ClickStack 中的事件增量
事件增量将延迟热力图与自动属性分析结合起来,让您无需编写查询,即可查看追踪数据的形态,并找出慢 span 的不同之处。其用法有三种:
- 分布模式 (始终开启) — 当热力图上没有选区时,会显示当前 span 集合中每个属性的值分布。适合用来发现占主导地位或异常稀有的值 (基数异常值) 。
- 对比模式 — 在热力图上拖出一个矩形,将其中的 spans (Selection) 与外部的所有 spans (Background) 进行比较。适合用于定位偏差。
- 迭代式下钻 — 点击任意条形即可按该值筛选 (或排除) 。热力图会基于筛选后的结果重新渲染,因此您可以不断缩小范围,直到原因变得明显。
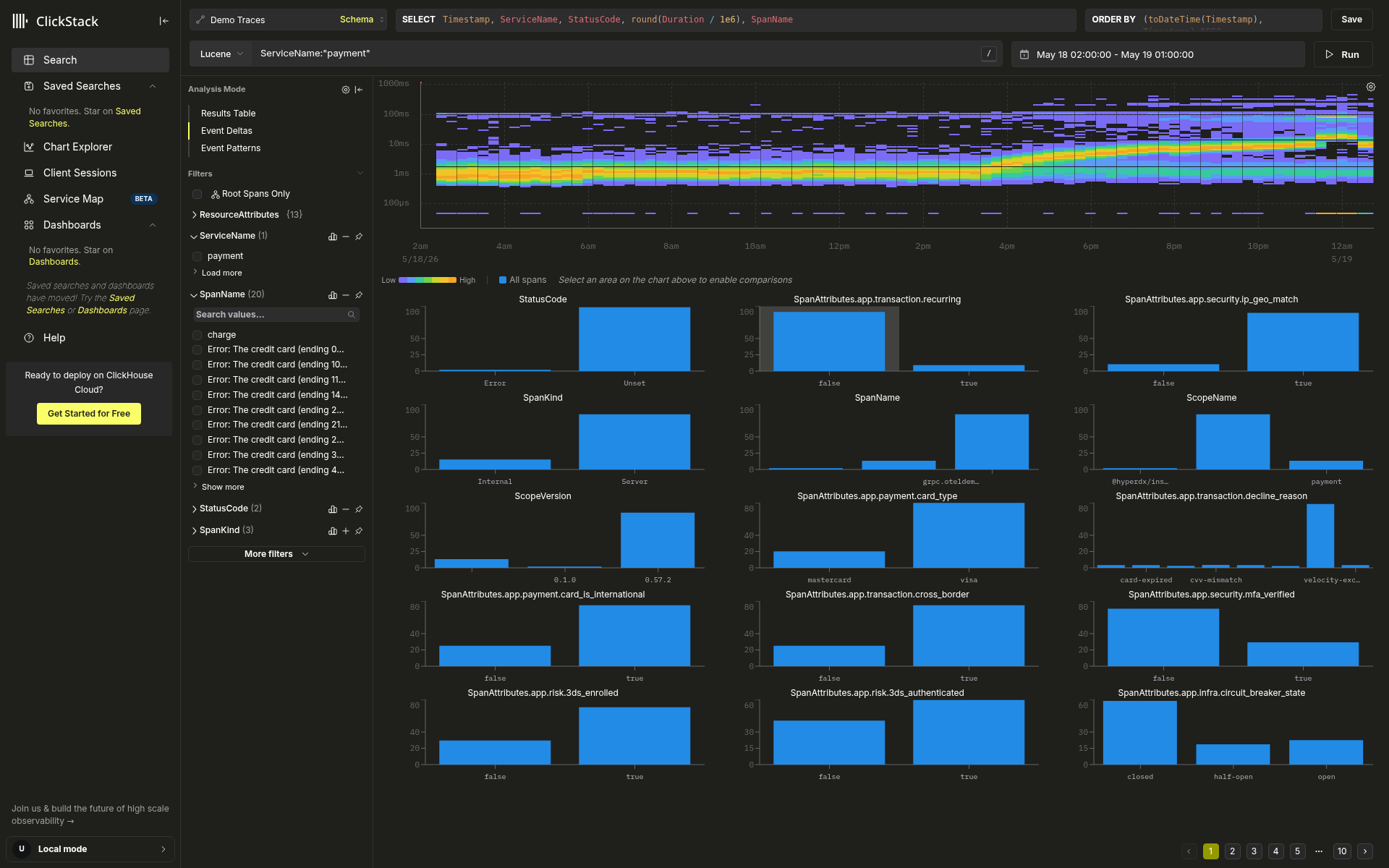
在上面的截图中,热力图右侧边缘大约位于 10 ms,而不是回到整个上午一直维持的 1 ms 基线。性能劣化仍在持续,因此我们是在这次事件尚未结束时捕捉到这一情况。
先决条件
事件增量需要一个带有耗时表达式的 Trace 数据源。任何通过 OpenTelemetry 进行埋点并生成 span 数据的服务都可以。所有 ClickStack 部署 (托管版、开源版、ClickHouse Cloud) 均提供此功能。
入门
- 在 数据源 下拉菜单中,选择一个包含链路追踪的数据源。源名称可以任意设置,关键在于该数据源配置为 Trace 类型。事件增量 选项卡仅对此类数据源启用。
- 在 分析模式 部分中,点击 事件增量 选项卡。
事件增量是与 结果表 和 事件模式 并列的一种独立分析模式。切换到该模式后,视图会变为热力图和属性分析网格,但您的搜索筛选器和时间范围会保持不变,且您可以随时切换回来。
热力图
热力图按两个维度绘制 span:
- X 轴: 时间
- Y 轴: 数值,默认为 span 的耗时 (以毫秒计,对数刻度)
颜色强度表示每个分桶中的事件数;越亮表示 span 越多。
您可以直接从热力图中看出一些模式:双峰延迟、特定时间点的延迟峰值、持续偏慢的 span 带状分布,或随时间逐渐上移的慢速带状分布 (逐步恶化的性能回退) 。要查看某个区域,请在其上单击并拖动框选一个矩形。这会成为您的 Selection,并将下方分析切换为比较模式。
分布模式:基数异常值
在热力图上未选择任何内容时,分析面板会为每个属性显示一个条形图,基于所有匹配的 span 计算得出。图例显示为 所有 span (可见于上方的概览截图中) 。
属性会按其值的集中程度排序:由少数几个值主导的属性会排在前面;分布均匀、熵较高的属性则会靠后。
当你想了解数据的基数形态时,请使用分布模式:
- 高值:哪些服务、端点、状态码或主机主导了你的 span 总体?这通常会暴露出某个租户、版本或路由承载了大部分流量。
- 低值:那些确实出现但很少见的值。某个状态码只出现在
0.5%的 span 中,或者某台主机几乎不出现,都可能是最值得关注的信号。长尾部分往往隐藏着回归问题和异常行为。
先结合搜索栏缩小总体范围 (例如,仅查看 error spans、仅查看 client spans,或仅查看某一个端点) ,然后再查看该子集的分布情况。
对比模式:与常态的偏差
在热力图上拖出一个矩形即可进入对比模式。选中的 spans 会成为 Selection (橙色条形) ;其余部分会成为 Background (绿色条形) 。随后,每个属性图表都会并排显示这两组数据,并按差异程度排序,因此偏差最大的属性会排在最前面。某个值如果几乎只出现在其中一侧,或只在其中一侧缺失,往往就是造成差异的最强线索。
你画出的矩形形态会改变你想要回答的问题。下面介绍两种常见的形态。
用例 1:回归前后对比
当热力图显示延迟随时间线逐渐上升时 (慢速带变厚、亮色带上移,或出现一个明显的拐点,将健康时段与性能退化时段分隔开) ,从上升拐点开始拖出一个矩形框,一直拉到窗口右边缘。为了让对比更清晰,应将矩形框的底边设在健康基线上,而不是坐标轴底部:这样可以只圈出退化窗口中确实比正常情况更慢的 spans,而不会把恰好落在同一时间范围内、但其实仍然健康且较快的 spans 一并纳入。
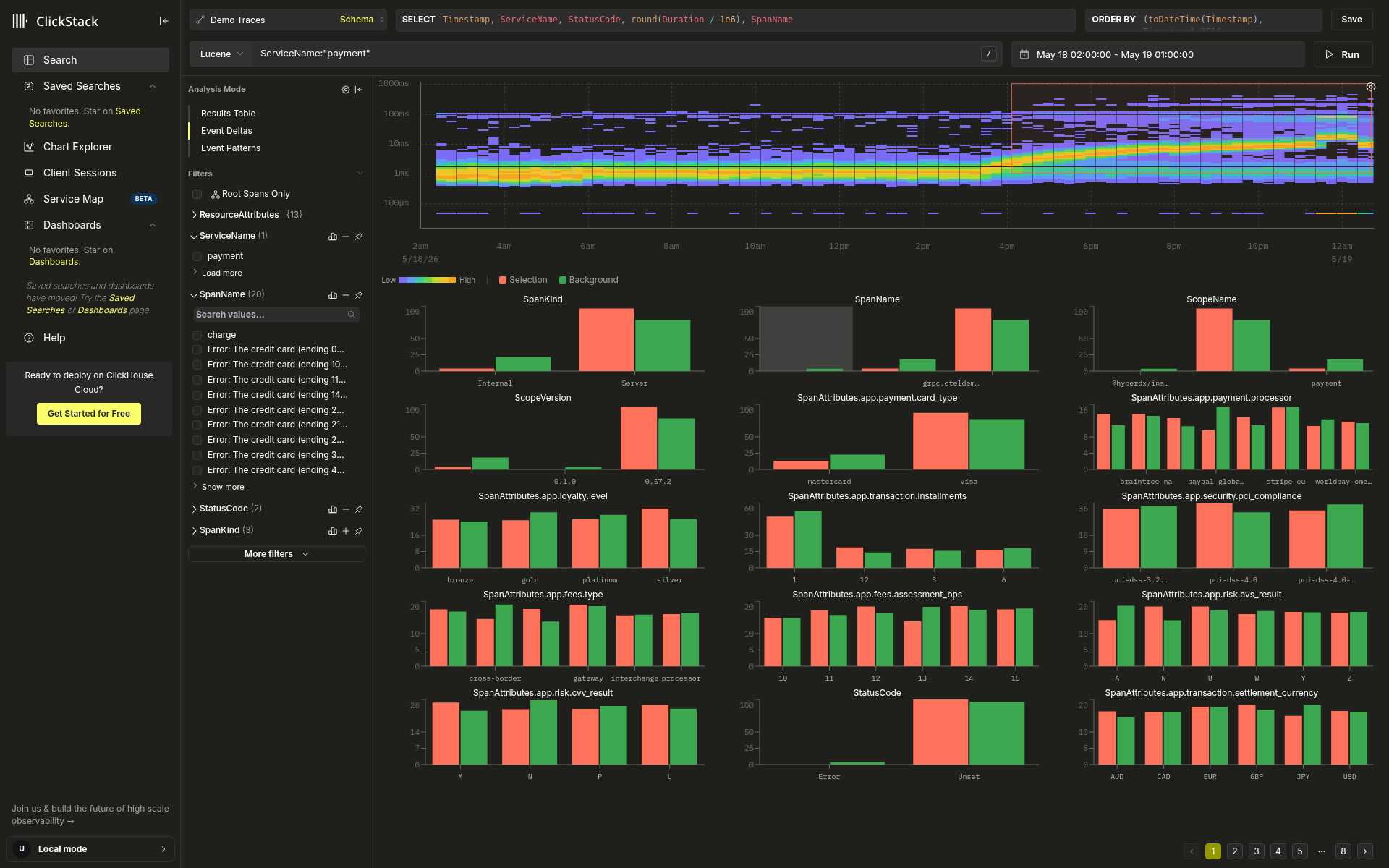
热力图下方的属性条会按差异最大的项优先排序。在这个示例中,顶行图表呈现出最强的信号:SpanKind、SpanName 和 ScopeName 都清楚地显示出慢速 Selection 与健康 Background 之间明显的橙绿分化。综合来看,它们勾勒出了拐点处发生变化的特征。
当你想问“发生了什么变化?”时,这就是合适的形态。还有一个更紧凑的变体,工作流程相同:当一小团慢速 spans 出现在原本平静的带状区域中时 (例如右边缘的短暂突发,或稳定时段中部的一簇) ,改为只围绕那一簇画一个小框即可。形态会改变问题本身:竖向条带问的是_时间上发生了什么变化_;小而聚焦的框问的是_这个簇有什么特别之处_。
用例 2:慢与快
当热力图在耗时轴上清晰显示出两个彼此分离的延迟群体时,拖出一个较宽的矩形,使其横跨整个时间范围,但只覆盖上方清楚分离出来的带状区域。较慢的群体会成为 Selection;较快的主体部分则成为 Background。
将矩形紧贴上方带状区域绘制,并确保它与下方密集主体之间留有明显的水平间隔。如果矩形画得过松、侵入快速群体,差异就会被冲淡。
100 s 的上限线本身就很有参考价值:在一个整数值上出现恒定的水平线,通常就是固定超时的典型特征。如果没有任何 span 属性能够清晰地区分这两个群体,这同样是一个有用的结果:它会提示你去查看主机和运行时层面的指标 (GC 停顿、I/O 争用、调度器延迟、冷缓存效应、噪声邻居) ,而不是继续看 span 属性。
当你想问“慢 span 与快 span 到底有什么不同?”而不是追查某个特定异常时,这就是合适的形态。出现明显差异的属性通常指向某条代码路径或某类输入原因;而对比结果平淡,则通常指向系统性原因。
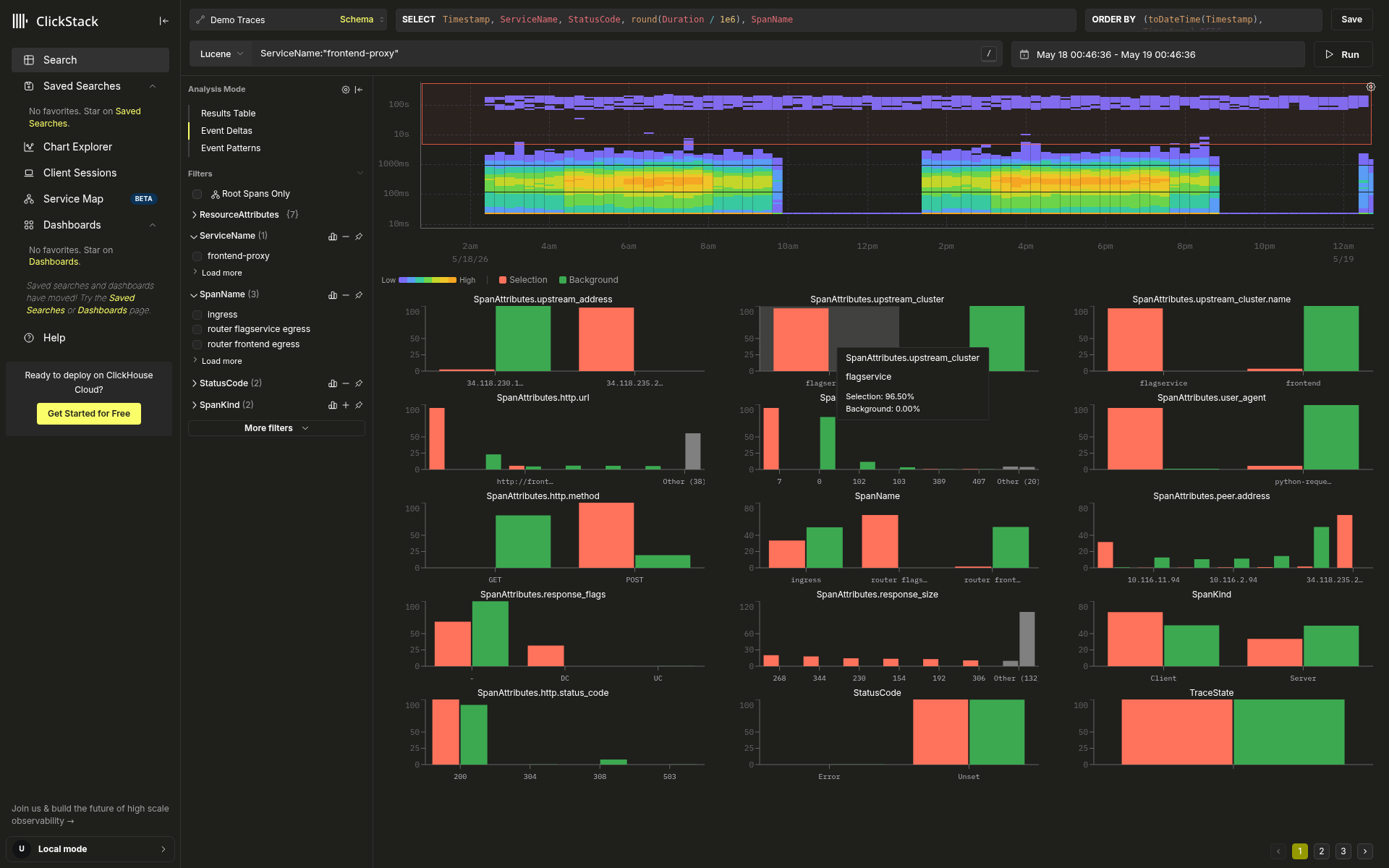
迭代式下钻
比较模式和分布模式在串联使用时效果最佳。单击任意条形图,即可打开一个包含三个操作的弹出框:
- Filter: 仅保留具有该值的 spans
- Exclude: 排除具有该值的 spans
- Copy: 将该值复制到剪贴板
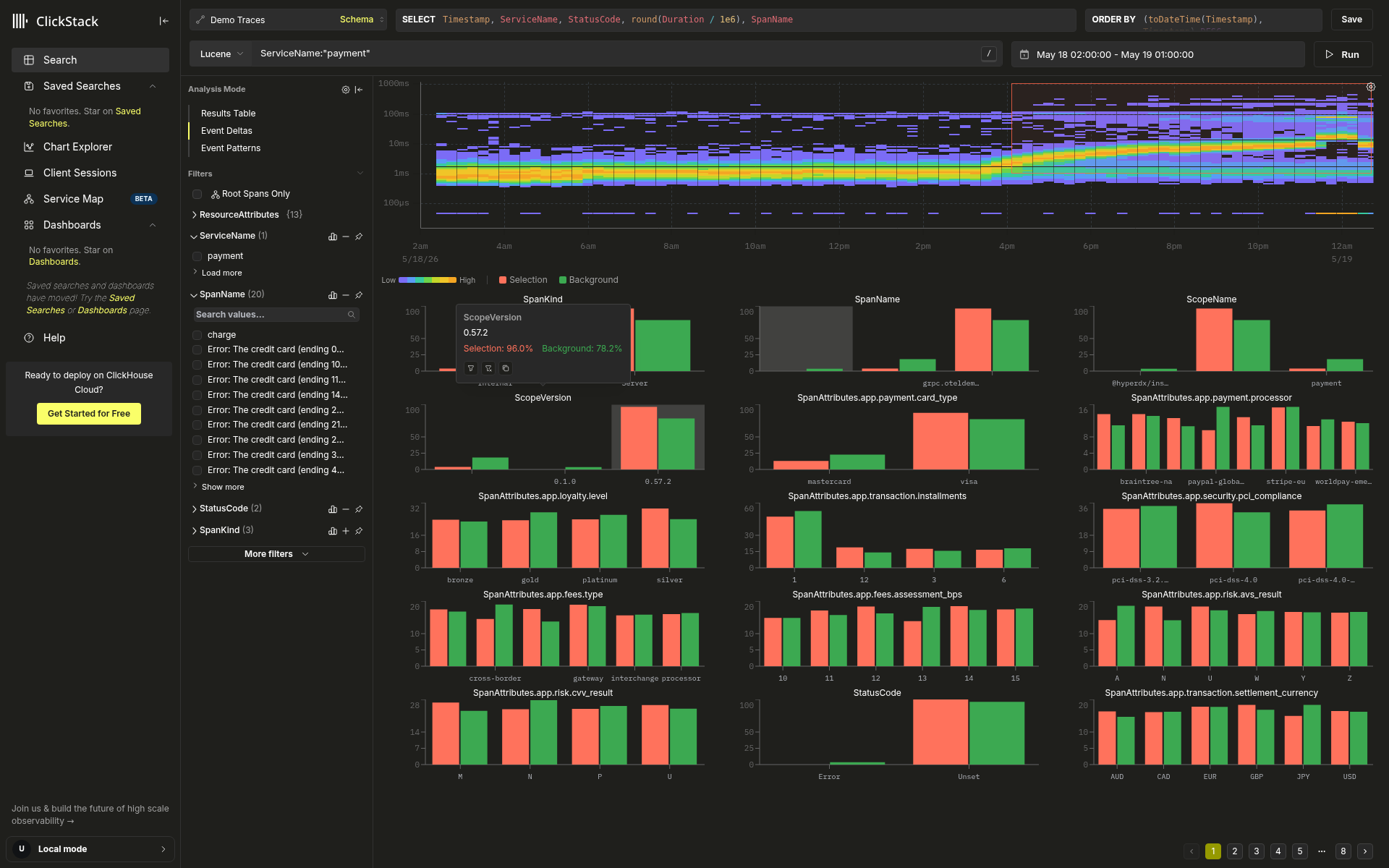
应用 filter 或 exclude 后,热力图中的选择会被清除,热力图会基于新的总体重新渲染,分布模式也会基于该筛选后的集合继续显示。观察热力图如何改变形态——成功的筛选会明显消除慢速带、收拢双峰分化,或拉平向上漂移。重复这一过程:找出下一个可疑值,筛选,查看新的热力图,再查看新的分布。经过几轮迭代,通常就能将回归范围缩小到一两个属性。
将低频值聚合后的 Other (N) 分桶不可点击。若要筛选该分桶中的特定值,请直接使用搜索栏。
当总体足够小时,切换到 结果表 选项卡以检查单个链路追踪;你的筛选条件会被保留。
自定义热力图
热力图右上角的齿轮图标会打开 Display Settings 抽屉。
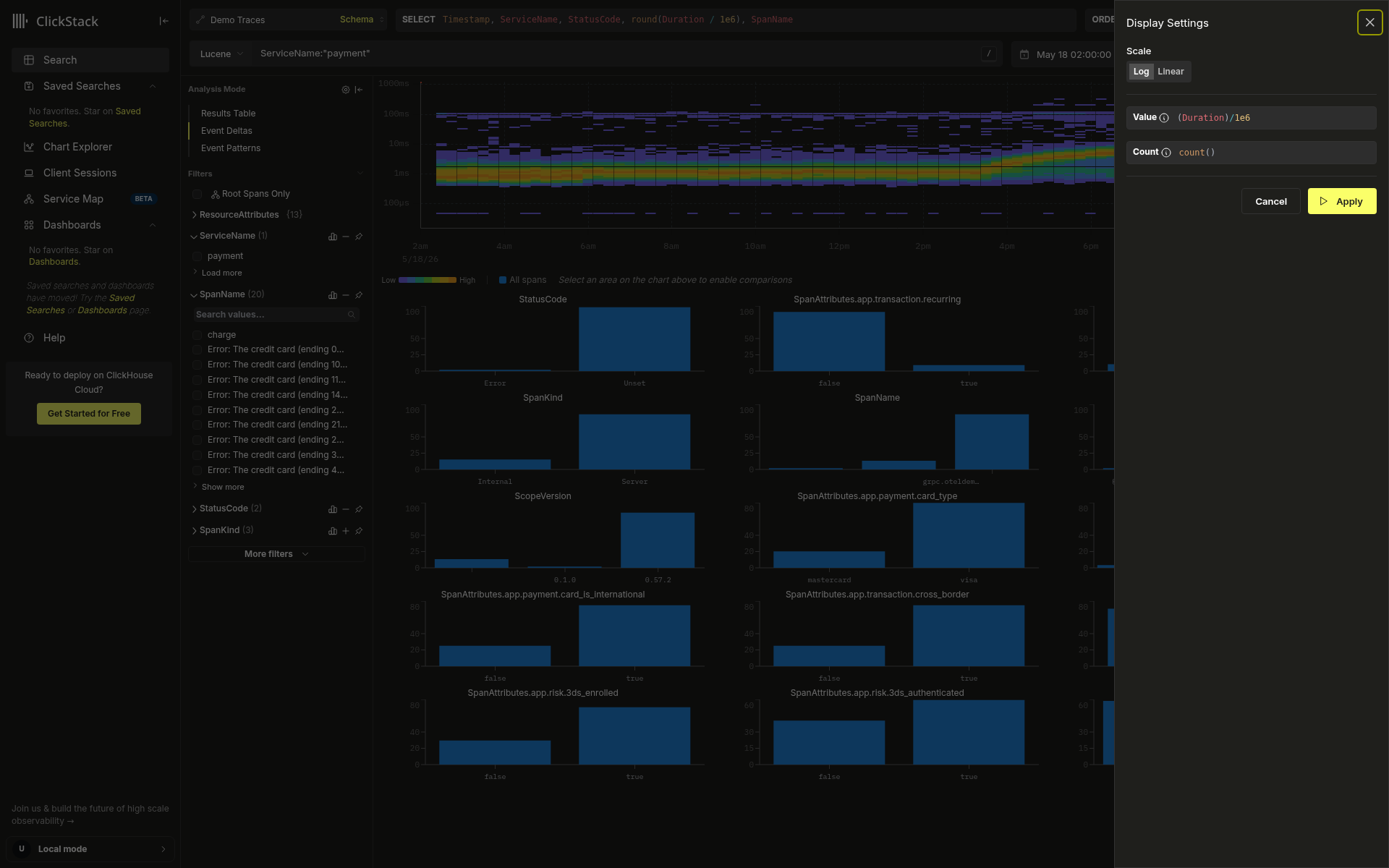
| 参数 | 默认值 | 说明 |
|---|---|---|
| Scale | Log | Log 适用于跨度较大的延迟范围;Linear 更适合范围较窄且分布均匀的场景。 |
| Value | (Duration)/1e6 | 任何数值表达式:响应大小、错误率或自定义 span 属性。 |
| Count | count() | 用于颜色映射的聚合方式。可切换为 avg()、sum()、p95(),或使用 countDistinct(field) 之类的表达式。 |
点击 Apply 更新热力图;下方的属性分析也会随之更新。
同一个热力图也可作为仪表板卡片使用,当你希望在事件增量下钻流程之外监控分布形态随时间的变化时,这会很有用。
以下是你可能会调整这些默认值的常见场景:
- 当延迟区间较窄时,将 Scale 切换为 Linear (例如某个服务的 spans 都在 5 到 50 毫秒之间) 。Log 标度会把没有数据的高值区间浪费掉垂直空间。
- 在 Y 轴上绘制耗时以外的指标。 将 Value 设置为
SpanAttributes.http.response.size,可帮助你排查缓慢且体积大的响应;像if(StatusCode = 'Error', 1, 0)这样的表达式则可按时间展示各服务的错误频率。 - 按 count 以外的指标着色。 将 Count 设置为
p95(Duration)后,每个 bucket 会按尾延迟而非数量着色,从而突出那些在基于 count 的视图中容易被淹没的少见高延迟区段。countDistinct(TraceId)则可在单个 trace 产生许多 spans 时,区分 trace 数量与 span 数量。
有效使用技巧
以下做法能让 Event deltas 发挥更大作用:
- 先筛选到单个服务。 不同服务之间的延迟差异可能很大,混在一起会掩盖信号。开始前,先用搜索栏将范围缩小到一个
ServiceName(或一个端点) ,这样热力图和分布反映的才是可比较的同类数据。 - 选择具有清晰视觉对比的区域。 比较模式在 Selection 带与 Background 有明显区别时效果最佳,例如从某个容易识别的时刻开始出现劣化的时间段,或与主体部分明显分离的慢尾。若所选区域与其余数据高度重叠,往往看到的是噪声,而不是真正的偏差。
- 按“过滤、热力图、再过滤”的方式迭代。 单次选择很少能直接定位原因。将第一次比较视为一个假设,对差异最大的值添加过滤器,然后重新查看新的热力图和分布。经过两到三轮迭代,通常就能将回归范围缩小到一两个属性。
- 在没有选区时使用分布模式,适用于暂时还看不出明显对比的情况 (你知道存在问题,但热力图看起来很均匀) 。先应用一个假设性过滤器,例如仅看错误 span、仅看客户端 span,或仅看某一个端点,然后在进行任何矩形框选之前,让属性分布先帮你找出影响最大的值。
故障排查
“事件增量”选项卡不可见
仅当在 分析模式 下选择了带有耗时表达式的 Trace 数据源时,才会显示 事件增量 选项卡。请确认您的数据源已配置为 Trace 类型,并且包含带有耗时信息的 span 数据。
属性图表显示的结果很少或没有结果
如果样本过小 (少于几十个 span) ,这些分布在统计上可能意义不大。请扩大时间范围或放宽搜索筛选器。
