主要な概念
セットアップガイド
1
ClickHouse の接続情報を確認する
HTTP(S) で ClickHouse に接続するには、次の情報が必要です。
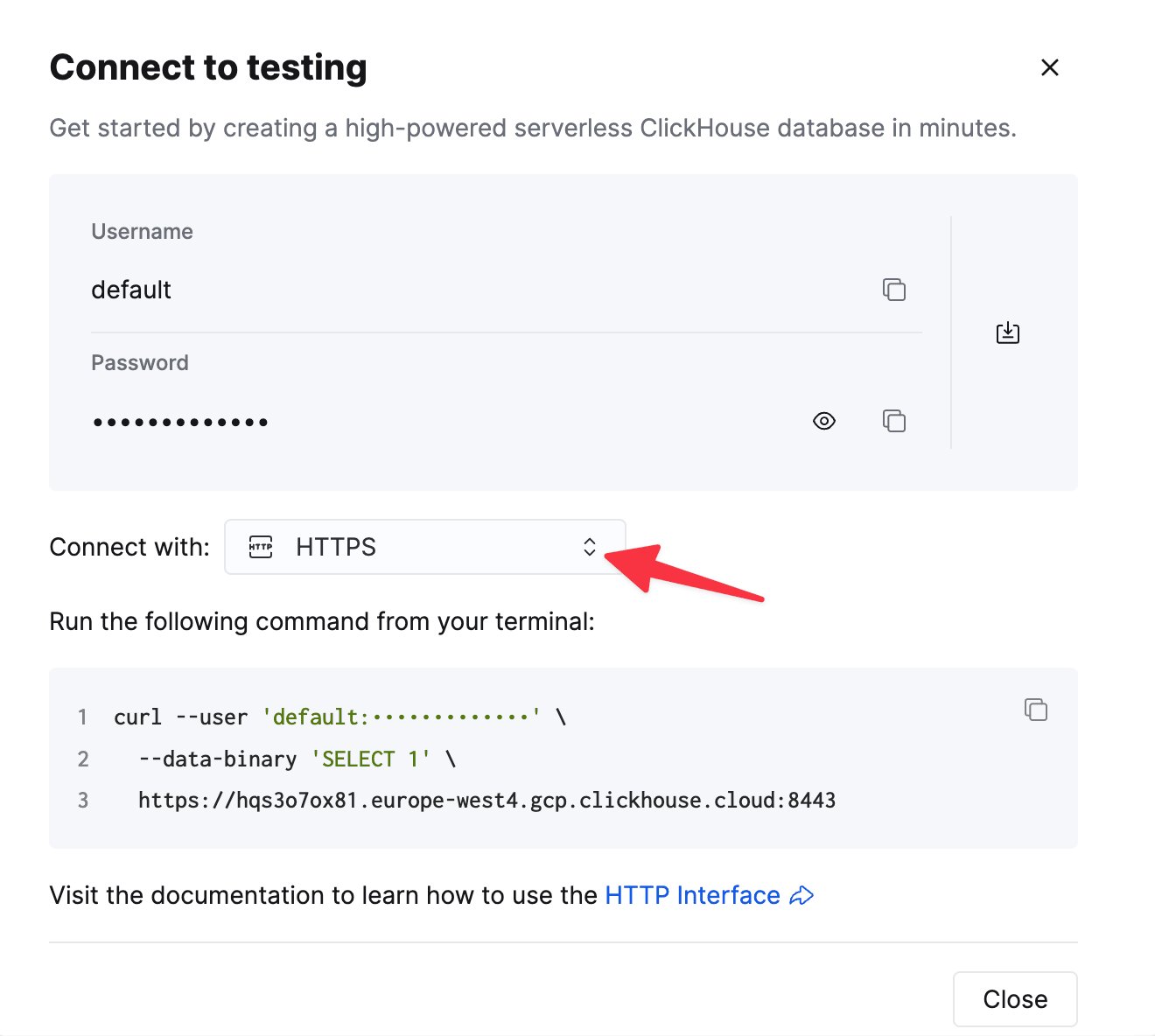
ClickHouse Cloud サービスの詳細は、ClickHouse Cloud コンソールで確認できます。
サービスを選択し、Connect をクリックします。
curl コマンドの例として表示されます。2
Apify の前提条件
あわせて、以下が必要です。
- Apify アカウント (無料プランあり)。
- Apify API トークン、Apify Console の Settings > Integrations で確認できます。
- ローカルにインストールされた Node.js 18 以上 (JavaScript のサンプル用)。
3
依存関係をインストールする
Apify JavaScript クライアント と ClickHouse JavaScript クライアント をインストールします。
Apify では Python クライアント も提供しています。Python を使う場合は、pip で
apify-client をインストールし、ClickHouse には clickhouse-connect を使用してください。4
ClickHouse にターゲットテーブルを作成する
スクレイピングしたデータを格納するテーブルを作成します。スキーマは使用する Actor によって異なります。この例では、商品スクレイピング用の Actor に対して MergeTree を使用しています。
5
Apify Dataset を取得して ClickHouse に読み込む
次のスクリプトは、Apify Actor の実行結果を取得して ClickHouse に挿入します。
6
webhook で自動化する
スクリプトを手動で実行する代わりに、Actor の完了時に毎回データが ClickHouse に読み込まれるよう、パイプラインを自動化します。
- Apify Console で対象の Actor を開き、Integrations タブに移動します。
- 次の内容で新しい webhook を追加します。
- Event type:
ACTOR.RUN.SUCCEEDED - Action: ローダーのエンドポイントへの HTTP POST、または ClickHouse への挿入を処理する別の Actor をトリガー。
- Event type:
- webhook の payload には
defaultDatasetIdが含まれており、これを使ってその実行結果を取得できます。
ベストプラクティス
Apify からデータを取得する
apify-client または Python) を使用してください。ページネーション、再試行、認証を自動で処理してくれます。大規模な Dataset では、List dataset items エンドポイントの limit パラメータと offset パラメータを使って、結果をページ分割しながら取得してください。
ClickHouse へのロード
JSONEachRowフォーマットを使用してください。追加の変換は不要で、Apify の JSON 出力にそのまま対応しています。
ClickHouse のテーブルスキーマは、Actor の出力フィールドに合わせてください。Actor の出力スキーマは、Apify Store の該当ページ、または実行後の Dataset タブで確認できます。
パフォーマンス
セキュリティ
default ユーザーとデータベースを使用しています。本番環境では、ターゲットテーブルへの挿入に必要な最小限の権限のみを持つ専用ユーザーを作成し、認証情報は安全に保管してください (たとえば、ソースコードにコミットするのではなく、環境変数やシークレットマネージャーに保存します) 。詳しくは、クラウドアクセス管理を参照してください。