり、ZookeeperのボトルネックのためにDDLステートメントのタイムアウトが発生していました。そのため、単一のクラスタを維持する代わりに、以下のように複数のクラスタを作成しました:
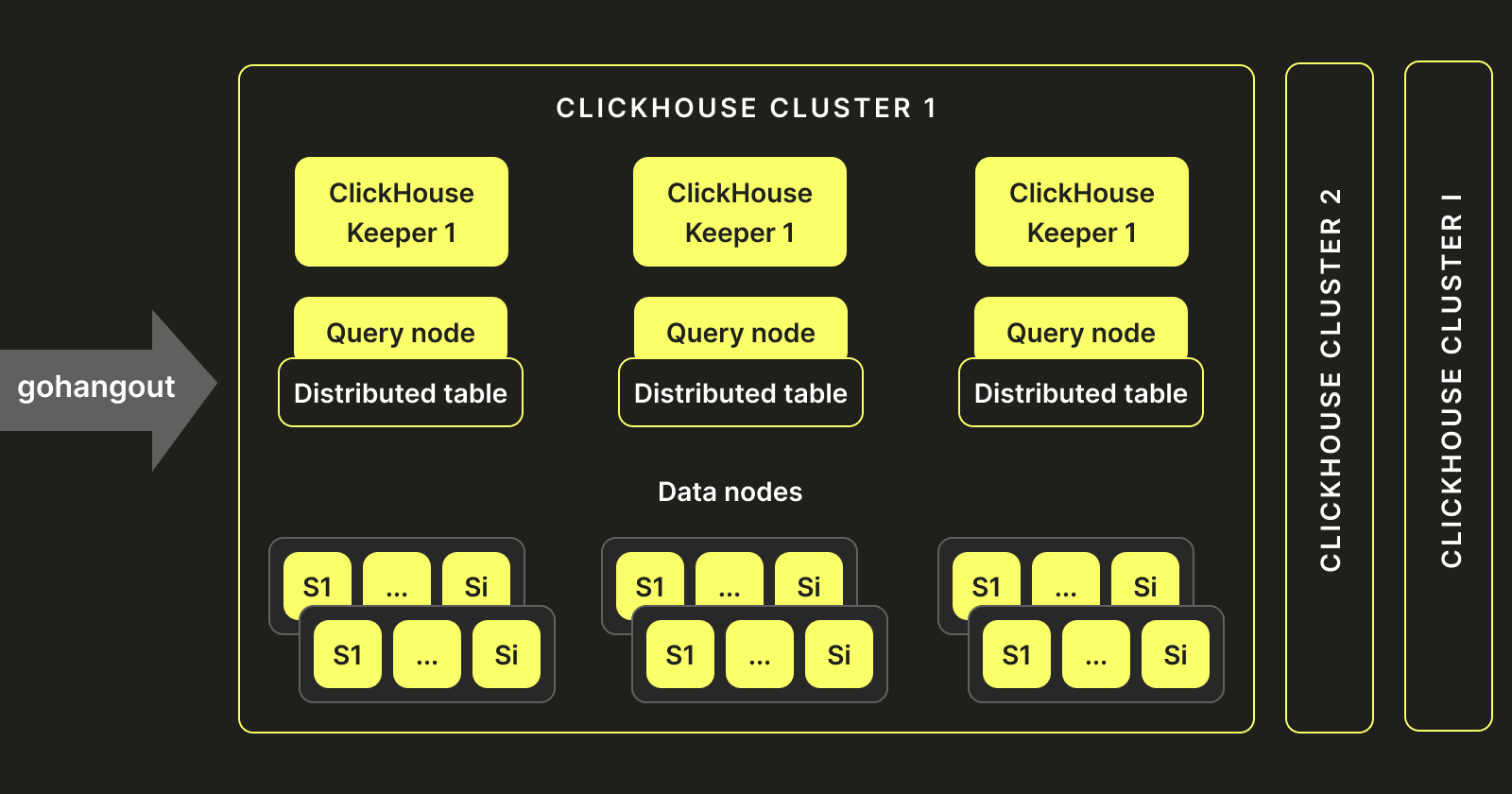
この新しいアーキテクチャは、Zookeeperの制約を克服しつつスケールアップを可能にしました。これらのクラスタをKubernetesにデプロイし、StatefulSets、アンチアフィニティ(非親和性)、ConfigMapsを使用しています。このアプローチにより、単一クラスタの配信時間は2日から5分に短縮されました。同時に、デプロイメントのアーキテクチャを標準化し、グローバルな複数環境でのデプロイメントプロセスを簡略化しました。このアプローチにより、運用コストを大幅に削減し、上述した方法の実装を支援しました。
クエリルーティング #
上述の問題を解決したにもかかわらず、ユーザーから特定のクラスタにクエリをどのように割り当てるかという新たな複雑さが導入されました。
例を用いて説明します:
3つのクラスタ:クラスタ1、クラスタ2、クラスタ3、および3つのテーブル:A、B、Cがあると仮定します。以下で説明する仮想テーブルパーティショニング手法を実装する前は、単一のテーブル(例えばA)は1つのデータクラスタ(例:クラスタ1)にしか存在できませんでした。この設計上の制約により、クラスタ1のディスクスペースが一杯になると、テーブルAのデータをクラスタ2の比較的空のディスクスペースに移行する迅速な方法がありませんでした。代わりに、2重書き込みを使用して、テーブルAのデータをクラスタ1とクラスタ2に同時に書き込む必要がありました。その後、クラスタ2のデータが期限切れ(例:7日後)になると、クラスタ1からテーブルAのデータを削除することができました。このプロセスは煩雑で遅く、クラスタを管理するために多大な手作業が必要でした。
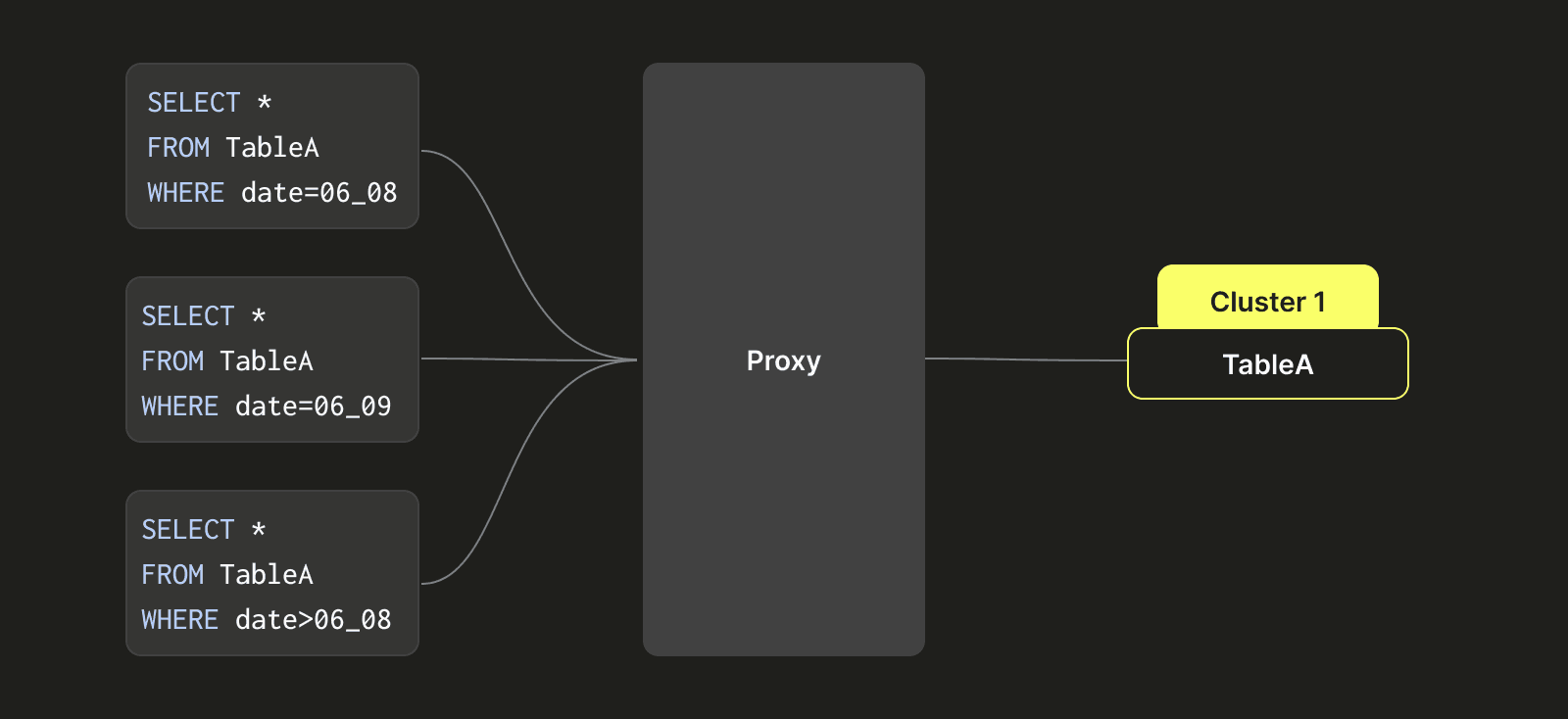
この問題に対処するため、テーブルAを複数のクラスタ(クラスタ1、クラスタ2、クラスタ3)の間で移動できるようにするクラスライクなパーティショニングアーキテクチャを設計しました。変換後の右側に示されているように、テーブルAのデータは時間間隔に基づいてパーティショニングされています(秒単位で正確にすることもできますが簡単にするためここでは日を例としています)。例えば、6月8日分のデータはクラスタ1に書き込まれ、6月9日分のデータはクラスタ2に書き込まれ、8月10日分のデータはクラスタ3に書き込まれます。6月8日のデータにクエリがアクセスするときは、クラスタ1のデータだけをクエリします。6月9日と10日のデータが必要な時は、クラスタ2とクラスタ3のデータを同時にクエリします。
この機能は、異なる分散テーブルを設定することで実現され、その各テーブルは特定の時間期間のデータを表し、各分散テーブルはクラスタの論理的な組み合わせ(例:クラスタ1、クラスタ2、クラスタ3)に関連付けられます。このアプローチにより、テーブルがクラスタをまたぐ問題を解決し、異なるクラスタ間のディスク使用率がより均等になる傾向があります。
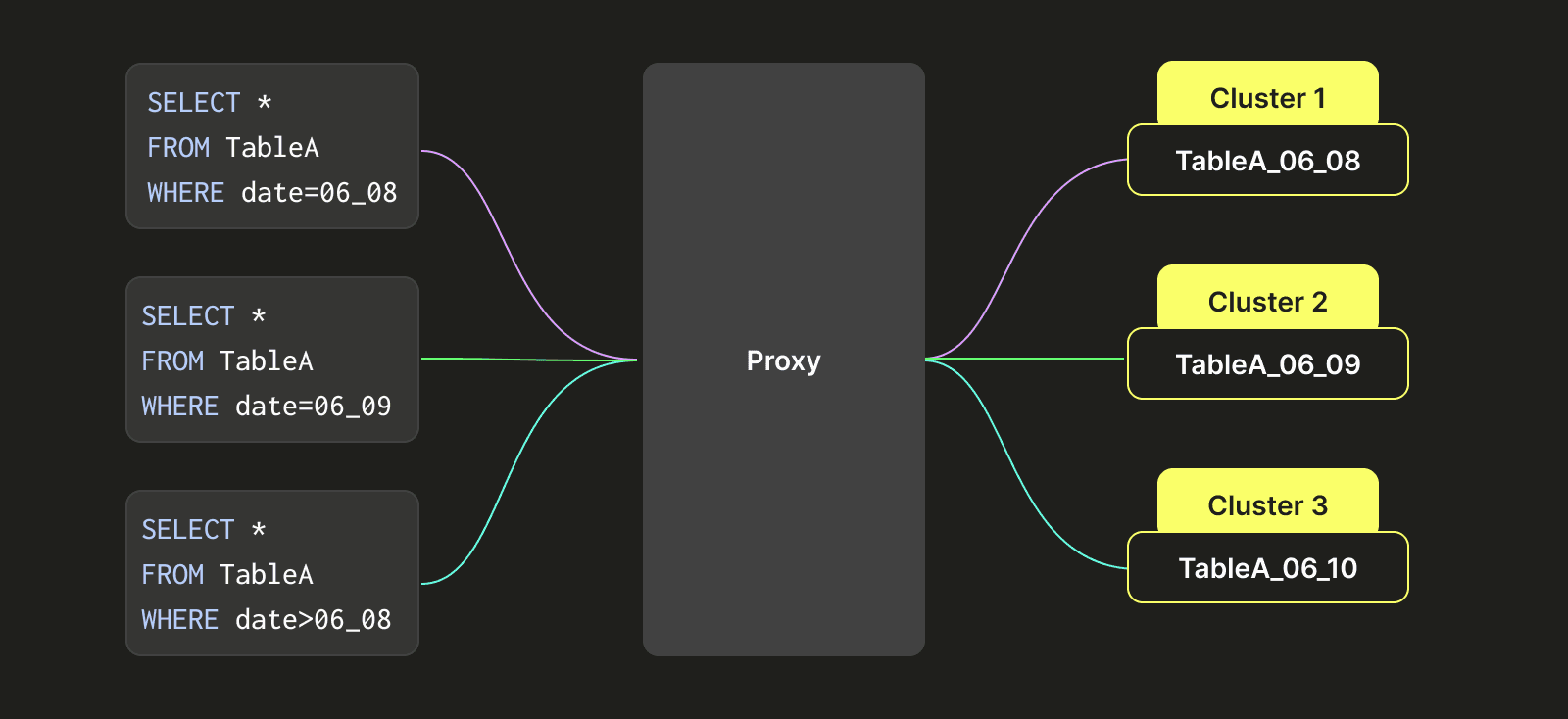
上の画像でわかるように、各クエリはWHERE句に基づいて、プロキシによって必要なテーブルを含む適切なクラスタに賢くリダイレクトされます。
このアーキテクチャは時間の経過に伴うスキーマの進化にも役立ちます。カラムを追加したり削除したりすることができるため、いくつかのテーブルはより多くまたは少ないカラムを持つことがあります。このルーティングは、クエリに必要なカラムを含まないテーブルをフィルタリングするプロキシと共に、カラムレベルで適用できます。
さらに、このアーキテクチャは進化するORDER BYキーのサポートにも役立ちます。通常、ClickHouseではORDER BYキーを動的に変更することはできません。上記のアプローチでは、新しいテーブルでORDER BYキーを変更し、古いテーブルを期限切れにするだけです(有効期限 (TTL)により)。
Antlr4によるSQLパース #
クエリ層では、Antlr4技術を使用してユーザーのSQLクエリを抽象構文木(AST)に解析しています。ASTツリーを用いることで、SQLクエリからテーブル名、フィルター条件、集計次元などの情報を迅速に取得できます。この情報を手に入れることで、データの統計、クエリのリライト、ガバナンスフロー制御など、SQLクエリに対してリアルタイムでターゲットとなる戦略を簡単に実装することができます。

すべてのユーザーSQLクエリに対して統一されたクエリゲートウェイプロキシを実装しました。このプログラムはメタデータ情報とポリシーに基づいてユーザーSQLクエリをリライトし、正確なルーティングや自動パフォーマンス最適化などの機能を提供します。さらに、各クエリの詳細なコンテキストを記録し、クラスタークエリの統一ガバナンスに使用され、QPS、大規模テーブルスキャン、クエリ実行時間に制限を課し、システムの安定性を向上させます。
私たちのプラットフォームの未来は? #
私たちのプラットフォームは40PB以上の規模で実証されていますが、まだ改善すべきことがたくさんあります。特に、休暇期間などの高いピーク使用時にもっとダイナミックにスケーラブルになることを望んでいます。この成長を扱うため、ClickHouse Enterprise Service(Alibaba Cloud経由)を検討し、SharedMergeTreeテーブルエンジンを導入しました。これにより、ストレージとコンピュートのネイティブな分離を提供し、この新しいアーキテクチャで、trip.com 内でのより多くのログ用例をサポートするためにほぼ無制限のストレージを提供できるようになります。
Alibaba Cloudで提供されるClickHouse Enterprise Serviceは、ClickHouse Cloudで使用されるのと同じバージョンのClickHouseです。
AliCloudでのClickHouse Enterprise Serviceのテスト #
ClickHouse Enterprise Serviceをテストするために、2重書き込みを行い、既存のデプロイメントとSharedMergeTreeを利用する新しいサービスの両方にデータを挿入しました。現実的なワークロードをシミュレートするために:
- 3TBのデータを両方のクラスタにロードし、その後継続的な挿入負荷をかけました。
- テストセットとして使用するためのさまざまなクエリテンプレートを収集しました。
- スクリプトを使用して、非空結果セットを保証する特定の値で1時間のランダムな時間間隔をクエリするクエリを構築しました。
インフラストラクチャについて:
- ClickHouse Enterpriseの提供(SMT)にはオブジェクトストレージを使用した32CPU、128GiBメモリの3ノード
- コミュニティエディション(オープンソース)はHDDを使用した40CPU、176GiBメモリの2ノード
クエリワークロードの実行には、両方のサービスでclickhouse-benchmarkツールを使用しました。
- エンタープライズとコミュニティの両オプションは、ファイルシステムキャッシュを使用するように構成されています。これは、本番環境での類似条件を再現したいからです(データボリュームがはるかに大きいため、本番環境でのキャッシュヒット率は低くなることが予想されます)。
- 最初のテストは2の並列実行で行われ、各クエリは3つの異なるラウンドで実行されます。
| Testing Round | P50 | P90 | P99 | P9999 | Avg | |
|---|---|---|---|---|---|---|
| Alicloud Enterprise Edition | 1st | 0.26 | 0.62 | 7.2 | 22.99 | 0.67 |
| 2nd | 0.24 | 0.46 | 4.4 | 20.61 | 0.52 | |
| 3rd | 0.24 | 0.48 | 16.75 | 21.71 | 0.70 | |
| Avg | 0.246 40.3% | 0.52 22.2% | 7.05 71.4% | 21.77 90.3 | 0.63 51.6% | |
| Alicloud Community Edition | 1st | 0.63 | 3.4 | 11.06 | 29.50 | 1.39 |
| 2nd | 0.64 | 1.92 | 9.35 | 23.50 | 1.20 | |
| 3rd | 0.58 | 1.60 | 9.23 | 19.3 | 1.07 | |
| Avg | 0.61 100% | 2.31 100% | 9.88 100% | 24.1 100% | 1.07 100% |
ClickHouse Enterprise Serviceの結果は黄色で表示され、Alicloudのコミュニティエディションの結果は赤で表示されています。コミュニティエディションとのパフォーマンスの割合は緑で示されており(低いほど良い)ます。
並列処理の数を増やすにつれ、コミュニティエディションはすぐにワークロードを処理できなくなり、エラーを返し始めます。これは実質的にエンタープライズエディションが同時クエリを3倍効果的に処理できることを意味します。
ClickHouseのエンタープライズサービスはデータの保存手段としてオブジェクトストレージを使用しているにもかかわらず、それでもなお高並行ワークロードに関して特に良好なパフォーマンスを発揮します。このシームレスなインプレースアップグレードが、私たちにとって大きな運用負荷を取り除く可能性があると考えています。
このテストの結果として、ビジネスメトリクスをエンタープライズサービスに移行し始めることに決定しました。これには、支払い完了率、注文統計などの情報が含まれています。全てのコミュニティユーザーに対して、ぜひエンタープライズサービスを試してみることをお勧めします!



