远程演示数据集
本指南假设您已按照一体化镜像部署说明或仅本地模式部署了开源版 ClickStack,并完成了初始用户创建。或者,您也可以跳过所有本地环境搭建,直接连接到我们托管的 ClickStack 演示实例 play-clickstack.clickhouse.com,该实例使用的就是本数据集。
本指南使用托管在公共 ClickHouse playground sql.clickhouse.com 上的示例数据集,您可以从本地部署的 ClickStack 连接到该数据集。
使用 Managed ClickStack 时不支持远程数据库。因此,在该环境中无法使用此数据集。
其中包含了大约 40 小时的数据,这些数据捕获自官方 OpenTelemetry (OTel) 演示的 ClickHouse 版本。数据会在每晚重放,并将时间戳调整到当前时间窗口,使用户能够通过 HyperDX 中集成的日志、链路追踪和指标来探索系统行为。
由于数据集会从每天的午夜开始重放,因此具体的可视化结果可能会因您查看演示的时间不同而有所变化。
演示场景
在本次演示中,我们将调查一个与销售天文望远镜及相关配件的电商网站有关的故障事件。
客服团队报告称,用户在结账时完成支付时遇到问题。该问题已升级至网站可靠性工程(SRE)团队进行排查。
SRE 团队将使用 HyperDX 分析日志、追踪和指标,以诊断并解决该问题,随后再审查会话数据,以确认他们的结论是否与真实的用户行为一致。
OpenTelemetry 演示
本演示使用了官方 OpenTelemetry 演示的一个 由 ClickStack 维护的分支。
演示架构
此演示由使用不同编程语言编写的微服务组成,这些微服务通过 gRPC 和 HTTP 相互通信,并包含一个使用 Locust 模拟用户流量的负载生成器。该演示的原始源代码已被修改为使用 ClickStack instrumentation。
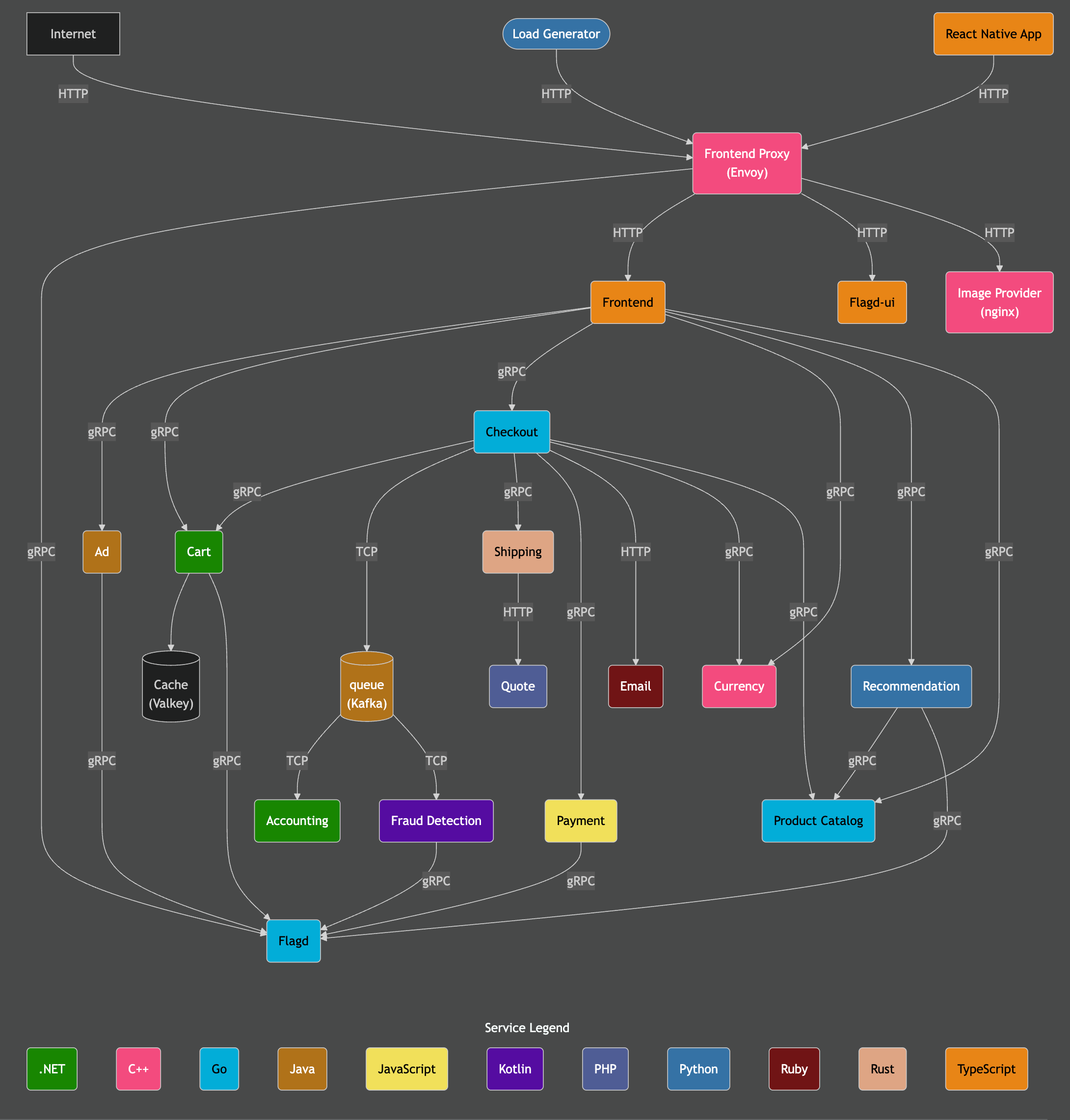
致谢:https://opentelemetry.io/docs/demo/architecture/
有关该演示的更多详细信息,请参阅:
演示步骤
我们已使用 ClickStack SDKS 对本演示进行了观测性埋点,将各个服务部署在 Kubernetes 中,并从中采集指标和日志。
连接到演示服务器
如果在本地模式部署时点击了 Connect to Demo Server,则可以跳过此步骤。如果使用此模式,数据源将以 Demo_ 为前缀,例如 Demo_Logs
导航至 Team Settings,然后点击 Local Connection 的 Edit 按钮:
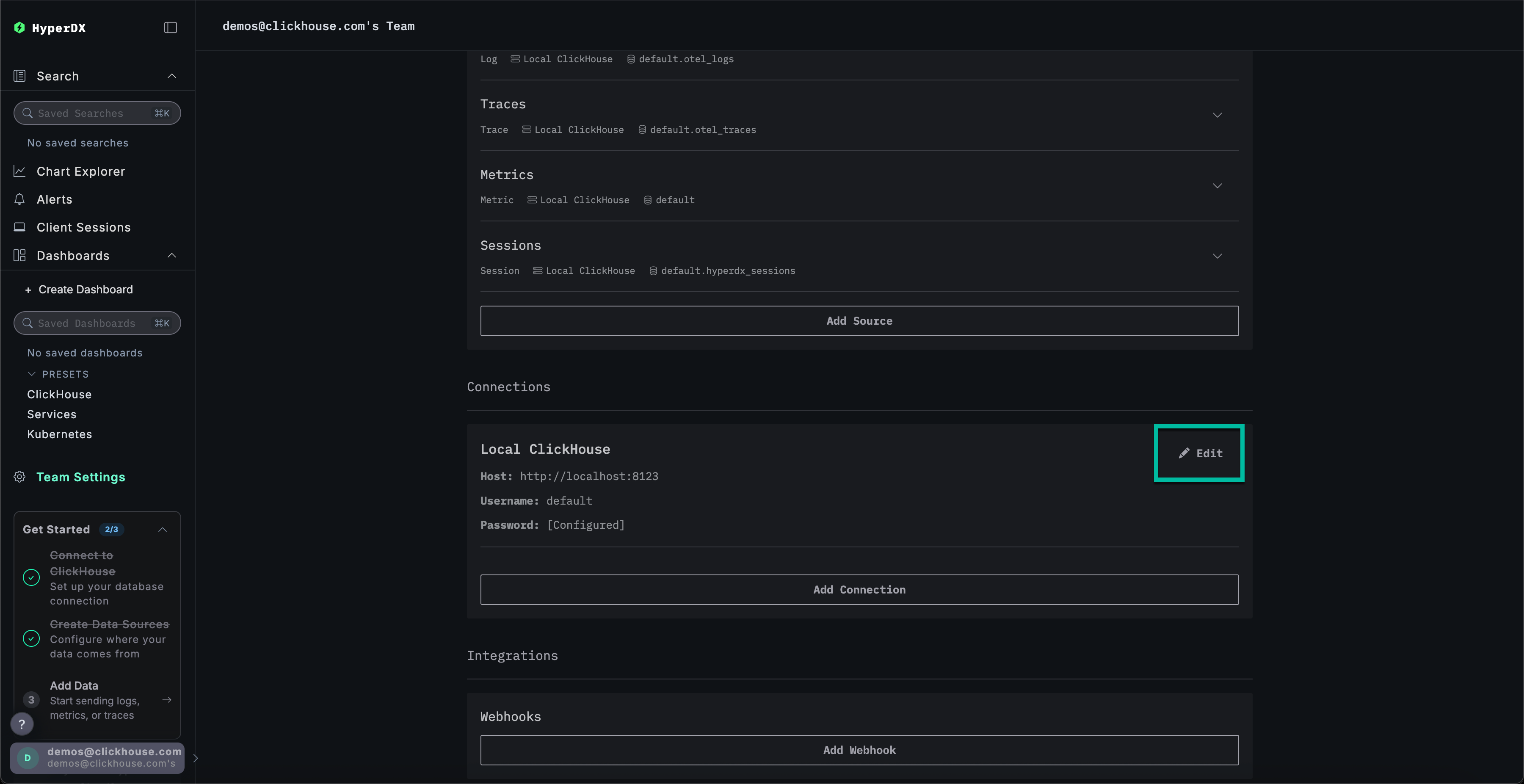
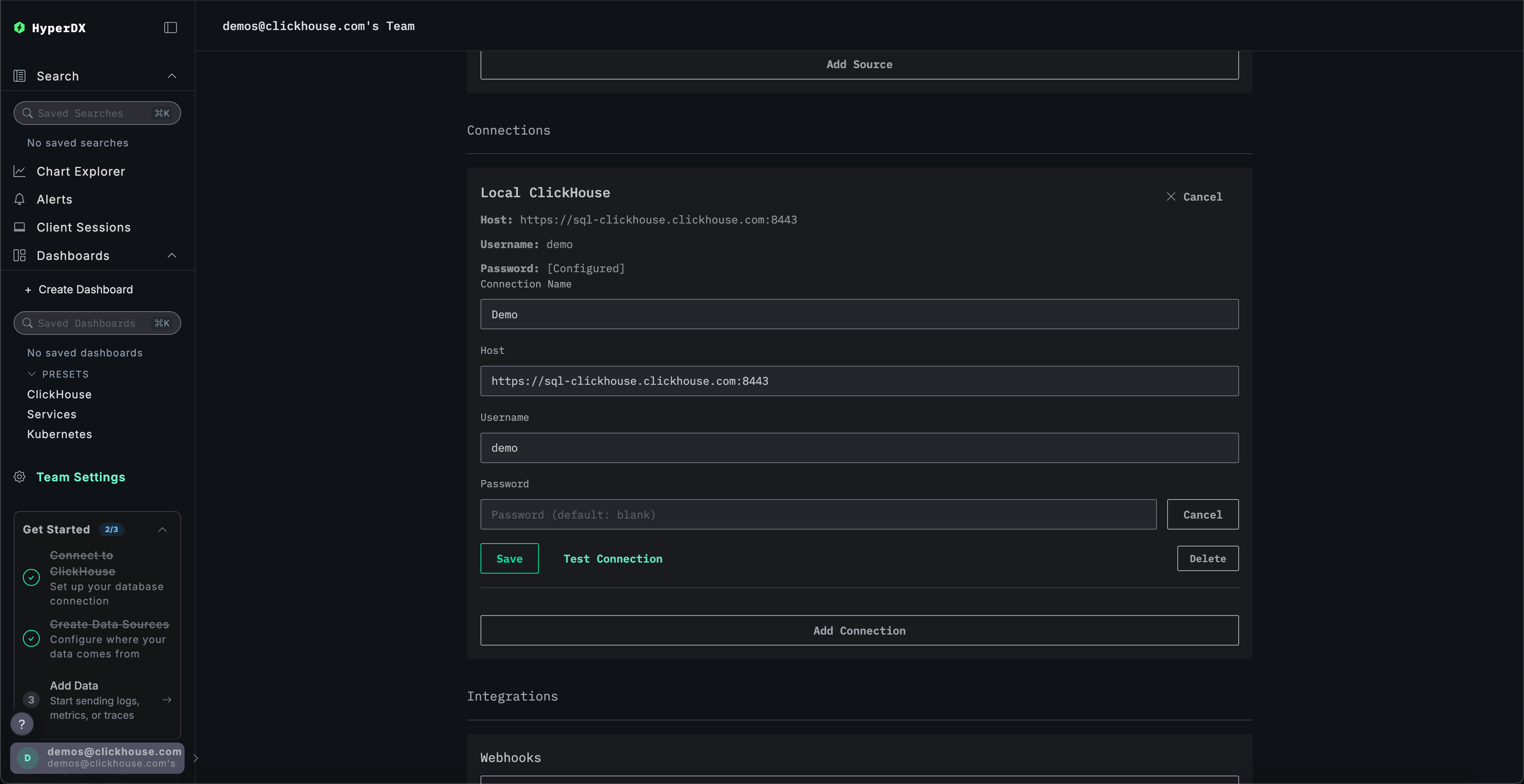
将连接重命名为 Demo,并在后续表单中填写演示服务器的以下连接详细信息:
连接名称:DemoHost:https://sql-clickhouse.clickhouse.comUsername:otel_demoPassword:留空
修改数据源
如果在本地模式部署时点击了 Connect to Demo Server,则可以跳过此步骤。如果使用此模式,数据源将以 Demo_ 为前缀,例如 Demo_Logs
向上滚动到 Sources 并修改每个数据源 - Logs、Traces、Metrics 和 Sessions - 使其使用 otel_v2 数据库。
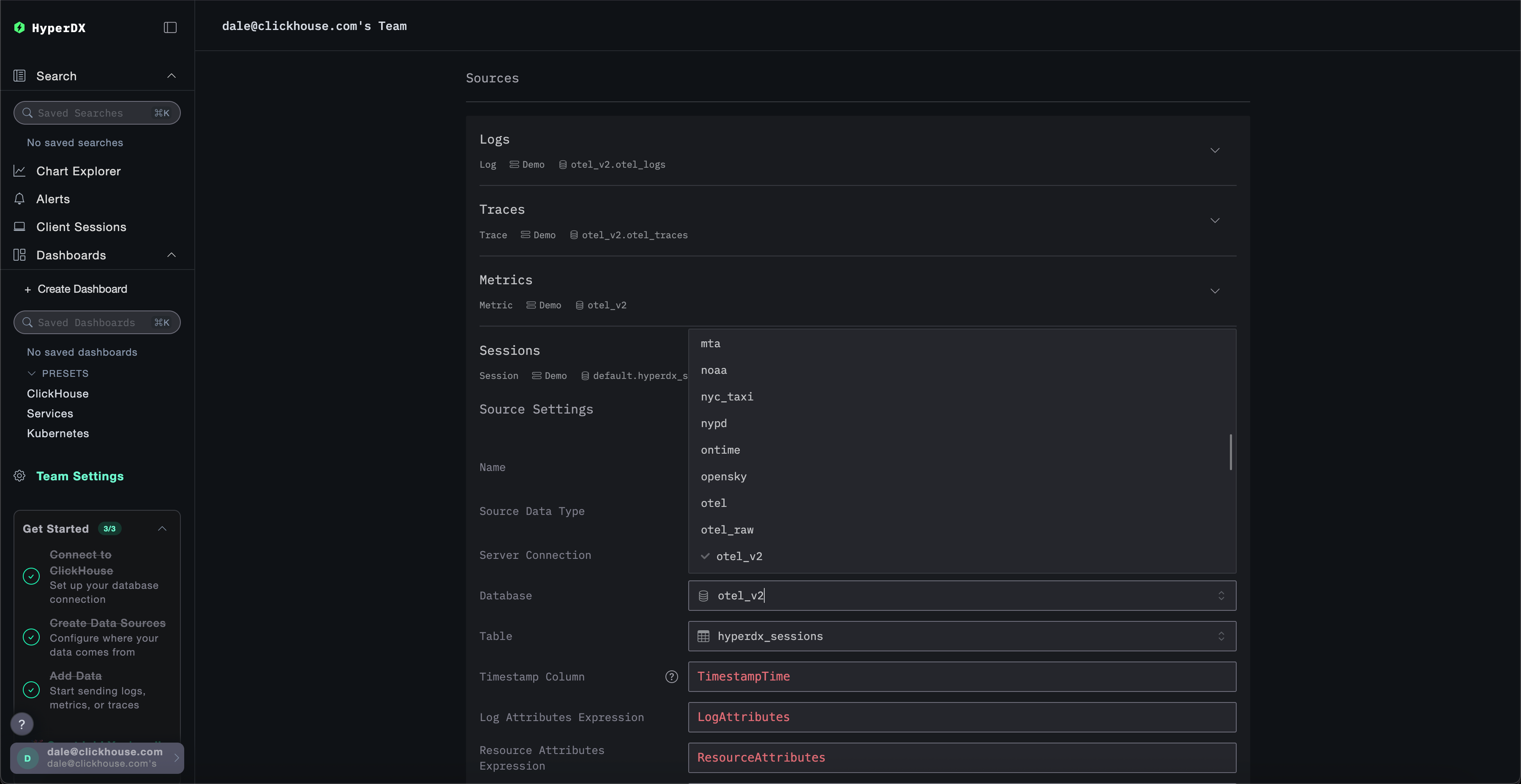
您可能需要刷新页面,以确保每个数据源中显示完整的数据库列表。
调整时间范围
使用右上角的时间选择器调整时间,以显示过去 1 天 的所有数据。
您可能会在概览条形图中观察到错误数量的细微差异,表现为连续几个柱状图的红色部分略有增加。
柱状图的位置将根据查询数据集的时间而有所不同。
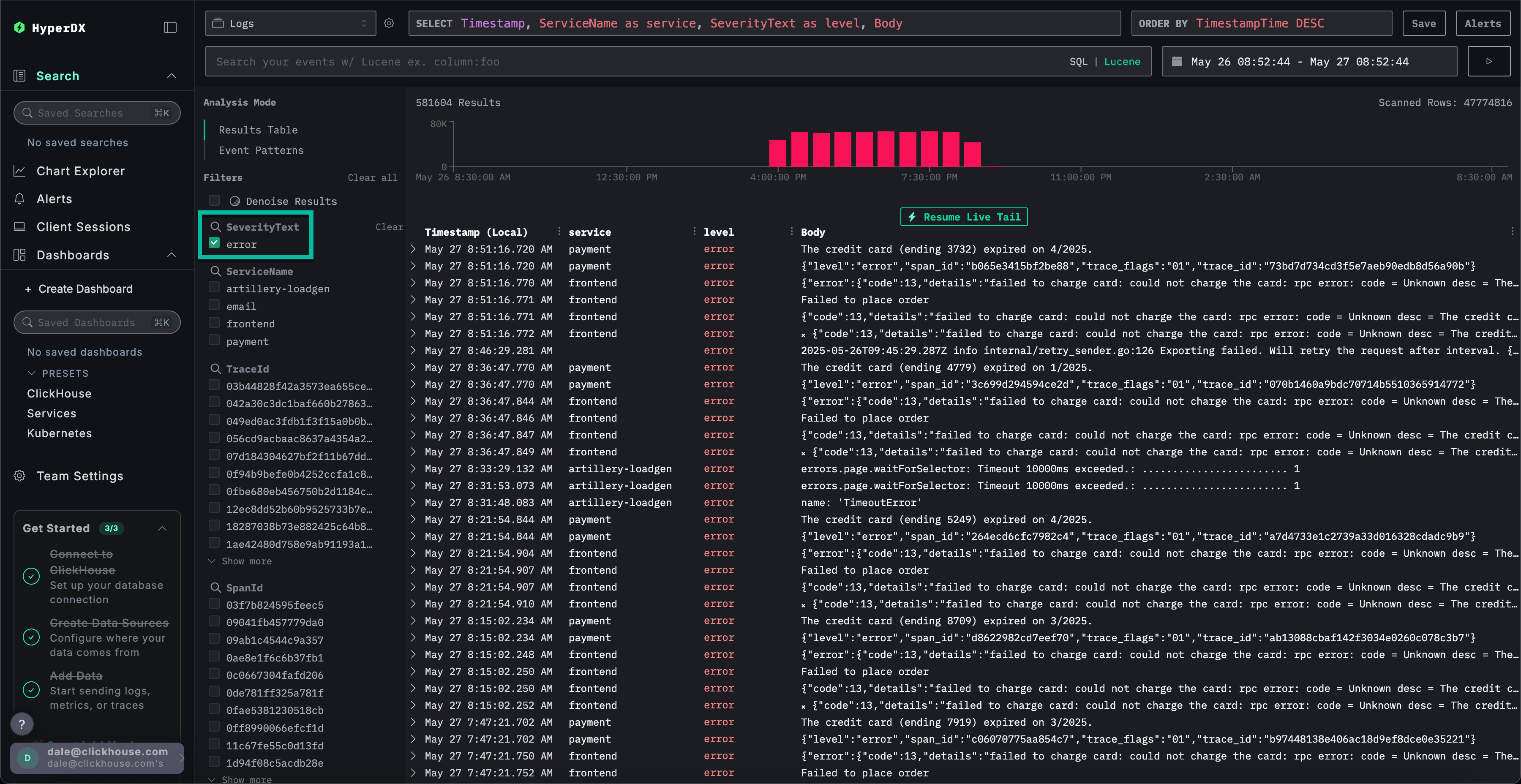
识别错误模式
通过 HyperDX 的聚类功能,您可以自动识别错误并将其分组为有意义的模式。在处理大量日志和链路追踪数据时,这可以加快分析速度。要使用该功能,请从左侧面板的 Analysis Mode 菜单中选择 Event Patterns。
错误集群显示了与支付失败相关的问题,包括一个名为 Failed to place order 的模式。其他集群还显示了信用卡扣款问题和缓存已满的问题。
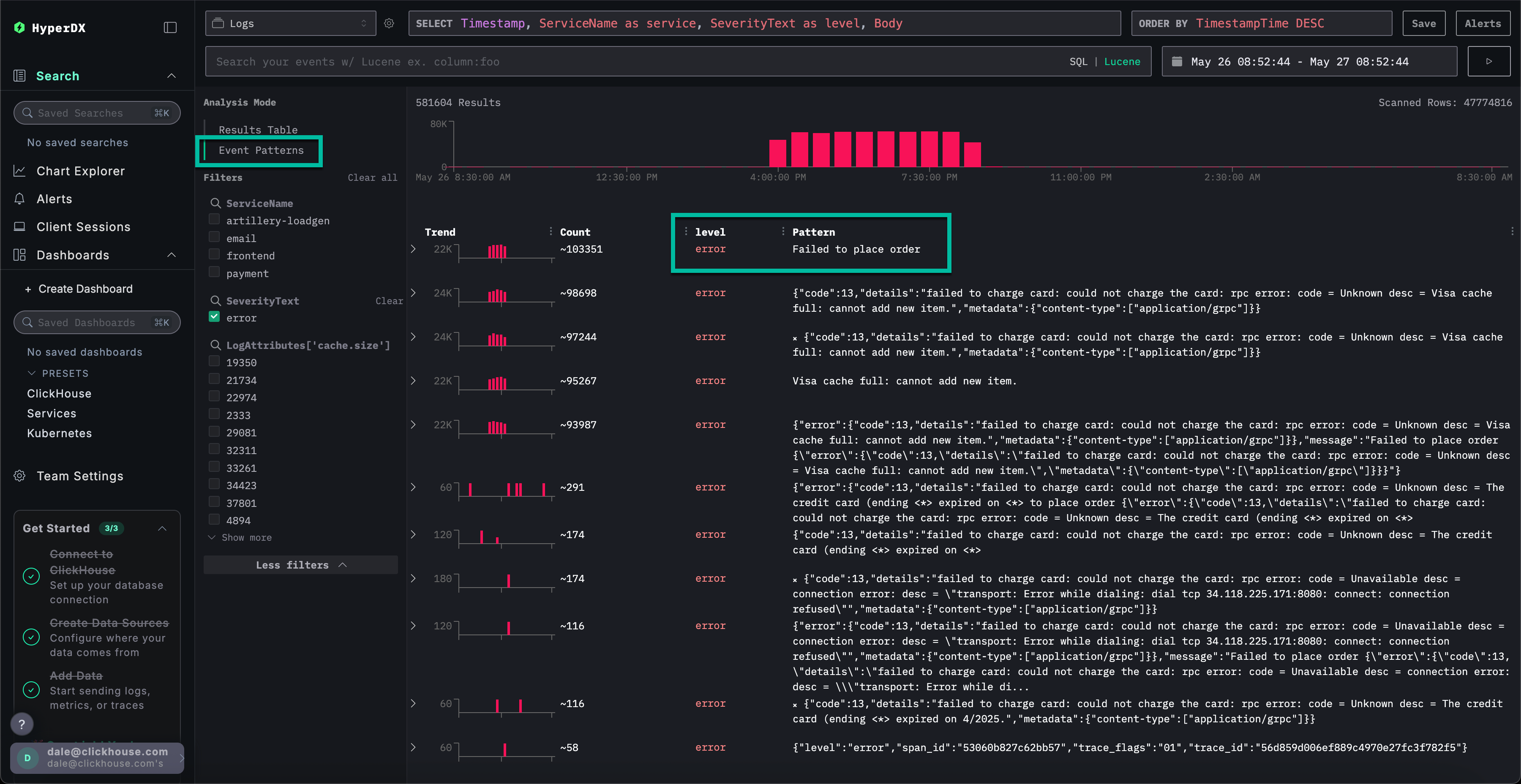
请注意,这些错误集群可能来源于不同的服务。
探索错误模式
点击与我们报告的用户无法完成支付问题关联度最高的错误集群:Failed to place order。
这将显示与 frontend 服务关联的所有此错误出现记录的列表:
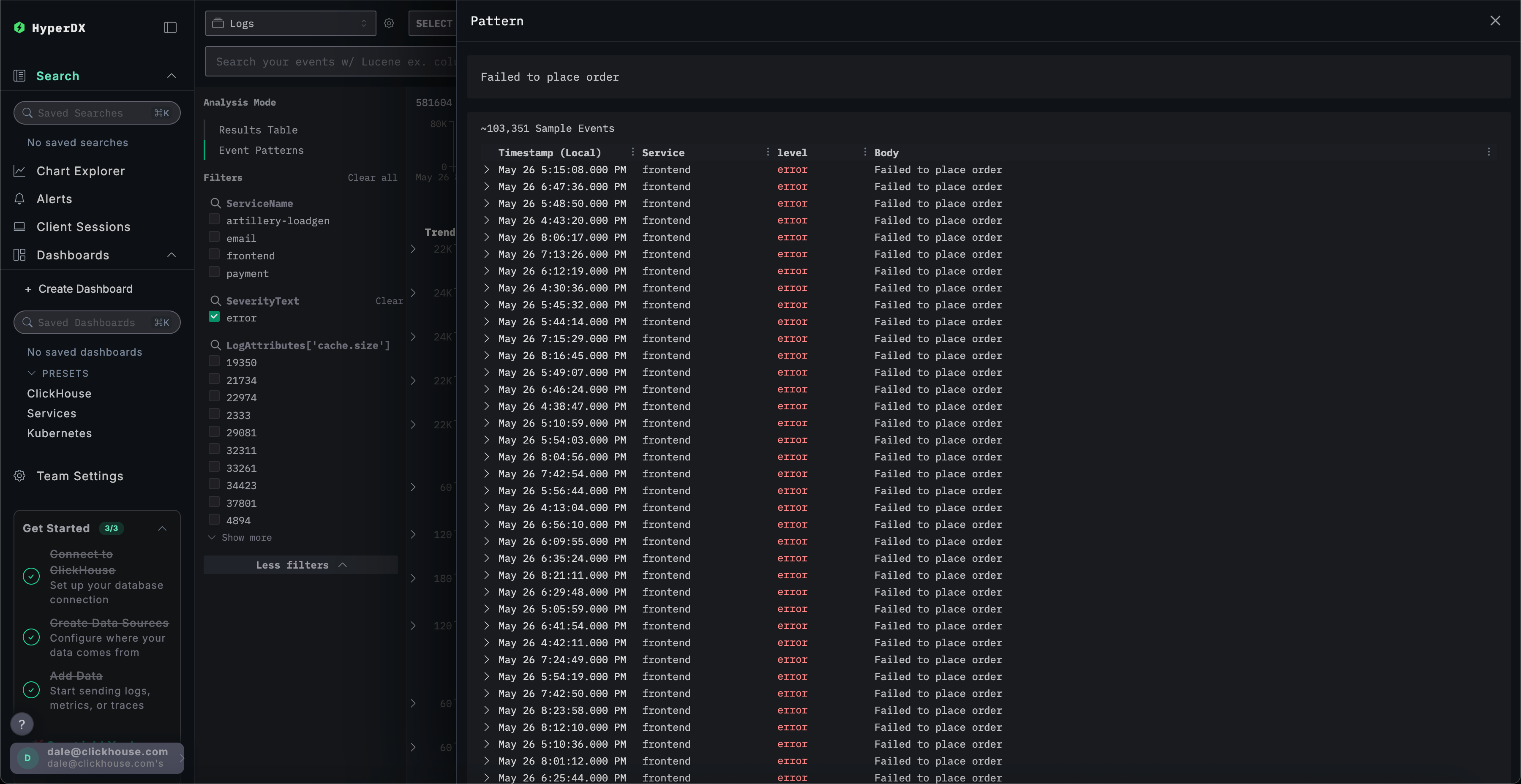
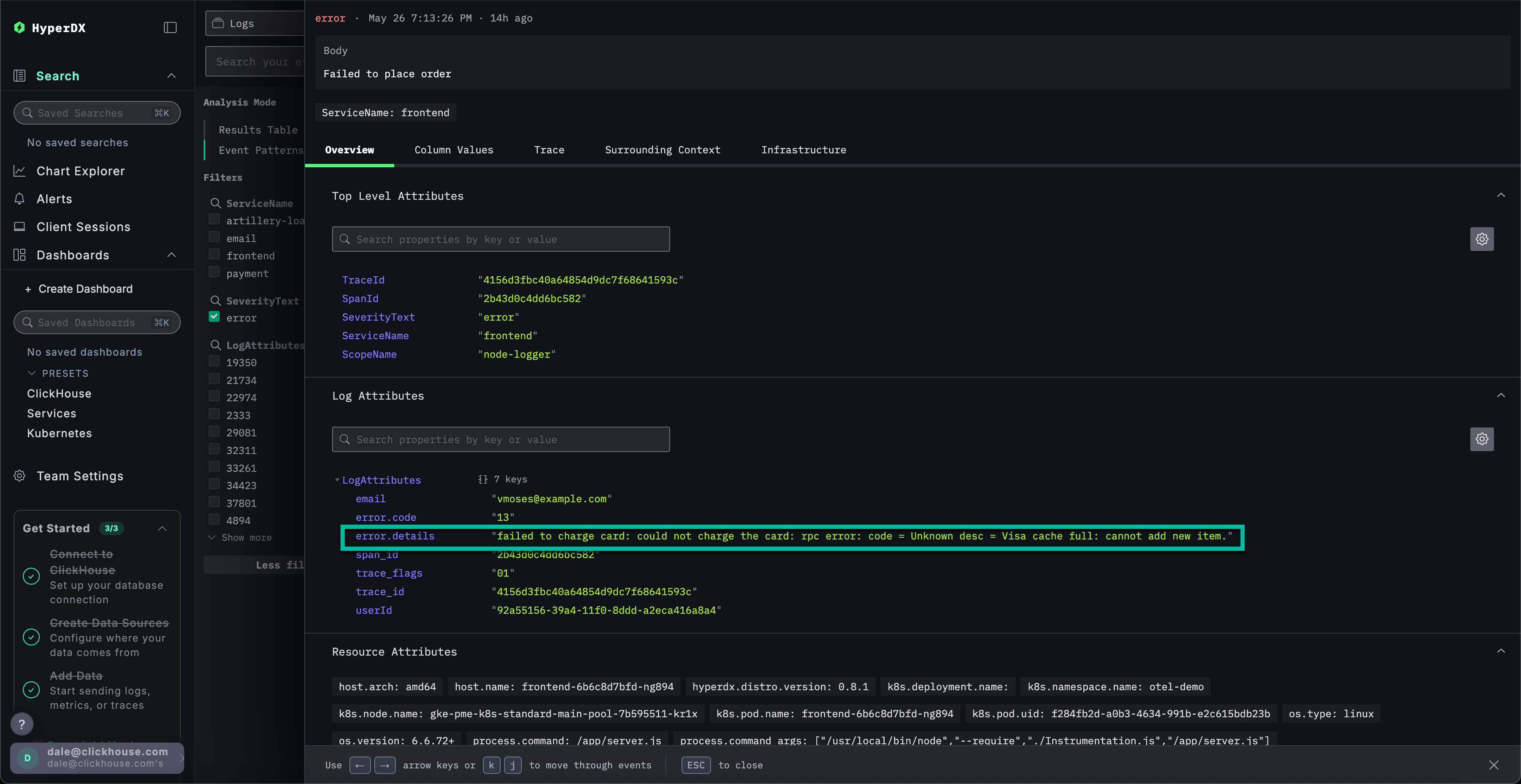
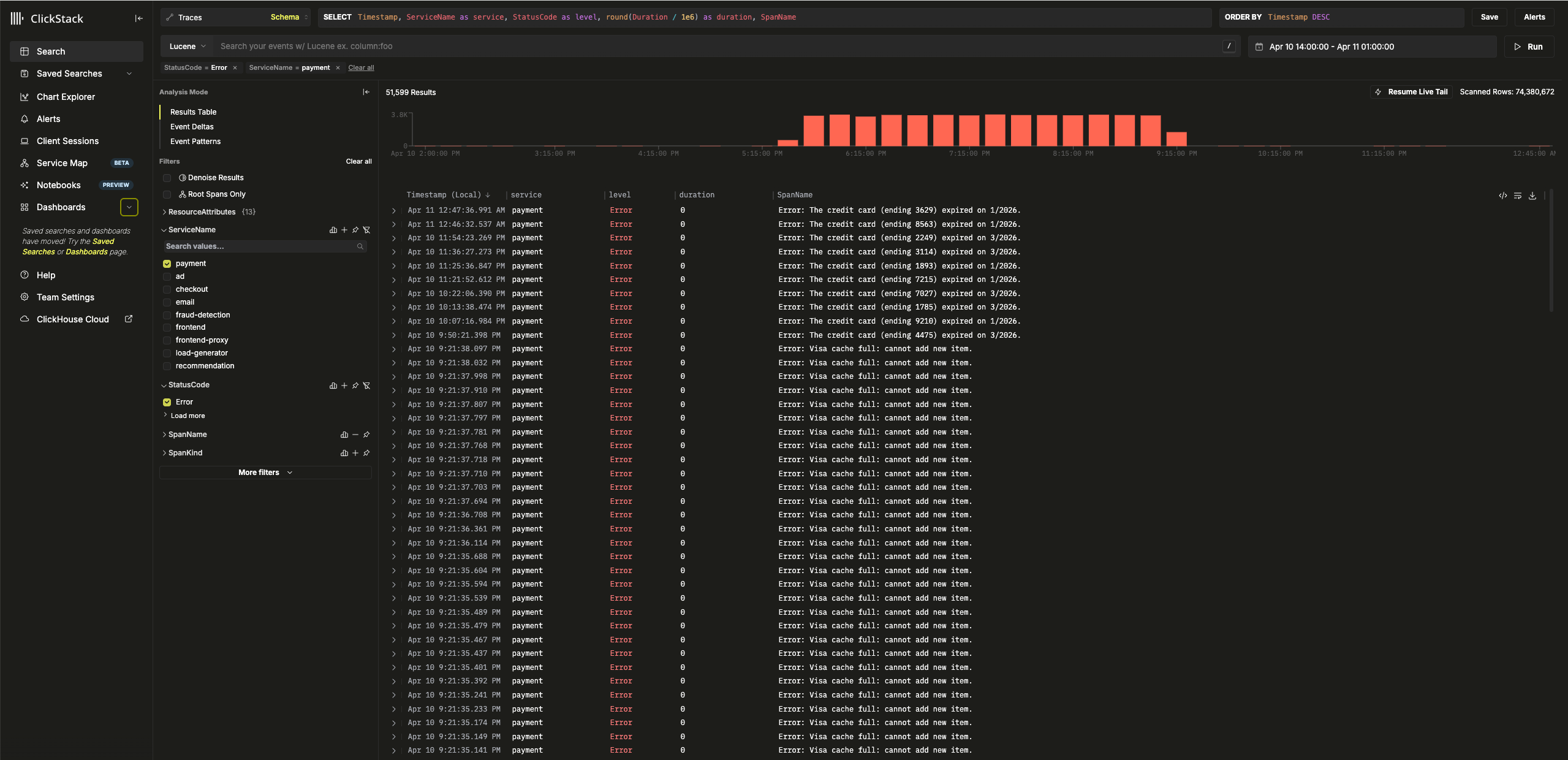
选择任意一个错误结果。日志元数据将详细显示。通过浏览 Overview 和 Column Values 两个部分,可以发现充电卡存在缓存相关的问题:
failed to charge card: could not charge the card: rpc error: code = Unknown desc = Visa cache full: cannot add new item.
探索基础设施
我们已识别出一个缓存相关错误,该错误可能导致支付失败。我们仍需定位此问题在微服务架构中的来源。
鉴于缓存问题,有必要检查底层基础设施——相关 Pod (容器组) 可能存在内存问题。在 ClickStack 中,日志和指标统一展示并关联上下文,便于快速定位根本原因。
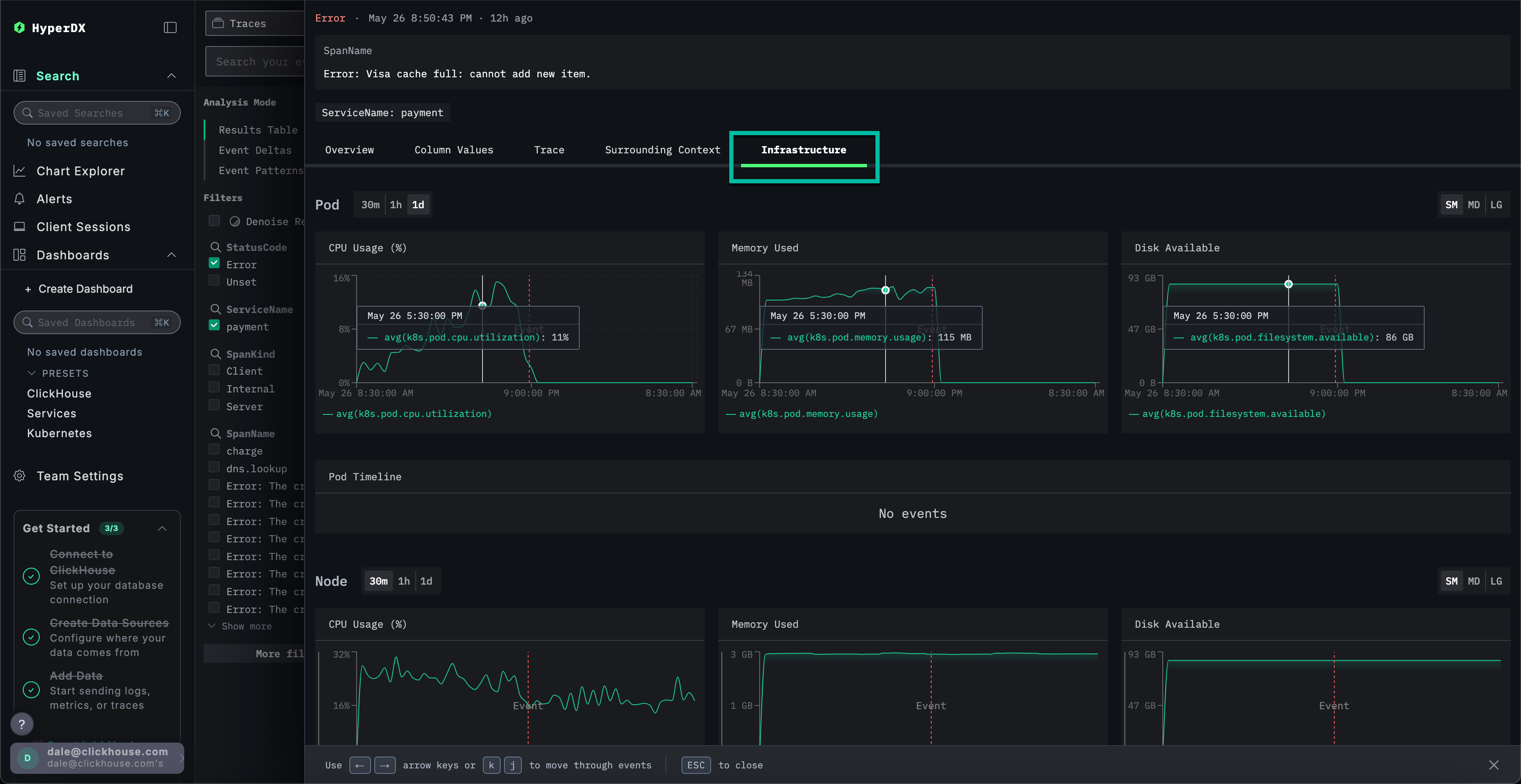
选择 Infrastructure 选项卡,查看 frontend 服务底层 Pod (容器组) 的相关指标,并将时间范围扩展至 1d:
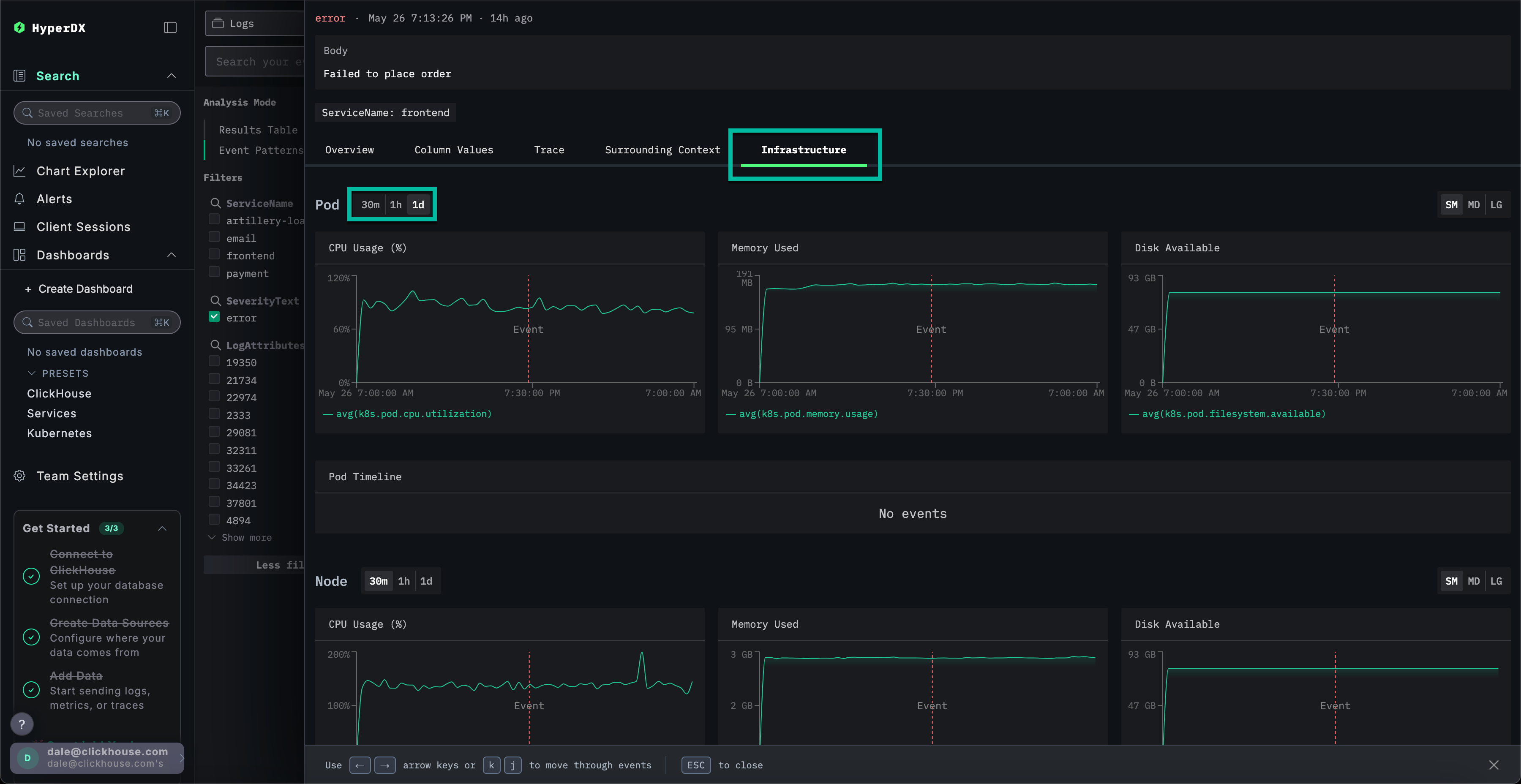
该问题似乎与基础设施无关——在错误发生前后的时间段内,各项指标均未发生明显变化。关闭基础设施选项卡。
探索追踪
在 ClickStack 中,链路追踪数据也会自动与日志和指标进行关联。让我们查看与所选日志关联的追踪数据,以确定负责的服务。
选择 Trace 以可视化关联的追踪。向下滚动查看后续视图,可以看到 HyperDX 如何将跨微服务的分布式追踪可视化,并连接每个服务中的 span。一次支付操作显然涉及多个微服务,包括执行结账和货币转换的服务。
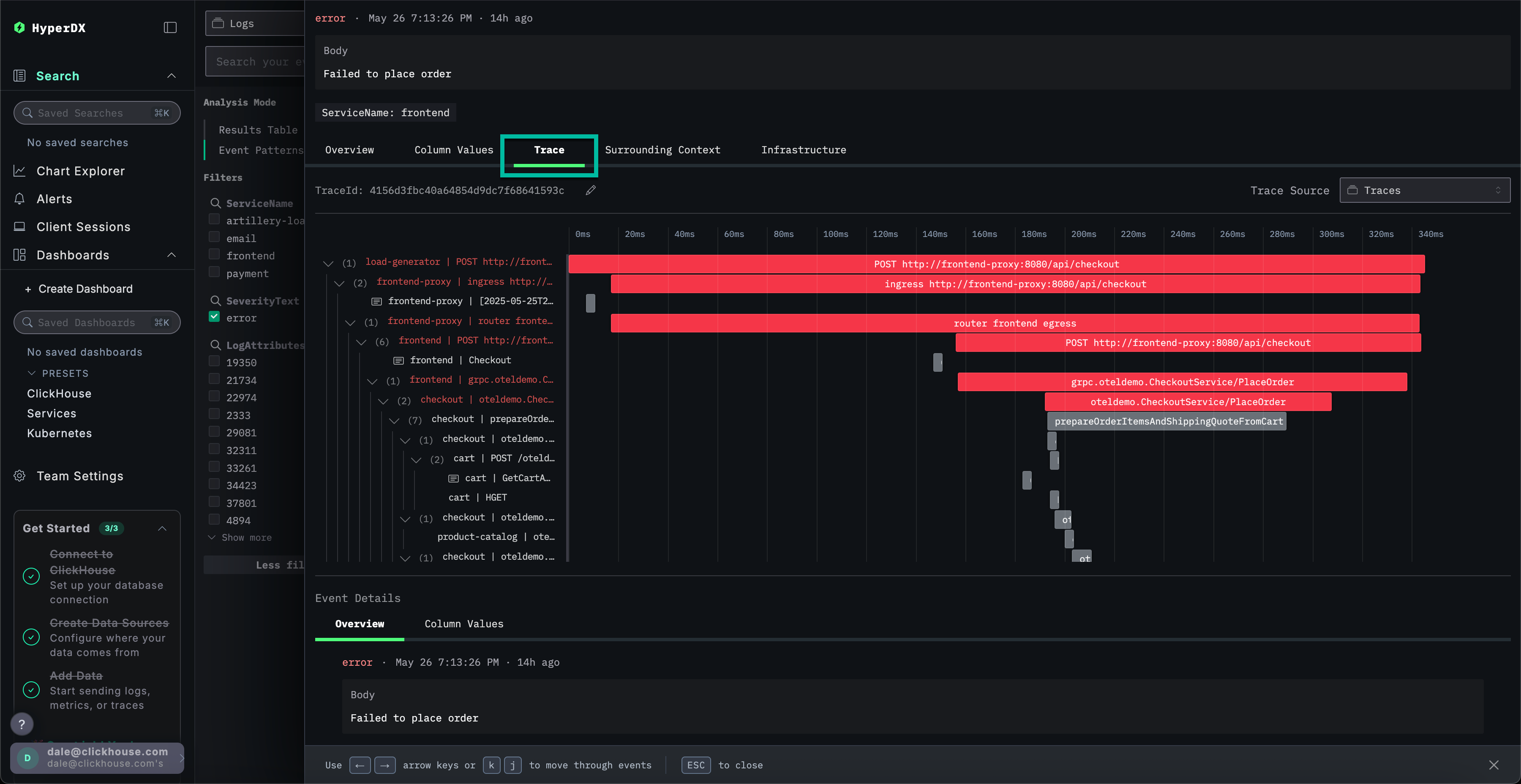
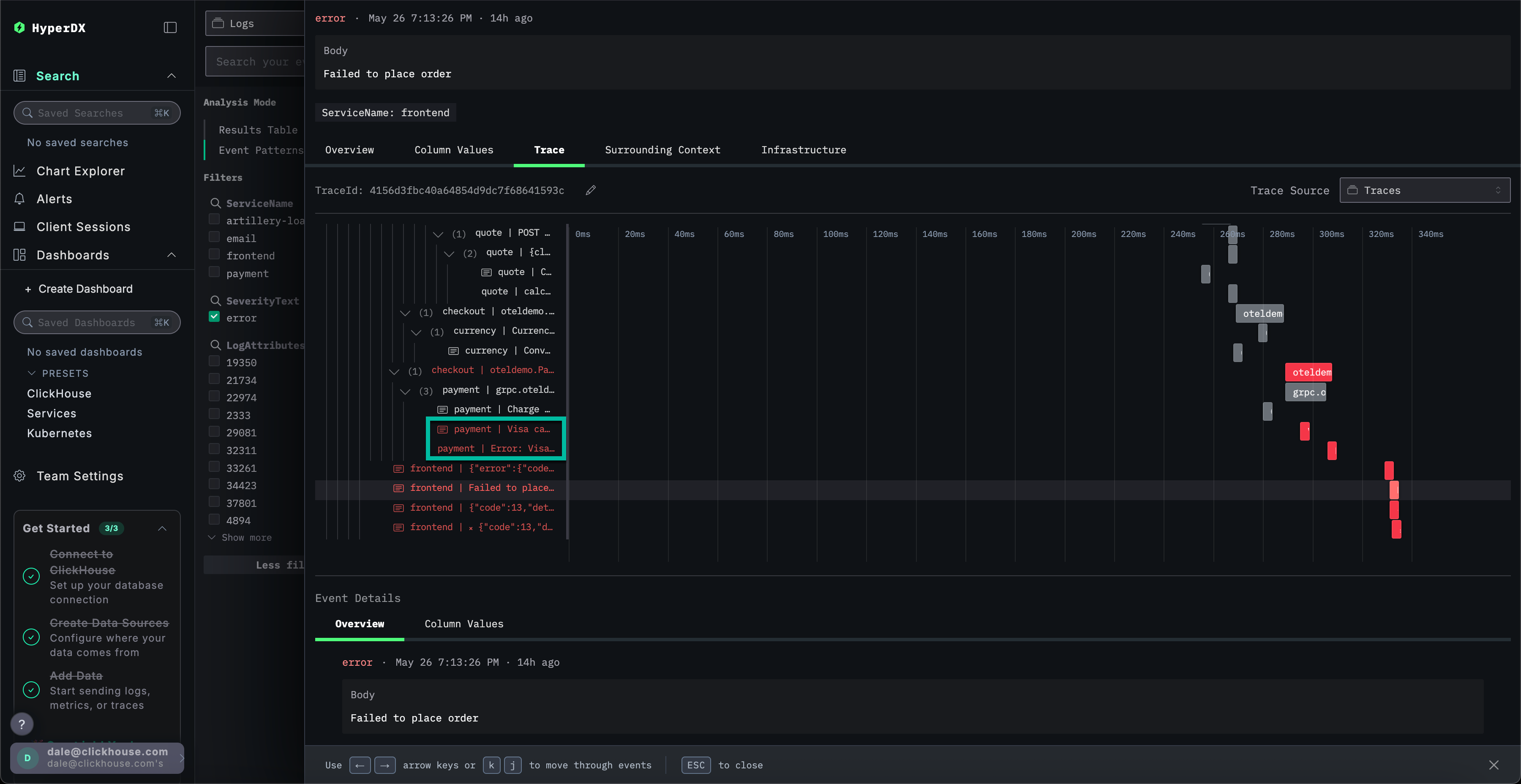
通过滚动到视图底部,可以看到 payment 服务引发了该错误,错误随后沿调用链向上传播。
搜索链路追踪
我们已确认用户因支付服务的缓存问题而无法完成购买。接下来,让我们更详细地查看该服务的链路追踪数据,以进一步分析根本原因。
通过选择 Search 切换到主搜索视图。将数据源切换为 Traces 并选择 Results table 视图。确保时间范围仍为最近一天。
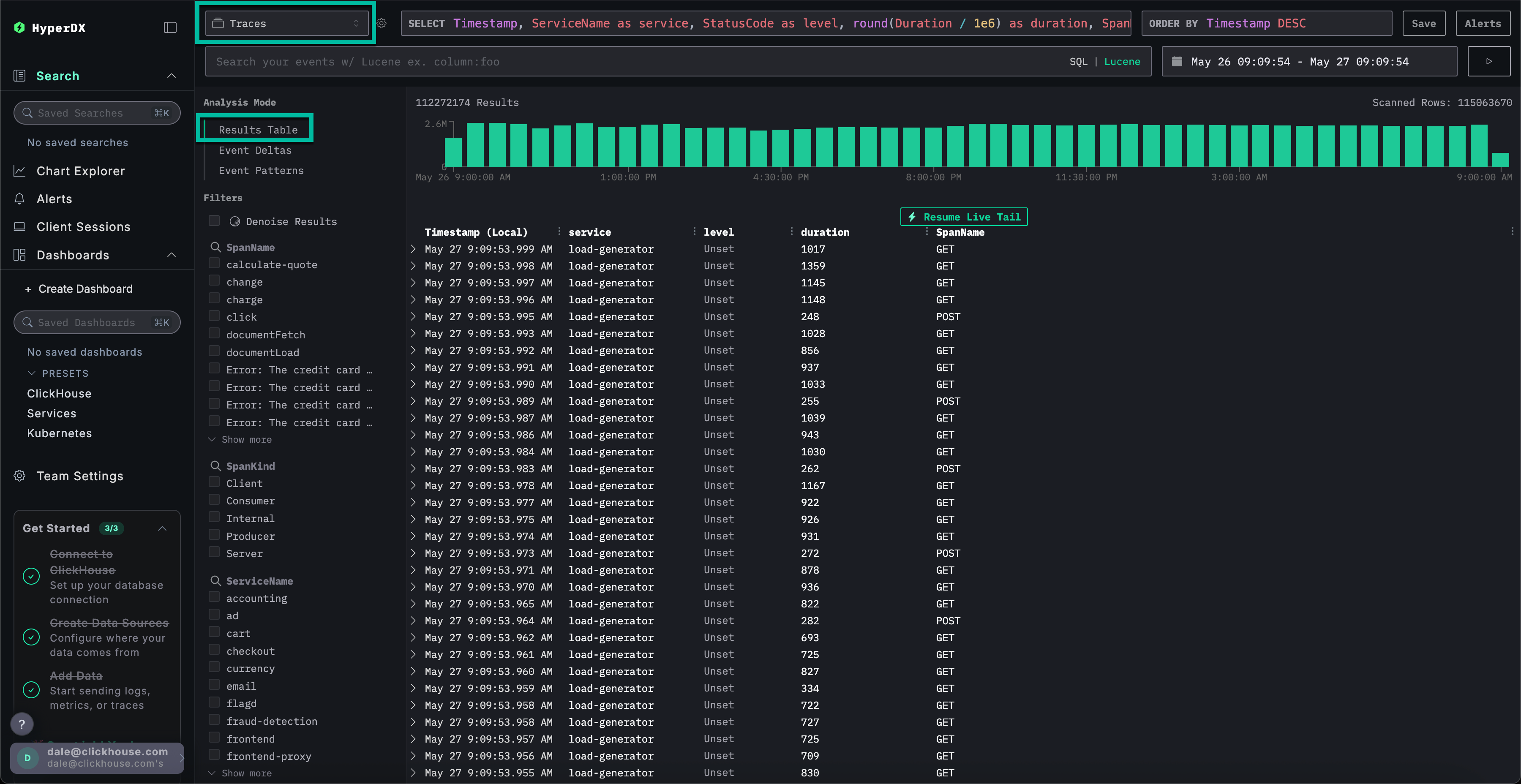
此视图显示最近一天内的所有链路追踪数据。我们知道问题源自支付服务,因此在 ServiceName 字段应用 payment 过滤器。
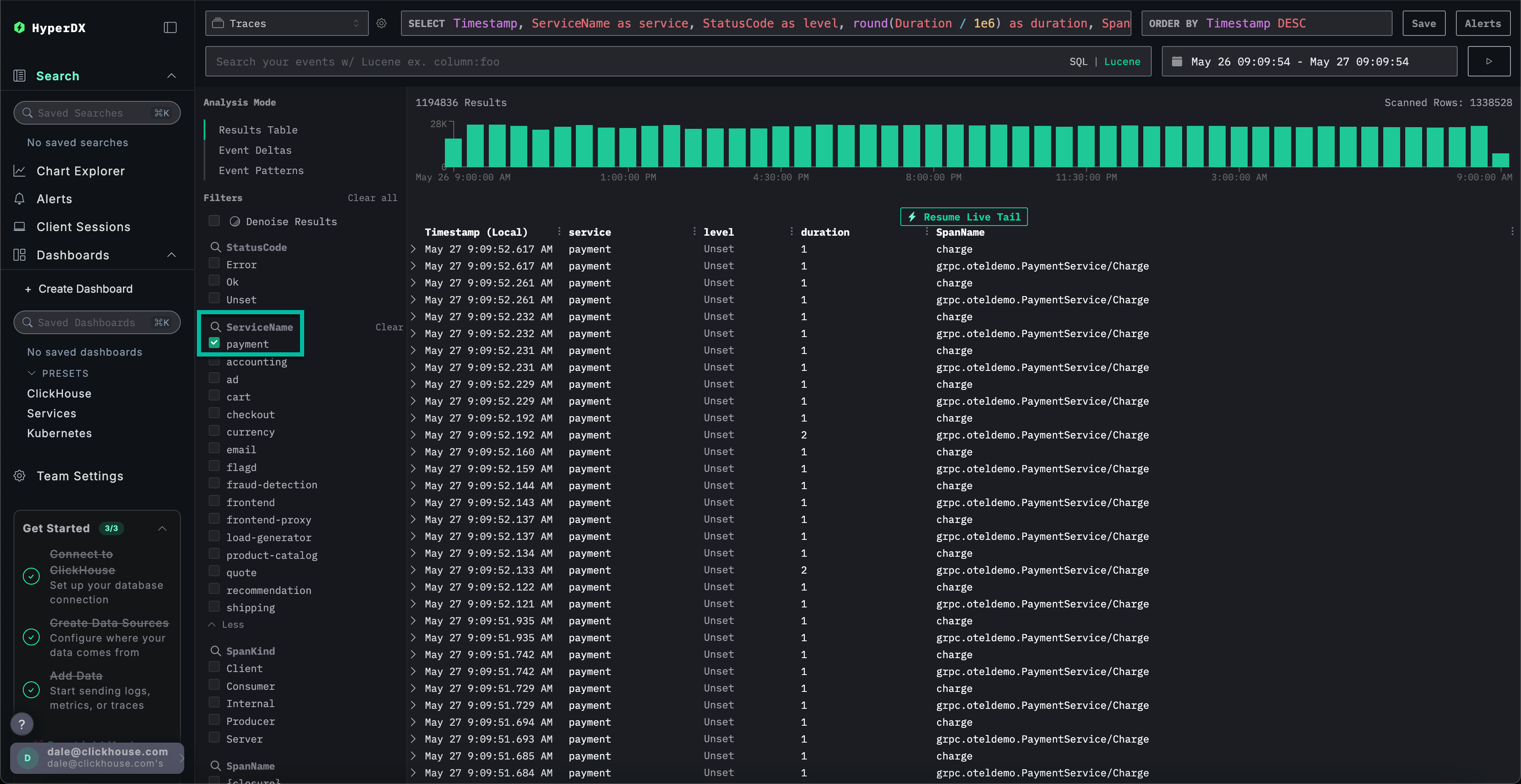
通过选择 Event Patterns 对链路追踪数据应用事件聚类,即可立即发现 payment 服务的缓存问题。
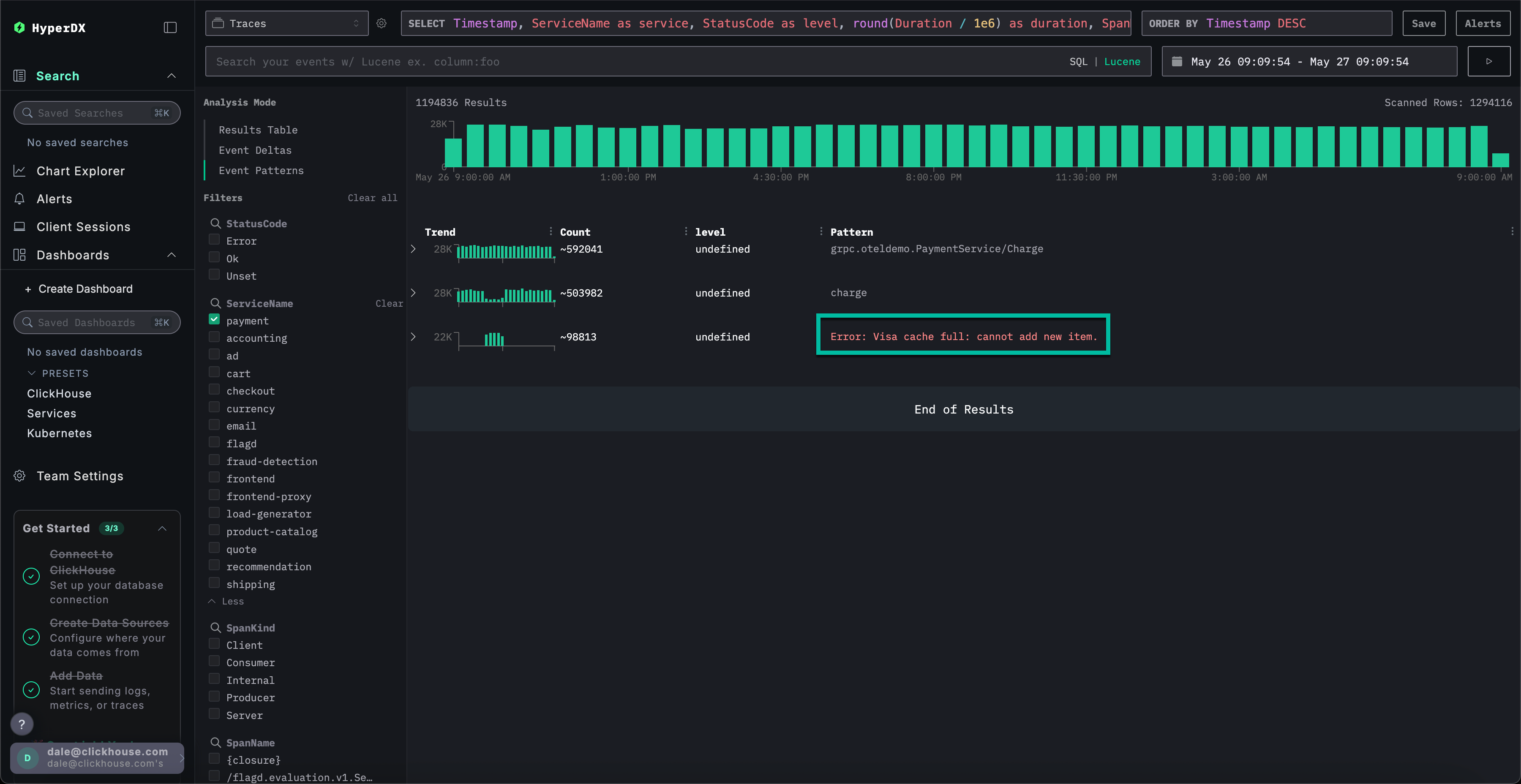
探索追踪的基础设施
点击 Results table 切换至结果视图。使用 StatusCode 筛选器和 Error 值筛选错误记录。
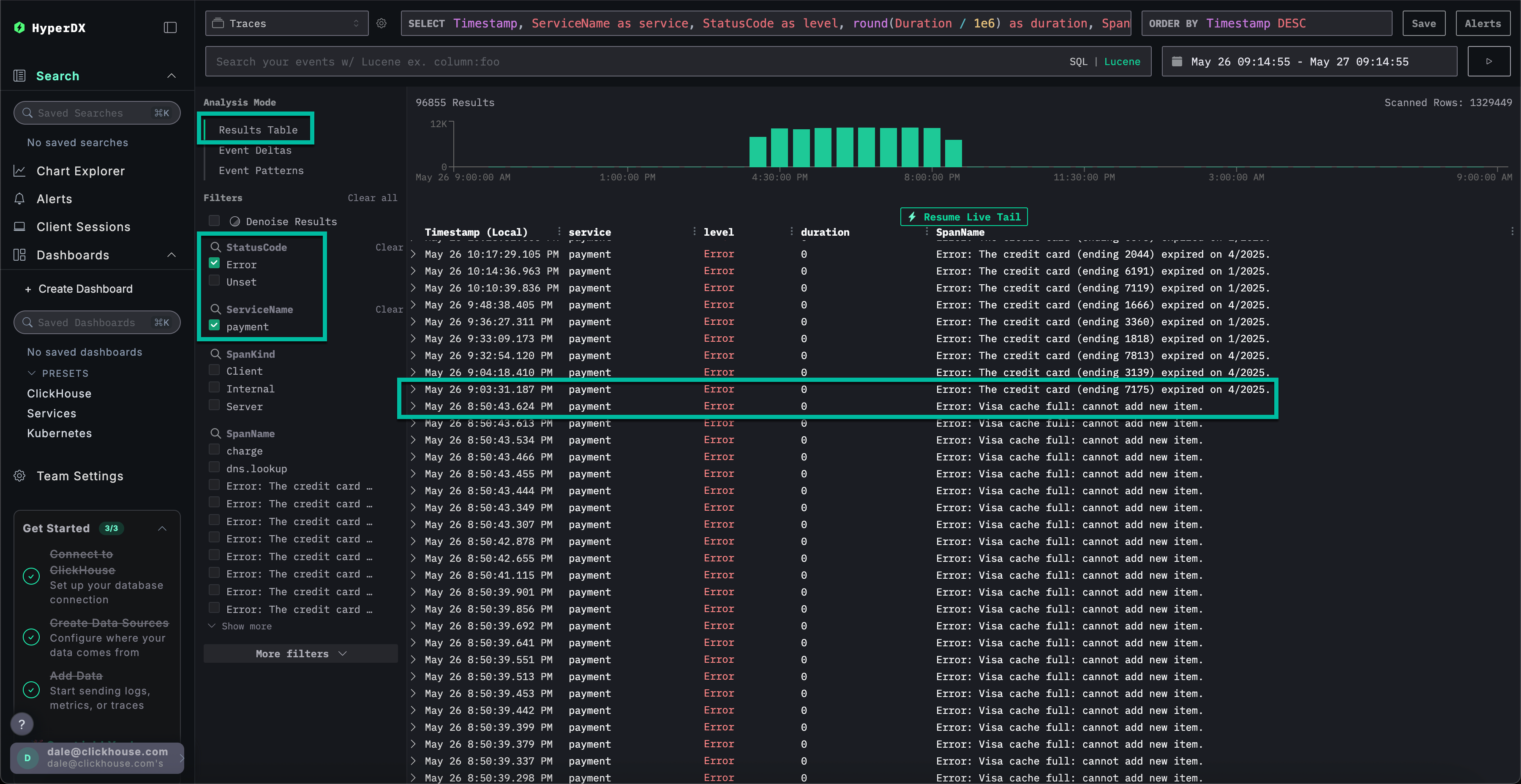
选择一个 Error: Visa cache full: cannot add new item. 错误,切换到 Infrastructure 选项卡,并将时间跨度扩大到 1d。
通过关联链路追踪数据与指标数据,可以看到 payment 服务的内存和 CPU 使用率上升,随后骤降至 0(可归因于 pod (容器组) 重启)——这表明缓存问题引发了资源问题。可以预期这已影响支付完成时间。
事件增量加速问题解决
事件增量 (Event Deltas) 通过将性能或错误率的变化归因于特定数据子集来帮助识别异常,从而更便于快速定位根本原因。
虽然我们知道 payment 服务存在缓存问题,导致资源消耗增加,但尚未完全确定根本原因。
返回结果表视图,选择包含错误的时间段以限制数据范围。请确保选择错误发生时间前后各几个小时的数据(如果可能),因为问题可能仍在持续:
移除错误过滤器,然后从左侧的 Analysis Mode 菜单中选择 Event Deltas。
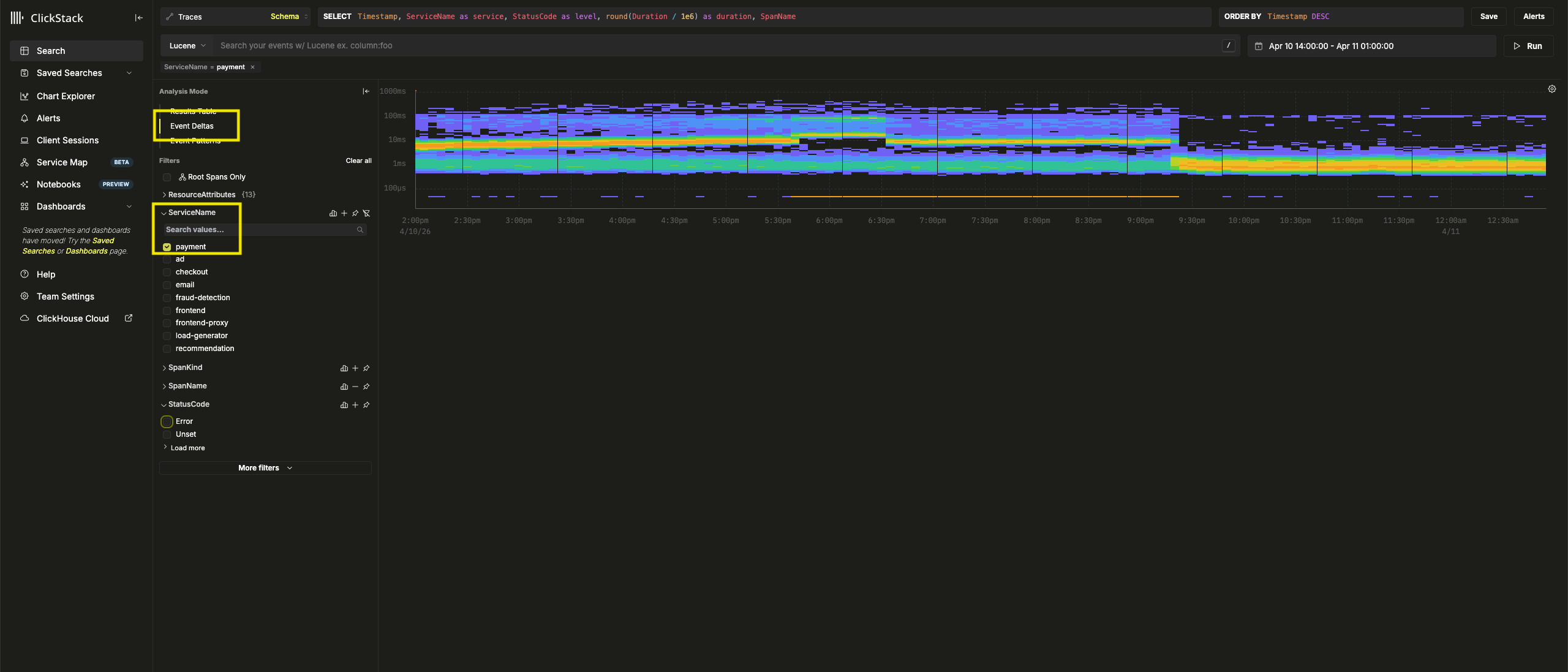
顶部面板显示时序分布,颜色表示事件密度(span 数量)。主要集中区域之外的事件子集通常值得重点排查。
选择持续时间大于 1ms 的事件,并应用 Filter by selection 过滤器,即可分析"正常"事件与持续时间约为 0ms 的高密度 span 组之间的差异:
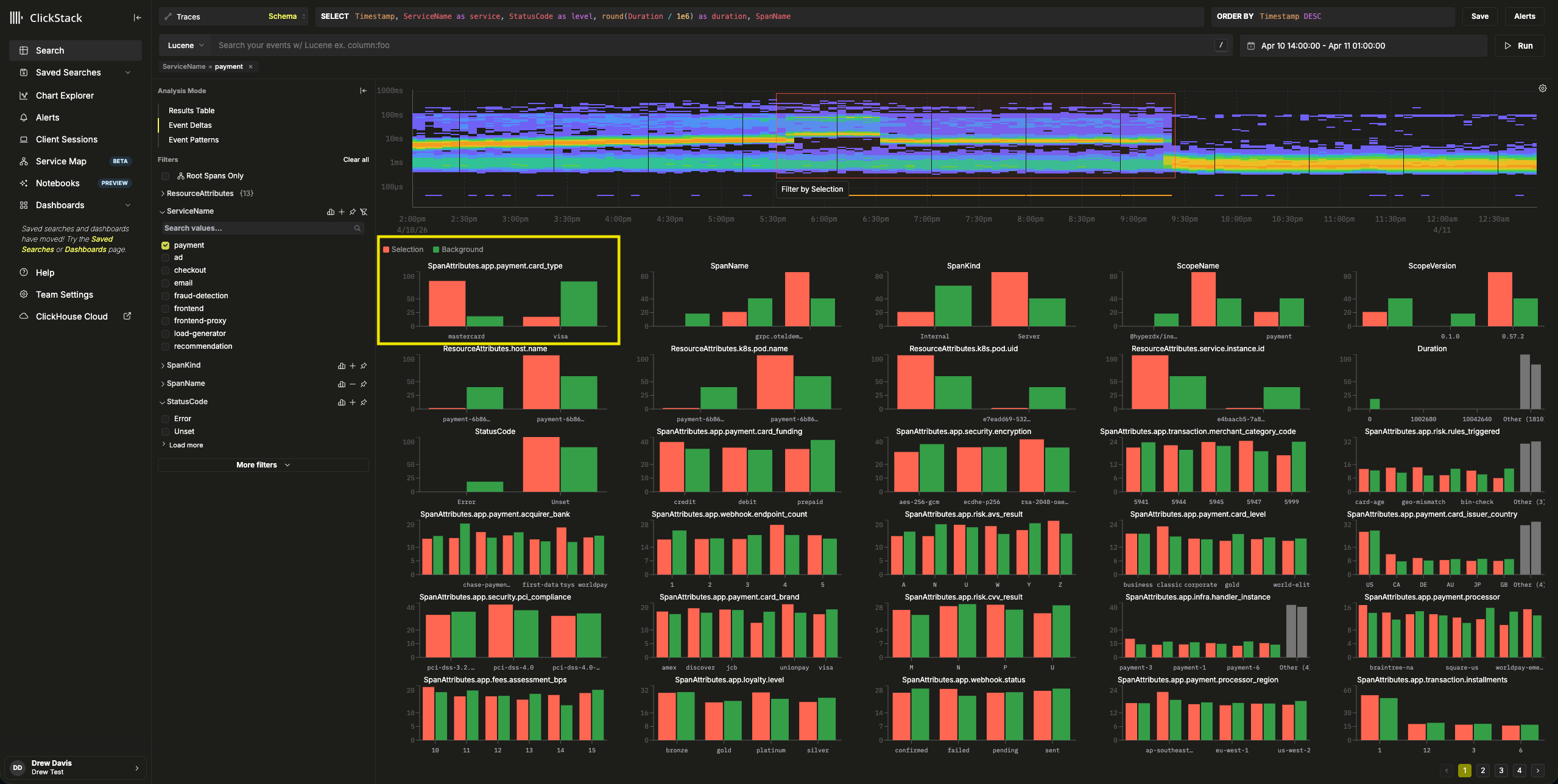
通过对数据子集的分析,可以看到选择范围之外的"背景" span 大多是 Visa 交易,由于缓存错误导致响应时间为 0ms。
使用图表获取更多上下文
在 ClickStack 中,我们可以将日志、链路追踪或指标中的任何数值绘制成图表,以获取更丰富的上下文信息。
我们已确认:
- 我们的问题出在支付服务上
- 缓存已满
- 这导致资源消耗上升
- 该问题导致 Visa 支付无法完成,或者至少会显著延长支付完成时间。
从左侧菜单中选择 Chart Explorer。填写以下值,按图表类型绘制支付完成所需时间:
数据源:链路追踪Metric:最大值SQL 列:DurationWhere:ServiceName: paymentTimespan:最近 1 天
点击 ▶️ 将显示支付性能随时间的变化趋势。
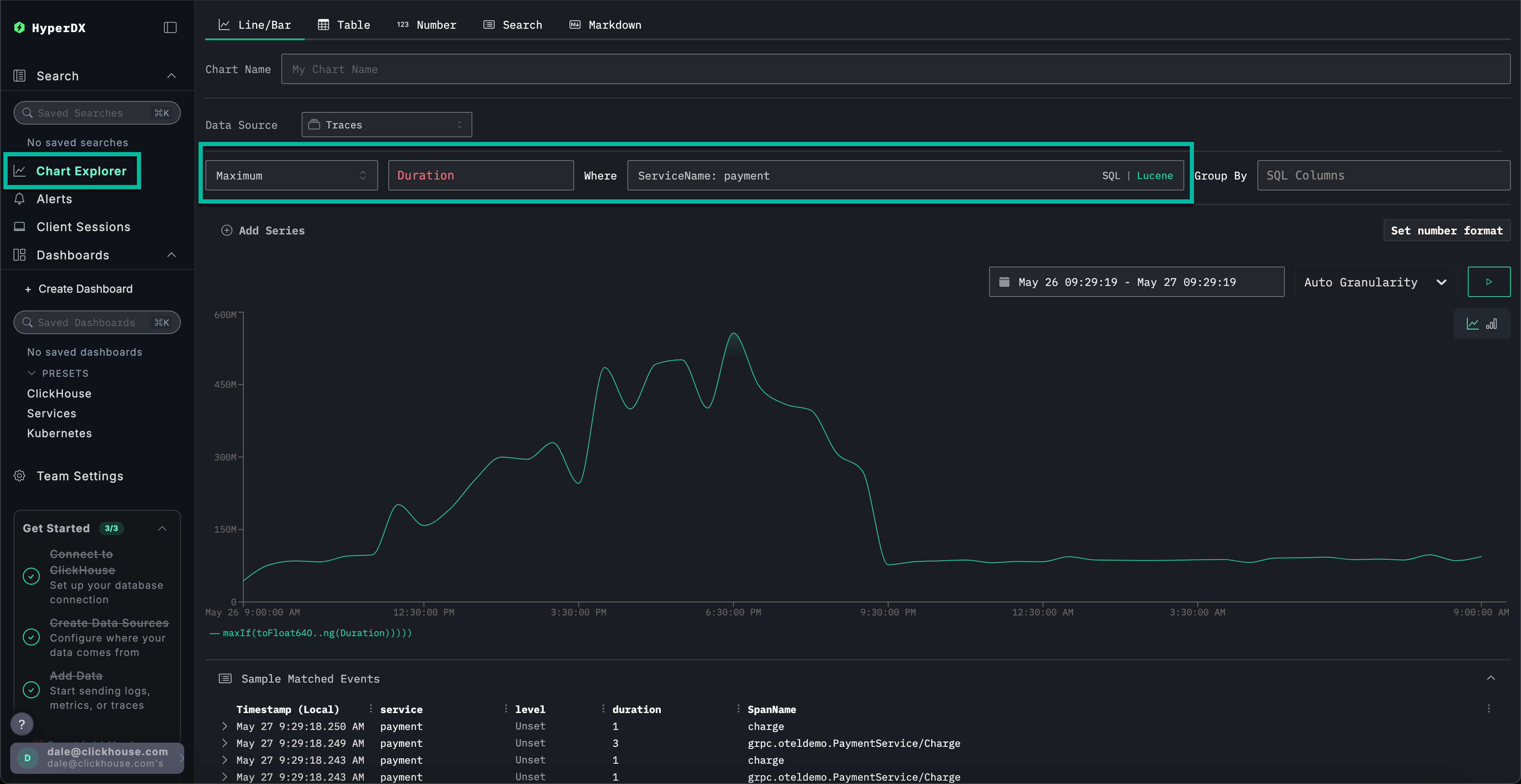
将 Group By 设置为 SpanAttributes['app.payment.card_type'](输入 card 即可自动补全),可以看到 Visa 交易相对于 Mastercard 交易的服务性能下降情况:
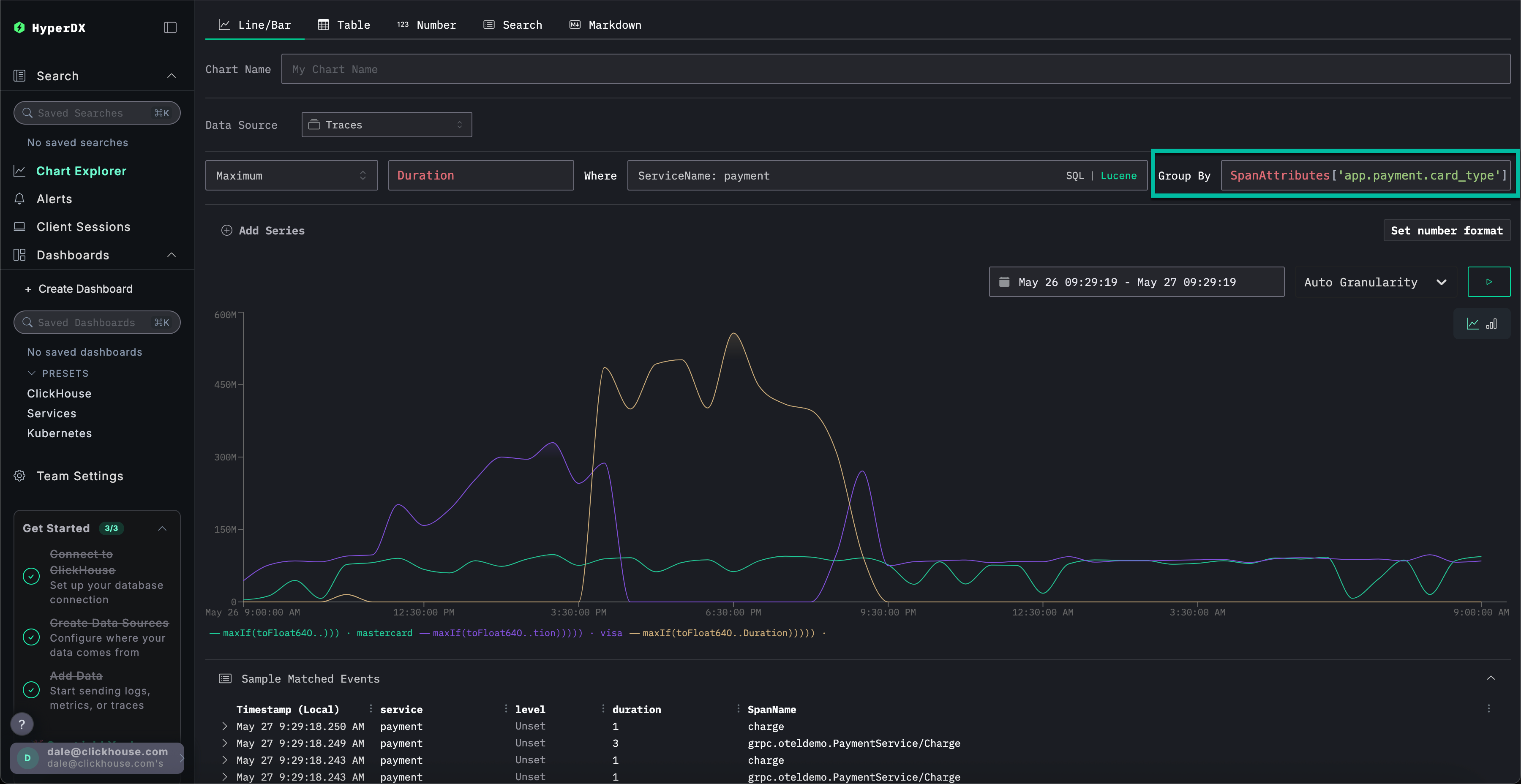
请注意,一旦发生错误,响应会立即返回(耗时 0s)。
探索指标的更多上下文信息
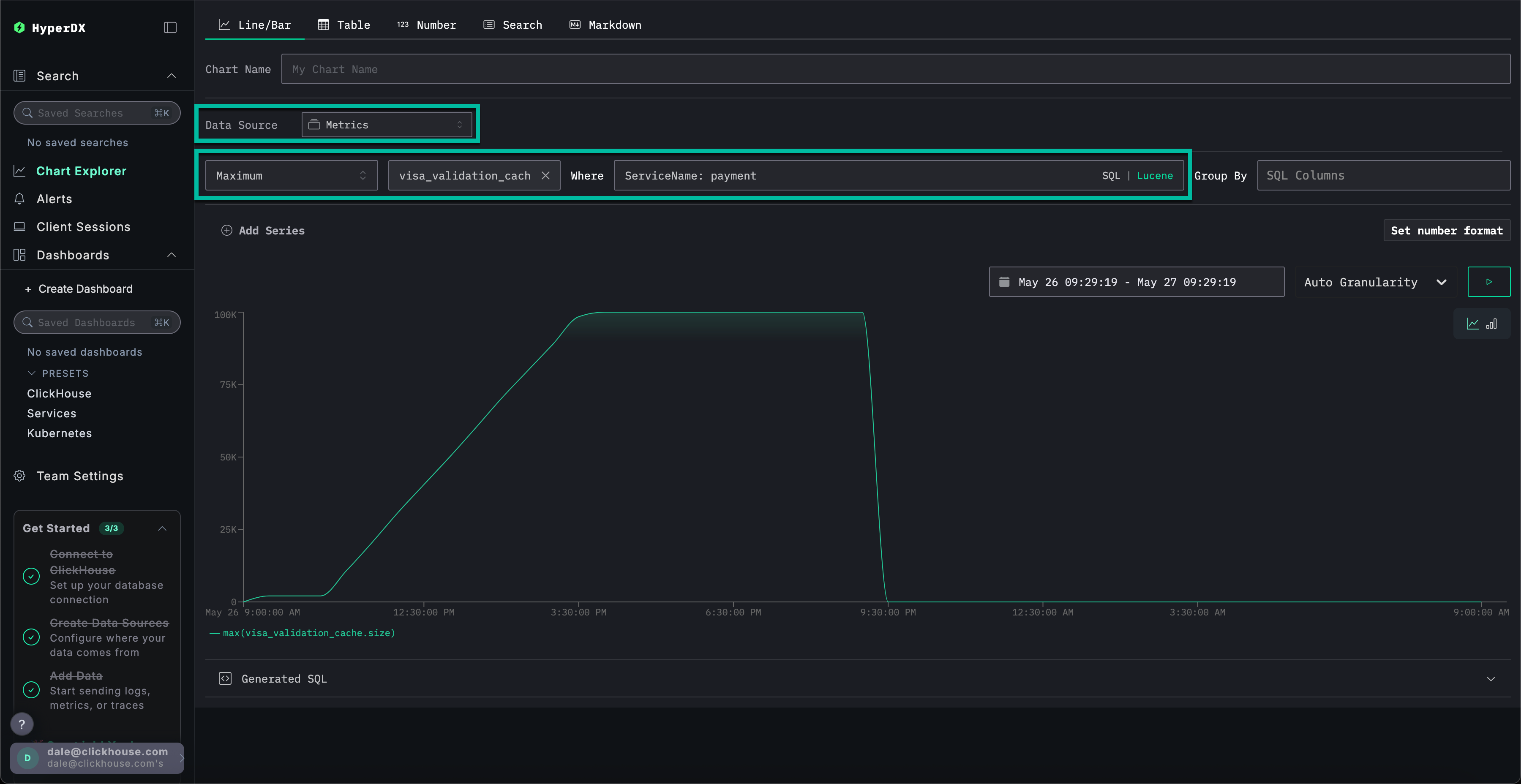
最后,我们将缓存大小作为指标进行绘制,以观察其随时间的变化行为,从而获得更多上下文信息。
填写以下配置值:
数据源:MetricsMetric:最大值SQL Column:visa_validation_cache.size (gauge)(只需输入cache即可自动补全)Where:ServiceName: paymentGroup By:<empty>
我们可以看到缓存大小在 4-5 小时内逐渐增加(可能是在软件部署之后),最终达到 100,000 的最大值。从 Sample Matched Events 中可以看到,我们的错误与缓存达到此限制关联,之后缓存大小被记录为 0,响应时间也变为 0s。
综上所述,通过探索日志、链路追踪和指标,我们得出以下结论:
- 我们的问题出在支付服务上
- 服务行为的变化 (很可能由一次部署引起) 导致 Visa 缓存在 4–5 小时内缓慢增长,最终达到
100,000的最大值。 - 随着缓存大小的增长,资源消耗随之增加——这很可能是由于实现不佳造成的
- 随着缓存不断增大,Visa 支付的性能逐渐下降
- 在达到最大容量时,缓存会拒绝支付请求,并显示其大小为
0。
使用会话
会话功能允许我们重放用户体验,从用户视角提供错误发生过程的可视化记录。虽然通常不用于诊断根本原因,但对于确认客户支持团队收到的问题报告非常有价值,并可作为深入调查的起点。
在 HyperDX 中,会话与链路追踪和日志关联,提供问题根因的完整视图。
例如,如果支持团队提供了遇到支付问题的用户邮箱 Ronny.Windler@gmail.com,通常从该用户的会话入手进行分析会比直接搜索日志或链路追踪更有效。
从左侧菜单导航至 Client Sessions 选项卡,并确保数据源设置为 Sessions,时间段设置为 Last 1 day:
搜索 SpanAttributes.userEmail: Ronny.Windler 以查找客户会话。选择该会话后,左侧将显示该客户会话的浏览器事件和关联 span,右侧将重现用户的浏览器操作过程:
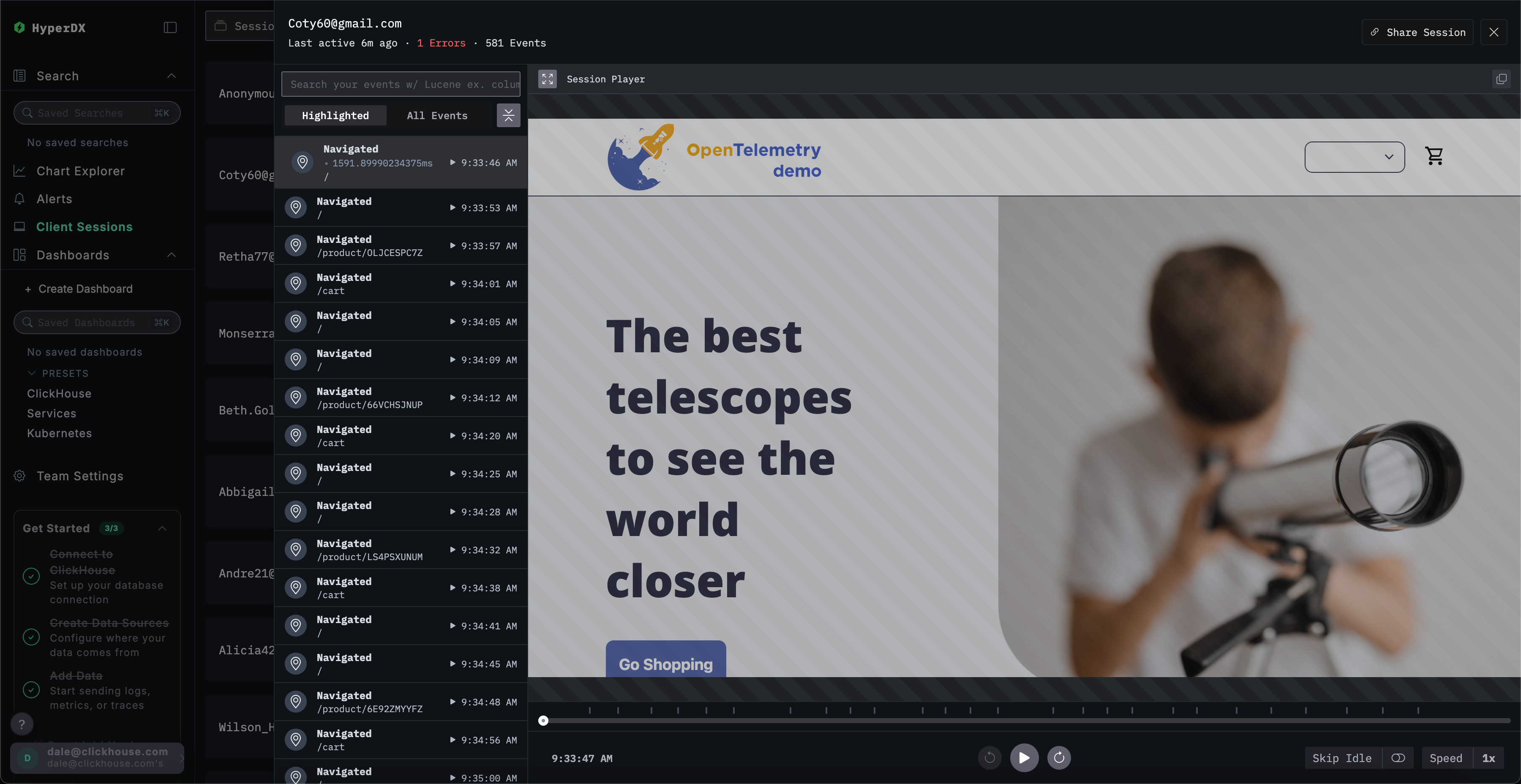
回放会话
点击 ▶️ 按钮即可回放会话。在 Highlighted 和 All Events 之间切换可调整 span 的粒度级别,前者突出显示关键事件和错误。
滚动到 span 列表底部,可以看到与 /api/checkout 关联的 500 错误。点击该 span 的 ▶️ 按钮,回放将跳转到会话中的此时间点,从而确认客户的实际体验——支付功能无法正常工作,且未显示任何错误信息。
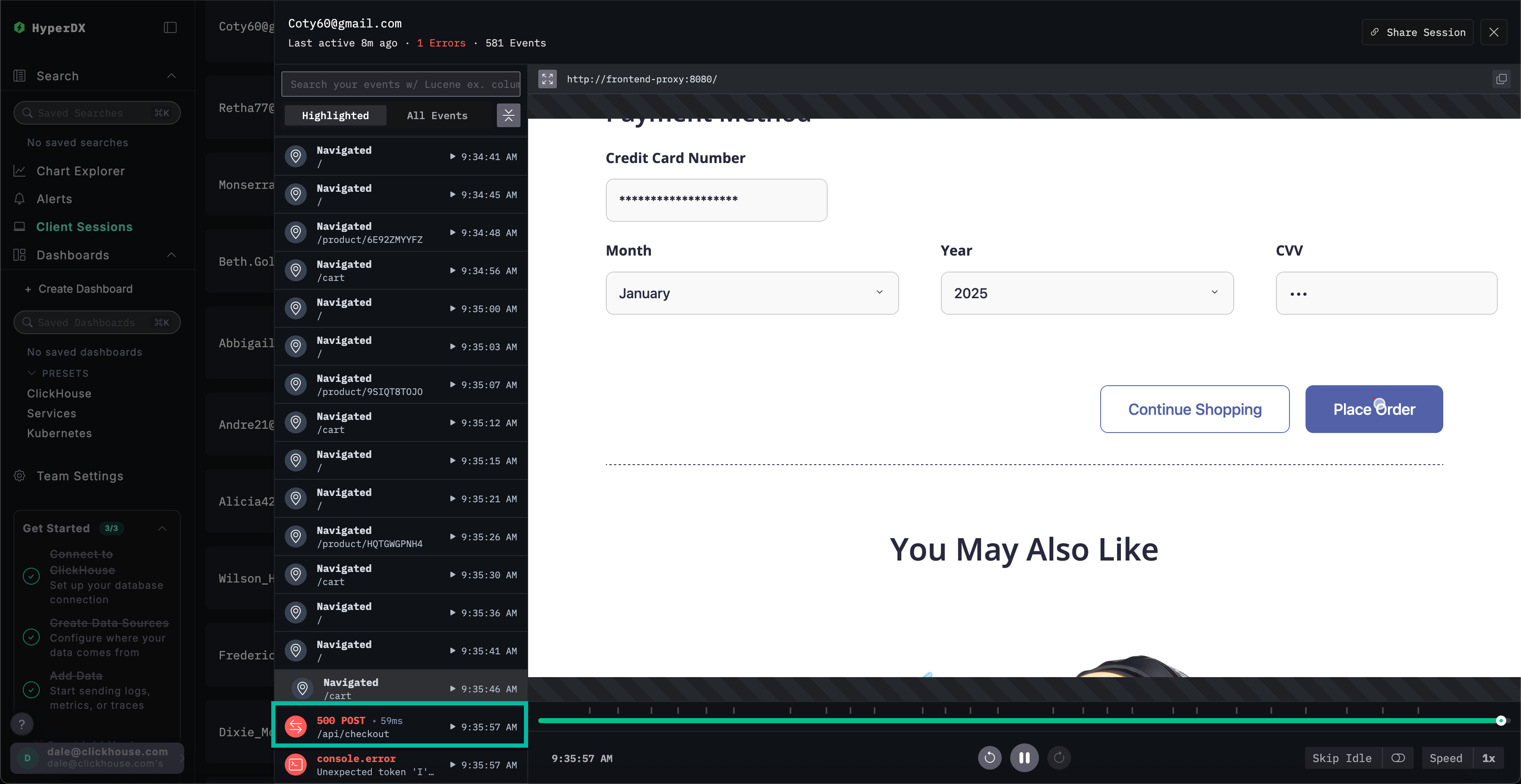
选择该 span 后,我们可以确认这是由内部错误导致的。通过点击 Trace 选项卡并滚动浏览关联的 span,我们能够确认该客户确实受到了缓存问题的影响。
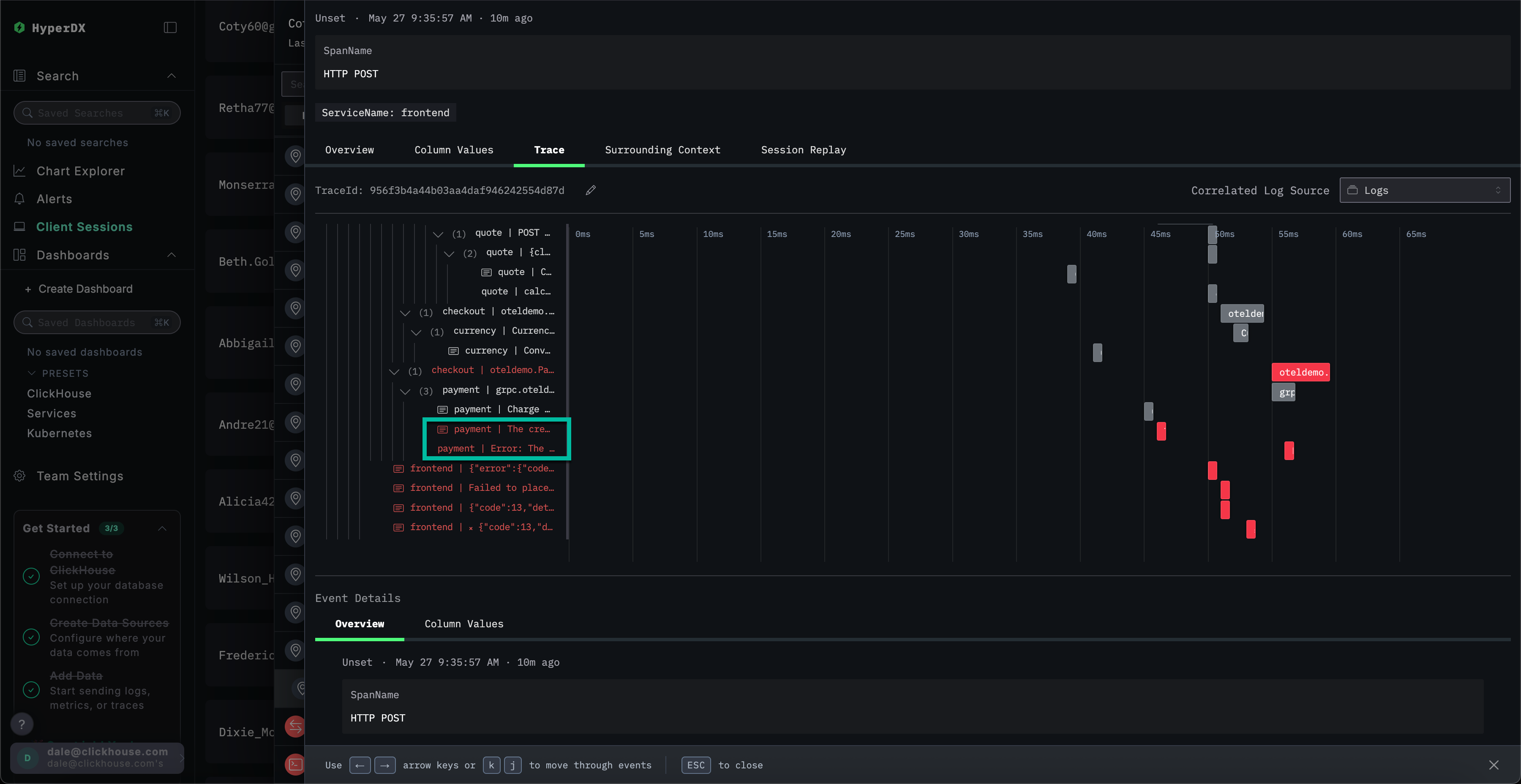
本示例演示一个电商应用中支付失败的真实事故,展示 ClickStack 如何通过统一的日志、链路追踪、指标和会话回放来帮助定位根因——可查看我们的其他入门指南,以更深入地探索特定功能。
