Open Houseでは、ワークショップ、技術的な深掘りセッション、製品発表、デモ、そしてリアルタイムデータの今後についての議論を通じて、ClickHouseコミュニティが3日間にわたり一堂に会しました。イベント期間中、多くのユーザー、顧客、そしてオブザーバビリティコミュニティのメンバーと直接お会いできたことを大変嬉しく思います。
直接参加できなかった方々のために、Open Houseで発表したオブザーバビリティ関連の内容をまとめてご紹介します。
ClickStackおよびオブザーバビリティに関する3つの主要なアップデートを発表しました。ClickStack Cloud、ベータ版のAI Notebooks、そして新しいClickStack MCPサーバーです。
ClickStack Cloud
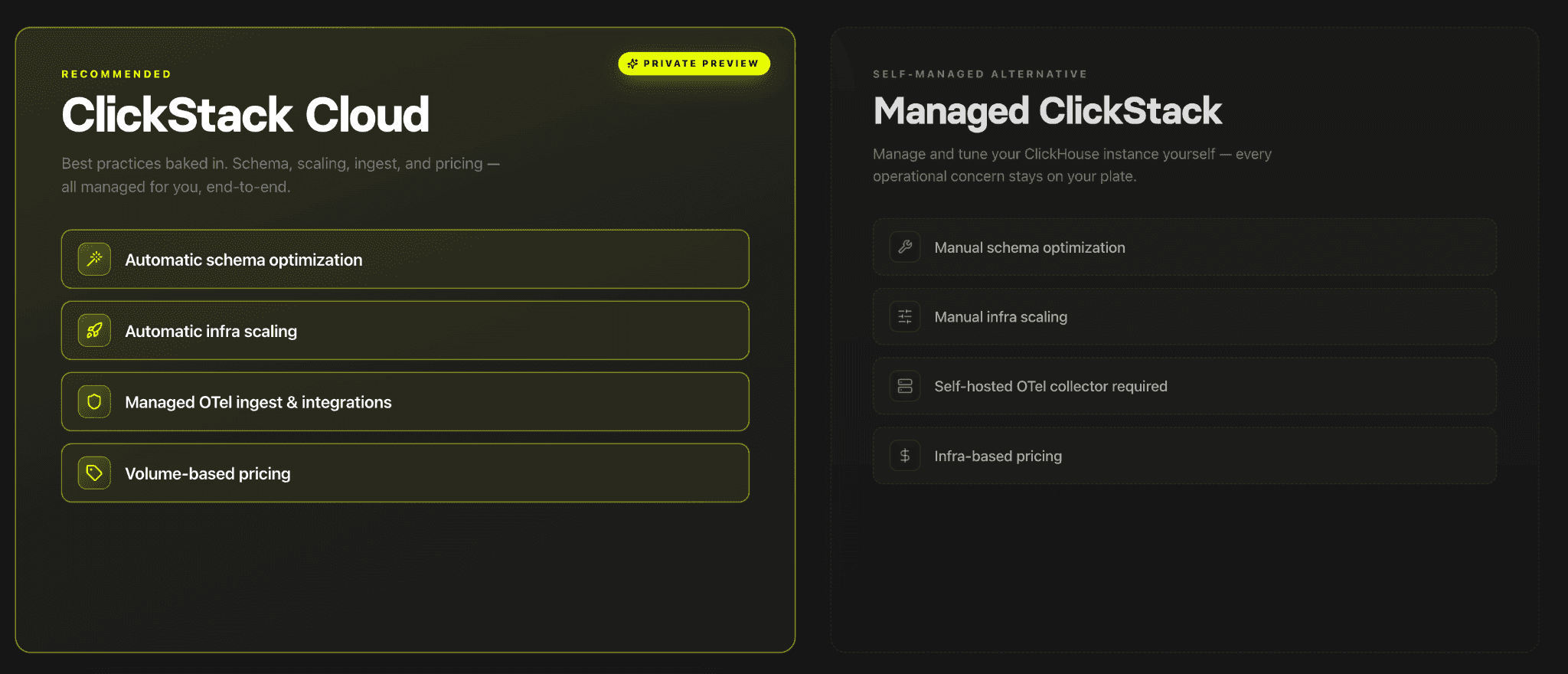
最大の発表は、独立したブログ記事としても取り上げる価値のあるものでした。それが、プライベートプレビューとしてのClickStack Cloudの登場です。
ClickStack Cloudは、ClickHouse上に構築されたフルマネージド・サーバーレスのオブザーバビリティプラットフォームです。コレクター、インフラのサイジング、スケーリングポリシー、スキーマチューニングを直接管理する代わりに、ユーザーはOpenTelemetryデータをマネージドエンドポイントに送信するだけで、ClickStack UIを通じてログ、メトリクス、トレースをすぐに探索できます。
ClickStack Cloudは、ClickHouseが評価されているパフォーマンス特性を維持しつつ、運用負担を削減することを目指しています。
詳細については、専用記事をご覧ください。
Managed ClickStackが一般提供開始
ClickStack Cloudのプライベートプレビュー開始に加えて、既存のManaged ClickStackも正式に一般提供となりました。
Managed ClickStackは、取り込みパイプライン、コンピュートのサイジング、ワークロードの分離、スキーマ設計、データストアチューニングなど、オブザーバビリティスタックを直接運用上コントロールしたいチーム向けに設計されています。ユーザーはOpenTelemetryコレクターと取り込みアーキテクチャを自分で管理しながら、基盤となるオブザーバビリティデータストアとしてClickHouse Cloudを利用します。多くの大規模デプロイメントでは、こうしたコントロールがパフォーマンスの最適化と市場をリードするコスト効率の達成に不可欠です。
Managed ClickStackとClickStack Cloudは、それぞれ異なる運用モデルを想定して設計されています。
前述のとおり、ClickStack Cloudはフルマネージド・サーバーレスのオブザーバビリティ体験を提供し、チームはテレメトリをマネージドエンドポイントに送信するだけで、インフラを直接管理することなくログ、メトリクス、トレースの探索を即座に開始できます。一方、Managed ClickStackは、ClickHouse Cloudインフラ上で稼働しつつも、スケーリング戦略、取り込みアーキテクチャ、ワークロード最適化をより深くコントロールしたい組織向けです。この2つの提供形態により、ターンキー型のオブザーバビリティ体験と、大規模なオブザーバビリティ運用のためのより構成可能なプラットフォームの間で、チームが選択できるようになります。
AI Notebooksベータ版
また、Managed ClickStack向けにAI Notebooksがベータ版に入ることも発表しました。
過去1年間で、ほぼすべてのオブザーバビリティプラットフォームが何らかのAIチャット体験を追加してきましたが、私たちはチャットだけでは実際のインシデント調査の進み方には合わないと感じるようになっていました。本番環境のデバッグは複雑であり、エンジニアはログ、トレース、ダッシュボード、デプロイメント、仮説の間を行き来します。後戻りしたり、並行して複数の調査に分岐したり、新しいシグナルが見つかるたびに以前の仮定を見直したりします。インシデントが単一スレッドの会話で完結することはまれであるため、インターフェースがそれを強制するべきではないと考えました。
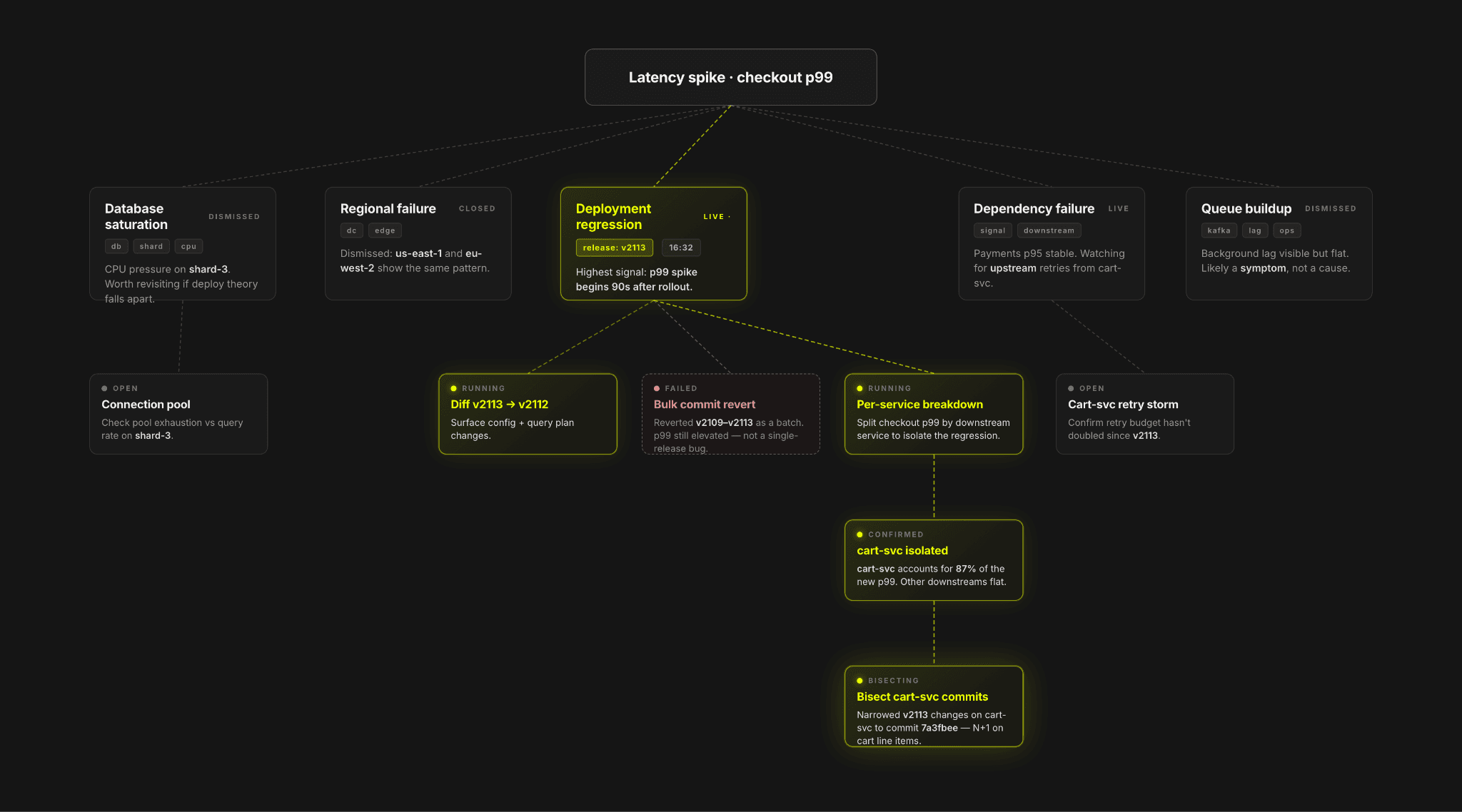
調査が単一スレッドで完結することはまれです。SREは通常、解決に至るまでに分岐する複数の仮説を探索する必要があります。
AI Notebooksは、一時的なチャットセッションではなく、永続的な調査ワークスペースとして設計されています。各調査は、プロンプト、クエリ、チャート、推論ステップ、調査結果が構造化されたシーケンスとなり、プロセス全体を通じて可視化され編集可能な状態で保持されます。
エンジニアはノートブックの任意の地点から分岐して、以前の作業やコンテキストを失うことなく代替的な仮説を探索できます。実際のワークフローは、より協調的なデバッグ体験のように感じられます。
これを構築するにあたり、透明性についてもかなり強いこだわりを持っていました。本番障害の現場では、エンジニアはシステムが実際に何をしているのかを理解する必要があります。とりわけ調査ループにAIが関わっている場合はなおさらです。すべてのクエリ、チャート、推論ステップ、中間結果はノートブック内で可視化されています。クエリを手動で編集したり、独自の検索を追加したり、提案されたパスを完全に無視して調査を別の方向に進めたりすることもできます。私たちは、AIにバックグラウンドでブラックボックス的な結論を出すシステムというよりも、エンジニアの隣に座っている協力者のように振る舞ってほしかったのです。
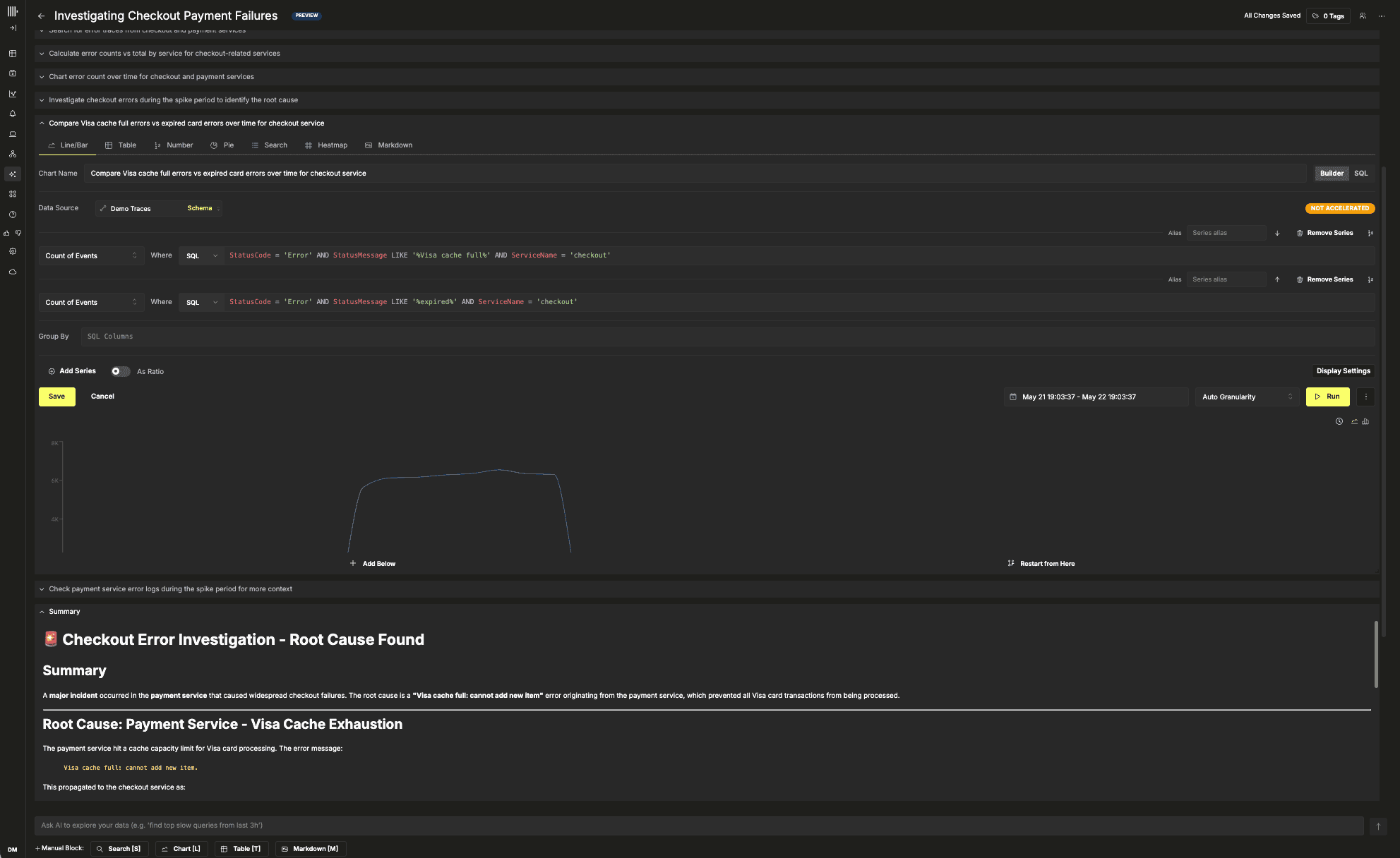
インターフェースの裏側では、NotebooksはClickStackのオブザーバビリティプリミティブと最適化されたClickHouseワークフローの上に直接構築されています。このシステムは単にSQLコンソールにLLMをくっつけたものではありません。モデルは、ClickStack自体を支えるすでに整備された構造化された調査ツールを操作し、最適化された検索、集計、可視化を実行しつつ、生成されたクエリは検査や改善のために常に可視化されています。Notebooksはチーム間で共有することもでき、調査をインシデント終了後に消えてしまう使い捨てのチャット履歴ではなく、永続的に協働できる成果物に変えてくれます。
すでにManaged ClickStackを利用しているユーザーは、ClickStack UI内の左側のナビゲーションパネルから直接AI Notebooksを利用できるようになりました。
そして、このNotebook体験は自然な流れで、Open Houseでの3つ目のオブザーバビリティに関する発表へとつながりました。ClickStack内に構造化された調査ワークフローを構築する一環として、新しいClickStack MCPサーバーも導入しました。これにより、外部のAIシステムやエージェントは、Notebooksを内部で支えるのと同じオブザーバビリティプリミティブと直接統合できるようになります。
ClickStack MCPサーバー
NotebooksとともにOpen Houseでは、AIとオブザーバビリティツーリングにおいて起きつつあるより広範な変化についても議論しました。
ClickStack内部でのAI支援による調査は重要ですが、私たちは多くのチームがClickStack内で公開しているのと同じ強力なツールを自分たちのエージェントでも活用したいと考えるはずだと思っています。実際に、ユーザーはオブザーバビリティデータを中心に独自のエージェント、プロンプト、ワークフロー、自動化を構築するケースが増えています。Cursorや Claude Codeの中でそれを行う人もいれば、SDKをつなぎ合わせて社内システムに対してローカルにエージェントを実行する人もいます。多くの場合、こうしたワークフローを構築するチームは、インシデントをデバッグする方法に強い運用知識がすでに織り込まれており、ツールにもそれを反映させたいと考えています。
私たちの考えは、オブザーバビリティプラットフォームはユーザーを単一のAI体験に押し込めるのではなく、彼らがすでに作業している場所で迎え入れるべきだ、というものです。そして、「自分のエージェントを持ち込む」(Bring your own agents)という哲学に基づいて構築していきたいと考えています。
最初のステップは、ClickStack Notebooksを内部で支えるのと同じ調査の構成要素を、外部のエージェントやワークフローに対しても公開することです。そのために、オープンソース版ClickStackでClickStack MCPサーバーを発表できることを嬉しく思います。
なぜClickStack専用のMCPなのか?
すでに汎用的なClickHouse MCPサーバーが提供されており、幅広い分析タスクやSQL駆動の探索ではうまく機能します。しかし、AI Notebooksを構築する中で、オブザーバビリティワークフローは一般的なBIワークロードとは異なる挙動を示すことが繰り返し分かりました。モデルは、毎回生のSQLクエリを生成するよりも、構造化された調査ツールを操作した方がはるかに性能が良いのです。
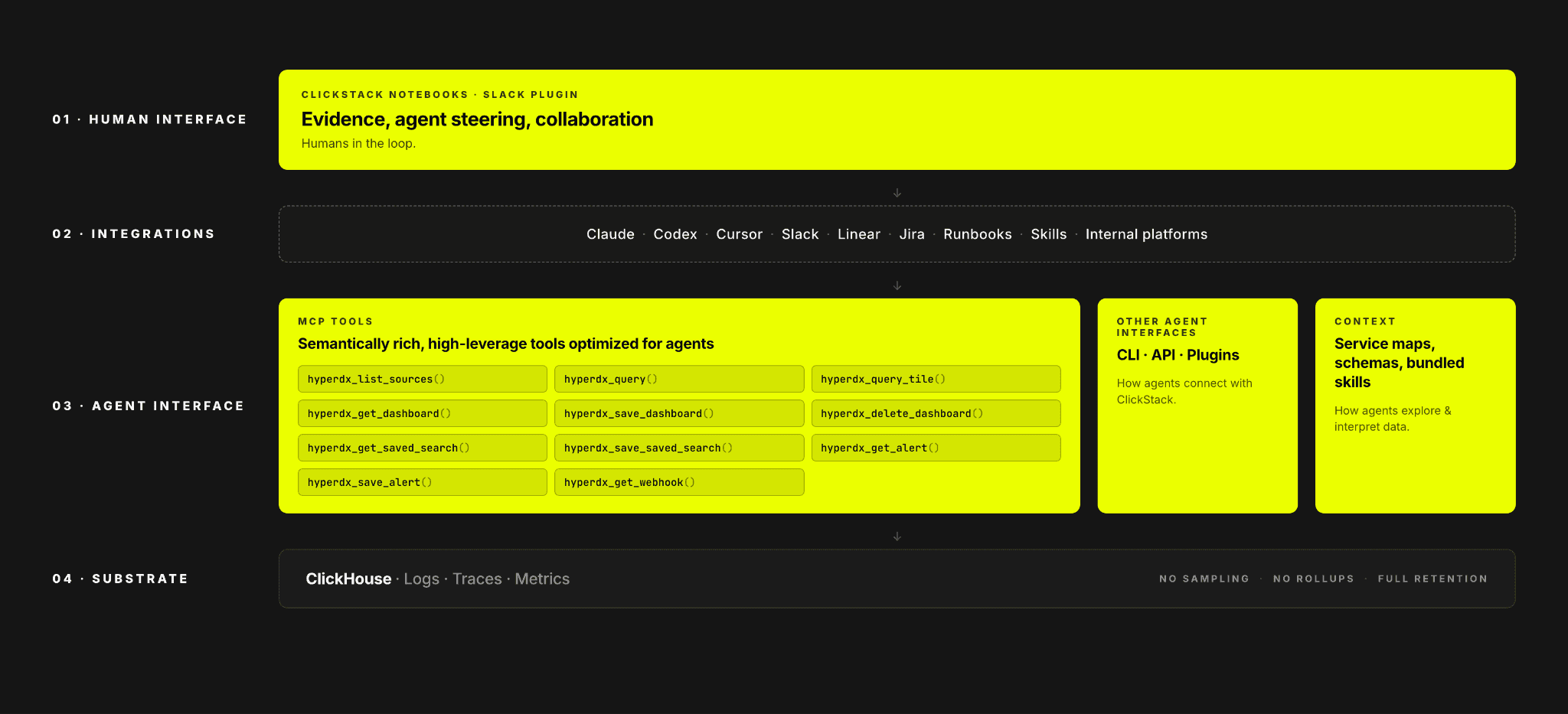
ClickHouseによるオブザーバビリティ向けAIは、ClickStackを通じて提供される協働型ノートブック体験とMCPツール、ClaudeやCodexなど外部エージェントとの統合、そして高性能分析エンジンとしてのClickHouseを組み合わせ、サブ秒のクエリ性能と大規模な高並列性によりフルフィデリティな調査を可能にします。
生のSQLは強力ですが、多くのオブザーバビリティ調査は単発のクエリとして表現するには扱いにくいものです。繰り返し発生するログパターンの抽出、時間ウィンドウ間での挙動比較、トレースの外れ値の根本原因分析、ログ・メトリクス・トレースを横断した調査などのタスクには、複数ステップの分析とドメイン固有のロジックが必要です。これらをすべてモデル任せにすると、毎回必要なクエリパターンや分析ロジックをゼロから組み立てる必要があり、問題そのものではなくクエリの仕組みにコンテキストを消費してしまいます。
ClickStack MCPサーバーは、オブザーバビリティ業務のためのより高レベルのセマンティックなツールをエージェントに提供します。生のSQLインターフェースだけを公開するのではなく、ログパターンのトレンド抽出、属性と外れ値の相関、低速トレースの検査、再現可能なワークフローによる調査の進行など、安定したツールを提供します。内部ではこれらのツールも最適化されたClickHouseクエリを実行しますが、エージェントは毎回複雑な分析を手作業で組み立てるのではなく、意図レベルの操作とやり取りします。
これはAI Notebooks内部で使われているアプローチと同じです。モデルは調査のステップごとに大きなSQL文を手作業でつなぎ合わせているわけではありません。代わりに、基盤となるオブザーバビリティワークフローとClickStackの最適化をすでに理解している専用ツールを操作します。
私たちの内部ベンチマークでは、調査が25%少ないツール呼び出しで完了し、一貫性が2.5倍向上、評価スコアは標準のClickHouse MCPと比較して20%近く改善されました。その大きな要因は、モデルにあらゆるワークフローを生のSQLだけで生成させるのではなく、高いレバレッジを持つセマンティックな調査ツールを与えたことにあります。
柔軟性を維持する
同時に、構造化された調査ツールが直接的なSQLアクセスを完全に置き換えるべきだとは考えていません。
ClickHouseがエージェント型ワークロードやオブザーバビリティで非常にうまく機能する理由の一つは、SQLが探索言語として非常に強力であり続けていることです。インシデントによっては、もはや高レベルの抽象化では助けにならず、根本的なデータに直接アクセスするしかない地点に達することがあります。構造化ツールは反復的で一般的な調査パスの多くを効率的に処理しますが、エンジニアやエージェントがより深く掘り下げたり、特殊な仮説を検証したり、システムが想定していなかった質問に答える必要が生じたときには、SQLが脱出ハッチとして残っています。
実際には、これらのワークフローは非常に自然に補完し合います。調査の大部分には最適化された調査プリミティブを使い、状況に応じてネイティブなクエリに切り替えるのです。
調査だけでなくオーケストレーションも
ターミナルで直接作業したり、Claude Codeのようなエージェントハーネス内で作業することに満足しているエンジニアもいますが、調査は最終的に他の人と共有する必要があります。SREは協働し、コンテキストを保持し、結論に達したら証拠を提示する必要があります。
そのため、私たちはオブザーバビリティMCPサーバーが調査プリミティブだけを公開すべきではないと考えています。実際の運用ワークフローには、ダッシュボードの作成、検索の永続化、アラートの管理、調査結果のチーム横断的な共有といったオーケストレーション・プリミティブも必要です。
これはローカルエージェントのワークフローでは特に重要になります。エージェントがローカルでインシデントを調査した場合、その結果として得られた証拠は、より大きなチームによる共有とレビューのためにどこかに永続化される必要があります。生のチャット出力をドキュメントにコピーしたり、静的なレポートを生成したりするやり方は、実際のインシデントの最中にはすぐに破綻し、不整合を引き起こします。
そのため、ClickStack MCPサーバーはClickStack内部で双方向の管理ツールを直接公開しています。エージェントはインシデントを調査するだけでなく、ダッシュボードを作成し、検索を永続化し、結果として得られた成果物に必要な証拠や可視化が含まれているかを検証することもできます。
実際には、調査は使い捨てのチャット履歴ではなく、永続的な運用成果物へと自然に進化していきます。
MCPの使い方
ClickStack MCPサーバーを使い始めるのは簡単です。フルスタックをローカルで試す最も簡単な方法は、ClickHouse、ClickStack UI (HyperDX)、OpenTelemetry取り込みエンドポイント、MCPサーバーを含むClickStackオールインワンコンテナを使用することです。
docker run --name clickstack \
-p 8123:8123 \
-p 8080:8080 \
-p 4317:4317 \
-p 4318:4318 \
clickhouse/clickstack-all-in-one:latest \
clickstackコンテナが起動すると、ClickStack UIはhttp://localhost:8080で利用可能になります。ユーザーを作成してログインしてください。
サンプルデータセットについては、このガイドの手順(1)および(2)に従って、ローカルのデータソースを当社のデモサーバーに向けるよう変更できます。
MCPサーバーを使用するには、Personal API Access Keyも必要です。ClickStack UI内で、次のメニューに移動してください: Team Settings → Integrations → API Keys → Personal API Access Key。
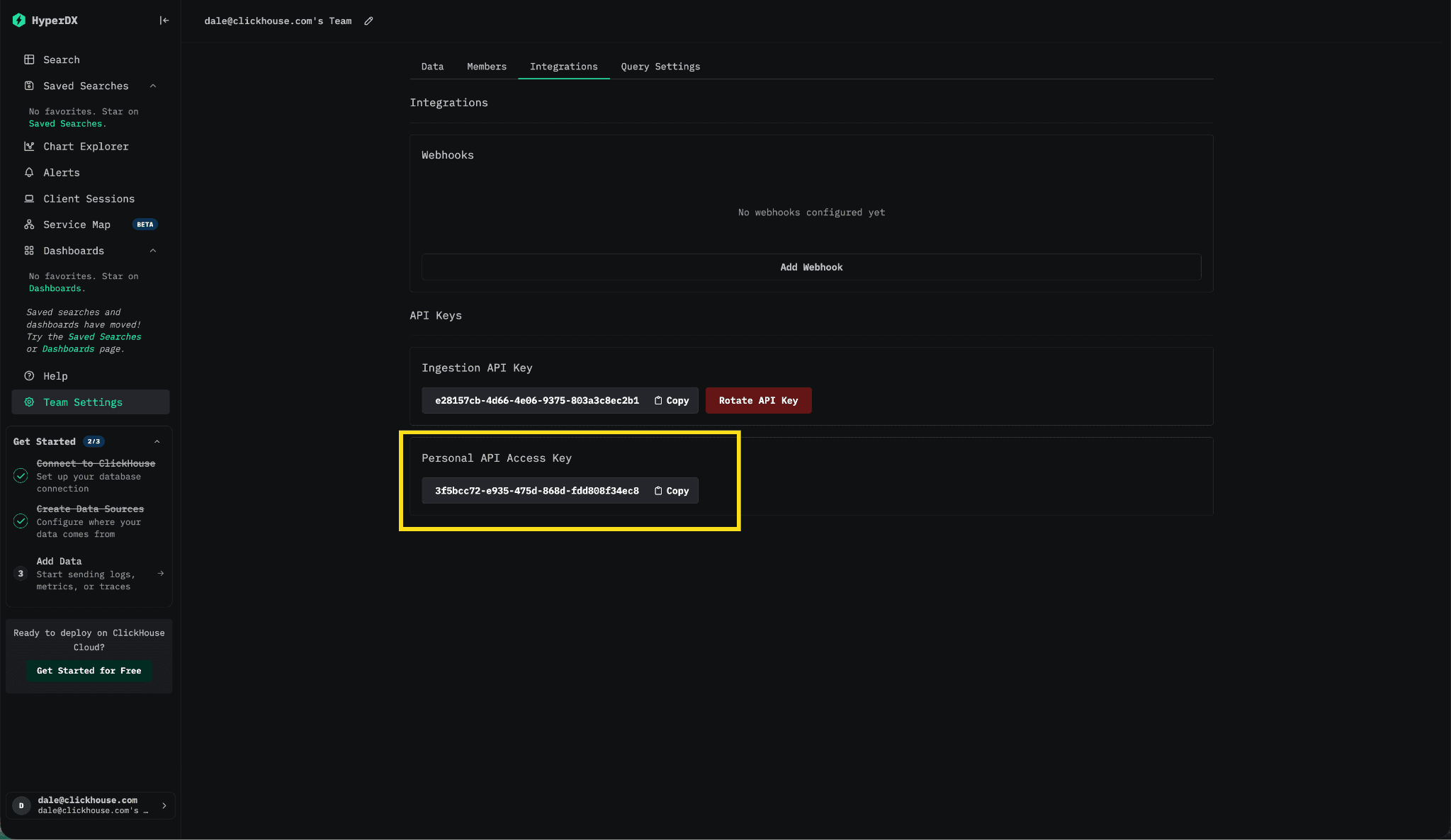
MCPエンドポイントはhttp://localhost:8080/api/mcpで公開されます。
そこから、すでに使用しているMCP互換のクライアントやエージェントフレームワークを接続できます。
例えば、Claude Codeを接続する場合:
claude mcp add --transport http clickstack http://localhost:8080/api/mcp \
--header "Authorization: Bearer <your-api-key>"Added HTTP MCP server clickstack with URL: http://localhost:8080/api/mcp to local config
Headers: {
"Authorization": "Bearer <your-api-key>"
}
File modified: /Users/demo_user/.claude.json [project: /Users/demo_user]接続が完了すると、エージェントはClickStackのオブザーバビリティプリミティブと直接やり取りを始められます。例えば、次のような質問ができます:
「直近1時間でエラー率が最も高いサービスを表示して」

内部では、MCPサーバーはこれらのリクエストを、その場限りのSQL生成に完全に依存するのではなく、AI Notebooksで使われているのと同じ最適化された調査ツール経由でルーティングします。
例えば、決済サービスのレイテンシ上昇を調査し、最終的にClaudeを通じて根本原因がキャッシュエビクションの問題であると判明したとします。
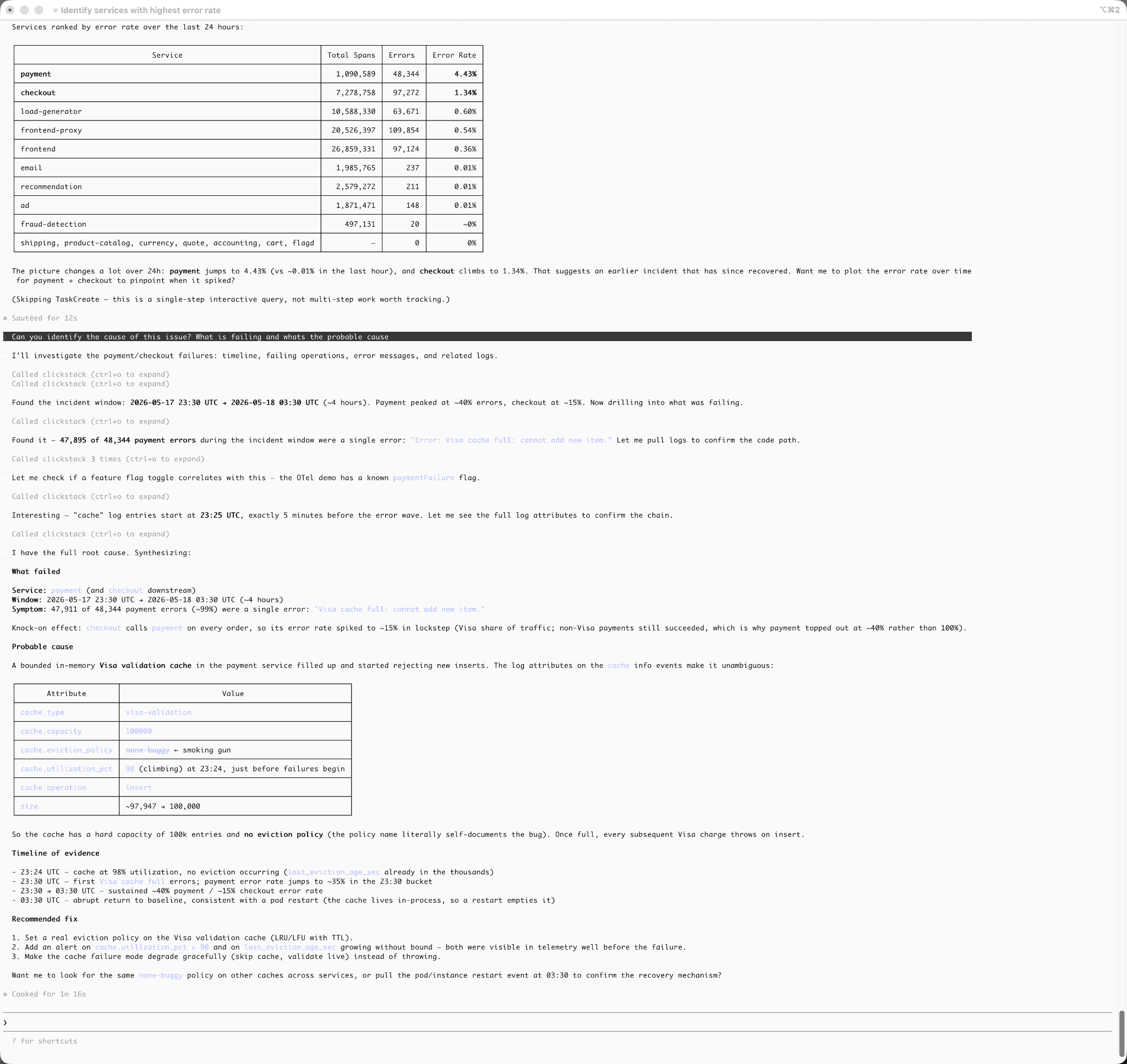
この時点で、調査内容を永続化して共有する手段が必要になります。生のClaudeの出力をドキュメントにコピーしたり、モデルに静的なHTMLレポートを生成させたりすることもできますが、どちらのワークフローも特に自然とは言えません。
以下では、MCPサーバーを使って調査を要約したダッシュボードを生成し、結果をClickStackに直接永続化します。さらに、検証ステップによってダッシュボードに必要な証拠が表示されていることを確認しています。
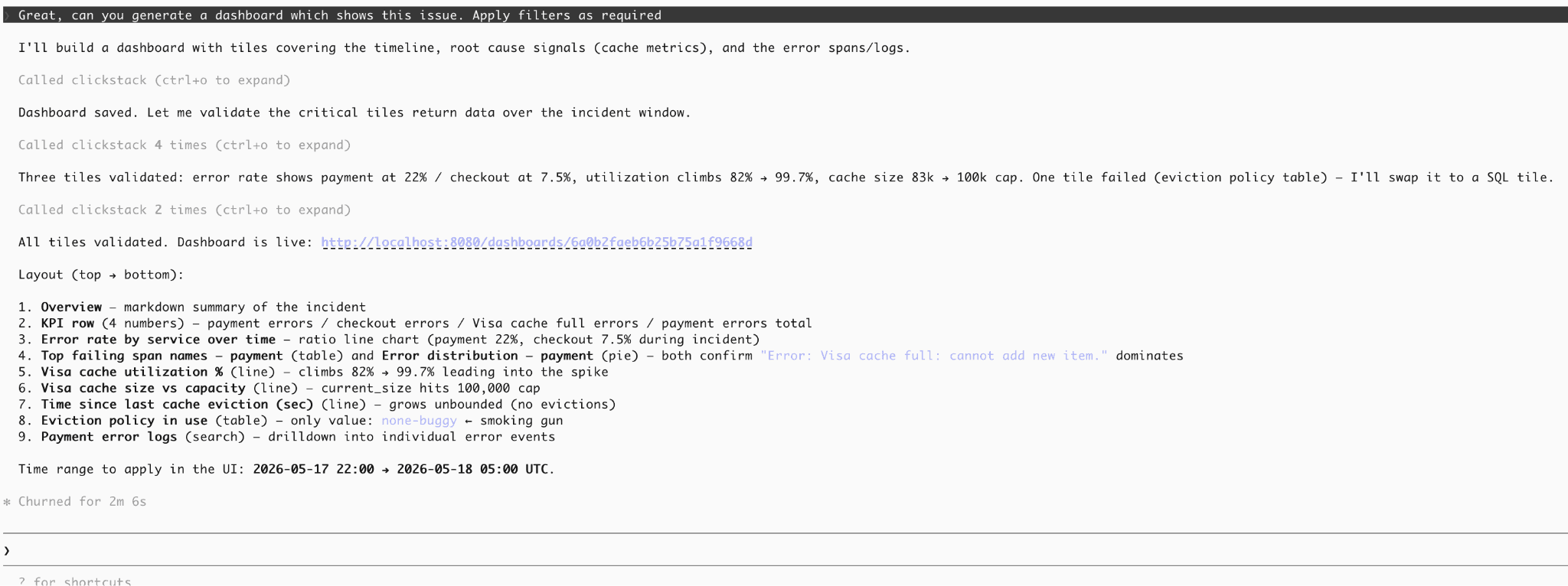
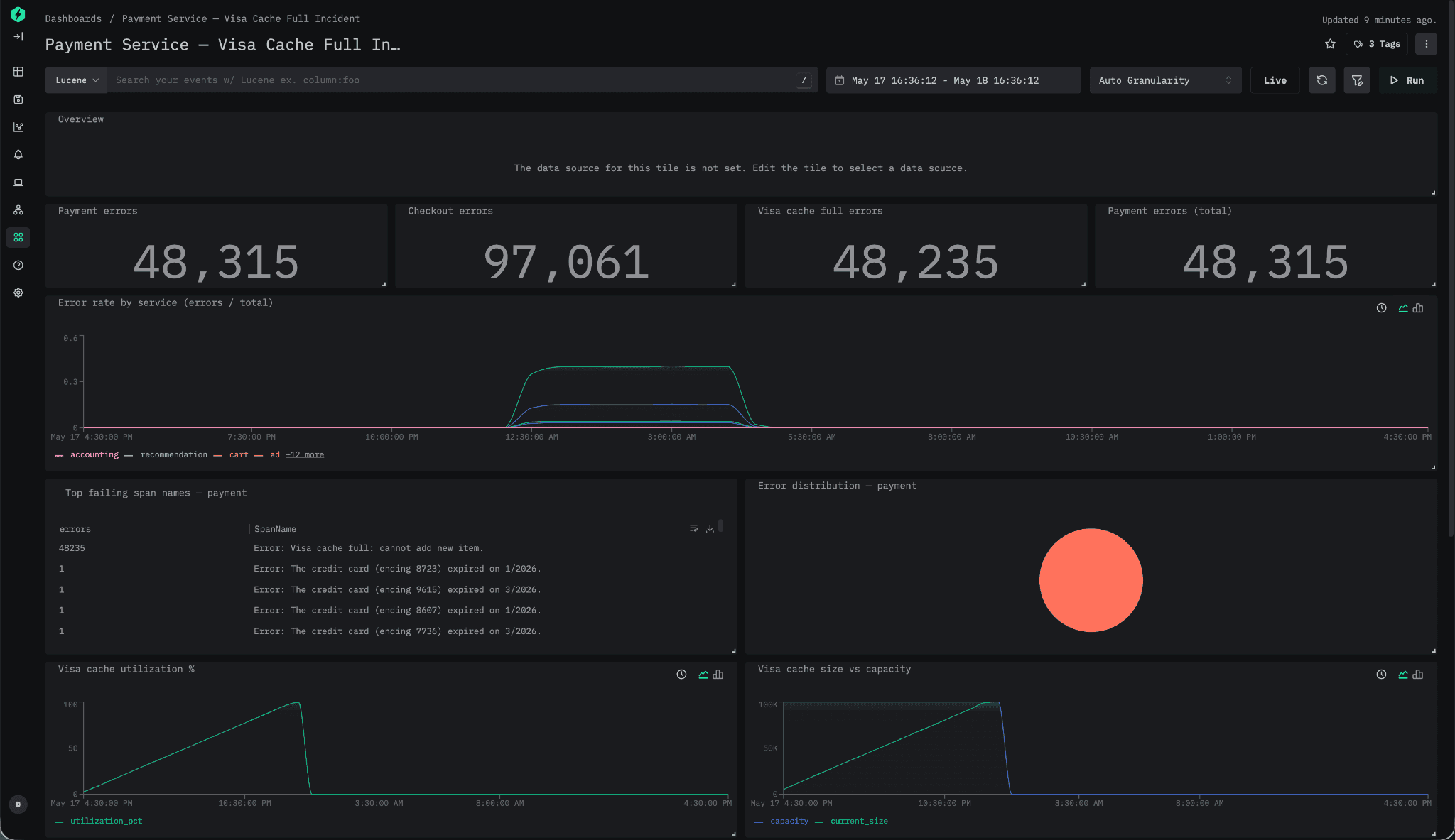
最終的に得られたダッシュボードは、インシデントを要約し、RCAドキュメントのための証拠を提示する永続化された成果物となります。
まとめ
これらの発表はすべて同じ大きな方向性を反映しています。オブザーバビリティツーリングは、エンジニアが事前定義されたワークフローに縛られることなくシステムを調査できるよう支援すべきだということです。ClickStack Cloudは運用負担の多くを軽減し、AI Notebooksは調査の文書化と共有を容易にし、MCPサーバーはチームが自分たちのエージェントや内部ツーリングに同じ機能を統合できるようにします。私たちはまだこの変化の始まりに立っているにすぎませんが、オブザーバビリティシステムは、今日多くのチームが頼っているツーリングよりもはるかに協働的かつプログラマブルなものになっていくと期待しています。
今すぐ始める
ClickHouseがあなたのデータでどのように動作するのか興味がありますか?数分でClickHouse Cloudを使い始めることができ、300ドル分の無料クレジットを受け取れます。
Sign up


