
これは、Azur Gamesのリードソリューションアーキテクト、Vladimir Rudev氏によるゲスト投稿です。
昨年、当社は既存の技術ソリューションがもはや当社の成長するニーズを満たしていないことに気づきました。技術的負債が手に負えなくなっていたため、大規模なインフラの刷新が必要であることは明らかでした。
当社は長年ClickHouseを使用していたため、AWS上のClickHouse Cloudを検討することは理にかなっていました。
課題は、分析にダウンタイムを引き起こすことなく、120TBのデータベースを移行し、シームレスな移行を保証することでした。この目標を達成するために、「完全複製」、検証、およびアトミックな切り替えアプローチを選択しました。これだけのデータがどこから来たのか疑問に思うかもしれません。ダウンロード数でトップのモバイルゲームパブリッシャーとして、当社は150を超えるプロジェクトを立ち上げ、合計80億以上のインストール数を達成しています。当然のことながら、これにより膨大な量のテレメトリーデータが生成されます。
ハイパーカジュアルゲームとは、参入障壁が低い、シンプルでプレイしやすいモバイルゲームです。このようなペースの速いシンプルなゲームは、プレイヤーの行動を理解し、収益化を最適化し、実験を行い、全体的なゲーム体験を向上させるために重要な、ユーザーインタラクションからの大量のテレメトリーデータを生成します。これは、Azur Gamesが開発するカジュアルゲームやミッドコアゲームにも当てはまります。データ分析の要件は、すべてのジャンルに当てはまります。
この記事では、移行がどのように進んだか、直面した課題、そして得られた利点について詳しく説明します。
ネタバレ:移行を成功させただけでなく、多くのポジティブな結果も体験しました。クラウドへの移行後の最終的なサービスコストは、以前とほぼ同じでした。さらに、2人のエンジニアの時間の半分を解放し、多くのストレスを軽減し、メンテナンスから創造的な、より興味深いタスクに焦点を移しました。

それでは、プロセスをポイントごとに見ていきましょう。
私たちが達成しようとしていた主な目標:
- ストレージの信頼性を向上させる。
- 運用上の信頼性を向上させ、障害の数を減らす。
- メンテナンスを簡素化する。
- 成長のための柔軟性を確保する。
- 予算に合わせてコストを最適化する。
私たちの出発点:
リソース:
- 20台の強力なデータベースサーバー + ZooKeeper用の3台の低電力サーバー。
- 11台のAirflowサーバー(200+ vCPU)。
- 6台のMinIOサーバー(S3エミュレーター、Airflowキャッシュ)。
- 4台のMySQLデータベースサーバー。
- BIおよびサポートサービス用の4台のサーバー。
- 2人のAirflowエンジニア。
- 1人のDevOpsエンジニア。
合計:45台のサーバーと3人の専門家。
また、多くのマネージドユニットがあり、最も重要な7つのユニットは、CH、ZK、MySQL、MinIO、Airflow(スケジューラー、ワーカー)、およびBIです。
ツール:
- すべてのサーバーを管理するAnsible。
- 2年前のAirflow 2.2.3。
- MinIOのバージョンも2年前のもの。
- 2年以上前のClickHouse 21.3。
懸念事項 #
TL;DR: 単一のディスク障害がシャード全体の崩壊につながるリスクが大きな懸念事項でした。これにより、一部のプロジェクトで長期間データが完全に利用できなくなる可能性があります。最も恐ろしいのは、データドライブの連鎖的な故障でした。
この問題は、ディスクの使用量が大きい長期実行プロジェクトでは珍しくありません。サーバーにインストールされているディスクは同じバッチからのものであることが多く、同じようなタイミングで故障する傾向があります。稼働時間が同じということは、故障の確率も同じであることを意味します。1つのディスクが故障すると、隣接するディスクへの負荷が増加します。RAID 10で構成された当社のサーバーでは、ディスクはペアで動作するため、1つのディスクの故障は、そのコピーであるパートナーディスクも故障する可能性を高める可能性があります。同じグループのディスクのペアが故障した場合、サーバー全体がダウンします。
1つのレプリカが3〜6時間ダウンしても心配はありません。ただし、15TBのドライブが故障した場合、同期には約1週間かかることがあります。この間に別のパートナーディスクが故障した場合、サーバー全体が故障し、レプリカの再同期には3日から1週間かかる可能性があります。この期間中、残りのレプリカはETLプロセスと新しいサーバーへの同期で過負荷になります。そのため、各レプリカの負荷が60%以下で、シャードあたり3つのレプリカを持つことが推奨されていますが、これは非常に高価です。
2番目の大きな問題はMinIOでした。MinIOをライブで更新することは危険でした。ボリュームが増加するにつれて、サービス障害が頻繁になり、MinIOクラスターにリソースを追加してもほとんど効果がありませんでした。何か間違ったことをしているか、まだ特定できていない特定のバージョンのMinIOのバグに遭遇しているかのどちらかであることは明らかでした。時間の経過とともに、障害が頻繁になり、ETLプロセスがクラッシュするようになりました。Airflowエンジニアは、故障したETLの確認と復元にかなりの時間を費やす必要がありました。
要約すると、私たちが慣れ親しんだ2つの主な問題点がありました。
- 管理者は、アップデートを伴わない簡単な修正では解決できないソフトウェアクラッシュが発生した場合に苦労しました。
- Airflowエンジニアは、ETLプロセスが中断した場合に常に混乱に直面しました。これは、何かが故障するたびに何らかの形で発生しました。これは、データの可用性のタイムラインと新機能の開発に影響を与えました。
これらの問題を最小限に抑えるために可能な限り自動化しましたが、ETLのサポートにはかなりの時間が必要であり、士気に影響を与えました。
ClickHouse Cloud以外の検討した代替ソリューション #
適切なソリューションを見つけるにはかなりの時間がかかりました。対処する必要がある主なタスクを思い出してください。
- ストレージの信頼性。
- 運用上の信頼性。
- メンテナンスの容易さ。
- 成長の柔軟性。
- 予算に対する最適なコスト。
選択肢は次のとおりでした。
1. ベアメタルにとどまるが、プロバイダーを変更する — その他は現状維持
これにより4番目のポイントに対処できますが、コストは同じにはなりません。
2. AWS/Google/Azureに移行する
適切に構成されていれば、このオプションはストレージの信頼性、運用上の信頼性、およびコストの柔軟性の問題を解決できる可能性があります。Kubernetesに関する専門知識があれば、メンテナンスの容易さにも部分的に対処できます。
ただし、コストの問題は依然として解決する必要があります。詳細な説明は次のとおりです。ClickHouse CloudなしでAWSに移行すると、より強力なハードウェアが提供されますが、データ量が多いため、価格が大幅に高くなります。AWSは、単一の「ファット」サーバーの使用を許可することで、非効率的な構成を緩和できます。複数の小さなシャードの代わりに1つの大きなシャードを使用し、そこに大量のドライブを入れることができますが、少なくとも2つのレプリカが必要になります。これは、ディスク上で240TBのデータを管理することを意味し、その他の費用を含めずに、ストレージだけでも数千ドルの追加費用がかかります。したがって、コストは依然として大きな懸念事項です。
データをホットストレージとコールドストレージに分割して、コストを半分にする可能性もあります。ただし、これらのソリューションには、高度な資格を持つエンジニアによる広範な計画、テスト、および時間が必要です。今後の速度とサービス品質を損なうことなく、当社のデータ処理パターンに適した適切な構成を見つけることが課題です。
3. 以前のプロバイダーにとどまるが、そのフレームワーク内で移動する
このオプションにより、最新のソフトウェアバージョンにアップデートし、いくつかの技術的負債に対処できます。ただし、他の目標には表面的な部分しか触れません。
ClickHouse Cloudを選んだ理由 #
AWS PrivateLinkを介してシームレスに接続されたClickHouse Cloudは、ディスクの代わりにS3にデータを保存する機能や、ゼロコピーレプリケーション(ZCR)などの機能により、大幅なコスト削減を実現します。後者はここで重要な役割を果たします。ZCRでは、データのコピーを2つ保存せずに、シャードに2つのレプリカを持つことができます。このようにして、保存されたデータのボリュームは、その実際のサイズと同じになります。
S3は、ストレージに使用される従来のディスクよりも低コストで99.999999%のデータ耐久性を提供します。
移行の結果 #
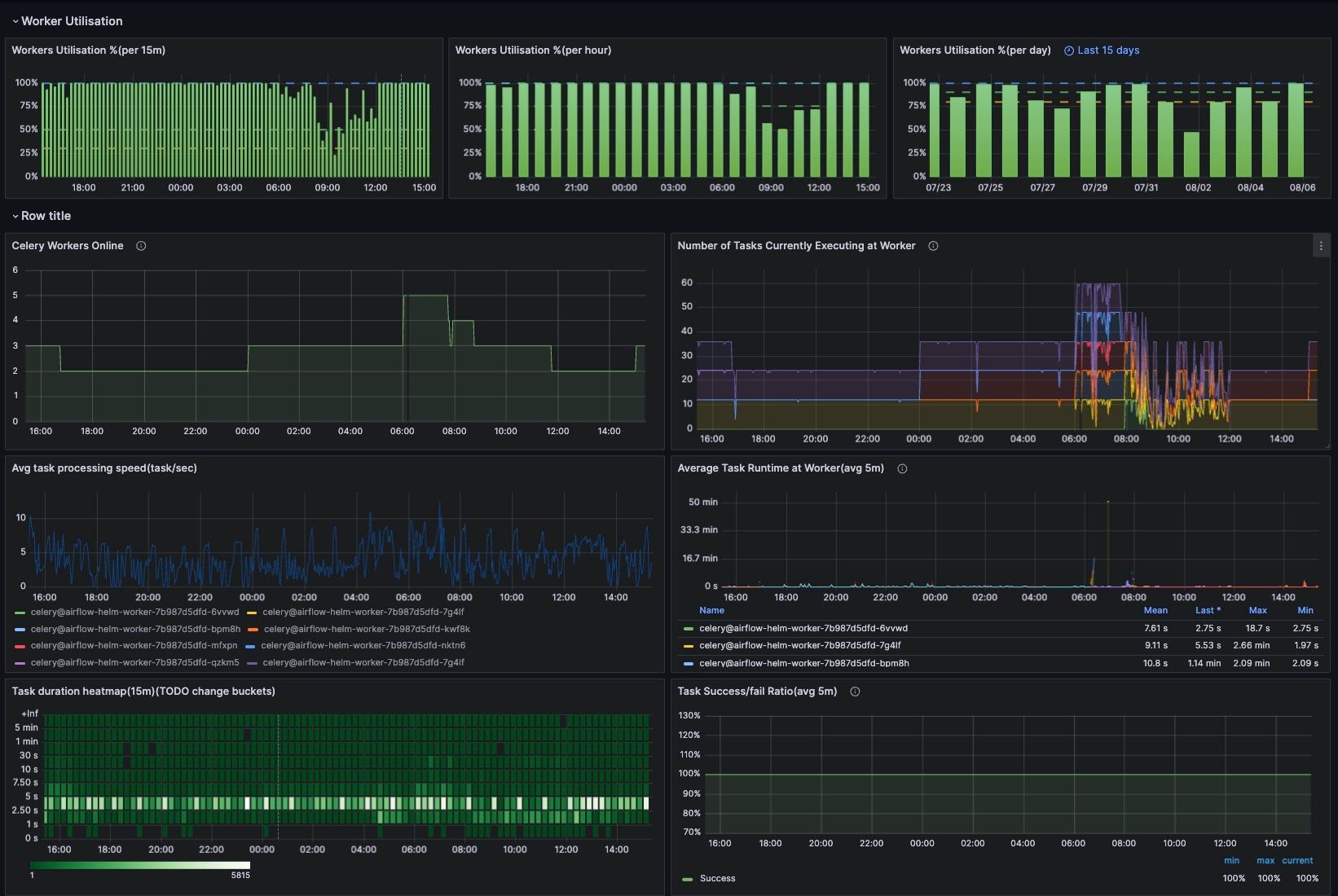
ハードウェア:
- Airflowは現在、24〜40 vCPUで動作しており、自動スケーリングに対応しています。
- ClickHouseには現在、S3上のすべてのデータを持つ3つのレプリカがあります。すべてのリクエストは実際のボリュームでテストされており、古いClickHouseセットアップよりもパフォーマンスが劣るものはありません(これは重要であり、何度も再確認しました)。
- リクエストの大部分は現在より高速に処理され、残りはほぼ同じパフォーマンスで実行されます。
- 残りのデータベースは現在、RDSに含まれています。
- 管理者とETLエンジニアの負荷が大幅に軽減されました。
- 総コスト(ClickHouseデータベース + ETLインフラストラクチャ)はわずかに増加しましたが、ほぼ同じです。
目標はどうなりましたか?
-
ストレージの信頼性:すべての重要なユニット(DB、S3)は、信頼性を保証する「サービス」に含まれています。多くの複雑なタスクをオフロードしたため、SaaSソリューションは比較にならないほど安価になりました。
-
運用上の信頼性、成長の柔軟性、および最適なコスト:100%達成。
-
メンテナンスの容易さ:80〜85%解決しました。問題は完全には解消されませんでしたが、大幅に軽減されました。投資したリソースを考えると、これは良い結果であり、エンジニアの時間を大幅に節約したため、わずかなコスト増を十分に補っています。
-
成長の柔軟性:100%達成。
-
2人のエンジニアの3か月間のフルタイム作業と私の1か月の移動期間を費やしました。サービスのコストはほぼ同じであるだけでなく、得られたメリットによって何度もカバーされています。
複雑さの軽減:
-
Amazon S3に置き換えられたMinIO。
-
3つの異なるAirflowデプロイメント。優れたハードウェア上の最新バージョンが、すべての負荷を完璧に処理します。
-
古いサーバーのセットアップとメンテナンスのための多数の不要な構成とスクリプト。
得られた利点:
-
システム全体がよりシンプルになり、高速になり、信頼性が高くなりました。
-
コードと結果の間の管理者の層が薄くなりました。私たちのチームは、より多くの制御と機能を備え、管理者に関与せずにそれらを使用できます。管理者を関与させることなく、Pythonに必要なソフトウェアを追加したり、スケールアップやスケールダウンを行ったりできるため、ルーチン操作の中間ステップが削減されます。
-
Amazonから優れたハードウェアを受け取りました。これは、新しいAirflowに特に当てはまります。高速S3は、超高速ネットワークとディスクとともに、ETLを大幅に高速化しました。
-
必要に応じて、数分で2倍、5倍、または10倍にスケールアップする機能を取得しました。たとえば、データプロバイダー側で統合が一時的に破損し、通常よりも多くのデータを迅速に受け入れる必要がある場合などです。
-
最新バージョンのClickHouseを受け取り、ClickHouseチームが管理するローリングベースでの継続的なアップグレードを受けました。これには、試してみる必要がある多くの新機能と最適化が含まれています。
- すべてを計算するための新しい便利な関数。
- クエリの一部を高速化できる最適化。
- データストレージに関連する新機能。これらは、スペース(コストに影響します)を節約し、クエリを高速化できる可能性があります。
- ETLをより高速、より信頼性が高く、より単純にするのに役立つ機能。
-
実験が必要なタスクはより迅速に完了します。最近では、最適なサーバーパラメーターを選択するとき、新しい構成が適用される前に紅茶を入れる時間さえありません。結果をすぐに確認できるのは常に良いことです。待っている間に別のタスクに切り替える必要はありません。
-
実験は現在管理可能です。私は常に頭の中に「より良くできること」のリストを持っており、ほとんどがデータに関連しています。データのストレージと記録回路の大幅な見直しを必要とする実験は、以前はディスクに負担をかけていましたが、これはもはや心配する必要はありません。このプロセスは古いClickHouseでは気が引けましたが、今はそうではありません。故障の心配なく、新しいClickHouseを好きなだけロードできます。
ビジネスへの影響 #
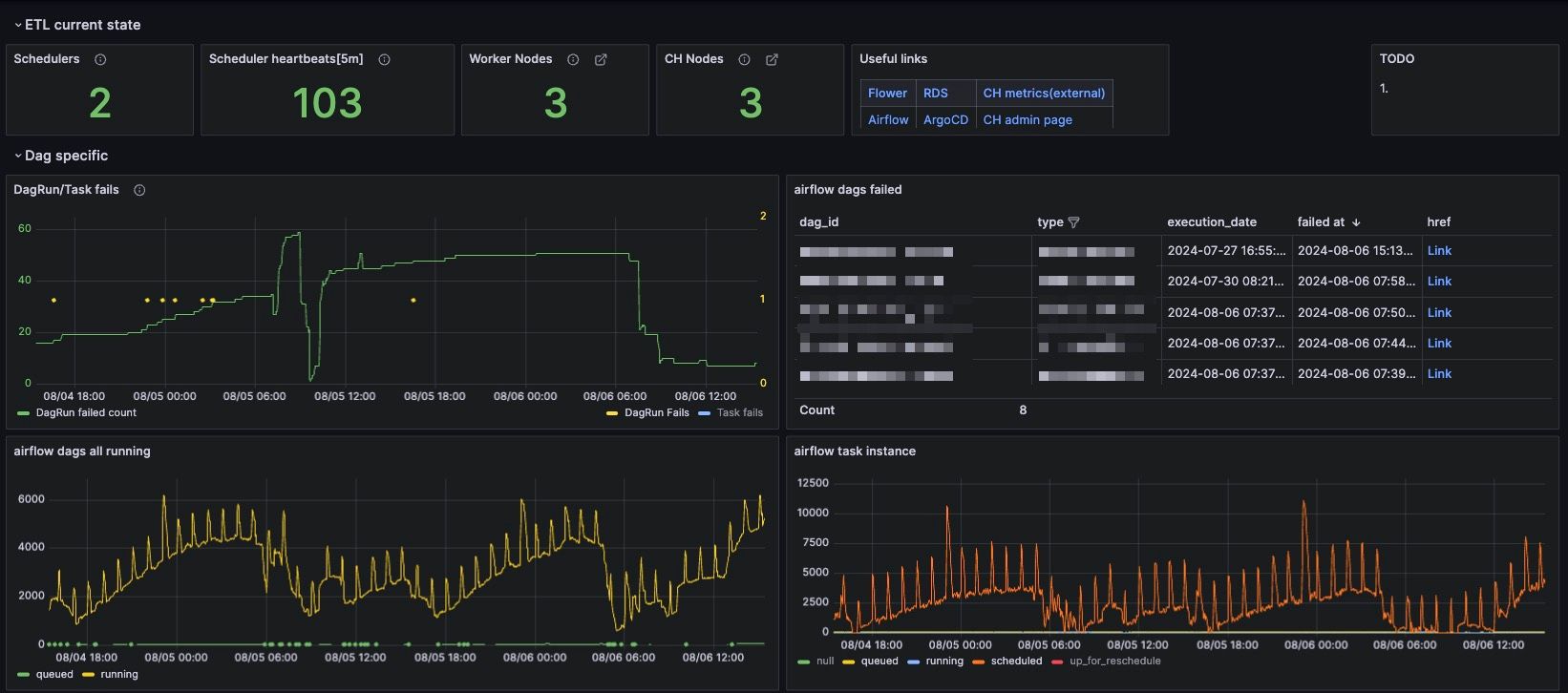
主な利点は、従業員の時間を節約できることです。これにより、よりエキサイティングで戦略的なタスクに時間を費やすことができます。当社の管理者の1人は時間の約60%が解放され、ETLエンジニアは現在時間の40%を節約しています。
これはまた、多くのストレスを軽減しますが、道徳的な要素を計算するのはより困難です。現在、複雑なインフラストラクチャを常に維持する代わりに、創造に焦点を当てることができます。 会社には常に興味深いタスクのバックログがあります。たとえば、現在分析で広く使用されており、当社のニーズに完全に適合しているDBT(データ構築ツール)の実験をようやく開始することができました。
さらに、多くのビジネスタスクが以前よりもはるかに早くリリースされるようになりました。多くの場合、費やされた時間が2倍以上短縮されました。
典型的な例は、履歴全体に対して再計算する必要がある新しいデータ集計の必要性です。
以前は、これを行うために、クラスターで利用可能な空きリソースを計算し、その速度を見積もり、計算量で乗算し、完了の締め切りを取得する必要がありました。すべてが順調に進み、重大な障害がなく、クラスターが安定したままであると仮定しました。
現在では、ETL側とDBMS側の両方でコンピューティングパワーを瞬時に追加できます。これは、タスクが使用されたリソースに比例してより高速に完了することを意味します。
正確なリソースコストでより早く結果を達成することで、ビジネスは当然恩恵を受けます。
新しい問題はありましたか? #
正確には新しい問題ではありませんが、新しい現実です。クラウドでの生活は異なるルールに従います。クラウドは通常、コストの面で容赦がありません。ネットワーク経由で送信されたすべてのバイトと使用されたすべてのプロセッササイクルに対して料金を支払います。そして、その可能性を最大限に活用しない場合でも、アイドル状態で実行されています。これにより、効率を最大化するためのアルゴリズムとアーキテクチャを実装する必要が生じます。
ただし、これはすべて良い影響をもたらします。非常に高速なスケーリングと超強力なハードウェアと組み合わせることで、最小限の労力でシステムのパフォーマンスを数倍向上させることができます。
新しいクラスターのアーキテクチャも、以前のアーキテクチャとは大きく異なります。以前はうまく機能していたものが、新しいクラスターでは非効率であることがわかりました。しかし、同じ問題に対処するための新しいソリューションが登場しました。移行中に、私たちは新しい現実に適応しました。
移行タイムライン #
7月。 移行に関する積極的な作業を開始しました。1か月間、ClickHouseチームと協力し、徐々に製品に慣れ、小規模な実験を実施しました。
8月。 入念な試行が必要であることを認識し、データの移行を開始しました。必要なリファクタリングも約1か月かかるため、1か月以内、または最大でも6週間以内に転送を完了することを目指しました。ここで最初のミスが浮上しました。2人のエンジニアがビジネス関連のタスクで頻繁に気を散らされており、遅延が発生しました。その結果、計画された時間枠内でいくつかのことしか完了できませんでした。
9月。 データ移行と必要な調整に1か月を費やしました。
10月。 この月は当初、セーフティネットとして計画されていました。保留中のタスクを完了し、徹底的なテストを実施しました。9月末までに、以前は気づいていなかったデータマージプロセスに問題があることを発見しました。10月前半はデータの追加を続けました。後半は、すべてのデータが正しく転送されていることを確認することに重点を置きました。努力にもかかわらず、作業は10月末までに完了する必要がありました。
11月。 残り1か月となり、少し息を整えて、より細心の注意を払ってデータの転送と検証に集中できるようになったようです。正確さが最優先でした。チームは素晴らしい仕事をしてくれました。11月中旬までに、分析を新しいシステムに切り替える準備がほぼ整いました。
11月21日に切り替えを行いましたが、すぐに2つの不快なバグに遭遇しました。ClickHouseの一部のクエリが、予想とは異なる動作をし始めました。問題をClickHouseチームに報告したところ、最初の問題に対する回避策が迅速に提供され、2番目の問題はClickHouse側で修正されました。
11月23日までに、BI操作を新しいClickHouseシステムに切り替えました。
11月27日に契約を締結し、古いサーバーをシャットダウンしました。
合計: 3か月の積極的な作業。
ClickHouseチームと協力する理由 #
ClickHouse Cloudのアーキテクチャは、従来のオンプレミス設定とは大きく異なります。これにより、テストフェーズ中にいくつかの問題が発生しました。ClickHouseチームは非常に協力的で、代替ソリューションを見つけるのを手伝ってくれ、当社のニーズに合わせてClickHouseのコードを迅速に変更してくれました。
まとめ #
わずか3か月で、より技術的に高度な新しいソリューションを展開しました。これにより、ストレージとサービスの信頼性をほぼ100%達成し、将来の成長の可能性を提供し、エンジニアの時間を大幅に解放することができました。これらの改善から得られた利点は、メンテナンスコストのわずかな増加を十分に正当化します。



