This blog post is part of a series:
- Join Types supported in ClickHouse
- ClickHouse Joins Under the Hood - Hash Join, Parallel Hash Join, Grace Hash Join
- ClickHouse Joins Under the Hood - Full Sorting Merge Join, Partial Merge Join
- ClickHouse Joins Under the Hood - Direct Join
In the previous three posts, we did a deep dive on the 6 different join algorithms that have been developed for ClickHouse. In this final post, we will summarize and directly compare the execution times and memory usage of all ClickHouse join algorithms. Based on this, we will provide decision trees as well as a join type support overview that you can use for deciding which join algorithm fits best into your specific scenario.
Overview of ClickHouse join algorithms
The following 6 join algorithms have been developed for ClickHouse so far:
These algorithms dictate the manner in which a join query is planned and executed. By default, ClickHouse is using the direct or the hash join algorithm, based on used join type and strictness and engine of the joined tables. Alternatively, ClickHouse can be configured to adaptively choose and dynamically change the join algorithm to use at runtime, depending on resource availability and usage: When join_algorithm is set to auto, ClickHouse tries the hash join algorithm first, and if that algorithm’s memory limit is violated, the algorithm is switched on the fly to partial merge join. You can observe which algorithm was chosen via trace logging. ClickHouse also allows users to specify the desired join algorithm themselves. This chart gives an overview of the ClickHouse join algorithms based on their relative memory consumption and execution time:
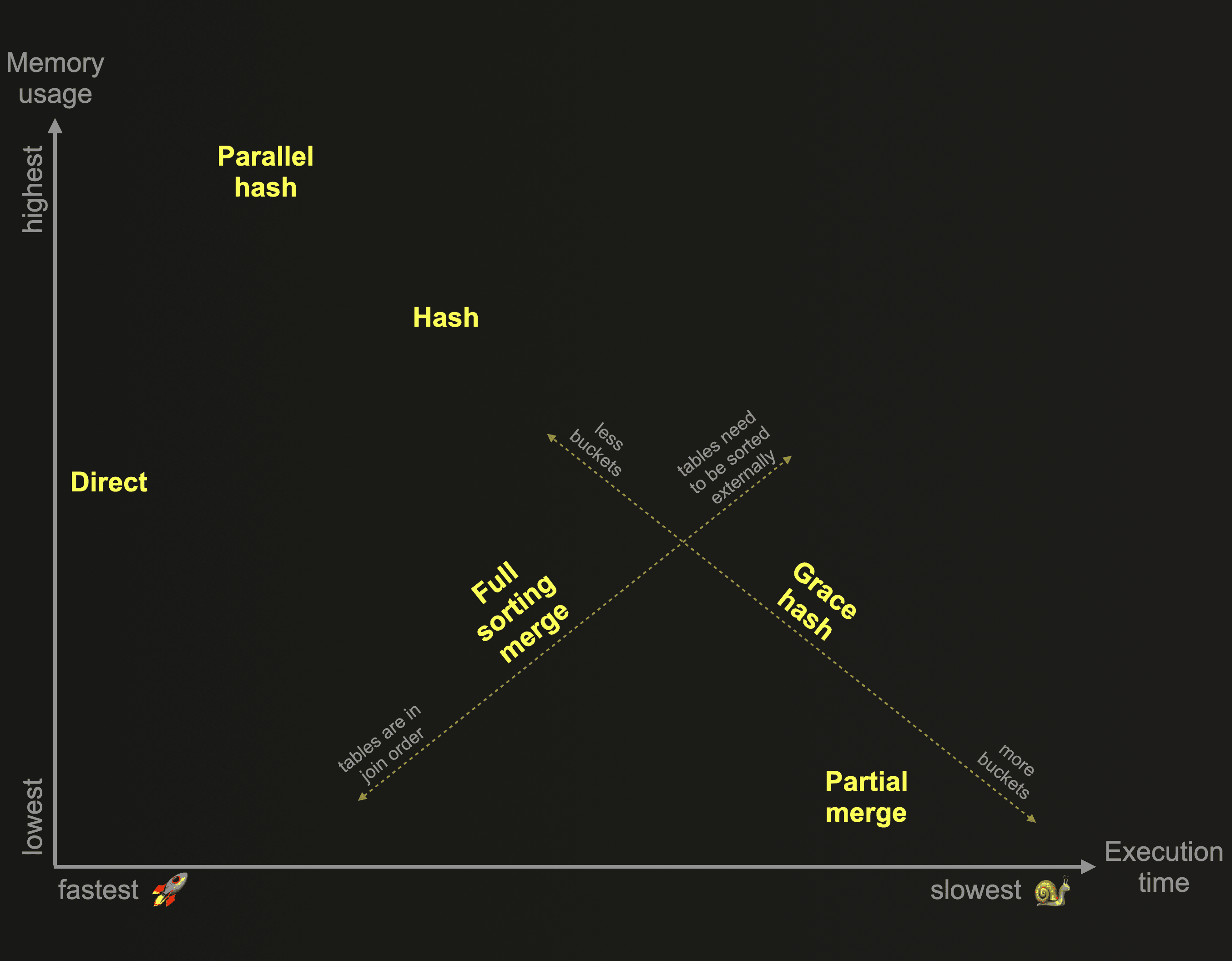
The Direct join is ClickHouse’s fastest join algorithm and is applicable when the underlying storage for the right-hand side table supports low-latency key-value requests, and when LEFT ANY JOIN semantics is adequate. Especially with large right-hand side tables, the direct join beats all other ClickHouse join algorithms with a significant improvement in execution time.
Three of the ClickHouse join algorithms are based on in-memory hash tables:
- The Hash join is fast but memory-bound, and the most generic join algorithm supporting all join types and strictness settings. The algorithm can be constrained by high memory usage. Plus, the creation of the in-memory hash table from the right-hand side table of the join is single-threaded and can become a bottleneck in terms of join execution time if the right-hand side table is very large.
- The Parallel hash join can be faster with large right-hand side tables, by building several hash tables concurrently, but it requires even more memory.
- The Grace hash join is a non-memory bound version that spills data temporarily to disk without requiring any sorting of the data. This overcomes some of the performance challenges of other non-memory bound ClickHouse join algorithms, that spill data temporarily to disk but require prior sorting of the data.
ClickHouse offers two additional non-memory bound join algorithms based on external sorting:
- The Full sorting merge join is based on in-memory or external sorting and can take advantage of the physical row order of the joined tables and skip the sorting phase. In such cases, the join performance can be competitive with some of the hash join algorithms from the chart above while generally requiring significantly less main memory.
- The Partial merge join is optimized for minimizing memory usage when large tables are joined and always fully sorts the right table first via external sorting. The left table is also always sorted, block-wise in-memory. The join matching process runs more efficiently if the physical row order of the left table matches the join key sorting order.
Choosing the right join algorithm
The join algorithm choice mainly depends on three factors:
- Performance
- Memory
- Join type support
The following three sections provide guidance for these factors.
Performance
Next to the overview chart from above, you can use this decision tree for choosing the right join algorithm when the main criteria is executing joins as fast as possible:
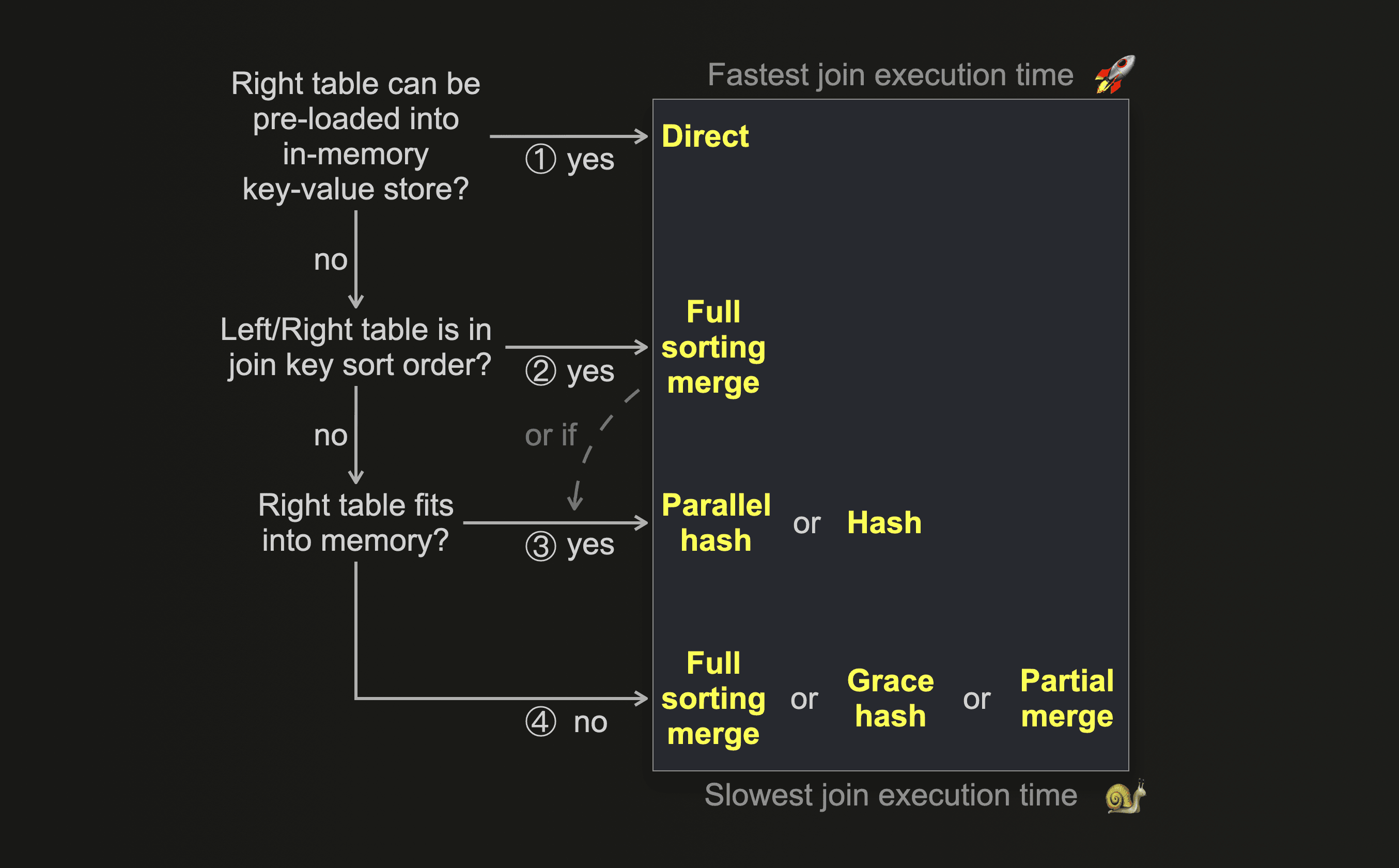
① If the data from the right-hand side table can be pre-loaded into an in-memory low-latency key-value data structure, e.g., a dictionary, and if the join key matches the key attribute of the underlying key-value storage, and if LEFT ANY JOIN semantics is adequate - then the direct join is applicable and offers the fastest approach.
② If your table’s physical row order matches the join key sort order, then it depends. In this case, the full sorting merge join skips the sorting phase resulting in significantly reduced memory usage plus, depending on data size and join key value distribution, faster execution times than some of the hash join algorithms. However, if ③ the right table fits into memory, even with the additional memory usage overhead of the parallel hash join, then this algorithm or the hash join can be faster. This depends on data size, data types, and value distribution of the join key columns.
④ If the right table doesn’t fit into memory, then it depends again. ClickHouse offers three non-memory bound join algorithms. All three temporarily spill data to disk. Full sorting merge join and partial merge join require prior sorting of the data. Grace hash join is building hash tables from the data instead. Based on the volume of data, the data types and the value distribution of the join key columns, there can be scenarios where building hash tables from the data is faster than sorting the data. And vice versa.
Partial merge join is optimized for minimizing memory usage when large tables are joined, at the expense of join speed which is quite slow. This is especially the case when the physical row order of the left table doesn’t match the join key sorting order.
Grace hash join is the most flexible of the three non-memory-bound join algorithms and offers good control of memory usage vs. join speed with its grace_hash_join_initial_buckets setting. Depending on the data volume the grace hash can be faster or slower than the partial merge algorithm, when the amount of buckets is chosen such that the memory usage of both algorithms is approximately aligned. When the memory usage of grace hash join is configured to be approximately aligned with the memory usage of full sorting merge, then full sorting merge was always faster in our test runs.
Which one of the three non-memory-bound algorithms is the fastest depends on the volume of data, the data types and the value distribution of the join key columns. It is always best to run some benchmarks with realistic data volumes of realistic data in order to determine which algorithm is the fastest.
Memory
If you want to optimize a join for the lowest memory usage instead of the fastest execution time, then you can use this decision tree instead:
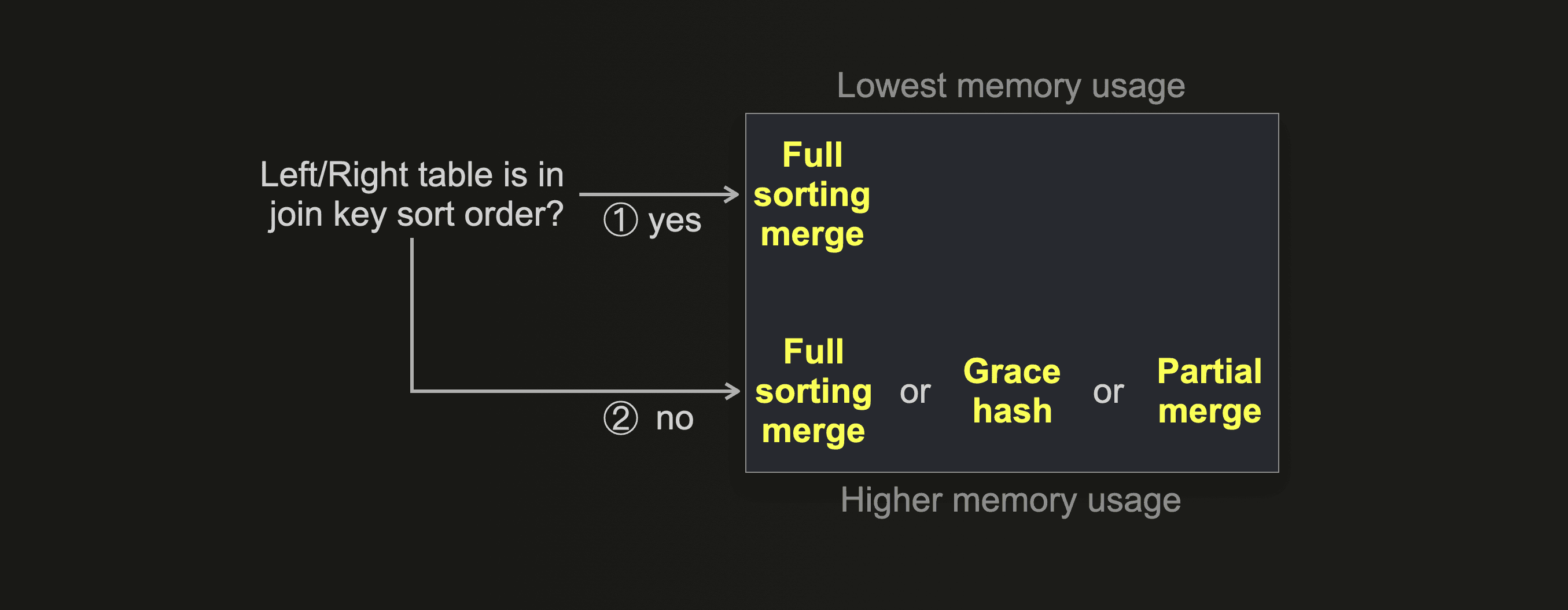
① If your table’s physical row order matches the join key sort order, then the memory usage of the full sorting merge join is as low as it gets. With the additional benefit of good join speed because the sorting phase is disabled.
② The grace hash join can be tuned for very low memory usage by configuring a high number of buckets at the expense of join speed. The partial merge join intentionally uses a low amount of main memory. The full sorting merge join with external sorting enabled generally uses more memory than the partial merge join (assuming the row order does not match the key sort order), with the benefit of significantly better join execution time.
Join type support
Not only execution speed and memory consumption are factors in choosing the right join algorithm. It also depends on if your required join type is supported by the join algorithm. For that, we created this overview chart:

Comparisons
We are now going to compare the execution times and peak memory consumptions of all ClickHouse join algorithms.
Test setup
We will use the tables that we introduced in the second post.
For all join query runs we use the default setting of max_threads. The ClickHouse Cloud node executing the queries has 30 CPU cores (and 120 GB of main memory) and therefore a default max_threads setting of 30. The version of ClickHouse used for the query runs is 23.5.1.
Join query
We run the same join query with the larger table on the right-hand side of the join with different join algorithm settings:
SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = ...;
Datasets
IMDB Large tables
As a reminder, in the previous posts, we used the actors and roles table from the imdb_large database. The query below lists the number of rows and amount of uncompressed data in each table:
SELECT
table,
formatReadableQuantity(sum(rows)) AS rows,
formatReadableSize(sum(data_uncompressed_bytes)) AS data_uncompressed
FROM system.parts
WHERE (database = 'imdb_large') AND active
GROUP BY table
ORDER BY table ASC;
┌─table──┬─rows───────────┬─data_uncompressed─┐
│ actors │ 1.00 million │ 21.81 MiB │
│ roles │ 100.00 million │ 2.63 GiB │
└────────┴────────────────┴───────────────────┘
IMDB X-Large tables
For further join algorithm comparison, we generated an even larger imdb_xlarge database:
SELECT
table,
formatReadableQuantity(sum(rows)) AS rows,
formatReadableSize(sum(data_uncompressed_bytes)) AS data_uncompressed
FROM system.parts
WHERE (database = 'imdb_xlarge') AND active
GROUP BY table
ORDER BY table ASC;
┌─table──┬─rows───────────┬─data_uncompressed─┐
│ actors │ 100.00 million │ 2.13 GiB │
│ roles │ 1.00 billion │ 26.33 GiB │
└────────┴────────────────┴───────────────────┘
In the following section, we will present charts comparing runs of the example query with each join algorithm over the tables of both databases.
Direct join is a bit special
Note that we are using separate charts for the direct join algorithm because it only makes sense to compare this algorithm with similar, memory-bound non-sorting algorithms like hash and parallel hash. As mentioned in the previous post, a direct join with a dictionary-backed right-hand side table is also effectively a LEFT ANY JOIN:
SELECT *
FROM actors AS a
LEFT ANY JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = ...;
IMDB Large join runs
The following chart summarizes the peak memory usage and execution time of the same example join query using the imdb_large tables with:
- the larger table on the right-hand side of the join
- different join algorithm settings
- a node with
30 CPU coresand the default setting of 30 formax_threads
Note that the 10 query runs are ordered by execution time, starting with the fastest query run on the left-hand side of the chart:
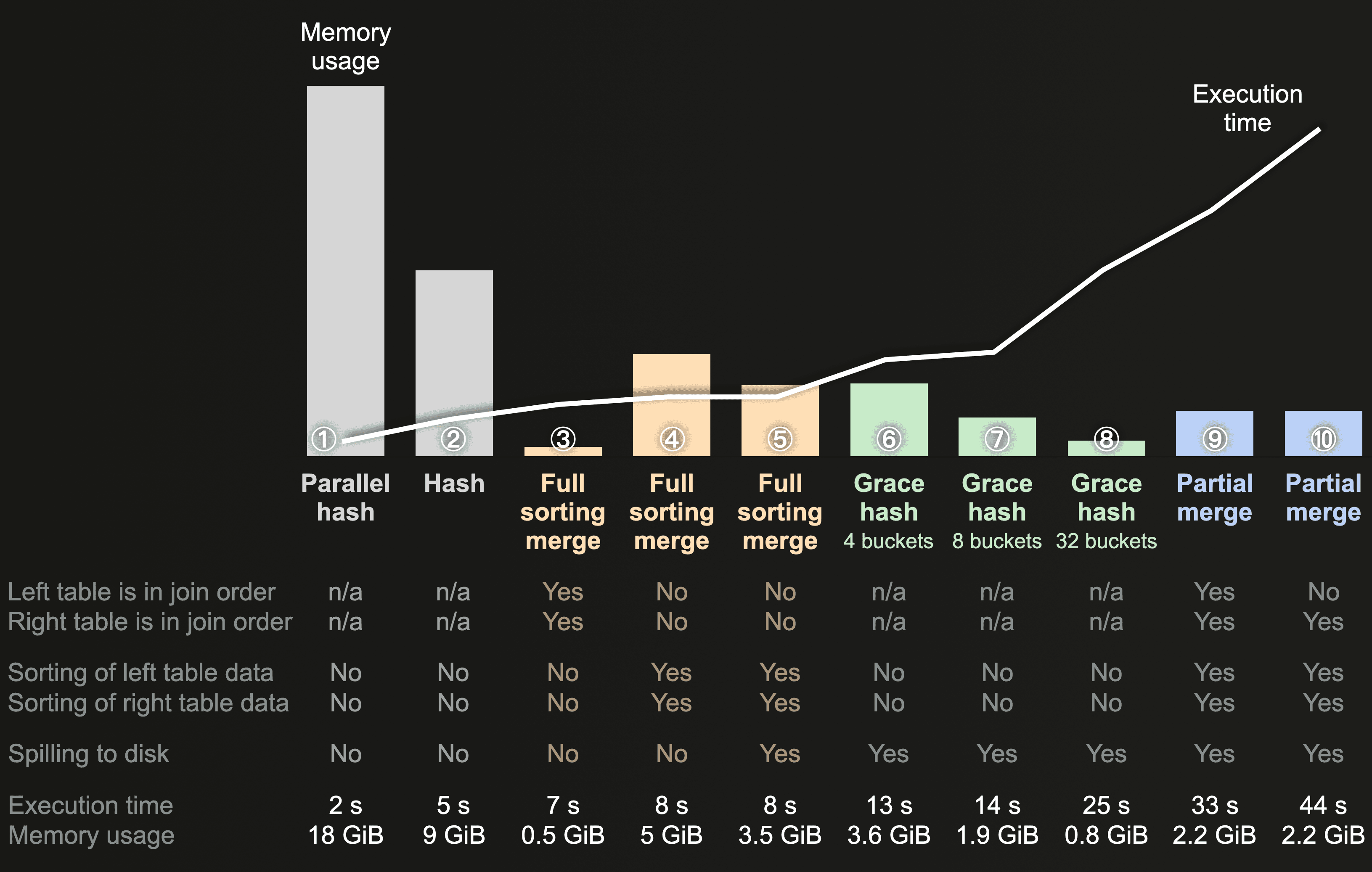
For our sample tables, the fastest join algorithms (see ① and ②) use the highest amount of memory. With the significant exception of the ③ full sorting merge. When the sorting phase can be skipped because the table's physical row order on disk is matching the join key sort order, then the full sorting merge’s execution time becomes competitive (or better - see the next chart below) with the hash join algorithms while requiring significantly less memory. In this case, because the data from both tables is streamed through the query engine block-wise and in order, just a few data blocks are in memory at the same time for merging.
With ④ in-memory sorting of both joined tables, the full sorting merge join has higher memory consumption. With ⑤ external sorting (sorted data is spilled to disk instead of in-memory sorting), the memory consumption is reduced at the expense of execution speed.
Grace hash is one of the three non-memory bound join algorithms that temporarily spill data to disk to reduce memory consumption. In contrast to the other two algorithms - full sorting merge and partial merge - grace hash allows one to control its memory usage based on the configured amount of buckets. We were interested in comparing the join speed of grace hash when it uses approximately the same and less memory amount as the other two non-memory bound algorithms. For this we run grace hash with three different bucket amounts. In run ⑥ with 4 buckets, we aligned the grace hash memory usage with the full sorting merge run ⑤. In this case, the grace hash was slower than the full sorting merge for joining our two example tables. In run ⑦ with 8 buckets we aligned the memory usage approximately with the partial merge run in ⑨. Here the grace hash run is two times faster. An additional run ⑧ with 32 buckets reduced the memory usage below the partial merge runs while still running faster.
For joining our example tables, the partial merge runs (see ⑨ and ⑩) are the slowest. Remember that the partial merge join fully sorts the right table and stores their sorted blocks, together with min-max index files temporarily to disk first. It then sorts and compares each block from the left table with the sorted blocks from the right table on disk while utilizing the min-max indexes for skipping non-matching blocks. For our example tables this is memory efficient but slow. Especially in run ⑩ when the physical row order of the left table doesn’t match the join key sorting order.
Generally, we can see that explicitly sorting the tables prior to identifying join matches is more expensive regarding execution time than just building hash tables from one of the tables.
However, keep in mind that we only benchmarked joins over one particular imdb dataset. Based on the volume of data, the data types and the value distribution of the join key columns, there can be scenarios where the sorting of data blocks is faster than building hash tables. For an example, see the following chart.
IMDB X-Large join runs
The following chart summarizes the query runs when the joined tables stem from the imdb_xlarge database:
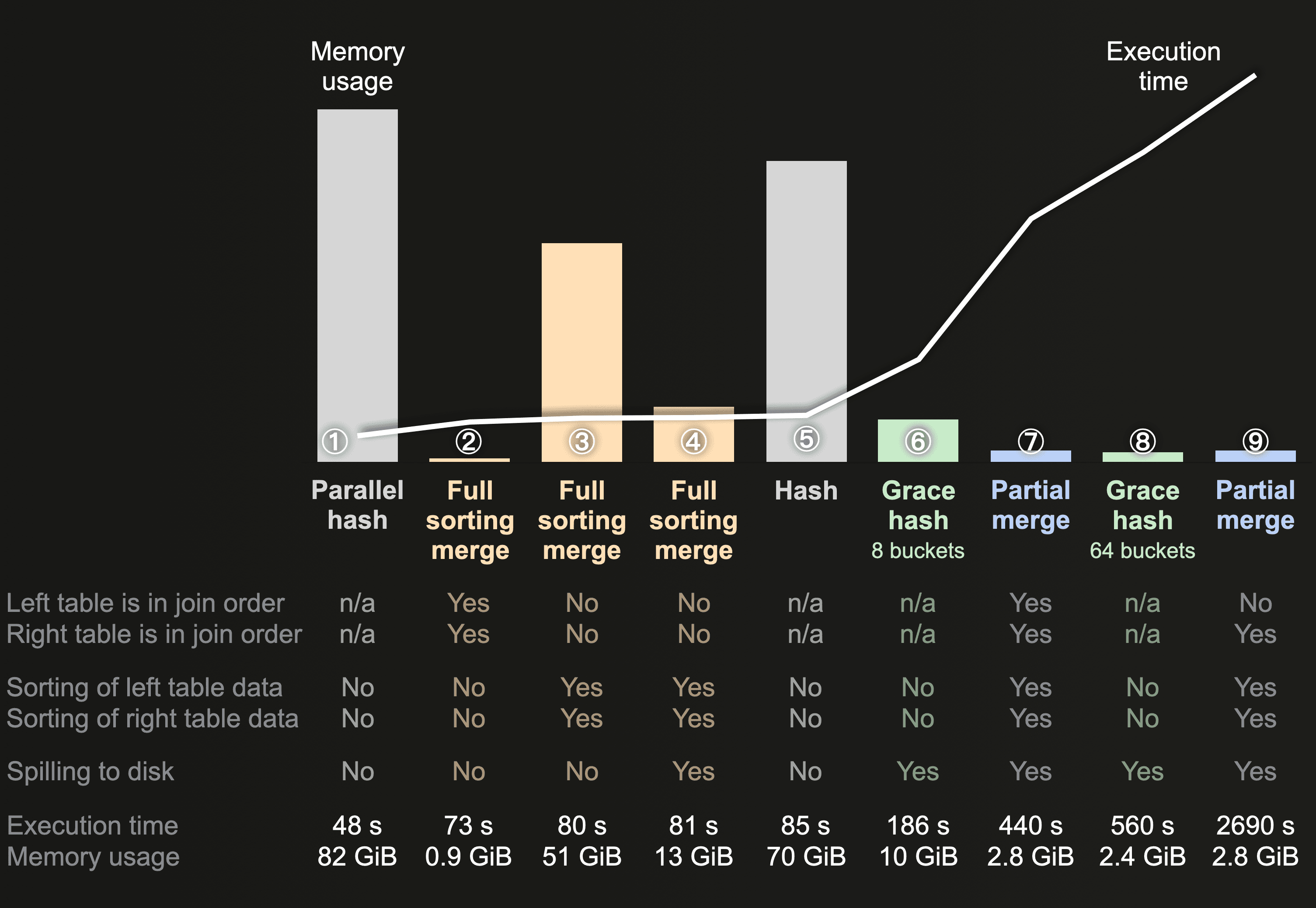
Like in the previous chart, the parallel hash join run ① is the fastest but also uses the most memory. Unlike in the previous chart, when joining the two larger tables from the imdb_xlarge database, the full sorting merge runs ②, ③, and ④ are faster than the hash join run ⑤ while using less peak main memory. As mentioned earlier, the creation of the in-memory hash table from the right-hand side table of the hash join is single-threaded and can apparently become a bottleneck if the right-hand side table is very large.
When the memory usage of the grace hash run in ⑥ with 8 buckets was approximately aligned with the full sorting merge run in ④ with external sorting, then, like in the previous chart, the grace hash was slower than the full sorting merge for joining our two example tables. With the memory usage approximately aligned in run ⑧, with 64 buckets, to the memory usage of the partial merge runs (see ⑦ and ⑨), then this time, in contrast to the previous chart, the partial merge join is faster than the grace hash join. For our example right-hand side table with 1 billion rows, the building and spilling of sorted blocks and the min-max index based scanning (partial_merge) is faster than the building and spilling and scanning of 64 hash tables (grace_hash with 64 buckets). The partial merge also benefits from the fact that the left table is sorted by the joining key, which enables efficient min-max index based scanning of the sorted blocks of our very large right table.
However, when the physical row order of the left table doesn’t match the join key sorting order in run ⑨, then then the min-max indexes of the sorted blocks from the right table don’t help as much, and in the worst case, effectively, a cross product is created between the blocks of both tables: for each block of the left table, a large set of sorted blocks from the right table is loaded from disk. Apparently, resulting in very high execution times, especially for very large tables.
Direct Join Runs
IMDB Large join runs
The following chart summarizes the peak memory usage and execution time of the same example LEFT ANY JOIN query for the imdb_large database, with
- the larger table on the right-hand side of the join
- different join algorithm settings
- a node with
30 CPU coresand the default setting of 30 formax_threadsand
The 4 query runs are ordered by execution time, starting with the fastest query run on the left-hand side of the chart:
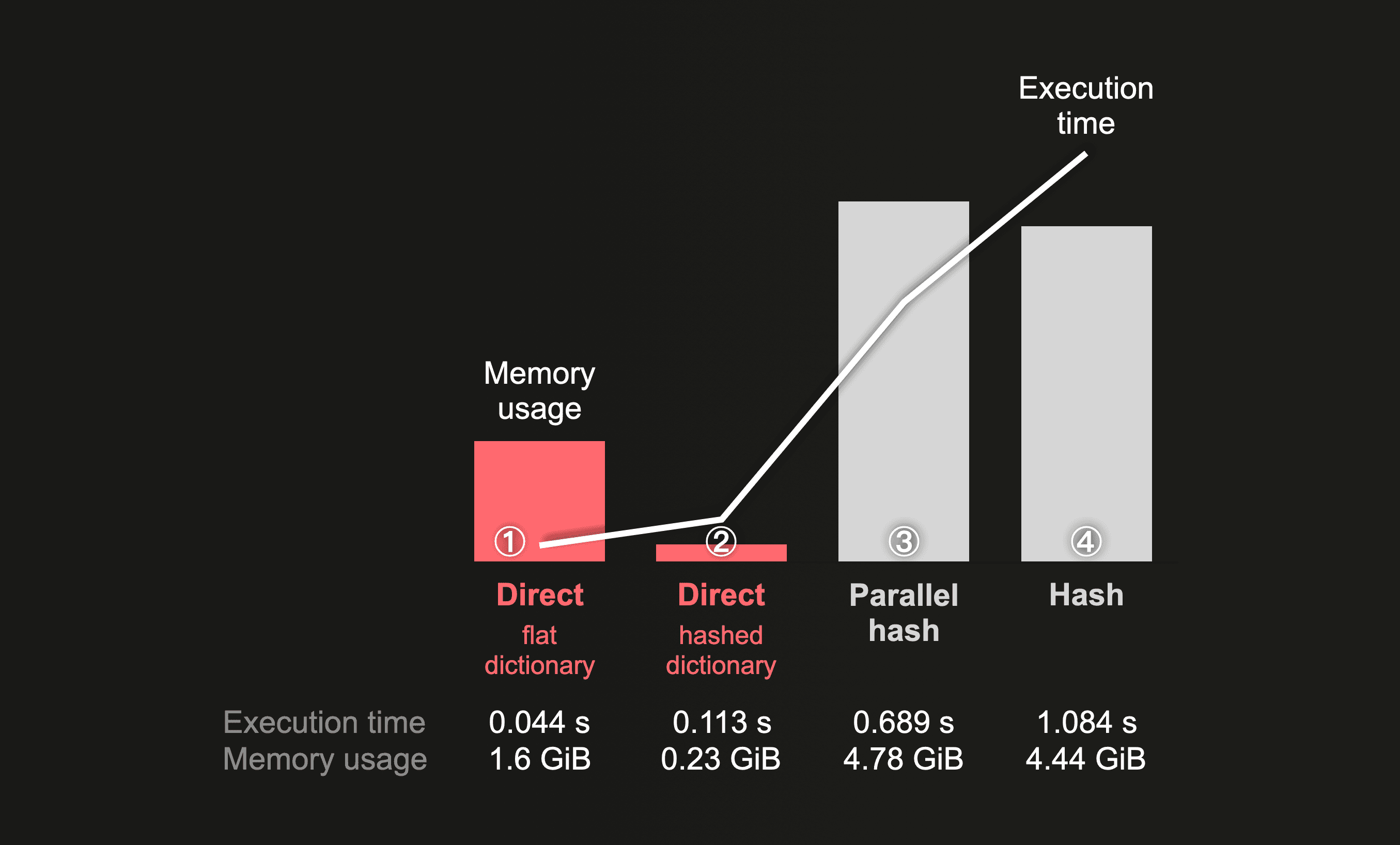
The direct join is as fast as it gets. ① With a right-hand side table backed by a dictionary with a flat memory layout, the algorithm is ~25 times faster than ④ hash join, ~15 times faster than the ③ parallel hash, and ~2.5 times faster than ② the direct join with the right-hand side table backed by a dictionary with a hashed memory layout. Regardless of dictionary layout type, the overall peak memory consumption is lower compared to the hash algorithm runs.
IMDB X-Large join runs
The following chart summarizes the direct join algorithm comparison runs when the joined tables stem from the imdb_xlarge database:
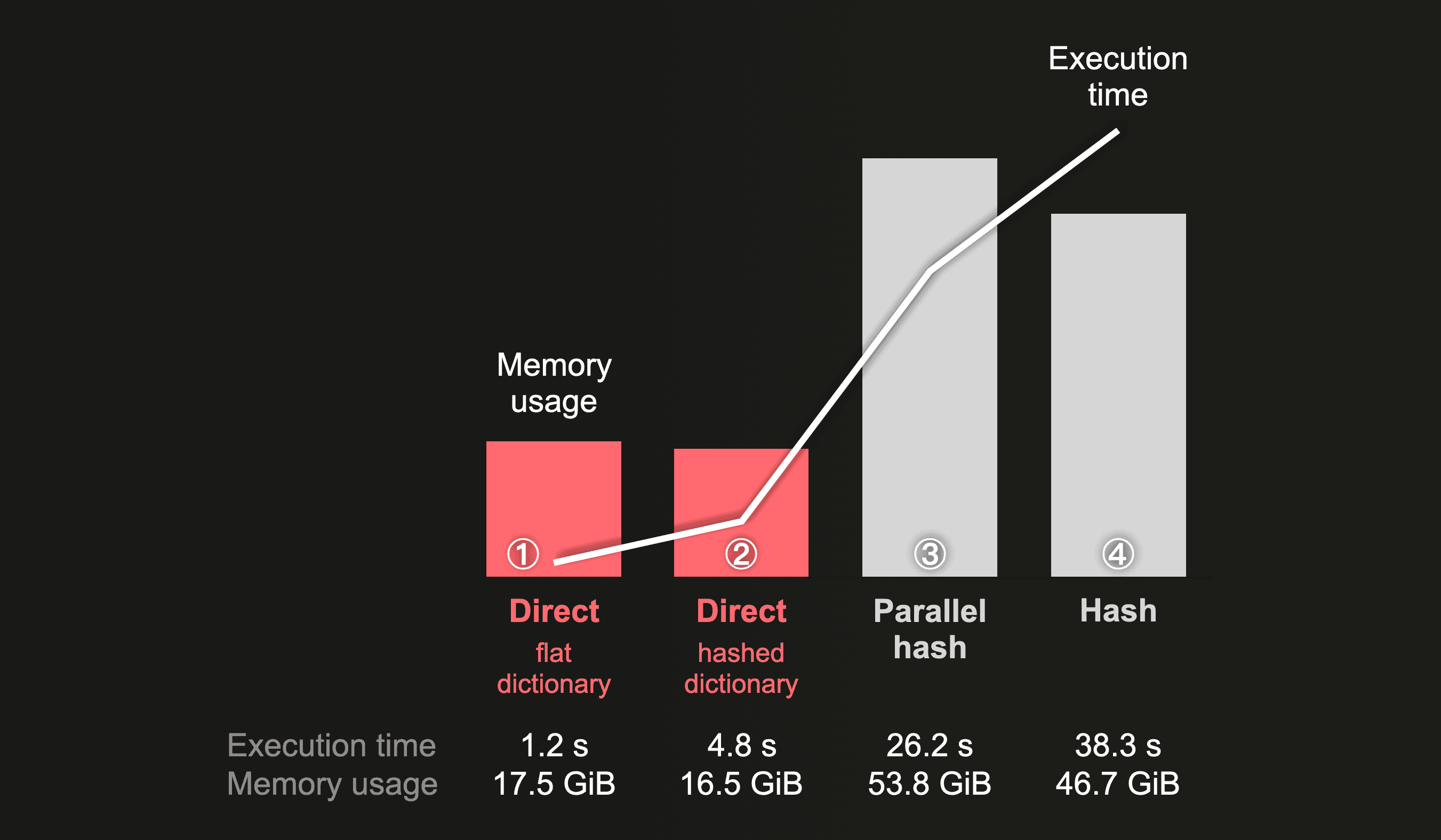
① The direct join algorithm with the right-hand side table backed by a dictionary with a flat memory layout joins the 100 million rows from the left table in ~1 s. That is fast! This is ~32 times faster than the ④ hash algorithm, ~22 times faster than the ③ parallel hash algorithm, and 4 times faster than the ② direct join with the right-hand side table backed by a dictionary with a hashed memory layout. Like in the previous chart, the overall peak memory consumption of the direct join runs is lower compared to the hash algorithm runs.
This finishes our exploration of the ClickHouse join algorithms.
In our next join series, we will explore distributed join execution in ClickHouse, stay tuned!


