
概要 #
この「ClickHouse vs. Snowflake」ブログシリーズは2部構成になっており、それぞれ独立して読むことができます。内容は以下の通りです。
- Benchmarks and Cost Analysis - 本記事では、あるアプリケーションで使用されるリアルタイム分析向けクエリ群をベンチマークし、両システムで性能を比較します。幅広い最適化手法を適用した上でクエリを評価し、コストを直接比較します。
- Comparing and Migrating - こちらの記事では、ClickHouseとSnowflakeのアーキテクチャ上の類似点と相違点を整理し、特にリアルタイム分析でメリットが大きいClickHouse Cloudの機能をレビューします。SnowflakeからClickHouseへのワークロード移行を検討している方に向けて、データセットの相違点や移行方法についても解説します。
はじめに #
本記事では、Pythonパッケージのダウンロード状況を時系列で分析できるリアルタイム分析アプリケーションを例に取り上げます。データセットとしては、約6000億行からなるPyPIのデータセットを利用しています。
このアプリケーションで使用する代表的なクエリを特定し、ClickHouseとSnowflakeの両方でベンチマークを行い、ベンチマークの実行コストだけでなく、アプリケーションを運用し続ける上でのコスト分析も行います。
これらの分析結果から、Snowflakeと比較した場合、リアルタイム分析用途でClickHouseが大幅なパフォーマンスとコスト効率の向上を実現できると考えています。主な結果は以下の通りです。
- ClickHouse CloudはSnowflakeよりも3~5倍のコスト効率を実現します。
- ClickHouse Cloudのクエリ速度はSnowflakeより平均で2倍以上高速です。
- ClickHouse CloudではSnowflakeより38%優れたデータ圧縮率を示します。
今回のベンチマーク分析を再現するために必要な情報や実施手順は、https://github.com/ClickHouse/clickhouse_vs_snowflakeで一般公開されています。
ベンチマーク #
次のセクションでは、提案アプリケーションにおけるクエリを想定した場合、ClickHouseとSnowflakeでのデータ挿入性能、クエリ性能、圧縮率を比較します。すべてのテストでは、us-central-1のGCE上にホストされたインスタンスを使用しています。これは後述するテストデータセットがGCSに公開されており、エクスポートがしやすいためです。
ClickHouse側は、本記事の例としてClickHouse Cloudの本番用インスタンス(合計177、240、256 vCPU)を使用しています。Snowflake側では、2X-LARGEまたは4X-LARGEのクラスタを主に使っています。一般的にはこちらの情報にある通り、Snowflakeの各ノードは8 vCPU、16GiBメモリ、ローカルストレージ200GBを持つと考えられるため、2X-LARGEは256 vCPU程度、4X-LARGEは512 vCPU程度と推定しています。2X-LARGEの構成がClickHouseクラスタに最も近いと見なせます。Snowflakeのほうが見かけ上は多いvCPUを持つ構成となりますが、ClickHouse CloudはCPU:メモリ比がSnowflakeの1:2より大きい1、メモリ優位性が一部相殺されます。とはいえ、本ベンチマークはクエリがメモリを大量に消費するわけではないため、その差は限定的です。
本ベンチマークを再現される方へ注意点として、Snowflakeではテストが高額になる可能性があります。たとえばSnowflakeへのデータロードだけで1100ドル程度かかったのに対し、ClickHouse Cloudでは同様の作業が約40ドルでした。コストを削減するには、Snowflake側でデータの一部のみをロードするか、実行するベンチマークの回数を制限するといった方法が考えられます。ClickHouse側については、もしClickHouse Cloudが利用できない場合でも、同等の規模を持つ自前のClickHouseクラスタ上で同様の操作は再現可能でしょう。
アプリケーションとデータセット #
PyPIデータセット #
PyPIデータセットは現在、BigQueryのパブリックテーブルとして利用可能です。このデータセットでは、Pythonパッケージが1回ダウンロードされるごとに1行のレコードが記録されています(pipなどの方法を使った場合など)。今回は、このデータをParquetファイルとしてエクスポートしたものをgcs://clickhouse_public_datasets/pypi/file_downloadsに公開しています。手順はこちらを参照してください。元のスキーマは下図の通りです。ネスト構造を含むため、SnowflakeとClickHouseが対応しているParquetフォーマットでエクスポートするのが最適でした。

デフォルトでは、BigQueryのパーティション設定によりエクスポート時のファイルサイズが決定されます。約5600億行を丸ごとエクスポートした場合、19TiBのParquetが約150万ファイルに分割されます。ClickHouseへのインポートは容易ですが、Snowflakeには小さすぎるファイルが大量にあると問題が生じる場合があります(後述)。
そこで本テストでは、2023年6月23日時点での直近3か月分のみをエクスポートして使用します。またSnowflakeが推奨するParquetファイルサイズ(100~150MiB)に合わせるため、BigQuery上でテーブルをコピーして再パーティション化してからエクスポートしています。詳細はこちらを参照してください。その結果、合計8.74TiBのデータを70,608ファイル(平均サイズ129MiB)にエクスポートしました。
提案するアプリケーション #
今回のベンチマークにおいては、ユーザーがパッケージ名を入力すると、そのパッケージに関するいくつかの興味深い指標を取得(主にグラフ描画)できるシンプルな分析サービスを想定します。以下は例になりますが、このアプリケーションで想定されるクエリは次のような内容です。
- ダウンロード数の推移(折れ線グラフ)
- Pythonバージョンごとのダウンロード推移(マルチシリーズの折れ線グラフ)
- OSなどのシステムごとのダウンロード推移(棒グラフやマルチシリーズ)
- プロジェクトごとに最も多いファイルタイプ(sdistやbdistなど)の上位を出す集計(円グラフ、棒グラフなど)
さらに、このアプリケーションでは、以下のような機能も提供する可能性があります。
- ある技術に関連するサブプロジェクト(存在する場合)の合計ダウンロード数を把握する
例:ClickHouseの場合、clickhouse-connect - 特定のディストロ(例:Ubuntu)におけるトッププロジェクトを表示する
その画面イメージは以下のようになります。
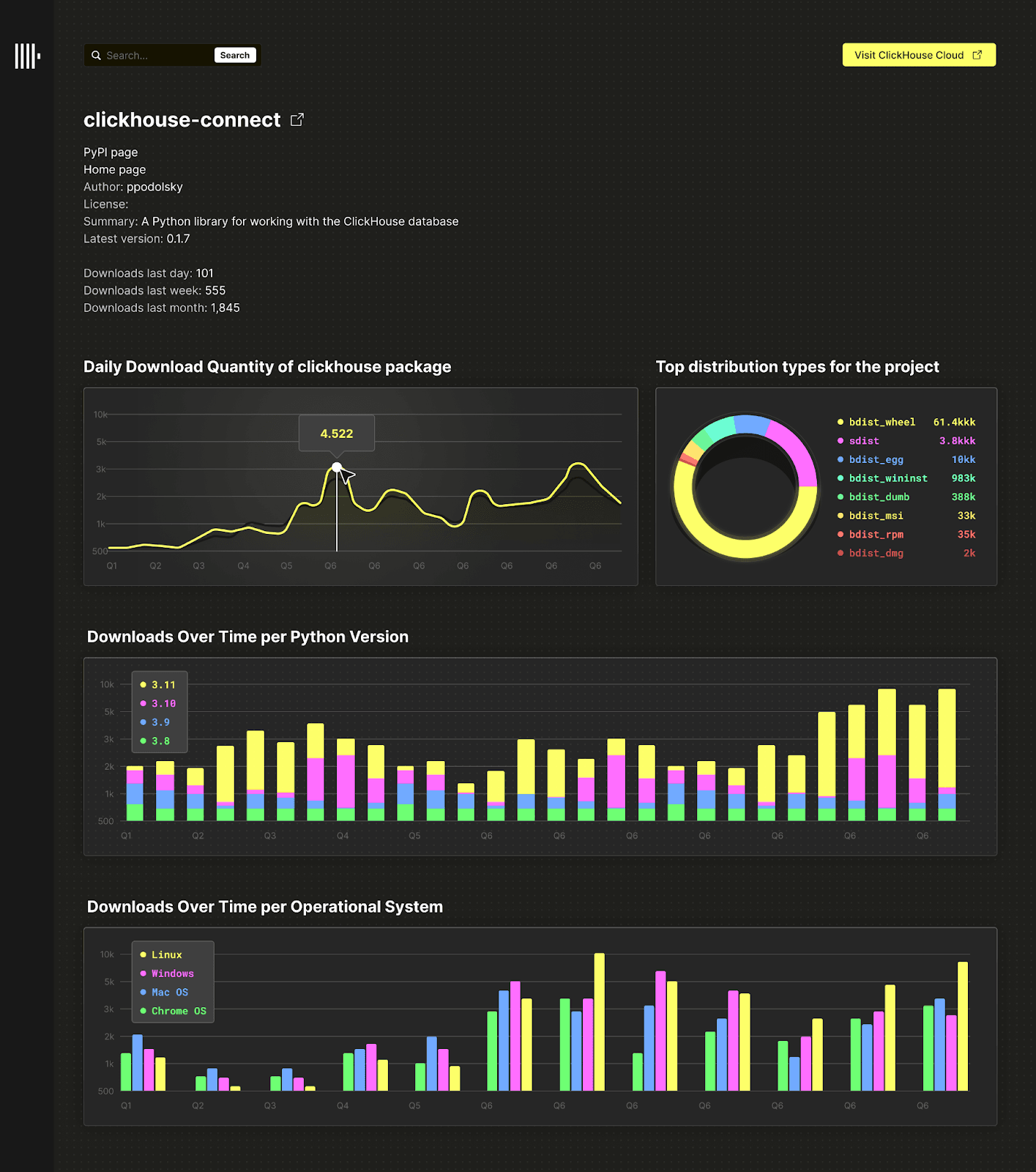
上記は、機能拡張がいくらでも考えられるごくシンプルなリアルタイム分析アプリケーションの例です。実際のリアルタイム分析アプリケーションはもっと複雑になるでしょうが、今回はクエリワークロードのモデル化を簡単にするため、この例に絞っています。ユーザーが日付範囲を指定してドリルダウンし、グラフを更新するなどの操作を想定しており、そのときのSnowflakeとClickHouseのクエリ性能を比較します。
ベンチマークでは、これらのチャートを描画するときに投げられるであろうSQLクエリを1つずつ定義し、それらをClickHouseとSnowflakeに対して同じ順番・同じ条件で実行します。単一スレッドでクエリを順番に実行(絶対的なレイテンシ重視)する形で、同時接続のワークロードはテストしていません。同時実行負荷をテストした場合、ClickHouseが優位に動くと予想されますが、フェアに測定して解釈するのが難しいため、今回は扱っていません。
仮定と制限 #
本ベンチマークでは、再現性が高く解釈しやすい結果を得るために、いくつか仮定を置いて範囲を絞っています。すべての仮定や制限事項はこちらで確認できますが、主な点を以下に示します。
- Snowflake のマルチクラスタウェアハウス機能は評価対象に含めていません。本ベンチマークのワークロードには適していないと判断したためですが、本番アプリケーションでスループットを拡張するうえでは非常に有用です。ノードを追加してサービスをスケールさせる ClickHouse Cloud とは対照的に、Snowflake ではマルチクラスタウェアハウスを用いるアプローチには多くの利点があります。
- Snowflake のパーシステントキャッシュは大きな価値をもたらします。ウェアハウスの再起動に強く、かつウェアハウスとは独立した完全分散型キャッシュであるため、高いキャッシュヒット率を確保できます。一方で、ClickHouse Cloud には Snowflake より高速なクエリキャッシュがありますが、現状ではノード単位です(将来的に分散キャッシュが予定されています)。
- Snowflake のクエリアクセラレーションサービスも評価対象外としました。これは特定のクエリ処理を共有コンピュートリソースにオフロードし、大幅な追加費用が発生するものの性能を向上させる機能です。しかし、Snowflake の説明ではサーバーの空き状況に依存するため、性能向上にばらつきが生じやすく、再現性のあるベンチマークには適さないと考えました。
スキーマ #
ClickHouse #
ClickHouseのスキーマは以下の通りです。
CREATE TABLE default.pypi
(
`timestamp` DateTime64(6),
`date` Date MATERIALIZED timestamp,
`country_code` LowCardinality(String),
`url` String,
`project` String,
`file` Tuple(filename String, project String, version String, type Enum8('bdist_wheel' = 0, 'sdist' = 1, 'bdist_egg' = 2, 'bdist_wininst' = 3, 'bdist_dumb' = 4, 'bdist_msi' = 5, 'bdist_rpm' = 6, 'bdist_dmg' = 7)),
`installer` Tuple(name LowCardinality(String), version LowCardinality(String)),
`python` LowCardinality(String),
`implementation` Tuple(name LowCardinality(String), version LowCardinality(String)),
`distro` Tuple(name LowCardinality(String), version LowCardinality(String), id LowCardinality(String), libc Tuple(lib Enum8('' = 0, 'glibc' = 1, 'libc' = 2), version LowCardinality(String))),
`system` Tuple(name LowCardinality(String), release String),
`cpu` LowCardinality(String),
`openssl_version` LowCardinality(String),
`setuptools_version` LowCardinality(String),
`rustc_version` LowCardinality(String),
`tls_protocol` Enum8('TLSv1.2' = 0, 'TLSv1.3' = 1),
`tls_cipher` Enum8('ECDHE-RSA-AES128-GCM-SHA256' = 0, 'ECDHE-RSA-CHACHA20-POLY1305' = 1, 'ECDHE-RSA-AES128-SHA256' = 2, 'TLS_AES_256_GCM_SHA384' = 3, 'AES128-GCM-SHA256' = 4, 'TLS_AES_128_GCM_SHA256' = 5, 'ECDHE-RSA-AES256-GCM-SHA384' = 6, 'AES128-SHA' = 7, 'ECDHE-RSA-AES128-SHA' = 8)
)
ENGINE = MergeTree
ORDER BY (project, date, timestamp)
ここでは、さまざまな型の最適化を適用するとともに、スキーマにマテリアライズドカラム date を追加しています。date は元のデータには含まれないカラムで、主キーやフィルタクエリに活用する目的で新たに作成されました。file、installer、implementation、distro といったネスト構造は、名前付きタプルとして表現しています。これは階層型データ構造であり、いわゆる完全なセミ構造化データというよりは、予測可能なサブカラムを持つ形式です。したがって、ルートカラムと同様の型最適化を適用できます。
適用した最適化の詳細は、こちらを参照してください。
Snowflake #
Snowflakeのスキーマは以下の通りです。
CREATE TRANSIENT TABLE PYPI (
timestamp TIMESTAMP,
country_code varchar,
url varchar,
project varchar,
file OBJECT,
installer OBJECT,
python varchar,
implementation OBJECT,
distro VARIANT,
system OBJECT,
cpu varchar,
openssl_version varchar,
setuptools_version varchar,
rustc_version varchar,
tls_protocol varchar,
tls_cipher varchar
) DATA_RETENTION_TIME_IN_DAYS = 0;
SnowflakeではVARCHARのサイズ指定が不要で、パフォーマンスやストレージに影響がないため宣言がシンプルです。またTRANSIENTテーブルとして作成し、time travelを無効(DATA_RETENTION_TIME_IN_DAYS = 0)にしています。TRANSIENTテーブルはSnowflakeのfail-safe機能を無効にするので、緊急復旧用の7日間保持が不要な場合のコスト削減につながります。ClickHouse Cloudはバックアップ機能を備えており、Snowflakeのfail-safeと同様のメリットをストレージコストに含めて提供しています。time travel機能は強力ですが、リアルタイム分析には不要なのでオフにしています。
細かい方はお気付きかもしれませんが、上記スキーマはオリジナルのBigQueryスキーマと同一ではありません。BigQueryでは
detailsカラム配下にさらにネスト構造がありました。今回は エクスポート時に余計なネスト階層を削除 して両DBともスキーマをシンプルにしています。その結果、クエリが簡潔になりました。
初期状態ではクラスタリングキーは指定していませんが、後の実験で必要に応じて付与します。
結果 #
本テストは、ClickHouse 23.6(特に明記がない場合)とSnowflakeを用いて、6月上旬~中旬に実施した結果をまとめています。
要約 #
今回のベンチマークから、SnowflakeとClickHouseの性能を以下のように評価できます。
- Snowflakeのクラスタリングを有効にしないと、ClickHouseより圧縮率が大幅に劣りますが、クラスタリングを有効にすることで最大45%ほど圧縮率が改善しました。特にORDER BYに依存するようなリアルタイム分析では、クラスタリングがないとSnowflakeのクエリ性能はClickHouseに太刀打ちできません。一方でクラスタリングには追加コストが発生します。
- データロード速度はSnowflakeが劣り、ClickHouseが同程度のvCPU数で最大2倍速く完了します(Snowflake側でクラスタリング時間を除外していても)。加えてSnowflakeは小ファイルが多い場合に極端に性能が落ちる可能性があります(今回のベンチマークでは注意して150MiB程度に揃えています)。
- ORDER BYやクラスタリングキーを活かせるケース(リアルタイム分析で非常に多いパターン)では、Snowflake(2X-LARGE、256 vCPU相当)と比べて、ClickHouse(177 vCPU)で2~3倍高速なクエリ応答が得られます。これらのクエリではSnowflakeに追加で物理コアを与えても大差は埋まらず、常にClickHouseの方が高速でした。
- コールドクエリでは差は小さくなりますが、それでもClickHouseは1.5~2倍程度Snowflakeより速いです。Snowflakeでクラスタリングを有効にするには大きな追加費用が発生する点も考慮すると、コスト面でより優れています。
- SnowflakeのマテリアライズドビューはClickHouseのプロジェクションと同等の役割を果たし、明確な性能向上をもたらします。ただし制約も多く、Snowflake側はそれでもClickHouseより1.5倍遅い結果でした。
- ORDER BY・クラスタリングキーをうまく使えないGROUP BYクエリなどでは、Snowflakeが約30%速い場合がありました。Snowflakeがノード間の並列処理を標準で行うのに対し、ClickHouseの並列レプリカ機能は現状実験的であり最適化の余地が残されています。
- テーブル全体を走査するようなLIKE検索では、Snowflakeのほうが95・99パーセンタイルが安定して低めでしたが、平均値はClickHouseより高い場合が多かったです。
- ClickHouseのセカンダリインデックス機能(たとえばBloomフィルタなど)は、SnowflakeのSearch Optimization Serviceに近い効果を発揮し、ホットクエリではSnowflakeを上回る高速性を発揮しつつ、コールドクエリでも若干Snowflakeより遅い程度に留まります。一方、Snowflakeでこの機能を使うには高額な追加費用がかかりがちです。ClickHouseはストレージ使用量がわずかに増えるだけです。
詳細は以下の各セクションにまとめています。
データのロード #
まず、SnowflakeとClickHouseにおけるデータロード性能を比較しました。両者ともvCPU・メモリが近しい構成でテストし、そのときのデータ挿入の完了時間を計測しています。
実行内容や詳細はこちらで公開しています。挿入性能を最大化するために、ClickHouseではINSERTを複数のスレッドで分散し、大きなバッチで書き込むように設定しました。Snowflakeではドキュメントのベストプラクティスに従い、Parquetファイルサイズを150MiB程度にしてあります。
ClickHouseのINSERT性能を上げるため、こちらに記載されているスレッド数などを調整しています。その結果、大量のパーツが作られ、バックグラウンドでマージが必要になります。パーツ数が多いとSELECT性能が落ちるため、3000(デフォルト推奨)以下に減らすまでのマージを含めた合計時間を、Snowflakeのロード完了時間と比較しています。なお、ノードごとに複数のマージが同時に走りますが、1ノードあたりのマージ数には上限があります。
| Database | Specification | Number of nodes | Memory per node (GiB) | vCPUs per node | Total vCPUs | Total memory (GiB) | Insert threads | Total time (s) |
|---|---|---|---|---|---|---|---|---|
| Snowflake | 2X-LARGE | 32 | 16 | 8 | 256 | 512 | NA | 11410 |
| Snowflake | 4X-LARGE | 128 | 16 | 8 | 1024 | 2048 | NA | 2901 |
| ClickHouse | 708GB | 3 | 236 | 59 | 177 | 708 | 4 | 15370 |
| ClickHouse | 708GB | 3 | 236 | 59 | 177 | 708 | 8 | 10400 |
| ClickHouse | 708GB | 3 | 236 | 59 | 177 | 708 | 16 | 11400 |
| ClickHouse | 1024GB | 16 | 64 | 16 | 256 | 1024 | 1* | 9459 |
| ClickHouse | 1024GB | 16 | 64 | 16 | 256 | 1024 | 2 | 5730 |
| ClickHouse | 960GB | 8 | 120 | 30 | 240 | 960 | 4 | 6110 |
| ClickHouse | 960GB | 8 | 120 | 30 | 240 | 960 | 8 | 5391 |
| ClickHouse | 960GB | 8 | 120 | 30 | 240 | 960 | 16 | 6133 |
2X-LARGE(256 vCPU相当)と960GB(240 vCPU相当)の中で最良の結果を比べると、同じようなvCPU数でもClickHouseはSnowflakeより2倍以上のスピードでロードが完了します。
さらに以下のような補足があります。
- ノードあたりのCPU数が多い構成(708GBなど)だと、最初の挿入時間自体は短くなりますが、その後マージに時間がかかります。対してノード数を増やした構成(960GBなど)なら同時に走るマージも増やせるので、結果的に全体の完了が早くなります。
- Snowflakeでロード性能を最大化するには、vCPU数と同じ数のファイルが必要になると推測されます。Parquetファイルの1つを複数スレッドで並行読み込みできない(ClickHouseは対応済み)ためです。今回のデータセットは150MiBのファイルを7万個程度用意したため、この点は問題ありませんでした。
- SnowflakeはParquetファイルを150MiB程度にそろえることを推奨しています。PyPI全体のフルデータ(19TiB)は小さいファイル(平均13MiB)が150万個あるため、そのままSnowflakeにロードするとさらに性能が低下すると予想されます。
- SnowflakeはvCPU数を増やすとロード時間が直線的に減るため、総コスト(時間×時給)はある程度一定になりがちです。大きなウェアハウスでロードを一気に終わらせて、終了後にウェアハウスを停止してしまう運用がしやすいわけです。ClickHouse CloudでもSharedMergeTreeを使えば同様にリニアに挿入性能をスケールできます。今回の結果は標準のMergeTreeで行ったベンチマークですが、SharedMergeTreeを使う場合の挿入性能の伸びについてはこちらで紹介しています。
- 上記の表にはSnowflakeのクラスタリングに要する時間は含まれていません。クラスタリングはSnowflakeのクエリ性能に必須ですが、非同期で実行されスケジューリングが非決定的のため、正確な計測は難しいです。これらを含めると、Snowflakeの方がさらにロード時間がかかります。
このテストから得られる追加の知見については、こちらをご覧ください。
ストレージ効率と圧縮 #
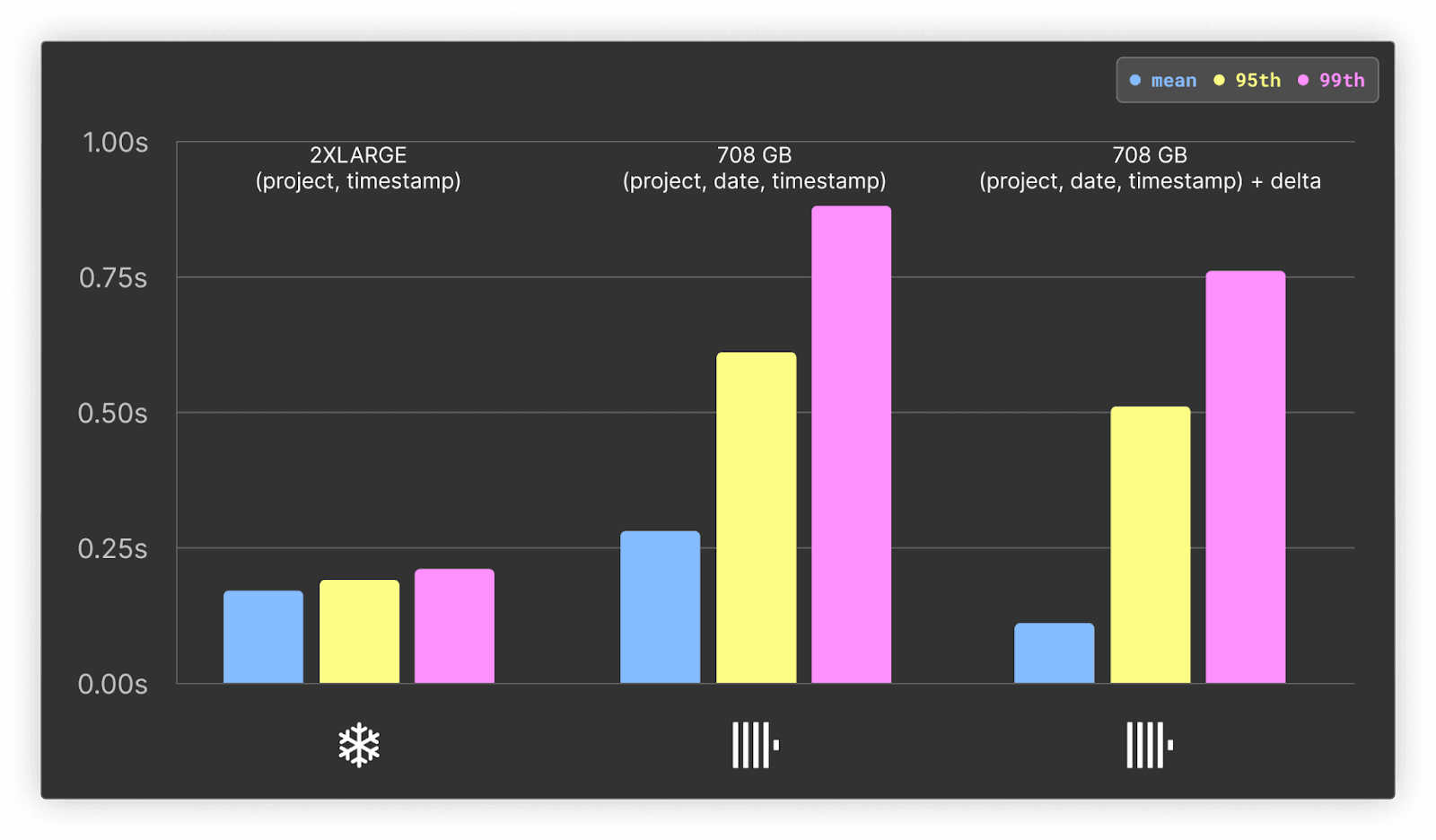
ClickHouseでは、先ほどのスキーマでほぼ最大限の圧縮を狙っています。下記に示す通り、dateとtimestampにdeltaコーデックを適用するとさらにサイズを削減できますが、コールドクエリの性能に影響が出る場合がありました。
Snowflakeはクラスタリングなしではデフォルト設定なので圧縮率は劣ります。クラスタリングキーの設定次第で圧縮が大きく変わるため、さまざまなクラスタリングキーで圧縮後サイズを計測し、結果を下図にまとめました。
詳細はこちらで確認できます。
| Database | ORDER BY/CLUSTER BY | Total size (TiB) | Compression ratio on Parquet |
|---|---|---|---|
| Snowflake | - | 1.99 | 4.39 |
| Snowflake | (to_date(timestamp), project) | 1.33 | 6.57 |
| Snowflake | (project) | 1.52 | 5.75 |
| Snowflake | (project, to_date(timestamp)) | 1.77 | 4.94 |
| Snowflake | (project, timestamp)* | 1.05 | 8.32 |
| ClickHouse | (project, date, timestamp) | 0.902 | 9.67 |
| ClickHouse | (project, date, timestamp) + delta codec | 0.87 | 10.05 |
| Most optional query performance |
| Most optimal compression |
Snowflakeの非圧縮サイズは確認できなかったため、ClickHouse同様の圧縮率を算出できませんでした。その代わり、元のParquet比としての圧縮率を掲載しています。
Snowflakeにクラスタリングを適用すると、今回のユースケースで最大40%程度のデータサイズ削減を得られました。一方、ClickHouseは追加でdateカラムがあってもSnowflakeよりも高圧縮を実現しており、Snowflakeの最良ケース(1.05TiB)より20%近く小さいサイズ(0.87TiB)になっています。
ただしSnowflakeで最も圧縮効率が高かったクラスタリングキーは、クエリ性能面では最適ではありません。Snowflakeユーザーは「圧縮率を取るかクエリ性能を取るか」のトレードオフに直面します。
本ベンチマークの目的はリアルタイム分析で高速にクエリを返すことなので、Snowflake側はクエリ速度を最優先するクラスタリングキー((to_date(timestamp), project))を使う設定にしています。
実際のクエリ速度重視構成で比較すると、ClickHouse CloudはSnowflakeより38%圧縮に優れた結果(0.902TiB vs 1.33TiB)となりました。
Snowflakeにおけるクラスタリングの時間とコスト #
Snowflake公式ドキュメントによると、クラスタリングにはクレジットを消費する非同期処理が発生します。特にリアルタイム分析で注文の多いケースでは、データを効果的に並べるための背景処理が走り、利用料金に上乗せされます。私たちの検証では、上記の各クラスタリングキーでクラスタリング処理が安定するまでを計測し、消費クレジットをまとめました(Snowflakeが提供するAUTOMATIC_CLUSTERING_HISTORYビューから1時間単位での集計しか取れないため、あくまで概算です)。
| CLUSTER BY | Time taken (mins) | Rows clustered | Bytes clustered | Credits used | Total cost (assuming standard) |
|---|---|---|---|---|---|
| (to_date(timestamp), project) | 540 | 53818118911 | 1893068905149 | 450 | $990 |
| (project) | 360 | 41243645440 | 1652448880719 | 283 | $566 |
| (project, to_date(timestamp)) | 180 | 56579552438 | 1315724687124 | 243 | $486 |
| (project, timestamp) | 120 | 50957022860 | 1169499869415 | 149 | $298 |
上の結果を、先ほどの挿入性能比較に加味すると、Snowflakeの効率的なクラスタリングはクエリ性能向上に欠かせないものの、クレジット消費や処理時間が大きいことが分かります。
一方、ClickHouseでは(ORDER BYを設定するのが当たり前のため)追加の課金は発生しません。背景で実行されるマージ処理やソート処理は既存のリソースで行われ、ユーザーが追加でコストを意識する必要はありません。プロジェクションなどにより追加のORDER BYを設定した場合も、ストレージコストがわずかに増えるだけです。Snowflakeのクラスタリングのように別途クレジット消費が積み上がることはありません。
クエリ #
提案アプリケーションが投げると想定される各種クエリをシミュレートし、その性能を比較しました。結果をざっくりまとめますが、詳細や実行ログは各リンク先で公開しています。前提条件は以下の通りです。
- Snowflakeではクラスタリングが完了している状態、ClickHouseではパーツ数が3000以下に落ち着いた状態をテスト。
- すべてのクエリは3回ずつ実行し、コールド(最初の実行)、ホット(最速の実行)を含めて計測。
- ClickHouseはクエリ前に
SYSTEM DROP FILESYSTEM CACHE ON CLUSTER 'default'を実行してファイルシステムキャッシュをクリア。Snowflakeは同等のコマンドがないため、ウェアハウスを一旦停止→再開でキャッシュをクリアしたとみなす。 - ClickHouseとSnowflakeのクエリキャッシュは無効化(ClickHouse Cloudはデフォルトで無効、Snowflakeは
ALTER USER <user> SET USE_CACHED_RESULT = false;)。 - 「直近90日」などの日付条件は常に同じ絶対日時を指定し、クエリ結果を再利用しても同じにならないようにしています(キャッシュヒットを排除するため)。
クエリ 1:1日あたりのダウンロード数 #
「直近90日間のダウンロード数を日次集計」で折れ線グラフを描画するようなクエリです。人気上位100のプロジェクトについて、以下の集計を行い、続けてランダムな日付範囲にフィルタをかけて再クエリする(ユーザーがドリルダウンした想定)。計200クエリになります。
SELECT
toStartOfDay(date),
count() AS count
FROM pypi
WHERE (project = 'typing-extensions') AND (date >= (CAST('2023-06-23', 'Date') - toIntervalDay(90)))
GROUP BY date
ORDER BY date ASC
詳しい結果はこちらにあります。
Hot only
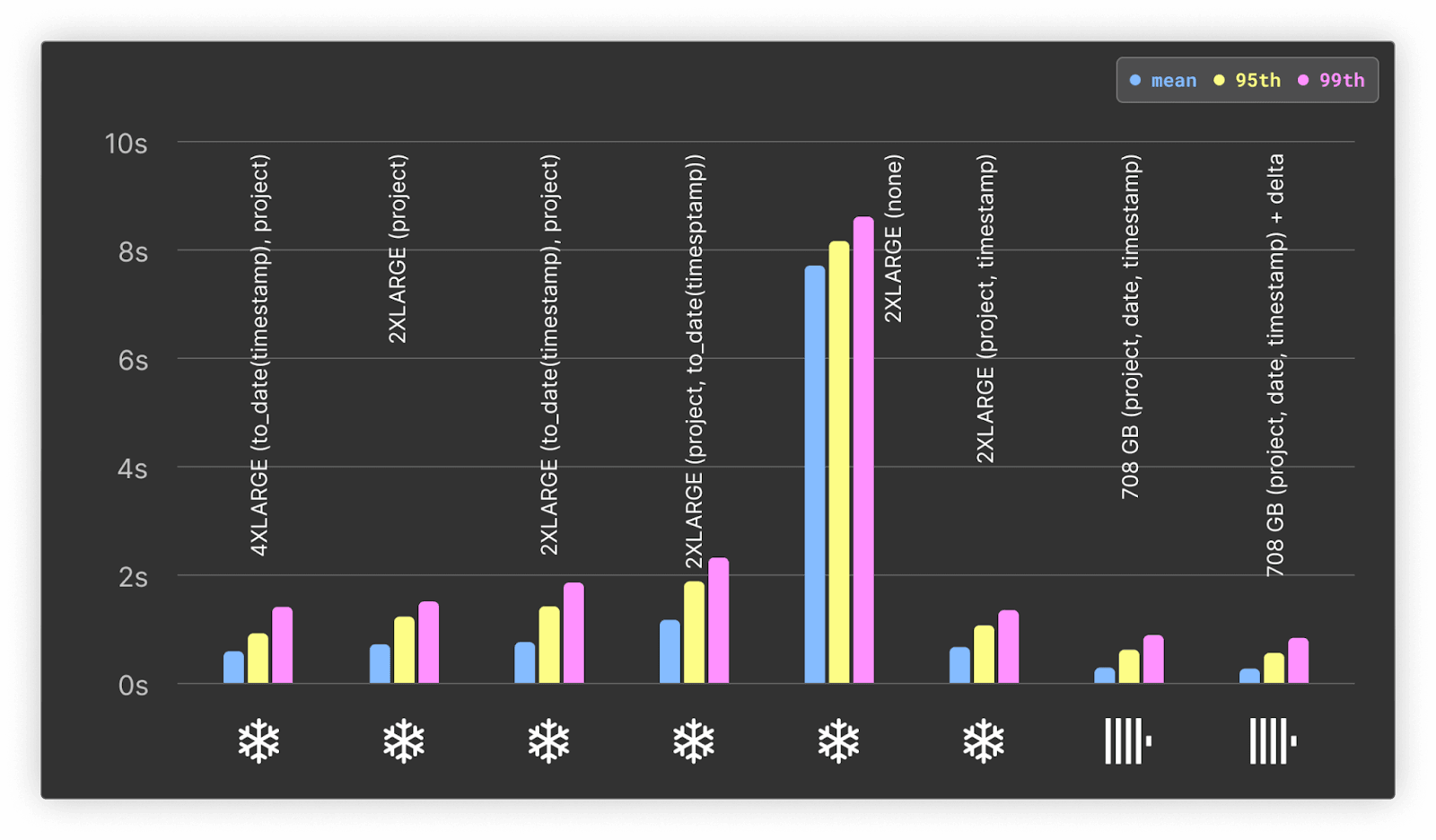
まとめると以下の通りです。
- Snowflakeでは、クラスタリングなしだとリアルタイム分析に耐えない7秒以上の応答時間になってしまいます。
- リソースが近しい構成で比べると、ClickHouseはSnowflakeの少なくとも3倍高速(平均値)で、95・99パーセンタイルでも2倍高速。
- ClickHouseの177 vCPU構成でも、Snowflakeの4X-LARGE(約1024 vCPU)より速いです。本ワークロードではSnowflakeが推奨する追加の並列化があまり効果を発揮しないと推測できます。
クエリ 2:Python バージョン別の1日あたりのダウンロード数 #
こちらは「Pythonバージョンごとのダウンロード数推移」をグラフにするクエリです。直近90日間、日次で集計してバージョン別にGROUP BYし、さらにプロジェクトでWHEREフィルタをかけます。その後、ランダムな日付レンジで再度クエリしてドリルダウンします。人気上位100プロジェクトで計200クエリです。Pythonバージョン列は低カーディナリティですが、ORDER BY・クラスタリングキーには含まれていません。
SELECT
date AS day,
concat(splitByChar('.', python)[1], '.', splitByChar('.', python)[2]) AS major,
count() AS count
FROM pypi
WHERE (python != '') AND (project = 'boto3') AND (date >= (CAST('2023-06-23', 'Date') - toIntervalDay(90)))
GROUP BY
day,
major
ORDER BY
day ASC,
major ASC
詳細や結果はこちらにまとめています。Snowflake側は to_date(timestamp), project でクラスタリングしたテーブルを使用しています。圧縮とホット・コールド両面でバランスが良いためです。
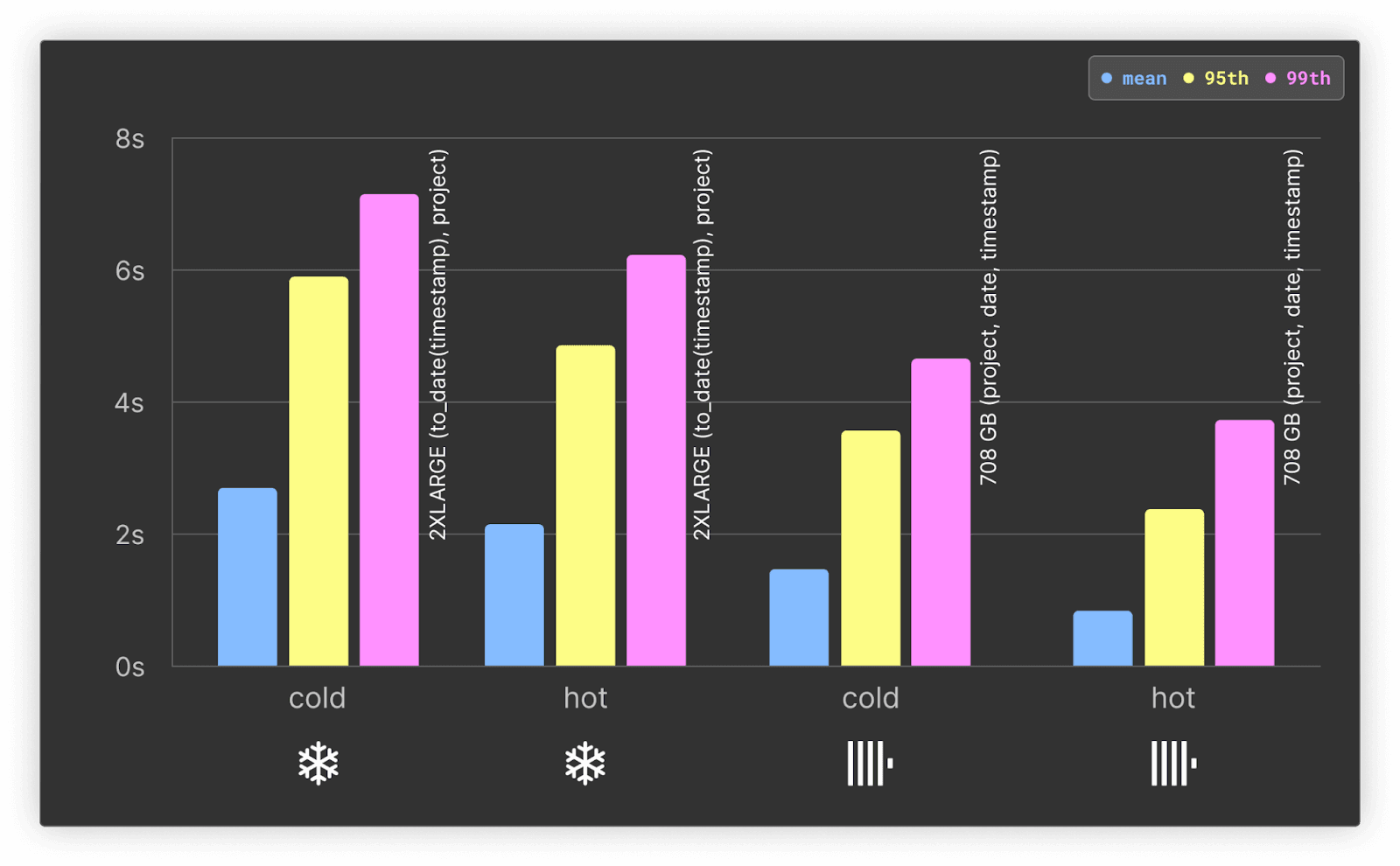
ホット・コールド問わず、ClickHouseがSnowflakeより少なくとも2倍速いという結果でした。
クエリ 3:システム別の1日あたりのダウンロード数 #
今度はシステム(OS)ごとのダウンロード数を集計し、やはり直近90日の日次推移を可視化するクエリです。systemという列でGROUP BYを行うため、Pythonバージョンよりカーディナリティは高めです。ただしPROJECTでWHEREフィルタしています。高カーディナリティ列をグラフ化する際は、上位数個に絞る実装がよくありますが、このベンチマークでもサブクエリでトップ10を取得してからメインクエリを投げる実装をしています。
SELECT
date AS day,
system.name AS system,
count() AS count
FROM pypi
WHERE (project = 'boto3') AND (date >= (CAST('2023-06-23', 'Date') - toIntervalDay(90))) AND (system IN (
-- sub query reading top 10 systems for the project
SELECT system.name AS system
FROM pypi
WHERE (system != '') AND (project = 'boto3')
GROUP BY system
ORDER BY count() DESC
LIMIT 10
))
GROUP BY
day,
system
ORDER BY
day ASC,
count DESC
このサブクエリ部分は、ClickHouseではプロジェクション、Snowflakeではマテリアライズドビューで加速できます。その比較も行っています。詳細はこちらを参照してください。
ホットのみ
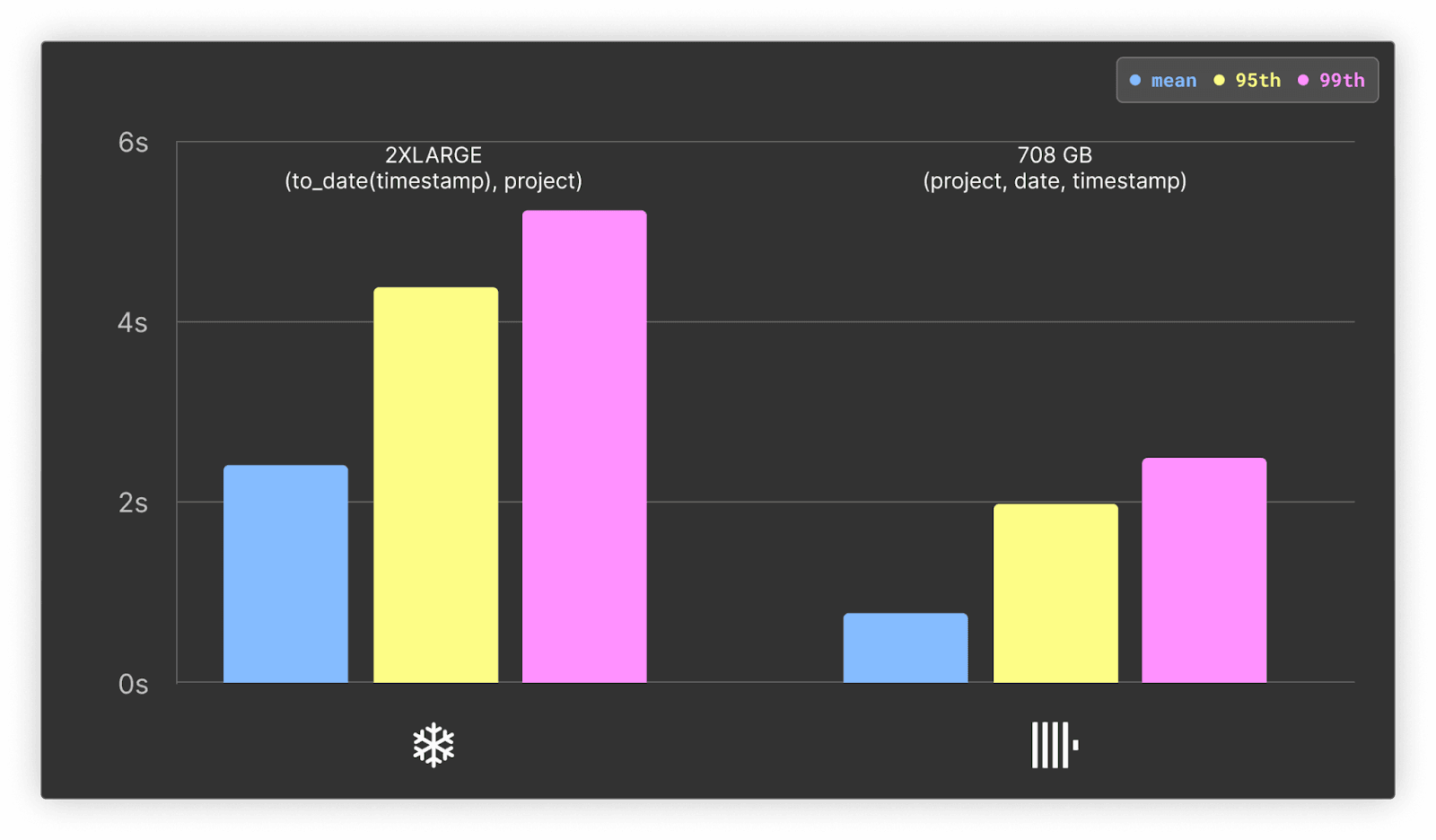
平均応答時間で2倍以上の差でClickHouseが速いという結果です。コールドクエリにおいても平均で少なくとも 1.5 倍、Snowflake を上回っています。
ClickHouse は、コールドクエリにおける最大値以外すべての指標で Snowflake を上回り、平均では 1.7 倍の速さを示しています。詳しい結果はこちらをご参照ください。
上記のとおり、プロジェクトで利用される主要なシステムを特定するサブクエリは、ClickHouse のプロジェクションや Snowflake(クラスタリングを用いたマテリアライズドビュー)を使って最適化できる理想的な候補です。
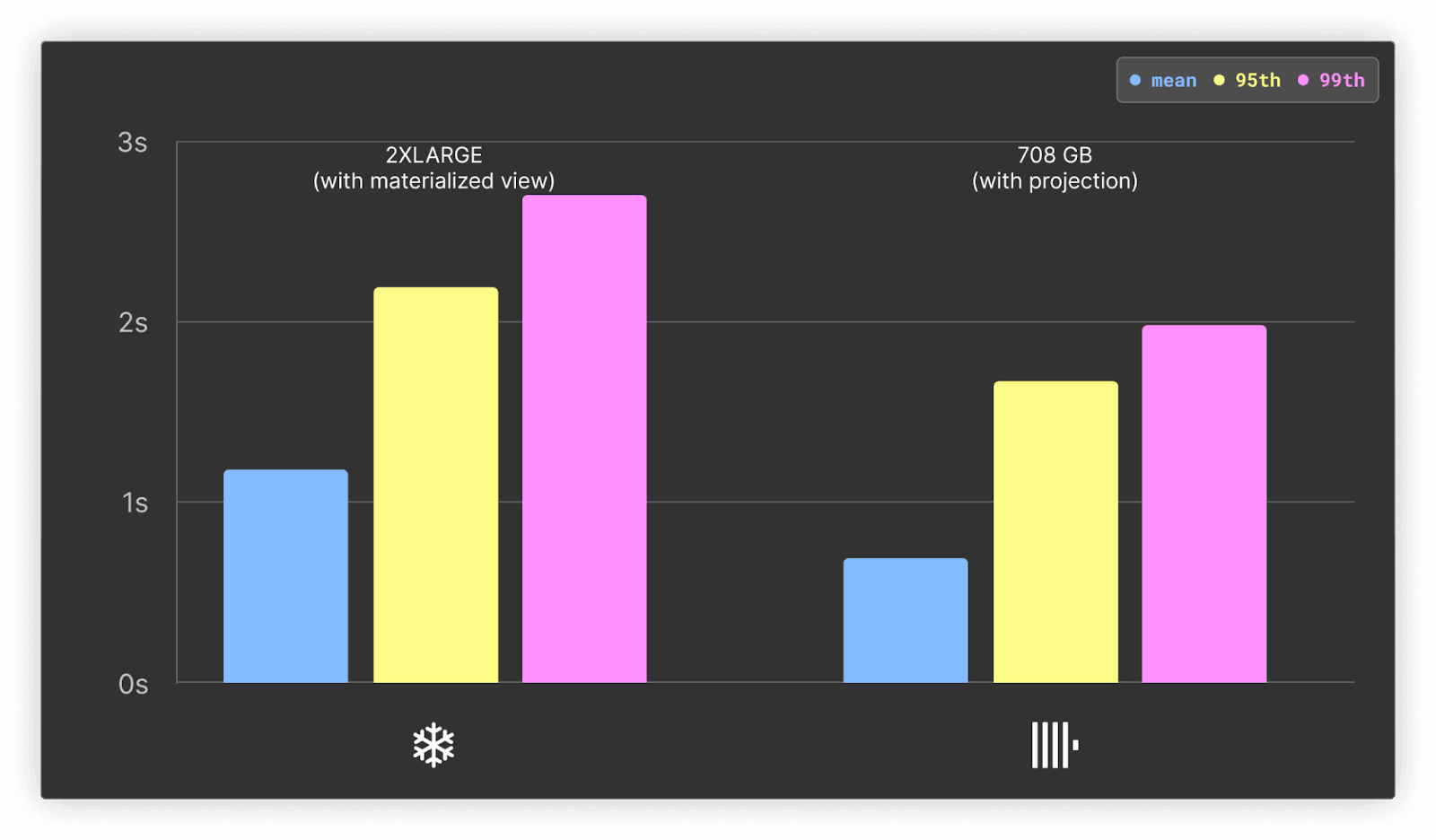
ClickHouseでは平均値ベースで約10%の高速化ですが、95・99パーセンタイルを15~20%ほど縮められます。Snowflakeのほうは50%前後の高速化が得られましたが、それでもClickHouseより平均1.5倍ほど遅いままです。
Snowflakeでマテリアライズドビューを使うと、追加コストがかさむ場合があります。エンタープライズプラン以上が必要(クレジット単価が3ドル)で、さらに背景処理のクレジット消費が増えます(コスト予測が難しい)。一方、ClickHouse Cloudはプロジェクションやマテリアライズドビューを使っても別料金は発生せず、INSERT性能への影響は定義したクエリ内容次第です。
クエリ 4:プロジェクトごとの最も多いファイルタイプ #
このクエリは、直近90日間のダウンロードについて、ファイルタイプごとに集計し、上位のファイルタイプを表示する想定です。マルチシリーズではなく、円グラフや棒グラフの描画向けです。日付フィルタは今まで同様に90日を絞り込んだあと、さらにランダムな日付範囲をドリルダウンします。ただし、ここでは日付を日の粒度に丸めているため、マテリアライズドビューをClickHouse/Snowflakeのどちらも適用しやすくなります。
SELECT
file.type,
count() AS c
FROM pypi
WHERE (project = 'boto3') AND (date >= (CAST('2023-06-23', 'Date') - toIntervalDay(90)))
GROUP BY file.type
ORDER BY c DESC
LIMIT 10
詳細はこちらを参照してください。
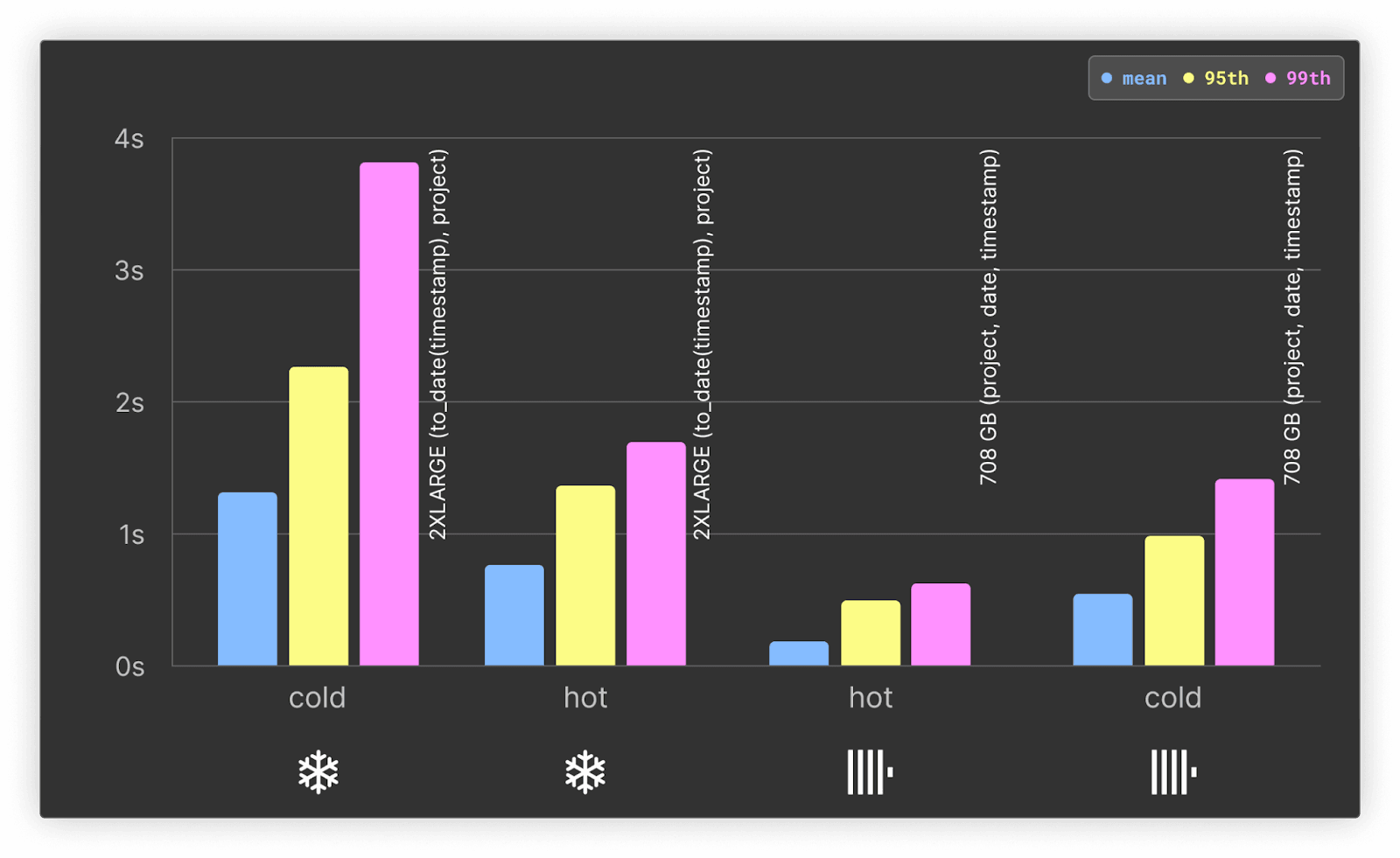
ホット・コールド問わず、ClickHouseが2倍以上速いという結果です。ClickHouse と Snowflake はどちらも、ホットクエリではコールドクエリの約 2 倍の速度を示しています。両システムとも、時間フィルターを日単位に丸めていることによる恩恵を受けており、平均的なパフォーマンスは以前のテストより高速になっています。
私たちのドリルダウンクエリは日単位で丸められているため、これらのクエリは両システムにおいてマテリアライズドビューに簡単に変換できます。Snowflake と ClickHouse ではマテリアライズドビューの仕組みが必ずしも同じではありませんが、どちらも挿入時に更新される集約済みデータを保存できる点は共通しています。最適化の詳細については、こちらをご覧ください。
マテリアライズドビューは、このクエリのパフォーマンスに大きな影響を与えます。
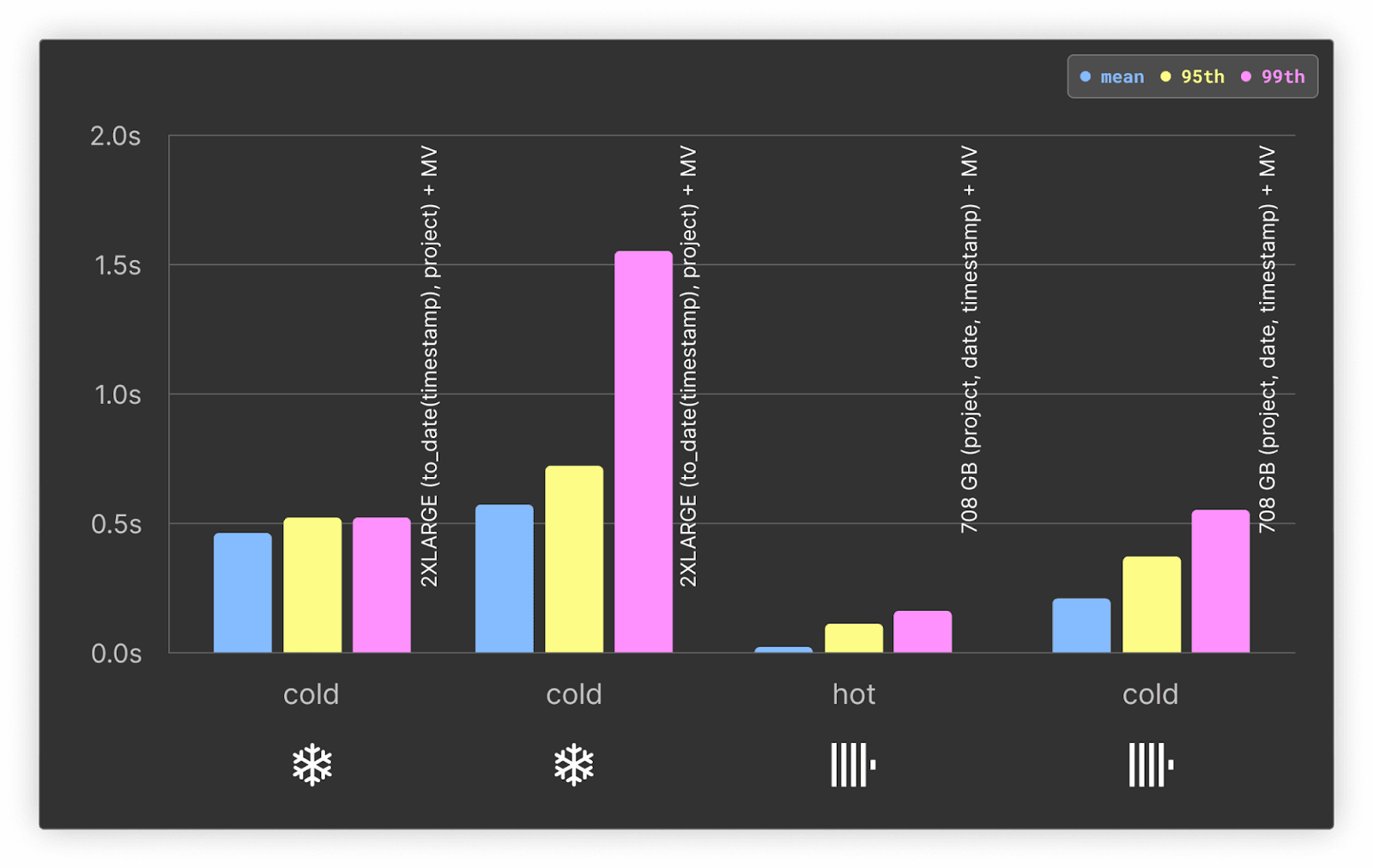
ClickHouse では、マテリアライズドビューによってコールドクエリのパフォーマンスが 2 倍、ホットクエリでは 4 倍以上向上し、高いパーセンタイルでも数ミリ秒という短い時間で実行できます。一方、Snowflake のパフォーマンス向上は、コールドおよびホットクエリともにおおむね 2 倍です。この結果、ClickHouse と Snowflake のクエリ実行速度にはより大きな差が生じ、ClickHouse が少なくとも 3 倍速くなります。
Query 5: ディストロごとのトッププロジェクト #
このクエリは、プライマリキーではないカラム(distro.name)を使用してフィルタリングを行い、パイチャートを作成するケースを想定しています。プロジェクトごとに集計し、過去 90 日間のダウンロード数をカウントする際に distro.name でフィルタリングします。ここでは、上位 25 のディストロを使用し、それぞれのディストロに対してランダムな期間をフィルタリングするクエリを発行します(両データベースとも同じ期間を適用)。
今回の注目点は、クラスタリングやソートが行われていないカラムでフィルタリングを行う場合のパフォーマンスです。日付/タイムスタンプでもフィルタリングしているため完全な線形スキャンではありませんが、性能は大幅に低下すると想定していました。このようなクエリは、クラスタ内のすべてのノードに計算を分散させることでメリットが得られます。Snowflake ではこれがデフォルトで行われます。ClickHouse Cloud でも、パラレルレプリカを使用することで同様の分散実行が可能です。この機能を使用すると、1 つのシャードから読み取りつつ、集計クエリの処理をクラスタ内のすべてのノードに分散できます。現在は実験的な機能ですが、一部の ClickHouse Cloud ワークロードではすでに利用されており、近いうちに一般提供が予定されています。
SELECT
project,
count() AS c
FROM pypi
WHERE (distro.name = 'Ubuntu') AND (date >= (CAST('2023-06-23', 'Date') - toIntervalDay(90)))
GROUP BY project
ORDER BY c DESC
LIMIT 10
完全な結果、クエリ、および考察はこちらでご覧いただけます。
以下では、元の 708GB サービスと project, date, timestamp をキーとしてソートした環境で、ClickHouse においてパラレルレプリカを有効化したときのパフォーマンス向上を示します。このサービスは合計 177 vCPU を含む構成で、3 つの vCPU に分散されています。
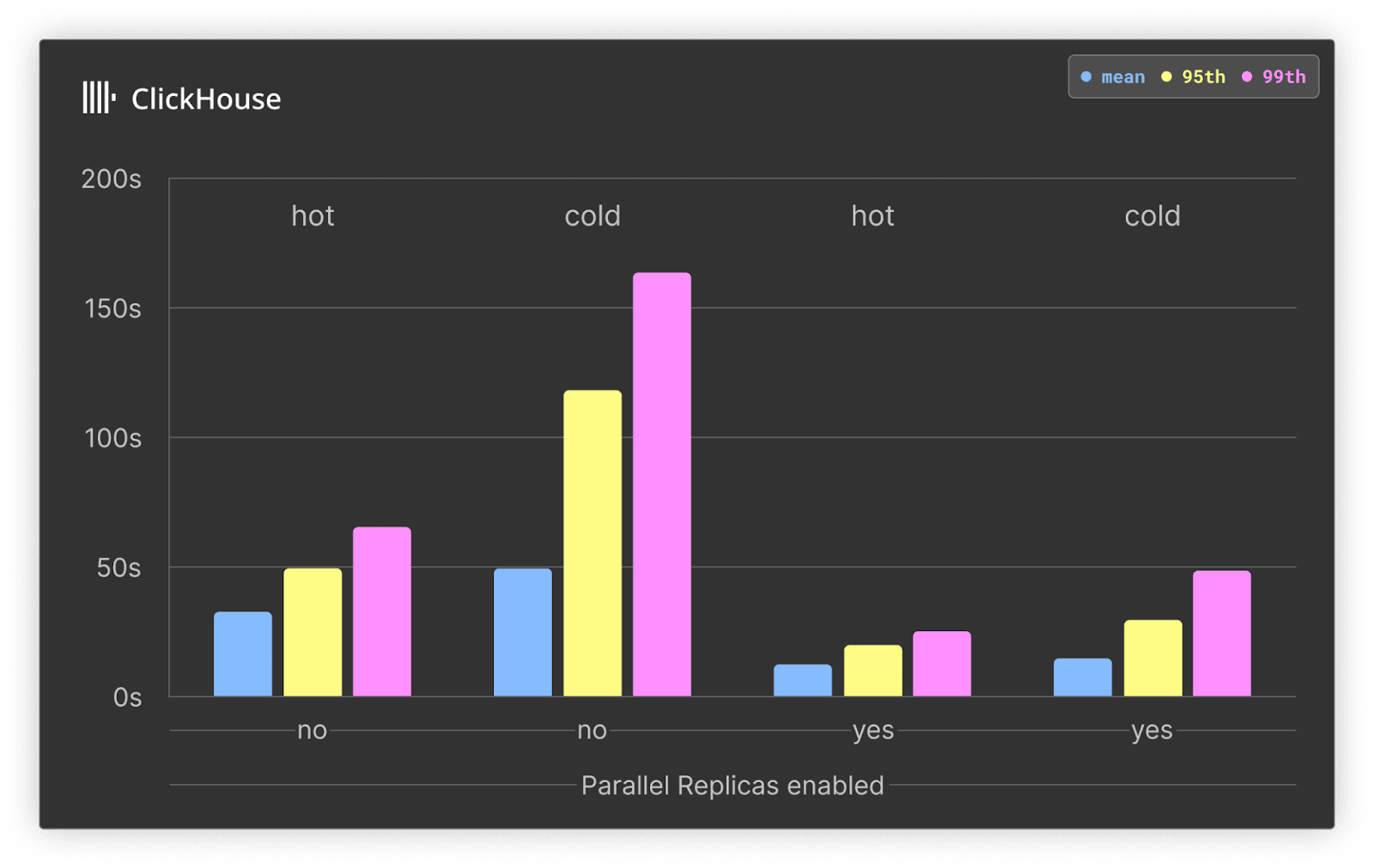
ホットクエリとコールドクエリの両方において、パラレルレプリカを有効化した ClickHouse Cloud のクエリ時間は約 3 倍高速化しています。これは、集約処理にすべてのノード(3 ノード)が利用されるためです。より多くのデータをスキャンする必要があるクエリにおいて、パラレルレプリカが大きな威力を発揮することが示されています。
以前のクエリでは、ClickHouse のオーダリングキーとして project を先頭に、date と timestamp をそれぞれ 2 番目と 3 番目に指定していました(Snowflake では日付を先頭に置く方が有利なケースとは異なる設定です)。しかし、このワークロードには project によるフィルタが存在しません。そこで、Snowflake に合わせる形で、ClickHouse でも date, timestamp をキーとしてソートすることで、このワークロードを最適化しました。
ClickHouse と Snowflake の結果:
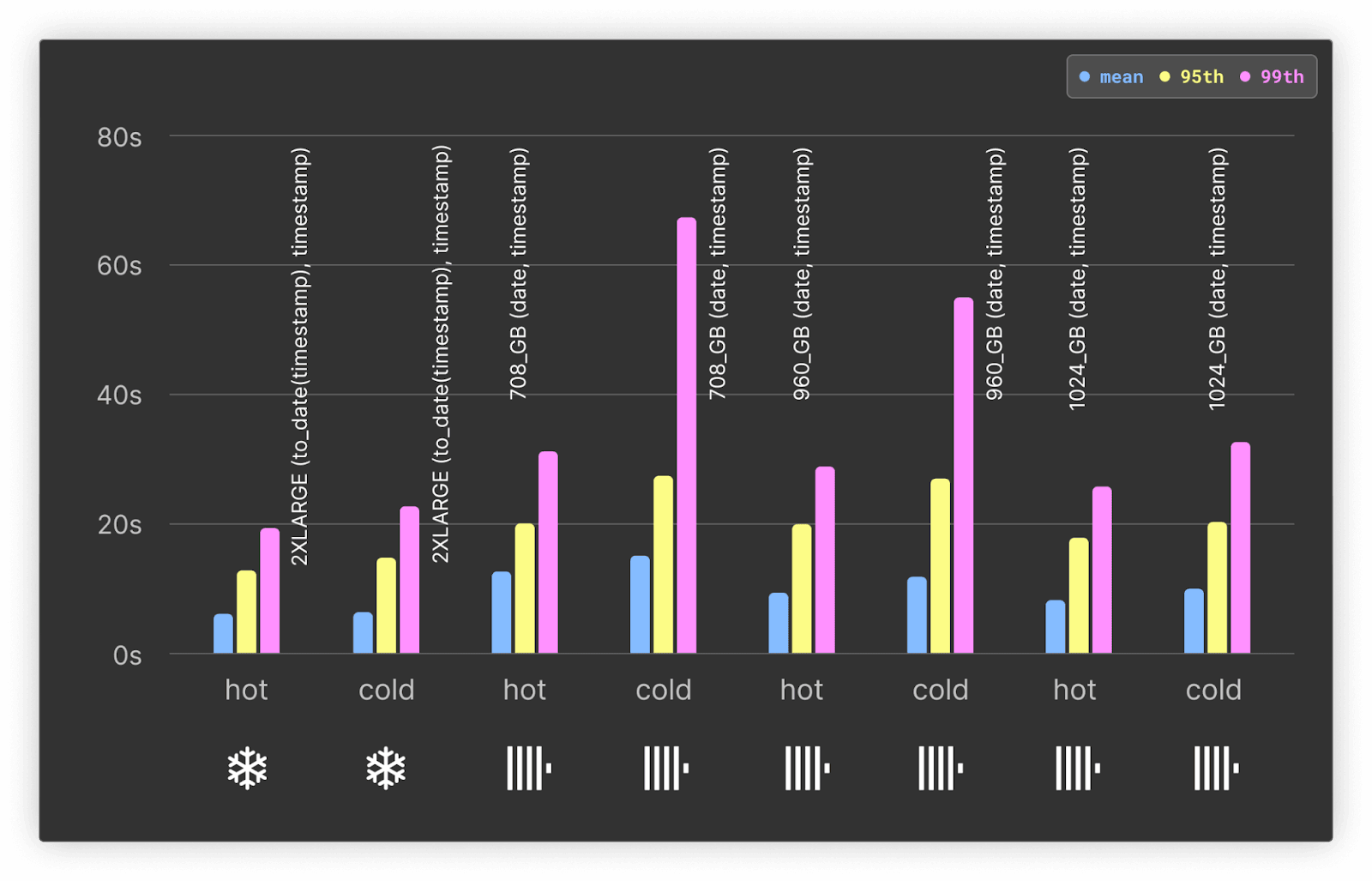
本クエリについては、Snowflakeが30%ほど速い結果となりました。並列レプリカ機能がまだ発展途上であることも影響しています。今後の改善に期待できますが、少なくとも本テストでは大量データを広範囲にスキャンする集計クエリはSnowflakeも得意とするところと言えます。
クエリ 6:サブプロジェクトのトップ #
このクエリでは、あるコア技術(例: mysql)に関連するサブプロジェクトを時間軸で表す円グラフのレンダリングとフィルタリングをテストします。サブプロジェクトは project ILIKE %<term>% のように判定され、<term> はリストから選択されます。このリストは、プロジェクト名に - を含むもののうち、先頭 20 件のプレフィックスを抽出することで得られます。例えば、以下のようなクエリです:
SELECT splitByChar('-', project)[1] as base
from pypi
GROUP BY base
ORDER BY count() DESC
LIMIT 20
このテストは、過去 90 日間のサブプロジェクトを集計し、ダウンロード数でソートし、特定のプロジェクト名をフィルタリングします。さらに、特定の時間帯をランダムに絞り込むことで、ユーザーがある用語に関するトップのサブプロジェクトを確認し、そのうえで特定の期間にドリルダウンするシナリオを想定しています。
クエリでは projectカラムをフィルタリングしていますが、たとえば project LIKE '%clickhouse%'のように LIKE演算子を使用するため、プライマリキーを十分に活かすことはできません。以下は ClickHouse のクエリ例です:
SELECT
project,
count() AS c
FROM pypi
WHERE (project LIKE '%google%') AND (date >= (CAST('2023-06-23', 'Date') - toIntervalDay(90)))
GROUP BY project
ORDER BY c DESC
LIMIT 10
このようなシナリオでは、Snowflake が提供する Search Optimization Service を利用することで、LIKEクエリのパフォーマンスを向上できます。一方、ClickHouse にはさまざまなセカンダリインデックスがあり、今回のようなクエリを高速化できます。これらのインデックスはスキップインデックスの仕組みを用い、実際のカラムデータを読み込む前に不要データを除外します。今回のケースでは、projectカラムに対して n-grams ベースのブルームフィルタインデックスを使用して、こうした機能を活用しています。
完全な結果、クエリ、考察についてはこちらをご覧ください。
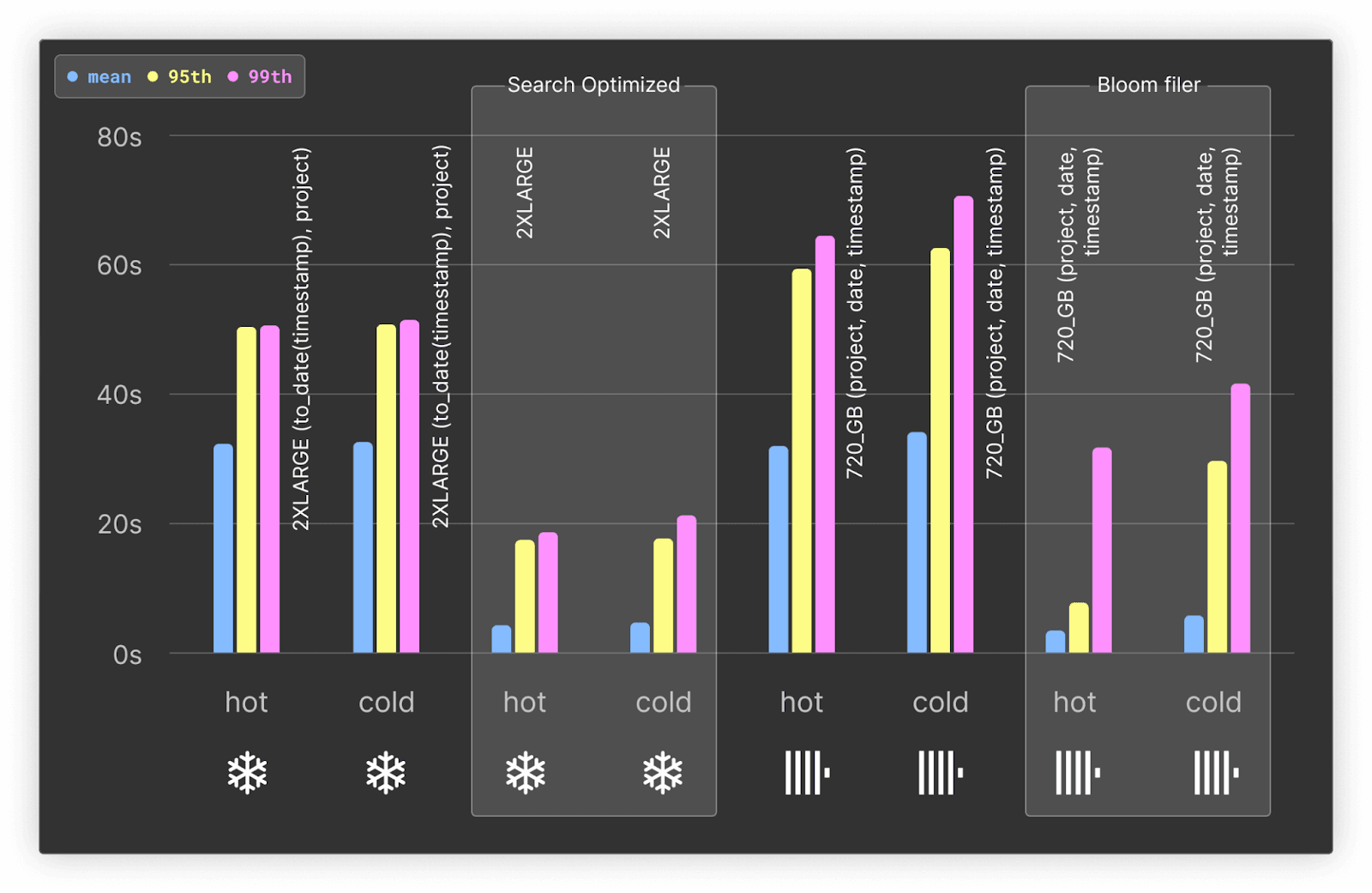
テストの結果、ブルームフィルタは ClickHouse 全体のストレージサイズ(圧縮後)に対して 81.75MiB の追加しか必要としません。圧縮前でも 7.61GiB 程度で、オーバーヘッドは最小限です。
ブルームフィルタを使わない場合、Snowflake と ClickHouse は LIKE クエリのパフォーマンスでほぼ同等になります。95 パーセンタイルや 99 パーセンタイルでは、Snowflake が最大 30% 上回ることさえあります。
しかし、ClickHouse のブルームフィルタを使用すると、ホットクエリ/コールドクエリいずれも平均で約 10 倍、上位パーセンタイルでも少なくとも 2 倍高速になります。
その結果、ブルームフィルタ適用時の ClickHouse は、すべての指標で Snowflake を上回り、最低でも 1.5 倍、平均では 9 倍ものパフォーマンス差を示します。 しかもブルームフィルタのコストはストレージ使用量が若干増えるのみで、追加費用が発生しません。
一方、Search Optimization Service を有効にした Snowflake では、パフォーマンスが大幅に向上します。ホットクエリにおいては依然として ClickHouse より平均的に遅い結果となりますが、コールドクエリと 99 パーセンタイルでは Snowflake が速い場合もあります。ただし、コスト分析で言及したように、この機能は非常に高額なため、実運用での利用は現実的ではない場合があります。
クエリ 7:1日あたりのダウンロード数(キャッシュあり) #
これまでのテストでは、Snowflake と ClickHouse それぞれのクエリキャッシュを無効にしていました。これは、リアルタイム分析のユースケースにおいて、クエリの内容が大きく変動してキャッシュヒットが起こりにくい場合や、基盤となるデータに変更が生じてキャッシュが無効化される場合など、より現実的なパフォーマンスを示すためです。それでもなお、今回私たちは「1 日ごとのダウンロード数」を集計する初期のクエリを用いて、それぞれのクエリキャッシュがパフォーマンスに与える影響を検証しました。
SELECT
toStartOfDay(date),
count() AS count
FROM pypi
WHERE (project = 'typing-extensions') AND (date >= (CAST('2023-06-23', 'Date') - toIntervalDay(90)))
GROUP BY date
ORDER BY date ASC
結果や詳細はこちらにあります。
ポイントは以下の通りです。
- ClickHouseのキャッシュは平均応答時間を大幅に下げますが、Snowflakeのほうが95・99パーセンタイルが安定して低いです。ClickHouseはノードローカルなキャッシュで、ロードバランサの動作状況などで応答のばらつきが生じます。Snowflakeはウェアハウスと独立した分散キャッシュが効いているため、結果がより安定しやすいと考えられます。ただし実運用では、データ更新があるとキャッシュが無効化されるので恩恵は限定的です。
- コールドクエリでは、ClickHouseはSnowflakeより1.5~2倍高速であり、CPU。
コスト分析 #
ここでは、ClickHouse CloudとSnowflakeのコスト比較を行います。ベンチマークを実施する際に、データのロード、ストレージ、クエリ実行にかかる費用がどれほどになるかを算出し、Snowflakeでリアルタイム分析を成立させるために必要となる追加コストを明らかにします。最後に、本番運用レベルの料金見積もり例も示します。
結論として、SnowflakeよりClickHouse Cloudのほうがすべての観点でコスト効率が優れていました。具体的には:
ベンチマークを実行する場合:
- データロード:SnowflakeはClickHouse Cloudの最低5倍のコストがかかります。
- クエリ:Snowflakeのクエリ実行コストは、ClickHouse Cloudの少なくとも7倍です。また同等レベルのクエリ性能をSnowflakeで実現しようとすると15倍のコストがかかります。
本番運用を想定する場合:
Snowflakeは最低でもClickHouse Cloudの3倍の費用がかかります。さらにClickHouse Cloudと同程度の性能をSnowflakeで発揮する場合は5倍の費用がかかる見込みです。
基本コスト #
SnowflakeとClickHouseの(us-central-1での)時間あたり料金は以下の通りです。
- Snowflake: 2X-LARGE - 1時間あたり32クレジット消費。クレジット単価はプランにより異なり、標準プランを2ドル/クレジットとすれば64ドル/時間です。
- ClickHouse: 708GB、177コアのサービス - 6 CPUごとに1時間あたり0.6888ドル、合計で1時間あたり20.3196ドル。
- ClickHouse: 960GB、240コアのサービス - 同様に6 CPUごとに1時間あたり0.6888ドル、合計27.552ドル/時間。
ベンチマークのコスト #
要約 #
| Database | Bulk Data Loading Cost ($) | Clustering Cost ($) | Storage Cost per month ($) | Cost of Query Benchmark* ($) |
|---|---|---|---|---|
| Snowflake Standard | 203 | 900 | 28.73 | 185.9 |
| Snowflake Enterprise | 304 | 1350 | 28.73 | 378.98 |
| ClickHouse | 41 | 0 | 42.48 | 25.79 |
* with clustering
今回のベンチマークを実行するだけでも、ClickHouse CloudはSnowflakeより圧倒的に安価でした:
- データロード:最低でもSnowflakeはClickHouse Cloudの5倍のコストが必要です。クラスタリングでさらにコスト増を考慮すると25倍に達します。
- クエリ:Snowflakeのクエリコストは最低7倍。これでもクエリ応答は数十秒かかり、ClickHouseは数秒以下です。同等の応答性能をSnowflakeで得ようとすると15倍のコストになります。
仮定 #
- Snowflake と ClickHouse には、それぞれ 2X-LARGE ウェアハウスと 708GB サービスを選択しました。これらはコア数がほぼ同等で、ベンチマーク全体で使用しています。
- グローバルにアクセス可能な Python パッケージの分析を提供するリアルタイム分析ユースケースを想定しているため、クエリは頻繁に実行されると見込まれます。このため、ウェアハウス/サービスがアイドル状態になることはないと想定しています。
- テストでは、Snowflake でエンタープライズ向けの機能(マテリアライズドビューや Search Optimization Service)を利用し、ClickHouse Cloud と同程度の性能を得られるようにしています。ただし、これらの機能を利用すると、Snowflake のコスト(クレジット単価)は増加します。そのため、Snowflake のコストは Standard と Enterprise の 2 通りで示しています。さらに、Snowflake のエンタープライズプランを利用すると、ロード(データ取り込み)のコストにも影響が及びます。
- クエリベンチマークのコストを算出する際は、エンタープライズプランや Standard プランといった構成の違いを考慮したうえで、最も高いパフォーマンスを示す構成の結果を採用し、すべてのクエリを実行するのに要した合計時間を、分単位で切り上げて計算します。
- クエリコストの算出には、サービスの分単位コストとクエリ実行に要した合計時間を掛け合わせています。Snowflake は 1 秒単位の課金ですが、ウェアハウスを起動するごとに最低 60 秒分の課金があります。ClickHouse Cloud は 1 分単位での課金です。そのため、ウェアハウスやサービスの起動および停止に要する時間は考慮していません。
- ClickHouse Cloud でデータをロードする場合は、最速のロード時間を示す 960GB サービスを利用し、ロード完了後にはサービスのサイズを縮小すると想定しています。
- Snowflake では、Cloud Services Compute による追加料金は発生しないものと仮定しています。また、Snowflake でより高度な機能を利用し、料金プランが変更される場合には、1 クレジットあたりの価格を調整して計算します。
- クエリコストを算出する際は、クラスタリングを有効にした結果を採用しています。これは、「クエリ 1:1日あたりのダウンロード数」 の結果からわかるように、Snowflake はクラスタリングキーなしでは ClickHouse に対抗できるほどの応答時間を達成できず、リアルタイム分析アプリケーションには十分でないためです。実際、このワークロードでクラスタリングキーを設定しない場合、Snowflake 2X-LARGE 環境での平均応答時間は 7.7 秒超となります。一方、最適なクラスタリングキーを設定すると、ClickHouse(708GB)では 0.28秒、Snowflake では 0.75秒という結果になります。この違いに基づき、その後のベンチマークではすべて Snowflake にクラスタリングを適用しています。
大量データのロード #
Snowflake のウェアハウスおよび ClickHouse のサービスについては、データロードの期間だけアクティブにし、データの挿入が完了次第ただちに停止すると想定しています。ClickHouse では、推奨上限である 3,000 個未満になるようパーツを削減するマージ処理に要する時間も考慮しています。
| Database | Specification | Number of vCPUs | Cost per hour ($) | Time for data load (seconds) | Bulk Data load cost ($) |
|---|---|---|---|---|---|
| Snowflake (standard) | 2X-LARGE | 256 | 64 | 11410 | 202 |
| Snowflake (enterprise) | 2X-LARGE | 256 | 96 | 11410 | 304 |
| ClickHouse | 708GB | 177 | 20.3196 | 10400 (174 mins) | 59 |
| ClickHouse | 960GB | 240 | 27.552 | 5391 (90 mins) | 41 |
Snowflakeは、同等vCPUの場合でも、ClickHouse Cloudより5倍近い費用がかかります。
なお、外部ステージを使ってロードしているため、Snowflakeのステージへのアップロード代は考慮していません。内部ステージを使うとSnowflakeで追加コストがかかります。
クラスタリングコスト #
前述のとおり、Snowflakeでクラスタリングなしだとクエリが7秒以上かかり、リアルタイム分析としては遅すぎます。そのためクラスタリングを使う前提で、ベンチマーク時に450クレジット(900ドル、標準プランの場合)を追加で消費しました。ClickHouse CloudではORDER BYによる追加課金はありません。
標準プランでもクラスタリング込みでSnowflakeは1100ドル超(203 + 900)となり、ClickHouse Cloudの27倍以上のコストです。今後データを追加入力するときも、クラスタリングが継続的に動き続けるためSnowflakeのコストはさらに上がる可能性があります。
ストレージ #
Snowflake と ClickHouse Cloud は、ベンチマークを実施した GCP us-central-1 リージョンで以下のストレージ料金を適用しています。他のリージョンでは料金が異なる場合がありますが、どちらの場合も全体コストに対して大きな割合を占めないと想定しています。いずれのサービスも、データの圧縮後サイズを基準として料金を計算します。
- ClickHouse: 1TB(圧縮後)あたり月額 $47.10
- Snowflake: 1TB(圧縮後)あたり月額 $46
上記の ClickHouse ストレージコストには、2 日分のバックアップ(24 時間ごとに 1 回)が含まれています。Snowflake で同等のデータ保持を行うには、本番運用において permanent table を使用し、1 日分の Time Travel を有効にすることを想定しています。これにより、デフォルトで 7 日間の FailSafe サポートも提供されます。
私たちのデータは不変かつ追記専用であるため、テーブルの更新頻度は非常に低く、初期コピーを除けば、新たに追加されるデータの Time Travel に要するコストだけが加算される想定です。これにより、7 日ごとにおよそ 8% の増加が見込まれるため、Snowflake には 1.08 の係数を適用すると見積もりました。
また、ほとんどのベンチマークでクラスタリング/オーダリングキーを利用していると想定しています。以上の料金モデルを用いて、1 か月あたりの総コストを算出しています。
| Database | ORDER BY/CLUSTER BY | Total size (TB) | Cost per TB ($) | Backup multiplier | Cost per month ($) |
|---|---|---|---|---|---|
| Snowflake | (to_date(timestamp), project) | 1.33 | 46* | 1.08 (for time travel) | $66.07 |
| ClickHouse | (project, date, timestamp) | 0.902 | 47.10 | 1 | $42.48 |
*on demand pricing
Snowflakeのオンデマンド料金では、Snowflakeのほうが1.5倍ほど高くなります。プリペイドが可能であれば1TBあたり20ドルにもできますが、その場合でも1.33×20×1.08=28.73ドルほどで、わずかにClickHouseと近い値になります。
クエリ #
Snowflake におけるコストの見積もりは複雑です。Snowflake でクエリを高速に実行するには、マテリアライズドビューや Search Optimization Service など、エンタープライズプランのみ利用可能な標準外の機能を使う場合があります。これにより、クレジットあたりのコストは $3 に上昇します。これらのサービスは追加コストも発生し、たとえば マテリアライズドビュー ではバックグラウンドでのメンテナンス費用が必要になります。Snowflake は、マテリアライズドビュー のように、こうしたコストを把握するための方法を提供しています。
クエリのコストを推定するにあたり、Snowflake 2X-LARGE ウェアハウス、708GB の ClickHouse サービスを用いて、それぞれのクエリタイプにおける最適構成の実行時間を基準としました。
Snowflake に関してはエンタープライズプランとスタンダードプランの 2 パターンでコストを計算しています。どちらの場合も、プラン(ティア)に応じて最速となる構成で計測したトータル実行時間を使用し、テスト完了と同時にウェアハウスを即時に停止すると楽観的に仮定しています。ClickHouse の実行時間は分単位で切り上げて計算しています。
また、Snowflake のメインテーブルに対する初回のクラスタリング費用はデータロード作業の一環とみなし、別途計上していませんが、マテリアライズドビュー用のクラスタリング費用については考慮しています。
クエリキャッシュが有効な場合の結果は考慮していません。これは、本番環境ではデータの更新や変更が行われ、キャッシュが無効化される可能性が高いと想定しているためです。本番環境であっても、両方のデータベースでキャッシュを有効化することを推奨します。キャッシュの結果は両システムでほぼ同等であるため、コスト比率には大きな影響がないと考えられます。
ClickHouse
| Test | Ordering columns | Features used | Cost per hour ($) | Total run time (secs) | Total Cost ($) |
|---|---|---|---|---|---|
| Query1: Downloads per day | project, date, timestamp | - | 20.3196 | 302 | $2.032 |
| Query 2: Downloads per day by Python version | project, date, timestamp | - | 20.3196 | 685 | $4.064 |
| Query 3: Downloads per day by system | project, date, timestamp | Materialized views | 20.3196 | 600 | $3.387 |
| Query 4: Top file type per project | project, date, timestamp | Materialized views | 20.3196 | 56 | $0.339 |
| Query 5: Top projects by distro | project, date, timestamp | - | 20.3196 | 1990 | $11.232 |
| Query 6: Top sub projects | project, date, timestamp | Bloom filters | 20.3196 | 819 | $4.741 |
| Total | 4452 | $25.79 |
Snowflake Standard
| Test | Clustering columns | Cost per credit ($) | Cost per hour ($) | Total run time (secs) | Total cost ($) |
|---|---|---|---|---|---|
| Query1: Downloads per day | date, project | 2 | 64 | 635 | $11.28 |
| Query 2: Downloads per day by Python version | date, project | 2 | 64 | 1435 | $25.51 |
| Query 3: Downloads per day by system | date, project | 2 | 64 | 1624 | $28.87 |
| Query 4: Top file type per project | date, project | 2 | 64 | 587 | $10.44 |
| Query 5: Top projects by distro | date, project | 2 | 64 | 1306 | $23.22 |
| Query 6: Top sub projects | date, project | 2 | 64 | 4870 | $86.58 |
| Total | 10457 | $185.9 |
Snowflake Enterprise
| Test | Clustering columns | Enterprise Features used | Cost per credit ($) | Cost per hour ($) | Total run time (secs) | Warehouse Cost ($) | Additional charges | Total cost ($) |
|---|---|---|---|---|---|---|---|---|
| Query1: Downloads per day | date, project | - | 2 | 64 | 635 | $11.289 | - | $11.29 |
| Query 2: Downloads per day by Python version | date, project | - | 2 | 64 | 1435 | $25.5111 | - | $25.51 |
| Query 3: Downloads per day by system | date, project | Clustering + Materialized views | 3 | 96 | 901 | $24.027 | 61.5 credits for materialized view = $184.5 5.18 credits for clustering = $15.54 | $224.07 |
| Query 4: Top file type per project | date, project | Clustering + Materialized views | 3 | 96 | 307 | $8.187 | 0.022 credits for clustering = $0.066No materialized view charges noted. | $8.25 |
| Query 5: Top projects by distro | date, project | - | 2 | 64 | 1306 | $23.218 | - | $23.22 |
| Query 6: Top sub projects | date, project | Clustering + Search Optimization Service | 3 | 96 | 684 | $18.24 | Search optimization charges - 22.8 credits = $68.4 | $86.64 |
| Total | 5268 | $378.98 |
Snowflake のクエリコストは、今回のベンチマークテストにおいて、ClickHouse Cloud と比べて最低でも 7 倍高くなるという結果が得られました。また、Snowflake のクエリパフォーマンスを ClickHouse Cloud に近いレベルにするためにエンタープライズ機能を利用すると、コストは 15 倍にも跳ね上がります。
上記の結果から、Snowflake でエンタープライズ機能を使うとクエリコストが急激に膨らむことが明らかです。これらの機能はほとんどの場合パフォーマンスを大きく向上させるものの、実行時間の短縮だけではクレジット単価の上昇分を相殺できないことがあります。そのため、ユーザーはクエリごとに最も費用対効果の良い手段を見極める必要に迫られます。一方、ClickHouse では高速化のための機能に対して追加料金が発生しないため、料金体系がシンプルです。
さらに、今回のシナリオでは、エンタープライズ機能が不要なテストにおいては Standard プランの料金を適用できると仮定し、Snowflake のコストをわずかに引き下げています。しかし、実際の本番環境でいったんエンタープライズ機能を有効にすると、Snowflake 上の他のすべてのクエリコストも一律で 1.5 倍になり、複雑な構成変更やデータの重複管理が必要になる場合があります。
本番環境でのコスト見積もり #
これまでのベンチマークのコスト分析は、Snowflake でどのようにコストが急激に増えるかを示すうえでは有用ですが、それをそのまま本番環境に当てはめるのは難しい面があります。
そこで、以下のような単純化した価格モデルを前提とします:
- ウェアハウス / サービスは常時稼働し、アイドル状態にはならないと仮定します。これは常にデータを取り込み(ingest)し、リアルタイムクエリに応答し続けているためです。
- データセット全体は実際には約 10 倍のサイズがありますが、アプリケーションに必要なのは最新 3 か月分で十分だと想定します。
- 2X-LARGE(Snowflake)と 708GB(ClickHouse)のウェアハウス / サービス構成で、アプリケーションに必要とされるレイテンシ要件を十分に満たせると想定します。
- 2X-LARGE(Snowflake)と 708GB(ClickHouse)であれば、本番アプリケーションで想定されるクエリの同時実行数をさばけるとします。
- 2X-LARGE(Snowflake)と 708GB(ClickHouse)は、新しいデータが追加されても著しくパフォーマンスが低下しないと考えます。
- Snowflake においては、初回ロード後のクラスタリング維持コストはさほど大きくならないと強気に仮定します(実際にはもっとかかる可能性があります)。
- ここでは、初期のデータロードコストは考慮しません。なぜならウェアハウス / サービスを常に稼働させる前提だからです。
これらを前提にすると、本番運用にかかるコストはストレージと、ウェアハウス / サービスを稼働させる時間の費用となります。Snowflake については、スタンダードプラン(Standard)とエンタープライズプラン(Enterprise)の 2 種類のコストを提示します。後者(Enterprise)の方が ClickHouse Cloud により近いクエリ応答時間を出せますが、Snowflake 側の料金は 1.5 倍になります。
一方 ClickHouse では、使用可能な箇所ではマテリアライズドビューやプロジェクションを活用することを想定しています。これらは追加コストがほぼかからない機能です。
最後に、Snowflake の 4X-LARGE ウェアハウスを使った場合の価格も示します。ユーザーによっては、クラスタリングを行わずに大きなウェアハウスを使うほうが良いと考える場合もあるかもしれません。クエリ速度はやや遅くなりますが、Snowflake が示している線形スケーラビリティを踏まえると、クラスタリングなしでも 2X-LARGE の 4 倍程度の性能が期待できます。たとえば 1日あたりのダウンロード数 テストで、2X-LARGE で平均 7.7 秒かかっていたクエリは、4X-LARGE であれば 2 秒未満に収まる可能性があります。
| Database | Specification | Compute Cost per hour ($) | Compute Cost per month ($) | Data Storage Cost per month ($) | Total Cost per month ($) |
|---|---|---|---|---|---|
| Snowflake (standard) | 2X-LARGE | 64 | $46,080 | $28.73 | $46,108 |
| Snowflake (Enterprise) | 2X-LARGE | 96 | $69,120 | $28.73 | $69,148 |
| Snowflake (standard) | 4X-LARGE | 256 | $184,320 | $28.73 | $184,348 |
| ClickHouse | 708GB | 20.3196 | $14,630 | $42.48 | $14,672 |
上記の結果から、Snowflake を本番環境で稼働させるためのコストは、ClickHouse Cloud と比較して 3 倍以上高いことがわかります。また、両システムのパフォーマンスを同程度にするためにエンタープライズティアの機能を利用する場合、Snowflake のコストは ClickHouse Cloud の約 4.7 倍になります。
実際には、上記の試算には含まれていない Snowflake 固有の追加料金もあり、差はさらに大きくなると考えられます。たとえば以下のようなものです:
- 新しいデータが追加される際のクラスタリング費用。シンプルにするため上記の見積もりでは除外していますが、ベンチマークでは無視できないレベルでコストが増加しました。クラスタリングを行わない 4X-LARGE 構成は、実際には実用的ではなく、競合力も低いと考えられます。
- マテリアライズドビューを使用する場合の維持コスト。特にクラスタリングと組み合わせると、ベンチマークで示したように大きなコストが発生することがあります。
- データ転送料。Snowflake ではリージョンによっては発生する場合があり、ClickHouse Cloud ではデータ転送料は不要です。
- データステージング費用。今回のテストでは外部ステージを用い、GCS バケットから単にデータをインポートしたため発生しませんでしたが、Snowflake の内部ステージを使用する場合は費用が発生することがあります。ClickHouse Cloud にはステージの概念がありません。
実際の運用環境では、さまざまな制約が存在します。異なるスペックのシステムをベンチマークした後、本番で使用するサイズを決定する必要があるでしょう。ワークロードの特性によってキャパシティプランニングの要件も変わります。たとえば一定期間内に処理しなければならない作業量や、低レイテンシを維持しながら同時に処理できるクエリ数など、さまざまな制限があります。いずれにせよ、一定の期間内に処理しなければならない作業量は必ず存在します。
以下に、クラスタを 100% 稼働させつつ、一度に一つのベンチマークを回し続けた場合、1 日あたりに処理できる作業量がどのように変わるかの一例を示します。
| Database | Specification | Total benchmark time (s) | Benchmark runs per day | Compute cost per day | Benchmark runs per $1k |
|---|---|---|---|---|---|
| Snowflake (standard) | 2X-LARGE | 10457 | 8.26 | 1536 | 5.37 |
| Snowflake (Enterprise) | 2X-LARGE | 5268 | 16.40 | 2304 | 7.11 |
| ClickHouse | 708GB | 4452 | 19.40 | 488 | 39.76 |
上記の結果から、同じコンピュートコストで比較した場合、ClickHouse は Snowflake の 5.5 倍の作業量を処理できることがわかります なお、すでに述べたように、Snowflake はマテリアライズドビューやクラスタリングなどのクエリ高速化機能を利用すると、コストが大幅に上昇する傾向があります。
結論 #
本記事では、Snowflake と ClickHouse Cloud をリアルタイム分析の観点から包括的に比較しました。その結果、今回のベンチマークにおいては、より実践的なアプリケーションを想定した場合でも コストとパフォーマンスの両面で ClickHouse Cloud が Snowflake を上回る ことが示されています。
- 本番環境におけるコスト効率は、ClickHouse Cloud が Snowflake より 3〜5 倍優れています。
- ClickHouse Cloud のクエリ速度は、Snowflake より 2 倍以上高速です。
- データ圧縮率は ClickHouse Cloud が Snowflake より約 38% 優れています。
リアルタイム分析の要件を満たしながらコストも抑えたい場合、ClickHouse Cloud は非常に有力な選択肢となると言えるでしょう。
こちらからお問い合わせいただければ、ClickHouse Cloudを使ったリアルタイム分析について詳しくご案内します。あるいはこちらから今すぐClickHouse Cloudを始めてみてください。300ドル分のクレジットが付与されます。



