仅部署 HyperDX
此选项适用于已经拥有运行中的 ClickHouse 实例,并且其中已写入可观测性或事件数据的用户。
HyperDX 可以独立于其余组件使用,并且兼容任意数据 schema——不仅限于 OpenTelemetry (OTel)。这使其非常适合已经基于 ClickHouse 构建的自定义可观测性管道。
要启用全部功能,必须提供一个 MongoDB 实例,用于存储应用状态,包括仪表板、已保存的搜索、用户设置和告警。
在此模式下,数据摄取完全由用户自行负责。你可以使用自己部署的 OpenTelemetry collector、从客户端库直接摄取、ClickHouse 原生表引擎 (例如 Kafka 或 S3) 、ETL 管道,或诸如 ClickPipes 等托管摄取服务,将数据摄取到 ClickHouse 中。这种方式提供了最大的灵活性,适合已经在运行 ClickHouse、并希望在其之上引入 HyperDX 以实现可视化、搜索和告警的团队。
适用对象
- 现有 ClickHouse 用户
- 自定义事件数据管道
部署步骤
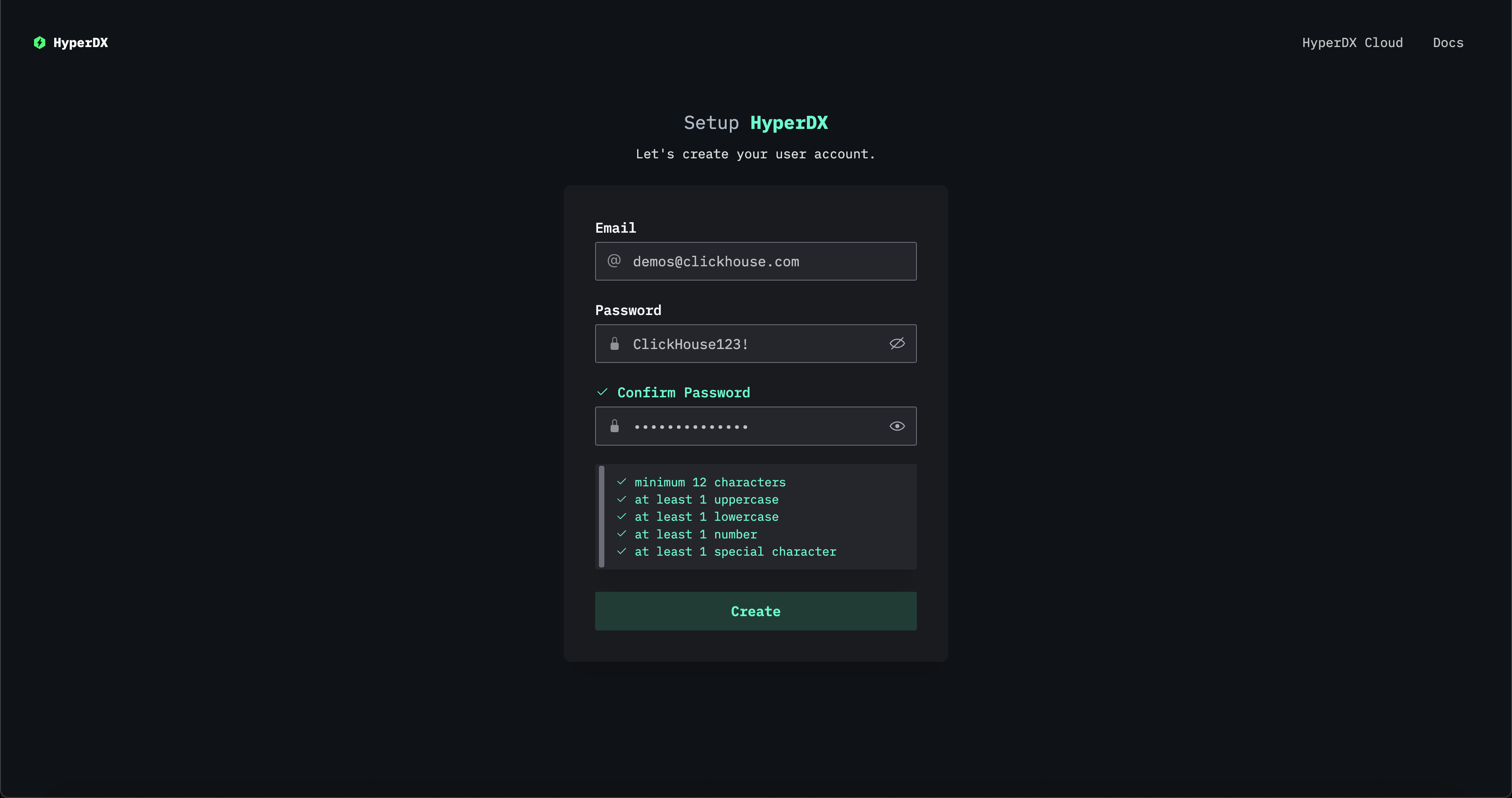
完成连接信息
连接到你自己的外部 ClickHouse 集群,例如 ClickHouse Cloud。
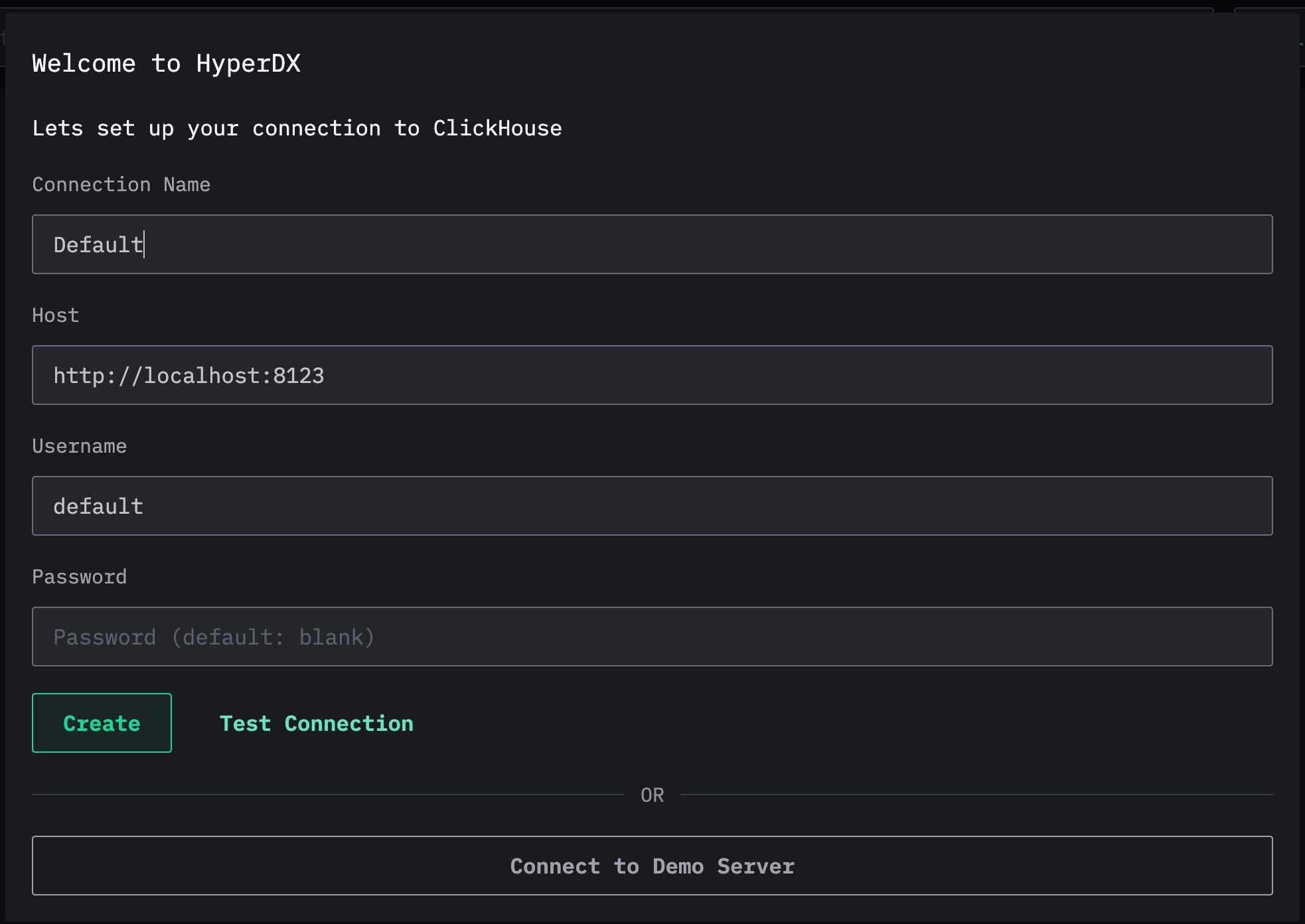
如果提示你创建一个 source,保留所有默认值,并将 Table 字段填写为 otel_logs。其他设置应会自动检测,此时可以点击 Save New Source。
创建 source 的前提是 ClickHouse 中已存在数据表。如果你还没有数据,建议部署 ClickStack OpenTelemetry collector 来创建数据表。
使用 Docker Compose
用户可以修改 Docker Compose 配置,以实现与本指南相同的效果,并从清单中移除 OTel collector 和 ClickHouse 实例。
ClickStack OpenTelemetry collector
即使您在该堆栈之外自行管理 OpenTelemetry collector,我们仍然建议使用 ClickStack 提供的 collector 发行版。这样可以确保使用默认的 schema,并采用推荐的摄取最佳实践。
有关部署和配置独立 collector 的详细信息,请参阅 "Ingesting with OpenTelemetry"。
schema 选择:Map 与 JSON
默认情况下,ClickStack 将属性存储为 Map(LowCardinality(String), String) 列。这是可观测性工作负载的推荐 schema。结合分桶化 Map 序列化以及 Map 键和值上的文本索引,它可以实现有选择的查找,而无需承担动态 JSON 子列为每个键带来的额外摄取开销。
JSON 类型的 schema 提供 Beta 版本,可用于评估属性键集合较小且稳定的工作负载。不建议将其作为默认选项。有关完整对比以及启用 JSON 支持所需的环境变量,请参见 Map 与 JSON 类型。
