使用 ClickStack 和 Elastic 进行搜索
在 ClickStack 和 Elastic 中搜索
ClickHouse 是一个原生支持 SQL 的引擎,从一开始就为高性能分析型工作负载而设计。相比之下,Elasticsearch 提供的是类 SQL 接口,会将 SQL 转换为底层的 Elasticsearch 查询 DSL——这意味着 SQL 不是一等公民,其特性对等性有限。
ClickHouse 不仅完整支持 SQL,还扩展了一系列面向可观测性的函数,例如 argMax、histogram 和 quantileTiming,用于简化对结构化日志、指标和链路追踪的查询。
对于简单的日志与链路追踪探索,ClickStack UI(HyperDX)提供了类 Lucene 语法,支持直观的文本式过滤,包括字段-值查询、范围查询、通配符等。其能力可与 Elasticsearch 中的 Lucene 语法以及 Kibana Query Language 的部分特性相媲美。
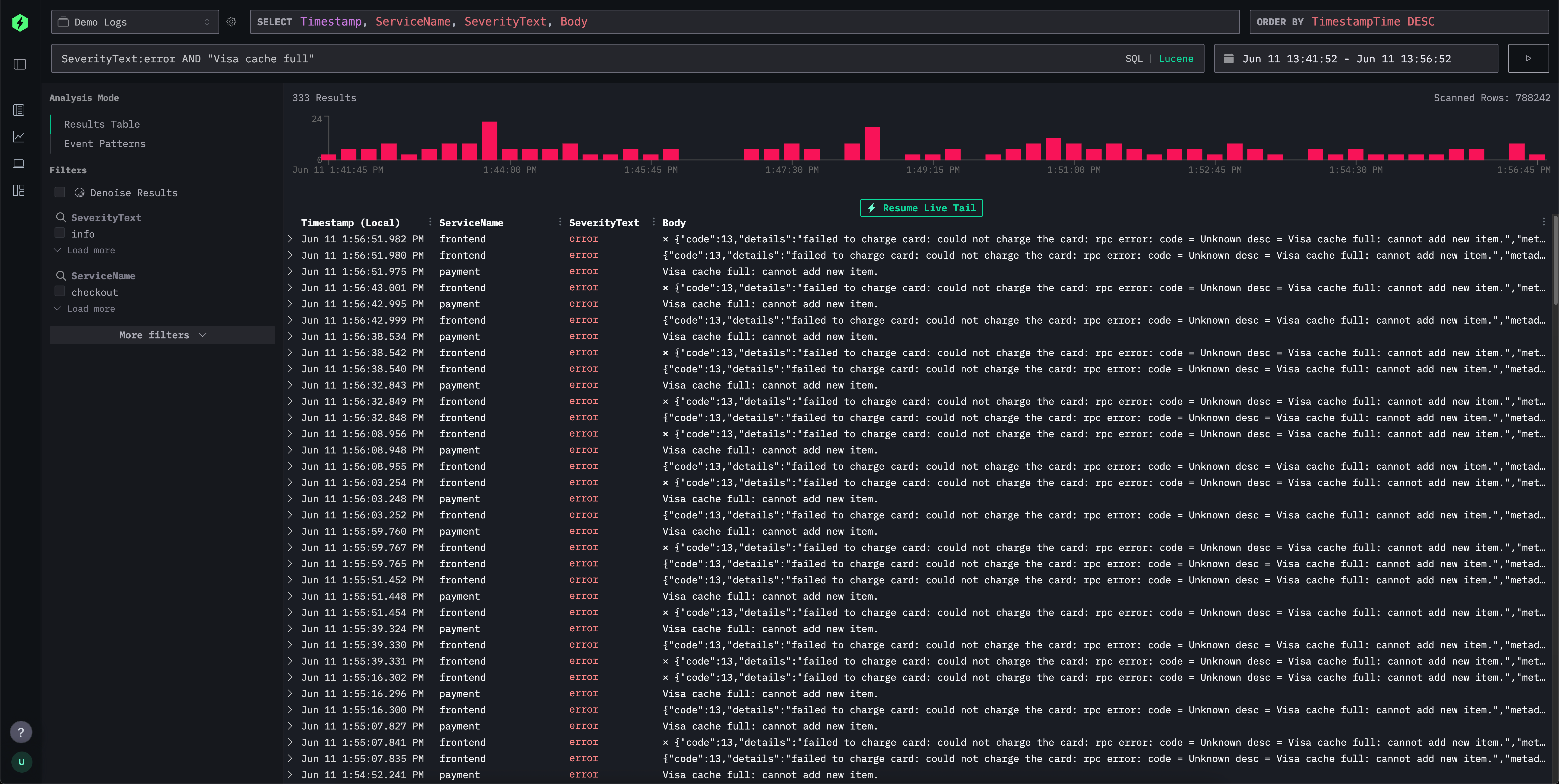
该搜索界面支持这种熟悉的语法,但会在后台将其转换为高效的 SQL WHERE 子句,使 Kibana 用户在保持熟悉体验的同时,在需要时仍能充分利用 SQL 的强大能力。这样,用户就可以利用 ClickHouse 中完整的字符串搜索函数、相似度函数以及日期时间函数。
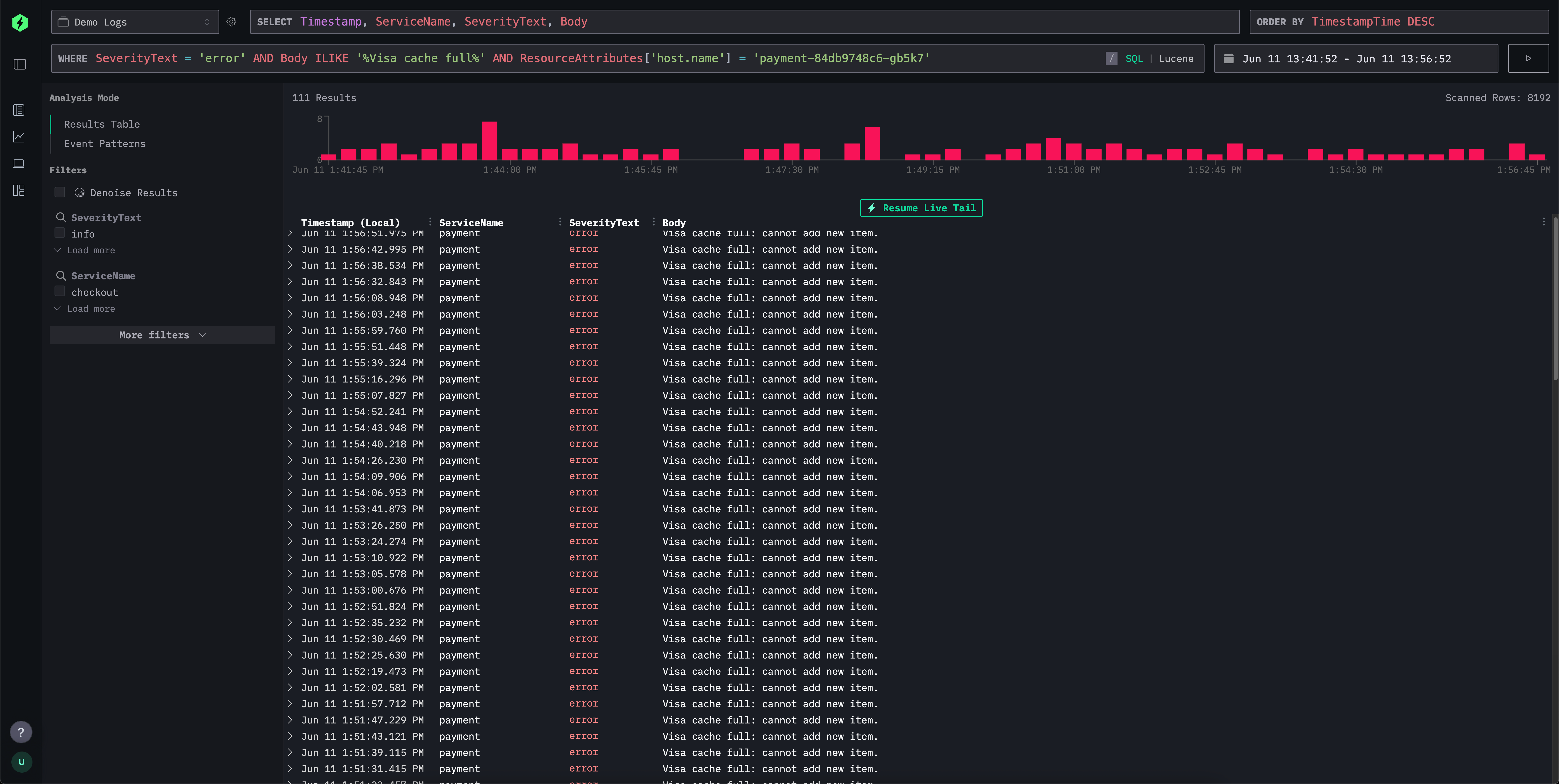
下面我们对比 ClickStack 和 Elasticsearch 中的 Lucene 查询语言。
ClickStack 搜索语法 vs Elasticsearch 查询字符串
ClickStack 和 Elasticsearch 都提供了灵活的查询语言,用于实现直观的日志和 trace 过滤。Elasticsearch 的查询字符串与其 DSL 和索引引擎紧密集成,而 ClickStack 则支持受 Lucene 启发的语法,并在内部转换为 ClickHouse SQL。下表概述了常见搜索模式在两个系统中的行为,对比语法上的相似性以及后端执行方式的差异。
| Feature | ClickStack Syntax | Elasticsearch Syntax | Comments |
|---|---|---|---|
| Free text search | error | error | 在所有已索引字段中匹配;在 ClickStack 中会被重写为多字段 SQL ILIKE。 |
| Field match | level:error | level:error | 语法完全相同。ClickStack 会在 ClickHouse 中匹配字段的精确值。 |
| Phrase search | "disk full" | "disk full" | 使用引号的文本会匹配完整短语;ClickHouse 使用字符串相等或 ILIKE。 |
| Field phrase match | message:"disk full" | message:"disk full" | 转换为 SQL ILIKE 或精确匹配。 |
| OR conditions | error OR warning | error OR warning | 词项之间的逻辑 OR;两个系统都原生支持。 |
| AND conditions | error AND db | error AND db | 都会转换为交集;用户语法上没有差异。 |
| Negation | NOT error or -error | NOT error or -error | 支持方式相同;ClickStack 会转换为 SQL NOT ILIKE。 |
| Grouping | (error OR fail) AND db | (error OR fail) AND db | 两者都支持标准的布尔分组。 |
| Wildcards | error* or *fail* | error*, *fail* | ClickStack 支持前缀/后缀通配符;Elasticsearch 为性能考虑默认禁用前导通配符。不支持在词项内部使用通配符,例如 f*ail。通配符必须与字段匹配一起使用。 |
| Ranges (numeric/date) | duration:[100 TO 200] | duration:[100 TO 200] | ClickStack 使用 SQL BETWEEN;Elasticsearch 会展开为范围查询。不支持在范围中使用无界的 *,例如 duration:[100 TO *]。如有需要,请使用下文的 Unbounded ranges。 |
| Unbounded ranges (numeric/date) | duration:>10 or duration:>=10 | duration:>10 or duration:>=10 | ClickStack 使用标准 SQL 比较运算符。 |
| Inclusive/exclusive | duration:{100 TO 200} (exclusive) | Same | 花括号表示排他区间边界。不支持在范围中使用 *,例如 duration:[100 TO *]。 |
| Exists check | N/A | _exists_:user or field:* | 不支持 _exists_。对于 Map 列 (如 LogAttributes) ,请使用 LogAttributes.log.file.path: *。对于根级列,这些列必须存在,如果在事件中未包含,则会有默认值。要搜索默认值或缺失列,请使用与 Elasticsearch 相同的语法,例如 ServiceName:* 或 ServiceName != ''。 |
| Regex | match function | name:/joh?n(ath[oa]n)/ | 当前在 Lucene 语法中不支持。你可以使用 SQL 以及 match 函数,或其他字符串搜索函数。 |
| Fuzzy match | editDistance('quikc', field) = 1 | quikc~ | 当前在 Lucene 语法中不支持。可在 SQL 中使用距离函数,例如 editDistance('rror', SeverityText) = 1,或其他相似度函数。 |
| Proximity search | Not supported | "fox quick"~5 | 当前在 Lucene 语法中不支持。 |
| Boosting | quick^2 fox | quick^2 fox | 目前在 ClickStack 中不支持。 |
| Field wildcard | service.*:error | service.*:error | 目前在 ClickStack 中不支持。 |
| Escaped special chars | 使用 \ 转义保留字符 | Same | 需要对保留符号进行转义。 |
存在/缺失差异
与 Elasticsearch 不同,在 Elasticsearch 中字段可以在事件中被完全省略,从而真正意义上“不存在”;而在 ClickHouse 中,表结构中的所有列都必须存在。如果在插入的事件中未提供某个字段:
- 对于
Nullable字段,该字段会被设置为NULL。 - 对于非 Nullable 字段(默认情况),该字段会被填充为默认值(通常是空字符串、0 或等价值)。
在 ClickStack 中,我们采用后一种方式,因为 Nullable 不建议使用。
这一行为意味着,无法像在 Elasticsearch 中那样,直接检查某个字段在“是否存在”意义上的状态。
相应地,用户可以使用 field:* 或 field != '' 来检查是否存在非空值。因此,无法区分真正缺失的字段和被显式设置为空的字段。
在实践中,对于可观测性用例,这一差异很少会导致问题,但在不同系统之间迁移或转换查询时需要牢记这一点。
