使用 Vector 进行数据摄取
Vector 是一个高性能、与供应商无关的可观测性数据管道。它通常用于从各种来源收集、转换和路由日志与指标,并且由于其灵活性和低资源占用,在日志摄取场景中尤其受欢迎。
在将 Vector 与 ClickStack 一起使用时,用户需要自行定义模式(schema)。这些模式可以遵循 OpenTelemetry 约定,也可以完全自定义,用于表示用户定义的事件结构。实践中,Vector 摄取最常见的使用场景是 日志,在这种场景下,用户希望在数据写入 ClickHouse 之前,对解析和富化具备完全的控制权。
本指南侧重介绍在 ClickStack 开源版和托管版中,如何使用 Vector 将数据导入 ClickStack。为简化说明,它不会深入讲解 Vector 的 sources 或 pipeline 配置,而是重点说明如何配置将数据写入 ClickHouse 的 sink,并确保生成的模式与 ClickStack 兼容。
对于 ClickStack 而言,无论使用开源还是托管部署,唯一严格的要求是数据中必须包含一个 时间戳列(timestamp column)(或等效的时间字段),并且可以在 ClickStack UI 中配置数据源时进行声明。
通过 Vector 发送数据
- 托管版 ClickStack
- 开源版 ClickStack
以下指南假定您已创建托管 ClickStack 服务并记录了服务凭据。如果尚未完成,请遵循托管 ClickStack 的入门指南,直至进入配置 Vector 的步骤。
创建数据库和表
Vector 需要在数据摄取之前定义表和架构。
首先创建一个数据库。可以通过 ClickHouse Cloud 控制台完成此操作。
在以下示例中,我们使用 logs:
为您的数据创建表。该表应与数据的输出架构相匹配。以下示例假定使用经典的 Nginx 结构。请根据您的数据进行相应调整,并遵循架构最佳实践。我们强烈建议您熟悉主键概念,并根据此处概述的指南选择主键。
上述主键假设了 ClickStack UI 中 Nginx 日志的典型访问模式,但可能需要根据生产环境中的工作负载进行调整。
将 ClickHouse sink 添加到 Vector 配置
修改 Vector 配置以包含 ClickHouse sink,更新 inputs 字段以接收来自现有管道的事件。
此配置假定您的上游 Vector 管道已准备好与目标 ClickHouse 模式匹配的数据,即字段已完成解析、正确命名并设置了适当的类型以供插入。请参阅下方的 Nginx 示例,了解如何将原始日志行解析和规范化为适用于 ClickStack 的模式的完整示例。
默认情况下,我们建议使用 json_each_row 格式,该格式将每个事件编码为每行一个 JSON 对象。这是 ClickStack 在摄取 JSON 数据时的默认格式和推荐格式,应优先选择此格式,而非其他格式(例如将 JSON 对象编码为字符串)。
ClickHouse sink 还支持 Arrow 流编码(目前处于 beta 阶段)。这可以提供更高的吞吐量,但存在重要限制:数据库和表必须是静态的,因为 schema 仅在启动时获取一次,且不支持动态路由。因此,Arrow 编码最适合固定且定义明确的摄取管道。
我们建议查阅 Vector 文档中可用的接收器配置选项:
上述示例使用了托管 ClickStack 的默认用户。对于生产环境部署,我们建议创建专用的摄取用户,并配置适当的权限和限制。
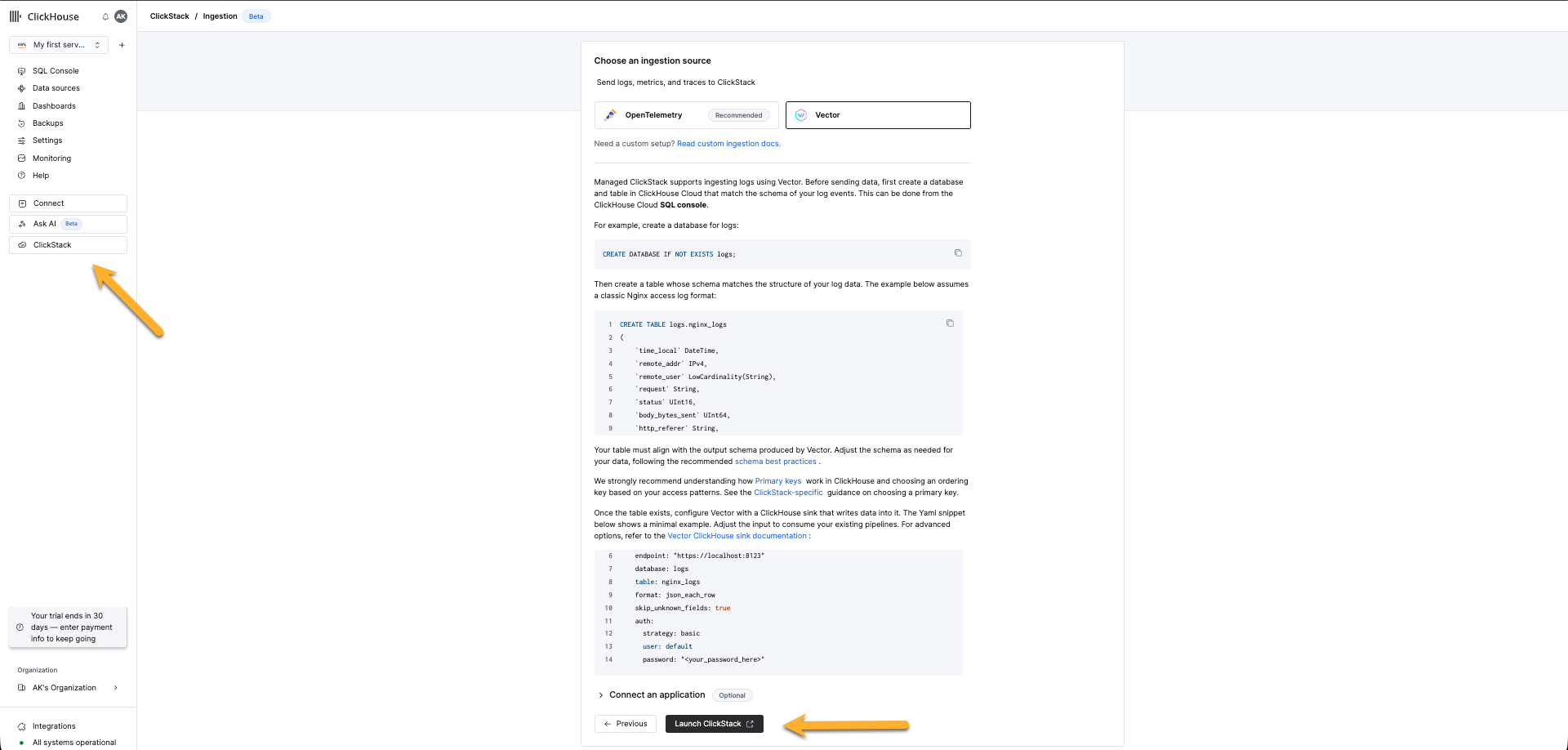
导航到 ClickStack UI
导航至您的托管 ClickStack 服务,从左侧菜单中选择"ClickStack"。如果您已完成初始配置向导,系统将在新标签页中启动 ClickStack UI,并自动完成身份验证。如果尚未完成,请继续完成初始配置向导,在选择 Vector 作为输入源后,点击"启动 ClickStack"。
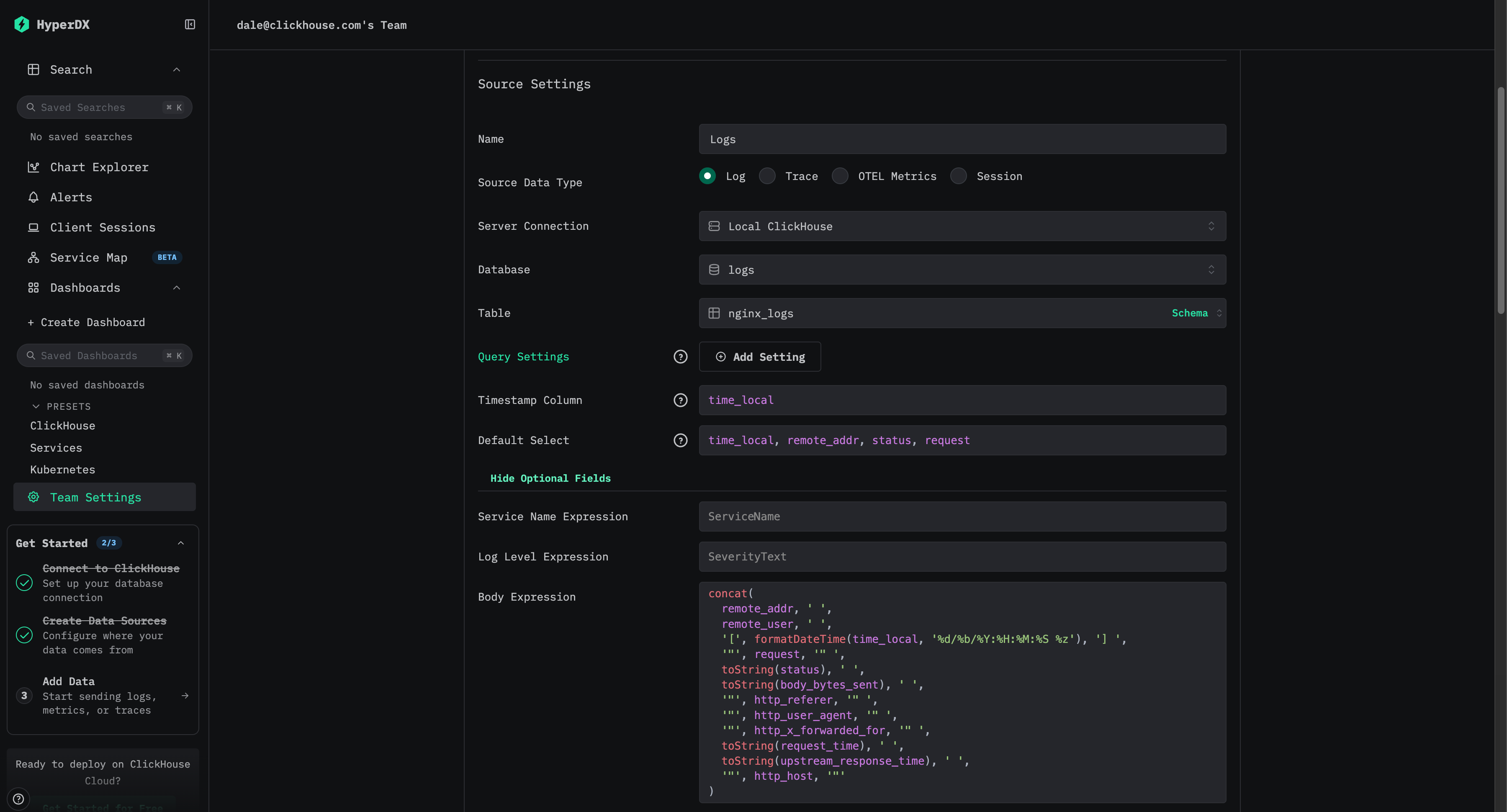
创建数据源
创建日志数据源。如果不存在数据源,首次登录时系统将提示您创建。否则,请导航至团队设置并添加新数据源。
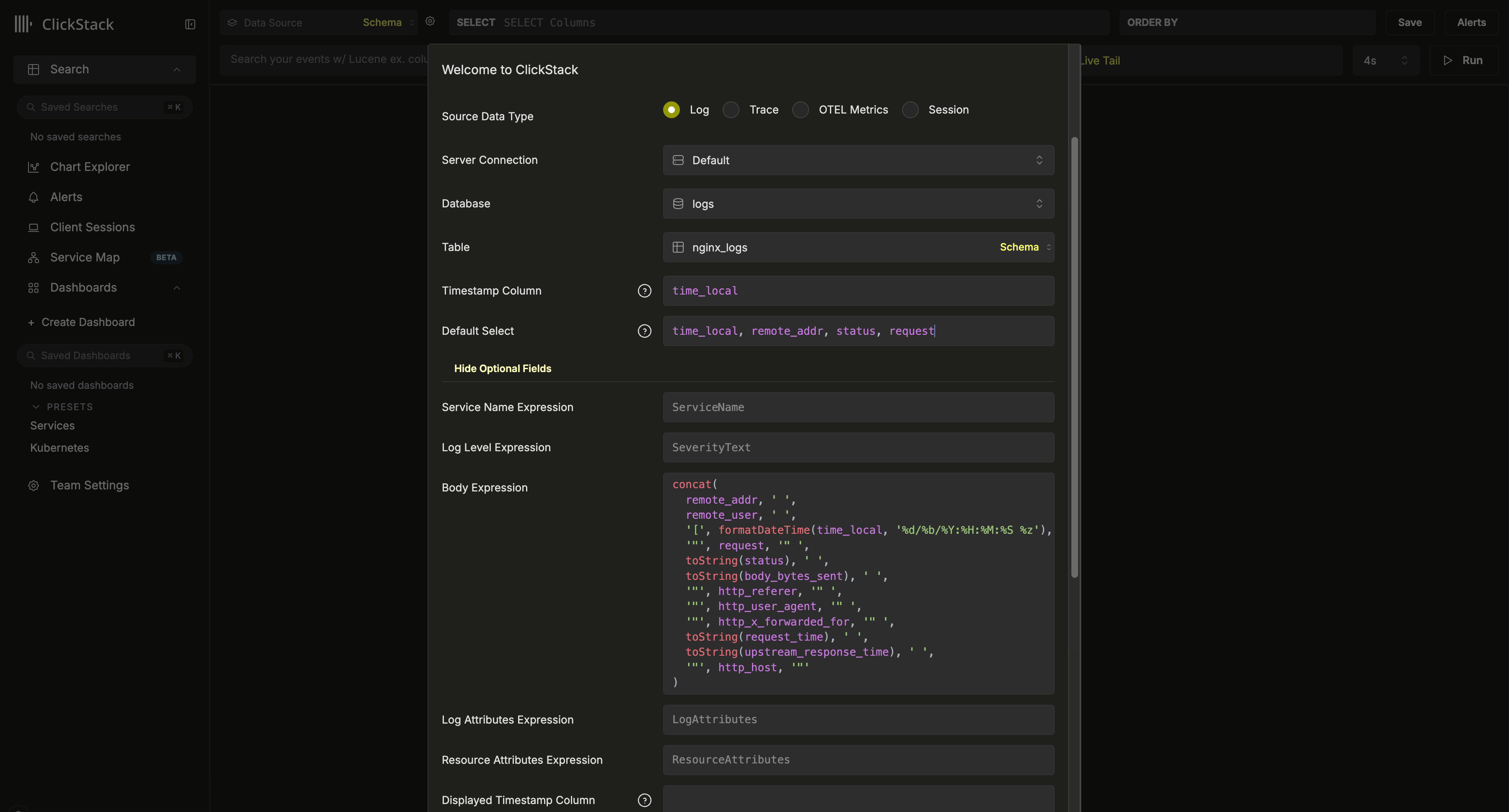
上述配置假定采用 Nginx 风格的模式,其中 time_local 列用作时间戳。该列应尽可能为主键中声明的时间戳列。此列为必需项。
我们还建议更新 Default SELECT 以明确定义日志视图中返回的列。如果有其他可用字段(例如服务名称、日志级别或 body 列),也可以进行配置。如果时间戳显示列与表主键中使用的列不同且已在上文配置,则也可以覆盖该列。
在上述示例中,数据中不存在 Body 列。该列通过 SQL 表达式定义,从可用字段重构 Nginx 日志行。
有关其他可用选项,请参阅配置参考。
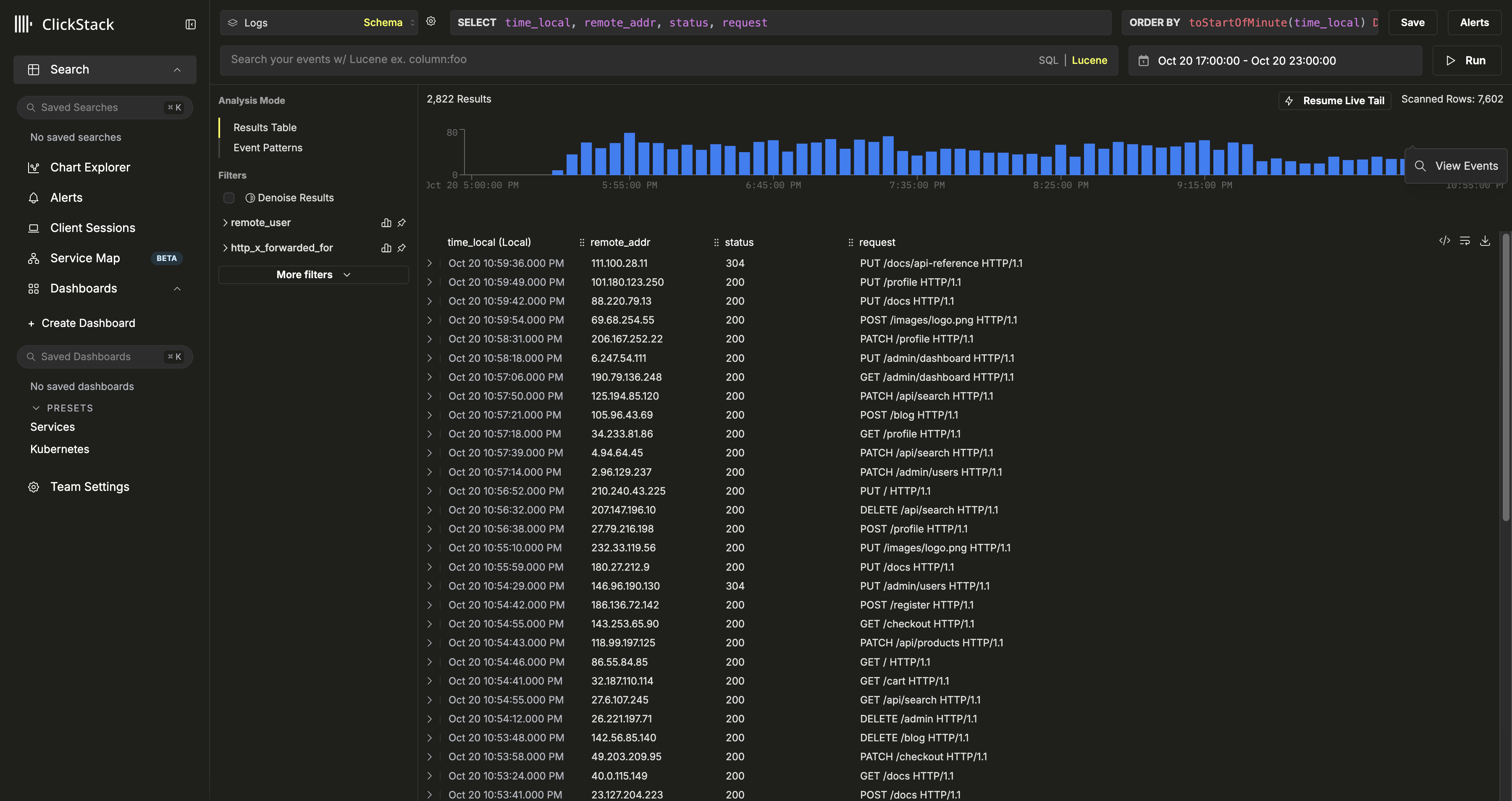
创建数据库和表
Vector 需要在数据摄取之前定义表和架构。
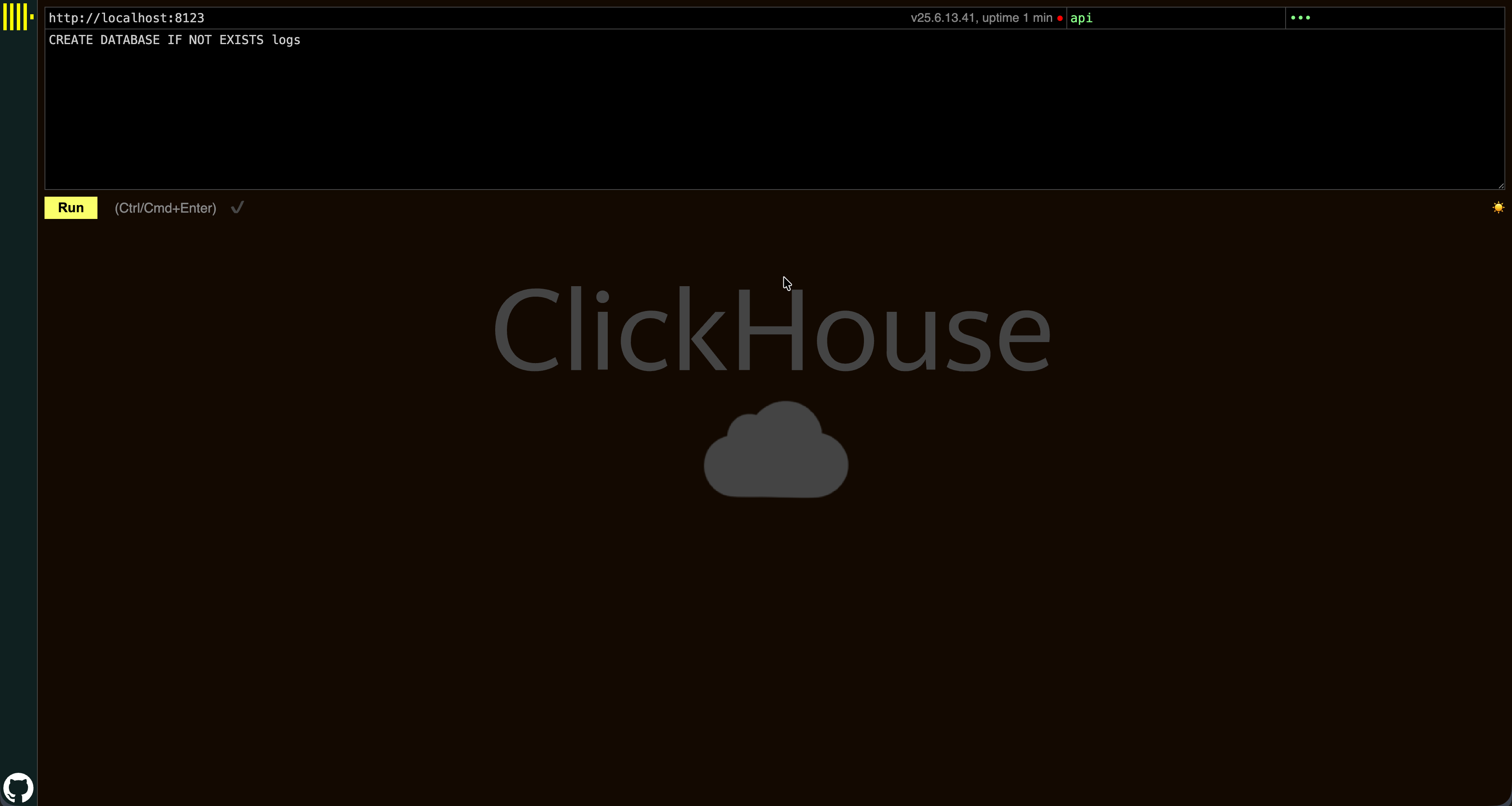
首先创建一个数据库。这可以通过 ClickHouse Web 用户界面 在 http://localhost:8123/play 完成。使用默认用户名和密码 api:api。
在以下示例中,我们使用 logs:
为您的数据创建表。该表应与数据的输出架构相匹配。以下示例假定使用经典的 Nginx 结构。请根据您的数据进行相应调整,并遵循架构最佳实践。我们强烈建议您熟悉主键概念,并根据此处概述的指南选择主键。
上述主键假设了 ClickStack UI 中 Nginx 日志的典型访问模式,但可能需要根据生产环境中的工作负载进行调整。
将 ClickHouse sink 添加到 Vector 配置
使用 Vector 向 ClickStack 摄取数据时,应直接发送到 ClickHouse,绕过收集器公开的 OTLP 端点。
修改 Vector 配置以包含 ClickHouse sink,更新 inputs 字段以接收来自现有管道的事件。
此配置假定您的上游 Vector 管道已准备好与目标 ClickHouse 模式匹配的数据,即字段已完成解析、正确命名并设置了适当的类型以供插入。请参阅下方的 Nginx 示例,了解如何将原始日志行解析和规范化为适用于 ClickStack 的模式的完整示例。
默认情况下,我们建议使用 json_each_row 格式,该格式将每个事件编码为每行一个 JSON 对象。这是 ClickStack 在摄取 JSON 数据时的默认格式和推荐格式,应优先选择此格式,而非其他格式(例如将 JSON 对象编码为字符串)。
ClickHouse sink 还支持 Arrow 流编码(目前处于 beta 阶段)。这可以提供更高的吞吐量,但存在重要限制:数据库和表必须是静态的,因为 schema 仅在启动时获取一次,且不支持动态路由。因此,Arrow 编码最适合固定且定义明确的摄取管道。
我们建议查阅 Vector 文档中可用的接收器配置选项:
上述示例使用 api 用户用于 ClickStack Open Source。对于生产环境部署,我们建议创建专用的摄取用户并设置适当的权限和限制。上述配置还假设 Vector 与 ClickStack 运行在同一主机上。在生产环境部署中,这种情况可能会有所不同。我们建议通过安全的 HTTPS 端口 8443 发送数据。
使用 Vector 的示例数据集
为了提供一个更完整的示例,我们在下面使用一个 Nginx 日志文件。
- 托管版 ClickStack
- ClickStack 开源版
以下指南假定您已创建托管 ClickStack 服务并记录了服务凭据。如果尚未完成,请遵循托管 ClickStack 的入门指南,直至进入配置 Vector 的步骤。
安装 Vector
在继续之前,请确保在计划运行摄取 pipeline 的系统上已安装 Vector。请按照官方 Vector 安装指南安装适合您环境的预构建二进制文件或软件包:
安装完成后,在继续下面的配置步骤之前,先确认 vector 可执行文件已在您的 PATH 中可用。
它可以安装在与 ClickStack OTel collector 相同的实例上。
在将 Vector 部署到生产环境时,请遵循架构与安全方面的最佳实践。
下载示例数据
如果你想使用示例数据集进行试验,请下载以下 nginx 示例。
这些数据是从一个已配置为输出 JSON 格式日志(便于解析)的 Nginx 实例中收集的。有关这些日志的 Nginx 配置,请参见 《使用 ClickStack 监控 Nginx 日志》。
创建数据库和表
Vector 要求在数据摄取之前先定义表和 schema。
首先创建一个数据库。可以通过 ClickHouse Cloud 控制台完成此操作。
创建数据库 logs:
创建数据表。
上述主键假设了在 ClickStack UI 中访问 Nginx 日志的典型模式,但可能需要根据生产环境中的工作负载进行调整。
导航到 ClickStack UI
导航至您的托管 ClickStack 服务,从左侧菜单中选择"ClickStack"。如果您已完成初始配置,系统将在新标签页中启动 ClickStack UI,并自动完成身份验证。如果尚未完成,请继续完成初始配置流程,在选择 Vector 作为输入源后点击"启动 ClickStack"。
以下指南假设您已通过入门指南完成 ClickStack 开源版的部署配置。
安装 Vector
在继续之前,请确保在计划运行摄取 pipeline 的系统上已安装 Vector。请按照官方 Vector 安装指南安装适合您环境的预构建二进制文件或软件包:
安装完成后,在继续下面的配置步骤之前,先确认 vector 可执行文件已在您的 PATH 中可用。
它可以安装在与 ClickStack OTel collector 相同的实例上。
在将 Vector 部署到生产环境时,请遵循架构与安全方面的最佳实践。
下载示例数据
如果你想使用示例数据集进行试验,请下载以下 nginx 示例。
这些数据是从一个已配置为输出 JSON 格式日志(便于解析)的 Nginx 实例中收集的。有关这些日志的 Nginx 配置,请参见 《使用 ClickStack 监控 Nginx 日志》。
创建数据库和表
Vector 要求在数据摄取之前先定义表和 schema。
首先创建一个数据库。这可以通过 ClickHouse Web 用户界面 在 http://localhost:8123/play 完成。使用默认用户名和密码 api:api。
创建数据库 logs:
创建数据表。
上述主键假设了在 ClickStack UI 中访问 Nginx 日志的典型模式,但可能需要根据生产环境中的工作负载进行调整。
